OpenSeeker: Democratizing Frontier Search Agents by Fully Open-Sourcing Training Data翻译
⚠️ 在开始阅读之前,如果你对 实时 Agent / 数字人 / 多模态系统 / LiveKit 架构 感兴趣,
欢迎先到 GitHub 给项目点一个 ⭐ Star,这是对开源作者最大的支持。
🚀 AlphaAvatar 项目地址(强烈建议先收藏,该项目正在持续更新维护):
👉 https://github.com/AlphaAvatar/AlphaAvatar
🚀 AIPapers 项目地址(具有更全的有关LLM/Agent/Speech/Visual/Omni论文分类):
👉 https://github.com/AlphaAvatar/AIPaperNotes
摘要
深度搜索能力已成为前沿大语言模型(LLM)智能体不可或缺的核心能力,然而,由于缺乏透明、高质量的训练数据,高性能搜索智能体的开发仍然被行业巨头所主导。这种持续的数据匮乏从根本上阻碍了更广泛的研究群体在该领域的开发和创新。为了弥合这一差距,我们推出了 OpenSeeker,这是首个完全开源的搜索智能体(包括模型和数据),它通过两项核心技术创新实现了前沿级别的性能:(1)基于事实的可扩展可控问答合成,它通过拓扑扩展和实体混淆对网络图进行逆向工程,生成具有可控覆盖范围和复杂度的复杂多跳推理任务。(2)去噪轨迹合成,它采用回顾性摘要机制对轨迹进行去噪,从而促进教师 LLM 生成高质量的动作。实验结果表明,OpenSeeker 仅使用 11.7k 个合成样本进行单次训练,便在包括 BrowseComp、BrowseComp-ZH、xbench-DeepSearch 和 WideSearch 在内的多个基准测试中取得了最先进的性能。值得注意的是,OpenSeeker 使用简单的 SFT 训练,其性能显著优于排名第二的完全开源智能体 DeepDive(例如,在 BrowseComp 测试中,OpenSeeker 的准确率分别为 29.5% 和 15.3%),甚至在 BrowseComp-ZH 测试中超越了 Tongyi DeepResearch 等业界竞争对手(后者通过大量的持续预训练、SFT 和强化学习进行训练,准确率分别为 48.4% 和 46.7%)。我们完全开源了完整的训练数据集和模型权重,旨在促进前沿搜索智能体研究的民主化,并构建一个更加透明、协作的生态系统。
1.介绍
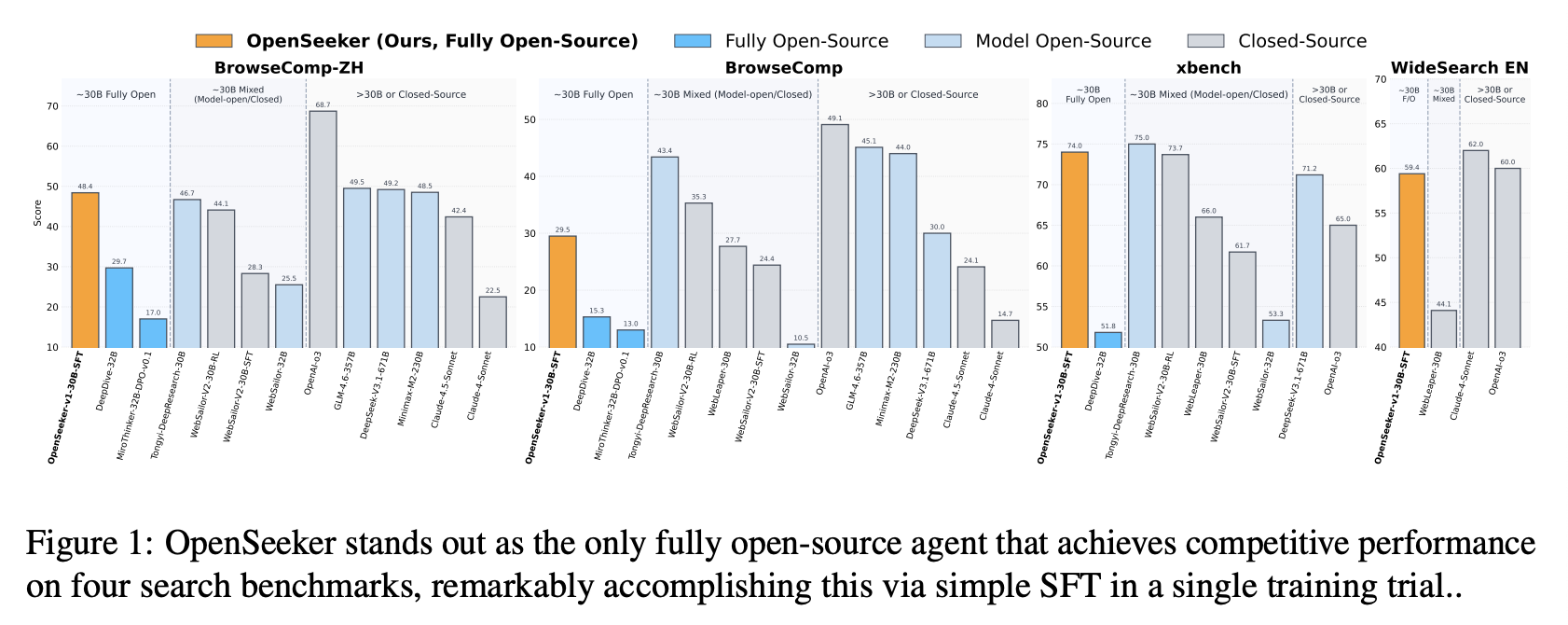
在信息爆炸的时代,从浩瀚的互联网中获取准确、实时、可靠的信息已成为现代决策的基石。因此,深度搜索能力已成为前沿大语言模型(LLM)智能体不可或缺的核心能力。过去一年,搜索智能体的发展突飞猛进。然而,截至2025年4月10日,即使是最先进的 LLM,例如OpenAI 的 o1,在具有代表性的 BrowseComp 基准测试中也难以突破 10 分。然而,到 2026 年 3 月,形势发生了巨大变化,超过 10 个智能 LLM 的得分超过了 50 分的阈值,这标志着自主网络智能的新时代。
然而,尽管取得了如此快速的进展,高性能搜索 Agent 的训练仍然是一场几乎完全由资金雄厚的企业实体主导的“闭门游戏”。目前,最强大的搜索 Agent 主要由谷歌和 OpenAI 等巨头的专有模型所主导。虽然包括 Kimi 和 Minimax 在内的知名实验室贡献了开源权重模型,但它们对训练数据却保持沉默。即使在研究界内部,现有工作要么开源模型却不提供数据,要么只提供部分数据,要么无法达到具有竞争力的性能。这种持续缺乏完整高质量训练数据的状况,已经阻碍了开源社区近一年的发展。
为了弥合这一差距,我们这个纯粹的学术团队推出了 OpenSeeker,这是首个完全开源的搜索 Agent,在网络搜索任务中达到了前沿水平。OpenSeeker 不仅仅是一个开放权重模型;它全面实现了搜索 Agent 流程的民主化,向社区提供了所有训练数据,包括复杂的问答对和详细的搜索轨迹。
OpenSeeker 背后的高保真数据由两项核心技术创新驱动:(1)基于事实的可扩展可控问答合成和(2)去噪轨迹合成。具体而言,(1) 我们的问答合成框架旨在超越当前模型通常通过表面模式匹配解决的简单检索任务。为了确保查询需要真正的多跳推理,我们从海量网络语料库中随机抽取的种子页面开始,对网络图进行逆向工程。具体来说,我们执行拓扑图扩展以识别相互关联的信息簇,然后将其提炼为实体子图。通过对这些子图应用实体混淆,我们将简单的事实转化为结构上要求多步骤导航的复杂推理难题。这种方法确保我们的数据基于事实(锚定于真实世界的网络拓扑结构)、可扩展(可用 TB 级网络存档)和可控(通过子图复杂度调节难度)。(2) 我们的轨迹合成方法旨在克服原始网络内容中固有的干扰因素。在生成阶段,我们采用 LLM 来总结先前的工具响应,从而为 teacher LLM 提供更清晰/去噪的历史记录,以生成更优的推理和行动。然而,在训练阶段,我们 student 模型预测这些专家决策,同时使其基于原始的、未经处理的历史记录轨迹。这种解耦迫使智能体内化强大的信息提取能力,学会“透过噪声看本质”,识别实现前沿性能所需的关键信号。
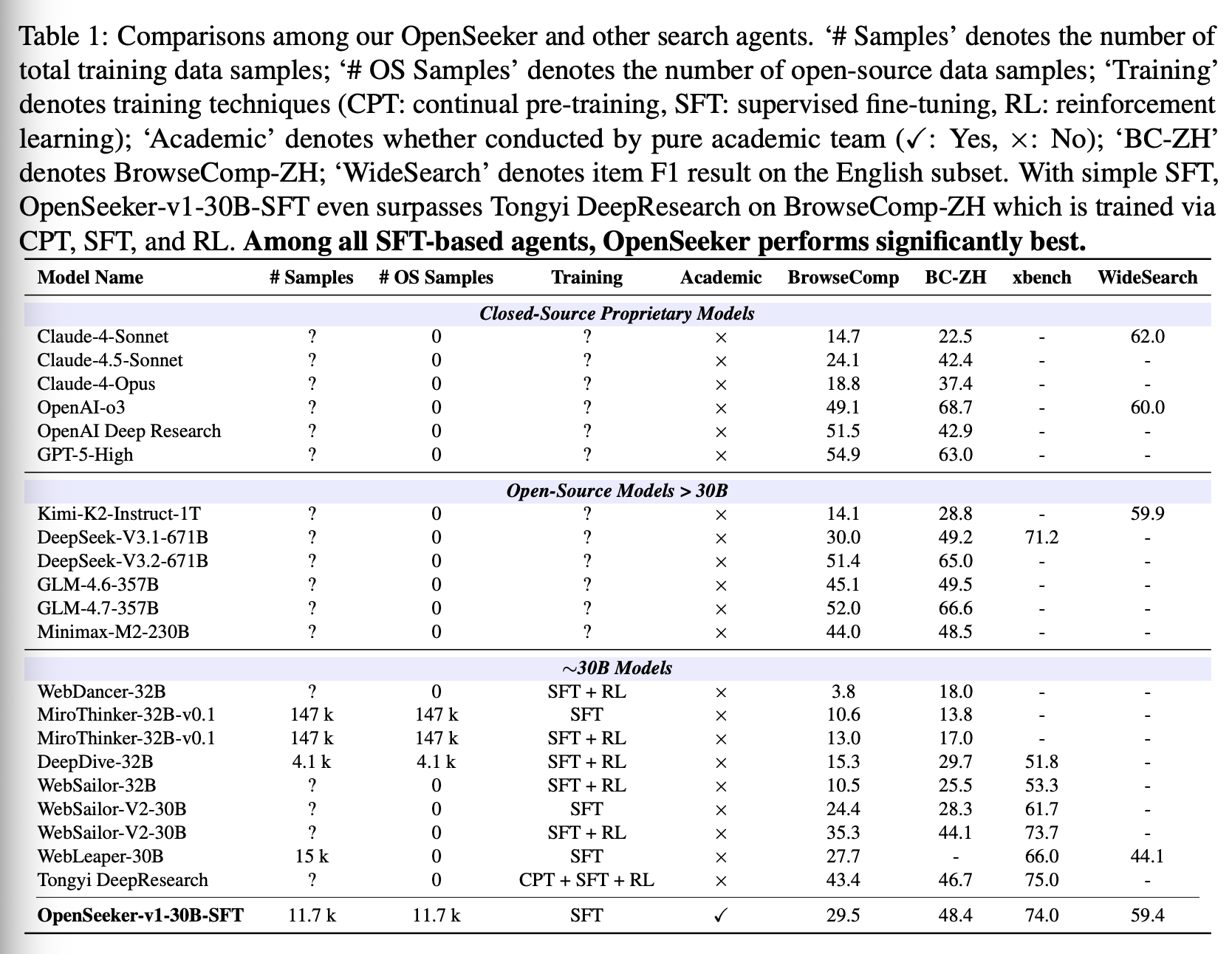
为了验证我们数据的有效性,我们合成了一个包含 10.3k 个英文样本和 1.4k 个中文样本的数据集,并在 Qwen3-30B-A3B 数据集上执行有监督微调 (SFT)。尽管仅使用了 SFT,OpenSeeker 在包括 BrowseComp (29.5%)、BrowseComp-ZH (48.4%)、xbench-DeepSearch (74.0%) 和 WideSearch (59.4% 项目 F1) 在内的基准测试中,与企业实体训练的模型相比,展现出了显著的竞争力。值得注意的是,在 BrowseComp-ZH 数据集上,OpenSeeker 的性能优于阿里巴巴的 Tongyi DeepResearch,后者采用了大量的持续预训练、SFT 和强化学习(OpenSeeker 的得分为 48.4,而同义深度学习的得分为 46.7)。在其他仅使用 SFT 训练的同等规模模型中,我们的 OpenSeeker 平均性能最佳,证明了我们训练数据的高质量。
我们的主要贡献总结如下:
- 我们提出了两种有效的技术:基于事实、可扩展、可控的 QA 合成和去噪轨迹合成,从而能够自动生成前沿级训练数据。
- 我们开发并发布了 OpenSeeker,这是一款在开源 Agent 中性能最先进的搜索 Agent,其性能可与企业开发的尖端解决方案相媲美甚至超越。
- 我们完全开源了整个合成解决方案、最终训练数据集(问答对和完整轨迹)以及模型权重,旨在加速搜索 Agent 的开发。
据我们所知,OpenSeeker 是首个由纯粹的学术团队开发,在完全开源所有训练数据的同时,在尖端搜索基准测试中取得最先进性能的项目。我们的工作完全由学术团队开发,旨在通过展示战略性数据合成能够有效弥合与工业级规模项目之间的性能差距,从而实现搜索智能的民主化。我们希望通过提供完全透明的数据,OpenSeeker 能够促进研究界参与到更加开放、协作和健康的自主智能体开发中。
2.Related Work
基于 LLM 的搜索 Agent 的演进,已将信息检索的范式从简单的关键词匹配转变为自主的多轮合成。大多数当代搜索 Agent 都基于 ReAct 范式构建,该范式利用推理-行动-观察循环与网络环境交互。历史上,这条道路一直由企业实体主导。(1) OpenAI 的Deep Research 开创了完全闭源的道路,随后出现了一系列专有 Agent,包括 Kimi-Researcher、Gemini 的Deep Research 和 Perplexity 的Deep Research。(2)近六个月来,涌现出一批具备搜索能力的“开放权重”模型,例如 Kimi K2/2.5 系列、智普 GLM 4.5-5、MiniMax M2-2.5 以及阿里巴巴旗下 Tongyi DeepResearch。然而,这些业界成果均未公开其训练数据,实际上构筑了一道“数据护城河”,将前沿性能作为商业机密加以保护。 (3)尽管研究界在 WebDancer、WebSailor、WebSailor-V2、WebLeaper、AgentFounder、DeepDive 和 MiroThinker 等框架方面取得了显著进展,但它们要么缺乏公开发布,要么只提供一小部分数据,要么数据保真度低,无法达到具有竞争力的性能。
这种现状导致研究界缺乏训练高性能智能体所需的高质量数据。OpenSeeker 通过完全开源其整个合成流程和高保真训练数据,明确地解决了这一空白,使前沿搜索智能的“配方”得以普及。据我们所知,OpenSeeker 是首个由纯粹的学术团队完成的工作,在开源完整训练数据的同时,在前沿搜索基准测试中取得了最先进的性能。值得注意的是,我们仅通过一次训练试验就获得了最先进的结果,无需任何迭代优化,这凸显了我们合成数据的高质量,并为未来的探索留下了广阔的空间。
3.Methodology
3.1 Overview & Problem Formulation
我们的主要目标是合成一个高保真数据集 D={(q,y,τ∗)}\mathcal D = \{(q, y, τ^∗)\}D={(q,y,τ∗)},其中包含复杂问题 qqq、真实答案 yyy 和最优工具使用轨迹 τ∗τ^∗τ∗。该数据集旨在使智能体 πθπ_θπθ 能够掌握用于深度搜索任务的长时工具调用策略。
我们将网络建模为一个有向图 G=(V,E)\mathcal G = (\mathcal V, \mathcal E)G=(V,E),其中 V\mathcal VV 表示网页,E\mathcal EE 表示超链接。合成挑战在于从 G\mathcal GG 中导出 (q,y)(q, y)(q,y) 对,使得求解 qqq 需要一条长度为 T≫1T ≫ 1T≫1 的轨迹 τ=[a1,o1,...,aT,oT]τ = [a_1, o_1, ..., a_T, o_T]τ=[a1,o1,...,aT,oT],其中 ata_tat 表示搜索动作,oto_tot 表示观测结果。我们认为,要有效地训练深度搜索智能体,必须解决两个关键挑战:(1) 高难度问答:只有足够复杂的 qeury 才能迫使系统进行严格的多轮交互循环,即“推理 → 工具调用 → 工具响应”。这一过程对于生成具有明确决策点和扩展工具调用链的长时轨迹至关重要。(2)高质量轨迹:解决方案路径的合成必须依靠稳定和可重复的方法,以确保提炼出的训练信号代表“正确和可推广的”策略,而不是从随机抽样中获得的偶然成功。
为了解决这些问题,我们提出了一种基于事实的可扩展可控问答合成框架和一种去噪轨迹合成方法。问答合成框架基于推理图的逆向工程原理:我们首先识别图 G\mathcal GG 中的潜在推理路径,然后构建一个问题 qqq,该问题在结构上要求系统遍历该路径。作为补充,我们的轨迹合成方法利用动态上下文去噪来生成清晰的推理和精确的工具调用。通过后续对原始轨迹进行训练,我们使智能体能够内在地学习如何对噪声工具响应进行去噪并提取相关信息。
3.2 Fact-Grounded Scalable Controllable QA Synthesis
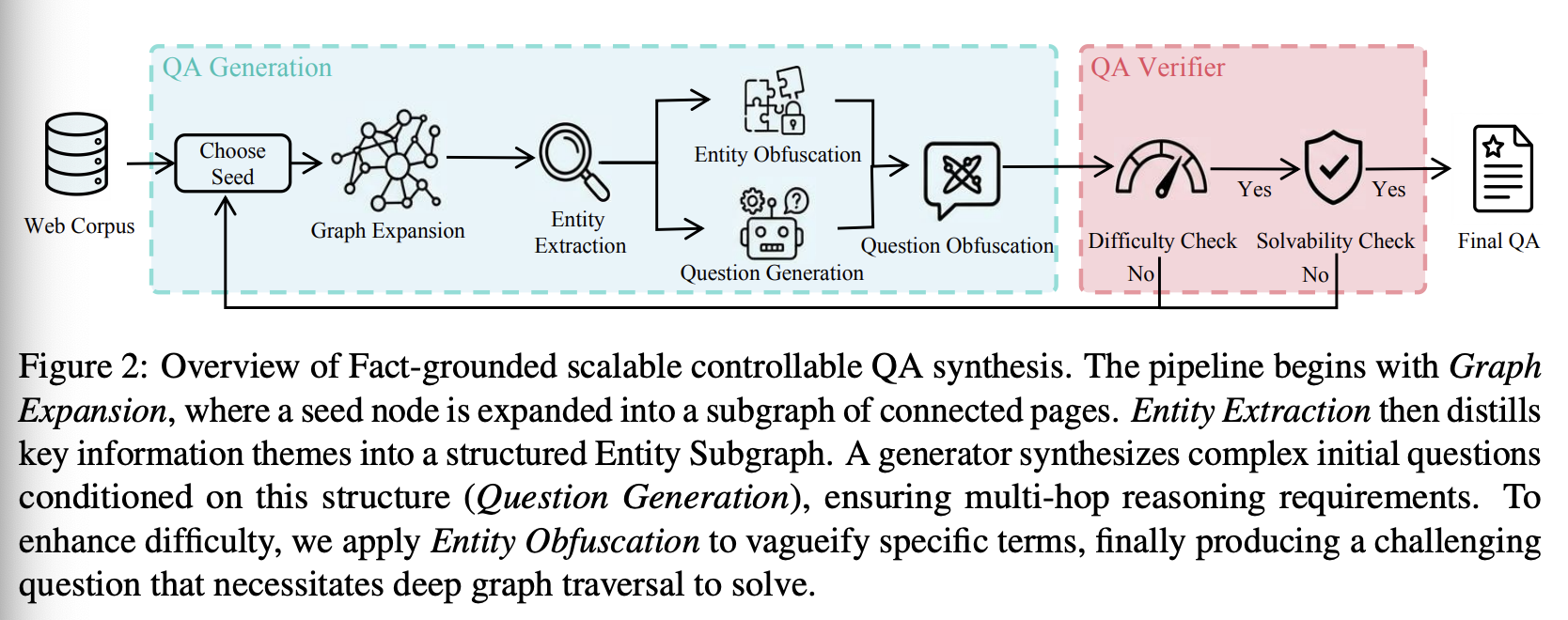
如图 2 所示,我们设计了一个流程,可以直接从网络图 G\mathcal GG 中构建问答对 (q,y)(q, y)(q,y)。通过利用网络图的内在连通性,我们将静态超链接转换为动态推理路径,从而确保事实依据和可控的复杂度。这个可扩展的框架分两个阶段运行:生成式构建阶段用于合成候选问答对,双重标准验证阶段用于严格筛选难度和可解性问题。
3.2.1 Generative Construction: From Graph to Question
Graph Expansion。为了模拟信息发现的自然过程(即一个线索引出另一个线索),我们首先对种子节点 vseed∼Vv_{seed} ∼ \mathcal Vvseed∼V 进行采样,以此启动流程。考虑到复杂问题很少仅存在于单个孤立的页面上,我们从 vseedv_{seed}vseed 出发,遍历其在 E\mathcal EE 中的出边,收集 kkk 个连通节点。这构成了一个局部依赖子图 Gsub={vseed}∪{vi∣(vseed,vi)∈E}k\mathcal G_{sub} = \{v_{seed}\} ∪ \{v_i |(v_{seed}, vi) ∈ \mathcal E\}_kGsub={vseed}∪{vi∣(vseed,vi)∈E}k,它作为构建问题所需的连贯且拓扑关联的知识库。
Entity Extraction。合成复杂问题需要利用生成模型来引用扩展子图 Gsub\mathcal G_{sub}Gsub 中的信息簇。然而,这些节点的原始内容通常包含过多噪声,会干扰生成模型。为了聚焦重点,我们识别出 vseedv_{seed}vseed 的中心主题 ythemey_{theme}ytheme,并执行提取函数。该函数从子图中提炼出一组与中心主题 ythemey_{theme}ytheme 直接或间接相关的关键实体,并将它们重组为一个精简的实体子图 Gentity\mathcal G_{entity}Gentity。在该图中,节点代表提取的实体,边则有效地保留了原始的拓扑连接。这一步骤有效地将 Gsub\mathcal G_{sub}Gsub 抽象成一个密集的关联结构,在去除文本噪声的同时保留了必要的逻辑路径。
Question Generation。为了防止生成可通过简单查找解决的问题,我们使用生成器 PgenP_{gen}Pgen 来合成初始问题 qinitq_{init}qinit,该问题明确地以实体子图 Gentity\mathcal G_{entity}Gentity 的结构为条件。我们施加了一个严格的结构约束:从 qinitq_{init}qinit 推导出 ythemey_{theme}ytheme 必须遍历 Gentity\mathcal G_{entity}Gentity 中的多条边。这明确地迫使智能体进行顺序多节点演绎推理,而不是单步检索。
Entity Obfuscation。合成问题旨在引导智能体执行多步骤的 ReAct 推理。然而,智能体通常会利用特定关键词通过直接搜索来简化推理过程。为了模拟真实的用户歧义并消除这些捷径,我们直接对 Gentity\mathcal G_{entity}Gentity 中的实体节点应用混淆算子 ΦΦΦ。具体实体 eee 被映射到模糊的描述性指称 e~=Φ(e)\tilde e = Φ(e)e~=Φ(e)。这种转换生成一个模糊实体子图 G~\tilde{\mathcal G}G~,其中结构连通性保持不变,但语义节点现在需要进行消歧。
Question Obfuscation。该流程最终生成最终问题 q~\tilde qq~,其输入为初始问题 qinitq_{init}qinit 和模糊实体子图 G~entity\tilde{\mathcal G}_{entity}G~entity。这种分离使得生成器可以直接引用 G~entity\tilde{\mathcal G}_{entity}G~entity 中预先混淆的描述,从而专注于合成复杂的问题结构。生成器重写 qinitq_{init}qinit 以纳入模糊描述,同时保留原始推理逻辑,目标答案保持不变,即 y=ythemey = y_{theme}y=ytheme。
3.2.2 Dual-Criteria Verification via Rejection Sampling
为了确保合成对 (q~,y)(\tilde q, y)(q~,y) 既具有挑战性又有效,我们采用基于两个指示函数的拒绝抽样方案:
(1)Criterion 1: difficulty (strict tool necessity)。设 πbaseπ_{base}πbase 为一个强基础模型。我们将难度条件定义为 I[πbase(q~)≠y]\mathbb I[π_{base}(\tilde q) \neq y]I[πbase(q~)=y],其中 πbaseπ_{base}πbase 在闭卷环境下(不使用任何外部工具)生成答案。如果模型仅使用参数记忆就能正确回答问题,则该问题将被舍弃。这保证了 q~\tilde qq~ 需要外部信息检索。
(2)Criterion 2: solvability (logical consistency)。我们将可解性条件定义为 KaTeX parse error: Undefined control sequence: \tilkde at position 20: …hbb I[π_{base}(\̲t̲i̲l̲k̲d̲e̲ ̲q|\mathcal G_{e…。这里,模型以实体子图 Gentity\mathcal G_{entity}Gentity 的完整内容作为上下文(oracle 设置)。如果模型无法推导出 y,则意味着推理路径断裂或出现错误。为了严格保证逻辑有效性,此类样本将被拒绝。
3.2.3 Discussions
我们的数据合成范式通过以下三个核心优势从根本上推进了智能体训练:
(1)Factual grounding:通过将 query 锚定在真实网络拓扑结构中,而不是依赖于 LLM 生成,可以显著降低甚至完全消除幻觉风险。每个训练样本都严格基于可验证的真实世界数据。
(2)Scalability:在这项工作中,我们利用约 68GB 的英文网页数据和约 9GB 的中文网页数据来验证我们的解决方案,结果表明该方案足以合成高质量的问答对,用于训练高性能的搜索代理。由于 TB 级网页存档仍未得到充分利用,我们的流程将开放网络转化为取之不尽的资源。通过不断改变种子页面或调整图配置,我们可以生成(几乎)无限的、多样化的、不重复的样本流,从而确保模型扩展不会出现数据瓶颈。
(3)Controllability:在我们的解决方案中,任务难度是经过精心设计的,而非随机变量。通过调整子图大小 (k),我们可以校准推理的复杂性和信息覆盖范围。这使我们能够构建定制化的课程,逐步引导智能体从简单的检索过渡到复杂的多跳调查。
3.3 Denoised Trajectory Synthesis
构建高质量的搜索轨迹需要严格平衡信息保留和上下文窗口约束。在网络规模的搜索中,原始观测数据往往充斥着无关噪声。为了解决这个问题,我们提出了一种合成框架,该框架在技术上将上下文生成(teacher)与上下文训练(student)解耦,并采用了一种动态上下文去噪策略。
3.3.1 Problem Formulation
定义搜索轨迹为序列 τ=[q,(r1,a1,o1),...,(rT,aT,oT),y]τ = [q,(r_1, a_1, o_1), . . . ,(r_T , a_T , o_T ), y]τ=[q,(r1,a1,o1),...,(rT,aT,oT),y],其中 qqq 为问题,rtr_trt 为推理步骤(思维链),ata_tat 为第 ttt 步的动作(工具调用),oto_tot 为第 ttt 步的观察结果(工具响应),最终得到答案 yyy。我们的目标是合成能够最优地导向答案 yyy 的特定推理路径 rtr_trt 和动作 ata_tat。
3.3.2 Synthesis via Dynamic Context Denoising
在轨迹合成过程中,我们采用一种**回顾式总结(retrospective summarization)**机制。这确保了智能体在保持简洁长期记忆的同时,能够利用来自最近过去的完整信息。形式化地,在第 ttt 步,智能体基于当前上下文 Ht\mathcal{H}_tHt 生成推理与动作对 (rt,at)(r_t, a_t)(rt,at)。我们的上下文构建遵循“Summarized History + Raw Recent”协议:
Ht={q,(r1,a1,s1),…,(rt−2,at−2,st−2)⏟Summarized Long-Term History,(rt−1,at−1,ot−1)⏟Raw Short-Term Context}(1) \mathcal{H}_t = \{q, \underbrace{(r_1, a_1, s_1), \ldots, (r_{t-2}, a_{t-2}, s_{t-2})}_{\text{Summarized Long-Term History}}, \underbrace{(r_{t-1}, a_{t-1}, o_{t-1})}_{\text{Raw Short-Term Context}}\} \tag{1} Ht={q,Summarized Long-Term History (r1,a1,s1),…,(rt−2,at−2,st−2),Raw Short-Term Context (rt−1,at−1,ot−1)}(1)
其中 si=Summarize(oi∣context)s_i = \text{Summarize}(o_i \mid \text{context})si=Summarize(oi∣context) 表示对观测 oio_ioi 的压缩语义摘要。该机制以两阶段循环方式运行:
-
决策阶段(信息使用):为了生成当前决策 (rt,at)(r_t, a_t)(rt,at),智能体接收上下文 Ht\mathcal{H}_tHt,其中包含来自紧邻前一步的完整原始观测 ot−1o_{t-1}ot−1。这保证了智能体可以访问最近观测中的所有潜在信号,从而指导其下一步行动,避免过早的信息丢失。
-
压缩阶段(上下文去噪):当步骤 ttt 结束并获得新的观测 oto_tot 后,系统会回顾性地调用总结器,将前一观测 ot−1o_{t-1}ot−1 压缩为 st−1s_{t-1}st−1。该摘要 st−1s_{t-1}st−1 随后在下一步 Ht+1\mathcal{H}_{t+1}Ht+1 的长期历史中替代 ot−1o_{t-1}ot−1。这种滑动窗口方法能够有效过滤噪声并对上下文进行去噪,从而在不降低性能的情况下支持极长时间跨度的生成。
3.3.3 Asymmetric Context Training for Robust Denoising
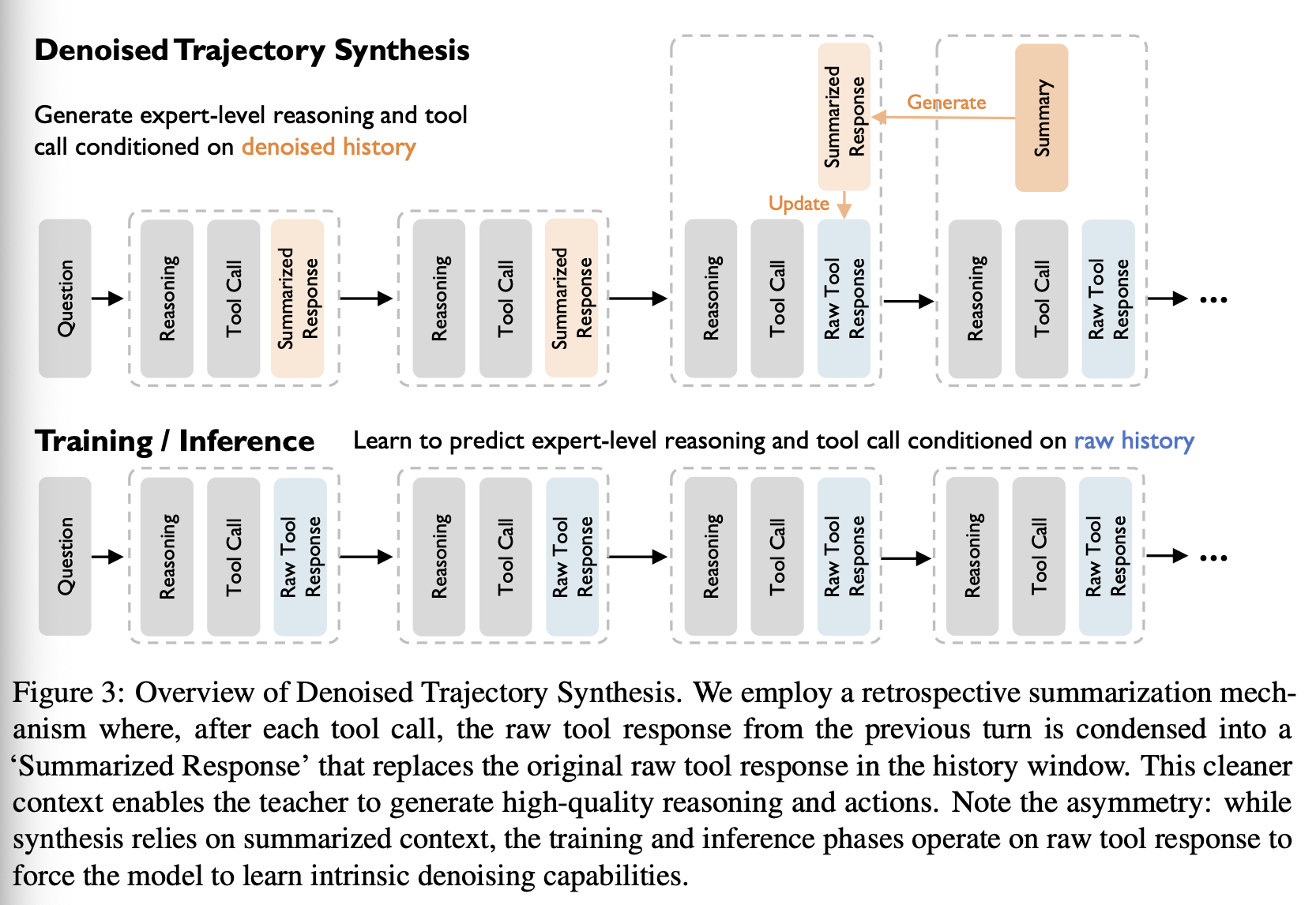
为了提升最终智能体的鲁棒性,我们在用于合成的数据格式与用于训练的数据格式之间定义了一种策略性的非对称性,如图 3 所示。
-
合成数据(教师):轨迹使用包含摘要的干净、去噪上下文 Ht\mathcal{H}_tHt 生成。这起到支架作用,使教师模型能够生成不受过多噪声干扰的“黄金”推理路径。
-
训练数据(学生):对于最终的训练数据集,我们去除摘要并恢复为完整的原始上下文:
Httrain={q,(r1,a1,o1),…,(rt−1,at−1,ot−1)}(2) \mathcal{H}_t^{\text{train}} = \{q, (r_1, a_1, o_1), \ldots, (r_{t-1}, a_{t-1}, o_{t-1})\} \tag{2} Httrain={q,(r1,a1,o1),…,(rt−1,at−1,ot−1)}(2)
学生模型在有噪声的原始上下文 Httrain\mathcal{H}_t^{\text{train}}Httrain 条件下,被监督去预测最优的 rt,atr_t, a_trt,at(来源于教师)。这迫使学生模型隐式学习去噪与信息提取能力,从而将上下文去噪逻辑内化到其自身参数中,以应对现实世界中的非结构化数据。
4.Experiments

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 0
0 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)