CVPR 2026 | 别人去噪要几十上百步,InvAD 只需 3 步反演:88 FPS 的扩散异常检测

导读
———————————————————————————————————————————
扩散模型做异常检测的主流范式是"重建":先给图片加噪,再去噪还原,通过比较原图和重建图的差异来定位异常。但这条路有两个绕不开的问题——噪声强度要精细调参(太强破坏正常区域,太弱漏检异常),去噪需要多步迭代(10-1000步),导致推理速度极慢,大多数方法只有1-2 FPS。
福井大学联合 UBC、Vector Institute 提出 InvAD,换了一条全新的思路:不做重建,做反演(inversion)。不是从噪声还原图片,而是把图片往噪声方向推,只需 3步 DDIM 反演,然后看最终的隐变量是否偏离了"正常分布"。正常图片会被映射到高密度区域,异常图片则会落在低密度区域。
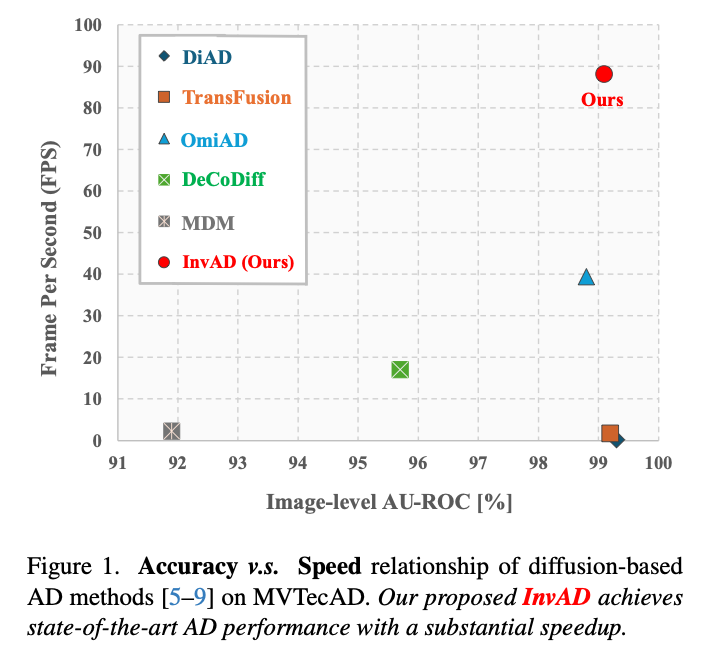
结果:MVTec-AD 图像级 AU-ROC 99.0%,推理速度 88.1 FPS,比此前最快的扩散方法 OmiAD(39.4 FPS)快 2.2 倍,且无需噪声强度调参。更关键的是,InvAD 是一个推理阶段的即插即用方案,可以直接嫁接到已有的扩散 AD 方法上。
论文信息
———————————————————————————————————————————
标题:InvAD: Inversion-based Reconstruction-Free Anomaly Detection with Diffusion Models
作者:Shunsuke Sakai, Xiangteng He, Chunzhi Gu(通讯作者), Leonid Sigal, Tatsuhito Hasegawa(通讯作者)
机构:福井大学、不列颠哥伦比亚大学(UBC)、Vector Institute for AI
发表:CVPR 2026
一、重建范式的两大痛点,为什么需要换一条路?
———————————————————————————————————————————
现有扩散模型做异常检测的方法几乎都遵循同一个范式:"在 RGB 空间做去噪检测"。流程是 x₀ → xₜ → x̂₀,先给输入图片加噪到某个时间步 t,再用训练好的扩散模型去噪还原,最后用原图和重建图的 MSE 差异来判断异常。
这个范式存在两个根本性问题:
问题一:噪声强度的两难困境。
加噪强度是一个需要精细调参的超参数。噪声太强,正常区域也会被破坏,重建不回来,产生大量误报;噪声太弱,异常区域也能被完美重建,导致漏检。论文在 Table 4 中做了系统对比:在 MVTec-AD 上,重建方法的 AU-ROC 从 64.7% 到 98.2% 不等,严重依赖噪声比例 r 和扩散步数 S 的组合。
问题二:多步去噪的计算瓶颈。
要获得高质量的重建结果,通常需要 10 到 1000 步迭代去噪。论文统计了现有方法的推理效率(Table 1):
|
方法 |
会议 |
函数评估次数(NFE) |
FPS |
免调参 |
多类别 |
|---|---|---|---|---|---|
|
DiAD |
AAAI'24 |
10 |
1.5 |
✓ |
✓ |
|
TransFusion |
ECCV'24 |
20 |
1.6 |
✗ |
✗ |
|
MDM |
ICML'25 |
40 |
1.9 |
✗ |
✗ |
|
OmiAD |
ICML'25 |
1 |
39.4 |
✗ |
✓ |
| InvAD(本文) | CVPR'26 | 3 | 88.1 | ✓ | ✓ |
InvAD 以 3 次函数评估达到 88.1 FPS,是唯一同时满足免调参和多类别统一检测的方法。
二、核心思路:"加噪检测"取代"去噪检测"
———————————————————————————————————————————
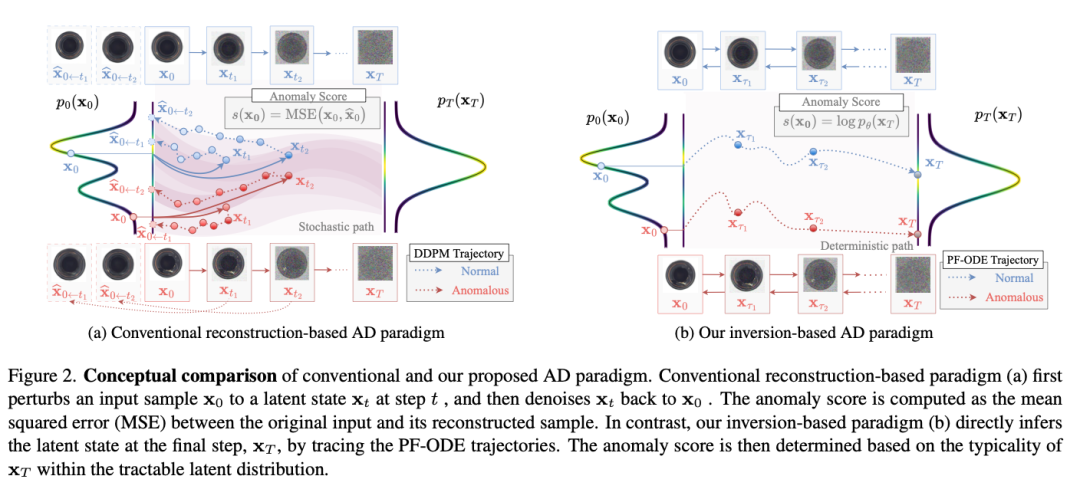
InvAD 的核心洞察是:扩散模型只在正常数据上训练过,它学到的就是正常数据的分布。与其用去噪来重建图片,不如用反演来测量图片是否"属于"正常分布。
具体做法:
DDIM 反演:给定输入图片 x₀,沿 PF-ODE(概率流常微分方程)的确定性轨迹,把图片反演到最终的隐变量 xT。由于 PF-ODE 是确定性的,这构成了数据分布和噪声先验分布之间的一一映射。
异常评分:正常图片会被映射到先验分布(标准高斯)的高密度区域,异常图片则会偏离。通过测量 xT 与已知先验分布的偏离程度来判断异常。
少步反演:用 Euler 方法近似 PF-ODE,只需 3 步反演就够了。因为扩散模型在反演过程中自适应地添加噪声,原始特征信息仍然被保留,不会因为步数少而丢失检测精度。
两种范式的对比:
|
维度 |
重建范式 |
InvAD 反演范式 |
|---|---|---|
|
流程 |
x₀ → xₜ → x̂₀(加噪+去噪) |
x₀ → xT(只做反演) |
|
异常评分 |
MSE(x₀, x̂₀) |
log p(xT)(先验分布偏离度) |
|
噪声调参 |
需要精细调参噪声比例 r |
不需要(免调参) |
|
推理步数 |
10-1000 步 |
3 步 |
|
轨迹类型 |
随机路径(DDPM) |
确定性路径(PF-ODE) |
异常评分的细节:论文设计了 NLL(负对数似然)+ Diff(欧氏范数空间差异)的双重评分方案。单独用 NLL 或 Diff 都不够鲁棒,但组合使用后对步数 S 的选择非常稳健——S=3 时 AU-ROC 99.0%,S=1000 时仍有 95.4%。
三、工业+医疗双场景验证:速度翻倍,精度SOTA
———————————————————————————————————————————
论文在 4 个主流基准上做了全面评估,涵盖工业和医疗两大场景。
工业异常检测(多类别统一设置)
Table 2 核心数据(图像级 AU-ROC / mAD 综合指标 / FPS):
|
数据集 |
InvAD AU-ROC |
InvAD mAD |
InvAD FPS |
OmiAD AU-ROC |
OmiAD mAD |
OmiAD FPS |
|---|---|---|---|---|---|---|
|
MVTec-AD |
99.0% |
83.7 |
88.1 |
98.8% |
85.3 |
39.4 |
|
VisA |
96.9% | 80.3 | 74.1 |
95.3% |
79.3 |
35.3 |
|
MPDD |
96.5% | 80.1 | 120 |
93.7% |
78.9 |
49.8 |
在 MVTec-AD 上需要区分两个指标:InvAD 的图像级 AU-ROC(99.0%)略高于 OmiAD(98.8%),但 综合 mAD 指标 OmiAD(85.3)反超 InvAD(83.7)——主要差距来自像素级 AP 指标(InvAD 46.5% vs OmiAD 52.6%)。在 VisA 和 MPDD 上,InvAD 在两项指标上均领先。
InvAD 真正的优势在于速度:88.1 FPS,是 OmiAD(39.4 FPS)的 2.2 倍,是 DiAD(1.5 FPS)的 58 倍。在 MPDD 上 FPS 达到 120,已接近实时检测的工业需求。
医疗异常检测(BMAD 单类别设置)
|
方法 |
mAD 综合 |
FPS |
|---|---|---|
|
PatchCore(CVPR'22) |
86.4 |
20 |
|
RD4AD(CVPR'22) |
84.2 |
20 |
| InvAD | 87.2 | 88 |
InvAD 在 6 个医疗数据集(脑瘤、肝脏、视网膜、肺部等)上达到最优 mAD 87.2%,同时速度是 PatchCore 的 4.4 倍。这验证了 InvAD 不限于工业场景,在医疗异常检测中同样有效。
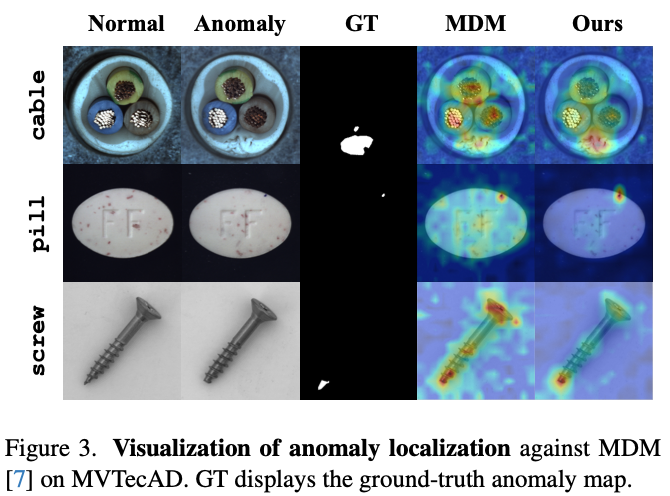
四、消融实验:反演为什么比重建好?3步为什么够?
———————————————————————————————————————————
反演 vs 重建的直接对比
论文在完全相同的模型上做了直接对比实验(Table 4):,只改变推理阶段的策略(重建 or 反演),对比在不同扩散步数 S 下的表现:
|
推理策略 |
S=3 |
S=5 |
S=10 |
S=50 |
S=100 |
S=1000 |
|---|---|---|---|---|---|---|
|
重建(最优 r) |
67.8% |
75.0% |
97.9% |
98.0% |
98.2% |
98.2% |
| 反演(InvAD) | 99.0% | 98.9% | 98.4% | 96.0% | 95.7% | 95.4% |
两个关键发现:
在少步(S=3)时差距巨大:反演 99.0% vs 重建 67.8%,说明反演范式天然适合少步推理
反演对步数选择很鲁棒:S 从 3 到 1000,AU-ROC 只从 99.0% 降到 95.4%;而重建方法需要 S≥10 才能达到可用水平
即插即用验证
InvAD 只修改推理阶段,不改变训练,因此可以直接嫁接到已有方法上(Table 5):
|
方法 |
原始 det. AU-ROC |
+InvAD det. |
原始 FPS |
+InvAD FPS |
|---|---|---|---|---|
|
DiAD |
97.2% |
98.2%(+1.0) |
0.1 |
88.1
(×880) |
|
MDM |
91.9% |
98.2%(+6.3) |
2.2 |
63
(×28) |
MDM 加上 InvAD 后,精度从 91.9% 跳到 98.2%,速度从 2.2 FPS 提升到 63 FPS。这验证了反演范式作为即插即用模块的实用价值。
各组件贡献
|
配置 |
特征空间扩散 |
单步反演 |
多步反演 |
mAD |
|---|---|---|---|---|
|
A1 |
✓ |
57.3 |
||
|
A2 |
✓ |
44.9 |
||
|
A3 |
✓ |
✓ |
71.0 |
|
| A4(InvAD) | ✓ | ✓ | 83.7 |
特征空间扩散(Feature Diffusion Model)和多步反演缺一不可。单步反演(A3: 71.0)远不如多步反演(A4: 83.7),3步是精度和速度的最优平衡点。
五、总结
———————————————————————————————————————————
论文贡献总结:
范式创新:提出"反演检测"取代"重建检测",从根本上绕开了噪声调参和多步去噪两大瓶颈
极致效率:3步反演达到 88 FPS,在保持 SOTA 精度的同时将推理速度提升 2 倍以上
即插即用:仅修改推理阶段,可嫁接到已有扩散 AD 方法上,如 DiAD 提速 880 倍
跨领域验证:在工业(MVTec-AD、VisA、MPDD)和医疗(BMAD 6个子集)两大场景均达到 SOTA
个人点评:
这篇论文最值得学习的是思路的简洁性。传统重建范式的问题(噪声调参、多步去噪)在社区中被认为是需要各种 trick 来缓解的工程难题,而 InvAD 直接换了一个角度——不重建了,直接测量反演后的隐变量是否"正常"。这种从 paradigm 层面解决问题的思路,比在旧范式里打补丁更有启发性。
88 FPS 的速度对工业部署有实际意义。目前工厂产线的检测节拍通常在 100-500ms/件,88 FPS(约 11ms/帧)已经完全满足实时需求,且留出了大量余量用于后处理。
需要注意的局限:
像素级定位精度有提升空间:虽然图像级检测是 SOTA,但像素级 AP 指标(如 MVTec 46.5%)低于 OmiAD(52.6%)和 DeSTSeg(54.3%)。对于需要精确标记缺陷边界的场景,这可能是瓶颈
依赖预训练特征提取器:InvAD 的性能与 EfficientNet-B4 特征提取器强相关(Table 7),更换特征提取器可能需要重新调优
训练仍需按数据集单独进行:多类别统一设置下仍需在每个数据集上从头训练扩散模型,跨数据集泛化能力未验证
总体而言,InvAD 用一个极简的思路解决了扩散 AD 的两大核心问题,在精度和速度上都达到了新的标杆。对于工业视觉检测场景,这是目前扩散路线中最值得关注的工作之一。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 26
26 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)