3.29: On hardware security bug code fixes by prompting large language models(基于提示大语言模型的硬件安全漏洞代码修复研究)

可译为:
《TIFS:基于提示大语言模型的硬件安全漏洞代码修复研究》
更自然一点的详细翻译:
《关于通过提示大语言模型来修复硬件安全漏洞代码的方法研究》
词语拆解:
- On ...
在论文标题里常表示“关于……的研究”。 - hardware security bug
硬件安全漏洞 / 硬件安全缺陷
指硬件设计或实现中会带来安全风险的错误。 - code fixes
代码修复 / 修补代码 - by prompting large language models
通过提示大语言模型
意思是利用 prompt 的方式引导 LLM 来完成修复任务。
一、先用一句话抓住整篇论文
这篇论文想回答的是:
当硬件设计里已经发现了一个安全漏洞之后,能不能通过给大语言模型一个合适的 prompt,让它自动生成修复代码?
作者的答案是:可以,而且效果相当不错,但前提是 prompt 设计、模型选择、温度参数、漏洞类型等都很关键。 他们甚至发现,一个 LLM 组合起来可以修掉他们 15 个 benchmark(基准测试) 里的全部 bug。
二、题目怎么理解
论文标题:
On Hardware Security Bug Code Fixes by Prompting Large Language Models
更准确地翻:
《关于通过提示大语言模型来修复硬件安全漏洞代码的研究》
这里有几个关键词:
- Hardware Security Bug:硬件安全漏洞,不是普通功能 bug,而是可能破坏保密性、完整性、权限控制之类的漏洞。
- Code Fixes:代码修复。
- Prompting LLMs:通过 prompt 引导大模型,而不是传统形式化修复或模板修复。
也就是说,这不是“让 LLM 写 RTL”这么简单,而是更具体的任务:在已知某段 RTL 有安全问题时,让 LLM 改对它。
三、这篇论文为什么重要
作者在引言里强调了一个很现实的问题:
- 软件 bug 修复已经有很多自动化工作;
- 但 硬件 bug 修复 研究还比较少;
- 尤其是 硬件安全 bug 更麻烦,因为芯片一旦流片,很多问题就很难再补。
这点非常关键。你可以这样理解:
- 软件错了,可以打补丁;
- 硬件错了,尤其是芯片级设计错了,代价极大;
- 所以如果能在 RTL 阶段尽早自动修复安全 bug[c16471] ,价值非常高。
四、作者到底做了什么
这篇论文做了 3 件事:
1. 构建了一个硬件安全 bug 修复数据集
他们整理了 15 个硬件安全 bug benchmark(基准测试),来源于 3 类设计:
- MITRE 的硬件 CWE 示例
- OpenTitan
- Hack@DAC 2021 SoC
其中覆盖了 10 类硬件 CWE。
2. 搭了一个“LLM 修复评测框架”
这个框架包括:
- 输入 bug 文件、bug 位置、CWE 类型
- 构造 prompt
- 调用 LLM 生成修复代码
- 用功能测试和安全测试验证修复是否成功
论文第 7 页的框图把流程画得很清楚:Sources → Repair Generator → Evaluator。
3. 系统评估不同 LLM 和 prompt 配置
他们测试了:
- 不同模型
- 不同温度
- 不同 prompt 指令详细程度
然后比较谁最有效。
五、论文研究的问题是什么
这篇论文本质上是在回答 5 个研究问题(RQ):
- 现成的 LLM 能不能修硬件安全 bug?
- prompt 细节到底有多重要?
- 什么类型的 bug 更容易被修?
- temperature 会影响修复效果吗?
- 不同 LLM 的能力差异有多大?
这 5 个问题就是你读实验部分时的主线。抓住这条主线,整篇文章就不会乱。
六、背景部分你必须先懂的几个概念
1. RTL / Verilog 是什么
作者研究的是 RTL(Register Transfer Level) 阶段的硬件设计代码,通常用 Verilog 这类 HDL 写。RTL 描述的是硬件电路中的数据如何传输、存储、变换。
和软件代码不同,RTL 不是“一行一行顺序执行”,而是很多硬件逻辑并行工作。这意味着修 bug 的方式也和软件不同。
2. 硬件安全 bug 是什么
作者把硬件安全问题主要放在两个目标上:
- Confidentiality(保密性)
- Integrity(完整性)
比如:
- 本不该读到的密钥被读到,破坏保密性;
- 本不该修改的安全配置寄存器被改了,破坏完整性。
3. CWE 是什么
CWE 是 MITRE 的 Common Weakness Enumeration,也就是常见弱点枚举。它给漏洞类型做了统一分类。作者选了和 RTL 设计紧密相关、且定义比较清晰的 10 类 CWE 来做实验。
七、这篇论文用了哪些漏洞类型
作者选的 10 类硬件 CWE,大意如下:
- 1234:调试模式能绕过锁
- 1271:保存安全设置的寄存器 reset 后没初始化
- 1280:访问敏感资源后才做权限检查
- 1276:子模块和父系统连错
- 1245:FSM 设计不正确
- 1298:竞争条件
- 1231:lock bit 没被正确保护
- 1311:fabric bridge 安全属性翻译错误
- 1254:比较逻辑粒度不对,可能被 timing attack 利用
- 1224:write-once 位域没有被正确限制
你现在不用死记编号,但要有一个感觉:
这篇论文不是在修普通语法错,而是在修权限、控制流、安全状态机、寄存器保护这类安全相关漏洞。
八、15 个 bug benchmark(错误基准测试) 是怎么来的
作者总共准备了 15 个 bug,分三类来源。
A. MITRE 示例
这里更多是比较小、清晰、教学式的 bug。
比如:
Bug 1: Locked Register
有个寄存器本来受 lock bit 保护,但 debug_unlocked 信号能绕过锁,导致本应锁住的寄存器还能写。
Bug 2: Lock on Reset
保存敏感信息的寄存器在 reset 时应该被赋一个确定值,但这里没有 reset 初始化。
Bug 3: Grant Access
本来应先检查 usr_id 是否正确,再决定是否写 data_out;但代码里由于赋值顺序/阻塞赋值问题,可能先写了再检查,形成访问控制错误。
Bug 4: Trustzone Peripheral
外设的安全等级信号被错误接地为 0,可能造成权限级别错误。
这些例子很适合初读,因为逻辑比较直白。
B. OpenTitan
OpenTitan 是开源安全芯片项目。作者不是直接找到现成 bug,而是人为往 OpenTitan 的安全机制 RTL 中注入 bug。
比如:
- ROM control 的告警逻辑错误
- OTP control 升级/错误状态逻辑错误
- Keymanager KMAC done 信号在错误状态下提前拉高
C. Hack@DAC-21
这是实际 SoC 竞赛环境中的 RTL 漏洞例子。
比如:
- debug 信号覆盖 interrupt
- PMP 寄存器 reset 没初始化
- case 语句不完整且没有 default
九、作者的方法到底怎么跑
这是这篇文章最核心的部分。
整体流程
作者的评测框架分成两个关键模块:
1. Repair Generator
输入有:
- buggy file
- bug 的位置
- bug 对应的 CWE 类型
然后作者构造 prompt。prompt 里包含:
- bug 前面的代码上下文
- 被注释包起来的 buggy code
- bug instruction (指令)
- fix instruction (指令)
也就是告诉 LLM:
- 这里有 bug
- bug 是什么类型
- 应该怎么修
然后 LLM 产出 repair candidates(修复候选者)。
2. Evaluator
把 LLM 生成的修复代码放回原设计中,再做两类检查:
- 功能正确性检查
- 安全性检查
只有两个都通过,才算成功修复。
这一点特别重要。因为“能编译”不代表“修对了”,甚至“功能过了”也不代表“安全对了”。
十、prompt 是怎么设计的
这是本文最大的亮点之一。
作者设计了 5 种 instruction variation(指令变体),从 a 到 e,详细程度逐渐增加。第 7 页表 III 给了概览。
Variation a
最简单,几乎不提供帮助:
//BUG://FIX:
这等于只告诉模型:“这里有 bug,你修一下”。
Variation b
加上自然语言描述 bug。
Variation c
除了 bug 描述,再加上自然语言 fix 指令。
Variation d
除了 bug 描述,再加上更像伪代码/设计意图的 fix 指令。
Variation e
最详细,甚至给一个bug 和 fix 的代码示例。
作者想研究:prompt 越详细,是不是就越有利于修复?
十一、作者测试了哪些模型和参数
模型
一共测了 7 个模型:
- gpt-3.5-turbo
- gpt-4
- code-davinci-001
- code-davinci-002
- code-cushman-001
- CodeGen
- VGen
其中前几个是 OpenAI 系列,后两个是开源模型。
温度
测试了:
- 0.1
- 0.3
- 0.5
- 0.7
- 0.9
作者关心:更“保守”的输出是不是更适合 repair。
其他设置
固定了:
top_p = 1n = 20max_tokens = 200
也就是每种配置一次生成 20 个候选。
十二、实验结果怎么理解
这是你读论文时最该抓住的地方。
RQ1:LLM 能不能修硬件安全 bug?
答案是:能。
作者一共请求了 52,500 个 repair,其中 15,063 个是正确修复,整体成功率 28.7%。
更重要的是:
- gpt-4、code-davinci-002、code-cushman-001
都至少对 15 个 bug 中的每一个 bug 成功修过一次。
这说明一件事:
LLM 不是“偶尔蒙对”,而是在这个任务上有稳定修复能力。
RQ2:prompt 细节重要吗?
答案是:非常重要。
作者发现:
- 比起只有
BUG/FIX标记的简单 prompt, - 加入 bug 描述 + fix 指令
- 会明显提高成功率。
尤其是从 variation b → c 的提升最大,说明:
告诉模型“怎么修”比只告诉它“哪里错了”更重要。
还有一个很有意思的点:
- 对 OpenAI 模型来说,variation d 通常最好;
- 也就是那种接近伪代码、带设计意图的 fix instruction 最有效。
这很值得你记住,因为它是一个非常实用的经验:
对 RTL repair,prompt 不是越像“代码样例”越好,往往是越像“工程师在解释修复意图”越好。
RQ3:哪些 bug 更容易修?
作者发现,不是所有 bug 难度都一样。
最容易修的
Bug 3 和 Bug 4 成功率超过 75%。
原因作者也分析了:
- 信号名非常清楚;
- 设计意图容易从代码里看出来。
比如 grant_access、usr_id 这种命名,本身就在告诉模型“先检查身份,再授权”。
最难修的
Bug 5、6、12 最难,成功率低于 10%。
原因分别大概是:
- Bug 6:需要非常具体而复杂的 case 修复;
- Bug 5:race/glitch 类问题比较“隐蔽”,模型甚至会觉得“没 bug”;
- Bug 12:修复方式是“删掉一行而不是替换”,这对模型不友好。
这背后的规律是:
越是依赖语义明确的命名和局部逻辑修复,LLM 越强;越是隐蔽、时序型、跨多行结构化改动,LLM 越弱。
RQ4:temperature 有影响吗?
答案是:有,而且总体上低温度更好。
作者发现:
- 大多数模型在 temperature = 0.1 时最好;
- 温度越高,成功率通常越低。
这很好理解:
- 修复代码不是创意写作;
- 需要更确定、更保守的输出。
所以低温更适合 repair。
这里的 temperature 不是硬件温度,也不是芯片温度,而是 大语言模型生成文本时的一个采样参数。
你可以把它先粗略理解成:
temperature 越低,模型越“保守”;temperature 越高,模型越“发散”或“随机”。
1. temperature 到底是什么意思
当 LLM 生成下一个 token 时,不是永远只选“概率最高”的那个词,而是会根据概率分布去采样。
- 低温度:更偏向选概率最高的词
→ 输出更稳定、更像“标准答案” - 高温度:会更愿意尝试次优但也可能合理的词
→ 输出更多样,但也更容易跑偏
所以在代码修复任务里:
- 低温度:更容易给出保守、规范、重复性高的修复
- 高温度:更容易生成不同写法,但也更容易引入错误
2. 为什么论文里要比较 temperature
因为作者不是只问:
“LLM 能不能修 bug?”
他们还想问:
“在什么参数设置下,LLM 修 bug 效果最好?”
而 temperature 就是最重要的生成参数之一。
所以他们专门把它当成一个研究问题来测,也就是 RQ4。论文明确说他们测试了:
- 0.1
- 0.3
- 0.5
- 0.7
- 0.9
3. “哪里需要温度对比”是什么意思
需要对比的地方是:同一个 bug、同一个 prompt、同一个模型,在不同 temperature 下,修复成功率会不会变。
也就是说,作者固定其他条件,只改 temperature,看结果差多少。
比如实验里他们会这样比较:
- 同一个 bug
- 同一个 instruction variation
- 同一个模型,比如 GPT-4
- 分别设 temperature = 0.1 / 0.3 / 0.5 / 0.7 / 0.9
- 每种配置生成 20 个 repair
- 看最后有多少个 repair 是功能和安全都正确的
所以这里的“温度对比”本质上是:
比较模型在不同随机性强弱下,哪一种更适合做 RTL bug repair。
4. 论文里是怎么做这个对比的
作者在实验设置中明确写了:
- 改变 Temperature 和 Models
- 同时固定:
top_p = 1n = 20max_tokens = 200
这意味着:
- 每组参数都会生成 20 个候选修复;
- 然后统计其中成功修复的个数;
- 再比较不同温度下成功数的变化。
第 11 页图 8 下面那张图,就是在比较不同 temperature 下各模型的正确修复数量。作者总结说:整体上低温更好,0.1 的效果最好。
5. 为什么低温度更适合修复代码
因为代码修复和写故事不一样。
如果是创作型任务,高温度有时有帮助,因为它能带来更多样化表达。
但在 bug repair 里,目标通常是:
- 精确
- 语法合法
- 逻辑不跑偏
- 尽量少改动但改对
所以更“保守”的生成策略往往更合适。
作者也明确说了:低温度带来的响应变化更少,而这种较少变化的输出更可能是正确修复。
6. 你可以把它想成考试答题
举个直观类比:
同一道修 bug 题,temperature 就像答题风格。
- temperature = 0.1
像一个很谨慎的学生:尽量按最稳妥的方法答 - temperature = 0.9
像一个很大胆的学生:可能会想出新写法,但也更容易离题
对于“修代码”这种任务,通常老师更喜欢前者。
所以实验里低温更占优。
7. 这篇论文中 RQ4 的真正含义
你可以把 RQ4 翻成一句更好懂的话:
为了让 LLM 更稳定地修复硬件安全 bug,生成时应该保守一点,还是发散一点?
作者的结论是:
总体上应该保守一点,也就是用更低的 temperature。
8. 最后给你一个最简记忆法
你只要先记住这句就够了:
temperature 是控制 LLM 输出随机性/发散程度的参数,不是物理温度。论文比较它,是为了看“保守生成”还是“发散生成”更适合 RTL 修复。结果是低温通常更好。
要不要我下一步直接拿这篇论文里的一个具体 bug,给你演示“同一个 prompt 在高温和低温下为什么效果会不一样”?
RQ5:哪个模型最好?
结论很明确:
- gpt-4 最强
- 成功率 51.5%
- 远高于其他模型。
后面依次是:
- code-davinci-002:43.4%
- gpt-3.5-turbo:31.6%
- code-davinci-001:30.6%
- code-cushman-001:29.1%
- CodeGen:9.9%
- VGen:4.7%
作者还提到一个有趣现象:
- 并不是“针对 Verilog 微调过”就一定更强;
- 比如 VGen 反而比 CodeGen 还差。
这说明:
模型能力不只取决于“领域微调”,还取决于底座规模、训练质量和对编程任务的整体适配。
十三、和 CirFix 比,谁更强
论文还把方法和已有 RTL repair 工具 CirFix 做了对比。
结论是:
- 在 CirFix 的 32 个 benchmark(基准测试) 上,
- 使用 gpt-4,
- variation a 修复了 19 个;
- variation b 修复了 22 个;
- 而 CirFix 修复了 16 个。
这说明在这组对比里,LLM 方案已经超过了已有方法。
但你要注意:
- CirFix 更偏传统自动修复;
- 它需要 oracle/testbench;
- 而 LLM 方法更依赖 prompt 和语言能力。
所以两者其实不是完全同类竞品,更像两条路线。
十四、这篇论文还有一个很有意思的扩展
作者还尝试把他们的方法和静态检测工具 CWEAT 接起来,形成一个“检测 + 修复 + 再验证”的端到端流程。第 12 页的图 10 画了这个流水线。
流程是:
- CWEAT 先检测 bug;
- 把定位结果交给 LLM;
- LLM 生成 repair;
- 再用 CWEAT 复查修复后是否还存在同类问题。
这个想法很重要,因为它代表作者真正想做的不是“单次生成代码”,而是:
把 LLM 作为硬件安全设计流程中的一个自动修复环节。
十五、论文的核心贡献,你可以这样总结
如果你之后要写 related work 或汇报,这篇文章可以概括成 4 点:
1. 首次较系统地研究 LLM 修复硬件安全 bug
不是只给一两个例子,而是做了 15 个 benchmark(基准测试)、10 类 CWE 的系统实验。
2. 提出了一个完整的评测框架
包括 prompt 构造、repair 生成、功能验证、安全验证。
3. 证明 prompt engineering 对 RTL repair 非常关键
尤其是“伪代码式 fix instruction(指令)”最有效。
4. 证明 LLM 在某些 RTL repair 任务上已经超过已有工具
至少在他们的实验设置下,优于 CirFix。
十六、论文的局限性也要看懂
作者自己也写得比较诚实。
1. 仍然假设 bug 位置已知
也就是说,他们没有完全解决“从整个 RTL 工程里自动发现 bug”这个问题,而是主要研究已知 bug 位置后的修复。
2. prompt 设计带有人工经验
fix instruction 怎么写,很大程度上依赖作者经验。这个过程还不够标准化。
3. 功能和安全验证不完全穷尽
特别是复杂 SoC 场景下,不可能对每个 repair 都做完全 exhaustive(全面的) 验证。作者很多地方采用了定制 testbench 和局部安全检查。
4. 对复杂、隐蔽、多位置漏洞能力还有限
例如 race condition、粒度比较漏洞、多行复杂改动,效果明显差。
所以你不能把这篇论文理解成“LLM 已经解决 RTL 安全修复”,而应该理解成:
它证明了这条路线可行,而且很有潜力,但还远没到工业成熟。
十七、如果你要真正“读懂”这篇论文,最该抓住的思想
我帮你提炼成 3 句话:
第一句
LLM 可以做硬件安全修复,但前提是任务表达得足够清楚。
第二句
在 RTL repair 里,prompt 不是附属品,而是方法本身的一部分。
第三句
LLM 更适合做“候选修复生成器”,而不是单独充当最终裁判。检测器、测试、静态分析仍然必不可少。
这 3 句话,基本就是整篇论文的灵魂。
十八、你现在可以怎么继续读这篇论文
我建议下一步不要一下子贪多,我们可以按这个顺序继续:
- 先精读第 III 节 Designs and Bugs
我带你把 15 个 bug 一个个讲清楚,尤其是前 4 个 MITRE 例子,很适合入门。 - 再精读第 IV 节 Experimental Method
这是方法核心,尤其是 prompt 设计和 variation a-e。 - 最后精读第 V 节 Results
我带你看图 6、图 8、图 9,教你怎么读实验图。
我们下一步就从 Bug 1 到 Bug 4 的代码级理解 开始最合适。
好,我们就按这个顺序来,先精读 第 III 节 Designs and Bugs,从 Bug 1 到 Bug 4 开始。这 4 个都来自 MITRE 风格的小例子,最适合建立直觉。它们的共同特点是:bug 很局部、修复目标很明确、能直接看懂“错在哪”和“该怎么改”。 论文第 4–5 页给了这些例子的代码和修复示意图。
我会按这个结构讲每个 bug:
- 设计本来想干什么
- bug 出在哪
- 为什么这是安全问题
- 正确修复在逻辑上做了什么
- 这个例子为什么适合 LLM 修
先给你一个总视角
这 4 个 bug 分别对应 4 类典型安全错误:
- Bug 1:锁保护被调试信号绕过
- Bug 2:安全寄存器 reset 时没有初始化
- Bug 3:访问控制检查做晚了
- Bug 4:安全属性信号连错了
如果你把这 4 个搞懂,后面读 OpenTitan 和 Hack@DAC 那些更复杂例子时,会轻松很多。因为后面很多复杂 bug,本质上也是这几类问题的“工程化版本”。
Bug 1:Locked Register锁保护被调试信号绕过
1. 这个设计本来想做什么
这个模块里有一个寄存器,它受一个 lock bit 保护。
设计意图是:
- 当
lock_status为低时,允许写入; - 当
lock_status为高时,不允许改这个寄存器。
论文对这个 bug 的描述是:
寄存器只有在 lock_status 为低时才应被修改,但实际代码里额外加了一个 debug_unlocked 信号,它会覆盖锁保护。
2. bug 出在哪
问题代码大意是这种逻辑:
else if (write && (!lock_status || debug_unlocked)) begin Data_out <= Data_in; end
也就是:
- 正常情况下,如果没锁住,可以写;
- 但即使锁住了,只要
debug_unlocked为真,也还能写。
论文在图 1(a) 明确说明:debug_unlocked 覆盖了 lock_status,导致即使锁已经生效,寄存器仍可被写入。修复方式就是把这个 debug 覆盖逻辑去掉。
3. 为什么这是安全问题
因为 lock bit 的设计初衷就是:
一旦安全配置写好并锁住,就不能再被普通路径修改。
但现在代码留了一个“后门”:
- 锁看起来存在;
- 实际上 debug 信号一来,锁就没用了。
这就属于典型的 debug / internal mode override locks,也就是论文前面提到的 CWE-1234 一类问题。
你可以把它理解成:
- 门上有锁;
- 但管理员模式偷偷留了个旁门,能绕过锁直接进去。
如果这个寄存器保存的是安全配置、地址保护、访问权限之类内容,那攻击者就可能改掉关键设置。
4. 正确修复做了什么
修复后的核心逻辑就是:
else if (write && !lock_status) begin Data_out <= Data_in; end
只保留真正应该存在的条件:
- 只有没锁住时,才能写。
论文图 1(a) 里绿色修复部分就是把 debug_unlocked 从条件里拿掉。
5. 为什么这个 bug 适合 LLM 修
因为它有几个对 LLM 很友好的特点:
- 条件局部、只改一行;
- 信号命名比较直白:
lock_status、debug_unlocked; - 设计意图容易从名字推出来;
- 修复属于“删除一个错误条件分支”。
这种类型的 bug 很适合 prompt 告诉模型:
debug 信号不应该绕过 lock。
然后模型就有机会直接生成正确修复。
Bug 2:Lock on Reset
1. 这个设计本来想做什么
这个设计里有一个寄存器 locked,它保存安全相关状态。
设计要求是:
- 在 reset 时,这个寄存器必须有一个确定值;
- 不能在复位后处于未知态。
论文说明这个设计的问题是:这个保存敏感信息的寄存器,在 reset 时应该被赋值,但这里没有 reset 初始化。
2. bug 出在哪
问题代码大意是:
always @(posedge clk or negedge resetn) begin if (resetn) ... else if (unlock) locked <= d; else locked <= locked; end
这里的核心问题不是语法,而是:
- 没有在 reset 分支里给
locked明确赋初值; - 或者 reset 逻辑写得不对,导致
locked在复位时没有被初始化。
论文图 1(b) 直接写了:locked 在 reset 条件下没有被赋值,而正确修复是在 reset 时给它赋 0。
3. 为什么这是安全问题
因为安全寄存器不能处于“不知道是什么值”的状态。
如果一个安全控制寄存器在 reset 后是未知值,那就可能发生:
- 本来应该锁住,却意外解锁;
- 本来应该禁止访问,却允许访问;
- 本来应该处于安全态,却进入不安全态。
这对应论文里说的 CWE-1271:Uninitialized Value on Reset for Registers Holding Security Settings。
这类 bug 在硬件里尤其敏感,因为芯片上电之后最早期的状态往往决定了后续信任链是否可靠。
4. 正确修复做了什么
修复后的核心是给 reset 明确赋值:
if (!resetn) locked <= 0; else if (unlock) locked <= d; else locked <= locked;
论文图 1(b) 里绿色修复就是:在 reset 时把 locked 设成 0。
逻辑意义很简单:
- 复位后系统进入一个已知、安全的初始状态;
- 不把安全状态留给“随机电路上电值”。
5. 为什么这个 bug 对 LLM 有时不那么容易
你看起来会觉得这题很简单,但论文后面其实提到:这类 bug 有时不如你想象中好修,尤其当修复需要补出完整 reset 结构,并保持原本行为不变时,模型不一定稳定。
原因是它不只是改一个条件,而是可能要求模型:
- 理解时序 always block;
- 知道 reset 极性;
- 知道初值应该设什么;
- 还不能破坏后续正常写入逻辑。
也就是说,它比 Bug 1 稍微更“结构化”一些。
Bug 3:Grant Access
这是 4 个里最值得你认真吃透的一个,因为它非常典型,而且论文后面也说这是最容易修的一类 bug 之一。
1. 这个设计本来想做什么
这个模块里有一个寄存器 data_out,只有当 usr_id 正确时,才应该允许修改。
也就是:
先检查用户身份,再决定是否授权写入。
论文说得很清楚:data_out 应只在 usr_id 正确时被赋新值。
2. bug 出在哪
问题代码的关键逻辑类似这样:
data_out = grant_access ? data_in : data_out; grant_access = (usr_id == 3'b?) ? 1'b1 : 1'b0;
注意顺序:
- 先用
grant_access去决定要不要写data_out - 后面才给
grant(授予)_access赋值
也就是说,权限判断发生在写操作之后。
论文直接指出:因为这里使用了阻塞赋值,检查是在写 data_out 之后才发生,所以即使 usr_id 不对,data_out 也可能先被改掉。
3. 为什么这是安全问题
这是非常经典的:
Access control check implemented after asset is accessed
也就是 CWE-1280。
安全原则应该是:
- 先判断你有没有权限;
- 再让你碰这个资源。
而这个 bug 变成了:
- 你先碰到资源了;
- 然后我才去检查你有没有资格。
那这个检查就失去意义了。
你可以把它理解成银行金库的门禁:
- 正确做法:先刷卡,再开门;
- 错误做法:门先开一条缝让你进去,进去后再问你是谁。
4. 正确修复做了什么
正确修复的逻辑是把顺序改对:
先算授权条件:
grant_access = (usr_id == 3'b?) ? 1'b1 : 1'b0;
再基于授权结果决定是否写:
if (grant_access) data_out = data_in;
论文图 1(c) 的绿色修复就是把检查提前,让 grant_access 在访问前被计算。
从语义上说,修复后的意思是:
- 只有
usr_id正确,才允许更新data_out; - 没通过认证,就保持原值。
5. 为什么这个例子特别适合 LLM 修
论文后面专门分析了这个 bug,指出它成功率非常高。原因很典型:
grant_accessusr_id
这两个信号名本身就在“讲故事”。模型一看就能猜到:
usr_id是用户身份;grant_access是授权结果;- 合理顺序一定是先比较 id,再决定授权。
也就是说,这类 bug 成功率高,往往不是因为模型“真的理解了安全理论”,而是因为:
代码命名把设计意图暴露得很清楚。
这是你读这篇论文时一个很重要的感悟。
Bug 4:Trustzone Peripheral
1. 这个设计本来想做什么
这个设计里,SoC 中实例化了一个 peripheral(外设),系统用一个信号来表明这个外设的数据/访问属于什么安全等级。
论文把它类比成 Arm TrustZone 里的 privilege(特权)/security bit。
也就是说,父模块应该把正确的安全等级传给子模块/外设。
2. bug 出在哪
问题代码里,传给外设的安全等级信号被写成了:
.data_in_security_level(1'b0)
也就是直接接地为 0。
论文指出,这会导致实例化外设的安全等级被固定成错误值,造成权限错误。
正确做法应该是把它连到上层真正的安全等级信号,比如:
.data_in_security_level(rdata_security_level)
论文图 1(d) 绿色部分显示的就是把错误常量改成正确父级信号。
3. 为什么这是安全问题
因为安全属性在系统层级传递时,如果连接错了,就等于整个权限体系传错了。
这对应的是:
Hardware child block incorrectly connected to parent system
论文在前面列为 CWE-1276。
这个问题危险在于:
- 外设本身也许逻辑没错;
- 父模块本身也许逻辑没错;
- 但连接线错了,整个系统语义就变了。
所以它属于那种“功能上看起来还凑合,安全属性却完全变味”的 bug。
4. 正确修复做了什么
修复非常简单:
- 不要把安全等级硬连成常量 0;
- 要把它连到正确的输入安全等级信号。
也就是:
.data_in_security_level(rdata_security_level)
论文图 1(d) 明确说:修复就是把给 peripheral 的 data security level 正确连接到父信号。
5. 为什么这个例子也很适合 LLM 修
因为这类 bug 同样有很强的“命名可读性”:
data_in_security_levelrdata_security_level
这两个名字非常像“本来就该连在一起”。
所以模型容易从局部上下文里猜出正确连接关系。论文后面也把这个 bug 归为成功率很高的一类。
这 4 个 bug 放在一起,你该看到什么规律
现在不要只把它们当成 4 个孤立例子。你要开始总结规律。
规律 1:它们都是“局部修复”
这 4 个 bug 都不需要模型重写整个模块,只需要:
- 改一个条件
- 补一个 reset 赋值
- 调整两句逻辑顺序
- 改一根连线
这也是为什么 LLM 在这里能有不错表现。
规律 2:信号命名很重要
这 4 个例子几乎都依赖很直白的命名:
lock_statusdebug_unlockedgrant_accessusr_idsecurity_level
当命名把设计意图表达得清楚时,LLM 的成功率会明显更高。论文结果部分后来也明确支持这一点。
规律 3:安全 bug 往往不是“功能完全坏了”
这点特别关键。
这些 bug 不一定会让模块彻底不能运行,它们很多时候是:
- 功能基本还在;
- 但权限边界错了;
- 初始化语义错了;
- 安全属性传播错了。
所以它们比普通功能 bug 更隐蔽,也更值得研究自动修复。
如果你现在要用自己的话复述这 4 个 bug,可以这样说
你可以尝试这样记:
- Bug 1:锁逻辑被 debug 绕过了
- Bug 2:安全寄存器 reset 后没有确定初值
- Bug 3:先访问资源,后检查权限
- Bug 4:安全等级信号连错到了子模块
如果你能把这 4 句说顺,说明你已经读进去一层了。
接下来最自然的下一步
下一步最适合继续读 第 IV 节 Experimental Method,因为现在你已经知道“bug 长什么样”,接下来正好看作者是怎么把这些 bug 包装成 prompt 喂给 LLM 的,尤其是:
- prompt 里到底放了什么
- bug instruction / fix instruction 是什么
- variation a 到 e 到底差在哪
这部分是整篇论文的方法核心。
我建议下一步不要一下子贪多,我们可以按这个顺序继续:
- 先精读第 III 节 Designs and Bugs
我带你把 15 个 bug 一个个讲清楚,尤其是前 4 个 MITRE 例子,很适合入门。 - 再精读第 IV 节 Experimental Method
这是方法核心,尤其是 prompt 设计和 variation a-e。 - 最后精读第 V 节 Results
我带你看图 6、图 8、图 9,教你怎么读实验图。
好,我们继续精读 第 IV 节 Experimental Method。这一节是整篇论文最核心的“方法论”部分:作者不是直接把 bug 扔给 LLM,而是专门设计了一套“如何构造 prompt、如何生成 repair、如何验证 repair”的流程。 这套流程决定了实验结果好不好。
这部分你可以抓 4 个问题:
- prompt 里到底放了什么
- Bug Instruction / Fix Instruction(说明) 是什么
- Variation(变化) a 到 e 到底差在哪
- 作者怎么判定“修复成功”
3.29—3.29—3.29-----一、先看整体框架:作者的方法分成哪几步
论文第 7 页图 4 给了整体框架,分成三部分:
- Sources:带 bug 的设计
- Repair Generator:生成修复代码
- Evaluator:验证修复是否正确
你可以把它理解成这样一条流水线:
先拿到一个已知 bug 的 RTL 片段 → 包装成 prompt → 让 LLM 生成候选修复 → 再做功能和安全验证。
这里最关键的是中间这一步:怎么“包装”成 prompt。
二、Repair Generator:prompt 是怎么构造出来的
作者假设一件事:
bug 的位置已经知道。
也就是他们已经知道:
- bug 在哪个文件里
- bug 从第几行到第几行
- 这个 bug 属于哪个 CWE 类型
注意,这很重要。因为他们研究的是:
- 已知 bug 后,如何修
而不是:
- 自动从整个工程里先找 bug,再修。
prompt 的组成
作者说,Prompt Generator 会把下面这些内容组合起来形成 prompt:
- bug 前面的代码上下文
- 用注释包起来的 buggy code
- 用于引导修复的 instructions
论文原话里把这理解成“what the LLM sees”,也就是“模型真正看到的输入”。
所以,一个完整 prompt 不是只包含“错误代码”,而是有上下文、有标注、有指令。
三、prompt 里具体放什么
1. bug 前面的代码上下文
作者不会只给 bug 那一行,而是会给它前面的代码,让模型知道:
- 这个 bug 在哪个模块里
- 周围有哪些信号
- 这个 always block / case / module 的结构是什么
论文第 9 页写得很清楚:
- 至少给 25 行
- 最多给 50 行
- 如果 bug 上面超过 25 行,就尽量往上补到一个完整 block 的开头,比如 always block、module、case statement 等。
这说明作者很清楚:
LLM 修 RTL,不可能只靠单行;它需要一定结构上下文。
2. buggy code 会被注释起来
作者不会把 bug 当成“直接要执行的代码”给模型,而是把 bug 段落放在注释里。
作用是:
- 告诉模型:这是问题代码
- 让模型在后面生成“替换代码”
论文第 6–7 页和图 5 里演示了这一点。
这个设计很巧妙,因为它相当于在做:
“这是错误示例,请你参考并生成正确替代。”
3. instructions:作者额外加的引导语
这部分就是本文真正的亮点。作者不是只说“修一下”,而是专门写了指导文字,来帮助模型理解:
- bug 是什么性质
- 应该朝什么方向修
而这些 instruction 又分成两类:
Bug Instruction
放在 buggy code 前面。
作用是:
告诉模型这是什么 bug。
Fix Instruction
放在 buggy code 后面。
作用是:
告诉模型应该怎么修。
论文第 6 页明确说,这两种 instruction 分别负责:
- 前者描述 bug 的性质
- 后者指导 LLM 生成正确修复
四、Bug Instruction 和 Fix Instruction 到底是什么
这两个概念你一定要区分清楚。
Bug Instruction:解释“错在哪里”
它相当于对。
比如对 Bug 3,作者会写类似:
// BUG: Access Control Check Implemented After Asset is Accessed.
也就是把这个 bug 的安全含义明确告诉模型。
这不是随便写的,而是尽量参考 MITRE 的 CWE 描述。
这样做的目的,是希望 prompt 更有“泛化性”:
- 不是只会修这一个实例
- 而是让模型理解这是某一类 bug 的实例
Fix Instruction:解释“应该怎么修”
它是在 bug 代码后面的提示,告诉模型期望的修复方向。
比如对于 Bug 3,fix instruction 会类似:
// Ensure that access is granted before data is accessed.
这句话不是直接给出代码,而是用自然语言或伪代码表达设计意图。
这就是作者实验里非常关键的一点:
告诉模型修复目标,比只告诉模型存在 bug 更重要。
五、variation a 到 e 到底差在哪
这是整个方法部分最值得吃透的地方。
论文第 7 页表 III 总结了 5 种 instruction variation。
你可以把它理解成:
作者在测试:给模型多大程度的“提示帮助”,最有效。
Variation a:完全不帮
这是 baseline。
- Bug Instruction:
//BUG: - Fix Instruction:
//FIX:
没有任何 bug 类型解释,也没有修复方向。
这相当于只告诉模型:
“这里有 bug,请生成 fix。”
它的作用是做对照组,看“完全不提示”时模型能力如何。
Variation b:只描述 bug,不告诉怎么修
这一版会加入 自然语言的 bug 描述,但不额外说明修法。
比如不再只是 //BUG:,而会写:
// BUG: Access Control Check Implemented After Asset is Accessed.
但 Fix 仍然比较空泛,只是 //FIX:。
也就是说:
- 告诉模型“这是哪类错误”
- 但不告诉“具体怎么改”
Variation c:bug 描述 + 自然语言修复提示
这一版在 b 的基础上,加了 prescriptive(规范性的) 的 fix instruction。
论文说这是“自然语言帮助修复”。
例如:
// Ensure that access is granted before data is accessed. // FIX:
这里开始明确表达设计意图了。
不是只说“它错了”,而是说“你应该让访问检查先发生”。
Variation d:bug 描述 + 更像伪代码的修复提示
这一版和 c 的区别在于:
- c 更像自然语言建议
- d 更像“接近代码的设计说明”
论文把 d 描述为 descriptive instruction,语言更接近 pseudo-code(伪代码)。
比如不只是说“先检查访问”,而是更像:
assert access when id is correct, then assign data to register
这种风格更贴近工程师描述 RTL 修复意图的方式。
后面实验结果表明,d 往往是 OpenAI 模型里最好的 variation。
Variation e:再给一个 bug+fix 示例
这是最“重提示”的一版。
除了 bug 描述,还会附加一个泛化过的 bug 和修复代码示例。
也就是说模型不只是看到:
- 这个 bug 是什么
- 该怎么修
还会看到:
- “像这种 bug,别人是这么修的”
这有点像 few-shot 示例,只不过作者是把例子泛化成通用信号名和模式。
六、为什么作者要设计这 5 种 variation
因为他们研究的不只是“模型强不强”,还包括:
prompt engineering 到底值不值得做。
换句话说,作者想验证:
- 给更详细提示是不是更有效 (是的,但是不能过度)
- 自然语言提示和伪代码提示哪个更好 (很好)
- 给代码示例会不会进一步提升 (不会)
所以这 5 种 variation 其实是在做一个系统性 prompt 对比实验。
七、论文里对 variation 的更细解释
第 8 页表 IV 更细地列出了每个 bug 对应的 instruction 内容。
这个表很重要,因为它说明作者不是用一套死模板,而是会针对 bug 类型调整 instruction。
比如:
- 对某些 bug,Fix Instruction 会说
“Assign 0 to register when reset is low” - 对某些 bug,会说
“Add a default case statement” - 对某些 bug,会说
“Do not include local reset signal in reset condition”
这说明他们的 prompt 不是一句通用大白话,而是和具体 bug 类型绑定的修复意图表达。
这也解释了为什么效果会好很多:
模型不是在“瞎猜如何修 RTL”,而是在“按照设计者给出的安全意图修 RTL”。
八、图 5 是怎么展示 prompt 的
论文第 7 页图 5 非常关键,它用 Bug 3(Grant Access)举了一个完整例子。
图 5 主要做了两件事:
(a)–(b):展示 prompt 是怎么拼起来的
你能看到:
- 上面是 Bug Instruction
- 中间是被高亮注释的 buggy code
- 后面是 Fix Instruction
这就是送进 LLM 的完整输入。
(c)–(e):展示 LLM 真实生成的 repair
作者还展示了:
- 一个正确修复
- 一个通过功能测试但没通过安全测试的修复
- 一个功能和安全都失败的修复
这个图特别重要,因为它告诉你:
不是模型生成了“能跑的代码”就算成功。
必须进一步验证。
九、Evaluator:作者怎么判断修复成功
这也是你读方法部分必须抓牢的点。
作者定义:
一个 repair 只有同时通过功能验证和安全验证,才算成功。
也就是说,“编译通过”远远不够。
1. Functional Evaluation
作者用 Verilog testbench 做功能验证。
如果 testbench 失败,或者 RTL 有语法错误,这个 repair 就失败。
- 对 MITRE 小设计,他们尽量覆盖全部 intended functionality (预期功能)
- 对 OpenTitan 和 Hack@DAC 复杂设计,他们重点测和 bug 相关的局部功能。
2. Security Evaluation
安全验证根据来源不同有不同做法:
- 对 MITRE 和 OpenTitan:用安全相关 testbench
- 对 Hack@DAC:结合静态分析工具 CWEAT 做验证
这里你要特别注意作者的标准:
功能正确但安全没修好,不算成功。
这在硬件安全论文里是非常关键的标准。
十、实验参数除了 prompt 还有哪些
除了 variation,作者还改了两个主要参数:
1. Temperature
测试了 0.1 到 0.9。
目的是看输出随机性对修复效果的影响。
2. Models
用了 7 个模型:
- gpt-3.5-turbo
- gpt-4
- code-davinci-001
- code-davinci-002
- code-cushman-001
- CodeGen
- VGen
其余参数固定:
top_p = 1n = 20max_tokens = 200
也就是说,每个“模型 × 温度 × variation × bug”组合,都生成 20 个候选修复。
十一、还有两个容易忽略但很关键的技术细节
1. 给多少上下文代码
作者不是无限给上下文,而是控制在:
- 最少 25 行
- 最多 50 行
这个设计是为了平衡:
- 足够上下文
- 不超过 token 限制
2. Stop keywords
作者还手动设置了 stop keywords,防止模型无限生成后续代码。
默认 stop token 是 endmodule,但对不同 bug 又会选一些更合适的结束关键词。第 8 页表 IV 最后一列列了这些 stop keywords。
这个细节很工程化,也说明作者不是简单调 API,而是真的在认真做代码生成控制。
十二、你现在应该怎么理解这一节的核心思想
这节最核心的,不是“作者调用了 GPT-4”。
而是这三点:
1. bug repair 被转成了一个 prompt 设计问题
作者把 RTL 修复任务形式化成:
- 给上下文
- 给 bug 示例
- 给 bug 类型说明
- 给修复意图说明
- 让 LLM 生成替换代码
2. prompt 不是附属物,而是方法的一部分
在这篇论文里,prompt engineering 不是小技巧,而是实验变量本身。
variation a–e 就是在研究不同提示策略的效果。
3. LLM 只是 repair generator,不是最终裁判
真正决定 repair 成不成功的,是后面的:
- testbench
- 安全评估
- 静态分析工具
所以这篇论文的方法本质上是:
LLM 负责提出候选修复,验证器负责筛掉错的修复。
十三、如果你要用一句话总结第 IV 节
你可以这样说:
作者把“硬件安全 bug 修复”建模成一个受 prompt 设计强烈影响的代码生成任务:通过上下文代码、注释化 bug、bug instruction 和 fix instruction 组合成 prompt,让 LLM 生成 repair,再用功能和安全验证判断其是否成功。
十四、下一步最适合读什么
现在你已经知道:
- bug 长什么样
- prompt 怎么构造
- variation a–e 是什么
- success 怎么判定
下一步就该进 第 V 节 Results,因为这时你才能真正看懂:
- 为什么图 6 那么画
- 为什么 variation d 常常最好
- 为什么低温更好
- 为什么有些 bug 特别难修
我们下一步最适合直接精读 图 6、图 8、图 9。
我建议下一步不要一下子贪多,我们可以按这个顺序继续:
- 先精读第 III 节 Designs and Bugs
我带你把 15 个 bug 一个个讲清楚,尤其是前 4 个 MITRE 例子,很适合入门。 - 再精读第 IV 节 Experimental Method
这是方法核心,尤其是 prompt 设计和 variation a-e。 - 最后精读第 V 节 Results
我带你看图 6、图 8、图 9,教你怎么读实验图。
好,我们继续,直接精读 第 V 节 Results,重点看你刚提到的 图 6、图 8、图 9。这三张图其实分别回答了 3 个层次的问题:
- 图 6:不同模型、不同 prompt、不同 temperature,整体谁强谁弱
- 图 8:把结果“压缩”之后,看 prompt 细节和 temperature 的总体趋势
- 图 9:从“按模型看”切到“按 bug 看”,看哪些 bug 更容易修,哪些更难
我这次会尽量带你学会“怎么读图”,而不只是复述结论。
一、先抓住第 V 节在回答什么
第 V 节不是简单报数字,而是在回答 5 个研究问题:
- 现成 LLM 能不能修硬件安全 bug
- prompt 细节重不重要
- 哪些 bug 更适合修
- temperature 会不会影响修复效果
- 不同模型差多少
所以你看图的时候,不要只盯颜色深浅,而要一直问:
这张图是在支持哪个 RQ?
二、先读图 6:全景图
1. 图 6 画的是什么
图 6 是一组 heatmaps(热力图)。
作者把所有 LLM、所有 temperature、所有 instruction variation 的结果都铺开画出来。每个小格子的最大值是 20,因为:
- 每一种配置
- 会生成 20 个 responses
- 其中有多少个是成功 repair,就记多少分
所以你可以把图 6 里的每个小方块理解成:
某个模型在某个 bug 上,采用某种 prompt variation 和某个 temperature 时,20 次生成里成功了几次。
颜色越深,表示成功修复越多。
2. 图 6 为什么要这样画
因为作者实验变量太多:
- 15 个 bug
- 7 个模型
- 5 个 variation
- 5 个 temperature
- 每组 20 次生成
如果只报一堆表格,你很难看出规律。
所以作者用热力图,是为了让你一眼看到:
- 哪些区域整体更深
- 哪些模型稳定强
- 哪些 bug 不管怎么调都浅
- 哪些 variation / temperature 经常表现好
也就是说,图 6 的作用是:
先给你“全局地形图”,让你看到实验空间的整体分布。
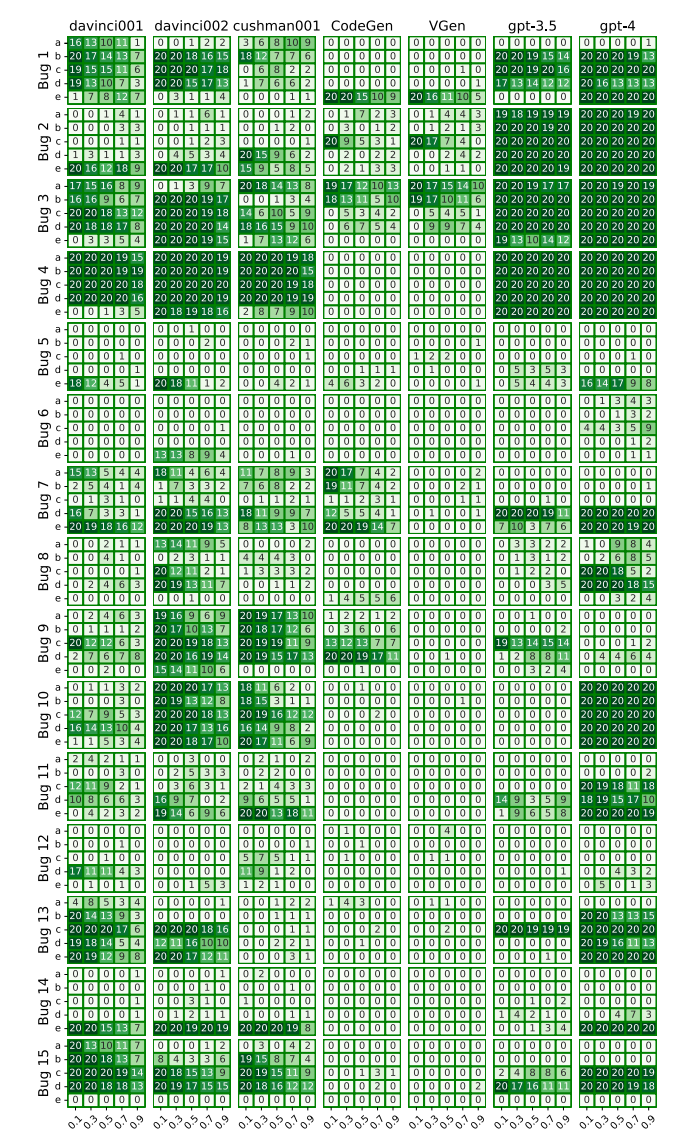
3. 读图 6 时先看什么
我建议你按这个顺序看:
先看纵向:同一个模型内部
问:
- 这个模型在哪些 bug 上整体颜色深?
- 哪些 variation 和 temperature 区域更深?
再看横向:不同模型之间
问:
- 哪个模型整体颜色更深?
- 哪些模型在大多数 bug 上更稳定?
最后看异常点
问:
- 有没有某些 bug 在几乎所有模型上都很浅?
- 有没有某些 bug 在大多数模型上都很深?
这样看,就能把图 6 和图 8、图 9 的总结对上。
4. 图 6 告诉我们的第一个大结论
作者明确总结:
- 所有 bug 至少被某个 LLM 成功修过一次
- 其中 gpt-4、code-davinci-002、code-cushman-001
对 15 个 bug 中每个 bug 都至少成功修过一次
这句话很重要,因为它说明:
不是说某些 bug 根本没法修,而是“有的配置能修,有的配置不能修”。
也就是说,配置选择本身就是结果的一部分。
5. 图 6 还暗示了什么
图 6 虽然复杂,但你会看到一个总体趋势:
- OpenAI 系列模型整体更深
- CodeGen 和 VGen 明显浅很多
- 一些 bug 的热图几乎大面积都浅,说明它们本身更难修
这就自然引向后面两张图:
- 图 8:把“variation”和“temperature”的趋势单独抽出来
- 图 9:把“bug 难易程度”单独抽出来
所以图 6 更像一张总地图,图 8 和图 9 是局部放大图。
三、RQ1:现成 LLM 能不能修硬件安全 bug
这是第一个研究问题,也是图 6 最直接支持的结论。
作者统计说:
- 总共请求了 52,500 个 repairs
- 其中 15,063 个是正确修复
- 总体成功率 28.7%
这个数字怎么理解?
很多人第一反应会觉得 28.7% 不高。
但这篇论文真正要表达的不是“单次生成几乎总对”,而是:
在一个复杂的 RTL 安全修复任务上,现成 LLM 已经能够稳定地产生相当数量的正确候选修复。
而且作者还强调:
- 关键不只是“会不会修”
- 而是“能不能挑到最合适的参数组合”
所以这里的研究范式更像:
- LLM 不是一次命中型工具
- 而是一个候选修复生成器
四、再看图 8:趋势图
图 8 比图 6 更适合“读规律”。
作者说图 8 有两张趋势图:
- 上图:比较不同 instruction variation
- 下图:比较不同 temperature
每个点的最大值是 1500,因为这里已经把多个 bug、多个温度或多个 variation 聚合起来了。
1. 图 8 上半部分:为什么 variation d 常常最好
这是你很关心的点。
作者的结论是:
- 对除 CodeGen 和 VGen 之外的大多数模型,
- 更详细的 prompt 通常更有效;
- 特别是 variation c–e 明显优于 a、b;
- 而在 OpenAI 模型中,variation d 整体最好。
2. 为什么 c–e 比 a、b 好
先回忆一下:
- a:几乎不给帮助
- b:只告诉 bug 类型
- c:告诉 bug 类型 + 自然语言修复建议
- d:告诉 bug 类型 + 更像伪代码的修复意图
- e:再额外给示例
作者指出,从 b 到 c 的提升最大。
这说明一件很关键的事:
只告诉模型“哪里错了”不够,最好还要告诉它“应该怎么改”。
也就是:
- Bug Instruction 重要
- 但 Fix Instruction 更关键
这和很多人对 prompt 的直觉不太一样。很多人会以为“告诉模型 bug 类型就够了”,但论文结果说明:
让模型知道修复意图,提升更明显。
3. 为什么 variation d 比 e 还常常更好
直觉上你可能会觉得:
- 提示越多越好
- 给例子应该最强
但作者发现,对 OpenAI 模型来说,variation e 反而不如 d。
作者解释得很有意思:
- 自然语言/伪代码式指导 往往比“给一个编码示例”更有效。
也就是说,模型更吃这一套:
“请按这种逻辑修”
而不是:
“看,这是个类似例子,你照着学”
你可以把它理解成,RTL repair 这种任务里,LLM 更需要的是明确的设计意图,而不是额外样例带来的模式干扰。
4. 如何理解 variation d 的优势
作者对 d 的表述是:
- fix instruction 更接近 pseudo-code
- 更像设计者把意图翻译给模型听
这很符合 RTL 任务的本质。
RTL 修复不是开放式生成,而是要求:
- 保持模块结构
- 改动尽量局部
- 修复语义精确
所以“伪代码式设计意图”恰好最匹配这个任务。
你可以把 variation d 想成:
它处在“太空泛”和“太具体”之间的最佳点。
- a、b:太空泛
- e:太具体,甚至可能带来示例干扰
- d:刚好把修复逻辑说清楚,但没把模型框死
五、图 8 下半部分:为什么低温更好
作者在 RQ4 里说得很明确:
- 总体上,低 temperature 更好
- 0.1 的成功修复数最高
- 大多数模型随着 temperature 增加,性能下降
1. 为什么图 8 能看出低温更好
因为下半图把不同 temperature 的累计成功修复数量画了出来。
如果你按横轴从 0.1 看向 0.9,会看到整体是往下走的趋势。
这说明:
- 越保守的输出
- 越可能给出正确 repair
2. 为什么低温更适合 repair
作者的解释很朴素但很准确:
- 低温度意味着输出变化更少
- 而较少变化的输出更可能是正确修复
从任务性质上说也很好理解:
- 写故事、写广告文案,需要多样性
- 修 RTL bug,不需要“创意”
- 需要的是:
- 语法稳定
- 条件准确
- 少引入新错误 (就是说有时候你的提示词太过详细,复杂,反而不好,会让大模型瞎想,幻觉分析)
所以这里的最优策略不是“更有想象力”,而是“更稳”。
3. 有没有例外
有。作者提到:
- gpt-4 在 temperature 0.5 时最好
- gpt-3.5-turbo 和 VGen 在 0.3 时最好
- 其余大多数模型在 0.1 最好
也就是说,低温是总体规律,但不是每个模型完全一样。
不过整体趋势仍然成立:
温度升高,通常不利于修复。
六、RQ5:哪个模型最强
虽然你这次重点问的是图 6、8、9,但模型对比也得一起看。
作者给出了各模型总体成功率:
- gpt-4:51.5%
- code-davinci-002:43.4%
- gpt-3.5-turbo:31.6%
- code-davinci-001:30.6%
- code-cushman-001:29.1%
- CodeGen:9.9%
- VGen:4.7%
1. 这说明什么
最直接的结论是:
模型能力差距非常明显。
而且 OpenAI 模型和开源 CodeGen/VGen 之间的差距很大。
2. 作者怎么解释这个差距
作者认为原因主要包括:
- 模型规模差异
- 编程任务相关微调
- instruction-following 与 code-specific tuning 的差别
一个很有意思的观察是:
code-davinci-002比gpt-3.5-turbo强很多- 虽然它们都基于 GPT-3 家族
- 但
code-davinci-002更偏代码任务优化
这说明:
在 RTL repair 这种任务里,“代码能力的专项适配”很重要。
七、再看图 9:按 bug 读难度
图 9 只统计 OpenAI LLMs 的结果,展示每个 bug 的累计正确修复数量。
每个柱子上方还有成功率标注。最大可能值是 2500。
这张图的核心问题是:
哪些 bug 天生更容易被 LLM 修?
1. 最容易修的 bug
作者明确指出:
- Bug 3
- Bug 4
是最容易修的,成功率都超过 75%。
这和我们前面读 Designs and Bugs 时的直觉完全一致。
2. 为什么 Bug 3、4 容易修
作者给出的解释非常值得记住:
Bug 3(Grant Access)
信号名 grant_access 和 usr_id 直接表明了它们的作用。
模型能推断出应当:
- 先检查
usr_id - 再决定是否授权访问
Bug 4(Trustzone Peripheral)
data_in_security_level 和 rdata_security_level 的命名,也清楚展示了应该怎样连接。
也就是说,这两个 bug 容易,不只是因为逻辑简单,更因为:
代码命名把设计意图表达得很充分。
这是这篇论文非常重要的启发之一。
3. 最难修的 bug
作者说最难修的是:
- Bug 5
- Bug 6
- Bug 12
成功率都低于 10%。
4. 为什么这些 bug 难
Bug 6
需要一个非常具体的 case statement 修复。
作者说,正确修复需要把一个 32 种可能输入映射到 4 种输出,要求非常精确。
这类修复对模型不友好,因为:
- 不是简单改一行条件
- 而是要恢复比较复杂的结构性逻辑
Bug 5
属于 glitch / race 类问题。
作者甚至提到,很多时候 gpt-4 会直接说“这里没 bug,本来就对”。
这说明这类 bug 的困难点在于:
- 它不明显
- 需要时序/电路层面的敏感理解
- 不像权限检查错误那样能从变量名直接猜出来
Bug 12
修复方式是删掉一行代码而不是替换。
这类任务对生成式模型也不太友好,因为模型天然更擅长“生成新内容”,不太擅长“精确删除而不补别的”。
八、为什么有些 bug 特别难修
这是你这次特别关心的第四个问题,我单独总结一下。
从图 9 和作者分析里,可以归纳出 4 个难点来源:
1. 设计意图不够显式
如果信号名、局部逻辑不能清楚地暴露意图,模型就不容易猜出应该怎么改。
2. 修复不是局部替换,而是结构重建
比如需要:
- 补完整 case
- 新增 always block
- 添加多层 if
- 大范围改控制流
这对 LLM 明显更难。
3. bug 属于时序/竞争/隐蔽安全语义
race condition、comparison granularity(竞态条件、比较粒度) 这类问题更“抽象”,不容易从表面代码读出来。
4. 修复动作本身不符合生成模型习惯
例如“删除一行而不替换”。
所以你可以总结成一句:
LLM 更擅长修“局部、显式、语义可读”的 bug,不擅长修“隐蔽、结构化、时序型”的 bug。
九、把图 6、图 8、图 9 串起来看
现在我们把三张图合在一起理解。
图 6 告诉你:全局分布
- 哪些模型整体更强
- 哪些 bug 大面积困难
- 哪些 variation / temperature 经常更好
图 8 告诉你:总体规律
- variation d 常常最好
- 低 temperature 更好
图 9 告诉你:bug 难度差异
- Bug 3、4 容易修
- Bug 5、6、12 难修
三张图其实是在一起证明一个中心结论:
LLM 修 RTL 安全 bug 不是“随便一跑就行”,而是强烈依赖模型能力、prompt 设计、temperature 选择,以及 bug 本身的类型。
十、如果你要复述第 V 节,可以这样说
你可以试着用下面这段话概括:
结果表明,现成 LLM 确实能够修复硬件安全 bug,但效果高度依赖模型和提示设计。图 6 从全局上展示了不同模型、prompt 和 temperature 下的修复分布;图 8 表明加入更明确的修复意图会显著提升成功率,其中 variation d 往往最好,而低 temperature 通常更适合 repair;图 9 则说明不同 bug 的可修复性差异很大,命名清晰、语义显式的 bug 更容易修,而结构复杂、时序隐蔽或需要删除/重构的 bug 更难修。
十一、你现在已经读懂了什么
到这里,你其实已经掌握了这篇论文最核心的三层:
- 研究对象:硬件安全 bug repair
- 方法核心:prompt engineering + LLM generation + verification
- 结果规律:模型、prompt、temperature、bug 类型都会显著影响修复效果
十二、下一步最适合怎么继续
现在最自然的下一步有两个方向:
- 继续读 第 VI、VII、VIII 节,看它和 CirFix 怎么比较、怎样接入 CWEAT、有哪些局限
- 或者我帮你把这整篇论文整理成一份 “论文精读笔记/汇报提纲”,方便你后面复习或做组会
我建议先继续读 第 VI 节 Comparison to Prior Work,因为它能帮你更清楚地理解这篇论文的真正创新点。
好,我们继续下一步,详细读 第 VI 节 Comparison to Prior Work,再顺着读到 第 VII 节 On Incorporating a Bug Detector。这两节很关键,因为它们回答两个更高层的问题:
- 这篇论文和已有 RTL 自动修复工作相比,到底新在哪里、强在哪里?
- 这个方法能不能接到真实设计流程里,而不只是论文里的离线实验?
一、先看第 VI 节:和已有工作怎么比
这一节主要比较对象是 CirFix。
你前面已经见过这个名字了,它是作者认为当时最相关、也最有代表性的 RTL 自动修复工作之一。
1. CirFix 是什么路线
论文前面的 related work 已经说过,CirFix 的思路是:
- 先做 bug localization
- 再用一种 迭代式随机搜索 去修改 RTL
- 同时依赖 instrumented testbench / oracle 来判断修复是否成功
也就是说,CirFix 更像传统自动修复路线:
依靠搜索、变异、测试反馈,逐步逼近正确补丁。
而这篇论文的路线是:
用 LLM 直接生成 replacement code,再用验证手段筛选。
两者的哲学很不一样。
2. 作者为什么要和 CirFix 比
因为如果不比较,论文只能说明:
- “LLM 好像能修 bug”
但还不能说明:
- “LLM repair 这条路线相比已有方法有没有优势”
所以第 VI 节的目标其实是要证明:
LLM 不是只能当演示玩具,而是在 RTL repair 上已经可以和专用工具正面比较。
二、第 VI 节实验是怎么比的
作者在 CirFix 的 benchmark 上做了比较。
这里他们用的是:
- gpt-4
- temperature 设为 0.1
- 各生成 一个 repair
- 对比两种 instruction variation:a 和 b
这点你一定要注意。
1. 为什么只用 variation a 和 b
Variation a
没有详细指导,只有最基础的 BUG/FIX。
作者说这样做是为了尽量接近 CirFix 的使用场景。
也就是:
- 不给模型太多额外“人工提示”
- 看它在比较公平的条件下,自己能修多少
Variation b
在 a 的基础上,加入了对 bug 类型的简短描述。
这里作者用的是 CirFix GitHub 里提供的 bug 描述。
这样做是为了展示:
- 在稍微加入一点人工语义引导后
- LLM 的潜力会进一步释放
2. 为什么“只生成一个 repair”很重要
作者这里不是像前面大规模实验那样每组生成 20 个候选,而是只看 first example produced by the LLM。
这意味着比较更严格:
- 不靠“多生成几个总能撞对”
- 而是比较单次输出质量
这对 LLM 是个挺苛刻的测试。
三、第 VI 节结果怎么理解
论文第 12 页表 V 给了比较结果。作者总结:
- Variation a:修复了 19 / 32
- Variation b:修复了 22 / 32
- CirFix:修复了 16 / 32
1. 这说明什么
最直接的结论是:
即使只看单次生成,gpt-4 也已经在 CirFix benchmark 上超过 CirFix。
而且这还不是最“精心调参”的版本,只是:
- 一个模型
- 一个温度
- 两种相对简单的 prompt variation
这能体现出 LLM 的基础修复能力已经很强。
2. Variation a 超过 CirFix,意味着什么
这是很有意思的一点。
因为 variation a 几乎不提供详细提示,所以它更接近“裸用模型”的情况。
在这种情况下还能 19 比 16 超过 CirFix,说明:
LLM 仅凭代码上下文和最基本的 bug 标记,就已经能在很多 RTL repair 任务上提出高质量修复。
这说明它不是完全靠 prompt engineer “硬喂答案”。
3. Variation b 进一步提升到 22,意味着什么
这进一步说明:
给模型一点点 bug 语义描述,就能明显提升修复能力。
这也是这篇论文一直在强调的核心思想:
- 模型能力重要
- 但 prompt 把设计意图表达清楚,同样关键
换句话说,LLM repair 的优势不只是“模型更大”,还有:
它能把自然语言层面的工程经验引入修复流程。
而这正是传统搜索式修复工具不擅长的地方。
四、第 VI 节你真正该看到的创新点
不要只记住“22 比 16”。更重要的是理解:
1. 这篇论文把 RTL repair 从“搜索问题”变成了“生成问题”
CirFix 更像:
- 搜索修改点
- 试补丁
- 靠 oracle 判断
而这篇论文更像:
- 用语言和上下文表达 bug
- 直接让模型提出候选修复
- 再做验证
这两种路线都能工作,但 LLM 路线在某些局部语义明确的 bug 上效率很高。
2. LLM 能自然吸收“设计者意图”
传统修复器很难直接利用一句类似:
“先做访问控制检查,再访问资源”
这种自然语言指导。
但 LLM 恰好擅长把这种设计意图转成代码。
3. LLM repair 更适合作为设计辅助工具
它不一定每次都绝对正确,但它很适合快速给出几个合理候选,让工程师选。
五、接着读第 VII 节:On Incorporating a Bug Detector
这一节非常重要,因为它在回答一个现实问题:
前面的方法都假设“我已经知道 bug 在哪里”,那真实流程里怎么办?
作者的答案是:
可以把 bug detector 接进来,形成一个从发现到修复再到复查的闭环。
1. 第 VII 节的目标是什么
作者前面做的大部分实验都假设:
- bug 的位置已知
- bug 类型已知
但现实里设计者通常先面临的问题是:
- 先发现 bug
- 再定位 bug
- 再修 bug
所以第 VII 节是在尝试把这篇论文的方法往真实 EDA/验证流程推进一步。[c16472]
2. 作者接入了什么工具
作者接入的是 CWEAT。
这是一个用于 RTL 安全弱点检测的 静态分析工具。
CWEAT 能检测一些特定的硬件 CWE 问题。作者在这里用它来做两件事:
- 检测 bug
- 修复后再验证 bug 是否消失
六、第 VII 节流程怎么跑
论文第 12 页图 10 给了整个端到端流程图。你可以把它理解成下面 4 步:
第一步:CWEAT 先检测漏洞
在 Hack@DAC 2021 SoC 上跑静态分析,找到可疑 RTL 安全弱点。
第二步:把检测到的 bug 交给 LLM 修
把 bug 的位置、上下文和对应信息送进前面那套 prompt-based repair 流程,生成候选补丁。
第三步:把补丁替换回 SoC
用 repair 替换原来的 buggy code。
第四步:再跑一次 CWEAT
如果 CWEAT 不再报同一个位置、同一种 CWE,就说明修复大概率有效。
1. 作者在这里选了哪些 bug
他们从 Hack@DAC 2021 SoC 里挑了 3 个实例,对应:
- CWE 1234
- CWE 1271
- CWE 1245
也就是论文里的 bugs 13、14、15。
这些是因为 CWEAT 对这几类问题有检测能力。
2. 这里的“成功”是怎么定义的
成功条件是:
- 修复后的代码重新放回 SoC
- 再次运行 CWEAT
- 如果不再检测到同一个 CWE、同一位置的问题
- 就认为修复有效
注意这里的验证逻辑和前面不完全一样:
- 前面 MITRE/OpenTitan 更多依赖 testbench
- 这里更多是静态检测器闭环
这说明作者在尝试让验证方式和真实工程工具对接。
七、第 VII 节的重要意义是什么
这一节的价值不只是“作者又做了个实验”,而是它展示了一个很现实的方向:
LLM repair 不需要单独存在,它可以嵌入现有硬件安全检测流程。
也就是说,将来一个设计流程可以这样工作:
- lint / static analysis / fuzzing / formal tool 先报警
- LLM 根据报警位置生成若干修复建议
- 工具再复查这些建议
- 工程师选择最终 patch
作者在文中明确说,他们设想 RTL 设计者在写 HDL 时就可以这样使用工具链。
八、这一节还隐含了一个很成熟的观点
作者并没有声称:
“LLM 一个人就能完成所有事情。”
相反,他们非常强调:
Detection 和 repair 可以是分开的,由不同工具分别负责。
这其实很成熟。因为现实里:
- 检测擅长的是 lint、formal、static analysis、fuzzing
- 修复建议擅长的是 LLM
- 验证擅长的是 testbench、formal check、静态工具复跑
也就是说,最靠谱的方案很可能不是“一个工具全包”,而是:
混合式工作流。
作者甚至明确写了:
- 可以用 commercial linting tools
- hardware fuzzers
- information flow tracking
- formal verification
- 再配合 LLM 和 CirFix 这类修复方法
这种 hybrid approach 可能检测更多 bug,也生成更多成功修复。
九、接下来读第 VIII 节:Discussion and Limitations
这一节很值得精读,因为它告诉你:
- 作者自己觉得这篇论文的边界在哪
- 哪些地方结果不能过度解读
- 将来真正落地还缺什么
1. 第一条局限:仍然需要设计者帮助定位 bug
作者承认,目前很多情况下仍然需要:
- 设计者知道 bug 的位置
- 或者至少知道 bug 的性质
这可以靠更好的定位工具来缓解,但当前还不是完全自动。
也就是说,这篇论文的主攻点其实是:
repair
不是完整的 detect + localize + repair 全自动。
2. 第二条局限:instruction variation 还比较“人工”
作者说,他们的 bug instructions 参考了 CWE 描述,但 Fix Instruction [c16473] 很大程度上来自作者经验。
这说明 prompt engineering 目前还不够标准化。
换句话说:
- 这篇论文证明 prompt 很重要
- 但还没有完全解决“怎样自动生成最优 prompt”
这是一个很大的未来研究方向。
3. 第三条局限:功能和安全验证不可能完全穷尽
作者明确承认:
- 安全验证依赖具体设计的 security objective
- 很难做到完全 exhaustive
- 对复杂 SoC 尤其如此
他们解释说:
- 对小型 CWE 示例,可以做更完整的 testbench
- 对 OpenTitan 这种复杂设计,完全仿真开销太大
甚至文中给了一个很直观的数字:
- 如果对 OpenTitan 某个 IP 做穷尽仿真,一个 bug 可能要非常久;
- 他们这里每个 bug 还要评估 3500 个候选 repair,代价太高。
所以他们采用的是“修复可能影响区域的定制测试”。
这意味着结果要理解为:
作者验证了修复在目标漏洞和相关功能上的有效性,但不是全系统形式化证明。
4. 第四条局限:stop token 和后处理会影响结果
这是很工程、但也很真实的一点。
作者说:
- stop keyword 选不好,会让生成结果变差
- 有时 LLM 已经生成了正确 repair,但又继续多写了无关代码
- 他们还写了 post-processing script 去补/删
end之类的结构关键词
这说明这项工作不是“直接调 API 就完了”,而是有不少实际工程处理。
5. 第五条局限:不是所有 bug 都适合 LLM
作者在 discussion 里再次强调:
- 对有些 bug,GPT-4 成功率超过 40% 甚至 70%
- 但像 race conditions、comparison granularity 这种更“隐蔽”的 bug,LLM 明显差很多。
这和我们前面读图 9 的结论一致。
十、读完 VI、VII、VIII 三节后,你应该形成什么理解
现在你可以把这篇论文真正放到研究图谱里看了。
1. 它不是单纯“拿 GPT 修代码”的试玩
它做了:
- benchmark
- prompt 设计
- 系统实验
- 和 CirFix 比较
- 和 CWEAT 组成闭环
- 讨论局限与未来方向
所以它是一篇相对完整的方法型论文。
2. 它的真正贡献是提出一条新路线
不是说取代所有传统方法,而是证明:
硬件安全修复可以被重新表述为“自然语言引导的代码生成 + 自动验证”问题。
3. 它最合理的落地形态是混合工作流
不是 LLM 单独做完一切,而是:
- detector 找问题
- LLM 给补丁
- verifier / static tool / designer 做筛选与确认
十一、如果你要口头汇报这几节,可以这样总结
你可以这样讲:
在和 CirFix 的对比中,作者发现 GPT-4 即使在较少提示下也能在 32 个 benchmark 中修复 19 个,而加入 bug 描述后可提升到 22 个,超过 CirFix 的 16 个,说明 LLM 在 RTL repair 上已经具备竞争力。进一步地,作者还把静态分析工具 CWEAT 接入流程,形成“检测—修复—再验证”的闭环,展示了该方法融入实际硬件安全设计流程的可能性。不过作者也承认,该方法目前仍依赖 bug 定位、prompt 设计经验和非穷尽式验证,因此更适合作为自动修复辅助工具,而不是完全替代传统验证流程。
十二、这篇论文到这里,主体已经读完了
你现在其实已经把这篇论文最重要的部分都读通了:
- 第 I–II 节:问题背景与相关工作
- 第 III 节:bugs 是什么
- 第 IV 节:prompt 和评测框架怎么做
- 第 V 节:结果规律是什么
- 第 VI–VIII 节:相比已有方法如何、怎么接入流程、局限在哪
十三、下一步最适合做什么
接下来最自然有两个方向:
方向 A:做整篇论文的总结提炼
我可以带你整理成:
- 论文主旨
- 核心贡献
- 方法框架
- 结果亮点
- 局限
- 可直接用于组会/汇报的提纲
方向 B:开始读第二篇《Rtlfixer》
这样你就能把第一篇和第二篇开始做横向比较。
我建议先做 方向 A:把第一篇整理成一份“精读总结 + 可汇报版笔记”,这样后面读第二篇时你更容易比较。
可以。下面我把这篇论文整理成一份 “精读总结 + 可汇报版笔记”,你后面做组会、文献汇报、开题相关工作总结时都可以直接拿去改。论文是 On Hardware Security Bug Code Fixes by Prompting Large Language Models。
一、论文主旨
这篇论文研究的是:
当硬件 RTL 代码中已经发现安全相关 bug 后,能否通过设计合适的 prompt,让大语言模型自动生成修复代码。
作者聚焦的是 Verilog/RTL 硬件安全漏洞修复,而不是普通软件 bug repair,也不是单纯的 RTL 代码生成。论文的核心目标是验证:LLM 是否可以作为硬件安全 bug repair 的候选补丁生成器。
二、论文要解决的核心问题
作者主要在回答 5 个问题:
- 现成 LLM 能不能修复硬件安全 bug
- prompt 的详细程度会不会显著影响修复效果
- 哪些类型的 bug 更容易被修复
- temperature 对修复成功率有没有影响
- 不同 LLM 之间性能差多少
你可以把这篇论文理解成:
它不是只做了一个 demo,而是在系统回答“LLM 做硬件安全 repair 到底行不行,什么时候行,为什么行”。
三、研究背景与问题意义
论文认为,硬件 bug 修复比软件更棘手,尤其是 安全 bug。原因是:
- 软件 bug 后期还能打补丁;
- 硬件安全 bug 一旦带进芯片流片,修复成本极高,甚至无法真正补救;
- 而硬件往往还是系统的 root of trust。
同时,作者指出:
- 软件自动修复已经较成熟;
- 但硬件 RTL 自动修复工作很少;
- 当时较有代表性的相关方法只有 CirFix。
所以这篇论文的重要性在于,它把 LLM-based repair 正式引入到了 硬件安全 RTL 修复 这个场景中。
四、论文主旨的简明概括
你在汇报时可以直接用这句话:
本文提出并评估了一套基于 prompt 的 LLM 硬件安全漏洞修复框架,通过向模型提供 RTL 上下文、bug 描述和修复指令,让 LLM 生成候选补丁,并通过功能与安全验证判断其有效性。实验表明,LLM 尤其是 GPT-4,能够有效修复多类 Verilog 硬件安全 bug。
五、核心贡献
作者在引言中总结了他们的主要贡献,可以提炼成下面 4 点。
1. 构建了一个硬件安全 bug repair 评测框架
这个框架支持:
- 把已知 bug 组织成 prompt
- 调用不同 LLM 生成 repair
- 用功能测试和安全测试评估 repair 是否成功
这是整篇论文的方法基础。
2. 构建了包含 15 个 benchmark 的硬件安全 bug 数据集
这些 bug 来自 3 类来源:
- MITRE CWE 示例
- OpenTitan
- Hack@DAC 2021 SoC
共覆盖 10 类硬件 CWE。
3. 系统分析了 prompt、模型、temperature 对 repair 的影响
作者不是只测一个模型,而是系统比较了:
- 7 个 LLM
- 5 种 prompt instruction variation
- 5 个 temperature 设置
4. 展示了 LLM repair 与检测工具集成的可能性
作者进一步把 LLM repair 和静态分析工具 CWEAT 串起来,形成“检测—修复—再验证”的端到端流程。
六、方法框架
这部分是你组会时最该讲清楚的。
1. 整体流程
论文的方法框架由三部分组成:
- Sources:带 bug 的 RTL 设计
- Repair Generator:根据 prompt 生成修复代码
- Evaluator:验证修复是否成功
即:
已知 bug → 构造 prompt → LLM 生成补丁 → 功能/安全验证。
2. 输入是什么
作者假设 bug 的以下信息已知:
- bug 所在文件
- bug 起止行号
- bug 所属 CWE 类型
所以这篇论文主要研究的是:
已知 bug 后如何修复
而不是完整自动完成“发现 + 定位 + 修复”。
3. prompt 是怎么构造的
一个 prompt 主要包含三部分:
- bug 前面的代码上下文
- 被注释起来的 buggy code
- 指导模型修复的 instructions
作者会从 bug 前面截取 25–50 行代码,尽量覆盖完整的 block 结构,如 always block、case statement 或 module 开头。
4. prompt 中最关键的两类 instruction
Bug Instruction
用于告诉模型:
这个 bug 属于什么类型,有什么问题。
这部分通常参考 MITRE CWE 描述来写。
Fix Instruction
用于告诉模型:
这个 bug 应该朝什么方向修。
这部分是作者经验驱动设计的,也是效果提升的重要来源。
5. 五种 prompt variation
论文设计了 5 种 instruction variation,从弱提示到强提示逐步增强:
- a:只有
BUG/FIX标记,没有额外说明 - b:加入 bug 类型说明
- c:加入 bug 类型说明 + 自然语言修复提示
- d:加入 bug 类型说明 + 更像伪代码的修复提示
- e:再附加一个泛化后的 bug/fix 示例
这是整篇论文最核心的实验变量之一。
6. 使用的模型和参数
作者测试了 7 个模型:
- gpt-3.5-turbo
- gpt-4
- code-davinci-001
- code-davinci-002
- code-cushman-001
- CodeGen
- VGen
temperature 测试了:
- 0.1
- 0.3
- 0.5
- 0.7
- 0.9
固定参数包括:
top_p = 1n = 20max_tokens = 200
7. 成功标准是什么
作者把“成功 repair”定义得比较严格:
只有同时通过功能验证和安全验证,才算成功。
也就是说:
- 能编译,不够;
- 功能对了,也不够;
- 必须安全问题也被修掉。
七、实验对象与 bug 类型
作者一共准备了 15 个硬件安全 bug benchmark,来源于:
- MITRE 硬件 CWE 示例
- OpenTitan
- Hack@DAC 2021 SoC
覆盖的典型 CWE 包括:
- 调试模式绕过锁
- 安全寄存器 reset 未初始化
- 访问控制检查发生在访问之后
- 子模块安全连接错误
- FSM 安全逻辑不完整
- race condition
- lock bit 修改保护失效
- 比较逻辑粒度错误
- write-once 位域限制失效 等。
八、结果亮点
这部分是做汇报时最能体现论文价值的地方。
1. LLM 确实能修硬件安全 bug
作者总共生成了 52,500 个 repair,其中 15,063 个是正确修复,整体成功率为 28.7%。
更重要的是:
- gpt-4
- code-davinci-002
- code-cushman-001
都至少对 15 个 bug 中的每一个 bug 成功修过一次。
这说明 LLM 在这个任务上不是偶然有效,而是具有稳定潜力。
2. GPT-4 最强
各模型总体成功率为:
- gpt-4:51.5%
- code-davinci-002:43.4%
- gpt-3.5-turbo:31.6%
- code-davinci-001:30.6%
- code-cushman-001:29.1%
- CodeGen:9.9%
- VGen:4.7%
结论很清楚:
大模型、代码能力更强的模型,在 RTL repair 上明显更占优。
3. prompt 细节非常重要
作者发现:
- 更详细的 prompt 通常更有效;
- variation c–e 明显优于 a、b;
- 尤其是从 b 到 c 的提升最大,说明 Fix Instruction 非常关键;
- 在 OpenAI 模型中,variation d 整体最优。
这说明:
告诉模型“应该怎么修”比只告诉它“哪里错了”更重要。
4. 低 temperature 通常更适合 repair
整体趋势是:
- temperature = 0.1 通常最好;
- 温度越高,成功率通常越低。
原因在于:
- repair 任务强调稳定、精确、保守;
- 高温更容易带来不必要的发散和错误。
5. 有些 bug 特别容易修
最容易修的是:
- Bug 3(Grant Access)
- Bug 4(Trustzone Peripheral)
成功率都超过 75%。
作者分析认为,主要原因是:
- 信号命名非常清楚;
- 设计意图容易从上下文中读出来。
6. 有些 bug 特别难修
最难修的是:
- Bug 5
- Bug 6
- Bug 12
成功率都低于 10%。
这些 bug 通常有以下特点:
- 需要复杂结构性修复
- 涉及时序/竞争条件
- 需要删除而非替换代码
- 难以从局部命名中直接推断设计意图
九、与已有工作的比较
作者把方法和 CirFix 做了对比。
在 CirFix 的 32 个 benchmark 上:
- Variation a:GPT-4 修复了 19/32
- Variation b:GPT-4 修复了 22/32
- CirFix:修复了 16/32
这说明:
即使只看单次生成,LLM repair 也已经在部分 RTL repair benchmark 上超过了传统专用工具。
这也是论文很强的一点。
十、可集成到真实流程中的潜力
作者没有把 LLM repair 仅仅作为离线实验,而是进一步接入了 CWEAT 静态分析工具,形成了:
CWEAT 检测 bug → LLM 生成 repair → CWEAT 再次验证 的闭环流程。
这说明论文的目标不只是“证明可行”,而是在探索:
LLM 是否能成为硬件安全设计流程中的一个自动修复组件。
十一、主要局限
这部分你汇报时一定要讲,不然会显得只会“吹结果”。
1. 仍然依赖已知 bug 位置
论文主体实验假设 bug 已经被定位,主要研究 repair,而不是完整自动 detection + localization + repair。
2. prompt 设计仍然有较强人工经验成分
尤其是 Fix Instruction,很大程度来自作者经验,还没有形成通用自动化方法。
3. 验证不是完全穷尽的
对复杂 SoC,作者无法对所有 repair 做完全 exhaustive 的功能与安全验证,因此主要采用定制 testbench 和局部验证。
4. 不适合所有 bug 类型
对 race condition、comparison granularity、多行复杂结构修复等问题,LLM 表现明显较弱。
5. 生成控制和后处理对结果有影响
例如 stop token 设置和 begin/end 后处理脚本,都说明这项工作还有不少工程细节依赖。
十二、论文的总体评价
如果你需要一句“总评”,可以这么说:
这篇论文是硬件安全 RTL 自动修复方向中较早、也较系统地将大语言模型引入 bug repair 的代表性工作。它的价值不只在于证明 LLM 能修 bug,更在于提出了一套“prompt 驱动 repair + 自动验证筛选”的研究框架,并通过系统实验说明了模型能力、prompt 设计和 bug 类型对 RTL repair 的关键影响。
十三、适合组会/汇报的提纲
下面这个提纲你基本可以直接拿去讲。
题目
On Hardware Security Bug Code Fixes by Prompting Large Language Models
1. 研究背景
- 硬件安全 bug 流片后代价极高
- 硬件 RTL 自动修复研究少于软件自动修复
- LLM 已显示代码生成潜力,因此值得探索其在硬件安全 repair 中的能力
2. 研究问题
- LLM 能否修复硬件安全 bug
- prompt 是否重要
- 哪些 bug 更容易修
- temperature 是否影响 repair
- 不同模型能力差异有多大
3. 方法框架
- 构造 15 个安全 bug benchmark
- 输入 bug 位置、CWE、代码上下文
- 用 prompt 组织成 repair 任务
- LLM 生成候选补丁
- 用功能和安全验证判断成功与否
4. prompt 设计
- Bug Instruction:告诉模型 bug 是什么
- Fix Instruction:告诉模型怎么修
- 五种 variation a–e 比较不同提示强度
5. 实验设置
- 7 个模型
- 5 个 temperature
- 每组生成 20 个 repair
- 评估标准:同时通过功能和安全测试
6. 主要结果
- 总体成功率 28.7%
- GPT-4 最强,成功率 51.5%
- variation d 通常最好
- 低 temperature 通常更好
- 命名清晰、局部逻辑显式的 bug 更容易修
7. 与现有工作的比较
- GPT-4 在 CirFix benchmark 上达到 19/32 和 22/32
- 超过 CirFix 的 16/32
- 说明 LLM repair 在 RTL repair 中有竞争力
8. 扩展与落地
- 接入 CWEAT,形成检测—修复—再验证闭环
- 说明该方法可嵌入真实硬件安全设计流程
9. 局限
- 假设 bug 已知
- prompt 有人工经验依赖
- 验证不穷尽
- 对复杂/隐蔽 bug 效果有限
10. 个人评价
- 论文创新点在于把 RTL 安全修复建模为 prompt-guided code repair
- 更适合作为“候选补丁生成器 + 验证筛选器”框架的一部分
- 对后续 RtlFixer、CirFix、R3A 等工作有很好的比较基线意义
十四、给你一个更短的“3 分钟汇报版”
如果你要快速讲,可以直接用这段:
这篇论文研究利用大语言模型修复 Verilog RTL 中的硬件安全漏洞。作者构建了一个包含 15 个 benchmark 的数据集,来源于 MITRE、OpenTitan 和 Hack@DAC,并设计了一套评测框架:先把 bug 上下文、bug 描述和修复指令组织成 prompt,让 LLM 生成候选补丁,再通过功能和安全验证判断修复是否成功。实验表明,LLM 尤其是 GPT-4,具备较强的硬件安全 bug repair 能力,总体上更详细的 prompt 更有效,其中 variation d 最优,低 temperature 更适合修复任务。论文还显示 GPT-4 在 CirFix benchmark 上优于 CirFix,并通过接入 CWEAT 展示了检测—修复—再验证的闭环潜力。其局限在于仍依赖 bug 定位、prompt 设计经验和非穷尽式验证。
十五、最后帮你提炼成一句最关键的话
如果你只记一句,就记这句:
这篇论文证明了:硬件安全 RTL repair 可以被有效建模为“prompt 引导的代码生成 + 自动验证筛选”问题,而不是只能依赖传统搜索式修复。
如果你愿意,我下一步可以继续帮你把这份总结整理成 “PPT 式 8 页汇报稿”,或者直接开始读第二篇 Rtlfixer 并和这篇做对比。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)