大模型微调之——PPO、DPO、GRPO 核心区别对比
·
文章目录
为什么要做强化反馈学习
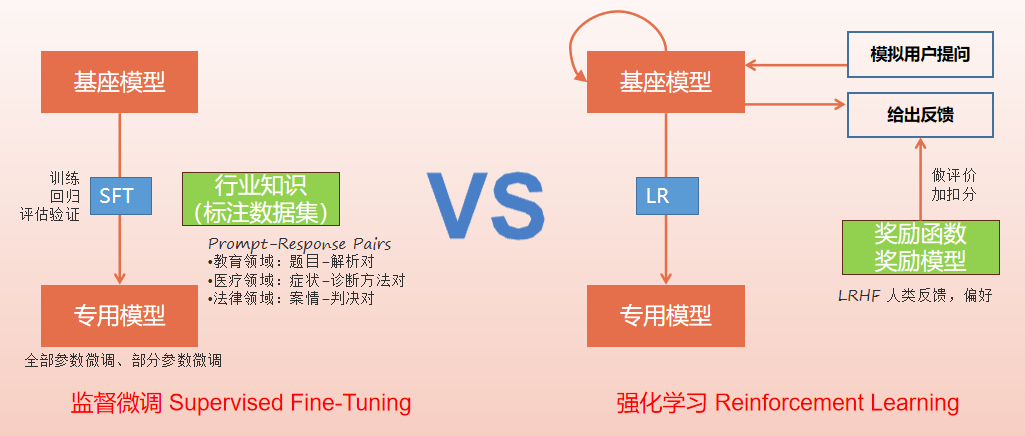
- 看看监督微调与强化学习的区别:
监督微调是要准备一组特征值X和结果值Y(也就是所谓的标注/标签)组成的数据集 来进行训练,通过调整函数的权重参数,让它的预测值与结果值Y尽可能接近,它的核心目标就是要最小化预测值与真实标签的误差;
强化学习则不需要预先准备好结果值Y,它只要提供输入让函数模拟计算,再通过与环境的交互获得反馈(奖励或惩罚),通过调整参数尽可能获取奖励,它的核心目标是要能最大化长期累积奖励期望值。
一、核心定义与原理
1. PPO (Proximal Policy Optimization,近端策略优化)
- 定位:经典 on-policy Actor-Critic 强化学习,RLHF 早期标准方案。
- 核心原理:
- 用 Critic(价值网络) 估计状态价值,计算优势函数(GAE)。
- 带 clip 裁剪 约束策略更新幅度,防止训练崩溃。
- 加 KL 散度 约束,避免偏离参考(SFT)模型。
- 组件:策略(Actor)+ 价值(Critic)+ 奖励模型(RM)+ 参考模型。
2. DPO (Direct Preference Optimization,直接偏好优化)
- 定位:离线偏好学习,跳过奖励模型,直接用偏好对优化。
- 核心原理:
- 基于 Bradley-Terry 模型,将偏好比较转化为对数概率优化。
- 目标:提升 Chosen(优选) 概率、压低 Rejected(劣选) 概率。
- 无 Critic、无显式奖励,单模型训练。
- 数据:
(Prompt + Chosen + Rejected)偏好三元组。
3. GRPO (Group Relative Policy Optimization,群体策略优化)
- 定位:on-policy 组级优化,PPO 简化版(无 Critic)。
- 核心原理:
- 单 Prompt 生成 N 个候选(组),用规则/验证器打分。
- 以 组内均值为基线、组内标准差归一化,计算相对优势。
- 保留 PPO 的 clip + KL 约束,但 不需要价值网络。
- 数据:在线采样组(每组 4–16 条)+ 可自动验证的奖励。
二、关键维度对比表
| 维度 | PPO | DPO | GRPO |
|---|---|---|---|
| 训练范式 | on-policy(在线采样) | off-policy(离线偏好数据) | on-policy(在线组采样) |
| 模型依赖 | Actor + Critic + RM + 参考 | 仅 Actor + 参考 | Actor + RM/规则 + 参考(无 Critic) |
| 优势估计 | Critic 网络(GAE) | 无(直接偏好对比) | 组内均值/标准差(无 Critic) |
| 数据类型 | 单样本绝对奖励打分 | 偏好对(Chosen/Rejected) | 组内多候选 + 可验证奖励 |
| 训练效率 | 低(多模型、计算密集) | 高(单模型、速度快 2–3 倍) | 中高(无 Critic、组可控) |
| 显存占用 | 高(多模型权重) | 低(单模型) | 中(少 Critic 权重) |
| 稳定性 | 高(多重约束) | 中(依赖数据质量、易过拟合) | 高(组归一化降方差) |
| 适用场景 | 复杂任务(多轮对话、长文本) | 轻量对齐、对话、内容生成 | 数学推理、代码、可自动验证任务 |
| 优点 | 理论成熟、鲁棒性强 | 流程极简、资源省、易复现 | 效率/稳定平衡、自动奖励友好 |
| 缺点 | 复杂、样本效率低、成本高 | 复杂偏好弱、难细粒度优化 | 推理开销增 20–30%、组大小敏感 |
三、一句话总结
- PPO:最稳但最贵,全流程强化学习。
- DPO:最便宜好用,直接学偏好、不用奖励模型。
- GRPO:PPO 简化版,组内对比、无 Critic、适合自动打分任务。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)