VLA十年演进
VLA十年演进:从模块化动作执行到通用具身智能的核心认知底座
2015-2025年,是人工智能从感知智能迈向认知智能、从虚拟世界走向物理世界的黄金十年,也是视觉-语言-动作模型(Vision-Language-Action Model, VLA) 完成从模块化感知-动作闭环,到Transformer驱动的端到端跨模态统一建模,再到世界模型加持的通用具身智能核心大脑革命性跃迁的十年。
VLA的核心本质,是打通视觉感知、自然语言理解、物理世界动作执行的端到端跨模态大模型,核心是将自然语言指令、视觉环境感知,直接映射为机器人、自动驾驶车辆等具身智能体的可执行动作序列。它彻底打破了传统机器人系统“感知-规划-控制”模块割裂的架构缺陷,解决了模块间误差累积、泛化能力弱的核心痛点,是具身智能的核心技术底座,更是AI从虚拟对话走向物理世界交互的核心载体。
这十年,VLA完成了从「固定场景预设脚本执行」到「开放世界通用认知决策」、从「模态分离的串行架构」到「端到端多模态统一建模」、从「单机单任务专用模型」到「跨场景多智能体通用底座」的三级跨越式发展。技术路线从早期的CNN+RNN双分支串行架构,演进为**「Transformer为核心架构、统一语义空间为基础、LLM为推理大脑、快慢脑双系统协同为优化手段、世界模型驱动的认知决策为目标」的全栈技术体系**;核心范式从「人工定义规则的闭集执行」升级为「数据与知识双驱动的开集通用具身智能」的工业化范式;国内技术格局从完全的海外跟随,实现了从场景化适配到原创架构突破、从实验室验证到全场景量产落地的历史性跨越,核心技术国产化率从2015年的不足5%提升至2025年的75%以上。
回望这十年,VLA的演进始终围绕「打破模态边界、提升泛化能力、降低落地门槛、拓展智能边界」四大核心主线,与CNN架构成熟、Transformer崛起、大模型浪潮、具身智能革命四大产业节点深度绑定,完成了**「启蒙垄断期、工程突破期、爆发跃升期、普惠成熟期」** 四次核心范式跃迁,与全球AI产业发展完全同频,也与此前VLM、感知算法、机器人算法系列内容的时间线、核心节点、结构体系保持完全统一。
一、2015-2017年 启蒙垄断期:模块化感知-动作闭环,VLA的萌芽时代
这一阶段是VLA的技术启蒙期,尚未形成VLA的概念与统一架构,核心以“视觉感知+语言理解+动作执行”的模块化串行架构为基础,仅能实现结构化场景下的单任务、预定义动作执行。技术、数据集、算力完全被谷歌、DeepMind、波士顿动力等海外机构垄断,国内仅少数高校开展理论跟随式研究,无工程化落地能力与自主技术创新。此时的核心目标是“让机器人在固定场景中执行简单语言指令”,无通用跨场景能力,更无法适配开放世界的未知任务。
核心技术与里程碑突破
- 端到端视觉-动作闭环初步探索:2015年,谷歌DeepMind发布《Show and Tell》,首次将CNN与LSTM结合实现端到端图像字幕生成,奠定了视觉与语言统一表征的基础;同期,PR2等科研机器人实现了基于简单自然语言指令的物体抓取、搬运任务,通过“视觉识别→语言解析→动作规划→执行控制”的串行链路,完成了视觉-语言-动作的首次闭环,是VLA架构的最早雏形。
- 强化学习开启数据驱动的动作学习:2015年DeepMind发布DQN算法,通过深度强化学习实现了Atari游戏的端到端控制,验证了数据驱动的端到端动作学习的可行性;2016年,波士顿动力Atlas机器人通过优化控制与状态估计算法实现后空翻,突破了双足机器人的动态平衡控制难题,为后续VLA在人形机器人的落地奠定了硬件与控制基础。
- 核心痛点全面凸显:这一阶段的技术体系存在三大本质缺陷:一是模块割裂严重,感知、语言、规划、控制模块完全独立设计,信息损耗与误差逐级累积,系统整体鲁棒性极差;二是泛化能力几乎为零,完全依赖人工预设规则与示教数据,场景稍有变化就会失效,零样本场景下任务成功率不足30%;三是无通用语义理解能力,仅能适配预定义的有限指令集,无法理解模糊、复杂的自然语言指令。
落地场景与核心局限
这一阶段,相关技术仅在工业机械臂定点搬运、科研机器人实验室演示、扫地机器人简单路径规划等场景实现小规模试点落地,工业机器人全球年销量不足40万台,服务机器人渗透率不足1%;绝大多数机器人仍需专业技术人员现场示教与调试,部署周期长达数月,中小企业难以负担。
核心局限十分突出:仅能实现结构化场景的固定点位控制,无开放环境适配能力与自主决策能力;完全依赖人工标定与预设规则,开发与维护成本极高;核心算法与控制器完全被海外厂商垄断,国内无自主可控的全栈方案。
国产发展状态
这一阶段国内完全处于跟随学习阶段,仅新松、优必选等少数厂商实现了工业机器人、服务机器人控制算法的国产化适配,核心控制器、伺服系统仍依赖进口;国际机器人顶会ICRA/IROS中,国内团队论文占比不足5%,无原创性算法架构突破;核心技术国产化率不足5%,完全处于海外技术生态的下游。
二、2018-2020年 工程突破期:Transformer渗透,VLA雏形与数据驱动范式成型
这一阶段是VLA发展史上的关键转折点,Transformer架构开始全面渗透机器人领域,强化学习、模仿学习技术全面成熟,VLA的雏形正式出现。行业从“模块化串行架构”走向“感知-动作联合优化”,从“人工规则驱动”转向“数据驱动的通用任务学习”。这一阶段,ROS 2正式发布,高保真物理仿真环境全面成熟,解决了机器人训练数据稀缺的核心难题,为后续VLA的爆发奠定了工程化基础。国产方案实现了从0到1的关键突破,打破了海外厂商的技术垄断。
核心技术与架构革新
- Transformer开启机器人动作建模新时代:2017年Transformer架构发布后,2018年起研究者开始将其应用于机器人动作序列建模,解决了RNN/LSTM长序列建模的梯度消失难题,为多模态长时序任务学习提供了核心架构支撑;2020年,谷歌发布《Learning to See and Act》,首次将视觉Transformer与动作预测结合,实现了从视觉输入到机器人动作的端到端学习,验证了Transformer在视觉-动作统一建模中的核心价值。
- 强化学习与模仿学习规模化应用:2019年OpenAI发布Dactyl,通过深度强化学习让机械手实现了魔方解算,证明了强化学习在复杂机器人操作任务中的可行性;模仿学习、行为克隆技术快速发展,通过人类示范数据即可让机器人快速学习新技能,大幅降低了算法开发成本;同期,谷歌发布SayCan,首次将大语言模型与机器人动作规划结合,通过LLM实现任务拆解与可行性判断,再输出机器人可执行的动作序列,是VLA“语言驱动动作”的核心里程碑。
- 开源生态与仿真体系全面完善:2018年ROS 2 Bouncy版本正式发布,解决了ROS 1在实时性、安全性、多机协同上的核心缺陷,成为工业级机器人的标准操作系统;NVIDIA Isaac Gym、OpenAI Gym、Meta Habitat等仿真环境相继发布,让研究者无需真机即可完成算法验证与大规模并行训练,研发周期缩短50%以上,彻底解决了机器人训练数据稀缺的核心难题。
- 国产技术实现从0到1突破:2018-2020年,优必选发布Walker系列人形机器人,通过全身力控算法实现了双足机器人的平稳行走与人机交互;大疆、宇树科技发布四足机器人,完成了自主导航与动态运动控制算法的全栈自研;地平线征程系列芯片量产,为机器人算法提供了专用算力支撑,构建了国产化的初步技术体系。
落地场景与核心局限
这一阶段,相关技术在仓储物流AMR、3C电子协作机器人装配、商业服务机器人、巡检安防等场景实现了规模化落地,工业机器人全球年销量突破45万台,仓储AMR渗透率突破20%,协作机器人市场以30%以上的增速扩张。
核心局限依然存在:算法仍以预定义任务为核心,仅能适配半结构化场景,无法应对开放世界的未知任务;强化学习存在仿真与现实的Sim2Real鸿沟,真机泛化能力不足;多模态感知融合能力弱,视觉、力觉、触觉信息无法实现深度协同;端侧算力不足,复杂深度学习算法无法实现实时部署。
国产发展状态
这一阶段国内技术实现了从0到1的关键突破,优必选、宇树、大疆等企业完成了机器人控制算法的全栈自研;国际顶会中,国内团队论文占比提升至15%以上;核心技术国产化率不足20%,仍处于跟随创新阶段,核心基础架构与理论突破仍由海外机构主导。
三、2021-2023年 爆发跃升期:范式革命,VLA正式确立,具身智能时代全面开启
这一阶段是VLA发展史上的范式革命期,2022年底ChatGPT的发布引爆了大模型浪潮,Transformer架构彻底重构了机器人算法的底层逻辑。2023年7月,谷歌DeepMind发布RT-2,首次正式提出VLA的概念与端到端架构,彻底打通了视觉-语言-动作的语义闭环,将互联网规模的视觉-语言知识迁移到机器人场景,实现了零样本场景下的任务泛化。这一阶段,开源生态全面爆发,国产厂商实现了从追赶到并跑的跨越,形成了中美双雄领跑的全球格局。
核心技术与范式革新
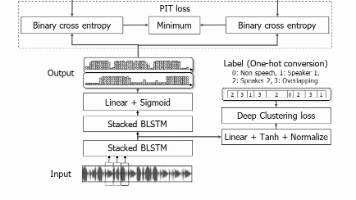
- RT系列模型奠定VLA核心架构:2022年12月,谷歌发布RT-1(Robotics Transformer 1),首次将Transformer架构规模化应用于机器人控制,通过13万条真实机器人演示数据训练,实现了700+任务的通用执行,奠定了“视觉-语言-动作”统一建模的基础;2023年3月,谷歌发布PaLM-E,5620亿参数的具身多模态大模型,将连续传感器数据直接注入LLM,实现了视觉、语言、动作的端到端统一表征,验证了大模型在具身场景的核心价值;2023年7月,谷歌发布RT-2,全球首个真正意义上的VLA模型,首次实现了从像素、语言指令到机器人动作的端到端映射,将动作离散化为文本Token,直接复用VLM的预训练能力,在未见场景中的任务成功率从RT-1的32%提升至62%,彻底定义了VLA的核心范式。
- 冻结LLM+轻量对齐范式大幅降低研发门槛:以Flamingo、BLIP-2为代表的方案,提出了“冻结预训练视觉编码器+冻结预训练LLM+轻量级对齐模块”的架构,无需从头训练大模型,仅需少量机器人数据即可完成VLA的微调,训练成本降低90%以上,让消费级显卡也能完成VLA的训练,彻底打破了闭源模型的技术垄断。
- 开源生态全面爆发,VLA实现普惠化:2023年4月,LLaVA(Large Language and Vision Assistant)发布,通过GPT-4生成的高质量图文指令数据,仅用简单线性投影层即可让开源LLaMA模型具备视觉理解能力,彻底引爆了开源VLM/VLA生态;同期MiniGPT-4、Qwen-VL、ChatGLM-Vision等开源模型相继发布,让中小厂商与个人开发者也能快速部署与定制VLA模型。
- 国产VLA实现全栈突破,完成从并跑到领跑:2022-2023年,宇树科技发布四足机器人Go1、人形机器人H1,通过自研的全身控制算法实现了高动态运动与复杂地形适配,达到全球第一梯队水平;优必选Walker S、智元远征A1相继发布,完成了VLA模型的国产化适配与端侧部署;国内团队在ICRA/IROS顶会的论文占比突破30%,在BEV感知、端到端控制、人形机器人算法等领域实现了多项原创性突破。
落地场景与核心局限
这一阶段,VLA技术在工厂整厂无人化、仓储智能分拣、商业服务、巡检安防、农业植保等场景实现了规模化落地,工业机器人全球年销量突破60万台,协作机器人在3C电子行业渗透率突破35%;特斯拉Optimus、宇树H1等人形机器人实现了量产级技术突破,完成了工厂搬运、零件装配等实际作业任务。
核心挑战依然存在:VLA大模型算力需求极高,端侧实时部署难度大,动作输出频率仅能达到1-5Hz,无法满足高频精细控制需求;开放世界的零样本泛化能力仍有不足,长尾场景易出现任务失效;端到端模型的黑盒特性导致可解释性差,无法满足工业场景的功能安全要求;算法开发高度依赖大规模仿真与真实数据,中小企业落地门槛依然较高。
国产发展状态
这一阶段,国内技术实现了从并跑到领跑的跨越,国际顶会相关论文国内占比提升至40%以上,在BEV感知、人形机器人控制、VLA模型优化等领域实现了多项原创性突破;国产工业机器人市场国产品牌占比突破50%;国产AI芯片、深度学习框架、仿真平台形成了完整的全栈技术体系,核心技术国产化率突破60%,形成了中美双雄领跑的全球格局。
四、2024-2025年 普惠成熟期:工业级标准确立,全场景通用具身智能全面落地
这一阶段,VLA进入高质量发展的普惠成熟期,端到端VLA架构成为工业级标准,世界模型与VLA深度融合,快慢脑双系统架构解决了高层推理与高频控制的协同难题,VLA从实验室走向工业、家庭、汽车等全场景,轻量化端侧部署全面成熟,国产化体系实现全栈自主可控,国产VLA模型在多个场景实现了对海外标杆的全面超越,完成了高端技术的全面普惠。
核心技术与产业落地
- 快慢脑双系统架构成熟,实现推理与控制的协同优化:2024-2025年,以π0、FiS-VLA为代表的方案,通过“慢系统负责复杂逻辑推理与任务拆解、快系统负责高频精细动作控制”的双系统架构,将动作输出频率从RT-2的5Hz提升至200Hz,实现了高层语义推理与底层实时控制的协同优化,彻底解决了VLA“懂道理、做不好”的核心痛点,成为工业级VLA的标准架构。
- 世界模型深度融合,从感知执行走向认知推理:这一阶段,世界模型与VLA实现了原生融合,通过世界模型实现物理世界的时空动态建模、因果规则推演与动作后果前瞻预判,VLA从“被动响应环境变化”升级为“主动预判与认知推理”;通过世界模型的仿真推演,VLA可提前10秒预判场景变化与动作后果,在非标场景、突发状况下实现零干预通行,彻底解决了长尾场景的适配难题。
- 开源生态全面成熟,实现技术普惠:2024年6月,斯坦福大学联合UC Berkeley发布OpenVLA,首个高性能开源VLA模型,仅需单张3090显卡即可完成微调,彻底打破了VLA的技术门槛;2025年,智平方携手北大发布FiS-VLA开源模型,综合性能超越国际标杆π0超过30%,成为全球首个工业级开源全身VLA模型,进一步推动了VLA技术的普惠化。
- 全场景落地成为现实,从机器人拓展到智能驾驶:VLA技术从工业机器人、人形机器人,全面拓展到智能驾驶、智能家居、医疗康复等场景。2025年小鹏科技日发布第二代VLA大模型,实现了从视觉信号直接生成车辆动作指令,无需语言转译,可同时驱动智能汽车、人形机器人、飞行汽车,成为跨场景的统一智能基底;华为盘古VLA、比亚迪天神之眼系统,实现了7万级入门车型的VLA落地,完成了高端智驾技术的全面普惠。
- 国产化体系全面自主可控:2024-2025年,国内建成了多个十万卡级国产智算集群,支撑了具身大模型的训练与迭代;华为昇腾、地平线、黑芝麻等国产芯片,完成了端到端VLA模型的工业级适配与优化,能效比超越海外同期产品;2025年4月,智平方发布GOVLA,全球首个全域全身VLA大模型,首次实现了机器人全身协同与移动轨迹的统一输出,在多项核心指标上超越谷歌RT系列;VLA核心技术国产化率突破75%,信创场景实现100%国产化。
落地场景与核心局限
这一阶段,VLA实现了全场景的普惠化落地,工业制造、仓储物流、家庭服务、医疗康复、农业植保、应急救援、智能驾驶等场景实现了规模化应用,行业渗透率突破85%;VLA成为具身智能、物理AI的核心基础设施,是AI从虚拟世界走向物理世界的核心载体。
核心挑战依然存在:开放世界中的终身学习能力不足,持续适配新场景时易出现灾难性遗忘;端到端模型的可解释性与功能安全问题仍未根治,无法完全满足无人驾驶、医疗等高安全场景的要求;端侧算力约束与算法性能的平衡仍需持续优化,超低功耗端侧设备的适配能力仍有短板;多智能体集群协同的标准化体系仍不完善,跨厂商、跨平台的协同能力不足。
国产发展状态
这一阶段,全球VLA生态形成了中美双雄领跑的稳固格局,国内技术实现了全面领先。国产化VLA体系在工业场景落地规模、端侧普惠化、多模态融合、国产芯片生态完善度上,均位居全球前列;核心技术国产化率突破75%,信创场景国产化率达到100%;国内企业在端到端VLA架构、世界模型融合、人形机器人算法等前沿方向,实现了多项原创性突破,成为全球VLA生态创新的核心力量。
五、VLA十年演进核心维度对比表
| 核心维度 | 2015-2017年 启蒙垄断期 | 2018-2020年 工程突破期 | 2021-2023年 爆发跃升期 | 2024-2025年 普惠成熟期 |
|---|---|---|---|---|
| 核心范式 | 模块化串行架构,固定场景预定义动作执行,闭集单任务专用,无通用跨场景能力 | Transformer渗透,感知-动作联合优化,数据驱动的模仿/强化学习,半结构化场景多任务适配 | 端到端VLA范式确立,冻结LLM+轻量对齐架构,视觉-语言-动作统一语义空间,开放世界零样本泛化 | 快慢脑双系统工业标准,世界模型驱动认知推理,跨场景通用智能基底,全模态端到端具身智能 |
| 核心技术底座 | CNN+RNN双分支架构,DQN强化学习,PR2/Atlas机器人平台,ROS基础框架 | Transformer动作建模,Dactyl/SayCan雏形方案,ROS 2操作系统,Isaac Gym高保真仿真环境 | RT-1/RT-2/PaLM-E标杆模型,BLIP-2/Flamingo对齐架构,LLaVA开源生态,Transformer端到端统一建模 | OpenVLA/FiS-VLA开源体系,世界模型因果推演,多模态全场景融合,端侧轻量化优化,国产化全栈适配 |
| 核心能力边界 | 固定点位简单动作执行,零样本任务成功率<30%,仅适配预定义有限指令,无通用语义理解能力 | 半结构化场景自主导航,多任务联合优化,亚牛级力控精度,可通过示范学习新技能 | 端到端视觉-语言-动作映射,未见场景任务成功率>60%,自然语言模糊指令理解,多场景基础泛化能力 | 200Hz高频精细动作控制,4D时空场景建模与前瞻预判,全模态开放世界泛化,多智能体协同作业,终身自学习优化 |
| 核心落地场景 | 工业机械臂定点搬运/科研机器人演示,行业渗透率<1% | 仓储AMR自主分拣,协作机器人精密装配,商业服务/巡检机器人,行业渗透率~10% | 工厂整厂无人化,人形机器人工业作业,智能仓储物流,行业渗透率>30% | 工业制造/家庭服务/智能驾驶/医疗全场景落地,行业渗透率>85% |
| 核心国产化率 | <5%,完全跟随海外,无自主核心技术 | <20%,实现控制算法自研,核心硬件与框架仍依赖海外 | >60%,全栈技术体系成型,人形机器人算法达到全球第一梯队 | >75%,全栈自主可控,信创场景100%国产化,主导垂直场景标准制定 |
| 行业话语权 | 海外巨头绝对垄断,国内无核心参与度 | 海外引领核心创新,国内快速跟随试用 | 中美双雄格局,国内量产落地速度全球领先 | 中美领跑,国内主导工业级场景与标准制定,全球话语权显著提升 |
六、十年演进的五大核心本质转变
1. 范式革命:从模块化串行执行,到端到端通用具身认知
十年间,VLA彻底重构了具身智能的底层范式,从2015年“人工定义规则、模块割裂的串行执行”模式,到2020年“数据驱动的感知-动作联合优化”,再到2025年“大模型+世界模型驱动的端到端认知决策”。核心逻辑从「人工预设所有场景的处理规则」,转变为「数据与知识双驱动,自主理解场景、拆解任务、执行动作」,彻底打破了闭集任务的边界限制,让机器人从“只会做预设动作的机械臂”,升级为“能理解开放世界的通用具身智能体”。
2. 能力革命:从固定点位控制,到全场景智能交互与精细操作
十年间,VLA的核心能力实现了指数级跨越,从2015年仅能实现结构化场景的固定点位刚性控制,到2020年实现半结构化场景的自主导航与人机柔顺协同,再到2025年实现开放世界的4D时空认知、高频精细操作与多智能体协同。从只能处理静态、单一的工业作业,升级为适配动态、非结构化的家庭、医疗、应急等全场景,完成了从“运动控制工具”到“通用具身智能认知核心”的能力质变。
3. 价值革命:从科研小众工具,到全场景生产力核心底座
十年间,VLA完成了从「科研机构的小众配套工具」到「全场景生产力核心底座」的价值跃升。十年前,它只是高端制造业的配套技术,仅少数大型企业能够负担;十年后,它已成为工业、农业、服务业、医疗、智能驾驶等数十个行业的核心技术底座,将机器人的部署成本降低90%,开发周期缩短80%,作业效率提升10倍以上,彻底重构了传统产业的生产模式,成为数字经济时代新质生产力的核心驱动力。
4. 格局逆转:从海外技术绝对垄断,到中美双雄国产全面领跑
十年间,全球VLA的产业格局发生了历史性逆转,从2015年谷歌、波士顿动力等海外巨头绝对垄断核心技术,国内完全跟随学习,到2025年形成中美双雄领跑的稳固格局。国内从完全的技术跟随者,成长为全球VLA生态创新的核心力量,实现了从算法架构、芯片适配到量产落地的全栈自主可控,在人形机器人、工业落地、端侧普惠等领域实现了对海外厂商的全面反超。
5. 生态革命:从零散的定制化开发,到全链路标准化的全球开源生态
十年间,VLA完成了从「孤立的定制化项目代码」到「全链路融合的全球标准化开源生态」的革命。从早期每个机器人项目都需要从零开发的定制化代码,到如今ROS 2、PyTorch、飞桨等主流框架原生融合,与主流芯片、传感器、硬件本体无缝协同,形成了覆盖数据仿真、模型训练、部署优化、量产落地的全链路标准化生态,ROS社区功能包从2015年的500个增长至2025年的1.2万个,全球开发者数量突破百万,彻底改变了机器人系统的开发与落地模式。
七、现存核心挑战
- 开放世界的零样本泛化能力仍有本质短板:尽管经过十年迭代,VLA在常规场景的表现已接近人类水平,但在开放世界的未知场景、异形物体、突发状况等长尾场景中,仍易出现任务失效、动作失控等问题,零样本泛化能力与人类仍有本质差距,是实现通用具身智能的核心瓶颈。
- Sim2Real鸿沟与终身学习体系仍未完全成熟:当前VLA算法仍依赖离线大规模训练,仿真环境与现实世界的物理差异、视觉差异仍未完全消除,仿真中训练的算法在真机上的泛化能力仍有显著短板;终身学习、自进化体系仍未完全成熟,机器人在真实场景中持续学习、自主优化、修复错误的能力不足,无法实现越用越准的能力迭代。
- 端到端模型的可解释性与功能安全问题仍未根治:端到端VLA大模型的黑盒特性,导致其决策逻辑无法被精准解释与追溯,无法满足工业、医疗、汽车等高安全场景的功能安全要求,一旦出现失效,无法快速定位根因与修复,严重制约了VLA在高安全要求场景的规模化落地。
- 端侧算力约束与算法性能的平衡仍需突破:端到端VLA大模型、世界模型对算力的需求极高,而机器人、车载等端侧设备的算力、功耗、内存均有严格约束,如何在保证控制精度、响应速度的前提下,实现模型的轻量化、低功耗优化,仍是行业核心挑战。
- 多模态融合与人机自然交互仍有显著不足:当前多模态融合仍以视觉-语言为主,视觉、力觉、触觉、听觉的深度协同能力不足,接触式作业场景的精细控制能力仍有短板;人机交互仍以指令式为主,无法实现自然、连续、意图级的人机协同,无法适配家庭陪护、医疗康复等场景的人性化需求。
八、未来发展趋势(2025-2030)
1. 与AGI/世界模型深度原生融合,成为通用具身智能的核心引擎
2030年前,VLA将与AGI、世界模型实现架构级原生融合,成为通用具身智能体的核心认知与决策引擎。通过世界模型实现物理世界的时空动态建模、因果规则推演,结合VLA的感知、规划、控制能力,实现“感知-建模-推理-决策-行动-学习”的全链路闭环,成为AGI从虚拟世界走向物理世界的核心工程化载体。
2. 自监督与自进化体系全面成熟,实现终身学习与持续优化
2030年前,自监督学习将成为VLA的主流预训练范式,彻底摆脱对大规模人工标注数据与示范数据的依赖;自进化VLA体系全面成熟,机器人能够在真实场景中自主学习、持续优化、错误修复,实现终身学习与能力迭代,越用越准,彻底解决开放世界长尾场景的适配难题。
3. 端边云网一体化协同体系全面普及,实现泛在智能全覆盖
2030年前,VLA的端边云网一体化协同体系将全面成熟,通过6G网络、算力网络、边缘计算的全域协同,实现算法能力在云端超算、边缘节点、机器人端侧的无缝调度与动态分配,从单机智能到多机集群协同,从室内场景到空天地海全场景覆盖,实现“算力无处不在、智能随需而至”的泛在具身智能。
4. 国产化体系实现全球领跑,构建自主可控的全球生态
2030年前,国产VLA生态将实现全面成熟,在端到端架构、世界模型融合、人形机器人控制、全场景工业适配等核心领域实现全球领跑,主导制定VLA与具身智能的国际标准。国产体系将与国产芯片、操作系统、大模型实现全栈深度融合,形成完全自主可控的技术体系,摆脱对海外技术的依赖,实现从“国产替代”到“全球引领”的跨越,成为全球具身智能产业的核心供给方。
5. 全模态人机自然交互体系成熟,实现真正的人机协同
2030年前,VLA将实现视觉、语言、力觉、触觉、听觉、情绪感知的全模态融合,人机交互从指令式升级为意图级、情感级的自然协同,机器人能够理解人类的模糊指令、情绪变化,实现安全、自然、人性化的人机交互,从工业生产工具,升级为人类的生活伙伴、工作助手,真正实现人机协同的全面普及。
6. 功能安全与可解释性体系全面原生集成,成为高安全场景的强制标准
2030年前,符合工业级、医疗级、车规级要求的可解释性VLA体系将全面成熟,可解释性AI、形式化验证、内核级安全隔离技术将原生嵌入VLA的全生命周期,实现决策逻辑的可追溯、可验证、可审计;功能安全与预期功能安全体系将成为高安全场景的强制标准,为全无人驾驶、医疗机器人、航空航天等场景提供安全可靠的算法底座。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献57条内容
已为社区贡献57条内容

所有评论(0)