【说话人日志】从聚类到端到端:EEND 2019 是怎么重新定义说话人日志的
论文:End-to-End Neural Speaker Diarization with Permutation-Free Objectives
简称:EEND
作者:Yusuke Fujita, Naoyuki Kanda, Shota Horiguchi, Kenji Nagamatsu, Shinji Watanabe
时间:2019
会议:INTERSPEECH 2019
任务:Speaker Diarization,回答“谁在什么时候说话”
一、前言
EEND 给出了 speaker diarization (SD)领域的 end-to-end 答案。
在它之前,主流 diarization 系统大多还是:
SADspeaker embeddingclustering
也就是先切语音、再抽说话人表示、最后聚类。
而这篇论文不再把 diarization 看成“分段后做聚类”的问题,而是直接把它改写成“逐帧多标签分类”的问题。
这改变了整个任务的建模方式。
一句话概括这篇论文的核心思想:
给定整段语音,模型直接输出每一帧上每个说话人的活动状态,并用 permutation-free objective 解决“speaker 槽位无序”这个训练难点。
这是后来 SA-EEND、EEND-EDA、EEND-TA 等工作的起点。
二、传统 diarization 方法的问题
1. 不是直接针对 DER 优化
传统系统虽然可以把 speaker embedding 训练得很强,但最后的 clustering 往往是无监督过程。
这意味着:
- 你可以优化 embedding
- 你也可以调聚类参数
- 但你很难让整条链路直接面向最终 diarization error 端到端优化
训练目标和最终评价指标之间并不完全一致。
2. 天然不擅长重叠语音
传统聚类方法默认一个时间段只对应一个 speaker。
但真实对话里经常有:
- 打断
- 抢话
- 同时说话
在这种情况下,“一个 segment 只能归给一个人”的假设就失效了。
所以这篇论文的出发点非常明确:
要想真正处理 overlapping speech,就不能再把 diarization 仅仅理解成聚类问题。
三、EEND 是怎么重新定义 diarization 的?
这篇论文最重要的一步,是把 diarization 写成一个多标签序列建模问题。
设输入特征序列为:
X=(x1,x2,…,xT),xt∈RF X = (\mathbf{x}_1, \mathbf{x}_2, \ldots, \mathbf{x}_T), \quad \mathbf{x}_t \in \mathbb{R}^{F} X=(x1,x2,…,xT),xt∈RF
其中:
- TTT 是时间帧数
- FFF 是每一帧的特征维度
模型不再为每一帧预测“属于哪一个单一说话人”,而是预测一个长度为 CCC 的二值向量:
yt=[yt,1,yt,2,…,yt,C],yt,c∈{0,1} \mathbf{y}_t = [y_{t,1}, y_{t,2}, \ldots, y_{t,C}], \quad y_{t,c} \in \{0,1\} yt=[yt,1,yt,2,…,yt,C],yt,c∈{0,1}
这里:
- yt,c=1y_{t,c} = 1yt,c=1 表示第 ccc 个 speaker 在第 ttt 帧说话
- yt,c=0y_{t,c} = 0yt,c=0 表示第 ccc 个 speaker 在第 ttt 帧不说话
于是,重叠语音就可以自然表达。例如:
yt=[1,1] \mathbf{y}_t = [1, 1] yt=[1,1]
表示这一帧上两个说话人同时活跃。
换句话说,EEND 说的不是“给每个段落分簇”,而是:
直接对每一帧预测所有说话人的 joint activity。
四、概率模型
论文先定义,目标是从所有可能的标签序列中找到最可能的那个:
Y^=argmaxY∈YP(Y∣X) \hat{Y} = \arg\max_{Y \in \mathcal{Y}} P(Y \mid X) Y^=argY∈YmaxP(Y∣X)
然后做了两个近似。
第一步,把整段序列拆成逐帧:
P(Y∣X)=∏t=1TP(yt∣y1,…,yt−1,X) P(Y \mid X) = \prod_{t=1}^{T} P(\mathbf{y}_t \mid \mathbf{y}_1, \ldots, \mathbf{y}_{t-1}, X) P(Y∣X)=t=1∏TP(yt∣y1,…,yt−1,X)
第二步,进一步近似成逐帧、逐 speaker 条件独立:
P(Y∣X)≈∏t=1TP(yt∣X)≈∏t=1T∏c=1CP(yt,c∣X) P(Y \mid X) \approx \prod_{t=1}^{T} P(\mathbf{y}_t \mid X) \approx \prod_{t=1}^{T} \prod_{c=1}^{C} P(y_{t,c} \mid X) P(Y∣X)≈t=1∏TP(yt∣X)≈t=1∏Tc=1∏CP(yt,c∣X)
它的意思是:
- 先不直接去做整段复杂组合搜索
- 而是让模型预测每一帧、每个 speaker 是否在说话
- 最终把这些逐帧预测拼起来,得到 diarization 结果
也正因为用了这种写法,overlap 才能自然进入模型输出空间。
五、网络结构
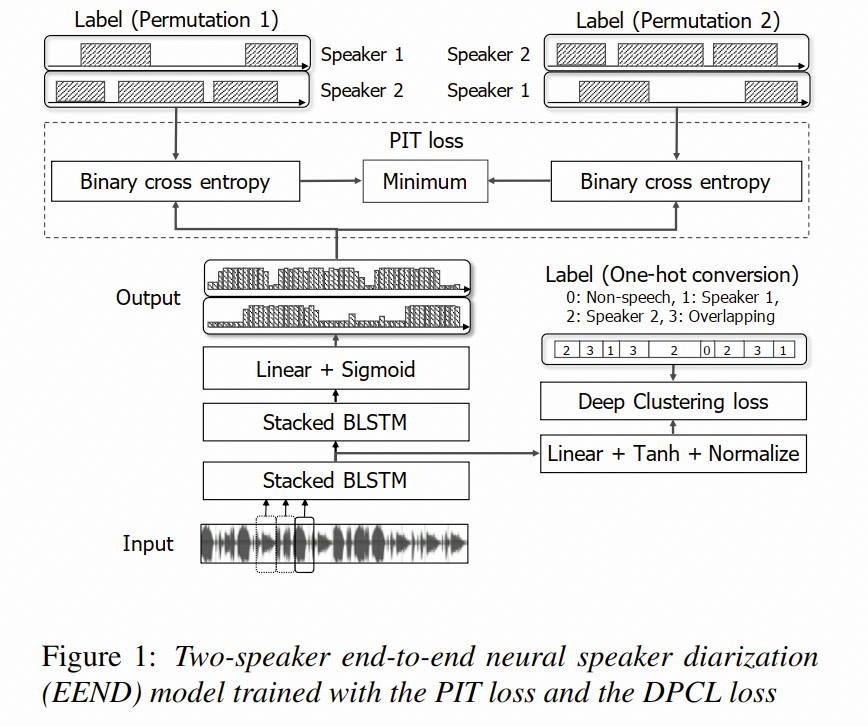
模型结构可以概括成:
输入声学特征
-> 多层 BLSTM
-> 线性层
-> sigmoid
-> 输出每一帧每个 speaker 的说话概率
具体公式如下。
第一层 BLSTM:
ht(1)=BLSTMt(x1,…,xT)∈R2H \mathbf{h}_t^{(1)} = \mathrm{BLSTM}_t(\mathbf{x}_1, \ldots, \mathbf{x}_T) \in \mathbb{R}^{2H} ht(1)=BLSTMt(x1,…,xT)∈R2H
第 ppp 层 BLSTM:
ht(p)=BLSTMt (h1(p−1),…,hT(p−1)),2≤p≤P \mathbf{h}_t^{(p)} = \mathrm{BLSTM}_t\!\left(\mathbf{h}_1^{(p-1)}, \ldots, \mathbf{h}_T^{(p-1)}\right), \quad 2 \le p \le P ht(p)=BLSTMt(h1(p−1),…,hT(p−1)),2≤p≤P
输出层:
zt=σ (Linear (ht(P)))∈(0,1)C \mathbf{z}_t = \sigma\!\left(\mathrm{Linear}\!\left(\mathbf{h}_t^{(P)}\right)\right) \in (0,1)^C zt=σ(Linear(ht(P)))∈(0,1)C
其中:
- zt\mathbf{z}_tzt 是第 ttt 帧每个 speaker 的说话概率
- 第 ccc 维 zt,cz_{t,c}zt,c 可以理解为第 ccc 个 speaker 在第 ttt 帧活跃的 posterior
最后再经过阈值化,就能得到二值的 speaker activity。
所以从结构上看,EEND 并不复杂。
真正难的,不是“怎么输出多路概率”,而是“多路输出怎么训练”。
六、EEND 真正的难点:speaker 槽位没有固定语义
Diarization 的标签和普通分类不一样。
以两说话人为例,同一段音频,下面两种标注方式都对:
方案 A:
输出通道 1 -> 真实说话人甲
输出通道 2 -> 真实说话人乙
方案 B:
输出通道 1 -> 真实说话人乙
输出通道 2 -> 真实说话人甲
speaker 1 / speaker 2 只是槽位,不是固定类别。
这和图像分类不同:
- 图像分类里,“猫”永远是猫
- diarization 里,“speaker 1”没有天然语义
如果直接用普通 BCE 去训,模型会被这种标签置换搞乱。
论文把这个问题叫做 label ambiguity。
七、论文核心:PIT 损失
为了解决 speaker permutation 问题,论文引入了 utterance-level permutation invariant training,也就是 PIT。
其损失函数为:
JPIT=1TCminϕ∈perm(C)∑t=1TBCE (ltϕ,zt) J_{\mathrm{PIT}} = \frac{1}{TC} \min_{\phi \in \mathrm{perm}(C)} \sum_{t=1}^{T} \mathrm{BCE}\!\left(\mathbf{l}_t^{\phi}, \mathbf{z}_t\right) JPIT=TC1ϕ∈perm(C)mint=1∑TBCE(ltϕ,zt)
这里:
- perm(C)\mathrm{perm}(C)perm(C) 表示 CCC 个 speaker 槽位的所有排列
- ϕ\phiϕ 表示其中一个排列
- ltϕ\mathbf{l}_t^{\phi}ltϕ 表示在排列 ϕ\phiϕ 下重排后的参考标签
- zt\mathbf{z}_tzt 表示模型输出
- BCE(⋅,⋅)\mathrm{BCE}(\cdot,\cdot)BCE(⋅,⋅) 是二元交叉熵函数。
PIT loss 的直观含义是:
对所有可能的 speaker 排列都算一遍 BCE,选择损失最小的那个排列来训练。
它告诉模型:
- 我不关心你把“输出通道 1”理解成谁
- 我只关心你输出的两条 speaker 轨迹能否和参考标签在某种排列下对应上
八、为什么还要再加一个 DPCL 损失?
论文没有只停在 PIT 上,还加入了一个辅助损失:Deep Clustering loss。
作者的直觉是:
- 低层 BLSTM 隐状态里,其实已经有 speaker representation
- 如果能显式约束这些中间表示“按 speaker 聚起来”,最终 segmentation 会更稳
于是,先把第 qqq 层的隐藏状态映射成归一化 embedding:
vt(q)=Normalize (tanh (Linear (ht(q))))∈RD \mathbf{v}_t^{(q)} = \mathrm{Normalize}\!\left(\tanh\!\left(\mathrm{Linear}\!\left(\mathbf{h}_t^{(q)}\right)\right)\right) \in \mathbb{R}^{D} vt(q)=Normalize(tanh(Linear(ht(q))))∈RD
然后定义 DPCL 损失:
JDC=∥VV⊤−L′L′⊤∥F2 J_{\mathrm{DC}} = \left\lVert V V^\top - L^\prime {L^\prime}^\top \right\rVert_F^2 JDC= VV⊤−L′L′⊤ F2
其中:
- V=[v1,…,vT]⊤V = [\mathbf{v}_1, \ldots, \mathbf{v}_T]^\topV=[v1,…,vT]⊤
- L′L^\primeL′ 是把帧级标签转换成 power-set one-hot 后得到的标签矩阵
- ∥⋅∥F\lVert \cdot \rVert_F∥⋅∥F 是 Frobenius norm
在两说话人场景里,power set 一共有 4 类:
- non-speech
- speaker 1
- speaker 2
- overlap
于是,DPCL 的目标可以理解成:
- 同一类帧的 embedding 彼此靠近
- 不同类帧的 embedding 彼此远离
最后论文把两个损失加权组合:
JMULTI=(1−α)JPIT+αJDC J_{\mathrm{MULTI}} = (1 - \alpha) J_{\mathrm{PIT}} + \alpha J_{\mathrm{DC}} JMULTI=(1−α)JPIT+αJDC
一个比较直观的理解是:
PIT负责最终输出和标签对齐DPCL负责让中间表示更有 speaker 结构
从结果看,论文也验证了这两个损失确实是互补的。
九、工程优化:设计了适合 diarization 的数据合成方式
这篇论文并没有拿传统 source separation 的混音方式直接套过来,而是专门设计了更像对话的 mixture simulation。
它的目标不是“让两个干净语音简单叠加”,而是生成:
- 每个 speaker 有很多段 utterance
- 句与句之间有随机间隔
- 允许自然产生 overlap
- 还能叠加噪声与混响
其核心控制变量是平均静音间隔 β\betaβ。
论文用指数分布采样句间隔:
d∼Exponential(mean=β) d \sim \mathrm{Exponential}(\text{mean} = \beta) d∼Exponential(mean=β)
直觉上:
- β\betaβ 越小,句间隔越短,重叠越多
- β\betaβ 越大,句间隔越长,重叠越少
它让作者可以系统性地控制 overlap ratio,专门分析模型在不同重叠强度下的表现。
把算法压缩成更好懂的伪代码:
for each mixture:
sample 2 speakers
for each speaker:
sample 20~40 utterances
insert random silences controlled by β
optionally convolve with a random RIR
concatenate into one speaker stream
pad all speaker streams to the same length
sum them into one mixture
sample background noise and SNR
add scaled noise
提出了一种更适合 diarization 任务的数据生成方式。
十、实验设置
1. 数据集
- 语音来源是电话语音语料:
Switchboard-2 Phase I/II/III、Switchboard Cellular Part 1/2、NIST SRE 2004/2005/2006/2008 - 这些语料里总共有 6,381 个 speaker
5,743 个 speaker 做训练
638 个 speaker 做测试 - 然后用这些 speaker 的语音去合成双人对话混合数据:
每个 mixture 固定是 2-speaker
每个 speaker 在一个 mixture 里抽 20~40 条 utterance
句间随机间隔由 β\betaβ 控制
还会加背景噪声和 RIR
2. 输入特征
论文使用:
23维 log-Mel filterbank- 帧长
25 ms - 帧移
10 ms - 拼接前后各
7帧上下文 - 再做
10倍下采样
所以最终输入既有局部上下文,又降低了序列长度。
3. 模型配置
论文里的 EEND 配置是:
5层 BLSTM- 每层
256hidden units - DPCL 分支使用第二层 BLSTM 输出形成
256维 embedding
4. 训练设置
- 优化器:Adam
- 初始学习率:10−310^{-3}10−3
- batch size:
10 - 训练轮数:
20
5. 后处理
模型输出的是概率,因此论文在评估时:
- 使用阈值
0.5 - 再做
11-frame median filtering
6. 评价方式
把 non-speech 和 overlapping speech 也都纳入了 DER 评估。
这和很多早期只在 oracle speech region 里评估的设置不一样,也更严格。
十一、结果 1:PIT 是必须的,DPCL 是有帮助的
论文先做了损失函数消融,结果如下:
| PIT | DPCL | DER (%) |
|---|---|---|
| 否 | 否 | 41.74 |
| 是 | 否 | 25.14 |
| 是 | 是 | 23.79 |
这个表说明了两件事。
第一,PIT 提升效果明显。
DER 从 41.74% 直接降到 25.14%,说明 permutation-free training 是绝对核心。
第二,DPCL 进一步改善了模型表现。
这说明中间层 speaker-discriminative representation 对最终 diarization 是有帮助的。
这里多说一下没有 PIT 损失的训练,是用 fixed permutation,具体做法是:
- 把参考 speaker 名字按字典序排序
- 用这个顺序决定输出通道和参考标签的对应关系
- 然后直接算普通 BCE
理论上模型只是对说话人进行区分,不一定非得知道输出通道是什么名字,但如果在另一条合成音频中,原本对应上一条音频的 spk A, 现在变成了 spk B, 模型会产生混乱。
十二、结果 2:训练数据量越大,EEND 越强
论文还比较了训练 mixture 数量的影响:
| 训练 mixture 数量 | DER (%) |
|---|---|
| 10,000 | 23.79 |
| 20,000 | 14.66 |
| 100,000 | 12.28 |
这个趋势非常清楚。
EEND 的一个重要优点是:
它只需要多说话人音频和对应帧级标签,就可以继续扩数据。
传统 clustering 方法往往更依赖 embedding 预训练和聚类策略,而 EEND 这条路线对大规模数据是非常敏感的。
这也解释了为什么后面几年,随着更好的模拟数据、更好的真实数据和更好的架构出现,EEND 系列会持续进步。
十三、结果 3:在重叠语音上,EEND 明显优于传统方法
论文把 EEND 和 i-vector / x-vector clustering 做了对比。
在 β=2\beta = 2β=2 的 simulated mixtures 上,结果如下:
| 方法 | DER | Miss | FA | Confusion |
|---|---|---|---|---|
| i-vector | 33.74 | 25.82 | 1.05 | 6.88 |
| x-vector | 28.77 | 25.82 | 1.05 | 1.90 |
| EEND | 12.28 | 4.47 | 5.20 | 2.61 |
这个结果很有意思。
1. EEND 最大的优势是显著降低了 Miss
传统 clustering 方法在 overlap 条件下,Miss 非常高。
原因很直接:它们对重叠语音建模能力弱,很多 overlap 片段会被漏掉。
而 EEND 的 Miss 从 25.82 直接降到 4.47,说明它确实学会了:
- single-speaker speech
- overlapping speech
- non-speech
这正是端到端多标签建模的价值。
2. EEND 的 False Alarm 偏高
EEND 的 FA = 5.20,高于 clustering baseline。
这说明早期 EEND 的一个现实短板是:
它虽然很擅长抓住 overlap,但边界和 speech/non-speech 判定还不够稳。
3. Confusion 没有全面碾压 x-vector
EEND 的 Confusion = 2.61,比 i-vector 好,但比 x-vector 的 1.90 稍差。
这也很正常,因为 x-vector + clustering 在 speaker discrimination 上本来就很成熟。
原始 EEND 的突破,主要是在 overlap 建模和端到端训练框架上,而不是一上来就在所有子项都绝对领先。
十四、结果 4:它对 overlap ratio 的泛化还不够稳
论文进一步测试了不同重叠比例:
| Evaluation set | overlap ratio (%) | i-vector | x-vector | EEND |
|---|---|---|---|---|
| Simulated β=2\beta=2β=2 | 27.3 | 33.74 | 28.77 | 12.28 |
| Simulated β=3\beta=3β=3 | 19.1 | 30.43 | 24.46 | 14.36 |
| Simulated β=5\beta=5β=5 | 11.1 | 25.96 | 19.78 | 19.69 |
这个结果其实有一点反直觉。
随着 overlap 变少:
- baseline 越来越好,这是符合预期的
- 但 EEND 反而从
12.28退化到19.69
作者给出的解释是:
模型过拟合到了训练时的 overlap ratio。
这也暴露出原始 EEND 的一个明显限制:
它虽然能处理 overlap,但对训练分布很敏感。
后面很多工作之所以继续沿着 EEND 往下做,一个重要原因就是要解决这种分布敏感性。
十五、结果 5:在真实 CALLHOME 上,domain adaptation 很重要
论文还在 CALLHOME 上做了实验。
结果是:
- x-vector:
11.53 - EEND:
31.01 - EEND + domain adaptation:
23.07
也就是说,原始 EEND 在真实电话对话上的零样本泛化并不好,但经过 domain adaptation 以后,DER 相对下降了 25.6%。
为什么会这样?
论文自己给出的解释很合理:
- 训练数据 overlap ratio 是
5.8% - CALLHOME 测试集 overlap ratio 是
11.8%
训练分布和测试分布差得比较大,导致原始 EEND 泛化不足。
所以这篇论文传达出的不是“EEND 一上线就全面超越传统方法”,而是:
EEND 在模拟重叠语音上已经非常强,但在真实域上还需要更好的数据匹配和适配策略。
这个判断其实非常诚实,也和后续研究方向完全一致。
十六、论文贡献
1. 第一次把 diarization 清晰地写成逐帧多标签问题
这是最根本的变化。
以前大家更多是在“segment + embedding + clustering”这个范式里打转;
这篇论文直接说:我不聚类了,我逐帧预测每个 speaker 的 activity。
2. 用 permutation-free objective 把训练问题真正打通了
这是 EEND 能够成立的关键。
如果没有 PIT,speaker 槽位无序这个问题会让普通监督学习目标失效。
3. 把 overlap 建模真正纳入了 diarization 主体
不是把 overlap 当边角问题修修补补,而是从标签定义开始就允许 overlap 存在。
4. 证明了端到端 diarization 至少在模拟 overlap 场景里是可行且有效的
12.28% 对 28.77% 这个结果,在当时是非常有说服力的。
十七、局限
1. 主要还是双说话人场景
原论文都是在仿真数据上做的实验,且几乎都围绕 2-speaker 设置展开。
这意味着它离真实会议场景中“说话人数未知、说话人数可变”的情况还有距离。
2. 编码器是 BLSTM
BLSTM 能建模上下文,但长距离 speaker 关联能力有限。
后来的 SA-EEND 会用 self-attention 替代 BLSTM。
3. 对训练分布敏感
这篇论文已经暴露出 overlap ratio mismatch 的问题。
后续很多 EEND 工作,本质上都在补这个短板。
4. 边界与 false alarm 还不够稳
早期 EEND 在 overlap 检测上很强,但在 speech/non-speech 边界和 false alarm 控制上仍有优化空间。
十八、总结
这篇论文最有价值的地方,不只是提出了一个新模型,而是把整个问题重新写了一遍。
它告诉我们:
- diarization 不一定非得走聚类
- overlap 不应该被排除在任务之外
- 端到端训练是可以直接为 diarization error 服务的
EEND 回答了为什么 speaker diarization 可以被重新定义成一个端到端多标签时序建模问题。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 13
13 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)