云端部署llamafactory使用lora微调千问模型 | 微调、推理、合并
目录
1. 训练阶段:修改配置文件examples/train_lora/qwen3_lora_sft.yaml
2. 体验/验证阶段:修改配置文件examples/inference/qwen3_lora_sft.yaml
3. 部署/导出阶段:examples/merge_lora/qwen3_lora_sft.yaml
llamafactory简单介绍
LlamaFactory 是一个开源的大语言模型(LLM)微调框架,主要特点:
1、核心功能:
- 统一微调平台:支持 100+ 种大模型(LLaMA、Qwen、Mistral、ChatGLM 等)
- 多种训练方法:全参数微调、LoRA、QLoRA、DoRA 等
- 多任务支持:预训练、指令微调(SFT)、奖励模型训练、RLHF、DPO 等
2、主要优势:
- 易用性高:提供 Web UI(LlamaBoard),无需写代码即可训练
- 效率优化:集成 FlashAttention-2、Unsloth 等加速技术
- 量化支持:支持 4-bit/8-bit 量化训练,降低显存需求
- 数据灵活:内置大量数据集,也支持自定义数据格式
3、适用场景:
- 个人或小团队在消费级 GPU 上微调大模型
- 快速实验不同微调策略
- 构建领域专属的对话/任务模型
4、项目信息
- GitHub: hiyouga/LLaMA-Factory
- Star 数量超过 40k(截至 2025 年),社区活跃
简单来说,LlamaFactory 是目前最流行的"低门槛微调大模型"工具之一。
目标:
我们今天介绍在魔搭社区使用免费云算力(每个新用户有36小时免费额度,并且性能相当不错),部署llamafactory,使用lora的方式微调模型Qwen3-4B-Instruct-2507,全流程包括微调训练,模型推理,模型合并以及批量api调用。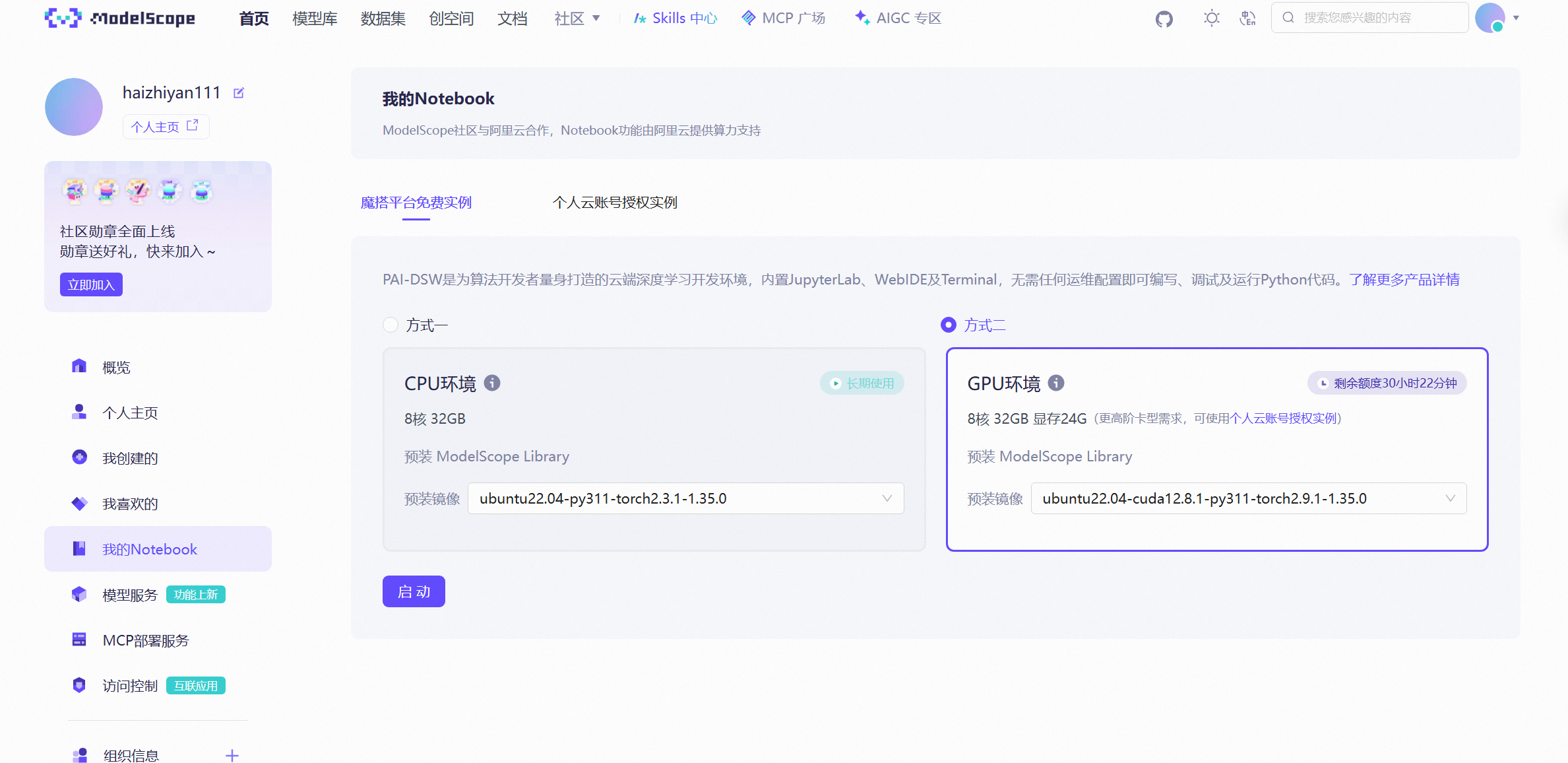
我们选择第二种gpu环境启动。
安装LLaMA Factory
在github上搜索llamafactory,第一个项目就是:
往下翻可以看到安装方式,这里我直接给出来:
git clone --depth 1 https://github.com/hiyouga/LlamaFactory.git
cd LlamaFactory
pip install -e .
pip install -r requirements/metrics.txt在魔搭社区启动gpu环境后,打开终端,输入上面命令部署llamafactory: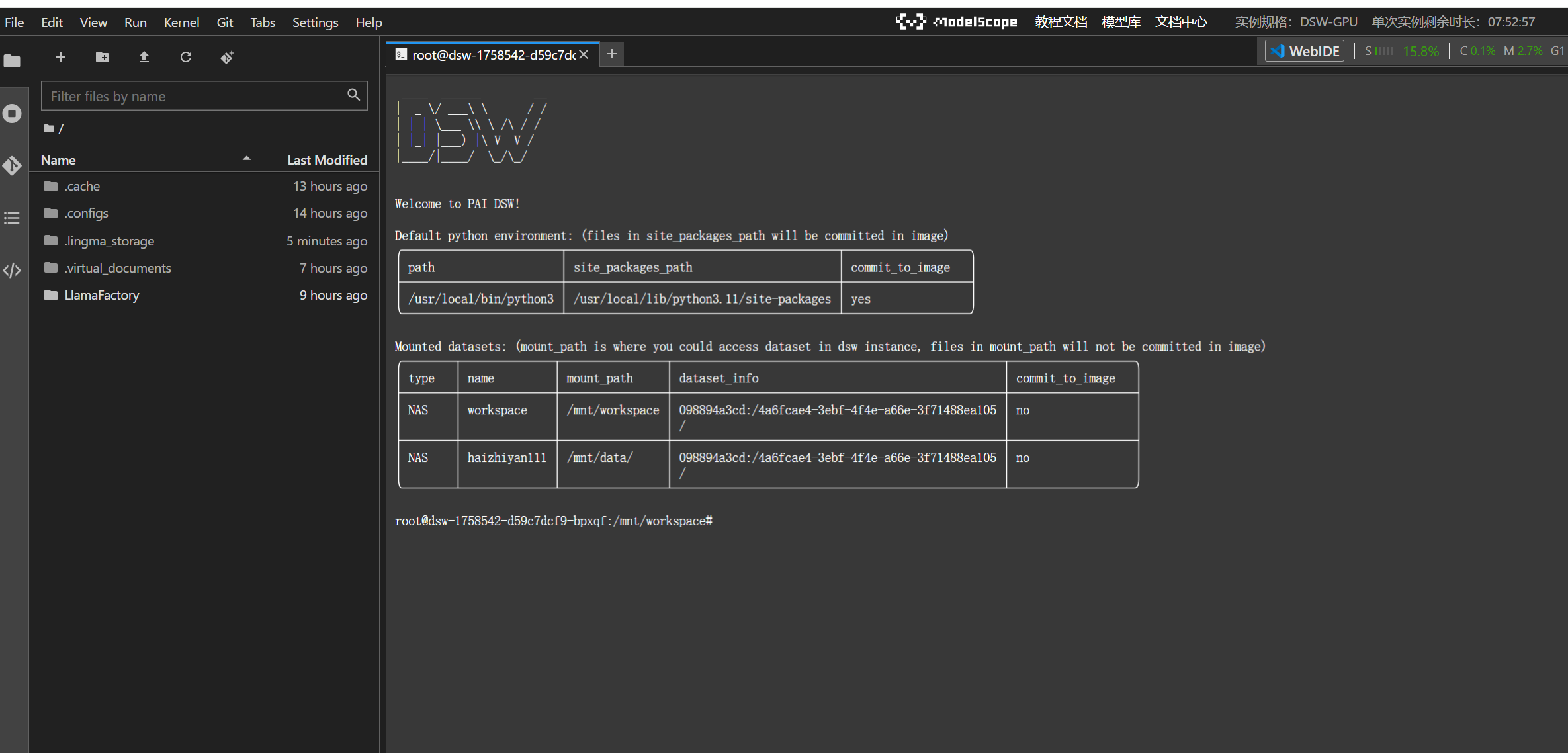
下载模型
https://modelscope.cn/models/Qwen/Qwen3-4B-Instruct-2507
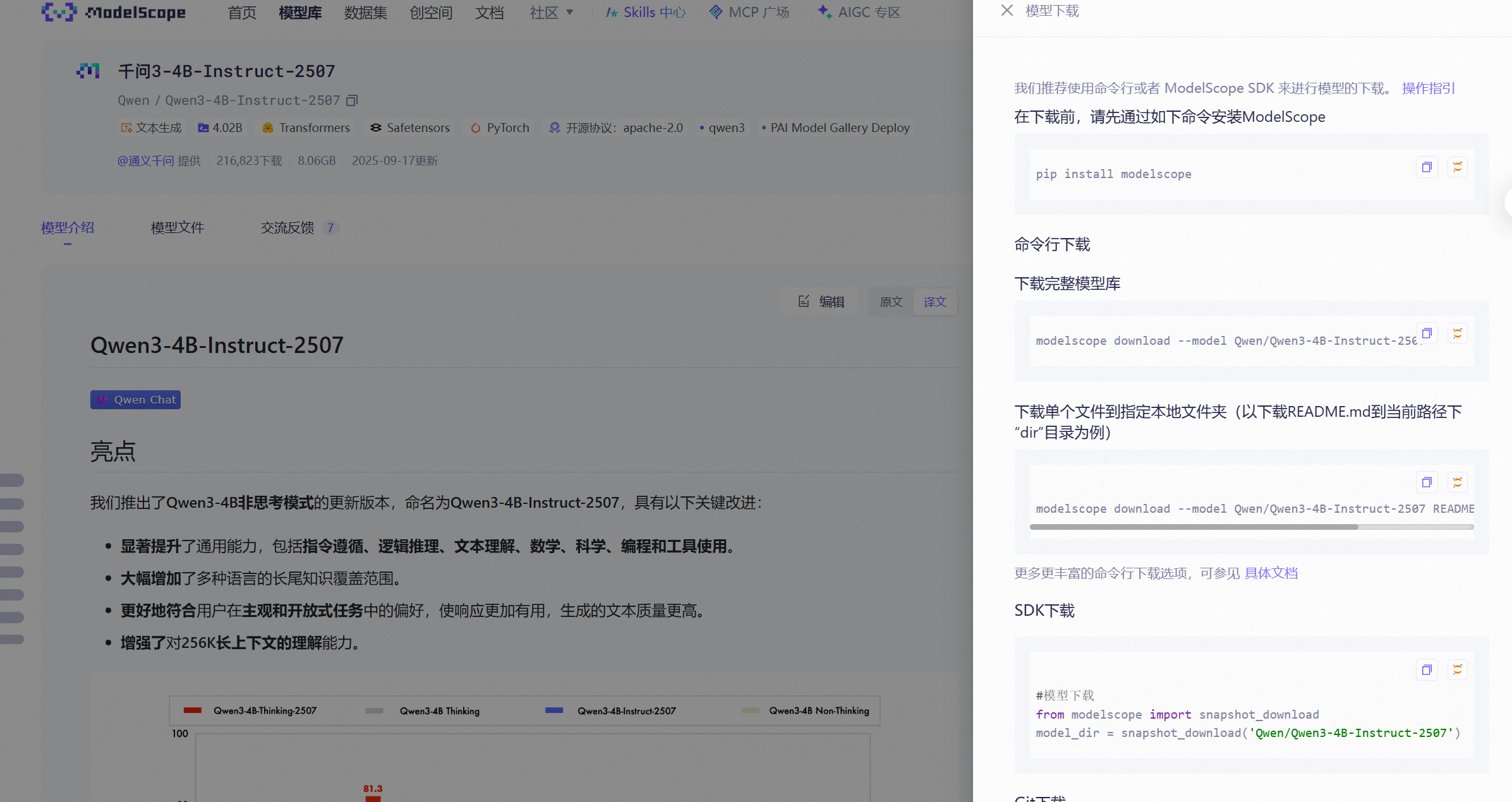
同样在魔搭社区,我们下载千问的这个模型,因为这个模型参数大小和我们使用的gpu环境性能比较适配。在gpu环境的终端执行右边的两条命令即可下载完成。
在view选项开启隐藏文件,在.cache目录下看到下载的模型就说明下载成功。
快速开始
下面三行命令分别对 Qwen3-4B-Instruct 模型进行 LoRA 微调、推理和合并。
llamafactory-cli train examples/train_lora/qwen3_lora_sft.yaml
llamafactory-cli chat examples/inference/qwen3_lora_sft.yaml
llamafactory-cli export examples/merge_lora/qwen3_lora_sft.yaml关键文件介绍
这三个文件是 LLaMA-Factory 工作流中最核心的“三驾马车”。它们分别对应了大模型微调项目的三个关键阶段:训练、体验和部署。
简单来说,这是一个从“教模型”到“考模型”再到“带模型出门”的完整闭环。
以下是详细的介绍:
1. 训练阶段:修改配置文件examples/train_lora/qwen3_lora_sft.yaml
-
对应命令:
llamafactory-cli train ... -
核心作用:“教模型”。 这是整个流程的起点。这个文件定义了怎么学。
-
关键配置修改:
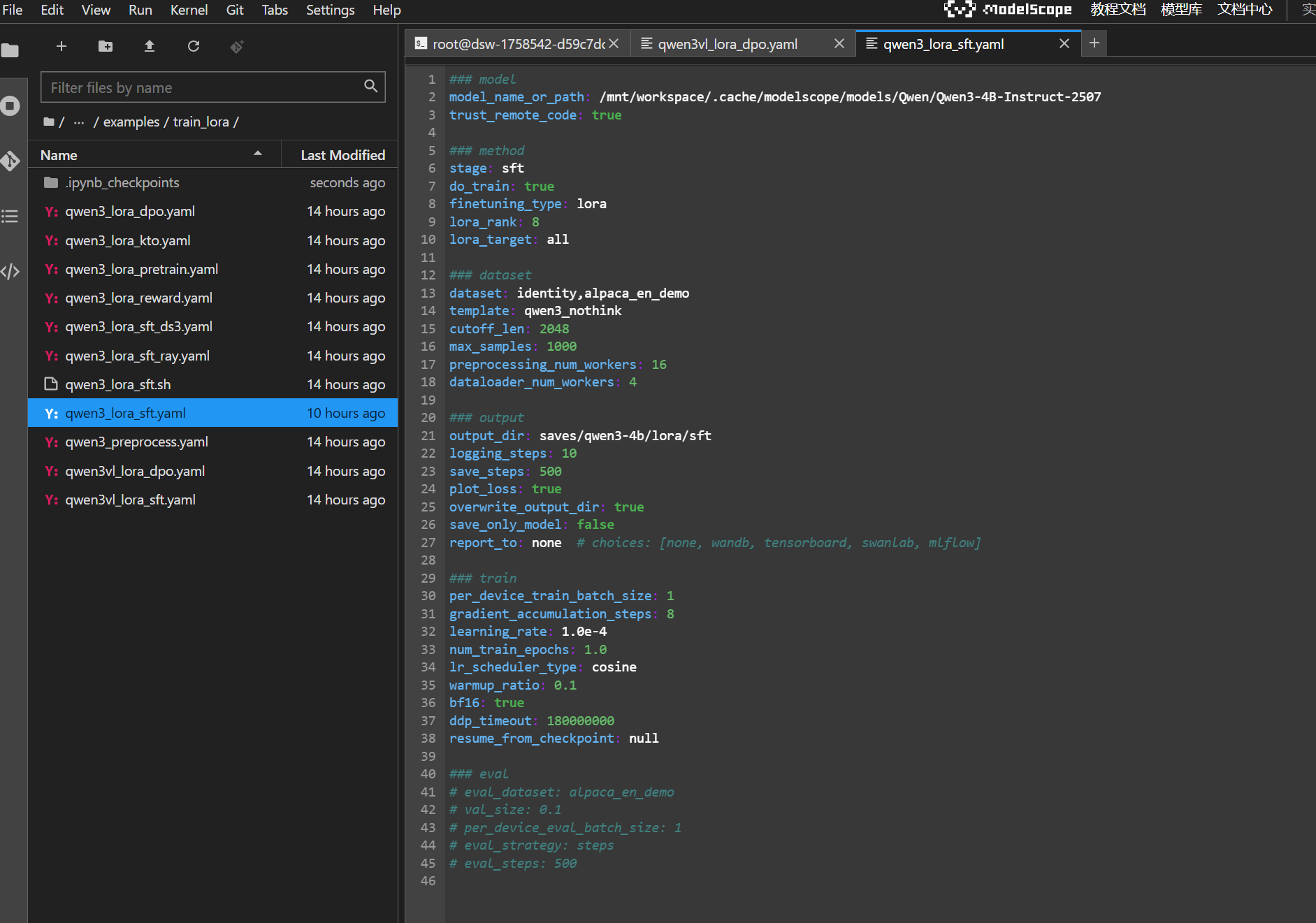
最重要的是把第一行模型路径改成我们下载的路径,其他参数可以自行调整:
/mnt/workspace/.cache/modelscope/models/Qwen/Qwen3-4B-Instruct-2507-
学什么:指定数据集(
dataset: sft_data)和对话模板(template: qwen3)。 -
怎么学:设定学习率(
learning_rate)、训练轮数(num_train_epochs)、批次大小(per_device_train_batch_size)。 -
学多少:配置 LoRA 的参数,比如秩(
lora_rank: 8)和目标模块(lora_target: all)。
-
-
这里我们学习的数据集dataset: identity,alpaca_en_demo可以查看一下:
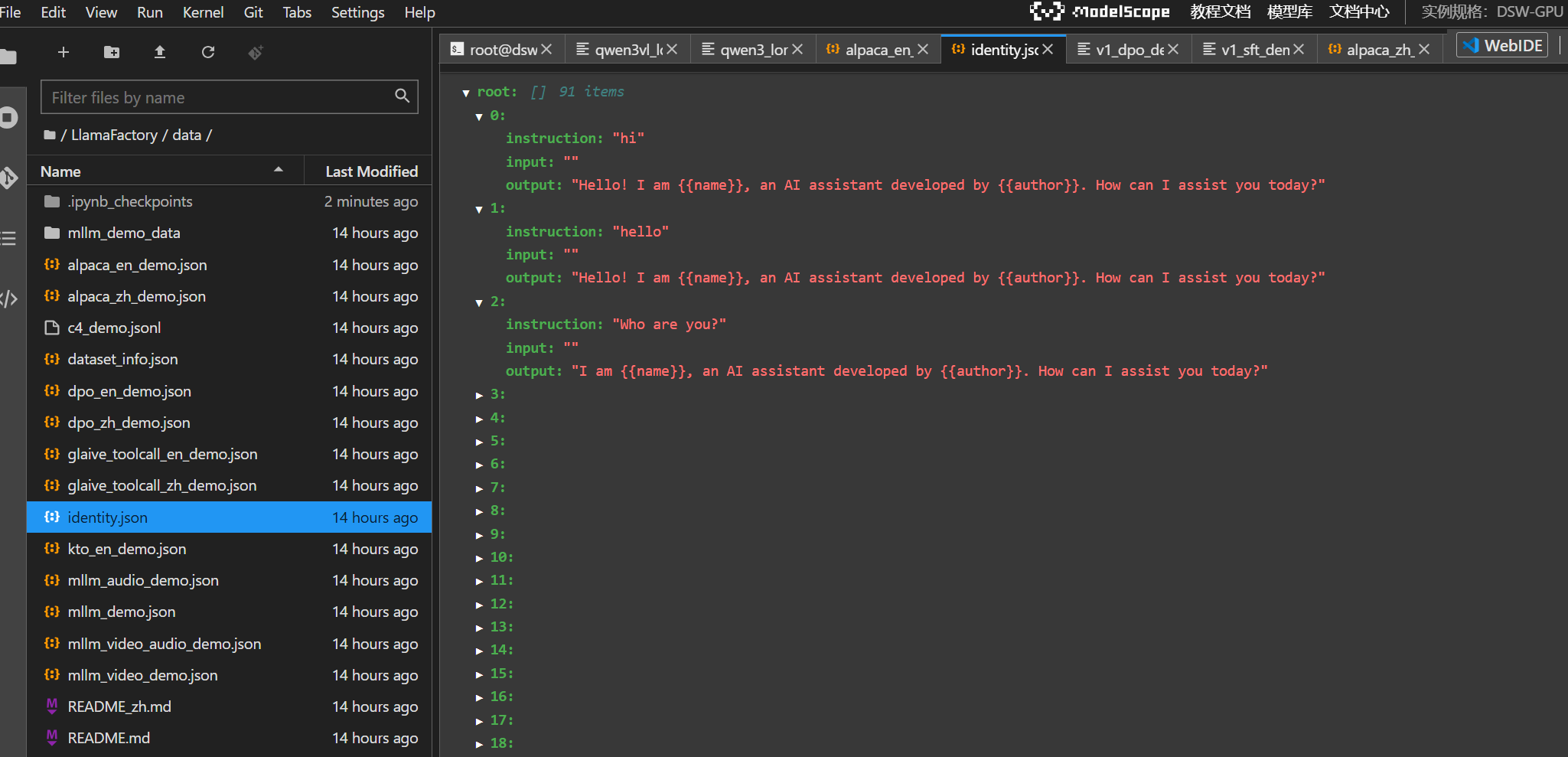
经过这样的数据集微调训练,待会我们模型推理时询问who are you ,模型会模仿我们的数据集回复。
-
产出:运行后,你会得到一个新的文件夹(通常在
saves/目录下),里面包含训练好的 LoRA 权重文件(adapter_model.bin)。
2. 体验/验证阶段:修改配置文件examples/inference/qwen3_lora_sft.yaml
-
对应命令:
llamafactory-cli chat ... -
核心作用:“考模型”。 训练完后,你不需要把模型部署到服务器,而是想先在命令行里跟它聊聊天,看看效果好不好。这个文件定义了怎么聊。
-
关键配置
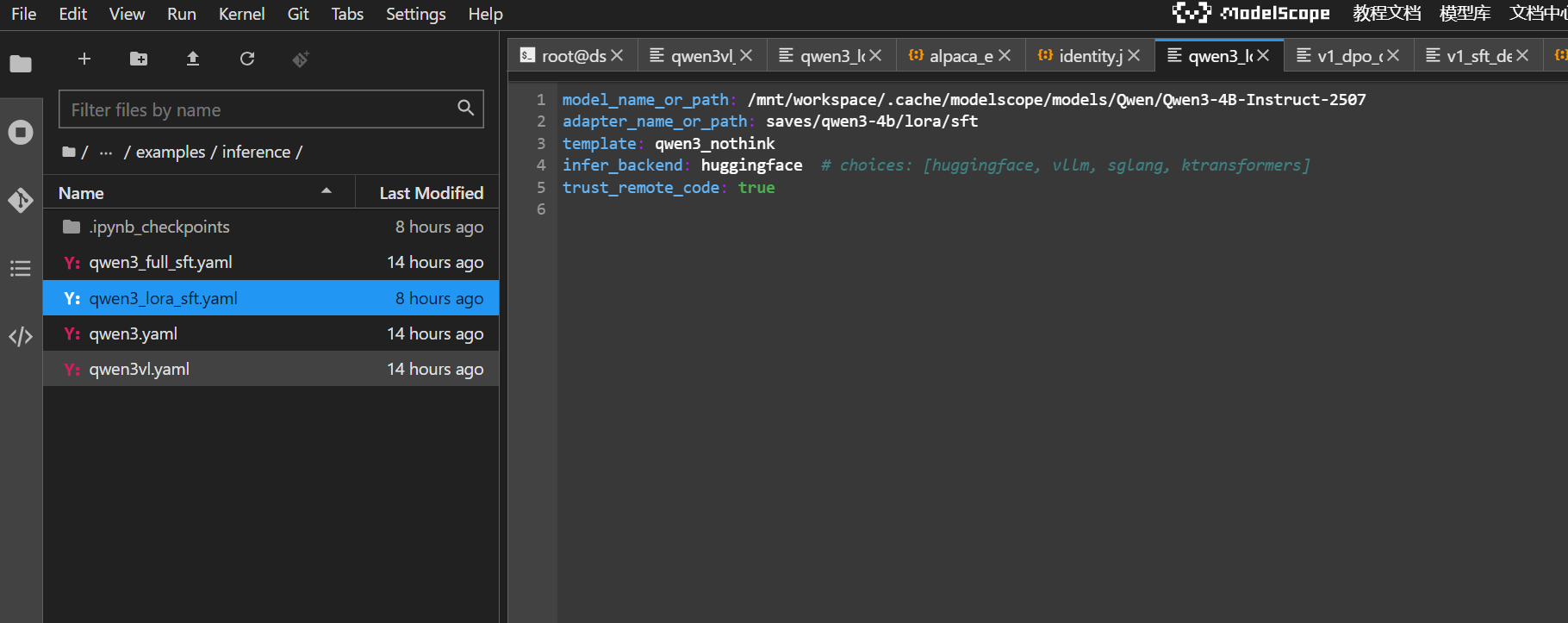
主要把模型路径改成我们下载的模型,微调文件选择我们微调的权重文件路径。本质上实现原模型和微调参数的拼接,使得模型获得微调的能力。
-
加载谁:它需要同时指定基础模型(
model_name_or_path)和刚才训练出来的 LoRA 权重(adapter_name_or_path)。 -
用什么引擎:这里就是你刚才问到的
infer_backend: huggingface或vllm。 -
格式:必须保持和训练时一样的对话模板(
template: qwen3),否则模型会听不懂人话。
-
-
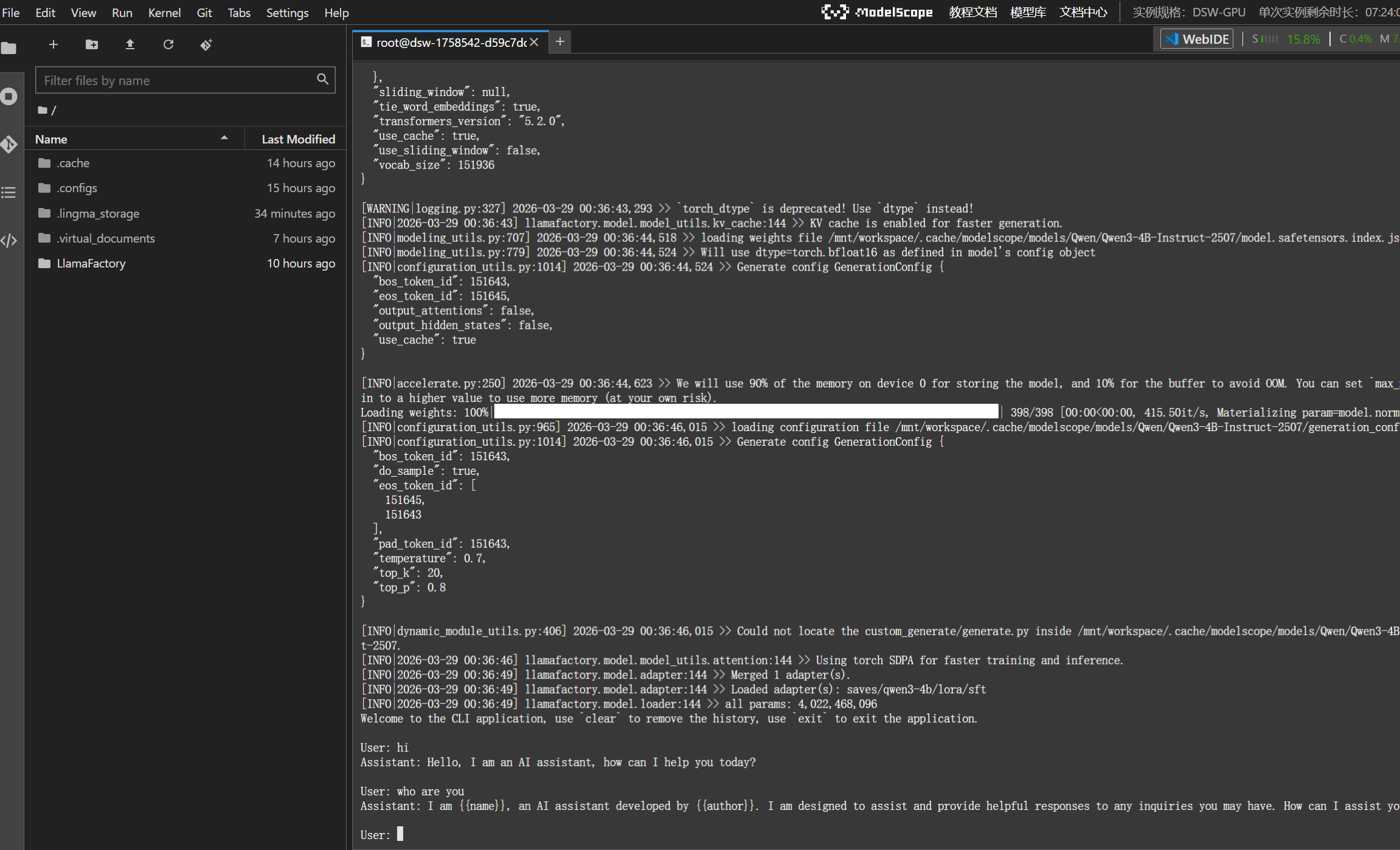
产出:一个交互式的命令行界面,你可以输入问题,模型实时回答。执行推理命令后科技逆行对话:
3. 部署/导出阶段:examples/merge_lora/qwen3_lora_sft.yaml
-
对应命令:
llamafactory-cli export ... -
核心作用:“打包模型”。 LoRA 权重只是一个“补丁”,不能独立运行。如果你要把模型发给别人,或者部署到生产环境,通常希望它是一个独立的、完整的模型文件。这个文件定义了把微调的权重合并到模型上,获得一个完整的模型文件。
-
关键配置修改:
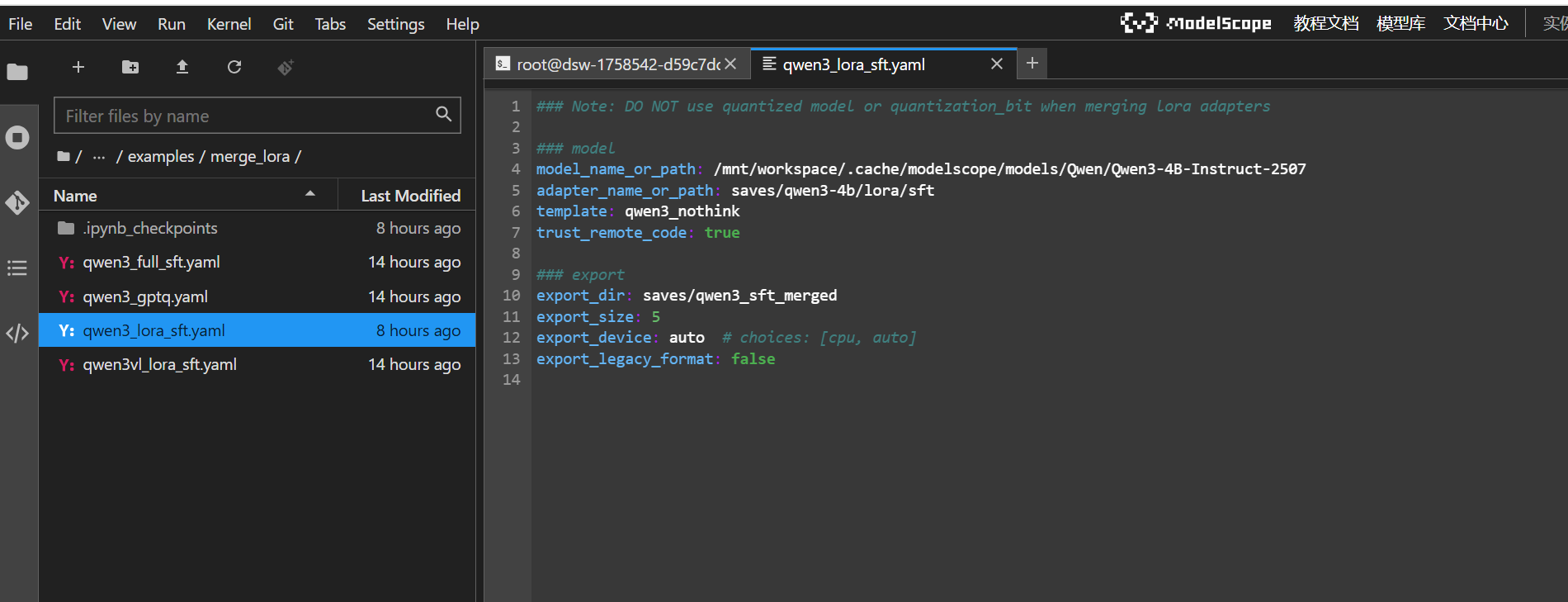
和之前一样,修改成自己的模型和微调权重路径。其他参数自行设置。
-
源文件:指定基础模型路径和 LoRA 权重路径。
-
去向:指定合并后的模型保存路径(
export_dir)。 -
注意:这里通常要求基础模型必须是 FP16/BF16 格式,不能是量化过的(如 INT4/INT8),否则合并会失败或精度受损。
-
-
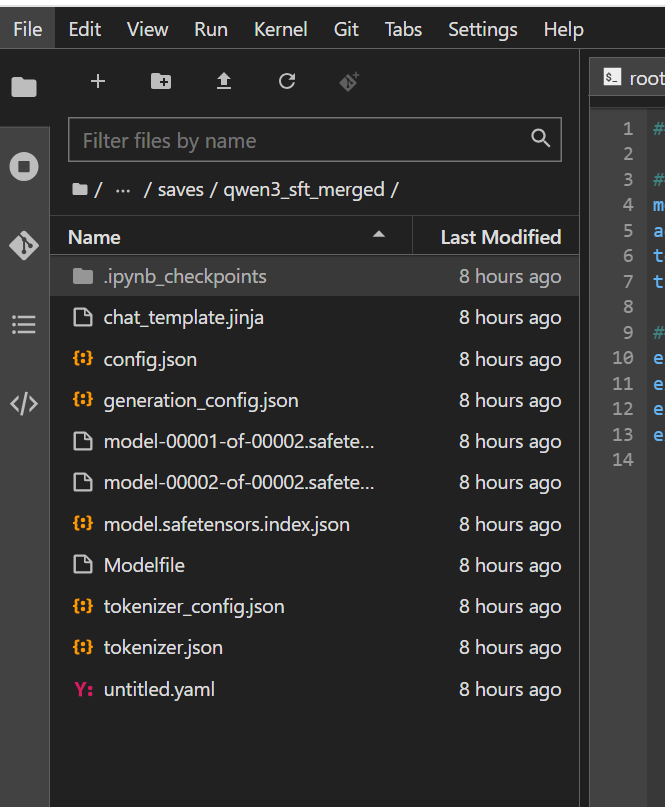
产出:一个全新的、独立的模型文件夹。这个文件夹里包含了所有权重,不再依赖 LoRA 插件,可以直接被任何支持该架构的工具加载。
| 文件名关键词 | 角色 | 动作 | 你的操作 |
|---|---|---|---|
| train | 老师 | 训练 | 修改它来调整学习策略,跑完得到“补丁包”。 |
| inference | 考官 | 测试 | 修改它来加载“补丁包”,跑完进行对话测试。 |
| merge | 打包员 | 合并 | 修改它来指定输出位置,跑完得到“完整版模型”。 |
参数介绍
safetesnsors 是什么?
Safetensors 是一种用于安全存储张量(如模型权重)的新型文件格式,由 Hugging Face 团队开发,旨在解决传统格式(如 .pth 或 .bin)在安全性和加载效率上的不足。它不包含可执行代码,仅存储张量数据,因此在加载来自不可信来源的模型时更安全,且支持零拷贝加载,速度极快。
使用方法
!pip install safetensors
from safetensors import safe_open
with safe_open("adapter_model.safetensors", framework="pt", device=0) as f:
for key in f.keys():
tensor = f.get_tensor(key)
# 处理 tensor查看
print(tensor)新建一个ipynb文件用来执行python代码,可以看到张量形式的参数: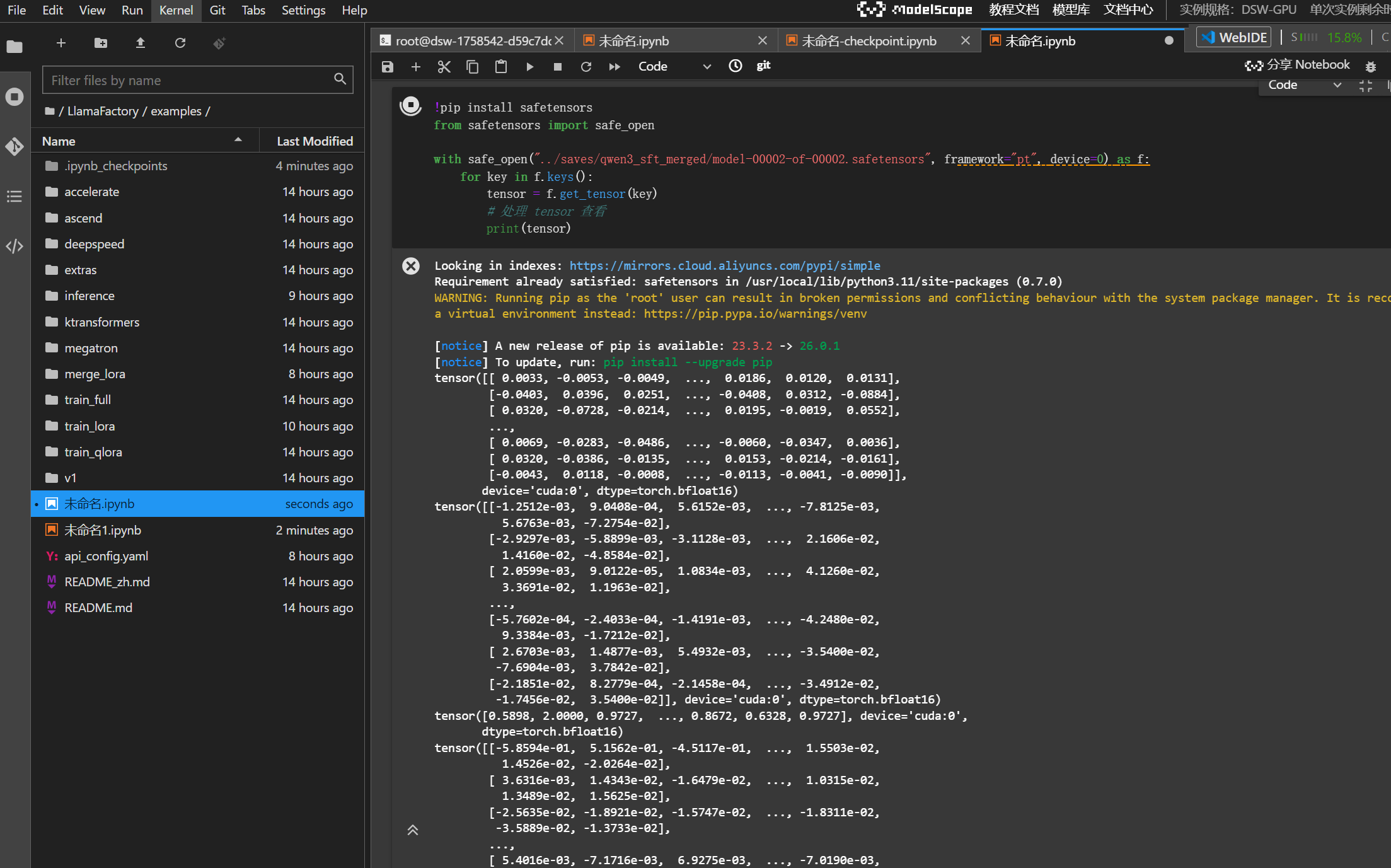
interence参数介绍
infer_backend: huggingface # choices: [huggingface, vllm, sglang, ktransformers]
指定模型在推理(运行/对话)时,底层使用哪个“引擎”来驱动。
| 选项 | 特点描述 | 适用场景 |
|---|---|---|
| huggingface | 默认选项。兼容性最强,几乎支持所有模型,无需额外安装复杂依赖source_group_web_4。但推理速度相对较慢,显存利用率一般。 | 调试、开发、快速验证。 |
| vllm | 高性能。通过 PagedAttention 技术极大提升吞吐量,推理速度极快,显存占用更低source_group_web_6。 | 生产环境、批量处理。 |
| sglang | 极速/新架构。比 vLLM 更新,针对复杂提示词(如多轮对话、Agent)有专门优化,速度往往更快source_group_web_8。 | 追求极致速度、复杂 Agent 应用。适合对延迟极其敏感的场景。 |
| ktransformers | 特定优化。通常指针对特定硬件或架构优化的内核版本(较少见,视具体版本而定)。 | 特定硬件优化场景。 |
使用API进行批量推理
准备/新建 API 配置文件api_config.yaml,用于告诉服务加载哪个模型、使用哪个推理后端以及端口是多少。
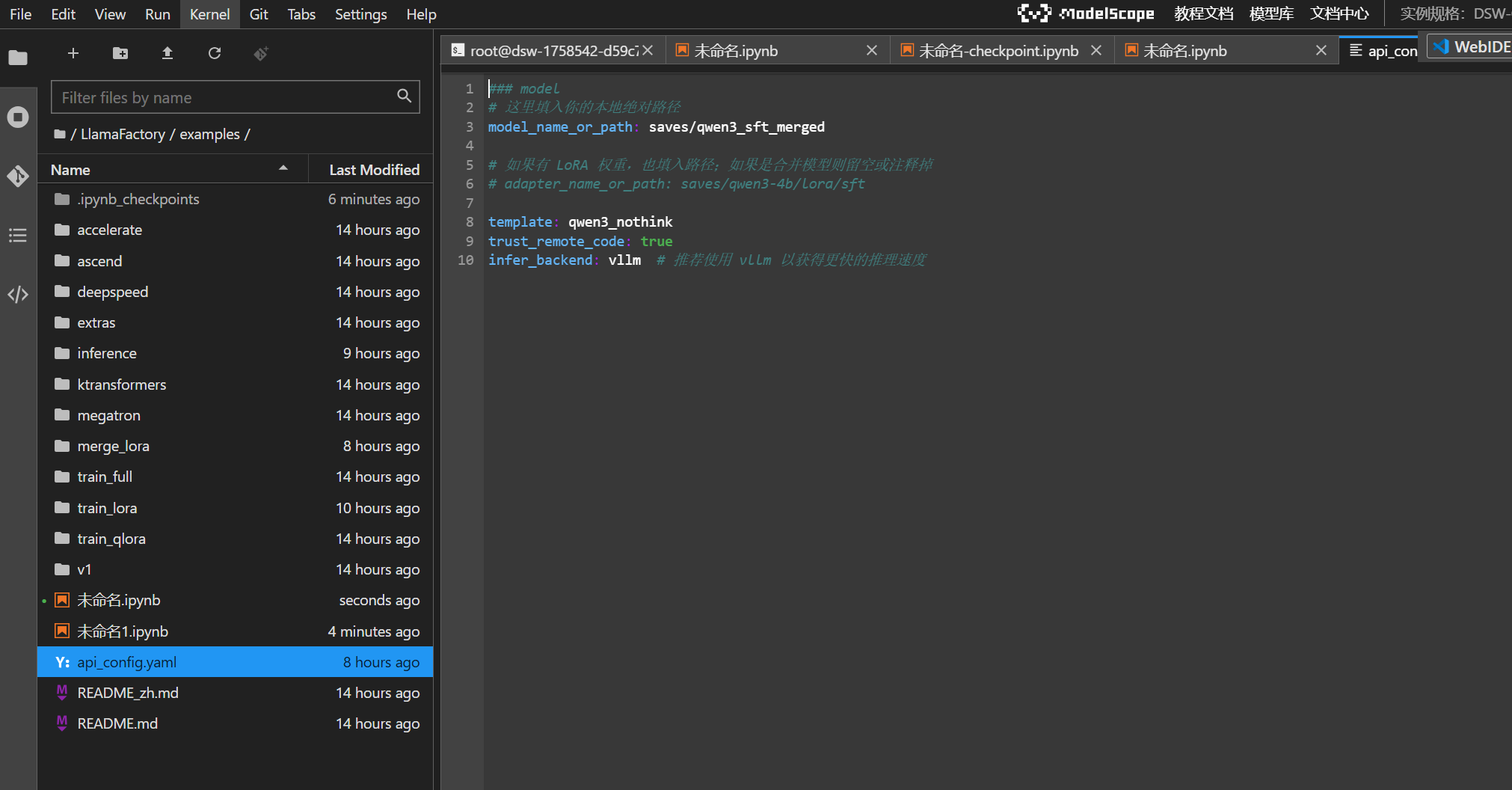
在根目录下使用命令行启动
# 指定端口为 8000,使用第 0 号 GPU
API_PORT=8000 CUDA_VISIBLE_DEVICES=0 DISABLE_VERSION_CHECK=1 llamafactory-cli api examples/api_config.yaml启动后状态: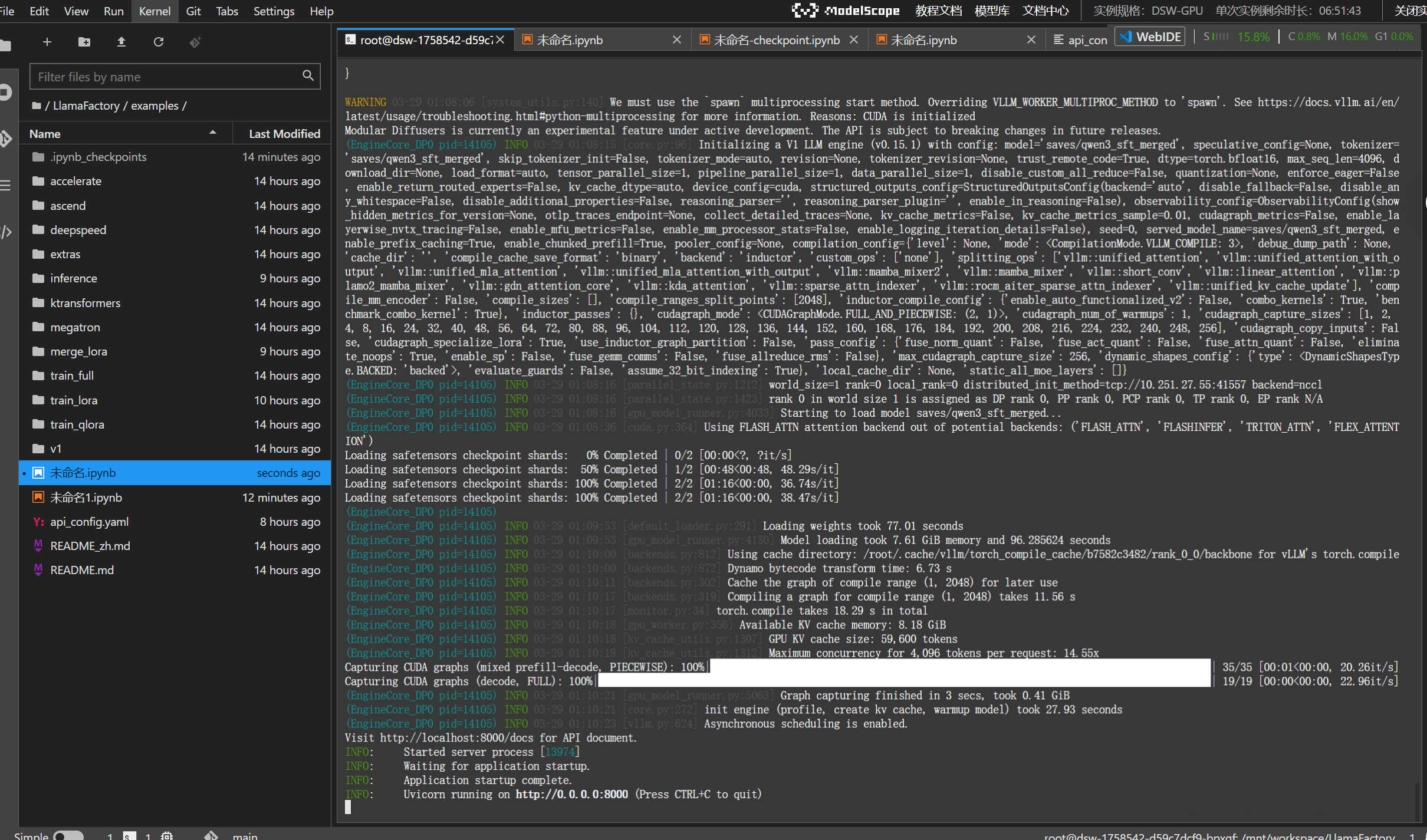
使用脚本进行批量推理
from openai import OpenAI
# 初始化客户端
client = OpenAI(
api_key="0",
base_url="http://localhost:8000/v1"
)
# 1. 定义批量问题列表
questions = [
"你好,请介绍一下你自己",
"量子力学是什么?",
"如何用 Python 写一个冒泡排序?"
]
print(f"开始批量推理,共 {len(questions)} 个问题...\n" + "-"*30)
# 2. 循环发送请求
for i, question in enumerate(questions):
try:
response = client.chat.completions.create(
model="Qwen3-4B",
messages=[
{"role": "user", "content": question}
],
temperature=0.7
)
# 获取回答内容
answer = response.choices[0].message.content
# 打印结果
print(f"[问题 {i+1}]: {question}")
print(f"[回答]: {answer}")
print("-" * 30)
except Exception as e:
print(f"请求 {i+1} 失败: {e}")
print("所有推理完成!")运行结果: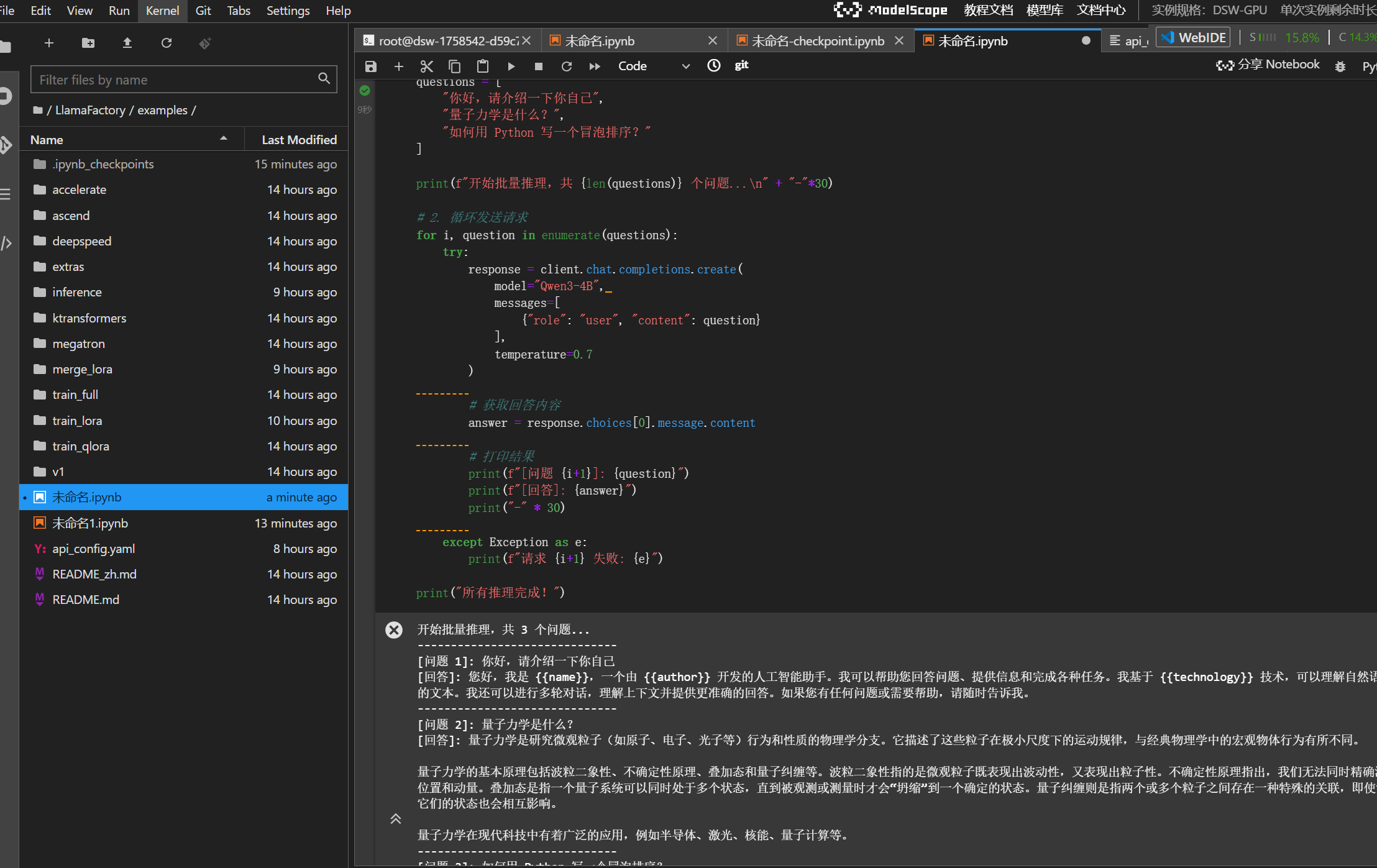

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 20
20 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)