机器学习回归与分类任务中常用的损失函数
在机器学习中,使用回归(Regression)和分类(Classification)任务使用的损失函数是不一样的,它们的本质区别在于:
回归预测的是连续值; 分类预测的是离散类别/概率。
下面我将详细介绍一下回归与分类任务经常用到的损失函数以及在sklearn中表示什么。
一、回归任务常用的损失函数
均方误差(MSE);绝对误差(MAE);Huber Loss。
首先是均方误差(MSE,Mean Squared Error):
作用:
计算预测值与真实值之间的平方平均值,适用于回归问题。
公式: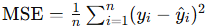
均方误差优缺点:
优点:光滑、易于求导(最常用)。
缺点: 对大误差/异常值非常敏感(平方);鲁棒性差。
(怎么理解大误差非常敏感?因为它会平方,当数据都为1,但其中一个为100,当他们开方后数据为1的还是1,但数据为100的则变成了10000!这个差距是非常巨大的!所以他对异常值很敏感。)
简单补充一个知识点,均方根误差(RMSE),就是均方误差开根号。
公式:![]()
在sklearn中的表示方式:
from sklearn.metrics import mean_squared_error其次是绝对误差(MAE,Mean Absolute Error):
作用:
计算预测值与真实值之间的差的绝对值。
公式: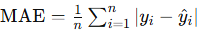
绝对误差的优缺点:
优点:鲁棒性较强。 缺点:在零点处不可导。
(什么是鲁棒性?就是模型在遇到比较差的数据时不容易被带偏,抗干扰能力强)
在sklearn中的表示方式:
from sklearn.metrics import mean_absolute_error最后是Huber Loss:
作用:
就是结合了MSE和MAE的优点(取其精华,去其糟粕),当误差小的时候采用MSE,当误差大的时候采用MAE。
详细解释:
当我们的误差很小时,就用MSE,因为在误差很小时采用MSE在零点处是可导的,并且也不会受到异常值的干扰,方便优化(梯度稳定);
当我们的误差很大时,就用MAE,因为MAE的鲁棒性很好,不会受到异常值的太大干扰,而MSE易受到异常值的干扰。
在sklearn中的表示方式:
from sklearn.linear_model import HuberRegressorMSE、MAE、Huber Loss的图像形式:
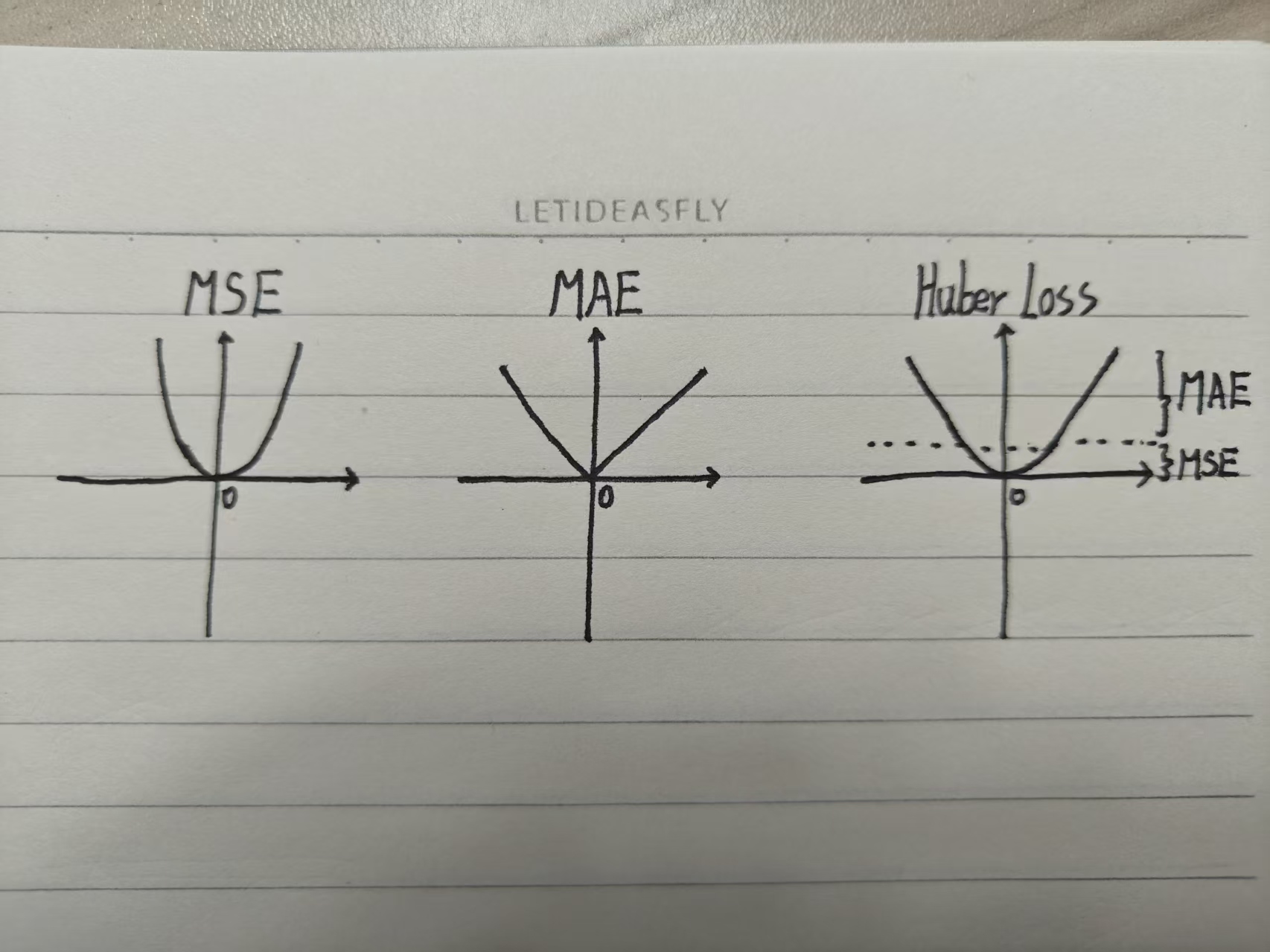
分析:(抱歉我忘记表示横纵轴了。横轴是误差(error),纵轴是损失(loss))
先看MSE,越靠近零点证明误差越小,图像越圆润,随着误差越来越大,损失呈现指数级增长,所以说MSE太容易收到大误差的干扰了;
再来看MAE,V字型,并且呈现线性增长,不会像MSE那样误差越大损失呈现指数级增长,但是缺点就是在零点处是不可导的;
最后看Huber Loss,很明显采用了MSE和MAE的优点,在误差小的地方采用了MSE优点,在误差大的地方采用了MAE的优点,所以Huber Loss还是很常用的。
以上就是我们在机器学习中用于回归任务常用的损失函数了。接下来就是机器学习中用于分类任务常用的损失函数了。
二、分类任务常用的损失函数
0-1损失、对数似然损失、合页损失、交叉熵损失。
0-1损失:
很简单,顾名思义就是当预测对的时候为0,预测错了就为1。本质是只看对错,不看“差了多少”。
问题:
不可导还不能优化,所以只用于评估,不用来优化。
在sklearn中的表示方式:
from sklearn.metrics import Zero_one_loss对数似然损失(Logistic Loss):
用于逻辑回归,适合二分类问题。本质就是最大似然。
(逻辑回归?回归?那是不是应该是回归任务?为什么是分类任务?这就要注意了,名字虽然带着回归,但他其实是分类任务,这一点要注意。)
预测概率越接近真实,损失越小;预测很自信但是错了,狠狠惩罚!
特点:
非常平滑(好优化);对“错误的自信预测”惩罚极大。
在sklearn中的表示方式:
from sklearn.metrics import log_loss合页损失(Hinge Loss)[支持向量机(SVM)核心]:
分对了还不够,还要“分的足够远”,即不仅分类要正确,还要有间隔(margin)。
公式:L = max(0, 1-y*f(x))
特点:
用于最大间隔分类(SVM很需要);只关注“边界附近的点”。
在sklearn中的表示方式:
from sklearn.metrics import hinge_loss交叉熵损失(Cross Entropy)[最常用]:
本质就是交叉熵 = 对数似然损失(本质一样),多用于多分类问题。
多分类问题公式:![]() 真实类别概率越高,损失越小,这句话是不是很熟悉?对吧,嗯对的对的。
真实类别概率越高,损失越小,这句话是不是很熟悉?对吧,嗯对的对的。
在sklearn中的表示方式:
很奇怪,交叉熵的表示方式不是应该是Cross_Entropy吗,为什么是LogisticRefression呢?诶!对的对的,因为它本质上就是对数似然损失。
from sklearn.linear_model import LogisticRegression以上就是对于分类任务中常用的损失函数了。
……
……
……
还没完。
接下来重点介绍一下决定系数R**2(Coefficient of determination)。它属于回归任务。
为什么要单独列出来呢,因为不太好理解,并且它还有衍生物以及他用到的地方也蛮多。
三、决定系数R**2
R**2用来衡量“模型对连续数值的拟合好坏”。核心思想就是“预测值和真实值之间的“解释程度””。
公式:
![]() 分子:残差平方和(模型误差);分母:总方差(数据本身波动)。
分子:残差平方和(模型误差);分母:总方差(数据本身波动)。
如果模型很好的话,误差远小于数据本身波动,那么R**2接近1。偷个懒:

R**2的局限:
1.不能比较不同的数据集;
2.会“虚高”:加特征后:R**2只会变大,不会变小,所以就出现了衍生物,调整后的R**2(Adjusted R**2,后续会讲到)。
在sklearn中的表示方式:
from sklearn.metrics import r2_scoreR**2总结:
决定系数R**2用来衡量回归模型对数据变异的解释能力,其值越接近1,表示模型的拟合越好,越接近零,表示与简单平均预测效果相当,小于零则说明模型表现很差,还不如瞎猜呢,选择单选题蒙对也有25%概率,甚至比25%还低,蒙的都比模型对的多。
四、Adjusted R**2
此物为决定系数的衍生物,它用来做什么?
R**2,我们在给它添加特征后它的值一定会变大,没错就是一定会变大。哪怕是垃圾特征给了它,它的值也会变大,那我加的这个特征还有什么意义呢?我要这个垃圾特征有什么用?浪费空间还增加模型的计算时间。此时,Adjusted R**2就出现了!它的目的就是在添加新特征时,它会判断一下这个特征加了之后有没有用?是否值得添加?如果没用就直接惩罚,或者提升不明显,直接惩罚,值下降。
核心思想: 给“多加的特征”收税。
在图像中,R**2只会上升,而Adjusted R**2是先上升再下降。
那什么时候用到Adjusted R**2呢?
多特征回归/特征选择。比如比较两个模型谁更好;判断要不要加新特征。
总结:
Adjusted R**2 在R**2的基础上引入了对特征数量的惩罚,用于避免因增加无关特征导致的拟合优度“虚高”,是评估多元回归模型更可靠的指标。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 19
19 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)