VLA-Touch: Enhancing Vision-Language-Action Models with Dual-Level Tactile Feedback(触觉与VLA)
论文:https://arxiv.org/abs/2507.17294
Github:https://github.com/jxbi1010/VLA-Touch
目前在使用触觉传感器时,只是将触觉传感器的图像信息作为一个模态输入给模型进行训练,这篇文章提供了一个新的思路。
把触觉的信息引入到了高层任务规划阶段中,即将触觉图像类的传感器数据转化为物理物体属性,如硬度和纹理的语言描述,从而向任务规划器VLM来提供触觉反馈。而VTLA还只是在底层控制阶段来引入的触觉信息模态的融合。
VLA-Touch 是一种无需微调基础 VLA 模型、通过双层级触觉反馈增强视觉 - 语言 - 动作模型的机器人操控框架,核心包含触觉 - 语言模型辅助高层任务规划与基于插值扩散的控制器优化底层动作执行两大创新,在杯子搬运、擦拭、芒果削皮三类高接触实操任务中,使规划效率最高提升40%、操控成功率最高提升35%,双层级融合效果显著优于单层级触觉反馈。
目录
1.文章速览
2.核心框架
Octopi:专门针对只有GelSight 触觉传感器与训练的触觉语言模型。
3.内容
现有视觉-语言-动作(VLA)模型仅依赖视觉与本体感觉,无法处理高接触操控任务中视觉难以感知的硬度、粗糙度、接触力等信息,且直接将触觉融入大模型面临无多模态数据集、基础模型无触觉输入机制两大难题。
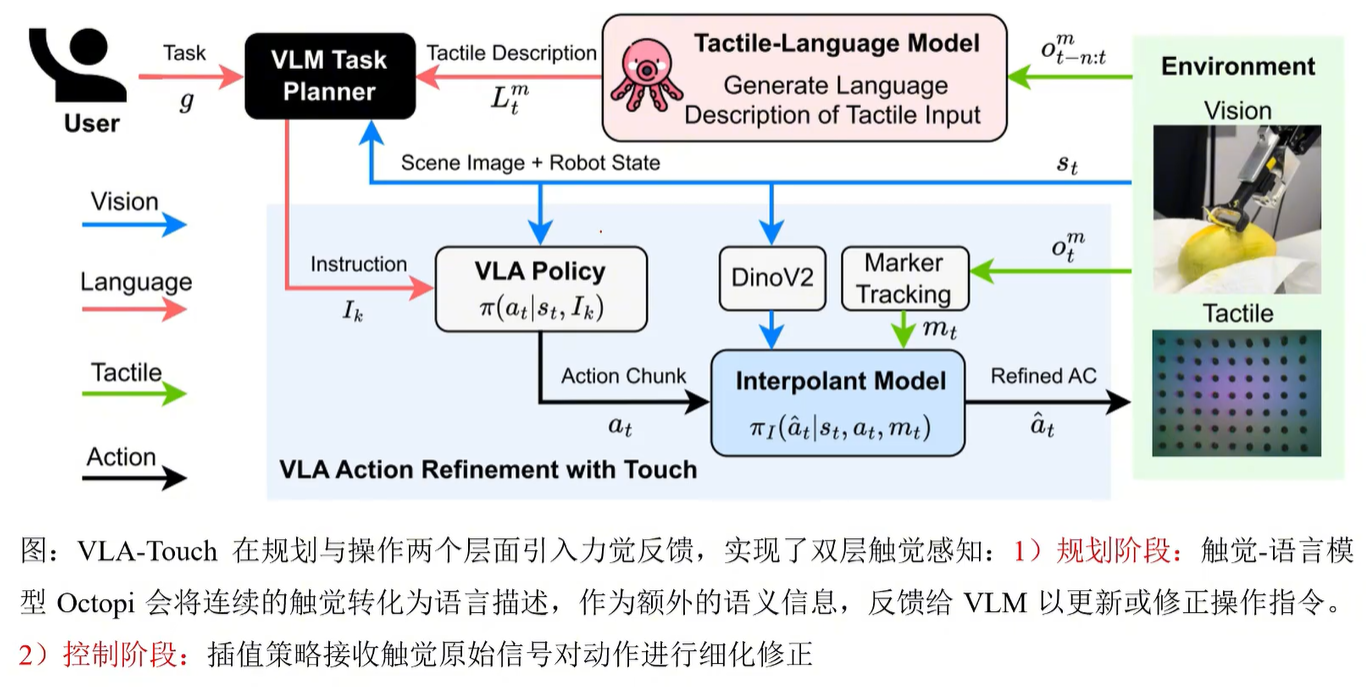
3.1 核心方案:VLA-Touch双层级框架
(1)高层级:触觉辅助任务规划
- 采用GPT-4o作为视觉-语言任务规划器,结合场景图像与任务目标生成操控指令
- 引入Octopi触觉-语言预训练模型,将触觉信号转为语言化描述(硬度、粗糙度),辅助循环更新规划
- 优势:无需改造VLA模型,规划效率最高提升40%
(2)低层级:触觉增强动作优化
- 以RDT-1B为基础VLA策略生成原始动作块
- 采用BRIDGeR插值扩散控制器,融合视觉嵌入(DinoV2)与低维触觉力信号,精炼动作序列
- 推理策略:滑动窗口逐段优化动作,执行频率8Hz
3.2 实验设计
(1)硬件平台
Franka Emika Panda机械臂、Robotiq 2F-140夹爪、GelSight Mini触觉传感器、双RealSense相机、RTX 4090 GPU
(2)评测任务
- 杯子:判断是否有水并放置防洒
- 擦拭:选择更光滑海绵擦净盘子
- 削皮:触摸判断芒果软硬并削皮
(3)对比基线
- 规划:纯GPT-4o、GPT-4o+原始触觉图、GPT-4o+Octopi
- 操控:纯RDT、RDT+残差控制器、RDT+插值控制器
- 融合:无规划触觉、无控制触觉、双层级VLA-Touch
3.3 实验结果
(1)任务规划效果
| 规划输入方式 | 力预测成功率 | 硬度预测成功率 |
|---|---|---|
| 无触觉 | 0% | 0% |
| 原始触觉图 | 50% | 60% |
| Octopi语言化触觉 | 90% | 75% |
(2)操控执行效果
插值控制器相较基础RDT,任务成功率提升:杯子42%、擦拭140%、削皮67%;相较残差控制器分别提升67%、100%、42%。
(3)双层级融合效果
| 任务 | 无规划触觉 | 无控制触觉 | VLA-Touch(双层级) |
|---|---|---|---|
| 杯子 | 5/20 | 6/20 | 9/20 |
| 擦拭 | 5/20 | 5/20 | 12/20 |
| 削皮 | 6/20 | 4/20 | 7/20 |
| 双层级系统任务成功率较单层级最高提升35%。 |
(4)模态消融
移除触觉反馈使高接触阶段成功率下降42%-50%;移除视觉反馈使空间定位精度下降,验证视觉-触觉融合必要性。
3.4 总结
(1)结论
双层级触觉反馈可同时提升VLA模型的规划效率与操控精度,语言化触觉表示更适配VLM,插值扩散控制器优于传统残差控制器。
(2)局限
- 触觉传感器与Octopi训练数据不匹配,影响硬度判断
- 泛化性仅验证位置与目标变化
- 控制器仅8Hz,未利用≥25Hz高频触觉信号
(3)未来方向
- 视觉-触觉融合主动抓取框架
- 事件触发式触觉推理
- 任务无关的通用策略优化方法
4.创新点
-
问题1:VLA-Touch为何选择双层级触觉反馈,而非仅在规划或控制层加入触觉?
答案:单一层级触觉反馈存在明显缺陷,高层触觉反馈解决视觉模糊下的物体属性推理(如软硬、粗糙),底层触觉反馈保障精准接触操控(如握力、持续接触);实验证明双层级融合任务成功率较单层级最高提升35%,缺一不可。 -
问题2:VLA-Touch为何使用触觉-语言模型而非直接输入原始触觉图像给VLM?
答案:原始触觉图像难以被通用VLM有效理解,力预测仅50%、硬度预测60%;经Octopi转为语言化结构化描述后,力预测达90%、硬度预测达75%,语言表示更适配VLM的推理范式。 -
问题3:VLA-Touch的插值扩散控制器相比传统残差控制器优势是什么?
答案:插值控制器以VLA生成动作为起点而非高斯噪声,能更好捕捉多模态动作分布;在杯子、擦拭、削皮任务中,成功率较残差控制器分别高67%、100%、42%,接触保持与操控稳定性更优。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)