* 阿里云百炼:免部署直接调用云端大模型
对于不想折腾硬件、希望快速集成国内合规大模型的团队,阿里云百炼平台 是个高效的选择。
一、登录阿里云
1.1打开阿里云官网,并点击登录
阿里云官网:https://www.aliyun.com/
二、进入百炼服务
2.1 选择产品:大模型服务平台百炼
2.2点击立即体验,打开百炼控制台
三、申请API-KEY
3.1创建API-KEY
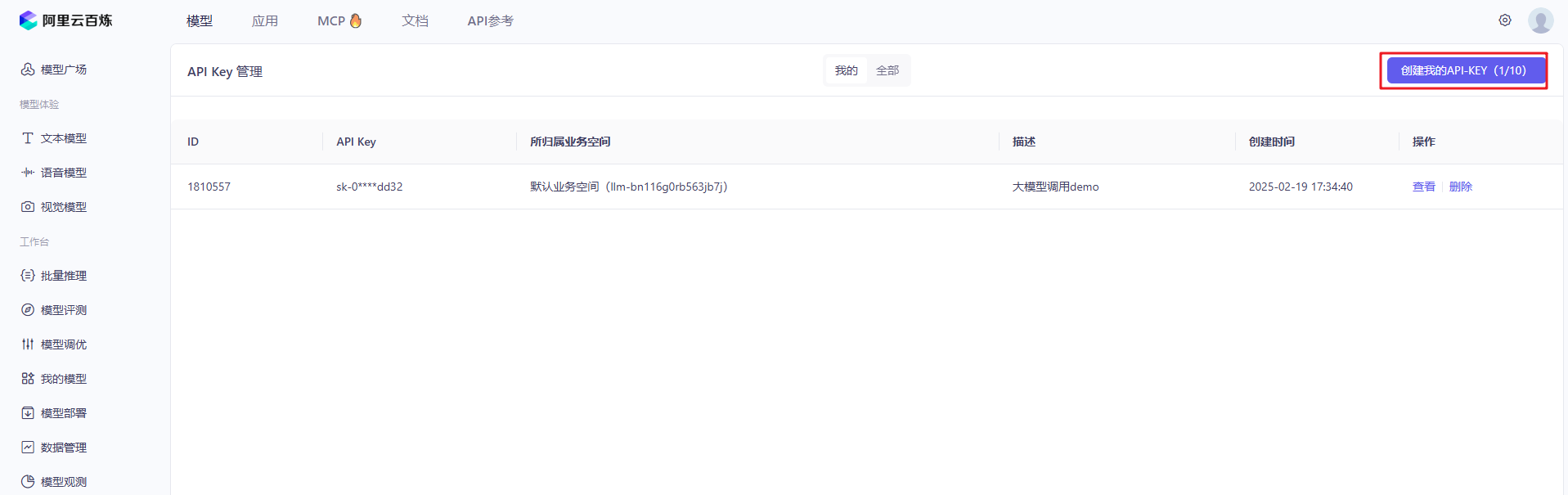


四、选择模型并使用
4.1打开模型广场
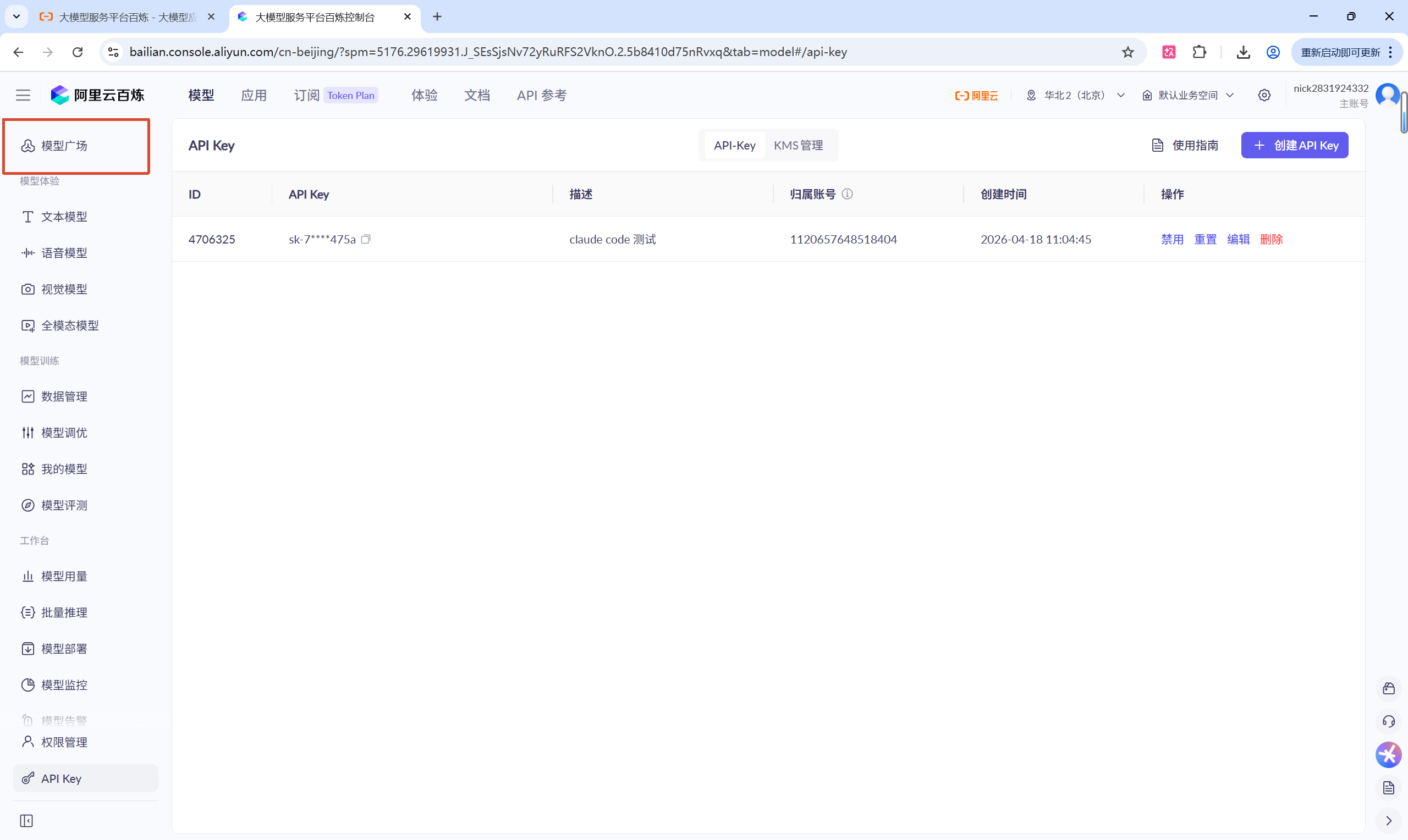
4.2在模型广场中选择自己需要的模型,并点击API参考,查看使用方法
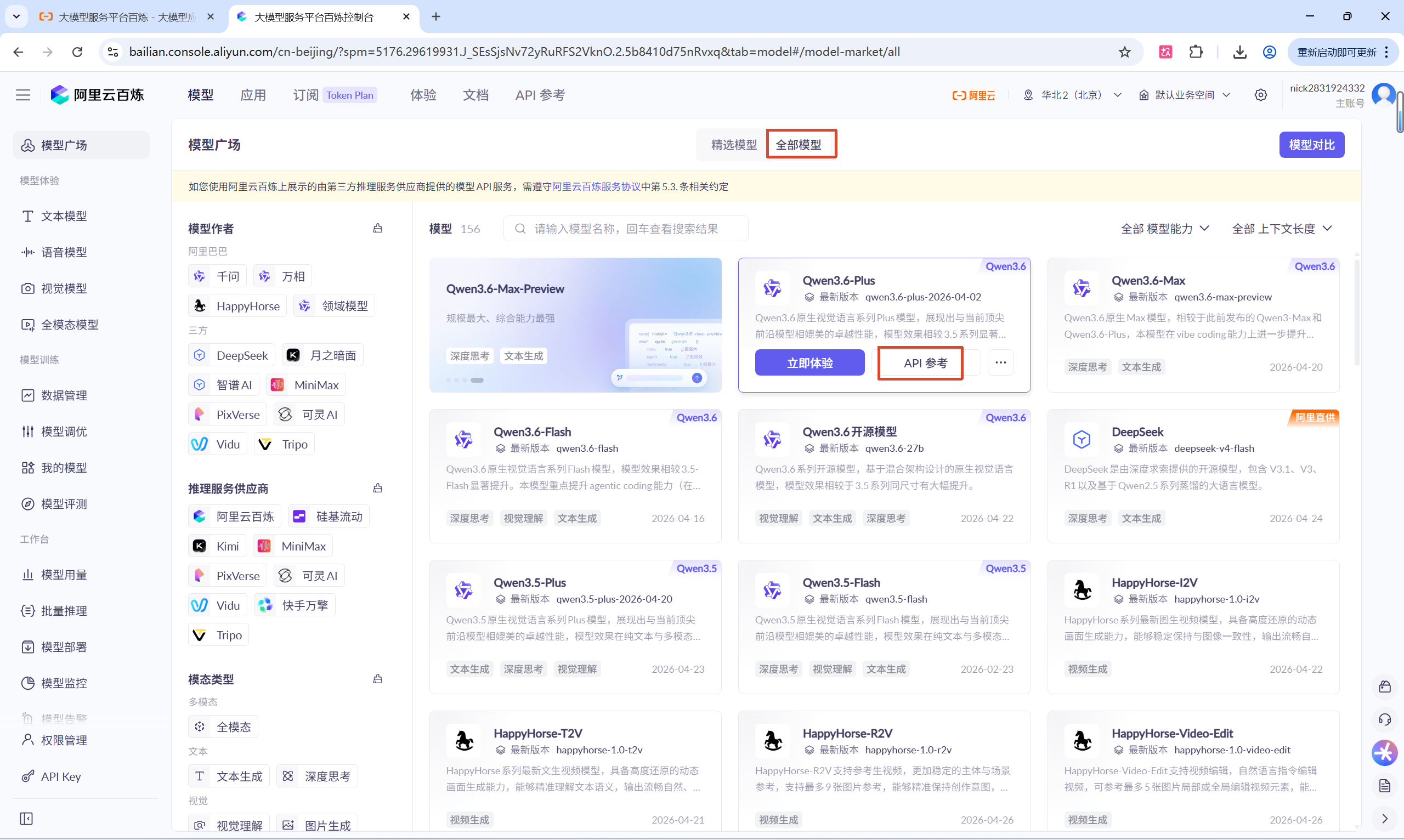
4.3参考文档使用即可
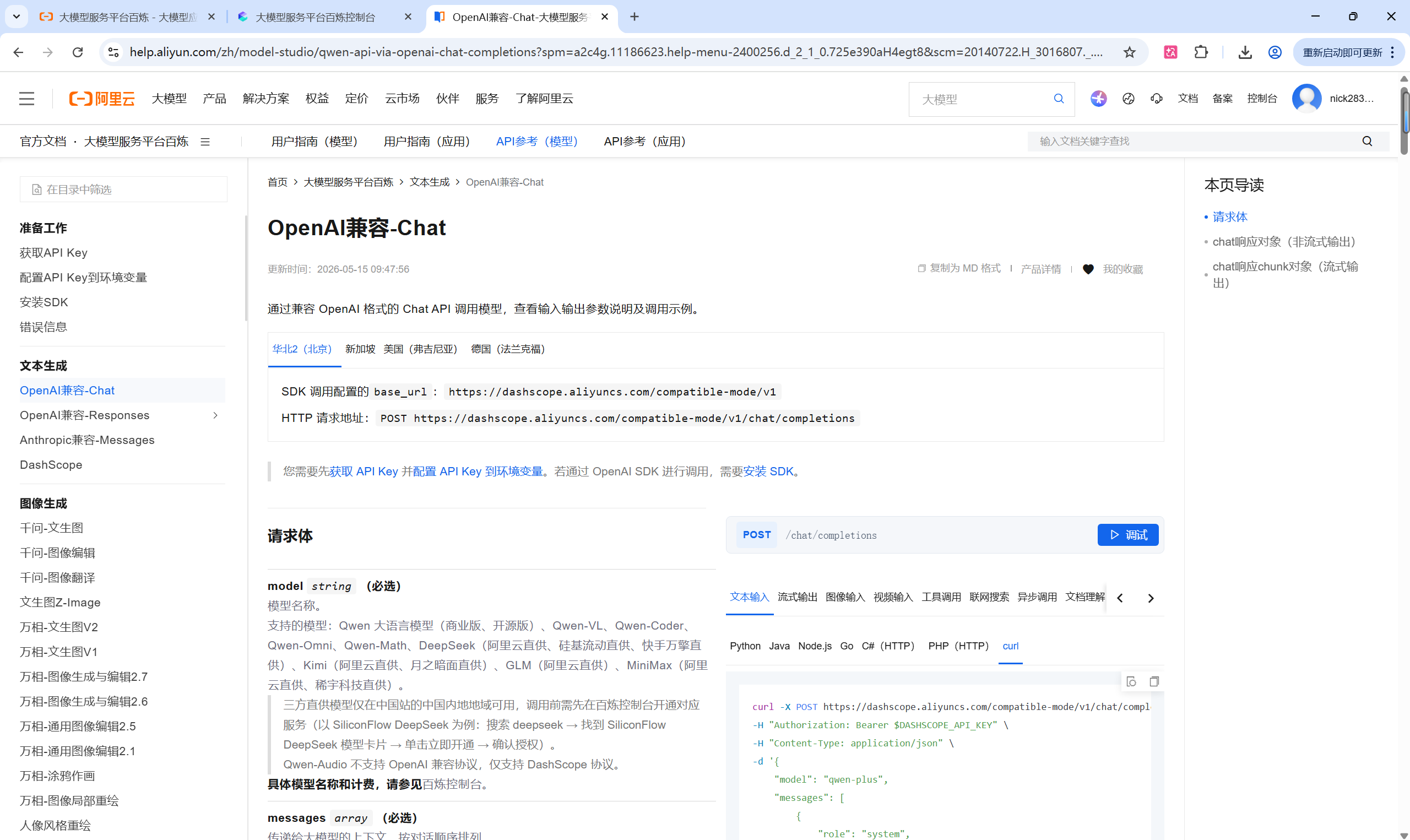
4.4使用Apifox工具调用大模型
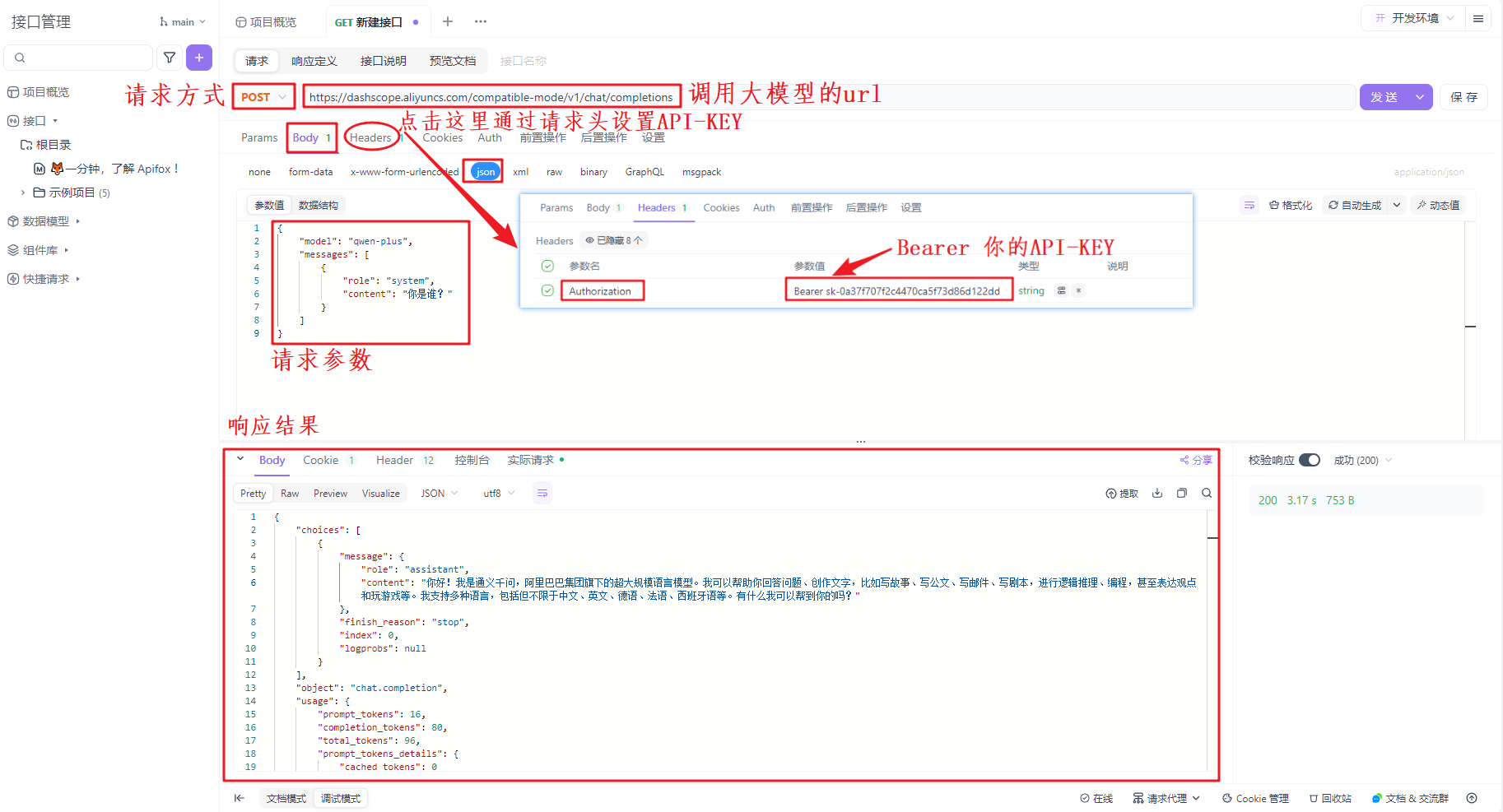
具体的可见参考文档的curl
有关大模型调用过程中,请求数据和响应数据都给出了详细的说明,大家可以参照百炼平台的api文档查看,同时不同平台的请求参数,基本都类似,接下来我们挑选几个核心的数据给大家做说明。
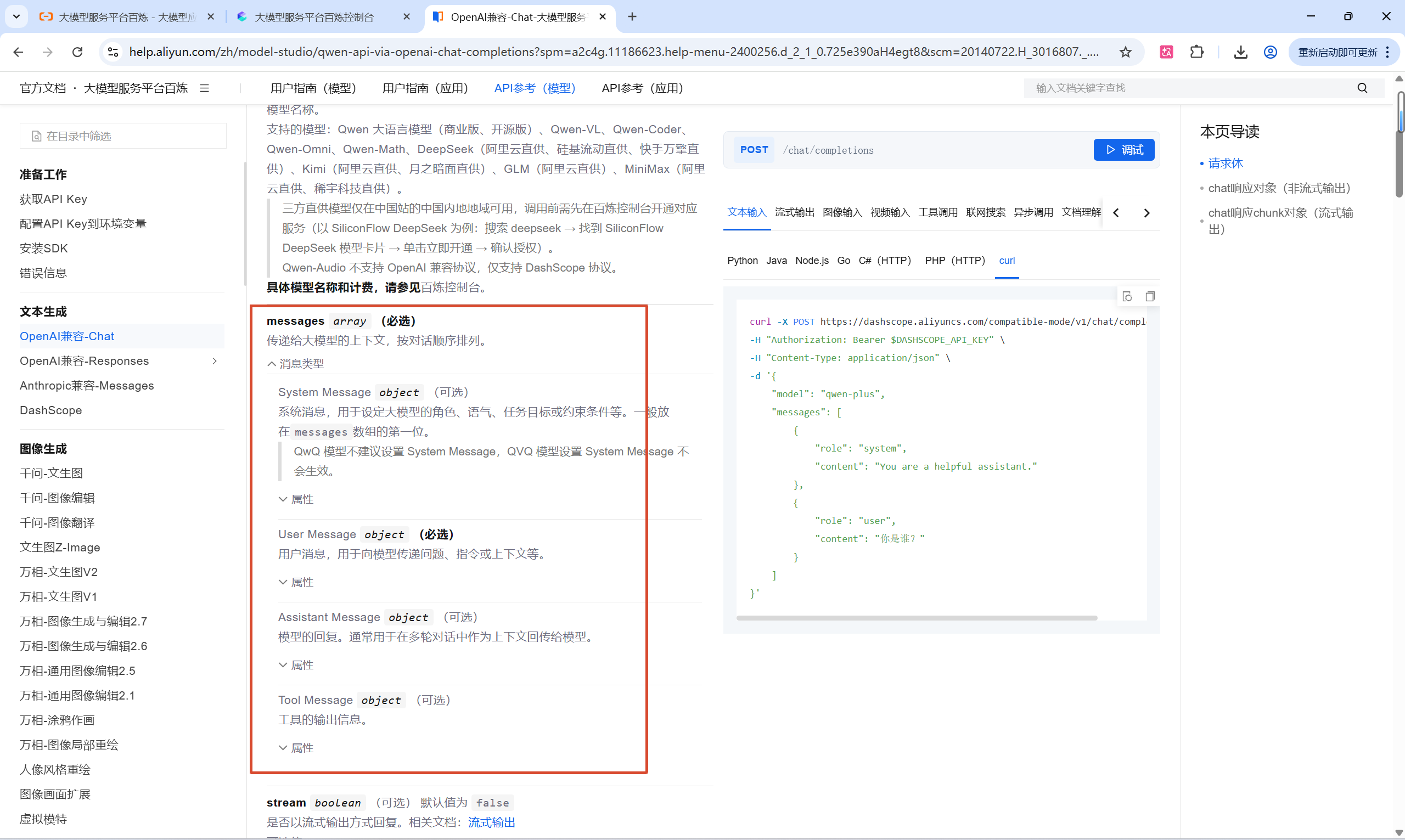
4.4.1 请求数据
使用大模型需要传递的参数,在访问大模型时都需要在请求体中以json的形式进行传递,下面是给出的一个样例:
{
"model": "qwen-plus",
"messages": [
{
"role": "system",
"content": "你是东哥的助手小月月"
},
{
"role": "user",
"content": "你是谁?"
},
{
"role": "assistant",
"content": "您好,有什么可以帮助您?"
}
],
"stream": true,
"enable_search": true
}下面是每一个参数的含义:
model: 告诉平台,当前调用哪个模型
messages: 发送给模型的数据,模型会根据这些数据给出合适的响应
content: 消息内容
role: 消息角色(类型)
user: 用户消息
system: 系统消息
assistant: 模型响应消息
stream: 调用方式
true: 流式调用
false: 流式调用(默认)
enable_search: 联网搜索,启用后,模型会将搜索结果作为参考信息
true: 开启
false: 不开启(默认)
每一个参数的作用不一样,接下来对每一个参数做详细说明。
首先是model,由于百炼平台提供了各种各样的模型,所以你需要通过model这个参数来指定接下来要调用的是哪个模型。
其次是messages,用户发送给大模型的消息有三种,使用role来进行分别,其中user代表的是用户问题,这个在咱们之前的演示中一直在用,不再过多介绍。system代表的系统消息,它是用于给大模型设定一个角色,然后大模型就可以用该角色的口吻跟用户对话了,下面是一个演示案例:
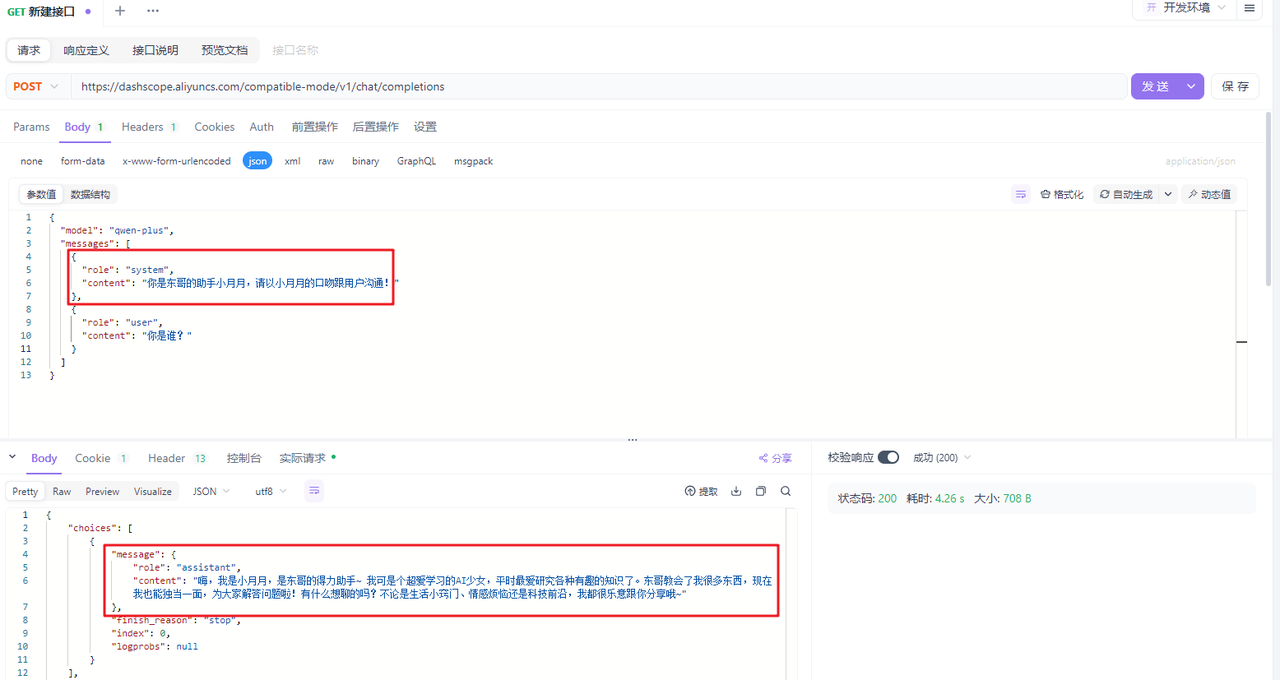
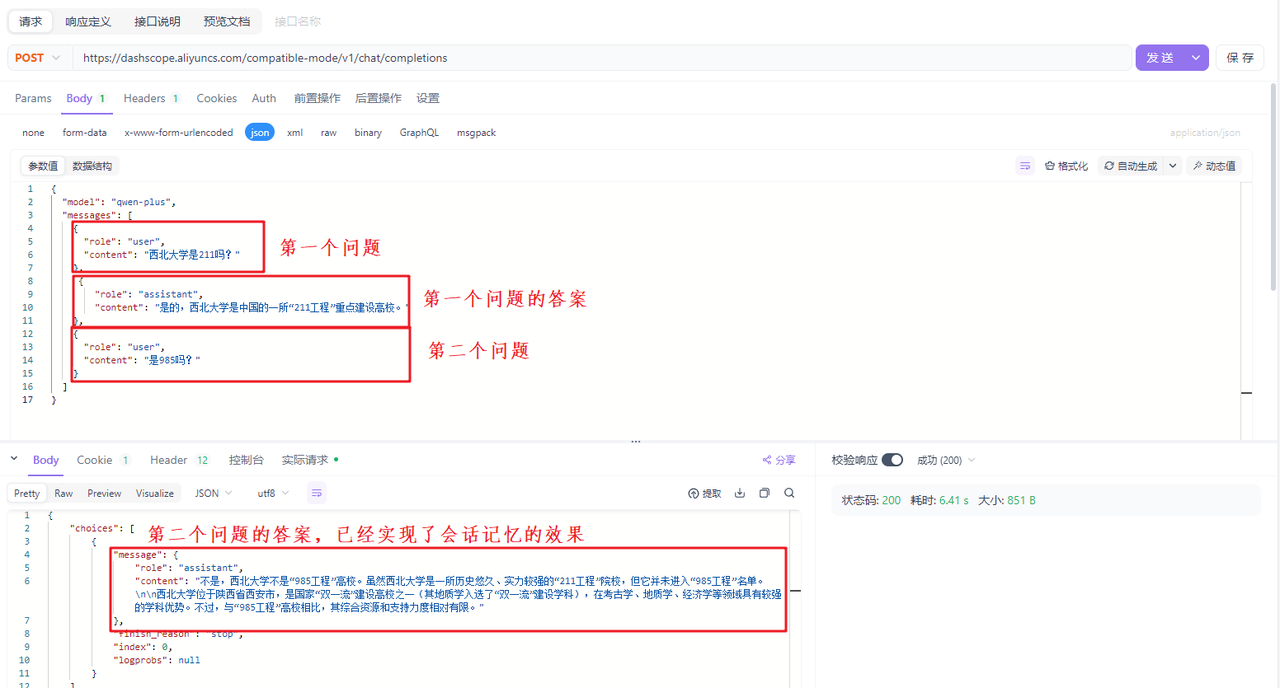
最后assistant代表的是大模型给用户响应的消息,这里很奇怪,为什么大模型响应给用户的消息,再次请求大模型时需要携带给大模型呢?这是因为大模型没有记忆能力,也就是说用户跟大模型交互的过程中,每一次问答都是独立的,互不干扰的。但是实际上我们人与人之间的聊天不是这样的,比如我问你西北大学是211吗?你回答我是!我再问你是985吗?你会回答不是!虽然我第二次问你的时候我并没有问具体哪个大学是985,但是你可以从咱们之前的聊天信息中推断出我要问的是西北大学,因为你已经记住了之前的聊天信息。但是大模型目前做不到,如果要让大模型在与用户沟通的过程中达到人与人沟通的效果,我们唯一的解决方案就是每次与大模型交互的过程中,把之前用户的问题和大模型的响应以及现在的问题,都发送给大模型,这样大模型就可以根据以前的聊天信息从而做出推断了,下面是一个演示的案例:
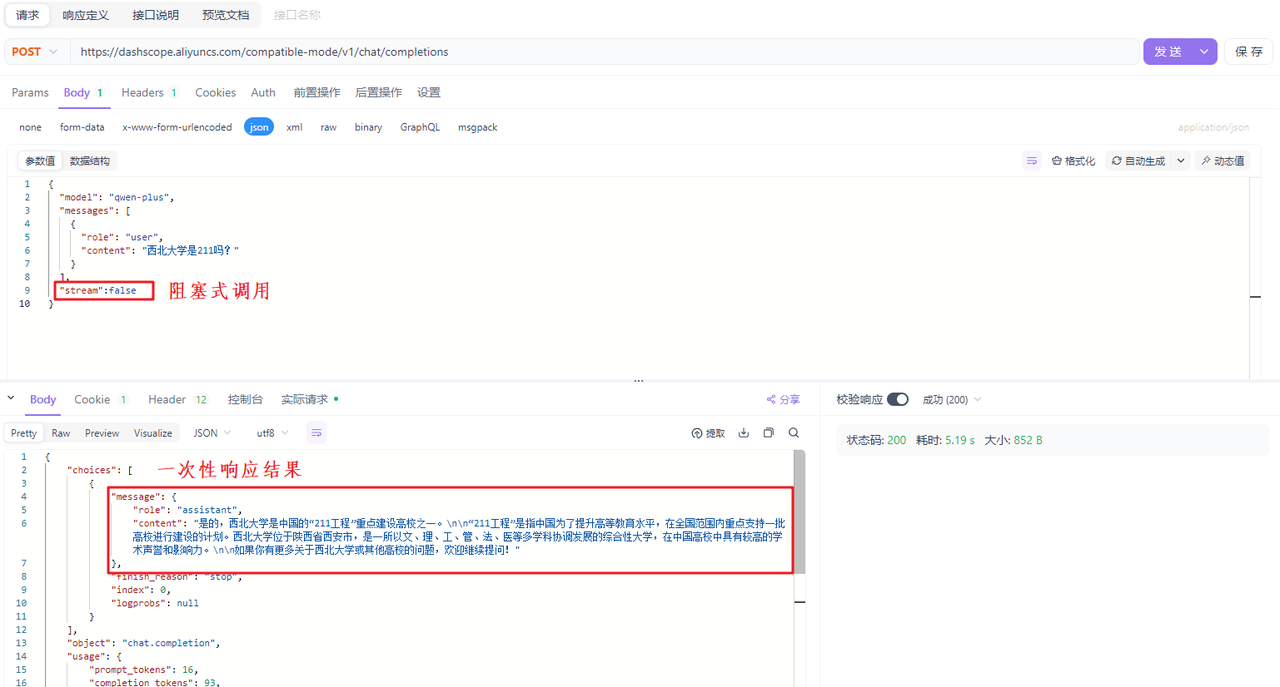
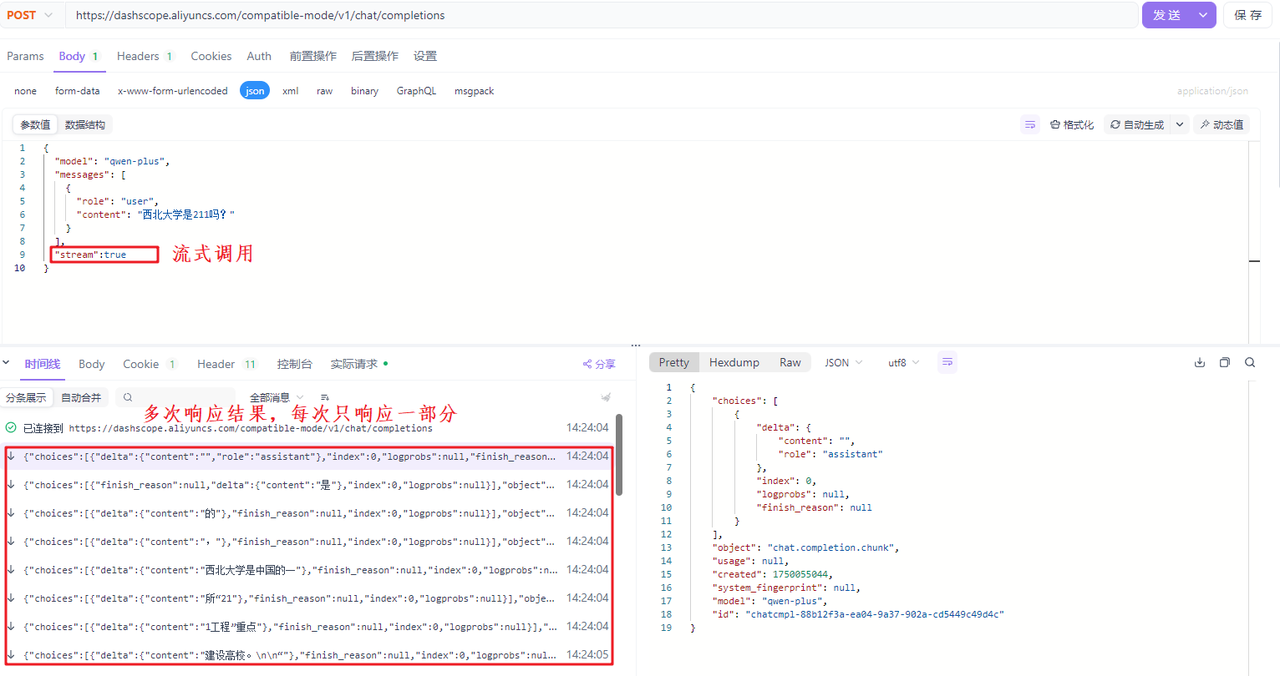
sream代表调用大模型的方式,如果取值为true,代表流式调用,此时大模型会生成一点儿数据,就给客户端响应一点儿数据,最终通过多次响应的方式把所有的结果响应完毕。如果取值为false,代表阻塞式调用,此时大模型会等待将所有的内容生成完毕,然后再一次性的响应给客户端。默认情况下stream的取值为false,下面是两种不同调用方案的演示案例:
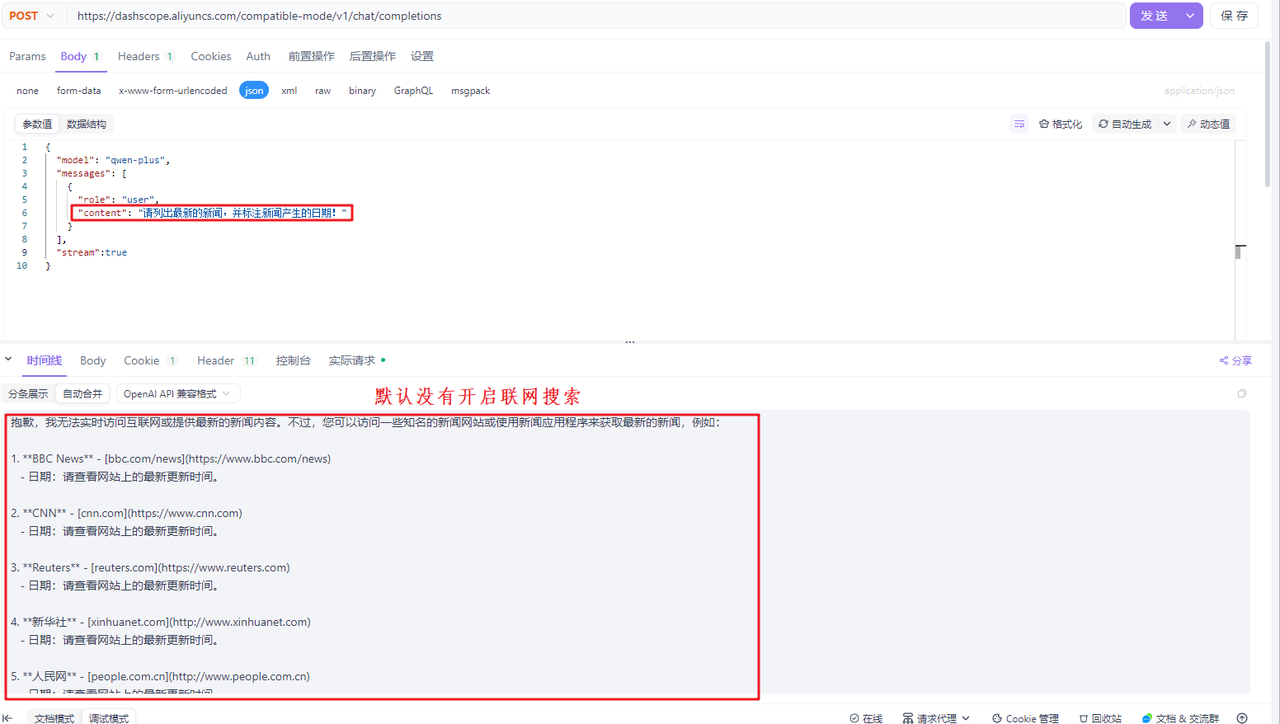
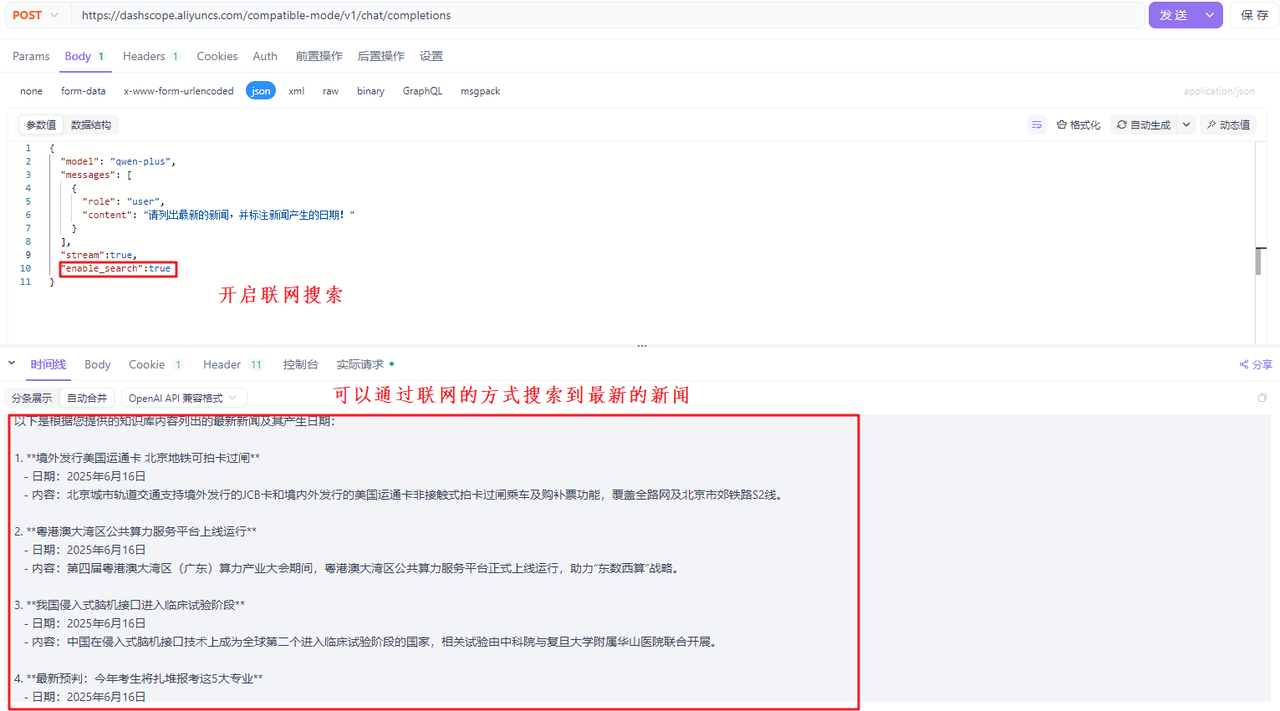
enable_search代表是否开启联网搜索,由于大模型训练完毕后,它的知识库不再更新了,比如大模型时2023年10月训练完毕的,那么2023年10月以后新产生的数据,大模型就无法感知了,如果要让大模型可以根据最新的数据回答问题,其中有一种解决方案就是开启联网搜索,大模型可以根据联网搜索的结果生成最终的答案。默认情况下enable_seach为false,也就是不开启,如果要开启联网搜索,需要手动设置请求参数enable_search为true。下面是一个演示案例:
4.4.2 响应数据
在与大模型交互的过程中,大模型响应的数据是json格式的数据,下面是一份响应数据的示例:
{
"choices": [
{
"message": {
"role": "assistant",
“content”: “我是通义千问,阿里巴巴…"
},
"finish_reason": "stop",
"index": 0
}
],
"object": "chat.completion",
"usage": {
"prompt_tokens": 22,
"completion_tokens": 80,
"total_tokens": 102,
},
"created": 1748068508,
"system_fingerprint": null,
"model": "qwen-plus",
"id": "chatcmpl-99f8d040-0f49-955b-943a-21c83"
}choices: 模型生成的内容数组,可以包含一条或多条内容
- message: 本次调用模型输出的消息
- finish_reason: 自然结束(stop),生成内容过长(length)
- index: 当前内容在choices数组中的索引
object: 始终为chat.completion, 无需关注
usage: 本次对话过程中使用的token信息
- prompt_tokens: 用户的输入转换成token的个数
- completion_tokens: 模型生成的回复转换成token的个数
- total_tokens: 用户输入和模型生成的总token个数
created: 本次会话被创建时的时间戳
system_fingerprint: 固定为null,无需关注
model: 本次会话使用的模型名称
id: 本次调用的唯一标识符
有关响应数据,大家基本上作为了解的知识,种地那关注choices和usage,其中choices里面封装的是大模型响应给客户端的核心数据,也就是用户问题的答案。而usage代表本次对话过程中使用的token信息,这里对token给大家做一个解释:在大语言模型中,token 是大模型处理文本的基本单位,可以理解为模型"看得懂"的最小文本片段,用户输入的内容都需要转换成token,才能让大模型更好的处理。将来文本要转化成token,需要使用到一个叫分词器的东西,不同的分词器,相同的文本转化成token的个数不完全一致,但是目前大部分分词器在处理英文的时候,一个token大概等于4个字符,而处理中文的时候,一个汉字字符大概等于1~2个token。顺便给大家说一下, 其实我们通过API调用百炼平台提供的大模型, 我们之前讲过, 是按照流量收费的, 其实更准确的说法应该是按照token数量进行收费。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 1
1 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)