深入研究RAG:总体流程与文档解析
目录
3.1.2 解析 vs 分片 (Parsing vs Chunking)
3.2.3.3 通用解析器 (TikaDocumentReader)
3.3.2 痛点二:表格解析 (Table Parsing)
3.3.3 痛点三:多栏排版 (Multi-column Layout)
前言
大家好,这里是程序员阿亮
众所周知,RAG是我们给LLM提供额外信息的一门技术,通过RAG我们可以提前封装好一系列的数据,如企业内部文档、额外的数据,让我们的Prompt在发送给LLM之前,检索出相关的数据,一起发送给LLM,去降低LLM响应的幻觉,提高准确率。
那么实际开发中我们RAG要考虑哪些部分呢,今天我来给大家深入研究一波~
本次博客会以SpringAI为例子来解释,实际上不管是langchain4j、SpringAI他们的内容都是差不多的,了解其中一个框架去学其他框架也是很快的!
一、为什么需要RAG?

所谓大模型,我们可以认为是一个大脑,但是,这个大脑其实并不是无所不知的,我们需要给这个大脑去提供一些它不知道的知识,这就是为什么我们需要RAG。
把 LLM 比作"大脑",把知识库比作"外部记忆"
那么传统 LLM: 只靠大脑里的记忆回答问题
如果加上RAG,就可以 先查外部记忆,再结合大脑回答问题 ,这样可以很明显降低我们大模型的幻觉,提高大模型的知识能力。
二、RAG全称?
RAG 的全称解释
|
英文 |
中文 |
含义 |
|---|---|---|
|
Retrieval |
检索 |
从知识库中查找相关信息 |
|
Augmented |
增强 |
用查找到的信息增强输入 |
|
Generation |
生成 |
LLM 基于增强后的信息生成答案 |
三、自顶向下解释之:RAG总体流程
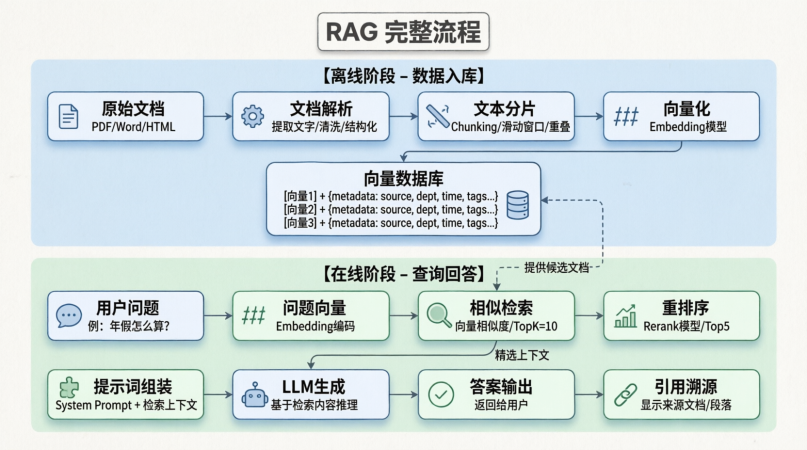
上面的图涵盖的RAG的总体流程,那么接下来我就带大家详解一波RAG的每个流程
3.1 文档解析
在 RAG 流程中,文档解析 (Parsing) 是最容易被忽视,但决定生死的一环。 "Garbage In, Garbage Out" (垃圾进,垃圾出) 是 RAG 的第一定律。如果你的解析器把表格弄乱了、把页眉页脚当成了正文、或者把扫描版 PDF 当成了空文件,那么后续的 Embedding 和检索再先进也无济于事。
3.1.1 什么是文档解析?
将非结构化或半结构化的原始文件(PDF, Word, HTML 等),转换为 RAG 系统可处理的 纯文本 (Text) + 元数据 (Metadata) 的过程。
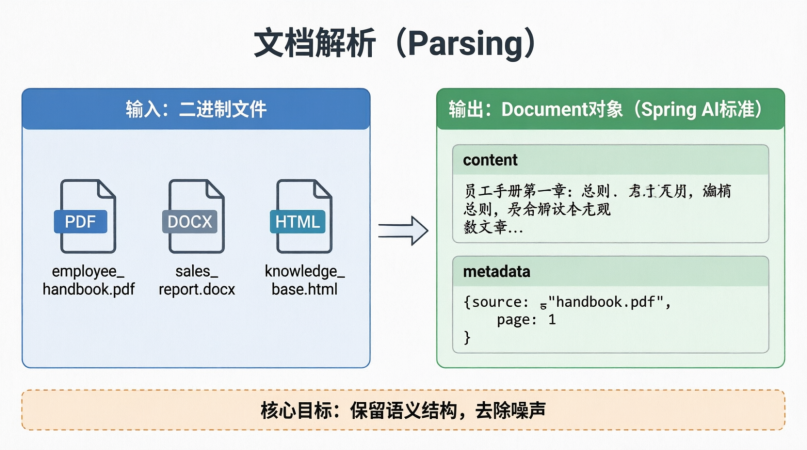
以SpringAI为例子,我们文档解析会把二进制文件如pdf、word等转换为一个Document对象,对象的字段有metadata、content,其中metadata就是我们内容的元数据。
比如说content的source(来源)、page等。
3.1.2 解析 vs 分片 (Parsing vs Chunking)
这是两个最容易混淆的概念,必须区分开:
|
环节 |
英文 |
输入 |
输出 |
目的 |
|---|---|---|---|---|
|
解析 |
Parsing |
原始文件 (PDF/Word) |
完整文本 + 元数据 |
把文件变成文字 |
|
分片 |
Chunking |
完整文本 |
文本片段 (Chunks) |
把长文切成小块以便检索 |
顺序:先 解析 (Parsing) -> 后 分片 (Chunking)。
3.1.3 解析的三大挑战
- 格式多样性:PDF 有文字版和扫描版,Word 有样式,HTML 有标签。
- 布局复杂性:多栏排版(如论文)、表格、页眉页脚、页码。
- 内容噪声:乱码、特殊符号、无关的版权声明。
3.2 SpringAI中的文件解析
浅浅讲解一下SpringAI处理文档的API
Spring AI 定义了统一的接口 DocumentReader,屏蔽了不同文件类型的差异。
3.2.1 核心接口:DocumentReader
public interface DocumentReader {
/**
* 读取文档并返回 Document 列表
* 通常一个文件会被解析为一个或多个 Document 对象
*/
List<Document> get();
}- 返回类型
List<Document>:为什么是列表?因为一个 PDF 可能有 100 页,解析器可能按页返回 100 个 Document,也可能合并为 1 个。 Document类:Spring AI 的标准数据载体。
public class Document {
private String id; // 唯一 ID
private String content; // 核心:解析出的文本
private Map<String, Object> metadata; // 核心:来源、页码等
}3.2.2 资源抽象:Resource
Spring AI 使用 Spring 的 Resource 接口来定位文件,支持 classpath, file, url 等。
// 从类路径加载
Resource resource = new ClassPathResource("documents/manual.pdf");
// 从文件系统加载
Resource resource = new FileSystemResource("/data/docs/manual.pdf");
// 从 URL 加载
Resource resource = new UrlResource("https://example.com/manual.pdf");3.2.3 常见解析器实现
3.2.3.1 文本文件解析 (TextReader)
最简单,直接读取纯文本。
@Bean
public DocumentReader textReader(ResourceLoader loader) {
return new TextReader(loader.getResource("classpath:/data/notes.txt"));
}3.2.3.2 PDF 文件解析 (PdfReader)
注意:Spring AI 自带的 PdfReader 通常基于简单的 PDF 库(如 Apache PDFBox),只能处理文字版 PDF。
@Bean
public DocumentReader pdfReader(ResourceLoader loader) {
return new PdfReader(loader.getResource("classpath:/data/manual.pdf"));
}局限性:
- 无法处理扫描版 PDF(图片型)。
- 表格内容可能会乱序(按流式读取,而非行列)。
- 多栏排版可能会错行。
3.2.3.3 通用解析器 (TikaDocumentReader)
基于 Apache Tika,支持 1000+ 种格式(Word, PPT, Excel, PDF 等)。
@Bean
public DocumentReader tikaReader(ResourceLoader loader) {
return new TikaDocumentReader(loader.getResource("classpath:/data/report.docx"));
}优点:格式支持广,开箱即用。 缺点:对复杂布局(表格、多栏)的处理依然一般。
3.3 痛点解决方案
企业文档远比你想象的复杂。以下是真实场景中的“坑”及填坑方案。
3.3.1 痛点一:扫描版 PDF (图片型)
现象:解析后 content 为空,或者全是乱码。 原因:文件本质是图片,没有文字层。 解决方案:OCR (光学字符识别)。
方案 A: 本地 OCR (Tesseract)
- 优点:免费,数据不出域。
- 缺点:配置麻烦,中文识别率一般,速度慢。
- 集成:Spring AI 目前无内置 Tesseract Reader,需自定义实现
DocumentReader调用 Tesseract CLI 或 Java 封装。
方案 B: 云端 OCR (推荐)
- 服务商:Azure Document Intelligence, AWS Textract, Google Cloud Vision, 阿里云 OCR。
- 优点:识别率极高,能还原表格结构。
public class OcrDocumentReader implements DocumentReader {
private final Resource resource;
private final CloudOcrClient ocrClient;
public List<Document> get() {
// 1. 上传图片
// 2. 调用 OCR API
// 3. 获取识别后的文本和布局信息
String text = ocrClient.recognize(resource);
Document doc = new Document(text);
doc.getMetadata().put("type", "scanned_pdf");
return List.of(doc);
}
}3.3.2 痛点二:表格解析 (Table Parsing)
现象:表格被解析成一行乱序文字。
- 原表:
姓名
年龄
张三
18
- 解析后:
姓名 张三 年龄 18(语义丢失,LLM 无法理解对应关系)
解决方案:
- Markdown 化:将表格转换为 Markdown 格式。
| 姓名 | 年龄 |\n| ---- | ---- |\n| 张三 | 18 |- LLM 对 Markdown 表格理解很好。
- HTML 化:保留
<table>标签。 - 专用工具:
- Camelot (Python): 专门提取 PDF 表格。
- Table Transformer (AI 模型): 识别表格结构。
- Azure Document Intelligence: 云端最强,直接返回结构化 JSON。
3.3.3 痛点三:多栏排版 (Multi-column Layout)
现象:论文或报纸,左右两栏。解析器按从左到右、从上到下读取,导致句子交叉。
- 原文:
| 左边栏内容 A | 右边栏内容 B | | 左边栏内容 C | 右边栏内容 D |
- 错误解析:
A B C D - 正确解析:
A C(左栏) +B D(右栏)
解决方案:布局分析 (Layout Analysis)。
- 使用 Nougat (Meta 开源模型) 或 Marker。
- 使用云端 API (Azure/AWS) 的布局分析功能。
- Spring AI 中需自定义解析器集成这些工具。
3.3.4 痛点四:页眉页脚与页码 (Noise)
现象:每一页底部都有 "© 2024 Company Name - Page 1"。 后果:这些噪声会被向量化,干扰检索(搜“页码”会搜出所有文档)。
解决方案:正则清洗 (Regex Cleaning)。 在解析后,分片前,增加一个
DocumentTransformer进行清洗。去降低我们的噪声。
@Bean public DocumentTransformer noiseCleaner() { return document -> { String content = document.getContent(); // 移除页码,如 "Page 1 of 10" content = content.replaceAll("(?m)^Page\\s+\\d+\\s+of\\s+\\d+$", ""); // 移除页脚版权 content = content.replaceAll("©\\s+\\d{4}.*", ""); // 移除过多空行 content = content.replaceAll("\\n{3,}", "\n\n"); document.setContent(content); return document; }; }
3.4 元数据
元数据是 RAG 实现权限控制和精准过滤的关键。解析时必须尽可能多地提取信息。
3.4.1 必提取的元数据字段
|
字段名 |
类型 |
用途 |
示例 |
|---|---|---|---|
|
|
String |
溯源,告诉用户答案来自哪 |
"employee_handbook.pdf" |
|
|
String |
过滤文件类型 |
"pdf", "docx" |
|
|
Integer |
定位具体位置 |
5 |
|
|
String |
语义增强,知道属于哪一章 |
"第三章:考勤制度" |
|
|
Date |
时间过滤,只用最新文档 |
"2023-10-01" |
|
|
String |
权限隔离核心 |
"HR", "Finance" |
3.4.2 Spring AI 中注入元数据
解析器通常只能提取基础元数据(如文件名)。业务元数据(如部门)需要手动注入。
@Service
public class MetadataEnricher {
public List<Document> enrich(List<Document> docs, String department) {
for (Document doc : docs) {
// 1. 基础元数据 (解析器通常已自动填充)
// doc.getMetadata().get("source")
// 2. 业务元数据 (手动注入)
doc.getMetadata().put("department", department);
doc.getMetadata().put("security_level", "internal");
// 3. 时间戳
doc.getMetadata().put("ingestion_time", System.currentTimeMillis());
}
return docs;
}
}4.3 从文件内容提取元数据
有些元数据在文件内容里,比如“文档版本号”。 方案:使用 LLM 在解析阶段提取元数据。
// 伪代码:解析后先过一遍 LLM 提取 Meta
public Document extractMeta(Document doc) {
String prompt = "从以下文本中提取版本号和发布日期,返回 JSON: " + doc.getContent().substring(0, 1000);
String metaJson = llm.call(prompt);
// 解析 JSON 并放入 doc.getMetadata()
return doc;
}3.5 解析总体流程
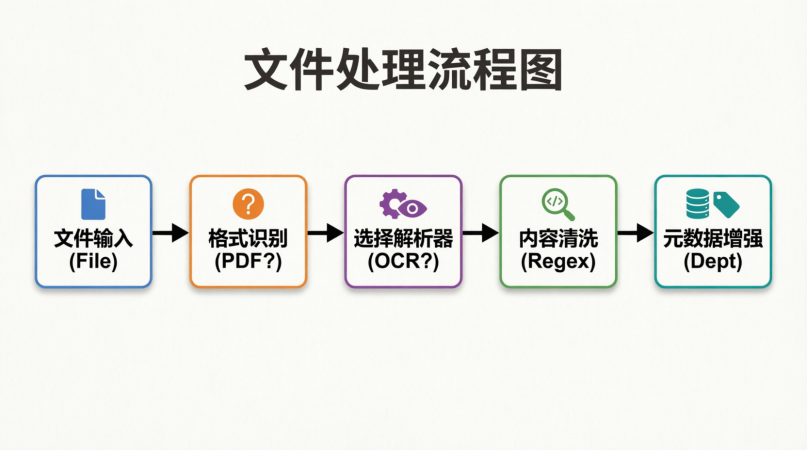
总结
到这里,我们学习了RAG的总体流程与第一个流程:文档解析的学习,为避免文章过长,我打算分多篇进行讲解

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 22
22 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)