【RL】Soft Adaptive Policy Optimization(SAPO)
note
- GRPO(token-level clipping)和 GSPO(sequence-level clipping)采用硬剪切(hard clipping):当重要性比率超出范围时,梯度直接被截断。尽管能避免灾难性更新,但有两个固有缺点:
- 学习信号丢失:被剪切区间外的所有梯度全部丢弃。对于 GSPO,只要有少数 token 异常,可能导致整个序列的梯度都被抛弃。
- 难以取得较好平衡:剪切范围太窄 → 大量样本没有梯度;太宽 → off‑policy 梯度噪声破坏稳定性。这在 MoE 模型里尤为明显。
- SAPO 使用平滑、温度控制的门控函数替代硬剪切,在保持稳定性的同时保留更多有效梯度。其特点包括:
- 连续信任域(无硬剪切不连续性),
- 序列级一致性(类似 GSPO,但不丢弃整段序列),
- token 级自适应性(弱化异常 token),
- 非对称温度设计(正负 tokens 差异化处理)。
- 通过用温度控制的平滑门控替换不连续的裁剪,并采用不对称温度更好地调节负token梯度,SAPO提供了更稳定且丰富的优化信号。
- 在多个数学推理基准上的实证结果表明,SAPO延长了稳定训练的持续时间,并在相等的预算下实现了更高的Pass@1性能。此外,在大规模Qwen3-VL模型的实验中进一步证明了SAPO在不同文本和多模态任务以及不同模型规模和架构中的一致改进。这些发现表明,平滑且自适应的门控机制为提高大型语言模型RL训练的鲁棒性和有效性提供了一个有前景的方向。
一、研究背景
- 研究问题:这篇文章要解决的问题是强化学习(RL)在增强大型语言模型(LLMs)推理能力方面的重要性日益增加,然而稳定且高效的策略优化仍然具有挑战性。特别是,token级重要性比率的高方差现象在专家混合(MoE)模型中被放大,导致更新不稳定。现有的基于组的策略优化方法,如GPSO和GRPO,通过硬裁剪来缓解这个问题,但这使得难以同时保持稳定性和有效的学习。
- 研究难点:该问题的研究难点包括:如何在保持序列一致性的同时,自适应地调整token级的重要性比率;如何避免硬裁剪带来的梯度消失和不稳定问题。
- 相关工作:该问题的研究相关工作有:GPSO和GRPO等基于组的策略优化方法,这些方法通过硬裁剪来解决梯度方差高的问题,但存在稳定性与有效性难以兼顾的问题。
二、SAPO
这篇论文提出了软自适应策略优化(SAPO),用于解决大型语言模型RL训练中的不稳定性和效率低下问题。具体来说,
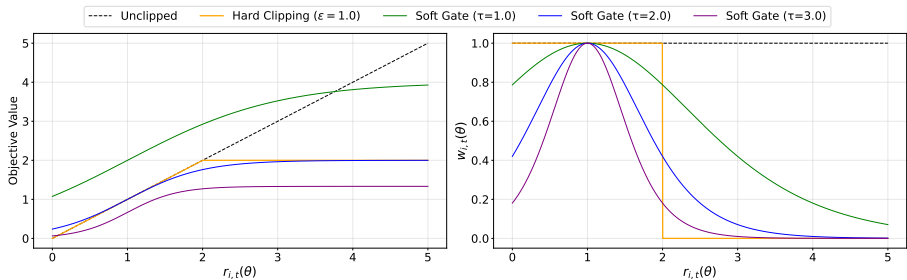
平滑自适应门控:SAPO通过一个温度控制的平滑门控替换了硬裁剪。该门控是一个sigmoid形状的有界函数,以当前策略点为中心。这使得梯度在接近当前策略时得以保留,而在偏离时平滑衰减,从而在保持中等偏差的学习信号的同时减少优化噪声。
不对称温度设计:为了进一步增强在大词汇表中的鲁棒性,SAPO对正负token使用不对称的温度。这使得负token的梯度衰减更快,反映了其不同的稳定性特征:负更新往往会增加许多不适当token的logits,因此比正更新更容易引入不稳定性。
三、实验设计
- 数据集:实验使用了从Qwen3-30B-A3B-Base冷启动模型微调而来的模型,并在数学推理查询上进行实验。验证集包括在AIME25、HMMT25和BeyondAIME基准上的性能。
- 训练过程:在RL训练过程中,每个批次的展开数据被分成四个小批次进行梯度更新。对于SAPO,设置Tpos=1.0和Tneg=1.05。
- 对比方法:将SAPO与GSPO和GRPO-R2(即配备了路由重放的GRPO)进行比较,使用与Zheng等人(2025)相同的超参数配置。
四、实验结果
-
控制实验结果:SAPO在所有基准上均一致提高了模型性能,表现出更高的稳定性和更强的最终性能。相比之下,GSPO和GRPO-R2在早期训练阶段出现崩溃,而SAPO保持了稳定的训练动态,并最终达到了更优的性能。
-
温度影响:为了实证检验选择 τ neg > τ pos \tau_{\text{neg}} > \tau_{\text{pos}} τneg>τpos 的效果,评估了三种配置: τ neg = 1.05 > τ pos = 1.0 \tau_{\text{neg}} = 1.05 > \tau_{\text{pos}}=1.0 τneg=1.05>τpos=1.0, τ neg = τ pos = 1.0 \tau_{\text{neg}}=\tau_{\text{pos}}=1.0 τneg=τpos=1.0,和 τ neg = 0.95 < τ pos = 1.0 \tau_{\text{neg}}=0.95<\tau_{\text{pos}}=1.0 τneg=0.95<τpos=1.0。结果表明,当负token分配较高的温度( T neg = 1.05 T_{\text{neg}}=1.05 Tneg=1.05)时训练最稳定,而分配较低的温度( T neg = 0.95 T_{\text{neg}}=0.95 Tneg=0.95)时训练最不稳定。这些结果表明,与负token相关的梯度对训练不稳定性贡献更大,SAPO的非对称温度设计有效地缓解了这一问题。
-
Qwen3-VL训练结果:将SAPO应用于Qwen3-VL系列模型的训练,评估其在实际大规模设置中的有效性。实验表明,SAPO在不同规模的模型和MoE及密集架构中均一致提高了性能。
Reference
[1] SAPO:让强化学习告别“硬剪切”
[2] 超越GRPO和GSPO!阿里千问提出升级版RL算法SAPO,已应用于Qwen3-VL
[3] 【LLM技术论文】《SAPO:软自适应策略优化》

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 2
2 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)