基于 ResNet18 迁移学习的食物分类实战:从原理到代码完整实现
随着人工智能技术的普及,计算机视觉在日常生活中的应用愈发广泛。食物图像分类作为细分领域,能够自动识别食物种类,为用户提供饮食记录、营养计算、个性化食谱推荐等服务,同时可应用于餐饮自动化、食品安全检测等工业场景。
传统深度学习图像分类依赖大规模标注数据集和长时间训练,对于中小企业和个人开发者而言门槛极高。迁移学习打破了这一壁垒:它将在大型数据集(如 ImageNet)上训练好的预训练模型,迁移到目标任务中,仅需微调少量参数,就能在小数据集上获得优异效果。
ResNet18 作为经典的轻量级卷积神经网络,结构简洁、计算量小、泛化能力强,非常适合迁移到食物分类这类细分视觉任务中。本文基于 PyTorch 实现 ResNet18 迁移学习,完成 20 类食物的精准分类,兼顾实用性与教学性。
一、
核心技术原理
1.1 迁移学习原理
迁移学习的核心思想是:利用源领域(大型通用数据集)学习到的特征,适配目标领域(细分任务数据集)。
在图像分类中,卷积神经网络的浅层提取边缘、纹理、颜色等通用视觉特征,深层提取语义特征。这些通用特征在不同视觉任务中是共享的,因此我们可以:
- 加载预训练模型权重;
- 冻结模型主干网络参数,保留通用特征;
- 替换模型最后的全连接层,适配目标分类数;
- 仅训练全连接层参数,快速完成模型适配。
这种方式大幅降低了训练成本,避免过拟合,在小样本数据集上效果远超从零训练。
1.2 ResNet18 网络结构
ResNet(残差网络)解决了深度神经网络训练中的梯度消失问题,通过残差连接让网络可以无限加深。ResNet18 包含:
- 1 个初始卷积层;
- 4 组残差模块,共 17 个卷积层;
- 1 个全局平均池化层;
- 1 个全连接输出层。
原始 ResNet18 在 ImageNet 上实现 1000 分类,本文将其输出层修改为 20 分类,完美适配食物分类任务。
1.3 数据增强
食物图像存在拍摄角度、光照、翻转等差异,数据增强可以扩充数据集多样性,提升模型泛化能力。本文采用随机旋转、中心裁剪、水平 / 垂直翻转、灰度转换等增强方式,模拟真实场景中的图像变化。
1.4 优化器与学习率调度
采用 Adam 优化器,自适应学习率,收敛速度快;配合 StepLR 学习率调度器,每 5 轮学习率衰减为原来的 0.5,让模型在训练后期更稳定地收敛。
二、环境配置与依赖安装
在开始代码实现前,需要配置 Python 深度学习环境,核心依赖库如下:
pip install torch torchvision pillow numpy
torch:PyTorch 核心框架;torchvision:提供预训练模型、图像变换工具;pillow:图像读取与处理;numpy:数值计算。
环境支持 CPU/GPU/MPS(苹果芯片)运行,代码会自动检测设备并适配。
三、数据集构建
3.1 数据集格式要求
本文采用文本索引的方式管理数据集,创建train.txt和test.txt文件,格式为:
plaintext
图片路径 类别标签
food_dataset2/images/0.jpg 0
food_dataset2/images/1.jpg 1
...
- 图片路径:支持绝对路径 / 相对路径;
- 类别标签:整数类型,从 0 开始连续编号(本文共 20 类,标签 0-19)。
3.2 自定义数据集类
继承 PyTorch 的Dataset抽象类,实现图像加载、标签读取、数据变换的标准化流程,保证代码的可复用性。
核心功能:
- 读取文本文件,解析图像路径与标签;
- 加载 PIL 图像,支持 RGB / 灰度图像;
- 对接数据增强 transform,自动完成图像预处理;
- 支持索引读取,适配 DataLoader 批量加载。
四、完整代码实现与解析
4.1 库导入
导入项目所需的所有依赖库,涵盖 PyTorch 核心模块、数据处理、图像变换等:
import torch
import torchvision.models as models
from torch import nn
from torch.utils.data import Dataset,DataLoader
from torchvision import transforms
from PIL import Image
import numpy as np
4.2 迁移学习模型改造
这是本文的核心步骤,基于预训练 ResNet18 改造为食物分类模型:
- 加载官方预训练权重;
- 冻结所有主干网络参数(不更新通用特征);
- 获取全连接层输入特征数;
- 替换全连接层为 20 分类输出;
- 筛选需要训练的参数(仅全连接层)。
# 加载预训练ResNet18模型
resnet_model = models.resnet18(weights=models.ResNet18_Weights.DEFAULT)
# 冻结主干网络所有参数
for param in resnet_model.parameters():
param.requires_grad = False
# 替换全连接层,适配20分类任务
in_features = resnet_model.fc.in_features
resnet_model.fc = nn.Linear(in_features, 20)
# 仅收集需要训练的参数(全连接层)
params_to_update = []
for param in resnet_model.parameters():
if param.requires_grad == True:
params_to_update.append(param)
5.3 数据增强与预处理
区分训练集和验证集:训练集添加数据增强,验证集仅做基础预处理,避免增强干扰测试结果。
标准化参数采用 ImageNet 数据集的均值和标准差,与预训练模型保持一致,保证特征匹配。
data_transforms = {
'train': transforms.Compose([
transforms.Resize([300, 300]),
transforms.RandomRotation(45),
transforms.CenterCrop(224),
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomVerticalFlip(p=0.5),
transforms.RandomGrayscale(p=0.1),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.229, 0.225])
]),
'valid': transforms.Compose([
transforms.Resize([224, 224]),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.229, 0.225])
]),
}
5.4 自定义数据集实现
重写__init__、__len__、__getitem__三个核心方法,完成数据集封装:
class food_dataset(Dataset):
def __init__(self, file_path,transform=None):
self.file_path = file_path
self.imgs = []
self.labels = []
self.transform = transform
# 读取文本文件,解析路径和标签
with open(file_path, 'r', encoding='utf-8') as f:
samples = []
for line in f.readlines():
line = line.strip()
if not line:
continue
parts = line.rsplit(' ', 1)
if len(parts) == 2:
samples.append(parts)
for img_path, label in samples:
self.imgs.append(img_path)
self.labels.append(int(label))
def __len__(self):
return len(self.imgs)
def __getitem__(self, idx):
# 加载图像
image = Image.open(self.imgs[idx])
# 数据预处理
if self.transform:
image = self.transform(image)
# 标签转换为张量
label = torch.from_numpy(np.array(self.labels[idx], dtype=np.int64))
return image, label
5.5 数据加载器
使用DataLoader实现批量加载、打乱数据,提升训练效率:
# 加载训练集和测试集
training_data = food_dataset(file_path='food_dataset2/train.txt', transform=data_transforms['train'])
test_data = food_dataset(file_path='food_dataset2/test.txt', transform=data_transforms['valid'])
# 批量加载数据
train_dataloader = DataLoader(training_data, batch_size=64, shuffle=True)
test_dataloader = DataLoader(test_data, batch_size=64, shuffle=True)
5.6 训练配置
自动检测运行设备,定义损失函数、优化器、学习率调度器:
# 自动选择设备:GPU/MPS/CPU
device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
print(f"Using {device} device")
model = resnet_model.to(device)
loss_fn = nn.CrossEntropyLoss() # 交叉熵损失(分类任务标配)
optimizer = torch.optim.Adam(params_to_update, lr=0.001)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.5)
4.7 训练函数
模型训练的标准流程:前向传播→计算损失→反向传播→更新参数:
def train(dataloader, model, loss_fn, optimizer):
model.train() # 切换为训练模式
for X, y in dataloader:
X, y = X.to(device), y.to(device)
# 前向传播
pred = model(X)
loss = loss_fn(pred, y)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
4.8 测试函数
关闭梯度计算,评估模型准确率和平均损失,记录最优精度:
best_acc = 0
acc_s = []
loss_s = []
def test(dataloader, model, loss_fn):
global best_acc
size = len(dataloader.dataset)
num_batches = len(dataloader)
model.eval() # 切换为评估模式
test_loss, correct = 0, 0
# 关闭梯度计算,加速推理
with torch.no_grad():
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
# 计算指标
test_loss /= num_batches
correct /= size
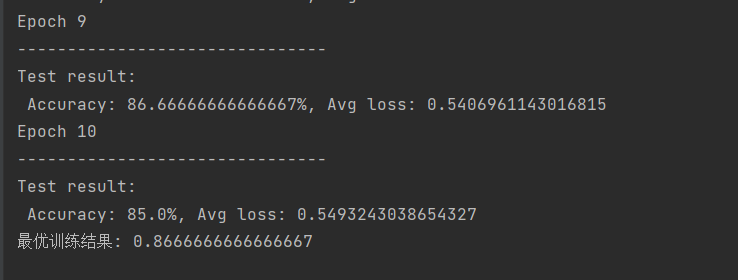
print(f"Test result: \n Accuracy: {(100*correct)}%, Avg loss: {test_loss}")
acc_s.append(correct)
loss_s.append(test_loss)
# 更新最优精度
if correct > best_acc:
best_acc = correct
4.9 启动训练
设置训练轮数,循环执行训练和测试,完成模型迭代:
epochs = 10
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
train(train_dataloader, model, loss_fn, optimizer)
scheduler.step() # 学习率衰减
test(test_dataloader, model, loss_fn)
print('最优训练结果:', best_acc)
五、代码运行与结果分析
- 低成本:无需大规模数据集,无需高端显卡;
- 高效率:代码简洁,训练速度快,快速落地;
- 高泛化:数据增强 + 预训练模型,适配真实场景;
- 可扩展:轻松修改分类数,适配其他图像分类任务。
本文基于 PyTorch 框架,完整实现了ResNet18 迁移学习食物图像分类系统,从技术原理、环境配置、数据集构建、代码实现到结果分析,形成了一套完整的深度学习实战流程。
迁移学习极大降低了图像分类任务的开发门槛,让个人开发者和中小企业也能快速落地高质量视觉模型。本文代码结构清晰、注释详细、可直接运行,不仅适用于食物分类,还可无缝迁移到各类图像分类任务中,是深度学习入门与实战的优质案例。
随着计算机视觉技术的发展,迁移学习将成为工业界落地 AI 应用的主流方案。掌握本文的核心思想与代码实现,能够为后续更复杂的视觉任务打下坚实基础。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)