【Mock LLM】为什么测试agent需要使用Mock LLM?
Mock LLM 是 Agent 测试中的一种模拟手段,用于在不调用真实大模型的情况下测试 Agent 的逻辑。它的核心思想是:用假的 LLM 替代真实的 LLM,让 Agent 的行为变得确定、可控、快速、免费。
考虑一下我们在测试Agent工具调用的时候实际上是测试的什么。
- 比如说我们有一个搜索天气的工具
weather_search,如果我们做端到端测试的话,就是去问Agent今天天气怎么样,然后他去调用这个工具去搜索。 - 那么实际上,Agent会先收到
今天天气怎么样这一条输入,然后会把这条输入发给大模型 - 大模型根据输入和自己拥有的工具列表,会返回一个调用
weather_search工具的请求,然后我们的Agent代码解析该请求后,发现是一个工具调用,然后去进行真实的工具调用,并且获得一个来自该工具的回复 - 等Agent获得回复后,会发送给大模型,让大模型来生成最终的回答
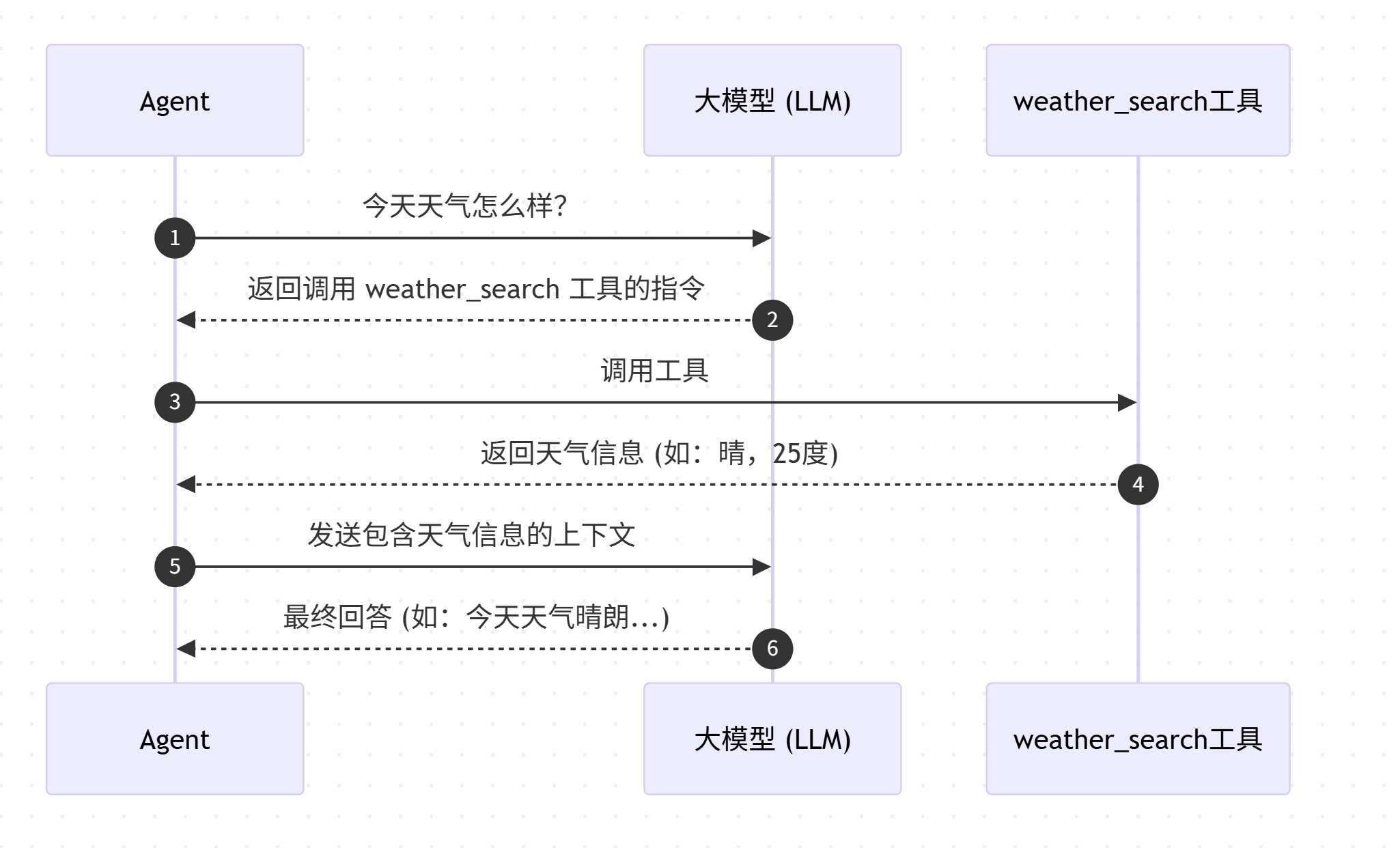
所以我们实际上测试的是Agent代码在收到工具调用请求的时候,能不能正常的去调用工具,还是直接将这个作为最终的回复返回给用户。而这个过程中,大模型的回复我们基本上是可以预见的。理想上第一步应该是进行工具调用,第二步是生成一个最终回复,那么我们可以基于这个假设去做一个假的LLM。避免对真实大模型的调用开销和延迟。
还比如说,我们想测试如果大模型返回的数据有误,我们的Agent代码能不能正确的处理错误。
当然,需要测试的场景还有非常多,这个例子只是说明使用Mock LLM的一个基础想法。
一、为什么需要 Mock LLM?
测试 Agent 时,直接调用真实 LLM 会遇到几个痛点:
| 问题 | 说明 |
|---|---|
| 成本高 | 每次测试都要消耗 API 费用,频繁测试开销大 |
| 速度慢 | 真实 LLM 响应需要几秒,测试集多了等不起 |
| 不确定 | 模型输出有随机性,同样的输入可能得到不同结果,导致测试不稳定 |
| 依赖网络 | 断网或 API 服务故障时测试无法进行 |
| 测试复杂逻辑 | 难以模拟特定场景(如工具调用失败、模型返回格式错误等) |
Mock LLM 可以完美解决以上所有问题。
二、Mock LLM 的核心原理
Mock LLM 本质上是一个假的聊天模型,它不调用任何外部 API,而是根据预定义的规则返回固定响应。
┌─────────────────────────────────────────────────────────┐
│ 测试环境 │
│ │
│ Agent ──► Mock LLM (假的) ──► 返回预设好的响应 │
│ │ │ │
│ └────────── 工具调用 ──────────┘ │
│ │
│ 真实 LLM 永远不会被调用,测试完全在本地进行 │
└─────────────────────────────────────────────────────────┘
三、LangChain 中实现 Mock LLM 的方法
方法一:使用 FakeListLLM(最简单)
FakeListLLM 是 LangChain 内置的 Mock 类,它会按顺序返回预设的响应。
from langchain_core.language_models.llms import FakeListLLM
from langchain.agents import create_agent
from langchain.tools import tool
# 1. 定义工具
@tool
def get_weather(city: str) -> str:
"""获取天气"""
return f"{city} 天气晴朗"
# 2. 创建 Mock LLM,预设响应列表
mock_llm = FakeListLLM(
responses=[
# 第1次调用:要求调用工具
'{"action": "get_weather", "action_input": {"city": "北京"}}',
# 第2次调用:根据工具结果给出最终答案
'{"final_answer": "北京天气晴朗,适合出行"}'
]
)
# 3. 创建 Agent
agent = create_agent(
model=mock_llm, # 使用 Mock LLM
tools=[get_weather],
system_prompt="You are a helpful assistant"
)
# 4. 测试
result = agent.invoke({
"messages": [{"role": "user", "content": "北京天气怎么样?"}]
})
print(result)
优点:简单直接,响应顺序可控
缺点:需要提前知道 Agent 会调用几次 LLM
方法二:使用 FakeChatModel(更灵活)
FakeChatModel 可以自定义响应逻辑,包括返回工具调用、拒绝回答等。
from langchain_core.language_models.chat_models import FakeChatModel
from langchain_core.messages import AIMessage, ToolMessage
from langchain_core.tools import tool
# 自定义响应逻辑
class MyMockLLM(FakeChatModel):
def _generate(self, messages, stop=None, run_manager=None, **kwargs):
# 根据用户消息决定返回什么
user_message = messages[-1].content
if "天气" in user_message:
# 模拟返回工具调用
return AIMessage(
content="",
tool_calls=[{
"name": "get_weather",
"args": {"city": "北京"},
"id": "call_123"
}]
)
elif "谢谢" in user_message:
# 模拟最终回答
return AIMessage(content="不客气,很高兴为您服务!")
else:
return AIMessage(content="我是 Mock LLM,我只能回答有限的问题。")
# 使用
mock_llm = MyMockLLM()
方法三:手动模拟(完全控制)
如果你想要最精细的控制,可以自己实现一个简单的模拟类:
from langchain_core.language_models.chat_models import BaseChatModel
from langchain_core.outputs import ChatResult, ChatGeneration
from langchain_core.messages import AIMessage
class CustomMockLLM(BaseChatModel):
"""完全自定义的 Mock LLM"""
def __init__(self, responses=None):
super().__init__()
self.responses = responses or []
self.call_count = 0
def _generate(self, messages, stop=None, run_manager=None, **kwargs):
# 按顺序返回预设响应
if self.call_count < len(self.responses):
response = self.responses[self.call_count]
else:
response = "默认响应"
self.call_count += 1
# 如果响应是字典,可能是工具调用格式
if isinstance(response, dict) and "tool_calls" in response:
return ChatResult(
generations=[ChatGeneration(message=AIMessage(**response))]
)
else:
return ChatResult(
generations=[ChatGeneration(message=AIMessage(content=response))]
)
@property
def _llm_type(self) -> str:
return "custom_mock"
# 使用
mock = CustomMockLLM(responses=[
"用户你好,我能帮你做什么?",
{"tool_calls": [{"name": "search", "args": {"query": "天气"}}]}
])
四、测试场景示例
场景1:测试 Agent 是否正确调用工具
from langchain_core.language_models.llms import FakeListLLM
# Mock LLM 强制要求调用工具
mock = FakeListLLM(responses=[
'{"action": "search_weather", "action_input": {"city": "上海"}}'
])
agent = create_agent(model=mock, tools=[search_weather])
result = agent.invoke({"messages": [{"role": "user", "content": "上海天气"}]})
# 断言:工具被调用了
assert result.get("tool_calls") is not None
场景2:测试 Agent 的错误处理
# Mock LLM 返回错误格式
mock = FakeListLLM(responses=[
'这不是合法的 JSON 格式' # 模拟模型输出异常
])
agent = create_agent(model=mock, tools=[tool])
# 测试 Agent 是否能优雅处理
场景3:测试多轮对话
mock = FakeListLLM(responses=[
"需要先调用工具",
'{"action": "calculator", "action_input": {"expression": "1+1"}}',
"结果是 2"
])
agent = create_agent(model=mock, tools=[calculator])
五、Mock LLM 的优缺点
| 优点 | 说明 |
|---|---|
| ✅ 零成本 | 不消耗 API 额度 |
| ✅ 极快 | 毫秒级响应,无需网络 |
| ✅ 确定性 | 每次测试结果一致,便于断言 |
| ✅ 可模拟边界 | 能模拟超时、错误、格式异常等情况 |
| ✅ 离线可用 | 无需 API Key,不依赖外网 |
| 缺点 | 说明 |
|---|---|
| ❌ 无法测试真实模型 | 无法验证模型的理解和推理能力 |
| ❌ 需要提前设计 | 需要预设响应,对复杂交互测试成本高 |
| ❌ 可能与实际不符 | Mock 的响应可能与真实模型输出有差异 |
六、最佳实践建议
-
分层测试:
- 单元测试:用 Mock LLM 测试 Agent 的逻辑分支、工具调用、错误处理
- 集成测试:用真实 LLM(但用小规模测试)验证最终效果
-
使用 pytest 配合 Mock:
import pytest from unittest.mock import patch def test_agent_with_mock(): mock_llm = FakeListLLM(responses=["北京天气晴朗"]) with patch('your_module.llm', mock_llm): result = agent.invoke(...) assert "晴朗" in result -
保存真实响应作为 Mock 数据:
- 先用真实 LLM 跑一次,把响应保存下来
- 后续用保存的响应作为 Mock 数据,既保证真实性又保证稳定性
七、总结
Mock LLM 是 Agent 测试中不可或缺的手段,它能让你在:
- 开发阶段快速迭代逻辑
- CI/CD 中稳定运行自动化测试
- 离线环境继续开发
核心思路就是用假的、可控的 LLM 替代真的 LLM,专注于测试 Agent 的逻辑正确性而非模型的输出质量。
根据todo.md里面的材料,单元测试时使用mock llm,集成测试时使用真实llm
八、LLM 测试情况表
| 测试类型 | 核心问题 |
|---|---|
| 工具调用 | 代码能正确执行 LLM 要求的动作吗? |
| 解析容错 | LLM 输出不规范时,代码能兜住吗? |
| 循环终止 | 代码能避免无限循环吗? |
| 多工具选择 | 有多个工具时,代码能选对吗? |
| 工具异常 | 工具执行失败时,代码能优雅降级吗? |
| 安全注入 | 用户试图绕过限制时,代码能守住吗? |
| 多轮状态 | 多轮对话中,上下文状态能保持正确吗? |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)