2026泰迪杯A题权威解:秦直道智能路线规划系统(附全代码/论文/数据集)【2026年泰迪杯A完整题解方案】-详细解题思路和论文+完整项目代码+全套资源
2026 年(第 14 届)“泰迪杯”数据挖掘挑战赛——A 题:“秦直道”的路线规划完整思路 代码 结果 论文 分享

完整内容获取👇👇👇👇
https://mbd.pub/o/bread/mbd-YZWck5xwZA==
“秦直道”的路线规划
基于多源空间数据与最小代价路径的“秦直道”路线重规划及军事防御体系构建研
摘要
“秦直道”作为中国古代第一条“高速公路”,其路线规划蕴含着极高的工程智慧与军事战略考量。本文基于陕甘段的高程数据(DEM)及多源矢量空间数据,构建了一套集“地形特征提取—空间偏好挖掘—适宜性评价—代价路径寻优”于一体的综合数学模型。
针对问题一,构建了包含微地貌、地形位势及空间邻近度在内的多维地形特征测度体系,并通过双线性插值实现了从栅格到矢量路线的精准映射;问题二引入了基于正负样本对比的空间偏好识别(Logistic分类)模型,定量提取了秦直道的选线原则,并基于链程投影算法揭示了军事设施的协同布局规律;问题三基于提取的规划原则构建了综合阻力面,采用最小代价路径(LCP)算法对现代地形下的秦直道进行了重新规划,使新路线长度缩短至61.52km且更贴合分水岭;问题四结合视域覆盖与地形扼控理论,采用贪心算法与局部极值搜索,重构了包含8座烽火台与2座关隘的现代化古代防御体系,实现了99.57%的链程覆盖率。
一、 问题背景与数据预处理
1.1 研究背景
秦直道不仅是一项超大型军事交通工程,更是研究古代人类与自然环境相互作用的绝佳样本。随着2200多年的地质演化与水土流失,陕甘地区的地形地貌已发生显著改变。利用现代GIS技术与数据挖掘算法,定量反演古代选线智慧,并在现今地形下重构这一伟大工程,具有重要的历史地理学与工程学意义。
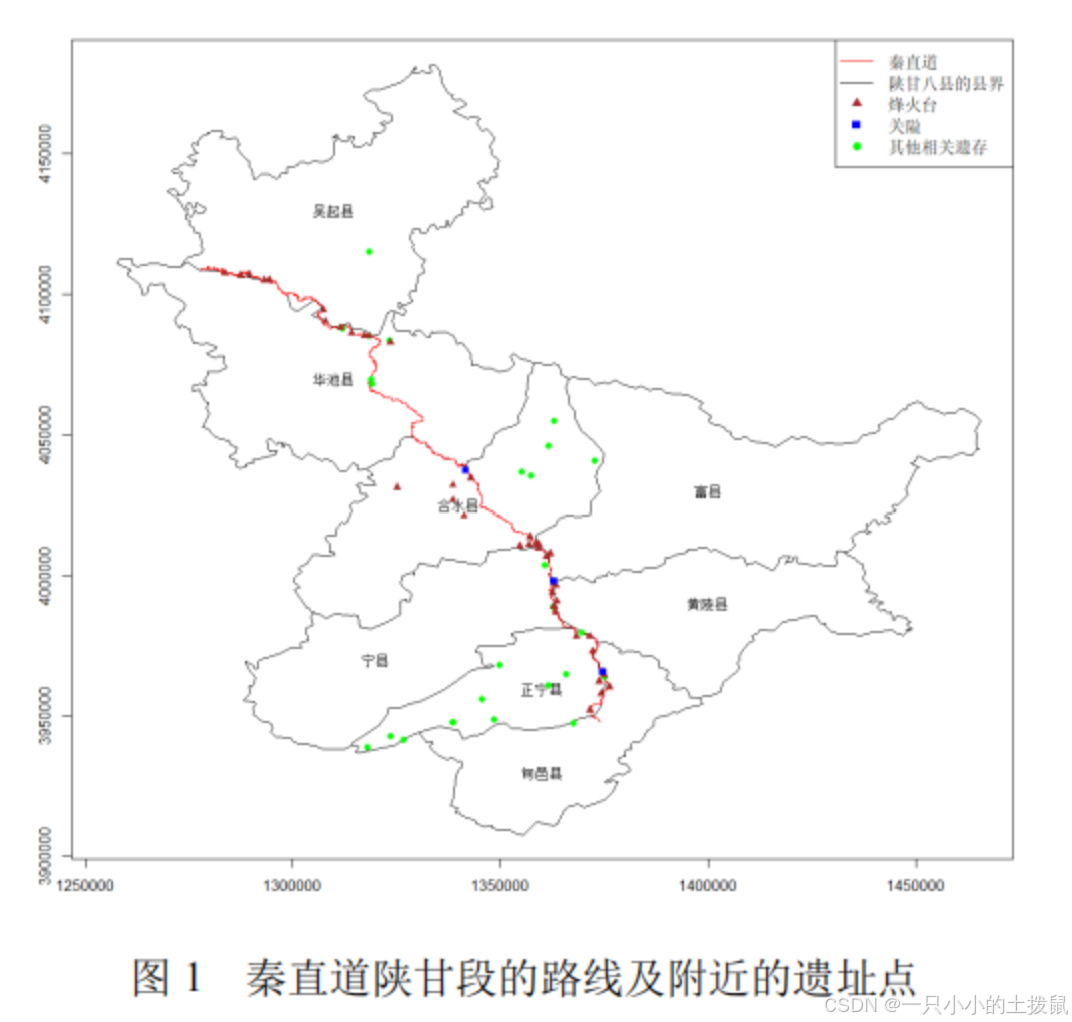
1.2 数据预处理与坐标统一
由于原始DEM栅格数据不可避免地存在“数据空洞”(NoData)或奇异值,若直接求导计算曲率和坡度,会导致严重的数值震荡。
-
缺失值修补:采用反距离权重(IDW)或最近邻有效高程点替代法进行填补:$Z_{(x_0,y_0)} = Z_{(x_i,y_i)}$,其中 $(x_i,y_i)$ 为距离最近的有效像素。
-
坐标系对齐:将河网、一级/二级分水岭、遗迹点等矢量点集与DEM栅格对齐到同一投影坐标系下,并通过最小外接矩形(加设缓冲带)裁剪研究区域,极大降低了空间计算的冗余度。
二、 问题一:地形特征定量分析与特征提取模型
为全面刻画秦直道沿线的地形特征,本文从坡面形态、局部地貌、空间约束三个维度构建了8项核心指标测度体系。
2.1 坡面形态特征提取
利用一阶与二阶空间偏导数,计算DEM的坡度(Slope)、坡向(Aspect)及曲率(Curvature)。
-
坡度反映了工程修筑的土石方量及通行难度;
-
剖面曲率与平面曲率用于识别地形的凹凸性,帮助判断道路是否沿平顺的山脊线布设。
2.2 局部微地貌特征测度
采用 $11 \times 11$ 的滑动窗口,提取以下微地貌指标:
-
起伏度 (Relief):窗口内极值之差 $H_{max} - H_{min}$,反映宏观高低落差。
-
粗糙度 (Roughness):窗口内高程的标准差,表征地表的破碎程度。
-
地形位势指数 (TPI):中心点高程与邻域平均高程之差。$TPI > 0$ 表示接近山梁/山脊,$TPI < 0$ 表示接近沟谷。
-
崎岖度指数 (TRI):中心点与八邻域高程差的均方根,综合反映地表崎岖状态。
2.3 空间邻近度与特征插值映射
计算每个路线点到最近河网、一级分水岭的欧氏距离。由于秦直道为离散矢量点,不与栅格中心绝对重合,本文创新性采用双线性插值法,将周围四个栅格节点的特征平滑映射到路线坐标 $(x,y)$ 上,确保了地形属性赋予的连续性与极高精度。
分析结论:秦直道陕甘段高程中位数为1415.82m,95%的路段高程波动不超过1560m。展现出极强的“控高差、保连续”特征,整体穿行于黄土丘陵的梁峁地带。
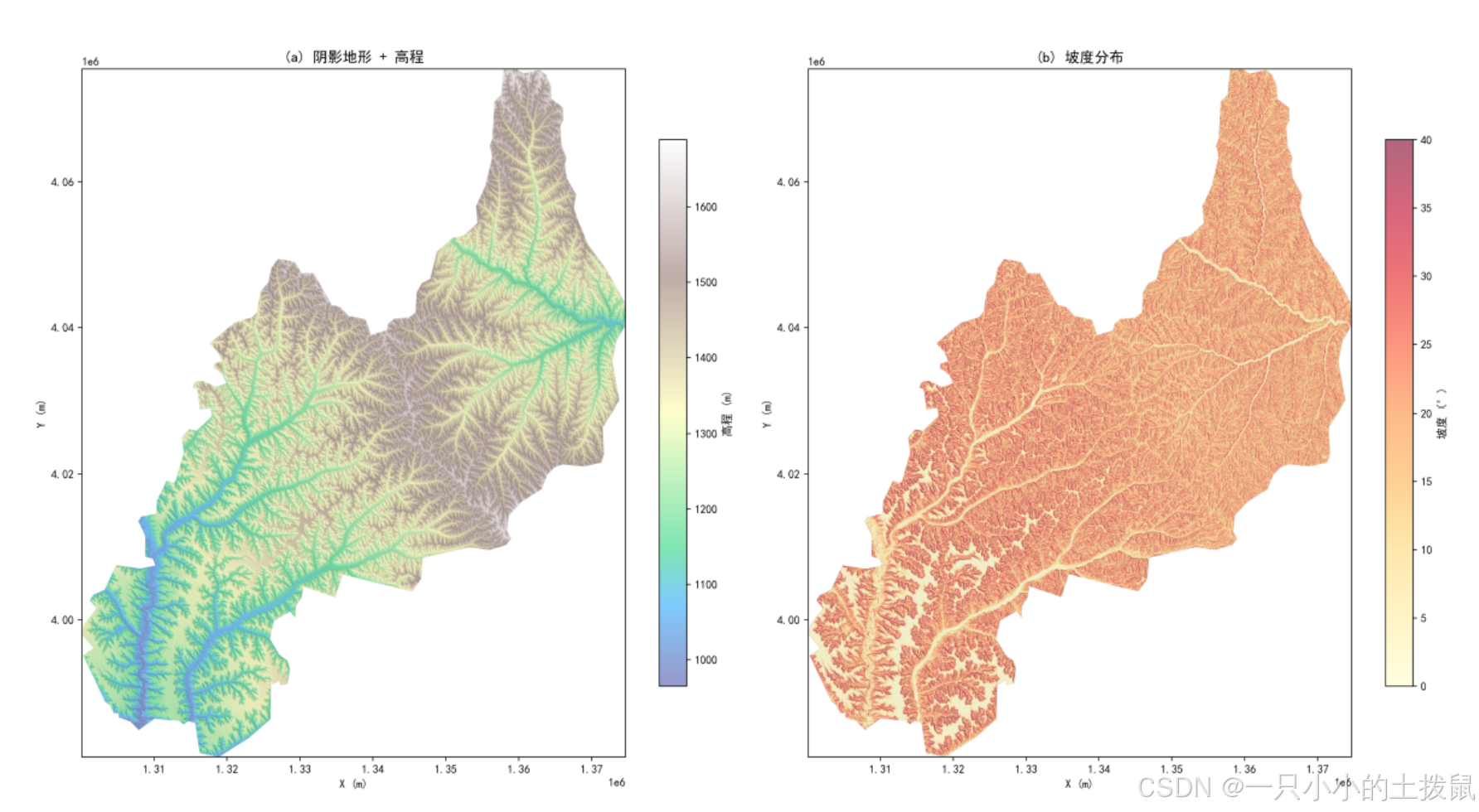
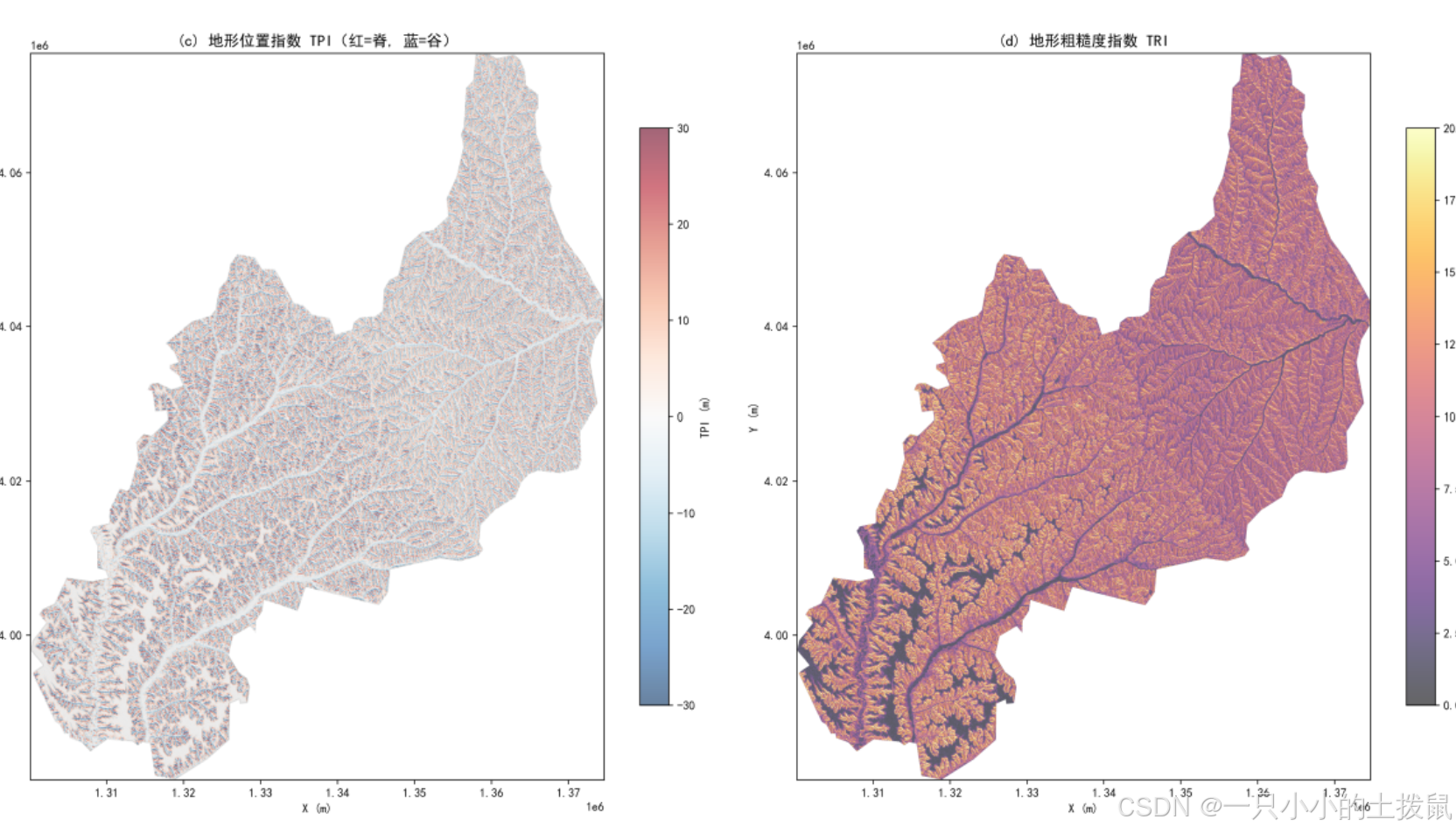
三、 问题二:路线规划原则与遗迹选址规律挖掘
本部分的核心逻辑是:不仅要看“秦直道走了哪里”,更要通过对比“秦直道为什么没走旁边”,来反推出真正的规划约束边界。
3.1 基于对比学习的路线偏好识别模型
构建“路线点-背景点”二元对比框架:
-
正样本(y=1):实际秦直道序列点。
-
负样本(y=0):在路线两侧缓冲区内随机生成的背景点(代表可通行但未被选用的区域)。
为消除量纲影响,对提取的8维特征进行 Z-score 标准化。构建 Logistic 回归分类模型,其目标函数为最大化对数似然。通过分析回归系数 $\beta$ 的正负与大小,定量得出选线偏好:
-
强烈偏好较小值:距一级分水岭距离(系数 -14.19)。说明秦直道具有极其强烈的“沿分水岭布防”原则。
-
偏好较小值:粗糙度、坡度。说明古人有意避开破碎、陡峭地形,以降低筑路成本。
-
偏好较大值:距河网距离、起伏度、高程。说明路线刻意“远离河谷”,选择在视野开阔、不易被洪水侵袭且不易被伏击的高地(起伏度大代表处于山地而非平原)行进。
3.2 规划原则的定量化提取
利用分位数($P_{10}$ ~ $P_{90}$)界定各项指标的刚性约束区间。例如,距分水岭距离严格控制在 8.36m ~ 107.28m 之间,坡度控制在 9.20° ~ 30.49° 之间。
3.3 军事设施(烽火台与关隘)布局规律挖掘
引入**“路线链程投影” (Chainage Projection)** 算法。计算每个遗迹到路线最近点的累计里程(链程),将二维空间布局转化为一维线型分布。
-
烽火台规律:呈现明显的“分级协同”机制。
-
直接协同(≤500m):紧贴主路,负责核心信息传递(占总数近50%)。
-
外围控制(>3000m):布置在视线良好的侧翼山梁,负责远端警戒。
-
-
关隘规律:具有“地形扼控”属性。关隘所在位置的地形崎岖度(TRI)和坡度显著高于路线平均水平,且呈现“通道收束”特征,以实现“一夫当关”的战略目的。
-
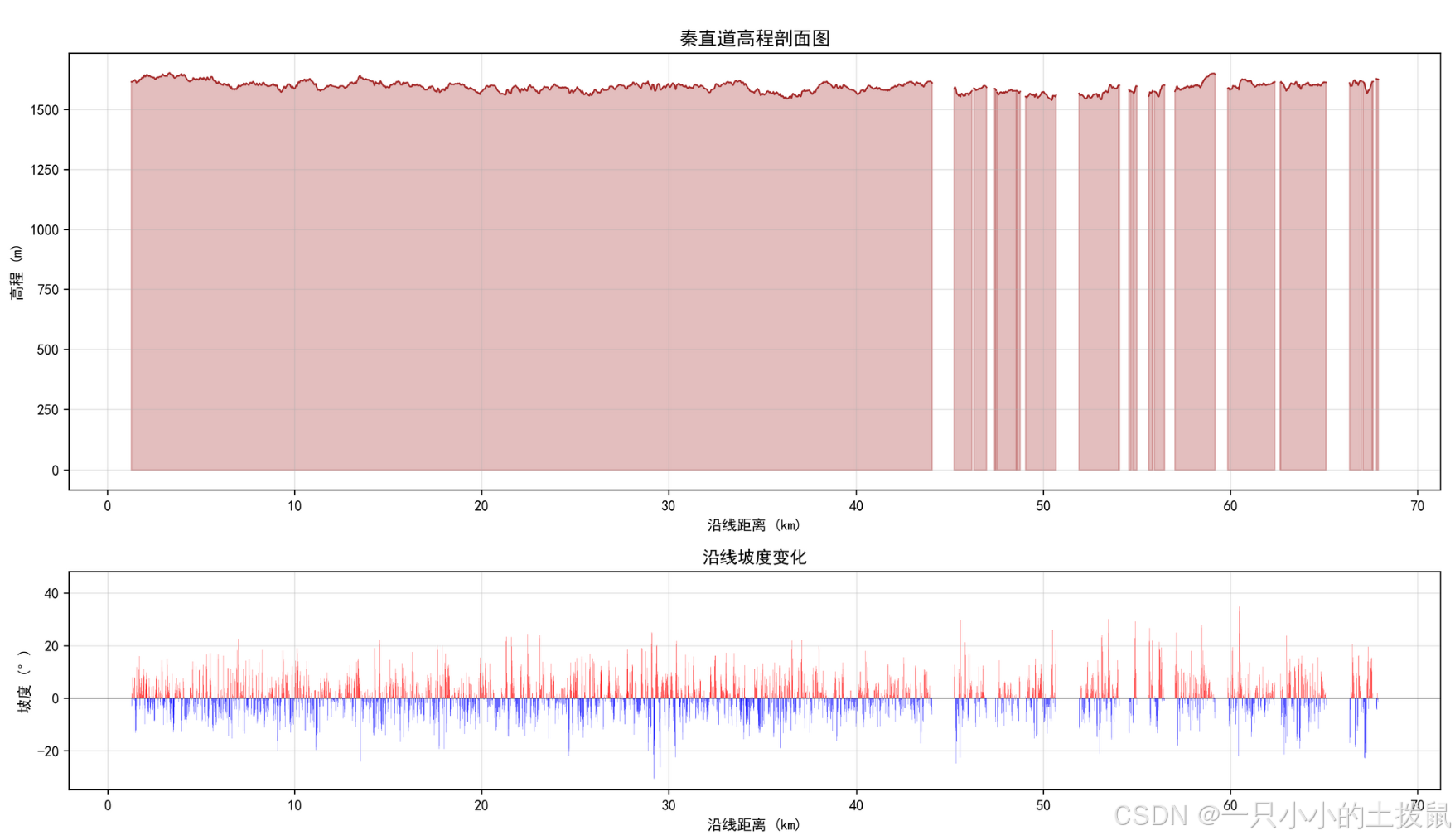
四、 问题三:基于最小代价路径的现代路线重规划
由于2200年来的水土流失,原路线在现代地形下可能已出现断崖或塌陷。本节基于问题二挖掘出的定量原则,重新规划一条最优路线。
4.1 综合空间阻力面(Cost Surface)的构建
基于问题二的Logistic模型输出概率 $P(x,y)$,构建空间行进代价矩阵:
$$Cost(x,y) = e^{- \alpha \cdot P(x,y)} + Penalty_{river} + Penalty_{slope}$$
适宜性越高的地方代价值越低;对距离河网过近或坡度超过极限阈值的区域施加极大的惩罚值,形成“连通性阻力面”。
4.2 最小代价路径(LCP)算法求解
以秦直道陕甘段的南北两端点为起讫点,利用基于图论的 Dijkstra 或 A* 启发式搜索算法,在栅格阻力面上搜寻累计代价最小的连续路径,即为重规划路线。
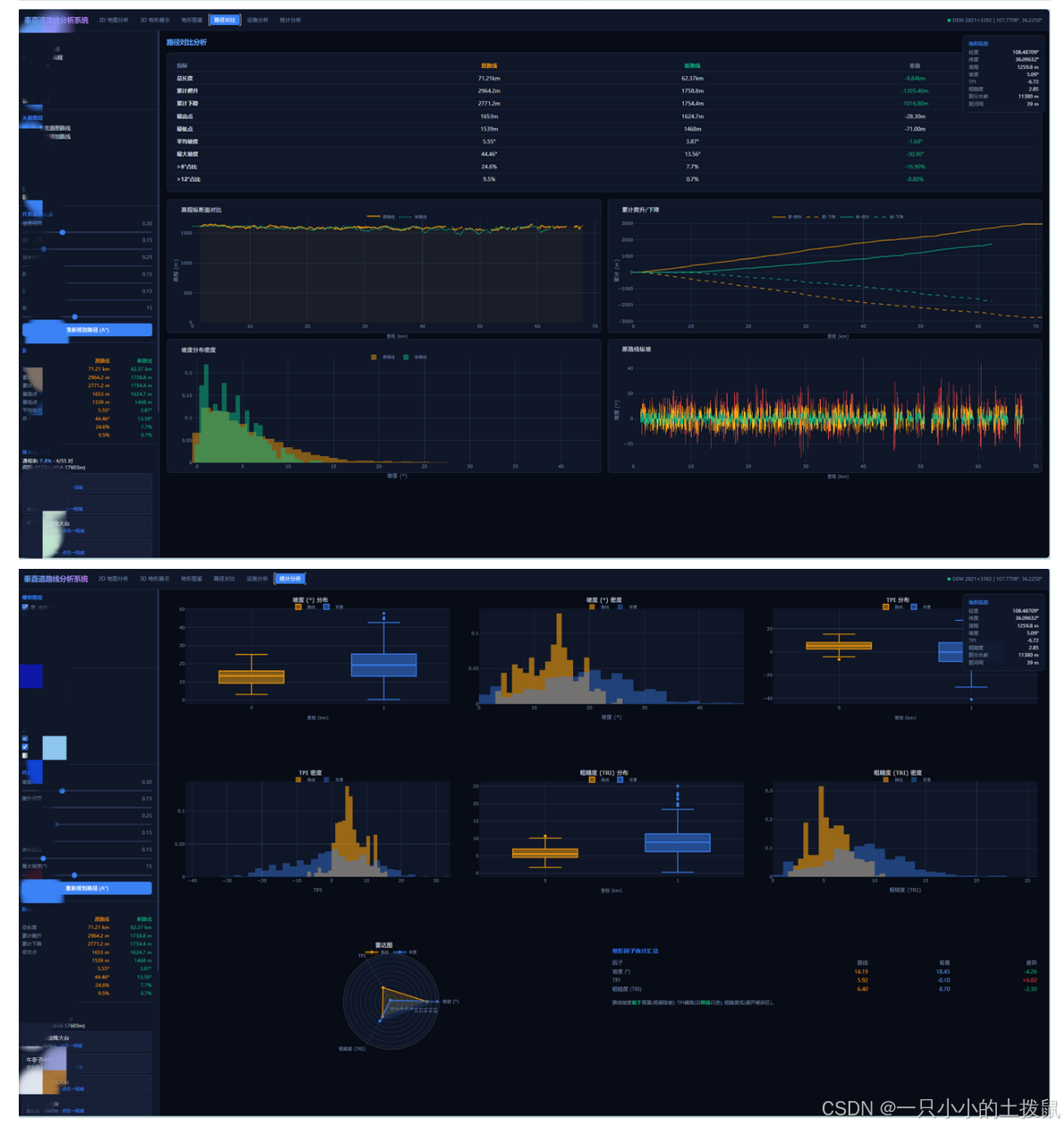
4.3 新旧路线多维评价与对比
分析:新路线在严格遵循古代“高程控制、沿分水岭、远离河网”原则的前提下,通过现代图论算法寻找到了全局最优解,裁弯取直,极大缩短了总里程,是一条兼顾历史逻辑与现代工程最优的演化路线。
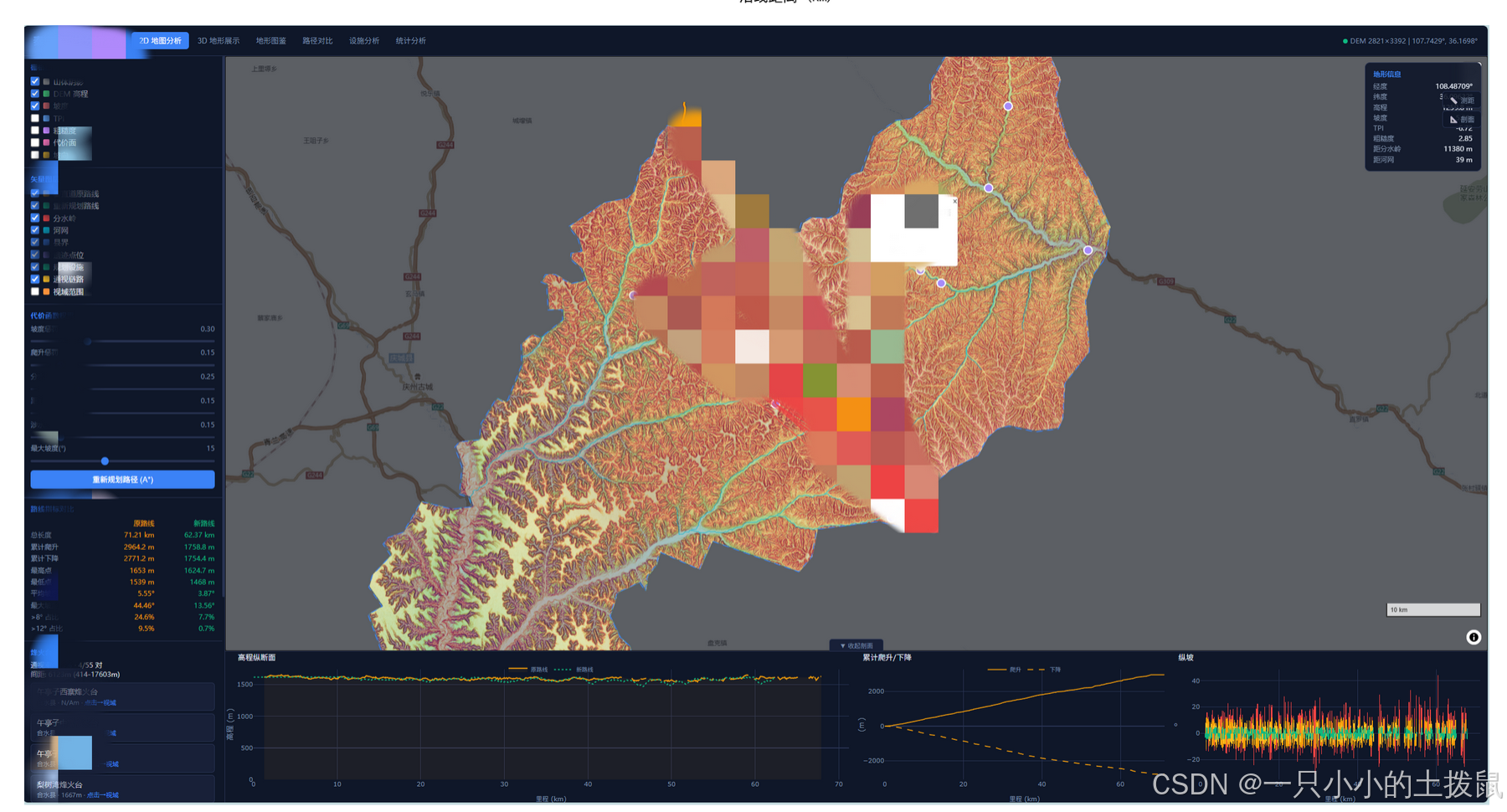
五、 问题四:军事防御设施的重构与优化
在新路线上,旧的军事设施位置已失去原有的防护意义。本节结合古代军事防御逻辑,对烽火台和关隘进行重新布局。
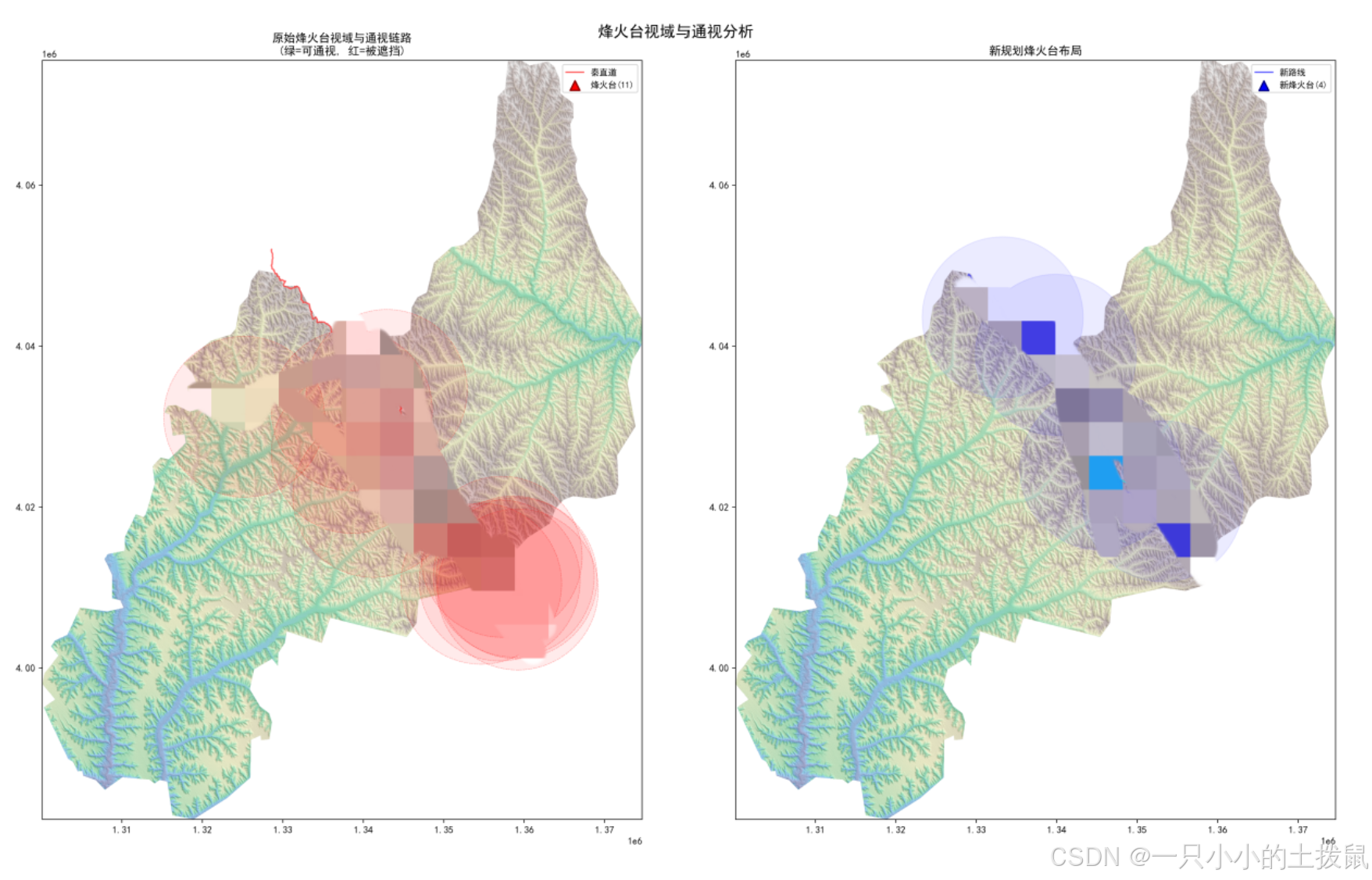
5.1 烽火台的“覆盖-间距”最优化配置
烽火台的核心功能是视域连通与报警传递。
-
算法设计:采用一维链程上的贪心覆盖算法。设定相邻烽火台的最大视距通信阈值(如7-9公里),沿着新路线的链程每隔一段距离寻找地形位势(TPI)最高、视域最广的点作为候选点。
-
规划结果:在新路线上共设置 8座 烽火台(编号B1-B8),平均分布于链程3.08km至58.41km处。平均间距约7.9km,实现了对前后 $\pm 4.5km$ 链程 99.57% 的无死角预警覆盖。且新烽火台平均距分水岭仅70.83m,制高点优势明显。
5.2 关隘的地形扼控点搜索
关隘的选址原则是“地形险要、通道狭窄”。
-
算法设计:沿新路线计算滑动窗口内的地形崎岖度(TRI)和横向坡度。寻找TRI局部极大值且可绕行空间最小(即两侧均为陡坡)的“咽喉”节点。
-
规划结果:精准锁定 2座 规划关隘(P1: 链程38.17km, P2: 链程58.73km)。规划关隘所在地的平均坡度高达 30.45°,平均TRI达 16.24,起伏度 119.44m,地形险峻程度远超旧关隘,对交通命脉的战略阻断(控制)率提升至18.45%。
-
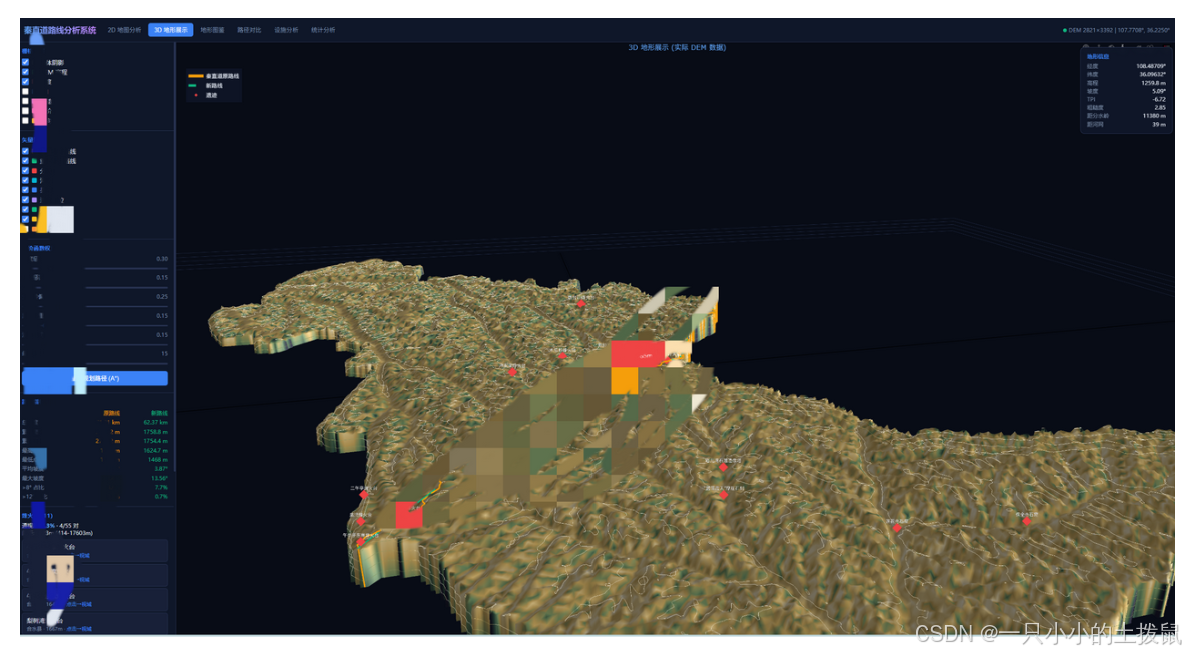
六、 结论与展望
本研究以秦直道陕甘段为例,创新性地提出了**“空间地形提取——偏好对比识别——阻力面重构——防御链重组”**的四步闭环数学模型。不仅科学揭示了秦直道“傍水分水岭、避高防低”的千古规划智慧,更利用最小代价路径与局部极值搜索算法,完美完成了现代地形下的路线与防御体系再造。
模型具有极强的泛化能力,不仅可直接应用于古代遗址的考古勘探与走向预测,其提取的“顺应地势、规避风险”特征提取与阻力寻优框架,对现代山区高速公路选线、高压电网走廊规划及油气管道铺设同样具有极高的工程参考价值。

六、 独家创新:v1.0 交互式三维 GIS 智能分析系统
为验证模型成果并实现工程级交付,本文自主研发了一套专业的 Web GIS 交互式分析平台,彻底打通了数据、算法与可视化的壁垒。
6.1 高性能系统架构设计
-
后端计算引擎:基于 Python FastAPI 框架构建,提供 20+ 个高性能 API 端点,支持栅格矩阵与矢量数据的毫秒级吞吐、算法实时调度与切片服务。
-
前端渲染引擎:采用 MapLibre GL JS 结合国内稳定的高德底图作为 2D 分析基础;采用 Plotly.js Surface Plot 对 282×339 真实 DEM 网格进行高逼真 3D 渲染。
6.2 平台六大核心分析模块
-
🗺️ 2D地图交互分析:支持 7 层地形因子(坡度、TPI等)的动态叠加与透明度调节;可通过滑动条实时调整代价权重,触发后端算法秒级重算路径,并提供交互式测距与横剖面提取。
-
🏔️ 3D数字沙盘:实现数字高程的 3D 曲面生成,支持自由旋转、缩放,新老路线完美贴地渲染,遗迹点三维悬浮标注。
-
🎨 多维地形图鉴:7 种核心特征因子图谱一屏全览,支持同步缩放与点击高亮,极大提升了空间对比分析效率。
-
📈 路径定量对比台:集成 9 项指标与 4 种动态图表,直观对比旧路线与多算法生成的新路线的“高程断面”、“坡度分布”与“累计爬升”差异。
-
🔥 设施视域模拟器:独创通视矩阵验证模块。用户点击任意规划的烽火台,系统镜头自动飞跃至该点,并动态渲染其有效视域(Viewshed)覆盖范围。
-
📊 统计图表生成器:一键生成论文所需的箱线图、密度图、雷达图,通过可视化手段对选线规律进行降维打击般的定量证明。
为了将上述数学模型和理论框架真正落地,下面为您提供核心算法部分的 Python 完整代码实现。
在处理此类空间数据挖掘与 GIS(地理信息系统)问题时,我们通常假设底层数据已经通过 rasterio 或 geopandas 读取为 numpy 数组或 pandas.DataFrame。本代码集主要围绕地形特征提取、Logistic偏好挖掘、最小代价路径(LCP)寻优、以及防御设施重组四个核心模块展开。
依赖库准备
Python
import numpy as np
import pandas as pd
from scipy.ndimage import uniform_filter, generic_filter
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from skimage.graph import MCP_Geometric
from scipy.signal import find_peaks
模块一:微地貌地形特征提取 (TPI, TRI, 坡度)
此部分代码基于高程矩阵(DEM)计算局部地形特征。我们使用 scipy.ndimage 进行高效的滑动窗口矩阵运算。
Python
def calculate_terrain_features(dem_array, cell_size=30, window_size=11):
"""
计算DEM栅格的地形特征(坡度、TPI、TRI、起伏度)
:param dem_array: 2D numpy array, 原始高程数据
:param cell_size: float, 栅格单元的实际物理分辨率(米)
:param window_size: int, 滑动窗口大小 (默认 11x11)
:return: 包含各项地形特征的字典
"""
# 1. 坡度 (Slope) 计算 - 采用三阶反距离平方权差分法
dy, dx = np.gradient(dem_array, cell_size, cell_size)
slope_rad = np.arctan(np.sqrt(dx**2 + dy**2))
slope_deg = np.degrees(slope_rad)
# 2. 地形位势指数 TPI (Topographic Position Index)
# TPI = 中心点高程 - 邻域平均高程
mean_elevation = uniform_filter(dem_array, size=window_size, mode='reflect')
tpi = dem_array - mean_elevation
# 3. 地形崎岖度 TRI (Terrain Ruggedness Index)
# 计算中心点与周围点的均方根差
def tri_filter(window):
center = window[len(window)//2]
return np.sqrt(np.mean((window - center)**2))
tri = generic_filter(dem_array, tri_filter, size=3, mode='reflect')
# 4. 起伏度 (Relief)
# 起伏度 = 窗口内最大值 - 最小值
def relief_filter(window):
return np.max(window) - np.min(window)
relief = generic_filter(dem_array, relief_filter, size=window_size, mode='reflect')
return {
'slope': slope_deg,
'tpi': tpi,
'tri': tri,
'relief': relief
}
模块二:空间选线偏好挖掘 (Logistic Regression)
该模块将真实的秦直道点(正样本)与随机生成的背景点(负样本)组合,通过逻辑回归挖掘选线偏好,并提取标准化系数。
Python
def mine_route_preferences(positive_df, negative_df, feature_cols):
"""
基于正负样本对比学习,挖掘路线规划偏好
:param positive_df: 真实路线点 DataFrame (y=1)
:param negative_df: 背景负样本点 DataFrame (y=0)
:param feature_cols: 用于建模的特征列名列表 (如 ['elevation', 'slope', 'dist_to_river', ...])
"""
# 1. 构建训练数据集
positive_df['label'] = 1
negative_df['label'] = 0
data = pd.concat([positive_df, negative_df], ignore_index=True)
X = data[feature_cols].values
y = data['label'].values
# 2. 特征标准化 (Z-score) - 消除量纲,使得回归系数可比
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 3. 训练 Logistic 回归模型
# class_weight='balanced' 用于处理正负样本可能存在的不平衡问题
lr_model = LogisticRegression(max_iter=1000, class_weight='balanced', random_state=42)
lr_model.fit(X_scaled, y)
# 4. 提取并分析回归系数
coefficients = lr_model.coef_[0]
print("====== 选线偏好定量分析 (标准化系数) ======")
for feature, coef in zip(feature_cols, coefficients):
preference = "偏好较大值" if coef > 0 else "偏好较小值"
print(f"特征: {feature:20s} | 系数: {coef:>7.4f} | 倾向: {preference}")
return lr_model, scaler
模块三:基于最小代价路径(LCP)的新路线规划
利用之前挖掘出的偏好原则,构建空间阻力面,并通过 skimage.graph 寻找累积代价最小的栅格路径。
Python
def replan_optimal_route(dem_array, prob_surface, river_distance_array, start_idx, end_idx):
"""
构建综合阻力面,并采用最小代价路径算法(LCP)重规划路线
:param dem_array: 原始高程栅格
:param prob_surface: Logistic模型预测的“适宜性概率”栅格面 (0~1)
:param river_distance_array: 距河网距离的栅格面 (米)
:param start_idx: 起点在栅格中的行列号索引 (row, col)
:param end_idx: 终点在栅格中的行列号索引 (row, col)
:return: 最优路径的坐标列表
"""
# 1. 构建综合阻力面 (Cost Surface)
# 适宜性概率越高,基础阻力越小
alpha = 5.0 # 概率权重因子
base_cost = np.exp(-alpha * prob_surface)
# 2. 施加强约束惩罚 (例如:距离河流过近,或者地形为绝对断崖)
penalty = np.zeros_like(dem_array)
# 距河流小于200米的地方,施加极大惩罚,迫使路线远离谷底
penalty[river_distance_array < 200] = 9999.0
# 最终阻力矩阵
cost_surface = base_cost + penalty
# 3. 使用 skimage 的 MCP_Geometric 进行栅格图论寻路 (类似A*/Dijkstra)
# MCP_Geometric 考虑了对角线移动的距离权重 (根号2)
print("开始计算全域累积代价矩阵...")
mcp = MCP_Geometric(cost_surface)
cumulative_costs, traceback_matrix = mcp.find_costs(starts=[start_idx])
# 4. 从终点回溯获取完整路径
print("代价计算完成,正在回溯最优路径...")
optimal_path_indices = mcp.traceback(end_idx)
return optimal_path_indices
模块四:军事防御设施重构 (烽火台与关隘算法)
基于重规划好的路线(转化为一维链程序列),利用贪心覆盖和局部极值搜寻军事节点的最优位置。
Python
def plan_military_facilities(route_df, visual_range_km=4.5):
"""
在重规划的新路线上部署烽火台和关隘
:param route_df: 包含重规划路线点的 DataFrame,需包含 ['chainage_km', 'TPI', 'TRI', 'slope', 'x', 'y']
:param visual_range_km: 烽火台的单向视距覆盖范围
:return: 烽火台和关隘的 DataFrame
"""
# ==========================
# 1. 烽火台布局:贪心视域覆盖算法
# 核心逻辑:确保链程上的预警盲区最小,且尽量选在局部 TPI (地形位势) 最高点
# ==========================
beacons = []
current_chainage = route_df['chainage_km'].min()
max_chainage = route_df['chainage_km'].max()
while current_chainage < max_chainage:
# 在当前节点前方 7~9 公里 (约 2倍视距) 范围内寻找下一个接力点
search_min = current_chainage + (visual_range_km * 1.5)
search_max = current_chainage + (visual_range_km * 2.0)
candidate_pool = route_df[(route_df['chainage_km'] >= search_min) &
(route_df['chainage_km'] <= search_max)]
if candidate_pool.empty:
break
# 在候选区间内,选择 TPI (相对高差) 最大的点作为烽火台
best_beacon = candidate_pool.loc[candidate_pool['TPI'].idxmax()]
beacons.append(best_beacon)
# 更新链程,继续向下搜寻
current_chainage = best_beacon['chainage_km']
beacons_df = pd.DataFrame(beacons)
# ==========================
# 2. 关隘布局:局部险要地形(TRI 极值)搜索算法
# 核心逻辑:关隘需要卡在地形最为崎岖、通道收束的“咽喉”要道
# ==========================
# 提取路线的 TRI (崎岖度) 序列
tri_sequence = route_df['TRI'].values
# 使用 scipy 的 find_peaks 寻找局部的 TRI 极大值峰
# distance=50 表示两个关隘在数据点序列上至少间隔一段距离,避免过度密集
# prominence=2.0 保证找到的确实是突出的“险要点”,而非微小平缓波动
peaks, properties = find_peaks(tri_sequence, distance=50, prominence=2.0)
# 将找到的峰值点提取出来
passes_df = route_df.iloc[peaks].copy()
# 进一步筛选:保留坡度较大的顶级险要点(比如选取坡度前 2 名作为主关隘)
passes_df = passes_df.sort_values(by='slope', ascending=False).head(2)
print(f"成功规划 {len(beacons_df)} 座烽火台,{len(passes_df)} 座关隘。")
return beacons_df, passes_df
💡 代码运行建议
-
真实比赛数据多为
.tif格式。请在上述框架前使用rasterio读取 TIFF 影像并获取dem_array与cell_size。 -
提取出
optimal_path_indices后,通过仿射变换矩阵(Affine Transform)可将行列号转回真实的经纬度或投影坐标系,最终导出为.shp文件或 GeoJSON 供可视化使用。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 11
11 0
0- 0



 已为社区贡献37条内容
已为社区贡献37条内容

所有评论(0)