清华团队发布机器人版“GPT时刻”:UniDex让机械手看懂世界,零样本操控万物!
80%成功率,碾压式超越现有方案,灵巧手操控迎来“GPT”时刻
 这篇论文用一种极其优雅且强大的方式,解决了机器人领域一个长期存在的根本性难题:如何让形态各异、复杂无比的灵巧手,像人类一样,看一眼就能学会使用各种工具?
这篇论文用一种极其优雅且强大的方式,解决了机器人领域一个长期存在的根本性难题:如何让形态各异、复杂无比的灵巧手,像人类一样,看一眼就能学会使用各种工具?
这篇论文的含金量极高,它不仅仅是一个算法,更是一整套从数据到模型、再到落地部署的“机器人基础套件”。看完它,你甚至会感觉,机器人大脑的“GPT时刻”,真的来了。
-
论文标题:UniDex: A Dexterous Robot Foundation Suite from Egocentric Videos
-
核心作者:Gu Zhang, Qicheng Xu, Haozhe Zhang等(来自清华大学、上海期智研究院、中山大学、北卡罗来纳大学教堂山分校)
-
论文链接:https://arxiv.org/pdf/2603.22264
-
官方链接:https://unidex-ai.github.io/
-
核心痛点:要让机器手学会精细操作,需要海量、多样、高质量的真实数据。但让人类去遥控机器人采集数据,成本高、速度慢,根本无法规模化。这就是阻碍灵巧手走向通用的最大瓶颈。
01 一个“机器人穷人”的困境:数据,全是数据!
想象一下,你想让家里的扫地机器人学会用剪刀。最直接的办法是什么?你拿个遥控器,手把手地教它。但问题是,你得先花几十万买一台带灵巧手的机器人,然后花几小时教它剪一次。等你教完剪A4纸,想教它剪快递盒,又得从头再来。这就是当前机器人学习的现状:极度昂贵、极度低效、极度依赖人工。
传统的做法,就是让人类专家用昂贵的设备“遥控”机器人,采集几十上百条演示数据,然后用这些“精贵”的数据去训练模型。结果就是,模型只会做那几件事,换个工具、换个位置,立马抓瞎。
论文里直接点出了一个更残酷的现实:大部分机器人基础模型都只关注简单的“夹爪”,而像我们人类一样拥有5根手指的“灵巧手”,相关的通用模型几乎为零。 但偏偏,我们日常生活中的工具(剪刀、喷壶、鼠标),都是为手设计的,夹爪根本玩不转。
那么问题来了,去哪找那么多高质量、多样化的灵巧手操控数据呢?
02 破解困局:从人类视频里“榨取”黄金数据
UniDex团队给出的答案堪称神来之笔:既然机器手是模仿人类手设计的,那为什么不直接向人类学习?
人类每天在YouTube、B站上分享着海量的第一人称(Egocentric)视频,做饭、修东西、玩魔方,这不就是最自然、最丰富、最免费的“操作教科书”吗?
但这里有个巨大的鸿沟:人类的手和机器人的手,长得不一样! 你不可能直接把视频里人类手指的角度,硬套到机器人的关节上。这就像让一只章鱼去模仿人类弹钢琴,光看视频是学不会的。
为此,UniDex团队设计了一套精妙绝伦的“人类-机器人”数据转换流水线,彻底填平了这个鸿沟:
-
动作模仿,先看指尖: 人类和机器人的手虽然结构不同,但都有一个共同点——指尖是接触物体的关键。团队把人类视频里“大拇指、食指、中指”等指尖的3D空间运动轨迹提取出来,作为机器人必须“跟上”的“金标准”。
-
人类“微调”,确保接触: 光对准指尖还不够,还得保证手和物体的接触是物理上合理的。团队开发了一个轻量级的图形界面,让人类可以像调音师一样,在关键帧上微调机器人的手腕位置,确保它的手指能“服帖”地握住物体。
-
视觉“伪装”,统一感知: 为了不让机器人被“人类的手”搞糊涂,他们直接用技术手段把视频里的人手“P”掉,然后把刚刚算好的机器人手模型“贴”进场景里。这样,机器人看到的画面就是“自己”的手在操作,视觉上的差异也消失了。
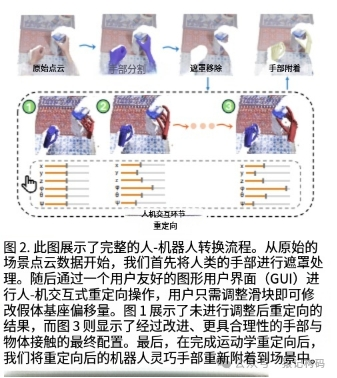
通过这套“人类-机器人”转换术,团队从H2O、HOI4D等四个开源数据集中,构建了全球首个横跨8种不同灵巧手(从6个自由度到24个自由度)、拥有超过5万条轨迹、900万帧数据的“机器人特供”大型数据集——UniDex-Dataset。
这相当于给机器人准备了一本包罗万象的“百科全书”,它学到的不是某一两只手的操作,而是所有手共同的、关于如何操作世界的底层规律。
03 统一语言FAAS:让不同“方言”的机械手能听懂同一句话
有了海量数据,下一个难题是:如何让一个模型,能指挥风格迥异的机械手?这就像你准备了一本中文教材,却要去教一个说英语、一个说法语、一个说德语的学生,他们各自的口音(关节结构)完全不同。
传统的做法是,每个手都要单独训练一个模型。UniDex再次祭出妙招,他们设计了一个统一动作空间——FAAS(Function-Actuator-Aligned Space,功能-执行器对齐空间)。
这个想法的核心极其巧妙:别管每个机械手的关节叫什么、怎么转,只看它的“功能”是什么。 比如,所有机械手都有一个负责“捏合”的功能(比如拇指和食指的相对运动),那么不管这个功能在A手上是由两个关节实现的,还是在B手上是由三个关节实现的,在FAAS里,它都被映射到同一个“槽位”上。

FAAS就像一个“同声传译官”,它把每个机械手那套独特的“关节方言”,实时翻译成一套全世界通用的“功能普通话”。比如,所有手想要“捏”一下,在FAAS里就是一个统一的指令。
这个设计的伟大之处在于:它让模型学到的技能,可以“零样本”地迁移到任何新手上。 就像你学会骑自行车后,给你一辆电动滑板车,你也能很快上手,因为它们背后的“操控功能”是相通的。
04 UniDex-VLA:机器人界的“GPT-4o”
当海量数据(UniDex-Dataset)遇到统一语言(FAAS),UniDex-VLA模型就顺理成章地诞生了。这是一个3D视觉-语言-动作(VLA)模型,它就像机器人大脑的“GPT-4o”。
它的工作流程可以想象成这样:
-
看: 机器人的“眼睛”(RGB-D相机)看世界,生成一个带颜色的3D点云(
Pt)。这比普通的2D图片包含了更丰富的几何信息。 -
听: 你给它下达指令(
ℓt),比如“把水壶里的水倒进咖啡滤杯”。 -
感知自身: 它知道自己当前的手是什么姿势(
qt)。 -
思考与预测: UniDex-VLA模型(基于强大的3D视觉编码器Uni3D和流匹配生成模型)会把看到的3D场景、听到的指令、感受到的自身姿态综合起来,直接预测出未来一段时间的动作序列(
At)。 -
动: 机器人按照预测的动作序列,用FAAS这个“通用语言”指挥它的机械手去执行。
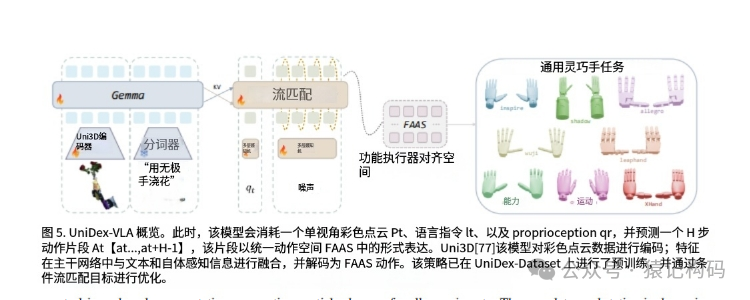
整个过程行云流水,模型真正做到了“所见即所得,所思即所动”。
05 实验结果:一场降维打击
光说不练假把式。UniDex团队在真实机器人上,设计了5个极具挑战性的工具使用任务,涵盖了两个不同品牌、不同结构的灵巧手(Inspire手和Wuji手):
-
做手冲咖啡:不仅要抓住水壶,还得稳稳地悬空倒水。
-
扫地:抓住扫帚,把桌上的垃圾扫进簸箕里。
-
浇花:抓住喷壶,还要用大拇指按下喷头。
-
剪袋子:用三根手指像人一样拿起剪刀,剪开袋子。
-
用鼠标:像人一样把手放在鼠标上,拖动并点击文件。
结果如何?我们来直接看数据:
|
算法 |
平均任务成功率(5个任务平均) |
最佳任务(剪袋子)提升 |
|---|---|---|
| UniDex-VLA (本文) | 81% | 84.6% |
| π0 (最强基线,VLA模型) |
38% |
- |
| UniDex-VLA (无预训练) |
31% |
- |
| 3D Diffusion Policy (DP3) |
25% |
- |
从这张表可以看得清清楚楚:UniDex-VLA以81%的平均成功率,碾压了所有其他基线方法。在难度最高的“剪袋子”任务上,它甚至比最强的基线方法π0提升了84.6%!这已经不是进步,而是降维打击了。
更令人惊叹的是它的泛化能力:
-
空间泛化:把咖啡壶和滤杯放到训练时从未见过的位置,UniDex-VLA依然能从容应对。
-
物体泛化:把黑色的水壶换成更小的紫色水壶,它照样能识别并完成倒水。
-
零样本手泛化:这是最惊艳的部分!把在Inspire手上训练好的“做咖啡”模型,直接部署到结构完全不同的Wuji手和Oymotion手上,一次都不用微调。结果,Oymotion手成功率60%,Wuji手成功率40%。这在以前想都不敢想,完全是“学会了骑自行车,就能骑摩托车”的水平。
06 反常识的思考:为什么“假数据”比“真数据”还好用?
看到这里,你可能会有一个巨大的疑问:用从人类视频里“变”出来的数据(假数据)去预训练模型,真的比用真实机器人数据(真数据)更好吗?
论文的实验给出了一个反常识的结论:是的!而且“假数据”和“真数据”结合,效果能达到最优。
这背后的逻辑是什么?UniDex-VLA的核心思想在于学习“操作的本质”,而不是“某个具体机械手的动作”。
人类视频提供了“操作的本质”——在杂乱环境中,如何用手和物体互动,如何用力,如何适应不同的工具。这是关于“目的”和“策略”的知识。
而真实机器人数据,则提供了“执行的细节”——在特定的机械手上,要输出多少扭矩,关节要转到多少度。这是关于“手段”和“控制”的知识。
UniDex-VLA通过在海量“假数据”上预训练,先学会了“应该怎么做”的通用智慧。然后,它只需要很少的“真数据”进行微调,就能学会“在我的手上该怎么做”的具体技能。两者结合,自然能力超群。
07 工程落地:不仅要“会”,还要“快”和“省”
UniDex不仅在算法上创新,在工程落地层面也考虑得非常周全,论文中提到了几个关键点:
-
推理速度:模型预测一个动作序列只需几十毫秒,完全可以满足实时控制的需求。
-
部署成本:整个系统仅需一个普通的RGB-D相机(如Intel RealSense L515)和一个机器人臂。他们甚至设计了一个便携式数据采集设备UniDex-Cap,结合了Apple Vision Pro的头显和RealSense相机,让普通人也能轻松采集自己的动作数据,然后“投喂”给机器人。这大大降低了数据采集的门槛。
-
人机协同训练:他们发现,用UniDex-Cap采集的人类数据,和真实机器人数据以2:1的比例混合训练,效果可以媲美只用真实数据。但采集一个人类演示的速度,比采集一个真实机器人演示快5.2倍。这意味着,你原本需要花100万买1000条机器人数据,现在可能只需花20万买200条机器人数据和400条人类数据,就能达到同样的效果。这简直是“花小钱,办大事”的典范!
08 行业意义与展望:机器人学习的新范式
UniDex这篇论文,在我看来,最大的价值在于它开辟了一条通往通用灵巧操作的、可规模化的康庄大道。
它打破了行业的两个固有思维:
-
“数据必须来自机器人”:它证明了,海量的、免费的人类视频,才是机器人学习的真正宝藏。
-
“一个模型只能服务一种硬件”:它证明了,通过一个统一的动作空间,一个模型可以零成本地适配任何灵巧手,真正实现“一次训练,到处部署”。
它把机器人学习从一个昂贵的、依赖手工调参的“手工艺”,变成了一个可以利用互联网海量数据、进行大规模预训练的“现代工业”。
正如论文最后所展望的,他们目前还未充分利用那些没有动作标签的海量视频,这将是未来继续“喂大”机器人脑容量、迈向真正AGI的必然方向。
最后,我想用论文中的一个类比来结尾:
如果说,当前绝大多数机器人模型,是在“背诵”一套固定的体操动作;那么,UniDex-VLA,就是让机器人学会了如何用身体去理解和表达“语言”。当它读懂了“倒水”、“扫地”、“剪开”这些词背后的物理世界,它才真正拥有了在这个世界上自由行动的能力。
这,才是通往通用人工智能的必经之路。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 4
4 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)