小白必看!收藏这份AI核心术语「词元」指南,解锁大模型终极密码
导语:2026年3月,国家数据局正式将 AI 领域的 Token 统一译名为“词元”。这个新闻一出,很多非技术背景的朋友可能一头雾水:之前的“令牌”、“标记”怎么就变成“词元”了? 它和语文课本里的“词语”是一回事吗? 为什么我输入“我今天吃了甜甜的苹果”(11个字),AI 后台却提示我消耗了 7 个词元?
如果你平时用 AI 聊天、写方案、画图,却还没搞懂“词元”是什么,那你可能只看到了 AI 的冰山一角 。今天,我们拔掉晦涩的技术术语,从“系统优化”的硬核视角,带你重新认识“词元”这个藏在 AI 大脑深处的终极密码。
一、 到底什么是词元(Token)?—— 优化视角下的“最优拆分”
从优化视角出发,我们给词元一个更精准的定义:
词元(Token)是 AI 处理语言、图像等信息时,拆分出来的最小且最优的处理单元 。
这里的“最优”绝非随意定义,它的核心目标是让 AI 在执行“下一个词元预测(next token prediction)”以及其他各类学习任务时,实现性能的最优解:
- 最小: 指的是不能再继续拆分了。如果再拆,就会失去语义,导致 AI 无法准确预测下一个词元 。
- 最优: 指的是这种拆分方式,能让 AI 在预测任务中,以最低的算力成本,获得最高的准确率 。
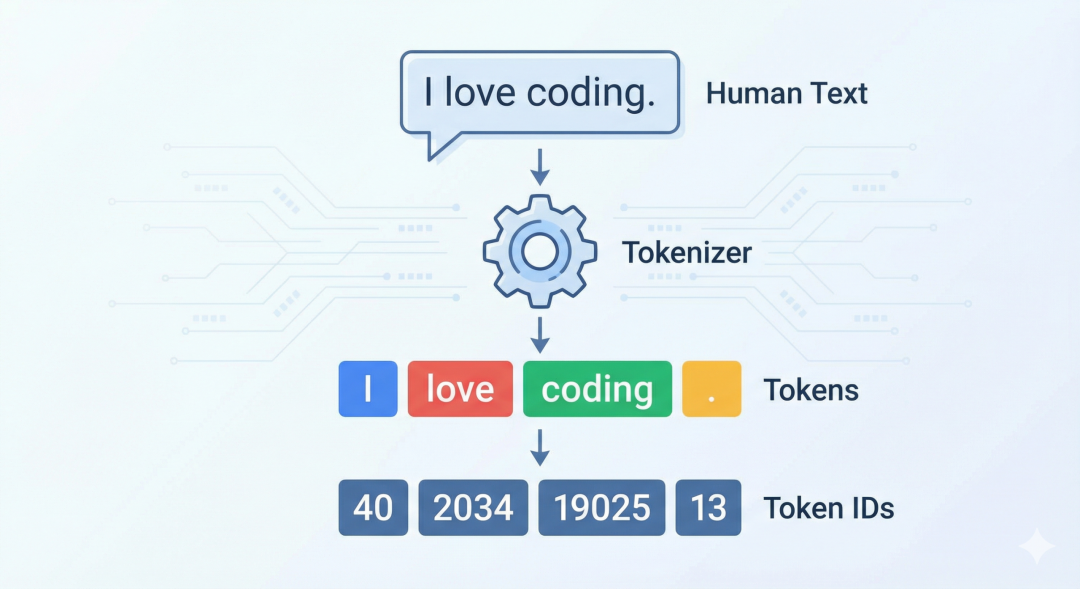
它根本不是语文里的“一个字”或“一个词语”,而是 AI 的“分词器”(拆分工具)严格根据“性能最优”原则,切分出来的语义小块 。其拆分逻辑完全服务于 AI 的学习和预测任务 :
- 🍎 常用词、高频语义组合(直接打包): 比如中文的“苹果”、“今天”,英文的“love”、“apple”。这类组合出现频率极高、语义完整,直接打包成一个词元能大幅减少计算量,让 AI 预测时更高效 。例如,看到“苹果”,AI 能快速预测后续可能是“好吃”或“手机”,而不是把它拆开后逐个单字去预测 。
- 🧩 生僻词、新词、长单词(拆成有意义的片段): 比如网络热词“绝绝子”会被拆成 绝绝/子,英文长词“unhappiness”会被拆成 un/happi/ness 。这样拆分的核心目的,是让 AI 即便没见过这个完整的生僻词,也能通过片段的语义准确预测下一个词元 。比如看到“un”,AI 就能联想到否定含义,预测后续可能是“happy”或“lucky”,避免了因“不认识生词”而直接预测失败 。
- ❗️ 标点、空格、数字(单独算作词元): 这类符号虽然没有复杂的语义,但会直接影响句子结构和语气 。单独拆分能让 AI 更准确地捕捉语境,避免因忽略符号导致偏差。比如看到“!”,AI 就能预测后续的语气可能会更加强烈 。
💡 举个直观的例子: 我们看到的一句话:“我今天去公园玩,很开心!” AI 的最优拆分(词元)是:我/今天/去/公园/玩/,/很/开心/!(共 9 个词元) 。
为什么不拆成单字(10个单元)?因为单字没有完整语义,AI 预测下一个字时不仅准确率低,计算量还特别大 。 为什么不拆成“我今天/去公园/玩,很开心/!”(4个单元)?因为拆分得太粗了,AI 无法精准捕捉每个动作的具体逻辑,预测后续内容时就容易跑偏 。 这 9 个词元的拆分,刚好实现了“语义准确 + 计算高效”的最优平衡,让 AI 猜得又准又快 。**

二、 词元的溯源:从“能用”到“最优”的进化史
词元的发展,本质上是一部 AI 信息处理方式“追求性能最优”的进化史 。从早期的勉强“能处理”,逐步迭代到现在的“处理最优”,每一次升级都紧紧围绕着“提升预测任务性能”展开 :
-
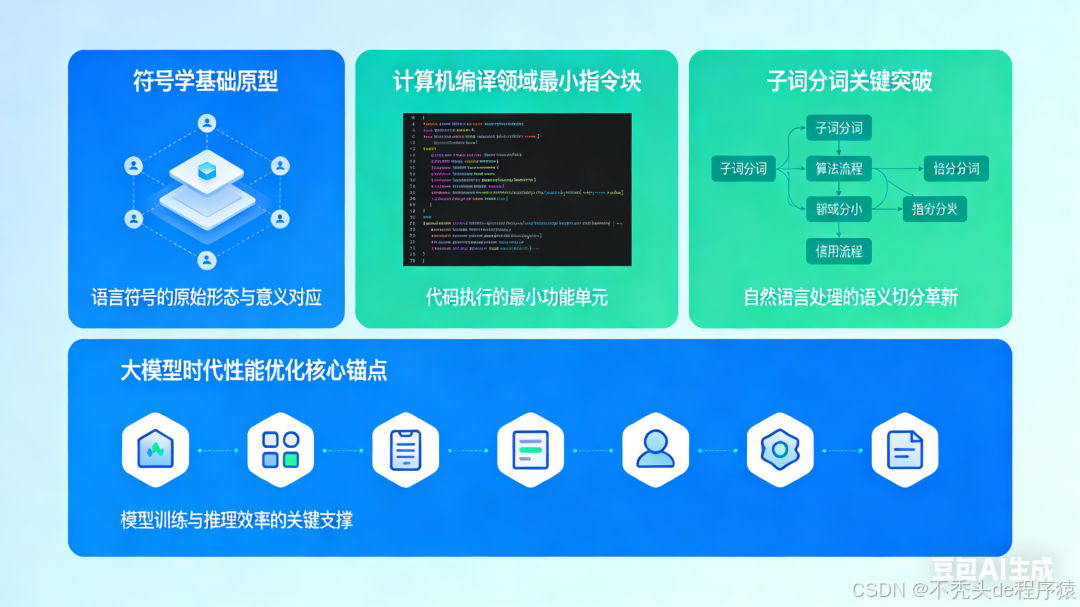
最早起源:符号学的“基础原型”(无优化目标) Token 的词源是古英语 tācen,本意就是符号、标记 。1906年,美国符号学创始人皮尔士将其定为学术概念,分为 Type(抽象符号原型) 和 Token(具体实例) 。比如连续说3遍“我”,1个 Type 就对应了 3个 Token 。此时的 Token 仅仅是语言分析工具,毫无“优化 AI 性能”的概念,只是为了描述符号的具体出现形式 。
-
第一次落地:计算机编译领域的“最小指令块”(初步优化效率) 上世纪五六十年代,计算机开始处理代码 。程序员写的代码必须被拆分成“最小可执行指令块”,这些块就被命名为了 Token 。比如代码 if a>10,必须拆成 if / a / > / 10 这 4 个 Token,计算机才能高效执行 。此时,Token 的核心目标变成了“提升指令执行效率”,这和今天 AI 的词元逻辑已经一脉相承——都是通过“最优拆分”来降低计算成本、提升速度 。
-
关键突破:解决“AI 预测不准”的子词分词(核心优化预测性能) 早期让 AI 处理人类语言时,有两种极端的拆分方式,但都无法实现“性能最优” :
- 按单字/字母拆分(最小但不最优): 语义极其碎片化,AI 无法捕捉完整含义,导致预测准确率极低,且计算量巨大 。比如把“苹果”拆成“苹/果”,AI 根本无法联想到水果或手机,后续预测极易出错 。
- 按完整词语拆分(最优但不最小): 语义确实完整了,但人类词汇量是无限的(中文常用词几十万,英文超百万,还在不断造新词) 。AI 的“词库”根本装不下,一旦遇到新词就无法预测,直接“宕机” 。
2015年,行业迎来了关键突破:子词分词(也就是现在的词元逻辑) 。它既不全拆成单字,也不全保留整词,而是根据“语义关联性”和“预测效率”,将经常一起出现的字词组合固定下来,把生僻词拆成有意义的子词 。这种方式既保证了语义完整(猜得准),又控制了词库数量(装得下),彻底解决了预测不准和处理新词的难题,这也是词元成为 AI 核心的关键原因 。
- 大模型时代:成为“性能优化的核心锚点”(全面优化) 2017年 Transformer 架构问世后,大模型彻底爆发,词元正式成为 AI 性能优化的核心锚点 。如今,所有大模型的训练、对话和生成,全部围绕“词元优化”展开:优化分词规则让拆分更合理,优化语义档案让预测更精准,优化处理效率让计算更飞速 。同时,全球 AI 厂商统一采用“按词元用量收费”,这本质上就是“按优化后的处理单元”在计价 。词元用得越少、效率越高,成本就越低,这就是“最优处理单元”在商业上的最直观体现 。**
三、 底层逻辑:为什么“最小且最优”是 AI 的唯一选择?
AI 本质上是一个超级计算器,它只认数字,不认文字 。词元的核心价值,就是要在“人类语言”与“机器数字”之间,搭建起一座“性能最优”的桥梁——既要保证 AI 准确理解语义,又要保证计算效率最高、成本最低 。这是 AI 处理信息的“最优解”,没有之一 。
用 3 句大白话,帮你讲透这份“最优逻辑” :
-
词元是“语义+数字”的最优转换载体 每个词元都对应一个唯一的数字编号(比如“你好”=1234,“世界”=5678) 。一句话必须先拆成最优词元,再转换为数字,AI 才能开始计算 。这种转换方式,既避免了按单字转换带来的“语义丢失”,又避免了按整词转换带来的“数字冗余”,完美兼顾了“准”和“快” 。
-
不选单字:为了避免“低效且不准”的无用功 如果把每个汉字、英文字母当最小单元,就像用一粒粒散沙去盖房子:效率极低(每个单元都没语义,AI 要反复算才能联想含义),且极不准确(无法捕捉全局语义,极易跑偏) 。比如英文“unhappiness”拆成 11 个字母,AI 得处理 11 次计算,还没法理解“否定+开心+名词”的意思 ;而拆成 un/happi/ness 3 个词元,AI 只需算 3 次,就能通过片段准确预测后续内容(比如 “is”, “makes”),效率和准确率双重飙升 。
-
不选整词:为了避免“无法承载且不灵活”的瓶颈 人类每天都在发明新词。如果把每个整词当处理单元,AI 的词库会无限膨胀,根本装不下,遇到没见过的生词直接瘫痪,这就违背了“性能最优”的任务目标 。而词元系统仅需 3 万到 50 万个固定词元,就能像搭积木一样组合出所有可能的文字 。哪怕遇到全新词汇,拆成词元片段后 AI 照样能预测后续,既极度灵活,又完美控制了成本 。

四、 AI 是怎么靠词元变聪明的?—— 学习与优化机理
我们常说“大模型越训练越聪明” 。从优化视角看,大模型的学习,本质上就是不断优化词元的拆分逻辑、语义关联和使用效率,让预测任务的表现越来越优 。简单来说,就是让 AI 猜下一个词元时:准确率越来越高,算得越来越快,犯错越来越少 。
这套靠词元优化性能的体系,包含 4 个核心环节 :
-
优化词元的“语义档案”:让预测更准 每个词元除了数字编号,还有一份极其详细的“语义档案”,记录着它的含义、常搭配的词元以及使用语境 。大模型的优化,就是不断充实这份档案 。比如“苹果”这个词元,AI 会逐步明确:它既可以是水果(常搭配“吃/甜/新鲜”),也可以是手机品牌(常搭配“iPhone/乔布斯/发布会”) 。档案越清晰,AI 在预测下一个词元时,就能根据上下文精准切换频道,减少错误判断 。
-
优化词元的“排列规律”:让预测更快 人类语言的本质就是词元的排列组合 。大模型在阅读了几千亿、几万亿个词元后,摸透了规律 。比如它学到“床前明月”后面跟“光”的概率极大;学到“我想吃”后面跟“苹果”或“米饭”的概率更高 。一旦摸清了这些规律,AI 就减少了海量的无效计算,直接从“慢慢思考”变成了“精准快速秒答” 。
-
优化词元的“权重分配”:让效率更高 文本中大约有 80% 的词元是冗余的(比如“的、地、得”、标点、词缀),只有 20% 是决定预测准确率的“关键信息词元”(核心名词、动词) 。AI 的优化方向之一,就是给关键信息分配极高的权重 。比如处理“我今天在公园吃了一个甜甜的苹果”时,AI 会把算力集中在“公园”、“吃”、“苹果”上,直接忽略“的”、“了”、“一个”等冗余词元。这既保证了极高的准确率,又大幅节省了算力成本 。
-
优化词元的“记忆长度”:减少“胡说八道” AI 的“短期记忆”取决于它的上下文窗口(一次能处理的词元数量) 。如果记忆太短,前面说过的话它转头就忘,自然会跑偏并产生“幻觉” 。如今大模型的核心发力点,就是疯狂拉长记忆长度:从最早只能记几千个词元,升级到现在能一口气处理几十万、上百万个词元 。现在 AI 能一次性读完一整本书而不忘掉前面的剧情,这极大提升了预测的可靠性,让输出更精准 。
—**

五、 词元的优化价值:它到底怎么影响我们?
词元的“最优拆分”绝对不是高高在上的技术概念,它正实实在在地影响着 AI 行业的发展,以及我们每个普通人的使用体验 。
(一)对 AI 行业从业人士:这是核心竞争力
对业内人士而言,词元的优化能力直接决定了产品的生死、成本与竞争力 :
- 👨💻 AI 开发者与算法工程师: 分词规则的优化是研发的第一步。如果规则优化得好,同样的模型训练速度能提升 30% 以上,算力成本直接砍半,且预测准确率更高 。比如专门针对中文语境优化分词器,避免语义偏差,这就是国产大模型最硬核的竞争壁垒 。
- 👩💼 产品经理与运营: 词元直接决定了产品的体验和定价 。窗口长度(记忆长度)决定了能不能处理长文档;处理速度决定了 AI 回复的快慢;词元消耗成本则直接决定了产品卖多少钱 。他们每天都在性能与成本之间寻找最优平衡点 。
- 🏢 企业用户与创作者: 懂逻辑才能降本增效 。用最精简的词元说清需求,不仅能减少消耗,还能让 AI 更快更准地响应;控制内容长度不超限,能避免跑偏 。这直接关乎企业的真金白银和创作者的创作效率 。
- 🌐 整个行业: 词元催生了全新的商业模式——“按用量收费” 。它就像水电气一样,用多少词元付多少钱,大幅降低了使用门槛。英伟达 CEO 黄仁勋那句著名的“数据中心是 Token 生产工厂”,本质上就是对词元核心商业价值的最高盖章 。
(二)对一般公众:让 AI 更好用、更便宜
对于普通大众,词元优化带来的红利肉眼可见 :
- 💰 使用成本更低: 算力消耗减少了,大厂的收费自然跟着降。现在的免费版额度越来越大,付费版越来越便宜,这都是词元优化的功劳 。
- ⚡ 回答更准、更快: 语义和规律优化得好,AI 就能更精准理解你的意思,且回复速度飞快,告别漫长等待 。
- 🗣 交流更顺畅: 懂了逻辑,你就会学会精简提问。用最少的词元聚焦关键信息,既省钱又精准;遇到长话题时,偶尔重复一下关键信息,就能帮 AI 唤醒记忆,聊得更加顺畅 。
- 🧠 认知更理性: 懂了词元,你就会恍然大悟:AI 并不是真的“懂”人话,它只是通过极致的优化规律,在精准预测下一个词元罢了 。这能让我们更理性地使用这个强大的工具,在它遇到没学过的内容而犯错时,多一份理解 。
六、 扫雷:关于词元的 3 个常见误区**
**❌ 误区一:词元就是字数,1 个汉字 = 1 个词元。
- ✅ 真相:错! 词元是“最优拆分”,绝非按字数死板对应 。在中文里,像“苹果”这样一个常用词可能只对应 1 个词元;而生僻字或特定标点,1 个字符可能就会被拆成 1-2 个词元。一切为了预测性能,而不是凑字数 。
- ❌ 误区二:所有 AI 的词元拆分规则都一模一样。 ✅ 真相:错! 不同的大模型(比如各家国产大模型)有着各自的“分词器” 。因为大家的优化侧重点不同(有的侧重准确率拆得细,有的侧重效率拆得粗),所以同一句话,不同 AI 拆出的数量和方式可能完全不同,但目标都是为了实现自身的“最优” 。
❌ 误区三:词元只适用于文字 AI。 ✅ 真相:错! 词元的优化逻辑已经统一了生成式 AI 的大江湖 。AI 画图时,图片被拆成了“视觉词元”;AI 生成视频时,画面被拆成了“动态词元” 。万事万物,皆可被拆分为最优单元供 AI 学习,词元已经是整个生成式 AI 的核心基础 。**
结语
从国家统一“词元”译名、消除公众对这一AI核心术语的困惑,到深入解读其“最小且最优处理单元”的本质,我们不难发现:词元从来不是晦涩的技术名词,而是贯穿AI学习、优化与应用全流程的核心纽带。它的存在,本质上是AI追求“高效、精准、低成本”的必然选择——通过最优拆分,让AI在下一词元预测等任务中持续提升性能,既支撑着AI行业的技术迭代与商业模式创新,也实实在在改善着每一个普通人的AI使用体验。
理解词元,不仅能让我们更理性地看待AI的“聪明”与局限,明白其核心是对词元规律的优化与预测,也能让行业从业者找准核心竞争力,让普通公众更好地利用AI、降低使用成本。随着AI技术的不断发展,词元的优化逻辑还将持续迭代,成为推动生成式AI向更高效、更精准、更普惠方向发展的重要力量,而我们对词元的认知,也将伴随技术进步,不断走向深入。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发# 普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。
希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容
-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
vx扫描下方二维码即可
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集
从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)
新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)
07 deepseek部署包+技巧大全
由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!# 普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。
希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容
-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
vx扫描下方二维码即可
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集
从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)
新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)
07 deepseek部署包+技巧大全
由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)