基于yolo26+pyqt5实现多个注意力机制的102种花卉识别系统python源码+数据集+训练好模型+精美GUI界面
🌸 基于 YOLO26 的花卉图像分类系统
集成多种注意力机制,支持 102 类花卉的高精度自动识别,提供完整训练流程与可视化 GUI 界面。
界面展示
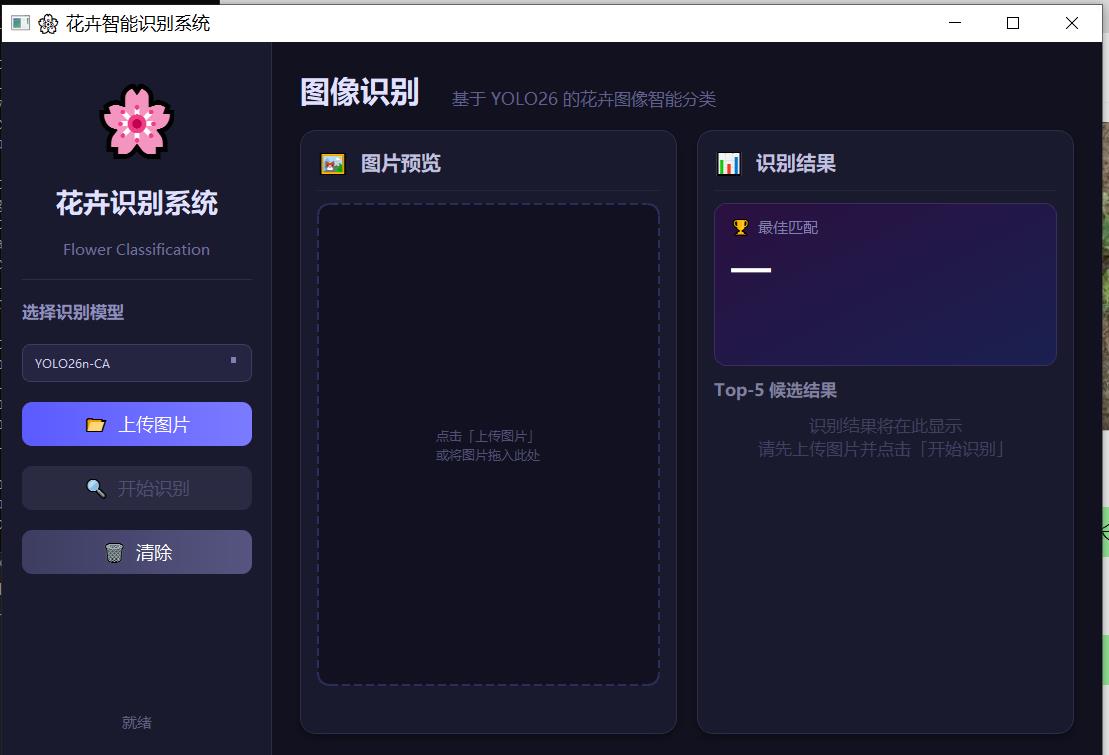
识别效果

目录
项目概述
本项目基于 Ultralytics YOLO26(定制版分类骨干网络),在 Oxford 102 Flowers 数据集上进行花卉图像分类研究。项目核心贡献是系统性地将 6 种主流注意力机制(SE、CBAM、CA、ECA、GAM、SimAM)集成到 YOLO26 网络中,并通过实验对比各机制在花卉分类任务中的效果。
关键特性:
- 支持 102 种花卉类别的自动识别(中英文双语标签)
- 集成 6 种注意力机制,可通过配置文件灵活切换
- 提供 PyQt5 可视化 GUI,一键上传图片即可完成识别
- 全流程脚本支持:数据划分 → 模型训练 → 性能评估
系统原理
整体架构
输入图片
│
▼
┌─────────────────────────────────────┐
│ YOLO26 骨干网络 │
│ Conv → C3k2 → 注意力模块 → SPPF │
└─────────────────┬───────────────────┘
│ 特征图
▼
┌─────────────────────────────────────┐
│ 分类头 (Classify) │
│ GAP → Dropout → Linear │
└─────────────────┬───────────────────┘
│ Softmax 概率分布
▼
Top-1 / Top-5 预测
│
▼
映射 flower102.json
│
▼
中英文花卉名称输出
YOLO26 分类网络
YOLO26 是在 YOLOv8 架构基础上改进的轻量化网络。用于分类任务时,去掉检测头,替换为全局平均池化(GAP)+ 全连接分类层:
| 阶段 | 模块 | 说明 |
|---|---|---|
| 输入 | Conv(3, 16, 3, 2) | 初始下采样,提取底层纹理特征 |
| 骨干 | C3k2 × 4 | 跨阶段部分网络,提取多尺度语义特征 |
| 增强 | 注意力模块 | 对关键通道/空间区域加权(可选) |
| 颈部 | SPPF | 空间金字塔池化,聚合多感受野信息 |
| 头部 | Classify | GAP → Dropout(0.0) → Linear(→102) |
注意力机制模块
注意力机制的核心思想是让网络「聚焦」于对分类最有判别力的特征区域,抑制无关背景噪声。
SE(Squeeze-and-Excitation)
输入特征图 [B, C, H, W]
│ 全局平均池化
▼
[B, C, 1, 1]
│ FC(C → C/r) → ReLU → FC(C/r → C) → Sigmoid
▼
通道权重 [B, C, 1, 1]
│ 逐元素乘法
▼
加权特征图 [B, C, H, W]
SE 通过对每个通道进行全局压缩后用全连接层学习通道重要性权重,再对原特征图逐通道缩放。
CBAM(Convolutional Block Attention Module)
在 SE 通道注意力的基础上,串联一个空间注意力模块:
输入 → 通道注意力(SE-like)→ 空间注意力(7×7 Conv + Sigmoid)→ 输出
空间注意力对特征图每个位置的重要性进行评估,使网络同时关注「哪些通道」和「哪些位置」。
CA(Coordinate Attention,坐标注意力)
将全局平均池化分解为水平与垂直两个方向的池化,分别捕获 X、Y 方向的位置感知信息,再融合生成空间感知的通道权重,保留了更丰富的位置信息。
ECA(Efficient Channel Attention)
用 1D 卷积 替代 SE 中的全连接层完成通道交互,仅用极少参数实现跨通道依赖建模,兼顾效率与效果。
GAM(Global Attention Module)
依次对通道维度(MLP)和空间维度(卷积)进行注意力建模,通过残差连接保留原始信息,擅长捕获全局上下文关系。
SimAM(Simple Attention Module)
基于神经科学的抑制原理,无需额外参数,通过计算每个神经元的活跃度与周围神经元的差异来自适应分配权重,是最轻量的注意力方案。
推理与类别映射
模型输出 102 维 Softmax 概率向量,索引从 0 到 101 对应 flower102.json 中的 c0 到 c101:
# 示例:模型预测索引 73
key = f"c{73}" # → "c73"
label = flower102["c73"] # → "rose,玫瑰"
en_name, cn_name = label.split(",") # → "rose", "玫瑰"
模型性能
以下为在测试集上的评估结果(图像尺寸 320×320):
| 模型 | 参数量 | 推理时间 | FPS | Top-1 准确率 | Top-5 准确率 | F1 值 |
|---|---|---|---|---|---|---|
| YOLO26n(基线) | 1.66 M | 3.16 ms | 316 | 98.04% | 99.90% | 0.980 |
| YOLO26n + CBAM | 1.67 M | 3.76 ms | 266 | 77.94% | 93.63% | 0.770 |
| YOLO26n + SE | 1.67 M | 3.87 ms | 259 | 77.25% | 93.43% | 0.763 |
| YOLO26n + CA | — | — | — | — | — | — |
| YOLO26n + ECA | — | — | — | — | — | — |
| YOLO26n + GAM | — | — | — | — | — | — |
| YOLO26n + SimAM | — | — | — | — | — | — |
详细图表见
performance_reports/目录。
项目结构
flower_classification-main/
├── dataset/ # 数据集(train / val / test)
│ ├── train/
│ ├── val/
│ └── test/
├── ultralytics/ # 定制化 YOLO26 框架
│ ├── cfg/models/26/
│ │ └── Att_yaml/ # 注意力机制模型配置
│ │ ├── yolo26-SE-cls.yaml
│ │ ├── yolo26-CBAM-cls.yaml
│ │ ├── yolo26-CA-cls.yaml
│ │ ├── yolo26-ECA-cls.yaml
│ │ ├── yolo26-GAM-cls.yaml
│ │ └── yolo26-SimAM-cls.yaml
│ └── nn/Attmodules/ # 注意力机制实现
│ ├── SE.py
│ ├── CBAM.py
│ ├── CA.py
│ ├── ECA.py
│ ├── GAM.py
│ ├── SimAM.py
│ └── ...(其他模块)
├── weights/
│ └── trained_weights/ # 已训练好的权重文件
│ ├── yolo26n_flower_cls_model.pt
│ ├── yolo26n_SE_flower_cls_model.pt
│ ├── yolo26n_CBAM_flower_cls_model.pt
│ ├── yolo26n_CA_flower_cls_model.pt
│ ├── yolo26n_ECA_flower_cls_model.pt
│ ├── yolo26n_GAM_flower_cls_model.pt
│ └── yolo26n_SimAM_flower_cls_model.pt
├── performance_reports/ # 性能对比图表与报告
├── runs/ # 训练过程记录
├── train_logs/ # 训练日志文件
├── flower102.json # 102类花卉中英文标签映射
├── flower_ui.py # PyQt5 可视化界面(主入口)
├── split_dataset.py # 数据集划分脚本
├── train_model.py # 模型训练脚本
├── model_comparison.py # 性能对比评估脚本
├── train_logs.py # 训练日志工具
├── requirements.txt # 依赖列表
└── pyproject.toml # 项目构建配置
环境安装
前置要求
| 依赖 | 版本要求 |
|---|---|
| Python | ≥ 3.8 |
| CUDA(可选,推荐) | ≥ 11.1 |
| pip | ≥ 21.0 |
第一步:克隆项目
git clone <仓库地址>
cd flower_classification-main
第二步:创建虚拟环境(推荐)
# 使用 conda
conda create -n flower_cls python=3.10 -y
conda activate flower_cls
# 或使用 venv
python -m venv venv
# Windows
venv\Scripts\activate
# Linux / macOS
source venv/bin/activate
第三步:安装 PyTorch
请根据你的 CUDA 版本选择对应命令(访问 https://pytorch.org 获取最新命令):
# CUDA 11.8
pip install torch torchvision --index-url https://download.pytorch.org/whl/cu118
# CUDA 12.1
pip install torch torchvision --index-url https://download.pytorch.org/whl/cu121
# 仅 CPU
pip install torch torchvision
第四步:安装项目依赖
# 以开发模式安装项目本体(包含定制 ultralytics)
pip install -e .
# 安装额外依赖
pip install -r requirements.txt
# 安装 PyQt5(GUI 界面必需)
pip install PyQt5
验证安装
python -c "import torch; print('PyTorch:', torch.__version__); print('CUDA 可用:', torch.cuda.is_available())"
python -c "from ultralytics import YOLO; print('YOLO26 加载成功')"
python -c "from PyQt5.QtWidgets import QApplication; print('PyQt5 安装成功')"
快速开始
图形界面(推荐)
直接运行 GUI 界面,无需任何额外准备,项目已内置 7 个预训练权重:
python flower_ui.py
使用步骤:
- 在左侧下拉框选择识别模型(默认推荐使用
YOLO26n基线模型) - 点击「📂 上传图片」选择一张花卉图片(支持 JPG、PNG、BMP、WebP)
- 点击「🔍 开始识别」,等待片刻
- 右侧将显示 Top-1 最佳匹配(中英文花名 + 置信度)及 Top-5 候选结果
也支持将图片拖拽到预览区域直接加载。
数据集准备
本项目使用 Oxford 102 Flowers 数据集,需要手动下载并放置到 dataset/ 目录(已按 train/val/test 划分)。
若数据集未划分,使用以下脚本自动划分:
python split_dataset.py
数据集目录结构要求:
dataset/
├── train/
│ ├── 类别名称1/
│ │ ├── img_001.jpg
│ │ └── ...
│ └── 类别名称N/
├── val/
└── test/
模型训练
在 train_model.py 末尾的 __main__ 块中指定要训练的模型配置,然后运行:
python train_model.py
训练指定注意力模型:
修改 train_model.py 第 195 行,指定 yaml 配置文件名:
# 示例:训练 CBAM 注意力模型
train_model('yolo26n-CBAM-cls.yaml')
# 训练基线模型(无注意力)
train_model('yolo26n-cls.pt')
可用的注意力配置文件:
| 文件名 | 注意力机制 |
|---|---|
yolo26-SE-cls.yaml |
Squeeze-and-Excitation |
yolo26-CBAM-cls.yaml |
通道 + 空间双重注意力 |
yolo26-CA-cls.yaml |
坐标注意力 |
yolo26-ECA-cls.yaml |
高效通道注意力 |
yolo26-GAM-cls.yaml |
全局注意力模块 |
yolo26-SimAM-cls.yaml |
无参数注意力 |
训练完成后,权重自动保存至 weights/trained_weights/,训练日志保存至 train_logs/。
主要训练超参数:
| 参数 | 默认值 | 说明 |
|---|---|---|
| epochs | 100 | 训练轮数 |
| batch | 16 | 批次大小 |
| imgsz | 320 | 输入图像尺寸 |
| amp | True | 混合精度训练 |
| device | 自动检测 | GPU 优先,无 GPU 则使用 CPU |
性能对比
训练多个模型后,运行以下命令生成性能对比报告及可视化图表:
python model_comparison.py
报告将保存到 performance_reports/ 目录,包含:
- 准确率对比图
- 推理速度(FPS)对比图
- 参数量对比图
- 内存占用对比图
- 综合性能雷达图
- 分类性能指标对比(精确率/召回率/F1)
常见问题
Q: 运行 flower_ui.py 报 ModuleNotFoundError: No module named 'ultralytics'
A: 确保已在项目根目录执行 pip install -e .,以开发模式安装本地定制版 ultralytics。
Q: GPU 未被使用
A: 检查 CUDA 驱动与 PyTorch 版本是否匹配:
python -c "import torch; print(torch.cuda.is_available(), torch.version.cuda)"
Q: 训练时内存溢出(OOM)
A: 减小 train_model.py 中的 batch 参数(如改为 8),或调小 imgsz(如改为 224)。
Q: 界面识别速度慢
A: 首次识别需加载模型(约 1~3 秒),之后识别通常在 10 ms 以内。若仍慢,建议安装 GPU 版 PyTorch。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)