[论文阅读]In-Place Test-Time Training
In-Place Test-Time Training
https://arxiv.org/abs/2604.06169
ICLR 2026 Oral,字节seed+北大
推荐阅读:https://www.itsolotime.com/archives/29482
阅后总结:
没有发明一个新的 TTT 层去替换 attention,而是把 Transformer 里本来就存在的 MLP 的最后一个投影矩阵,直接拿来当作 test-time 可更新的 fast weights。 这样模型在推理时,就能一边读上下文,一边把当前上下文压进这部分权重里。
用现有 MLP 的 Wdown 充当可在推理时更新的 fast weights,用面向 next-token prediction 的目标把当前上下文压进这块参数里,并通过 chunk-wise + prefix-sum 的方式把这个动态更新过程做成严格因果且可并行的机制。
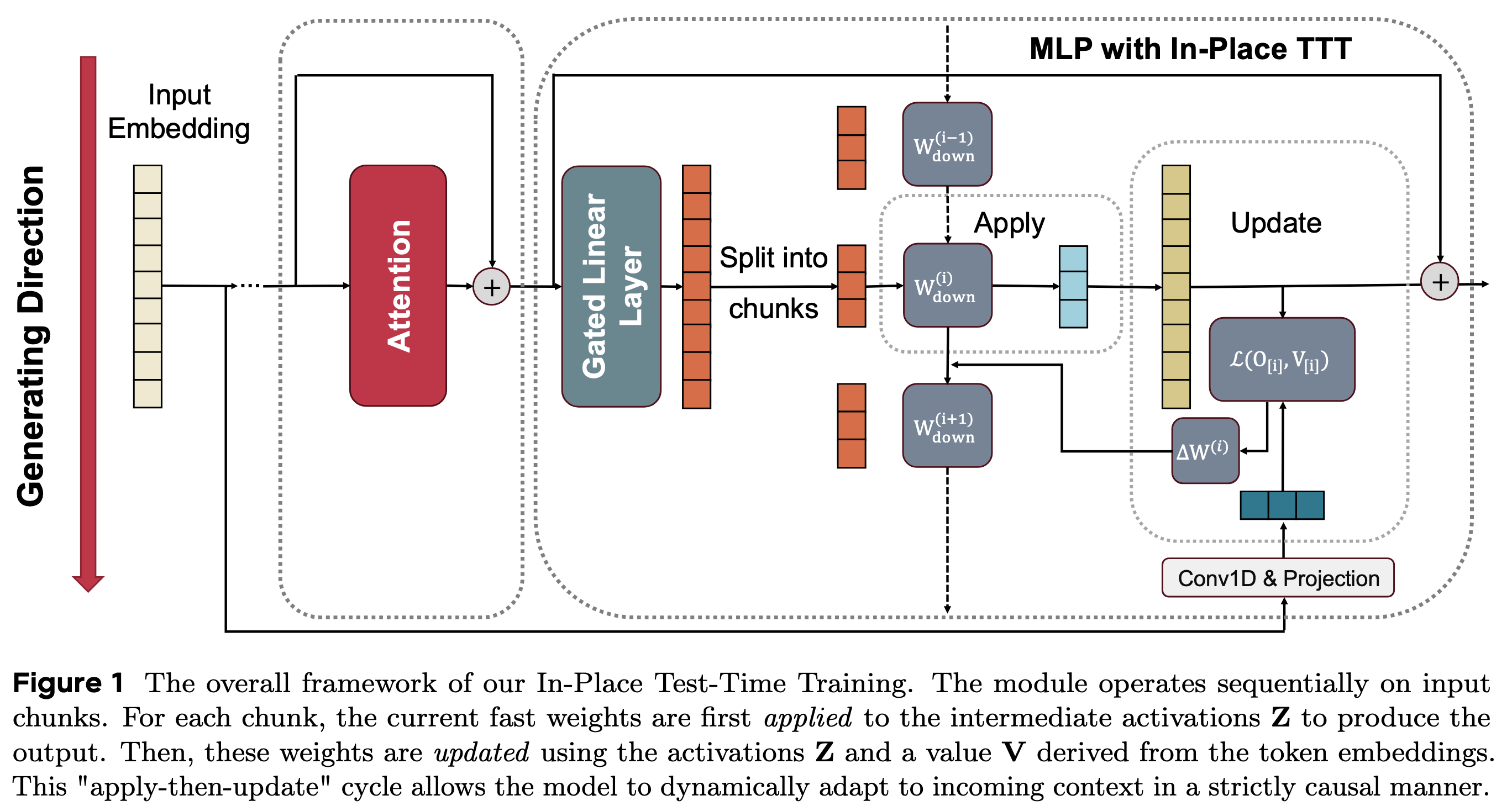
尝试看图理解文章:
直观上,这个图还是挺难理解的,因为不知道经过FFN层之后得到的隐状态为什么要进行切分?中间框起来的Apply,这里应用了什么?经过什么操作得到的黄色的隐状态?隐状态更新什么?loss是什么?为什么最初的embedding需要经过卷积核+投影?
这些都是疑点。
阅后理解链路:
输入 token → embedding → attention(完全不改) → gated MLP 前半段得到激活值 Z → 切成 chunks → 对每个 chunk:先用当前 Wdown 做 apply,再根据 V^=Conv1D(X0)Wtarget 做 update(图中的Conv1D & Projection) → 更新后的 Wdown 传给后续 chunk。
当前大模型存在的问题:应用的都是固定参数的大模型,没有动态依据信息数据调整内部参数的策略。测试时训练TTT方案通过在推理阶段更新一部分模型参数(快权重),但是难以适配到LLM,因为架构不兼容、计算效率低下、语言建模中快权重目标的错位。
作者提出了In-Place TTT来解决这个问题,In-Place TTT 将普遍存在的 MLP 块的最终投影矩阵视为其可适应的快权重,从而在无需昂贵的从头重训练的情况下,为 LLM 实现“即插即用”的增强。
将 TTT 通用的重构目标替换为一个量身定制、理论扎实的目标,该目标与控制自回归语言建模的“下一个 Token 预测”任务明确对齐。 这一原则性目标结合高效的块级更新机制,产生了一种与上下文并行计算兼容且高度可扩展的算法。
大量实验验证了框架的有效性:作为一种原地增强手段,它使一个 4B 参数的模型在高达 128k 上下文的任务上实现了卓越的性能;而在从头预训练时,它始终优于其他具有竞争力的 TTT 相关方法。 消融研究结果进一步为设计选择提供了更深刻的见解。
研究结果确立了 In-Place TTT 作为迈向 LLM 持续学习范式的重要一步。
大模型先训练后部署,导致模型权重无法更新,模型难以根据流式输入token提供的特定上下文进行动态适应。现有方案是ICL上下文学习,但是是把上下文信息放在提示词中,让输入序列变长,注意力机制的计算和存储开销大。
TTT思想很好,测试的时候动态更新参数,但是对LLM的适配上有gap:
(i) 现有的 TTT 方法通常依赖于标准 Transformer 块之外的特殊层,这通常需要昂贵的从头预训练才能达到令人满意的性能;(ii) 规范的 TTT 机制本质上是序列化的。 虽然现有研究探索了块级加速,但 TTT 作为主要 Token 混合器的角色迫使其依赖较小的分块来维持性能,从而阻碍了饱和现代加速器所需的大规模并行计算;以及 (iii) TTT 快速权重更新中普遍使用的通用重构目标并未明确针对自回归 LM 所需的因果预测任务(Next-Token Prediction)进行定制,这可能会妨碍其最终性能。
为了弥补这一差距,作者引入了 In-Place Test-Time Training (In-Place TTT),这是一个旨在通过直接解决上述障碍,从而无缝赋予 LLM 测试时训练能力的框架。
核心洞察是利用原位(in-place)设计来重用现有的 MLP 块,而不是引入新的专门层 (解决障碍 i)。 具体来说,In-Place TTT 将 MLP 块的最终投影矩阵视为其快速权重,并在推理过程中进行原位更新。 这种“即插即用”的设计不需要对模型架构进行任何修改,保持了预训练权重的完整性,并实现了无需昂贵从头重训的实时适应。
为了解决计算效率低下和目标不匹配的问题,作者进一步设计了一种专门用于语言建模的适应机制。 借鉴先前的工作,用可扩展的块级更新规则替换了效率低下的逐 Token 更新 (解决障碍 ii)。 此外,原位(in-place)设计与注意力机制形成了互补。 这种协同作用无需独立 TTT 层所需的小块(small chunks),从而确保了在现代加速器上的高吞吐量。 与此同时,超越了先前工作中通用的重构目标,并引入了一种明确与下一个 Token 预测(NTP)目标对齐的创新目标 (解决了障碍 iii)。 基于严谨的理论分析,作者证明了这种与 NTP 对齐的目标能够促使快速权重(fast weights)存储对自回归语言建模具有预测价值的信息,从而导向一种高效且可扩展的算法。
预备知识:TTT
是一种使模型能够在推理时动态适应新数据的范式

在这里,文章给出的一个TTT示例的操作如下:
给定输入序列 x1,x2,…,xN∈Rdmodel,每个 xi 首先通过可训练的线性投影(或更复杂的网络)得到三个向量qi, ki, vi,它们的维度都是d维,这里的d通常都会远小于输入的token数目。
这些向量类似于Transformer中的Q、K、V,但含义不同:在TTT中,键和值用于更新“记忆网络”,查询用于从更新后的网络中提取信息。
TTT处理序列是顺序的(类似于RNN),每个时间步 i 执行两个操作:
- 更新操作:
假设进入第 i 步之前,记忆网络参数为 Wi−1。当前 token 提供了一对键值 (ki,vi)。我们希望通过更新 W,使得网络能够在输入 ki 时输出 vi。
这被形式化为一个监督学习问题:我们希望 fW(ki) 接近 vi。为此,定义一个损失函数(如均方误差MSE)得到loss,使用loss来单步梯度下降更新参数,得到Wi
直观理解:这一步将当前的 (ki,vi) 对“训练”进记忆网络中。经过足够多的步骤,网络将学会将过去所有见过的 kj 映射到相应的 vj(类似于一个近似查询表)。由于梯度下降具有泛化能力,网络甚至可以回答未见过但相似的键。- 应用操作——从记忆中读取信息:
更新完参数后,使用新的 Wi 来处理当前 token 的查询 qi:oi=fWi(qi)这个输出 oi 就是融合了历史上下文信息的当前 token 的表示。它将被用于后续任务(如语言模型的下一个token预测)。
注意:这里 qi和 ki来自同一个 token,但也可以是不同的映射(比如 qi 来自当前 token,ki 来自前一个 token 的投影)。原始TTT论文使用相同的投影矩阵,但也可以设计为交叉注意力形式。

旧式 TTT 想直接进 LLM 生态,会碰到三个硬障碍。
第一,很多 TTT 方法是单独设计的新层,甚至想替换 attention,这意味着很难从现成大模型 checkpoint 直接 warm-start,通常得从头预训练。
第二,经典 TTT 是 per-token update,天然串行,不适合 GPU/TPU 的大并行。
第三,很多 TTT 的训练目标只是“重构当前 token 的某种表示”,这和自回归语言模型真正关心的 next-token prediction 并不严格对齐。
In-Place TTT
整体框架
重用 MLP 模块以实现原地适配。 先前的 TTT 研究主要将其定位为替代注意力机制的潜在解决方案。 然而,这些先前的研究通常是在中等规模下进行的,这与现代数十亿参数大语言模型的运行环境大相径庭。 因此,替换核心注意力机制(其习得的特性对于大语言模型的能力至关重要)是一种高风险的架构修改。 此外,引入任何新的、随机初始化的层也会与大语言模型中数十亿已训练参数产生冲突,需要昂贵且通常不切实际的重新训练来解决这种失衡。
核心洞见是完全规避这些挑战:不再替换或增加组件,而是重用一个普遍存在的模块——多层感知机 (MLP) 模块——使其同时充当快速权重。

H 是进入 MLP 的隐藏状态;Wup 和 Wgate 负责把表示升到 FFN 空间并做门控;最后再通过 Wdown 投影回模型维度。论文的做法是:
- Wup、Wgate 继续当冻结的 slow weights
- Wdown 被重新定义成可在 test time 更新的 fast weights
也就是说,它没有替换 attention,也没有插入随机初始化的新记忆模块,而是把 MLP 的最后一层投影矩阵“就地改造”为可适应上下文的临时记忆。这就是 In-Place 这个名字的含义:直接在原有 MLP 里面原位做 TTT。
MLP 本来就可以被看成一种参数化记忆,存着预训练阶段学到的通用知识;现在作者让其中一部分参数在推理时还能继续被当前上下文轻微改写,于是它既保留“长期知识”,又能短时吸收“当前文档/当前轨迹”的临时信息
在block内的策略:
先正常经过 attention,得到隐藏表示 H。然后进 gated MLP,先算出中间激活值Z=ϕ(HWgate⊤)⊙(HWup⊤)
这个 Z 就是 MLP 下投影之前的 FFN 表示。
接着把整段序列对应的 Z、目标值 V、输出 O 都切成若干 chunk。设第 i 个 chunk 为 [i],当前 chunk 开始前的 fast weights 状态记为 Wdown(i)。然后每个 chunk 按固定顺序做两件事:
第一步:Apply
先用当前的 fast weights 去处理这一块 token:
O[i]=Z[i](Wdown(i))⊤意思是:当前 chunk 的输出,使用的是“看到前面上下文后”已经更新过的 Wdown
第二步:Update
再用这一块 chunk 自己的 Z[i]和目标 V[i],对 Wdown 做一步梯度更新,得到下一块 chunk 要用的新状态:
Wdown(i+1)=Wdown(i)−η∇WL(Z[i](Wdown(i))⊤, V[i])这就形成了一个非常核心的循环:
先用旧状态处理当前 chunk,再用当前 chunk 去更新状态,供后面的 chunk 使用。
所以它本质上是一个严格因果的 apply-then-update 机制。论文 Figure 1 就是在画这个循环:attention 不动,进入 MLP 后先切 chunk,再对每个 chunk 执行 apply,再根据 chunk 的目标值产生 ΔW(i) 去更新 Wdown。
语言模型对齐目标

以前很多 TTT 做法,本质是让 fast weights 学会把当前 token 的某个表示重构回来。也就是输入来自当前 token,监督目标也来自当前 token。作者认为这更像“记住眼前这个 token”,而不是“为了后面的语言建模服务”。
因此他们设计了一个 LM-Aligned Objective。目标值不是当前 token 本身,而是从 token embedding X0 出发,用一个 1D Conv + 线性投影 Wtarget生成 V_hat
这个 Vhat可以带入未来 token 信息。如果你把 Wtarget 设成恒等映射、把卷积核设成“只取下一个 token”,那它就退化成标准的 next-token target。
论文实际做得更一般:不是只盯一个未来 token,而是让目标变成“局部未来 token 的可学习组合”,相当于把多 token 的预测信号压进 fast weights 学习目标中。
Wdown的更新公式表征的含义:每个 chunk 对 fast weights 的贡献,本质是一个外积累加。
看一号公式,
- Z[i]:这是模型看到当前 chunk 后,在 MLP 里形成的“键/特征摘要”
- V^[i]:这是作者特意构造出来的“对未来 token 有预测价值的目标信号”
- V^[i]⊤Z[i]:就是把“当前 chunk 的关键信息”写进一个能帮助后续 next-token prediction 的参数记忆里
所以它不是单纯把“我刚刚看到了什么”记住,而是在学:当前这段上下文里,哪些模式对接下来会出现什么最有帮助?
理论分析:目标函数的优势


结论是:在给定假设下,LM-aligned target 会提高正确下一个 token 的 logit,并且对其他 token 的 logit 基本不乱动;而 reconstruction target 对正确答案 logit 的提升则是可忽略的。
- reconstruction 更像“记住当前词长什么样”
- LM-aligned 更像“把当前模式和未来答案绑定起来”
实现细节

如果用常规的TTT,那就是token 1 更新一次、token 2 再更新一次、token 3 再更新一次……这会非常串行。论文利用上面那个闭式更新:ΔWi=V^[i]⊤Z[i]
因为这个更新是可加的,所以整条序列切成 T 个 chunk 后,可以先对所有 chunk 并行算出各自的 ΔWi。然后做一次 prefix sum:Si=j<i∑ΔWj
那么第 i 个 chunk 真正该用的 fast weights 就是:Wdown(i−1)=Wdown(0)+ηSi
最后,各 chunk 再并行算自己的输出:Oi=Zi(Wdown(i−1))⊤
这样就把原本看起来必须串行的更新过程,改写成了:
- 并行算每个 chunk 的局部更新
- 做一次并行友好的 prefix sum
- 并行算每个 chunk 的输出
这就是论文说它天然兼容 Context Parallelism 的原因

实验
-
Q1:In-Place TTT 以“直接插入”方式增强预训练大语言模型(LLM)的效果如何?
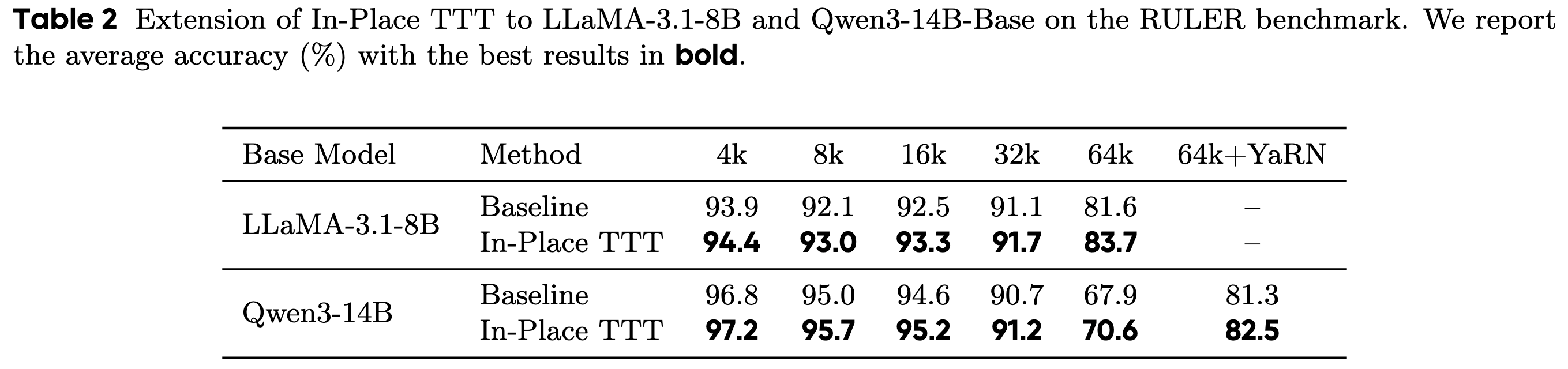
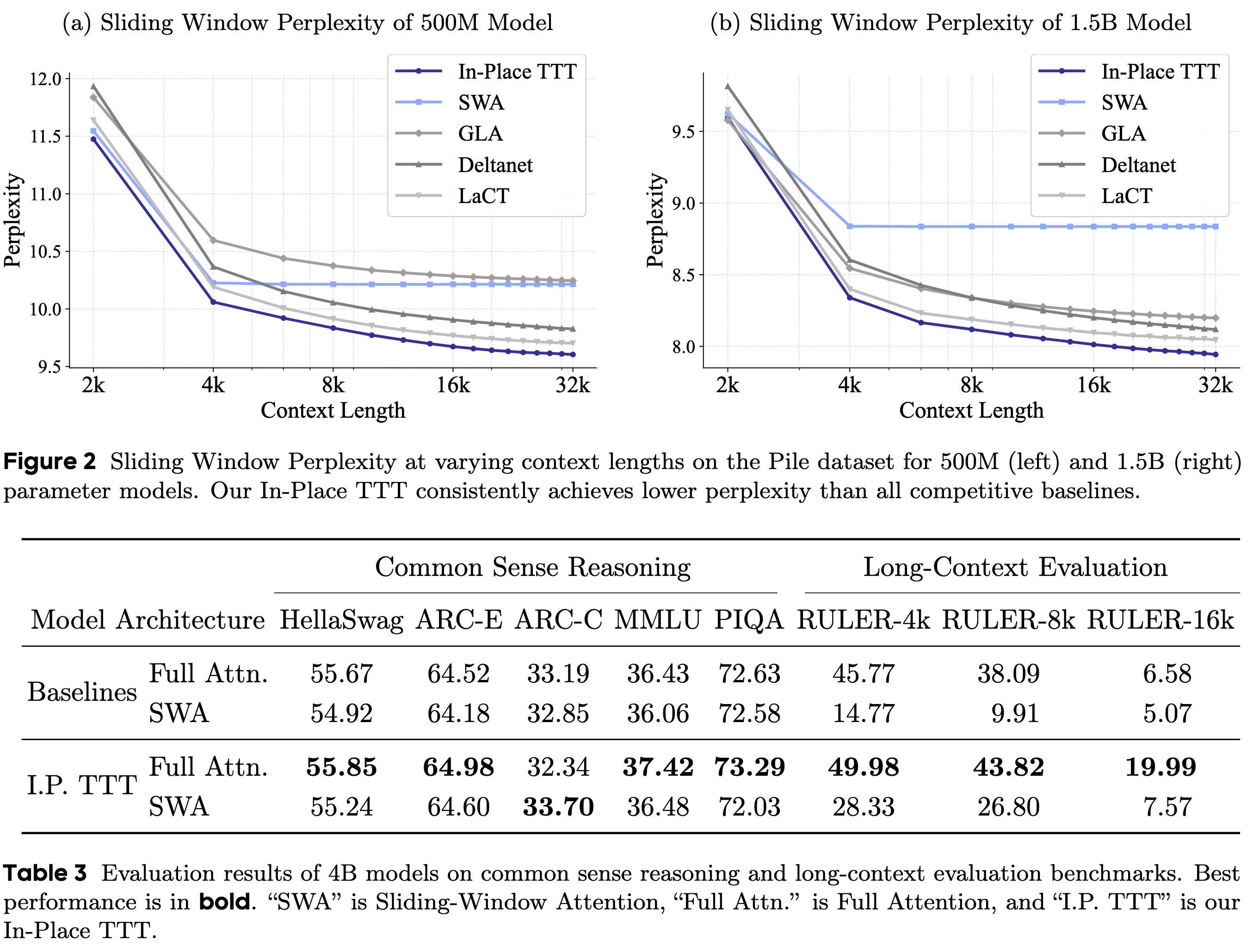
- Q2:从头开始训练时,In-Place TTT 与先前的 TTT 方法相比表现如何?
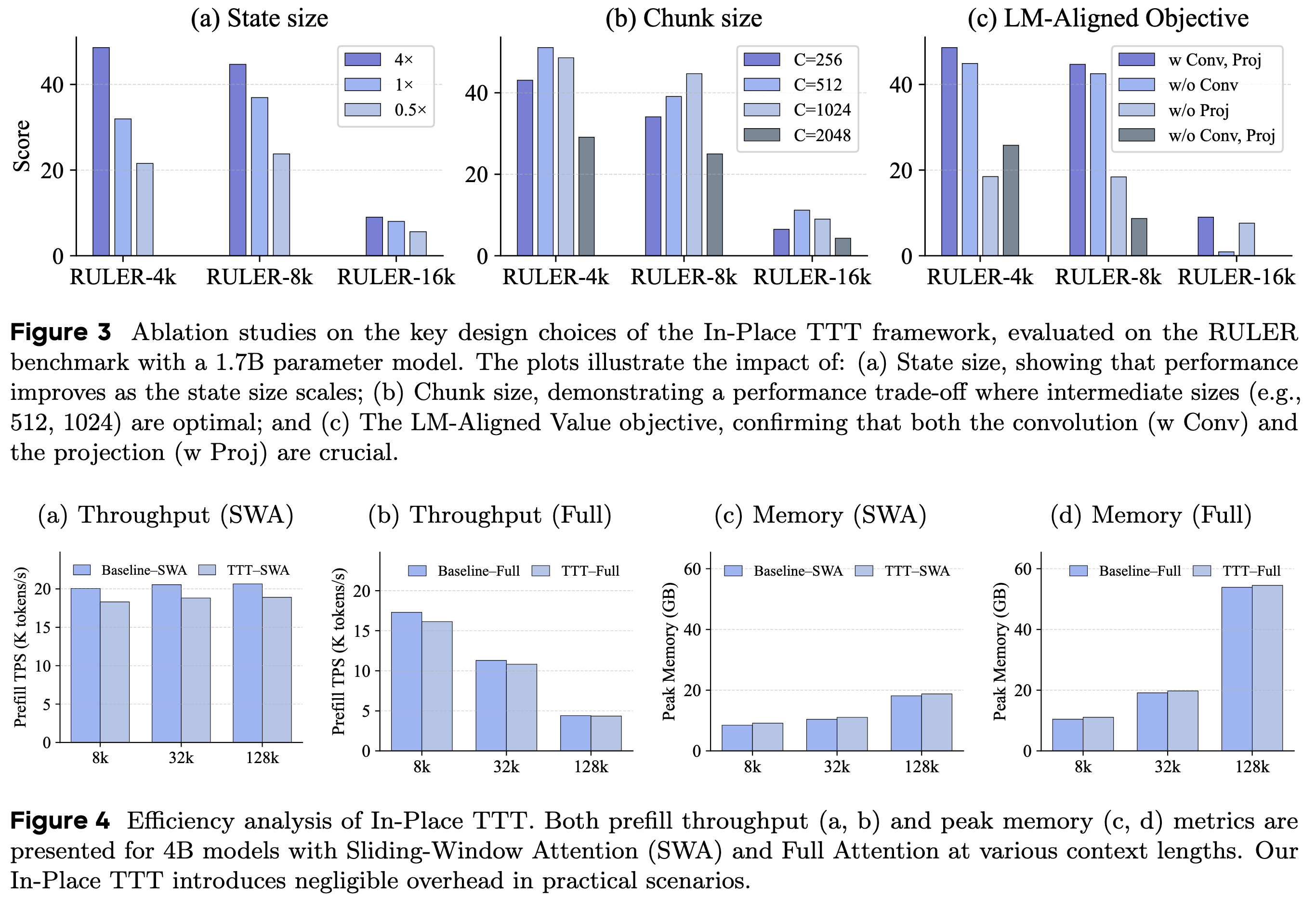
- Q3: In-Place TTT 框架中的关键设计选择有何影响?
1作为预训练大语言模型即插即用增强方案的 In-Place TTT
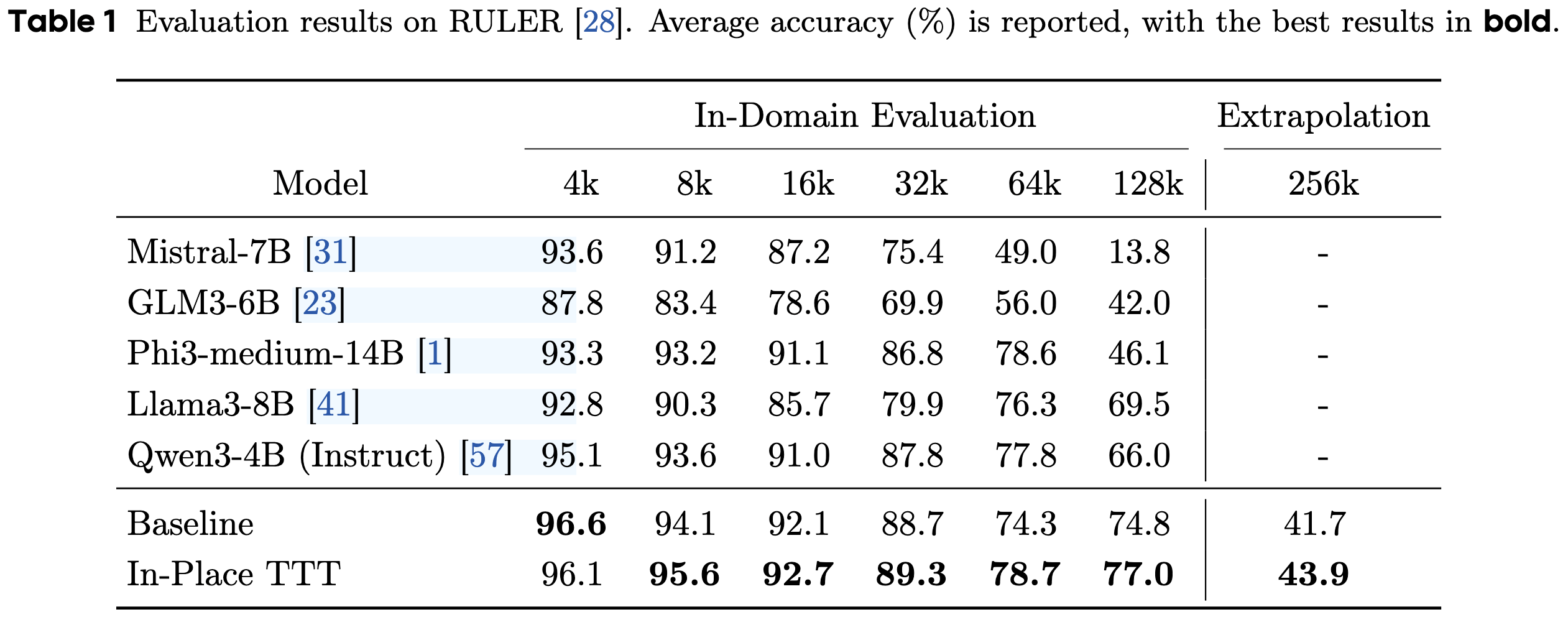
Qwen3-4B-Base。 其原始上下文窗口为 32k,因此可以通过不同上下文长度的语言建模任务,模拟需要TTT能力的长期演进任务。
比较了以下模型的性能:(1) Qwen3-4B-Base(基线);(2) Qwen3-4B-Base + In-Place TTT。 两个模型都经历了完全相同的持续训练课程,确保了公平的比较, In-Place TTT 是唯一的变量。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)