DeepVision-VLA:增强VLA模型的视觉基础表征
26年3月来自北大、Simplexity和港中大的论文“Look Before Acting: Enhancing Vision Foundation Representations for Vision-Language-Action Models”。
视觉-语言-动作(VLA)模型近年来已成为机器人操作领域极具前景的范式,其可靠的动作预测关键在于准确解读和整合基于语言指令的视觉观察结果。尽管近期的研究致力于提升VLA模型的视觉能力,但大多数方法将LLM骨干网络视为黑箱,对视觉信息如何转化为动作生成过程的理解有限。因此,对不同动作生成范式下的多个VLA模型进行系统分析,发现动作生成过程中,模型对视觉token的敏感度在更深的层级逐渐降低。基于此,提出基于视觉-语言混合Transformer(VL-MoT)框架的DeepVision-VLA模型。该框架实现视觉基础模型与VLA骨干网络之间的注意共享,将来自视觉专家的多层次视觉特征注入到VLA骨干网络的更深层级,从而增强视觉表征,实现精确且复杂的操作。此外,引入动作-引导的视觉剪枝(AGVP),它利用浅层注意机制剪除无关的视觉token,同时保留与任务相关的token,从而以最小的计算开销强化用于操作的关键视觉线索。在模拟任务和真实世界任务上,DeepVision-VLA 的性能分别比现有最先进方法提高 9.0% 和 7.5%,为设计视觉增强型 VLA 模型提供新的思路。
如图概述:(a) 在传统的 VLA 模型中,对任务相关视觉token的关注度在更深的层级中逐渐减弱,导致对视觉信息的敏感度降低。(b) 为了解决这个问题,DeepVision-VLA 引入一种视觉-语言混合 Transformer 框架,该框架将来自视觉基础模型的多级视觉特征注入到 VLA 主干的更深层级,从而增强用于精确复杂操作的视觉表征。© DeepVision-VLA 基于定制的 QwenVLA-OFT 构建,其性能显著优于基线模型,并在多个实际操作任务中取得了优异的性能。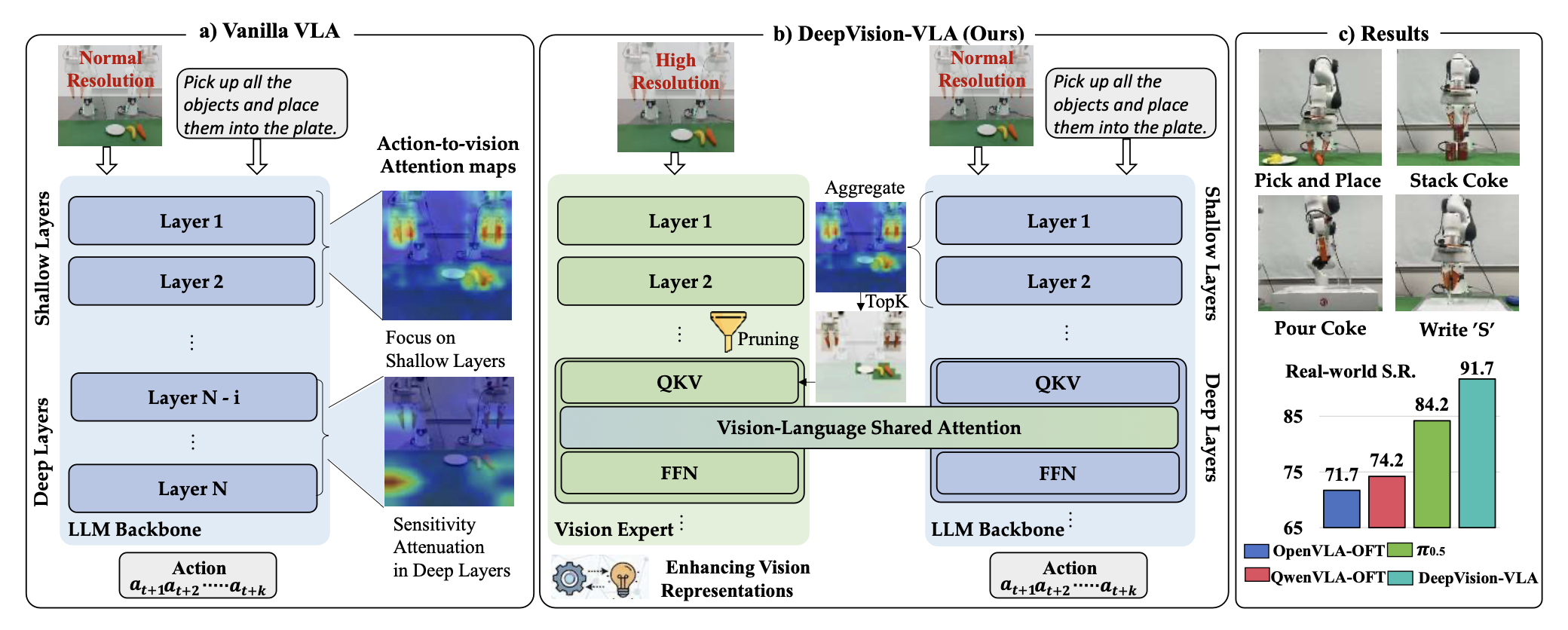
DeepVision-VLA
本文提出视觉-语言混合 Transformer (VL-MoT) 框架。为了便于理解,展示如何将该框架应用于 QwenVLA-OFT 基线模型以构建 DeepVision-VLA,如图 (a) 所示。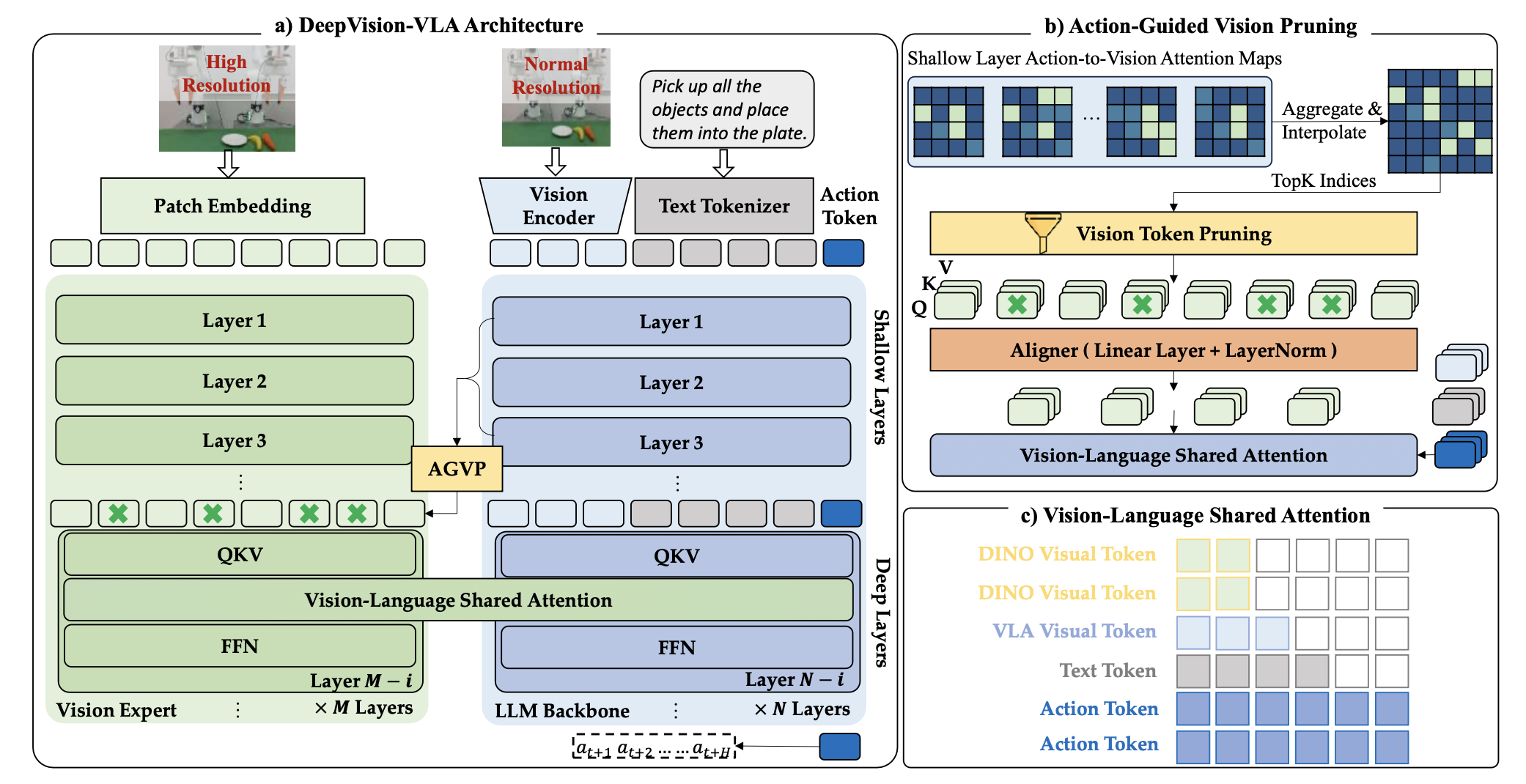
为了增强VLA深层中的视觉基础,引入视觉专家模型DINOv3。其多级Transformer特征通过共享注意机制注入到VLA的深层中。这种设计使得VLA能够将多级视觉信息融入到原本对任务相关视觉ROI不敏感的层中,从而提高动作生成的精度。
视觉专家模型。采用视觉基础模型DINOv3 [59],因为它提供了比现有VLA视觉编码器通常提取的高级语义特征更精细的空间细节表征[37, 44, 27],使其特别适用于精确操作任务。然而,方法并不局限于此,探索其他视觉专家模型将留待未来研究。
VL-MoT设计。为了将视觉专家模型的多级知识集成到VLA的深层中,并非简单地连接中间特征并通过LLM进行联合处理。其提出一种MoT架构,该架构直接暴露视觉专家的中间QKV表示,并通过共享注意机制将其与深度VLA层的相应QKV融合,如上图(a)所示。这实现跨分支信息交换,同时保持独立的处理路径,有效减少特征干扰并稳定融合训练。
AGVP。为了使 VLA 模型能够更好地专注于与任务相关的对象,提出动作引导视觉剪枝(AGVP),如上图 (b) 所示,它在将视觉专家的多级信息集成到更深的 VLA 层之前,过滤掉冗余的背景特征。根据观察,浅层 VLA 层提供了可靠的动作条件视觉基础,利用这些层中从动作token到视觉token的注意来识别 ROI 视觉token。一种多层平均方法可以有效地过滤掉噪声,并产生稳定的、与任务相关的 ROI 视觉token。
与VLA中使用的输入图像相比,利用Vision Expert强大的特征提取能力,输入更高分辨率的图像,使模型能够捕捉到更精细的物体细节。随后,对得到的注意图进行插值,使其分辨率与Vision Expert相匹配。
这种方法不仅能有效地将关键视觉区域信息注入到 VLA 的深层,还能在利用视觉专家的高分辨率输入的同时控制计算预算。
训练方案。在预训练 DeepVision-VLA 之前,用来自 Qwen3-VL [8] 和 DINOv3 [59] 的预训练权重初始化模型,然后以端到端的方式训练整个架构。参考先前的工作 [32, 26, 38, 51],精心处理和筛选了多个大规模跨具身数据集,包括 Open X-Embodiment [12]、DROID [13] 和 RoboMIND [14],从而构建一个专门的预训练数据集。最终得到的数据集包含超过 40 万条轨迹,DeepVision-VLA 在此数据集上训练一个 epoch。下游任务的微调设置将在实验部分进行描述,因为它们在模拟环境和真实世界环境中有所不同。
推理。在推理阶段,DeepVision-VLA 首先将当前图像观测结果和语言指令作为输入。这些输入会传递到VLA的浅层,在这些浅层中计算动作到视觉的注意图,以识别与任务相关的视觉区域。基于这些线索,从视觉专家中提取多级特征,并通过VL-MoT机制将其整合到更深的VLA层中。最后,在深层完成前向传播后,动作token的隐状态被输入到动作解码器中,以生成最终的动作。值得注意的是,这种识别关键视觉区域和增强VLA感知能力的方法不需要额外的标注或外部监督,并且整个流程在训练完成后仍然具有端到端的可执行性。
仿真实验
数据采集。基于 CoppeliaSim 仿真环境,对 RLBench [28] 基准测试中的 10 项操作任务评估 DeepVision-VLA 的性能,这些任务包括:1) 关闭盒子,2) 关闭笔记本电脑,3) 放下马桶盖,4) 将垃圾扫到簸箕,5) 关闭冰箱,6) 将手机放回底座,7) 取出雨伞,8) 从衣架上取下相框,9) 将酒放回酒架,以及 10) 浇花。所有任务均在 Franka Panda 机器人上完成,并采集单次前视 RGB 图像。遵循预定义的路径点,并利用开放运动规划库 (OMP) [61],构建一个训练数据集,其中每项任务包含 100 条轨迹,并采用了先前研究 [60] 中使用的帧采样技术。
训练和评估方案。将 DeepVision-VLA 与七个具有代表性的 VLA 基线模型进行比较:OpenVLA [37]、SpatialVLA [54]、CogACT [44]、CoT-VLA [24]、π0.5 [34]、Hybrid-VLA [32] 以及我们自行开发的 QwenVLA-OFT。除 QwenVLA-OFT 外,每个基线模型均使用其官方发布的预训练权重进行初始化,并严格按照其原始论文中推荐的配置和超参数进行端到端微调。QwenVLA-OFT 是我们自行预训练的。QwenVLA-OFT 的实现细节在 3.3.1 节中描述。对于图像处理,DeepVision-VLA 采用双分辨率:VLA 分支为 256×256,Vision Expert 分支为 512×512,从而为 Vision Expert 分支提供更精细的视觉细节。将DINOv3-H的最后16层整合到Qwen3VLA-OFT的最后16层中,并将剪枝率设置为0.5。用AdamW[62]优化器在8个NVIDIA H20 GPU上对DeepVision-VLA进行300个epoch的微调。遵循先前工作[51, 63]中的标准评估协议,报告每个任务20次rollout试验的最终检查点结果,每次试验使用三个随机种子,以考虑随机变异性。
真实世界实验
数据采集。用配备 Intel RealSense D455 摄像头(用于 RGB 观测)的 Franka Research 3 机器人,在四个复杂的单臂真实世界操作任务上评估 DeepVision-VLA 模型。评估的任务包括:1) 堆叠可乐罐;2) 书写字母“S”;3) 将水果放入盘中;4) 将可乐倒入瓶中。为了更全面地评估模型性能,我们将任务 3) 和 4) 分解为两个连续步骤。任务 3) 分为两个步骤:第一步是抓取并放置香蕉,第二步是抓取并放置胡萝卜。任务 4) 的评估分别针对初始抓取和后续的倾倒动作。任务 1) 和 2) 被定义为简单任务,并使用一个综合成功评分来评估其完整执行情况。
训练和评估细节。DeepVision-VLA 的训练方案与仿真中的方案相同。将方法与三种最先进的VLA模型基线进行比较,包括π0.5 [33]、OpenVLA-OFT [27] 和自定义的QwenVLA-OFT [64]。为了公平评估,所有基线均采用相同的相机设置,每个任务在一致的测试条件下进行20次迭代。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 2
2 0
0- 0



 已为社区贡献106条内容
已为社区贡献106条内容

所有评论(0)