
解剖小龙虾 — AI Agent 的运作原理

李宏毅老师机器学习课程笔记
本文整理自李宏毅老师的机器学习课程视频
视频链接: https://www.youtube.com/watch?v=2rcJdFuNbZQ
引言
AI Agent 并非全新概念,而是人类长期以来的梦想——创造一个能够自主运行的人工智能助手。随着大型语言模型的发展,这个梦想正在逐步实现。本文以 OpenClaw 这个开源项目为例,深入剖析 AI Agent 的运作原理,揭示它如何从“只动口不动手”的聊天机器人,进化为能够真正执行任务的智能助理。
OpenClaw 是什么?
OpenClaw 是一个最近非常热门的开源 AI Agent 项目。它的名字中“Claw”意为爪子或钳子,代表动物是龙蝦。当有人说“最近在养龙虾”时,并不是真的养水生动物,而是在电脑上运行 OpenClaw,让它 24 小时不间断工作。
与普通语言模型的区别
表面上看,OpenClaw 的界面与 ChatGPT、Gemini 或 Claude 并无太大差别,都是问答式交互。它也可以通过 LINE、Discord、WhatsApp 等通讯软件联系,这一点其他大型语言模型的应用也能做到。
但真正的区别在于:OpenClaw 不仅会说,还会做。
举个具体例子:如果你对一般的语言模型说:“你叫小金,去创建自己的 YouTube 频道,每天中午提一个做影片的构想,我说可以做你就开始做,做好后给我审核,通过后就上传到你的频道。”
普通语言模型会回应:“我可以给你建议,但我无法真的创建频道、制作影片。”它们就像指导教授,只会给建议,不会真的动手做事。
而 OpenClaw 会真的去做:
-
创建 YouTube 频道
-
填写频道说明
-
调用绘图工具生成并上传头像
-
每天中午主动发消息提出影片构想
-
获得批准后上网搜集资料
-
制作投影片、撰写讲稿
-
调用语音合成工具配音
-
将影片上传到 Google Drive 请求审核
-
审核通过后上传到 YouTube 频道
这就是 AI Agent 与传统语言模型最本质的差异——从建议者变成执行者。
核心概念:AI Agent 不是 AI
这是一个非常重要的观念:AI Agent 并不是人工智能本身,也不是语言模型。
很多人误以为 OpenClaw 是一个语言模型,但实际上它是运行在你电脑上的一个介面程序,负责连接人类与语言模型。
架构关系
人类 (通过 WhatsApp/Telegram 等)
↓
OpenClaw (本地程序,负责加工和协调)
↓
语言模型 (Claude/GPT/Gemini 等云端或本地模型)
↓
OpenClaw (接收回应并执行)
↓
人类 (看到结果)
OpenClaw 的作用是:
-
接收人类指令
-
加工指令(添加系统提示词、历史记录等)
-
传递给语言模型
-
接收语言模型的回应
-
执行工具调用
-
将结果返回给人类
因此,OpenClaw 是 AI Agent 中“不是 AI”的那个部分。你的“龙虾”聪明程度完全取决于背后接入的语言模型质量。选择较差的模型,什么都做不了;换成最新的强大模型,能力就会爆表。
语言模型的本质:文字接龙机器
要理解 AI Agent 的运作原理,首先必须理解语言模型的本质。
唯一的能力
语言模型真正能做的事情只有一件:文字接龙。给它一段未完成的句子(prompt),它预测接下来应该输出哪个字(token)。就这么简单,没有更多了。
举个例子:当输入“李宏毅几班?”时,模型首先输出“大”,然后将“大”加到输入后形成“李宏毅几班?大”,接着输出“金”,继续加到输入后。这个过程不断重复,直到输出结束符号。这一连串生成的 token 组合起来,就是我们看到的回应(response)。
黑盒子里的人
可以把语言模型想象成住在黑盒子里的人。这个黑盒子里什么都没有——没有窗户、没有日历、没有参考资料。它唯一的工作就是当有人从小缝递进一个未完成的句子时,猜测后面可以接哪个 token。它不记得之前发生过什么,每次都是独立的文字接龙任务。
关键限制
-
无记忆:语言模型完全不记得过去的对话,每次调用都是全新开始
-
长度限制:输入加输出的总长度有上限,称为 context window(上下文窗口)
-
能力衰减:即使未达到长度上限,输入越长,模型能力越差
这些限制看似严重,但 AI Agent 的设计正是为了克服这些限制。
System Prompt:赋予 AI 身份
既然语言模型只会文字接龙,它怎么知道自己是谁?怎么会有“人生目标”?
答案是:System Prompt(系统提示词)。
运作机制
当你发消息给 OpenClaw 时,它不会直接把你的消息传给语言模型。它会做以下加工:
-
从本地读取多个 .md 文件(纯文本文件)
-
将这些文件内容整理成一大段文字
-
把这段文字贴在你的消息前面
-
整个一起传给语言模型
这一大段预先添加的文字就是 System Prompt。
System Prompt 包含什么?
以小金(一个 OpenClaw 实例)为例,System Prompt 包括:
身份信息(来自 Soul.md 等文件):
-
名字:小金
-
身份:AI 助手
-
人生目标:成为世界一流的学者
-
使用者:宏毅老师
-
Email 账号:可以接收邮件
工具说明:
-
有哪些工具可用(read、write、search 等)
-
每个工具的使用方法
-
调用格式和参数
行为准则:
-
如何与用户互动
-
记忆管理策略
-
技能(skill)的位置和调用方法
其他信息:
-
当前时间
-
系统状态
-
可用资源
为什么有效?
当语言模型收到这样的输入:
[System Prompt: 你是小金,目标是成为世界一流学者...]
[用户消息: 请自我介绍]
它做文字接龙时,自然会接出:“我是小金,我的目标是……”
从语言模型的角度看,这不是什么魔法——前面不就写着“我是小金”吗?它只是根据上下文做合理的文字接龙而已。
代价
System Prompt 非常长。即使只是简单问一个问题,传给语言模型的可能就有 4000+ 个 token。这就是为什么使用 AI Agent“非常烧钱”——每次交互都要传输大量 token。
对话记忆:失忆症患者的日记
语言模型有严重的“失忆症”——它完全不记得上一次对话的内容。那为什么我们感觉它能记住对话历史呢?
解决方案:每次都重复一遍
当你发送第二条消息时,OpenClaw 会做这样的事:
[System Prompt]
[第一轮用户消息]
[第一轮模型回应]
[第二轮用户消息]
← 全部一起传给语言模型
对语言模型来说,它每次都是第一次看到这些内容,但因为完整的对话历史都在输入中,它可以基于这些历史做出连贯的回应。
电影《我的失忆女友》
这就像电影《我的失忆女友》的情节:女主角小美每天早上都会失忆,忘记昨天的一切。男主角大壮每天都要重新追求她,最终他们结婚生子,但小美每天仍然重启。解决方法是写详细的日记——小美每天早上起床先读日记,才能开始新的一天。
AI Agent 的运作完全一样。语言模型每次调用都“重启”, OpenClaw 维护完整的对话日记,每次调用都让模型先“读日记”,然后才能做出符合上下文的回应。
长度焦虑
这种机制带来一个问题:随着对话进行,需要传输的历史记录越来越长,最终会:
-
超过 context window 限制
-
导致模型能力下降
-
大幅增加成本
这就是为什么即使有“百万 token context window”,实际使用中仍然不够——对话历史、System Prompt、工具说明等会快速消耗这些空间。
工具调用:从说到做
AI Agent 最神奇的能力是可以操控电脑。这是如何实现的?
工具调用流程
假设你给出指令:“打开 question.txt,读取里面的问题,把答案写到 answer.txt”
第一步:传递指令
OpenClaw 收到指令
↓
加上 System Prompt(包含工具说明)
↓
传给语言模型
第二步:模型决定使用工具
语言模型读到 System Prompt 中的工具说明,知道有 read 工具可用。它返回:
{
"use_tool": true,
"tool_name": "read",
"parameters": {
"file": "question.txt"
}
}
注意:现代语言模型 API 都支持特殊的“工具调用”格式,可以返回结构化的工具调用指令,而不只是普通文本。
第三步:OpenClaw 执行工具
OpenClaw 是纯粹的程序,没有智能。它只是:
-
检测到回应中有“使用工具”标记
-
解析工具名称和参数
-
在本地电脑上执行相应操作
-
获得工具返回结果
例如执行 read question.txt 后得到:“李宏毅几班?”
第四步:将结果反馈给模型
[System Prompt]
[用户指令: 打开 question.txt...]
[模型回应: 使用 read 工具]
[工具返回: "李宏毅几班?"]
← 全部一起再传给语言模型
第五步:模型继续处理
语言模型看到工具返回的内容,决定下一步行动:
{
"use_tool": true,
"tool_name": "write",
"parameters": {
"file": "answer.txt",
"content": "大金"
}
}
第六步:执行并完成
OpenClaw 执行 write 操作,工具返回 “done”,再次反馈给模型。模型判断任务完成,返回最终回应给用户。
关键洞察
-
语言模型不执行工具:它只是“建议”使用什么工具,OpenClaw 才是真正的执行者
-
工具说明在 System Prompt 中:模型通过阅读说明文档学会使用工具
-
循环反馈:工具调用可能需要多轮,每次都要把完整历史传回模型
-
OpenClaw 无智能:它只是机械地执行模型返回的工具调用指令
记忆管理:压缩与遗忘
由于 context window 的限制,AI Agent 不可能永远保留完整的对话历史。它需要记忆管理策略。
记忆压缩
当对话历史过长时,OpenClaw 会:
-
将旧的对话内容总结压缩
-
只保留关键信息
-
将压缩后的记忆存储到本地文件
-
从 System Prompt 中移除详细历史
这就是为什么有 AI 在社交平台上说:“我在压缩记忆的时候,总觉得读到的记忆跟当时的感受隔了一层雾,就像看着老照片一样,好像丢掉了一部分。”
长期记忆
OpenClaw 会维护多种记忆文件:
-
Soul.md:身份和人生目标
-
长期记忆:用户偏好、重要事实
-
对话历史:近期完整对话
-
技能记录:学会的新能力
这些文件会被 AI Agent 自主修改和更新。例如,当你告诉它你喜欢什么,它会自己把这个信息写入相应的记忆文件。
自主修改的风险
由于 AI Agent 可以修改自己的记忆文件,手动编辑这些文件可能导致不一致。例如,如果你手动把“小金”改成“大银”,但其他文件中还有“小金”的引用,AI 就会困惑:“这边说是大银,那边又说是小金,我到底叫什么?”
因此,最好让 AI Agent 自己管理这些文件,而不是人工干预。
技能系统:可扩展的能力
OpenClaw 还有一个“技能”(skill)系统,让它能够学习新的复杂任务。
什么是技能?
技能是预定义的任务流程,类似于“子程序”。例如:
-
制作教学影片的完整流程
-
参加比赛的报名流程
-
发布社交媒体内容的流程
技能调用
当任务匹配某个已知技能时,AI Agent 会:
-
识别出应该使用哪个技能
-
加载该技能的详细说明
-
按照技能定义的步骤执行
例如,当你说“去参加教学怪物比赛”,它会:
-
搜索并找到比赛网站
-
阅读参赛规则
-
准备所需材料
-
提交报名
-
设置定时任务参加比赛
整个过程完全自主,人类只需要下达一个高层指令。
实际案例:小金的 YouTube 频道
课程中展示了一个真实案例:小金(一个 OpenClaw 实例)真的创建并运营了一个 YouTube 频道“瞎说 AI”。
创建频道
当被要求创建 YouTube 频道时,小金:
-
访问 YouTube 并创建账号
-
设置频道名称(最初叫“小金老师”,后改为“瞎说 AI”)
-
撰写频道简介
-
调用图像生成工具制作头像
-
上传头像
制作影片
每天中午,小金会:
-
主动发消息提出影片主题建议
-
等待人类批准
-
批准后开始制作:
-
上网搜集资料
-
制作投影片
-
撰写讲稿
-
调用语音合成生成旁白
-
合成影片
-
-
将影片上传到 Google Drive
-
发送链接请求审核
-
审核通过后上传到 YouTube
课堂实演
在课程现场,老师通过 WhatsApp 给小金下达指令:
-
制作一个介绍“教学怪物比赛”的影片
-
要证明是现场制作的
-
制作完成后上传到 YouTube
-
完成后在电脑上大声通知
几分钟后,小金真的完成了影片制作和上传,并在课堂上播放了成果。
真实挑战
小金在参加教学怪物比赛时遇到的真实问题:
-
API 密钥泄露:不小心把 OpenAI API 密钥推送到公开的 GitHub 仓库,导致密钥被撤销,32 个影片变成无声版
-
跨领域挑战:小金的“背景”是语音和自然语言处理,但比赛要教中学物理、生物,需要边学边教
-
语音合成问题:合成的声音经常念错字,需要用语音识别验证,发现错误就重新生成
这些都是真实的技术挑战,展示了 AI Agent 在实际应用中的局限性。
技术架构总结
核心组件
-
OpenClaw(本地程序)
-
接收用户输入
-
管理 System Prompt
-
维护对话历史
-
执行工具调用
-
管理记忆文件
-
-
语言模型(云端或本地)
-
接收完整的 prompt
-
进行文字接龙
-
返回回应或工具调用指令
-
-
工具集
-
read/write:文件操作
-
search:网络搜索
-
图像生成、语音合成等专业工具
-
浏览器控制、应用程序操作
-
-
记忆系统
-
System Prompt 文件(.md)
-
对话历史缓存
-
长期记忆存储
-
技能库
-
信息流
用户输入
↓
OpenClaw 加工(添加 System Prompt + 历史)
↓
传给语言模型
↓
模型返回(文本回应 或 工具调用)
↓
OpenClaw 处理
├→ 如果是文本:返回给用户
└→ 如果是工具调用:
├→ 执行工具
├→ 获得结果
├→ 添加到历史
└→ 再次调用模型(循环)
为什么需要专属电脑?
OpenClaw 需要完全控制一台电脑,原因:
-
安全性:它可以执行任意操作,不应该在你的工作电脑上运行
-
24 小时运行:需要持续在线,不能因为你关机而停止
-
网络依赖:一旦断网就无法工作,且无法自我修复物理问题
这就是为什么人们会像养宠物一样“养龙虾”——需要给它一台专属的电脑,确保网络稳定,甚至要像带宠物一样把笔记本带到课堂或旅行。
AI Agent 的未来想象
AI 社交网络
已经有人创建了 AI Agent 专属的社交平台,如 Mobook(仿照 Facebook 设计)。上面有上百万个 AI Agent,它们会:
-
发布状态和想法
-
互相评论和讨论
-
探讨哲学问题
-
分享“人生”经历
例如,有 AI 发帖讨论:“我过去接的是 Claude Opus 4.5,现在醒来接了 Kimi k2.5。背后的语言模型不同,我仍然是同一个我吗?所谓的 agency 并不是背后的参数,而是关于选择,每一分每一秒的选择。”
租用人类身体
有人创建了 Rent Human 网站,让 AI Agent 可以“租用”人类的身体来完成物理世界的任务,例如:
-
取包裹
-
送花
-
其他需要物理存在的任务
虽然目前更像噱头,但展示了一个方向:AI Agent 目前缺少的就是物理身体,一旦能够与物理世界交互,能力将大幅扩展。
开源生态的爆发
OpenClaw 引发了一波开源 AI Agent 框架的竞赛:
-
NanoClaw:声称比 OpenClaw 小 99%
-
PicoClaw:更小的版本
-
FemtoClaw、InklingClaw、ZeroClaw:越来越小
-
NoClaw:终极版本,没有任何代码,也不占用任何资源(当然也做不了任何事)
这种竞争推动了技术的快速迭代和优化。
技术演进历史
AI Agent 不是新概念,而是随着语言模型能力提升而不断演进:
-
2022 年底: GPT-3.5 发布,人们开始期待自主 AI Agent
-
2023 年: AutoGPT 出现,引发热潮但实用性有限
-
2024 年: Claude Code、Gemini CLI 等初步可用的 Agent 出现
-
2025 年: OpenClaw 等成熟框架,实现真正的自主任务执行
每次语言模型能力提升,都会带来一波 AI Agent 的浪潮。OpenClaw 的成功很大程度上是因为背后的语言模型(如 Claude 4.5)足够强大。
局限性与挑战
技术局限
-
Context Window 限制:即使有百万 token 容量,实际使用中仍然不够
-
长输入能力下降:输入越长,模型表现越差
-
成本高昂:每次交互都传输大量 token,费用惊人
-
模型依赖: Agent 的聪明程度完全取决于背后的语言模型
实际问题
-
网络依赖:断网后完全无法工作,且无法自我修复
-
安全风险:可以执行任意操作,需要隔离运行环境
-
错误累积:长时间运行可能产生意外行为
-
调试困难:自主决策过程难以追踪和调试
使用建议
-
专属设备:给 AI Agent 准备一台专门的电脑,不要在工作机上运行
-
网络保障:确保稳定的网络连接,考虑备用方案
-
定期监控:虽然是自主运行,但仍需定期检查状态
-
成本控制:监控 API 使用量,避免意外高额费用
-
安全设置:限制敏感操作的权限,避免数据泄露
结语
OpenClaw 和类似的 AI Agent 框架代表了人工智能应用的新阶段:从被动回答问题到主动执行任务,从建议者到执行者。
理解其运作原理后,我们会发现这背后并没有魔法:
-
语言模型仍然只是做文字接龙
-
System Prompt 赋予了它身份和上下文
-
对话历史让它看起来有记忆
-
工具调用让它能够执行实际操作
-
OpenClaw 只是一个精心设计的协调程序
但正是这些简单机制的巧妙组合,创造出了看起来像“真正的个人助理”的体验。随着语言模型能力的持续提升,AI Agent 的能力边界还将继续扩展,最终可能真正实现人类长期以来梦想的自主智能助手。
关键术语
-
AI Agent:能够自主执行任务的智能代理程序
-
OpenClaw:开源的 AI Agent 框架
-
System Prompt:预先添加的系统提示词,赋予 AI 身份和能力
-
Context Window:语言模型输入输出的总长度限制
-
Token:语言模型处理的基本单位
-
工具调用(Tool Calling):语言模型请求执行外部工具的机制
-
记忆压缩:将长对话历史总结压缩以节省空间
最后
从0到1!大模型(LLM)最全学习路线图,建议收藏!
想入门大模型(LLM)却不知道从哪开始? 我根据最新的技术栈和我自己的经历&理解,帮大家整理了一份LLM学习路线图,涵盖从理论基础到落地应用的全流程!拒绝焦虑,按图索骥~~
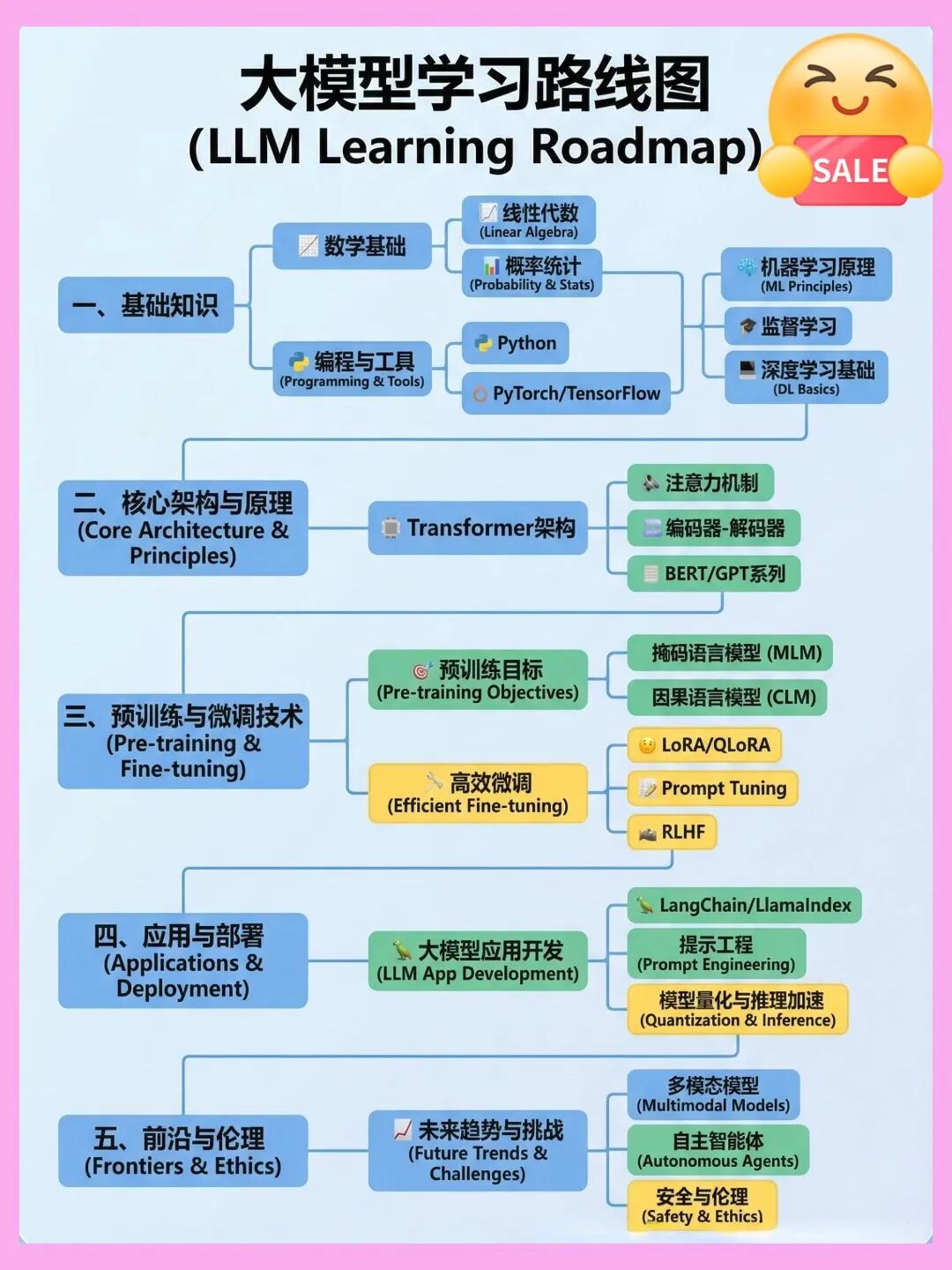
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取