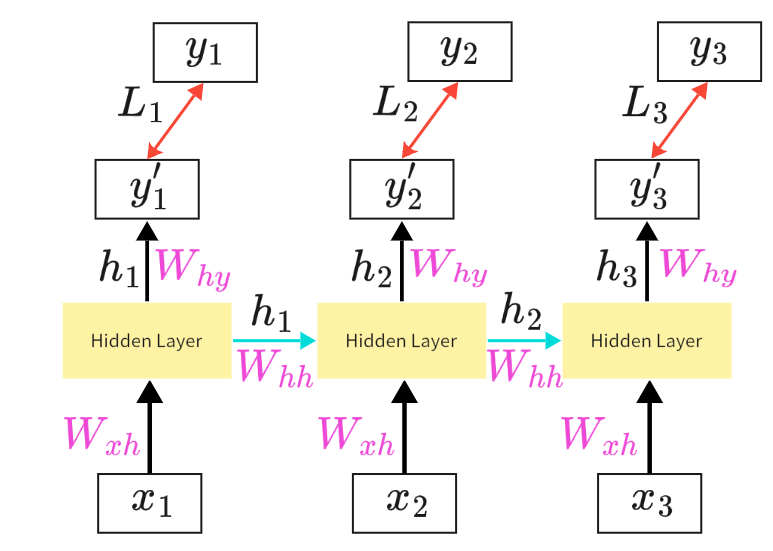
循环神经网络(RNN)
RNN
对于自然语言处理这种前后文之间有联系的任务,一般的前馈网络只能单独处理每个词,没有记忆(即无法联系前后文进行语义理解),即前馈网络处理不了 “序列依赖” 。
对于自然语言,在输入给模型前需要先将其转换为数值向量,共有两种方式:
- 1-of-N Encoding(One-Hot编码):
将可能出现的词都写入一个字典,如 {apple, bag, cat, dog, elephant}
每个词对应一个维度,该词位置为 1,其余为 0,如apple = [1,0,0,0,0],bag = [0,1,0,0,0]
这种方式虽然直观,但是词典大时向量极长,不适合作为模型的输入。通常用作损失函数的标签。
Dimension for “Other”:
在One-Hot基础上的改进,因为One-Hot 编码只能处理词典里见过的词,遇到词典里没有的词(未登录词,OOV)One-Hot 就没法编码了。
所以给One-Hot增加一个维度,遇到词典外的词直接把 Other 维度设为 1,其余为 0,如Gandalf = [0,0,0,0,0,1]- Word Hashing(词哈希):
One-Hot 编码词典越大,向量维度越高(比如词典有 10 万个词,One-Hot 就是 10 万维),计算量爆炸。Word Hashing 不是精确识别是哪个词,而是用字符片段的特征来表征词,用字符级的小片段来描述单词,既解决维度爆炸,又能处理未登录词。通常作为模型输入使用。
- 第一步,给单词加边界符,标记单词的开头和结尾。比如apple → <apple>
- 第二步,把单词拆成字符级 n-gram(通常是 3-gram,即连续 3 个字符),例如
<apple> → <ap, app, ppl, ple, le>,<Taipei> → <Ta, Tai, aip, ipe, pei, ei>
(边界符<和>也属于一个字符)- 第三步,把这些 n-gram 映射到固定低维向量。Word Hashing 的 3-gram 词典是语料里实际见过的片段集合,而非所有字母组合的全集,所以实际上Word Hashing 维度通常在几千维,完全可控。
假设 3-gram 词典只有 8 个维度:[<ap, app, <Ta, Tai, <Ga, Gan, <ar, arr]的向量:
<apple>[1,1,0,0,0,0,0,0](只包含<ap, app>)<Taipei>的向量:[0,0,1,1,0,0,0,0](只包含<Ta, Tai>)<arrive>的向量:[0,0,0,0,0,0,1,1](只包含<ar, arr>)
所以模型不是认Taipei这个词,而是认字符片段,只要片段相似,模型就会认为单词的角色相似。在训练一个能处理序列的模型时,通过 Word Hashing 将输入单词进行编码再喂给模型。在序列标注 / 槽填充 / 语言建模等分类任务中,通常用 One-Hot 来作为标签值,如某槽填充任务中有 “time”,“destination”,“name”三个槽位,此模型处理某个句子时会通过计算将它认为正确的槽位输出,比如 “Beijing” 属于 “destination” ,则在处理后模型输出[0, 1, 0]。
输入一句自然语言,如“I would like to arrive Taipei on November 2”,Word Hashing将其中的每个词转换为对应的数字向量,然后依次作为模型输入向量来计算得到输出。对于前馈网络,每个词单独作为模型输入,最终输出只是单个词的标签,比如它只知道自己看到了 “Taibei” 而无法将它与上下文联系起来理解。
如果再输入一句自然语言,如“I would like to leave Taipei on November 2”,对于前馈网络来说,它依然只知道 “Taipei” 而不知道是“leave” 还是 “arrive”。
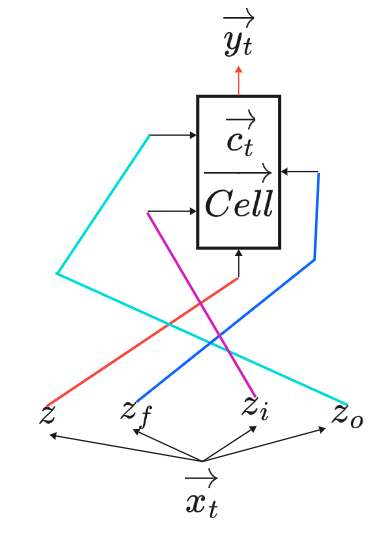
神经网络必须要有 “记忆” ,才能记住前面的词(arrive/leave),从而正确判断当前词的正确角色。RNN(Recurrent Neural Network,循环神经网络)的核心思路就是通过循环连接(把上一步的输出作为下一步的输入)让网络在处理当前输入时,能记住之前所有输入的信息,并把这些信息传递到下一步,让模型能建模序列里的上下文依赖,比如文本里的语序、时间序列里的先后关系。
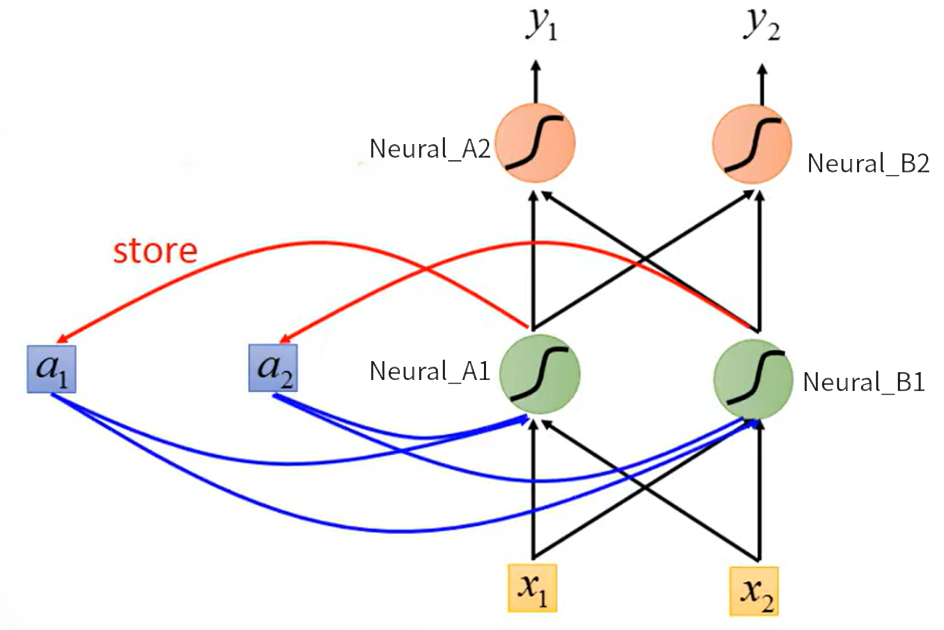
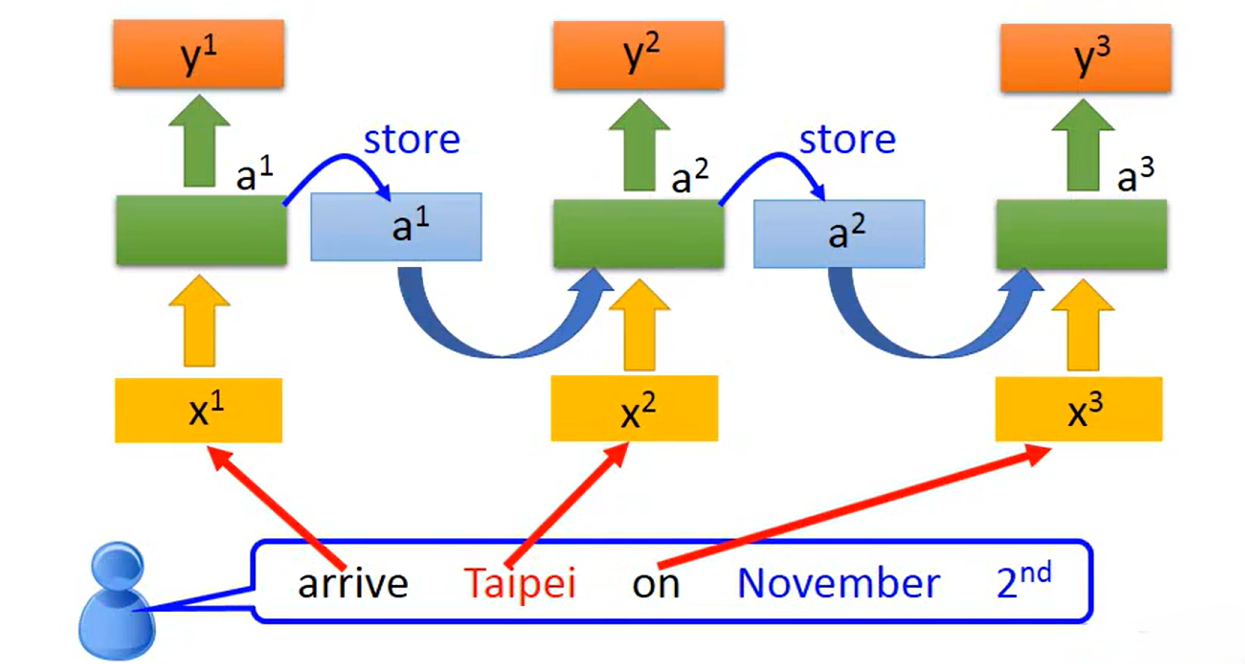
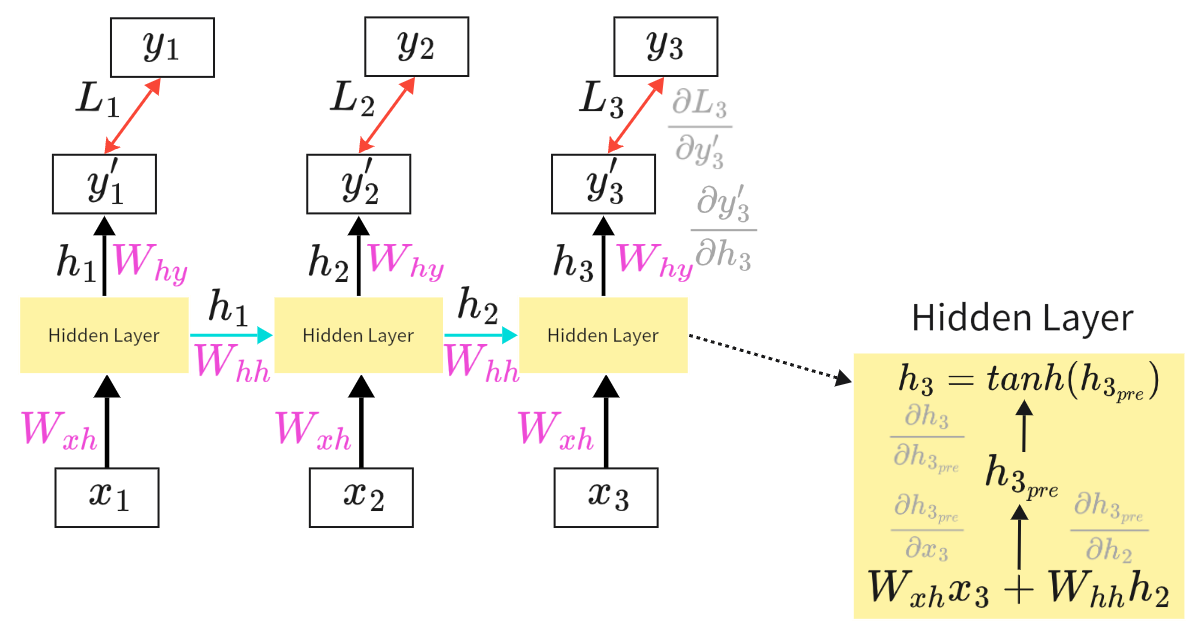
RNN的具体实现方式如下图所示。假设输入向量只有两个特征,Neural_A1和Neural_B1拿到输入
后计算得到两个输出
,RNN的创新点在于它不仅将
作为Neural_A2和Neural_B2的输入继续沿神经网络前馈,并且还将Neural的输出
存储起来作为下一个向量
输入神经网络时的输入。即下一个向量(如“Taipei”)输入神经网络时,神经网络的输入不仅有此向量的
还有上一个向量计算得到的
。由此可以得到RNN 的状态更新公式为:
![]()
这就是 RNN 的 “记忆” ,把历史信息压缩到状态向量里,供后续步骤使用。
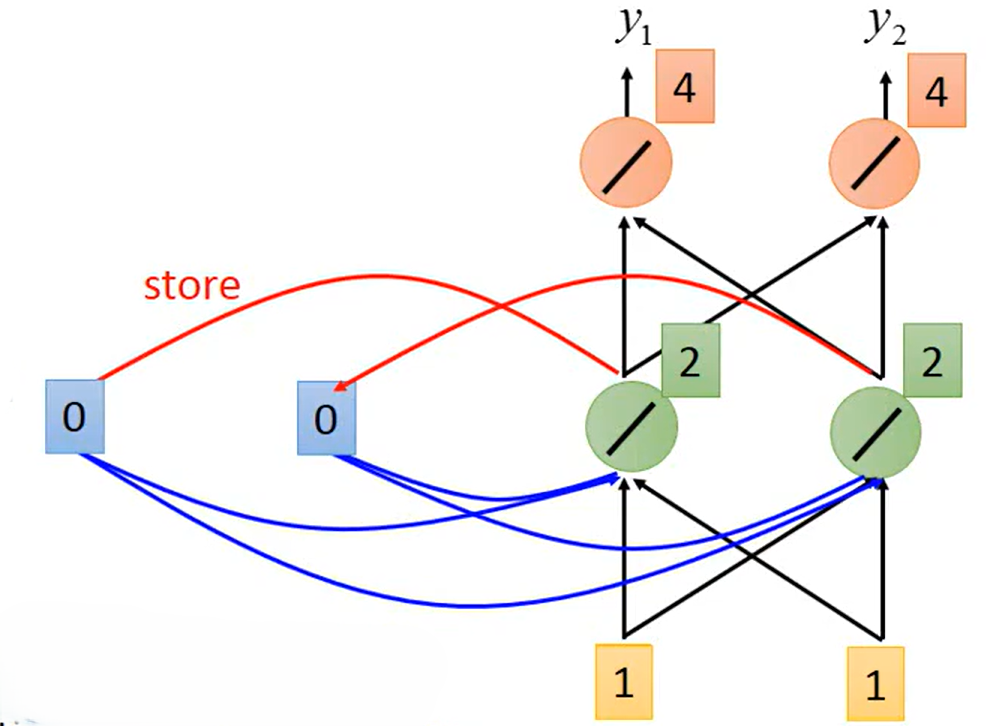
示例演示:
假设所有的权重均等于 1 ,无偏置。初始时存储的
均为0,即
,
input sequence =
。
第一步输入
,
,将
储存,并继续前馈计算得到输出
。
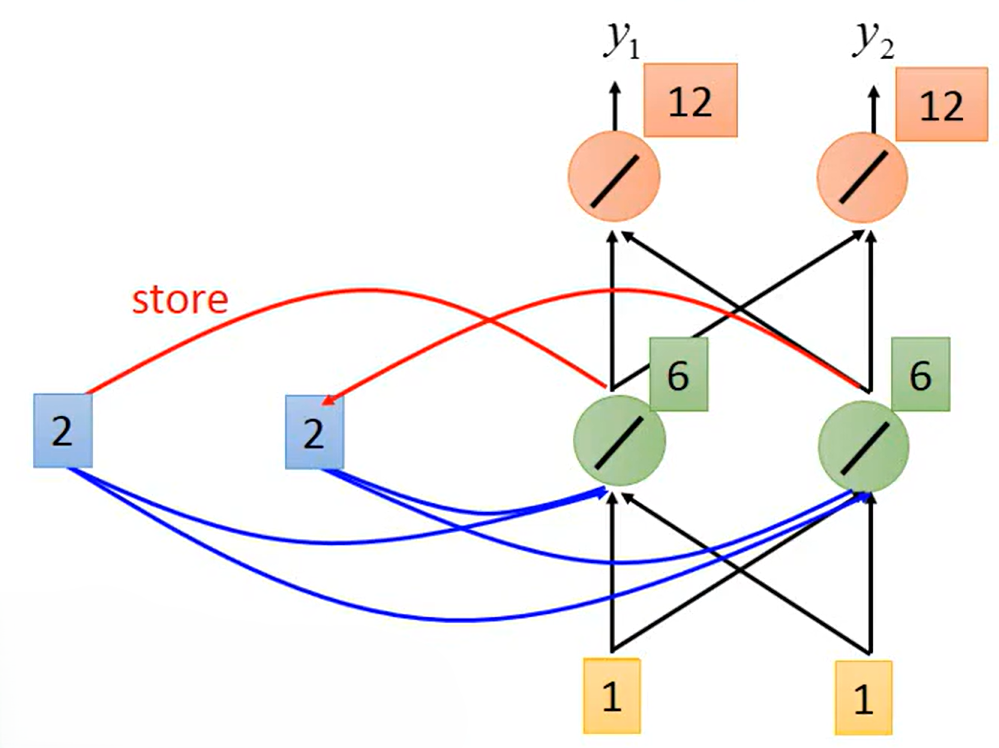
第二步输入
,
,将
储存,并继续前馈计算得到输出
第三步输入
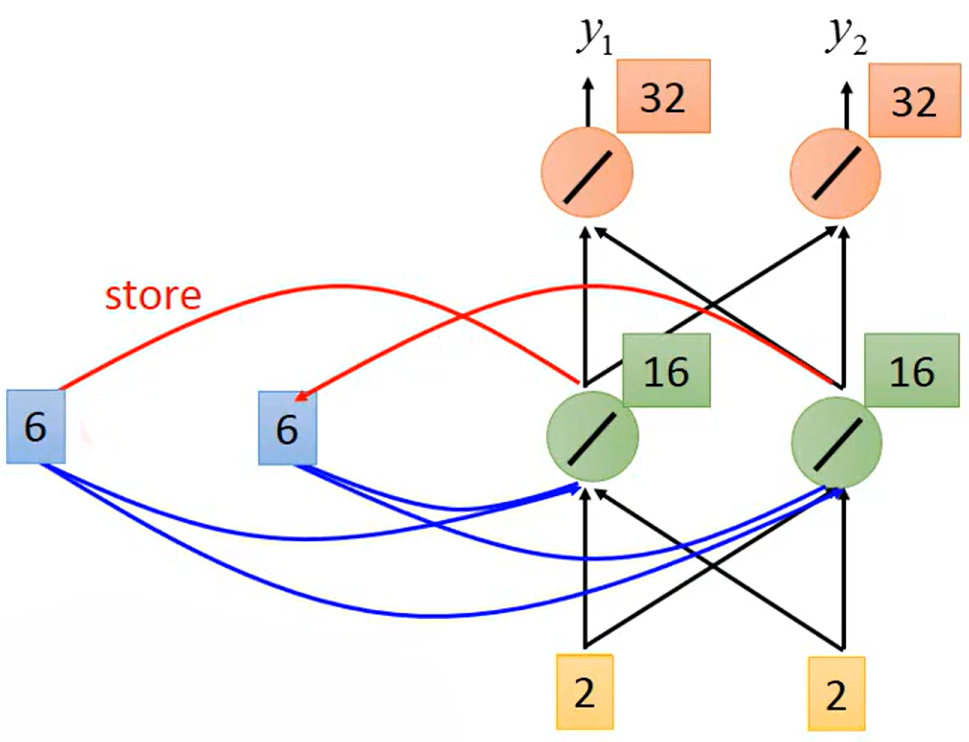
,
,将
储存,并继续前馈计算得到输出
最终得到输出序列
output sequence=
。如果调换input sequence
对于之前的例子,“arrive Taipei on November 2”在RNN模型中的过程如下。将词 “arrive” 输入RNN模型,存储中间Neural计算得到的再作为下一步的输入,依此类推,将“Taipei”、“on”等依次输入同一个RNN模型,得到最终的输出
,如果是不同的词语组合,则最终得到的输出值就不同,就可以区分不同的语义。
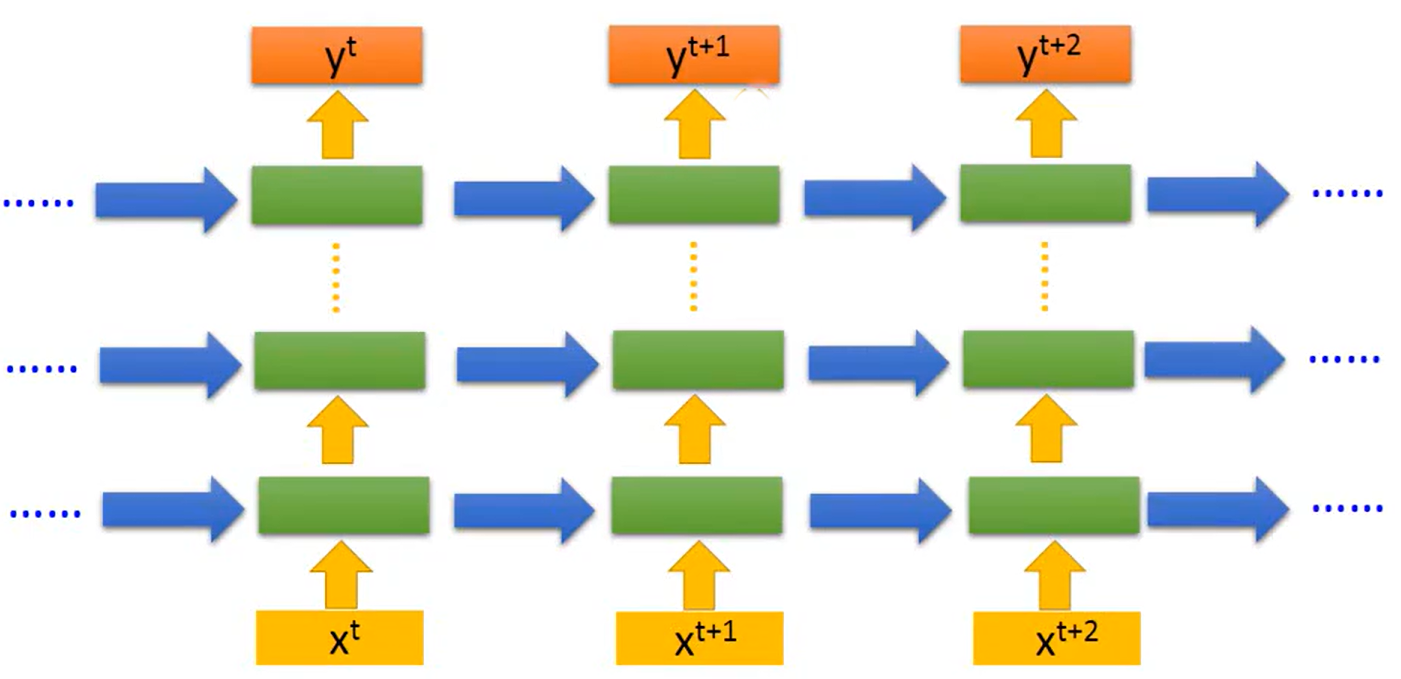
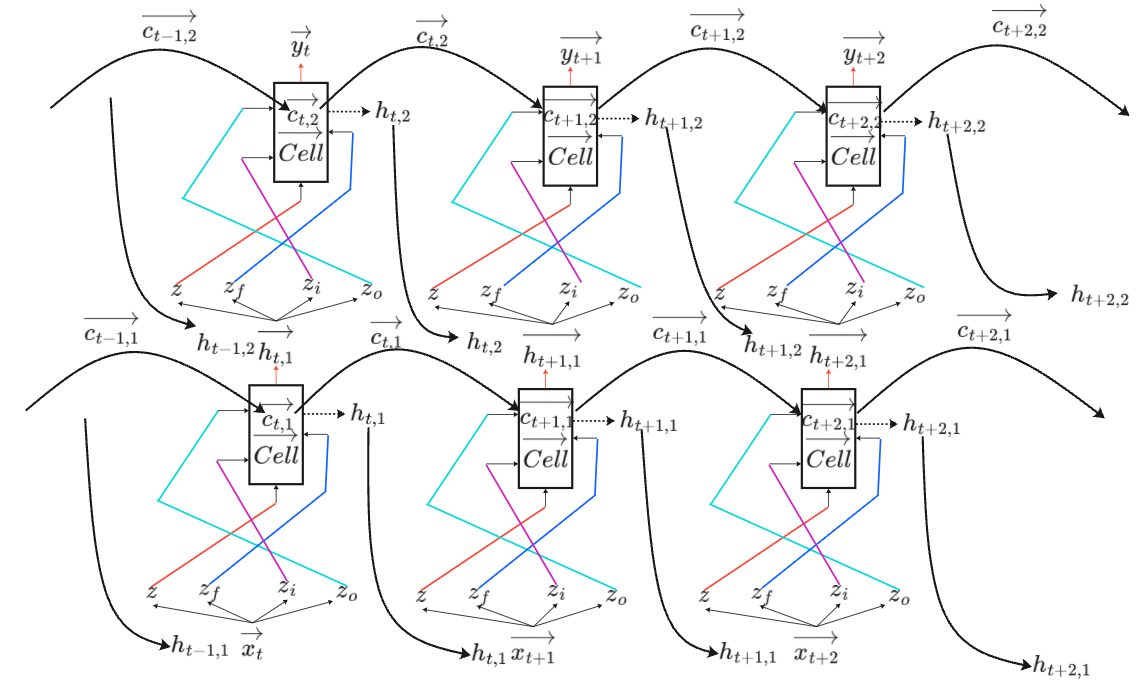
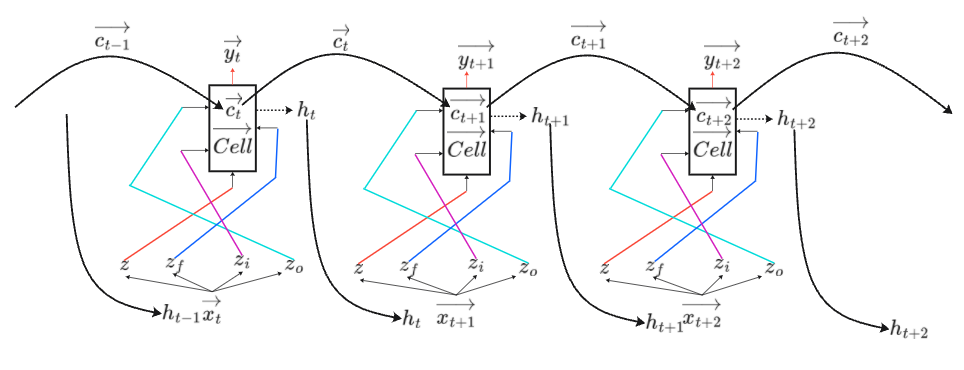
上述的RNN模型只有一个Hidden Layer(隐藏层),当然可以多加几个Hidden Layer将模型设计的更深。如下图所示,思路相同,将每一个Hidden Layer计算得到的输出值存储起来作为下一个时间点Hidden Layer的输入。
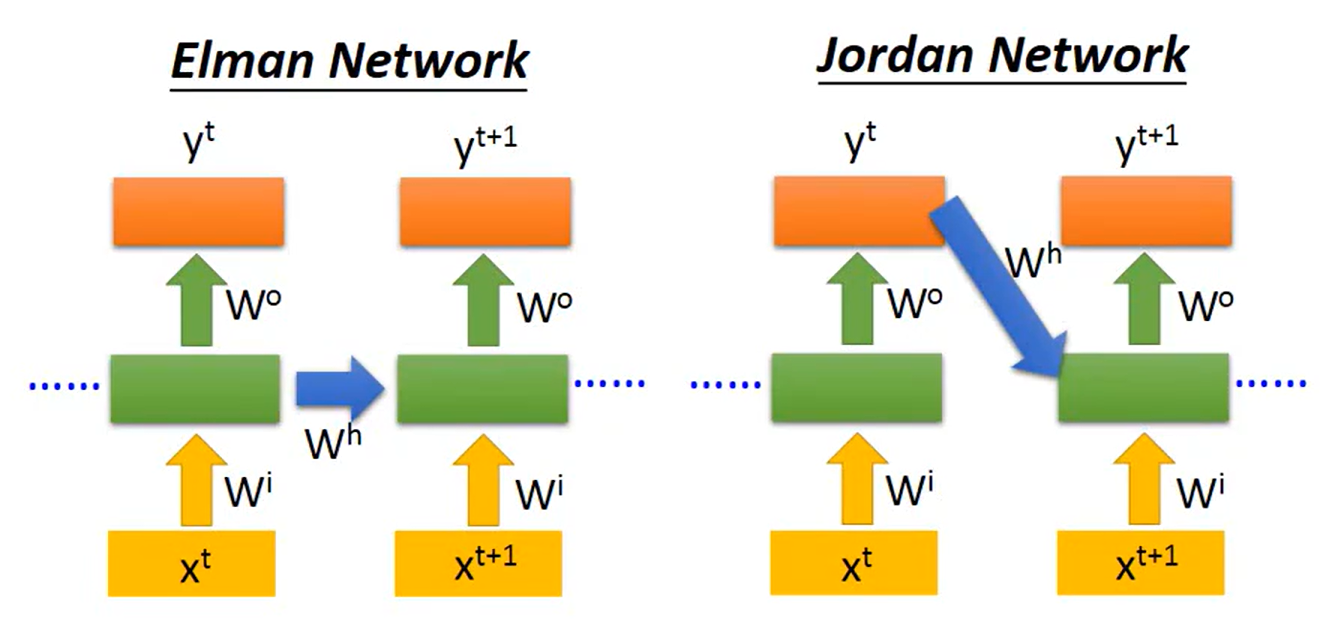
早期的RNN主要用两种:
上面主要介绍的是Elman Network,它是将Hidden Layer的输出存储起来作为下一个时间点同样位置的Hidden Layer的输入。而Jordan Network是将上一个时间点的模型输出
和下一个时间点的向量一起作为输入。
- Elman Network:
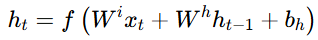
:上一时间点Hidden Layer计算得到的值。
:此时间点同样位置的Hidden Layer计算得到的值。其输入包括正常前馈的输入
和
- Jordan Network:
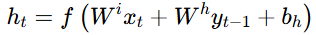
:上一时间点模型输出。
Elman Network循环路径更长,易梯度消失 / 爆炸。擅长捕捉输入序列内部的复杂依赖,适用于需要丰富上下文细节的任务,比如自然语言处理(理解句子语序、语义依赖)、序列标注(给每个词打标签)。
Jordan Network循环路径更短,梯度传播更稳定。擅长捕捉输出序列之间的时序依赖,适用于输出本身有强时序依赖的任务,比如时间序列预测(明天的销量依赖今天的销量)、文本生成(下一个词依赖上一个生成的词)。
激活函数的选择
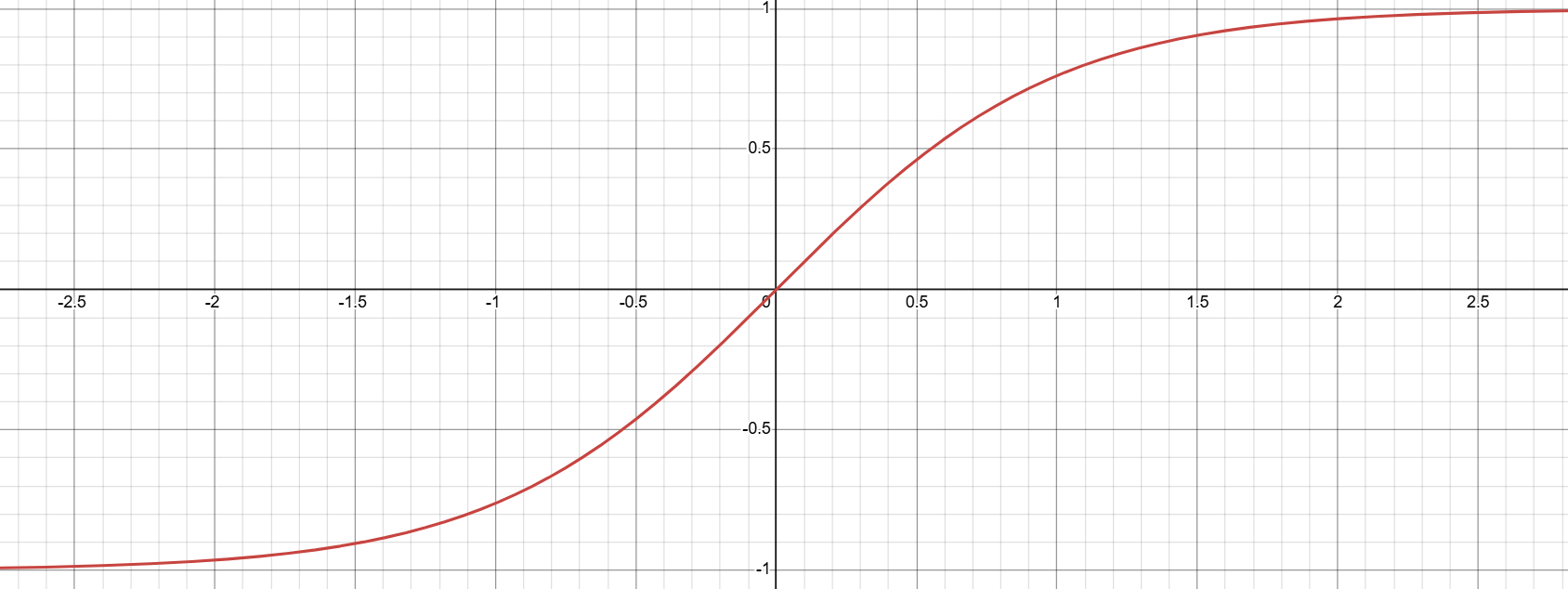
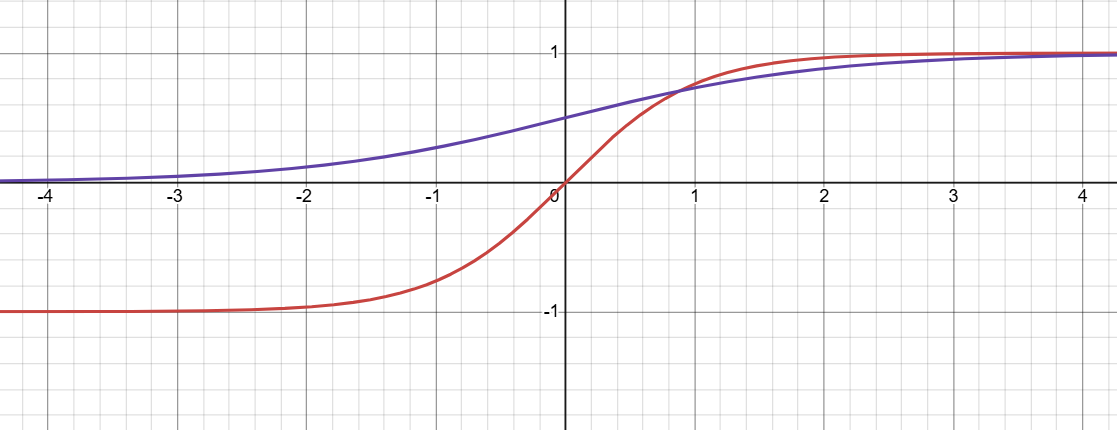
RNN使用 tanh(双曲正切) 做激活函数,tanh 是 S 型单调奇函数:
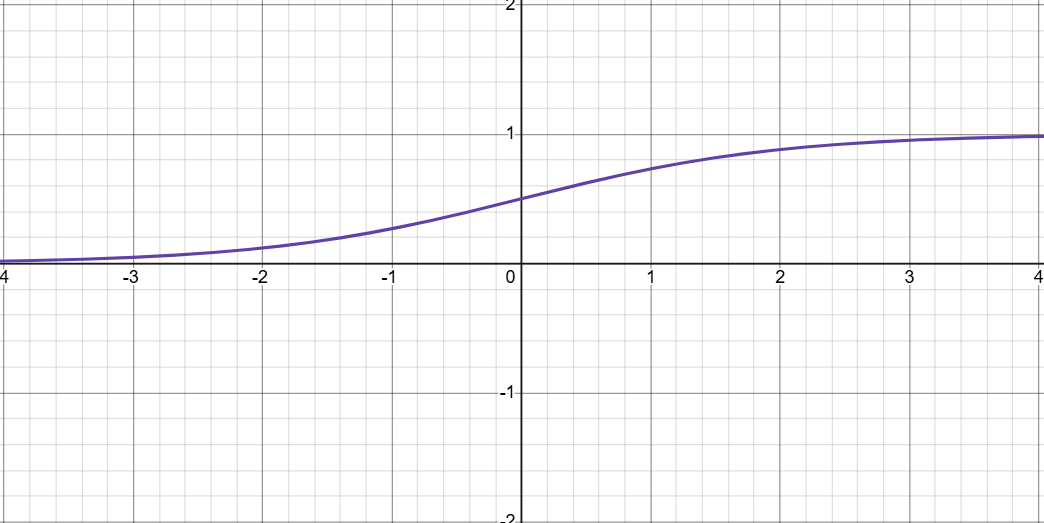
Sigmoid函数:
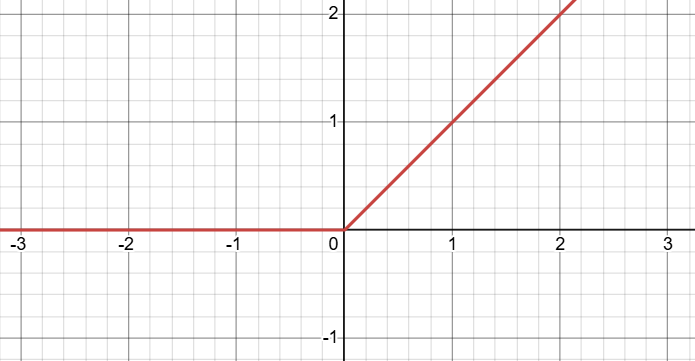
ReLU函数:
tanh和Sigmoid函数之间的关系是:
tanh的导数:
- 在
处导数最大为 1
- 当
时,函数值趋近于
,导数趋近于0
Sigmoid的导数:
- 在
- 当
ReLU的导数:
- 输入为正数,则输出等于输入,导数为 1
- 输入为负数,则输出为 0 ,导数为 0
RNN之所以使用tanh,原因如下:
- tanh 的导数最大值为 1(sigmoid 仅为 0.25),在循环梯度传递中,梯度衰减速度比 sigmoid 更温和,一定程度缓解梯度消失。
- tanh输出范围 (−1,1),均值为 0,相比 sigmoid(输出 (0,1),均值 0.5),能减少数据分布偏移,让梯度传播更稳定。
- ReLU不会像tanh一样将输出值压缩在
之间。如果
中的权重
大于1,那每一步都乘
并且ReLU 导数只有 0 和 1 两个可能,只要某一步,导数直接变 0,直接导致梯度消失。
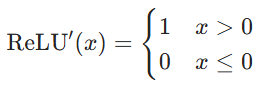
损失函数的选择
RNN 处理序列数据,损失函数是各时间步局部损失的累加或平均,具体形式由任务类型决定:
类别一:序列标注 / 槽填充 / 语言建模(分类任务,逐时间步输出类别)
这类任务中,每个时间步 t 输出类别概率分布(经 softmax 激活),使用交叉熵损失(Cross-Entropy)作为损失函数。单时间步损失(第 t 步):
:类别总数(如槽填充的
dest/time/other,或语言建模的词典大小):第 t 步真实标签的 one-hot 编码(类别 c 为 1,其余为 0)
:模型在第 t 步对类别
的预测概率(softmax 输出)
同一个模型同一套参数对句子里每一个位置 t,都输出一个分类概率,并且对每一个位置 t,都算一次交叉熵损失
总损失为(序列长度为
):
训练时常用平均值稳定梯度:
用这个总损失反向传播来更新参数。
类别二:序列分类(整个序列对应一个类别,如情感分析)只在最后一个时间步
类别三:序列回归(如时间序列预测,输出连续值)使用均方误差(MSE),总损失是各时间步误差的平方和 / 平均。
单时间步损失:
总损失:
以分析句子 “I love AI” 为例,使用Elman Network来说明RNN的完整训练流程:
- 数据预处理:
- 分词:将句子 “I love AI”分成3 个时间步单词 →
[I, love, AI] - 词向量编码:将单词转为向量(使用Word Hashing编码),这里为了简便,直接将其简化为二维向量
I →
love →
AI → - 输入:
待训练参数:输入→隐藏层权重
隐藏层→下一时间步隐藏层权重
隐藏层→输出权重
偏置
- 分词:将句子 “I love AI”分成3 个时间步单词 →
- 前向传播流程:
RNN 是时序循环结构,每一步都会复用同一套参数,并把上一步的隐藏状态传给下一步。时间步总数
,流程如下:
-
时间步
(输入 I ):
计算隐藏状态
计算输出
计算损失 -
时间步
(输入 Iove ):
计算隐藏状态
计算输出
计算损失 -
时间步
(输入 AI ):
计算隐藏状态
计算输出
计算损失 -
总损失
-
-
BPTT反向传播:
BPTT(Back Propagation Through Time)是 RNN 专用的反向传播算法,核心是把时序展开的 RNN 当成深度神经网络,从最后一步往第一步反向求导,更新共享参数。
RNN前向传播公式:
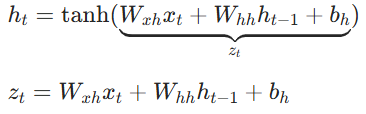
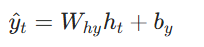
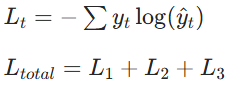
-
输出层梯度
隐藏层梯度
激活函数梯度(tanh)
最终得参数梯度 -
输出层梯度
隐藏层梯度
激活函数梯度(tanh)
最终得参数梯度
输出层梯度
隐藏层梯度
激活函数梯度(tanh)
最终得参数梯度- 所以总损失对参数的梯度:
-
- 参数更新:
RNN梯度消失 / 爆炸 的问题出现的原因:
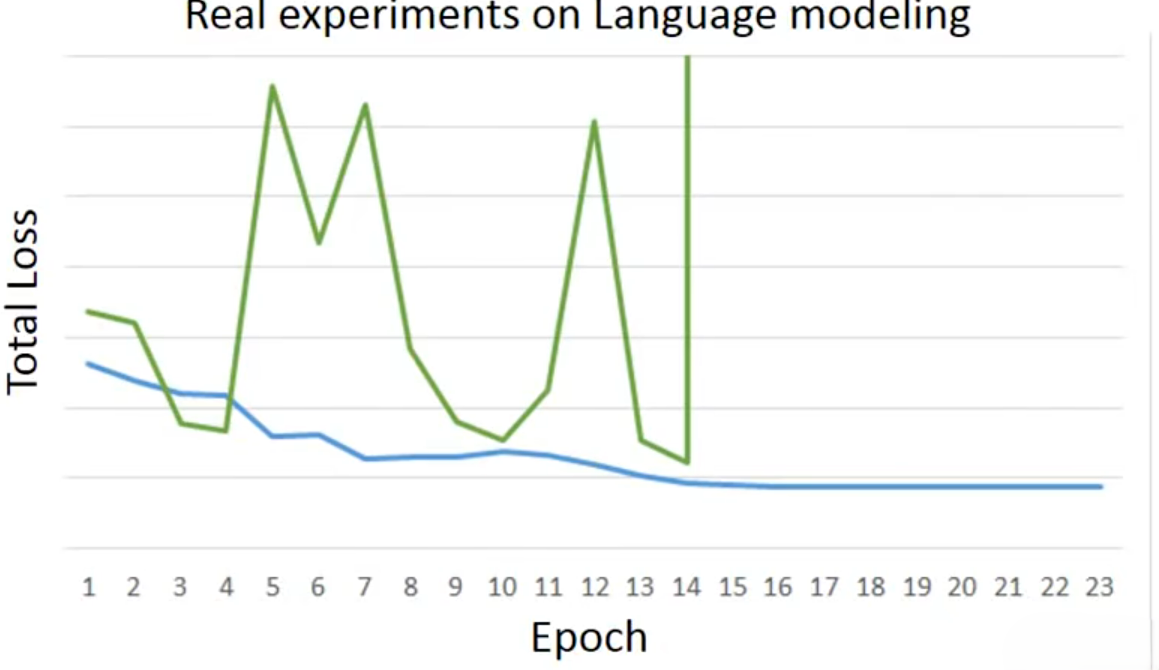
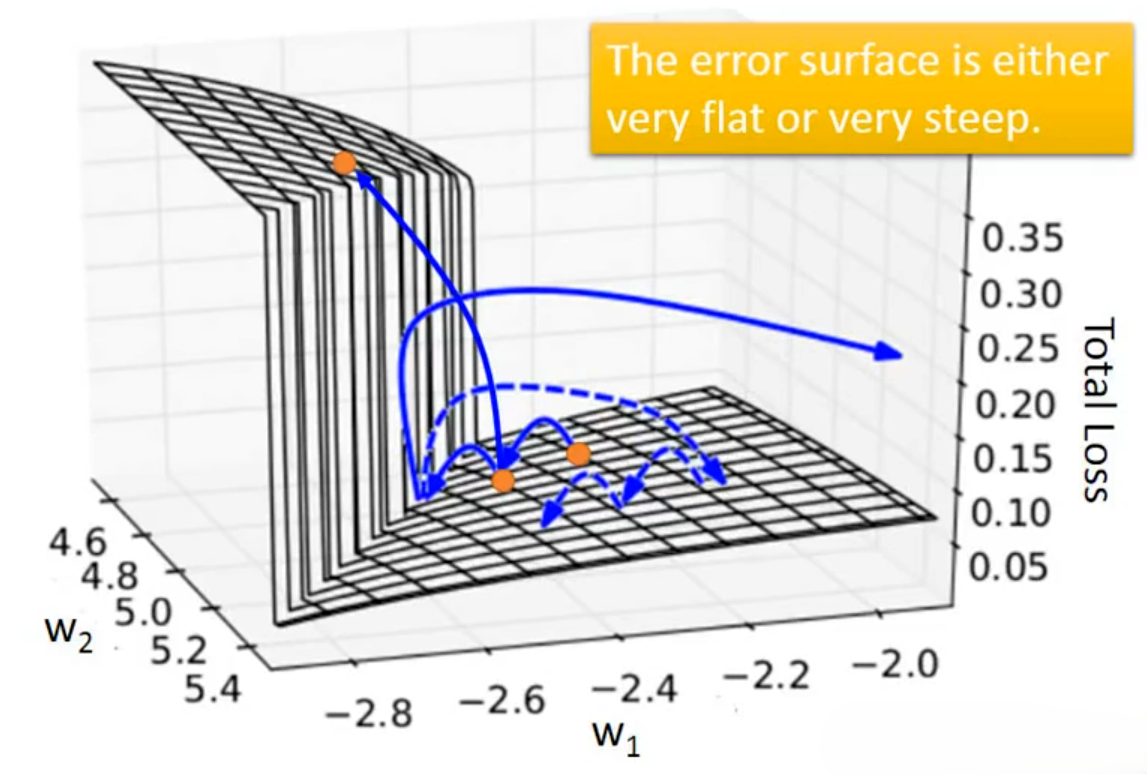
下图展示了RNN模型的训练对比图。蓝色曲线是正常训练的损失曲线,随 Epoch 增加平稳下降并收敛,符合语言模型训练的预期规律;绿色曲线为异常训练的损失曲线,出现剧烈震荡、多次陡升陡降,最终在 Epoch14 处发生梯度爆炸(损失瞬间飙升至无穷大),训练完全崩溃。绿色曲线就是出现了RNN 训练中 BPTT 算法导致的梯度爆炸问题,这是 RNN最经典的训练缺陷。
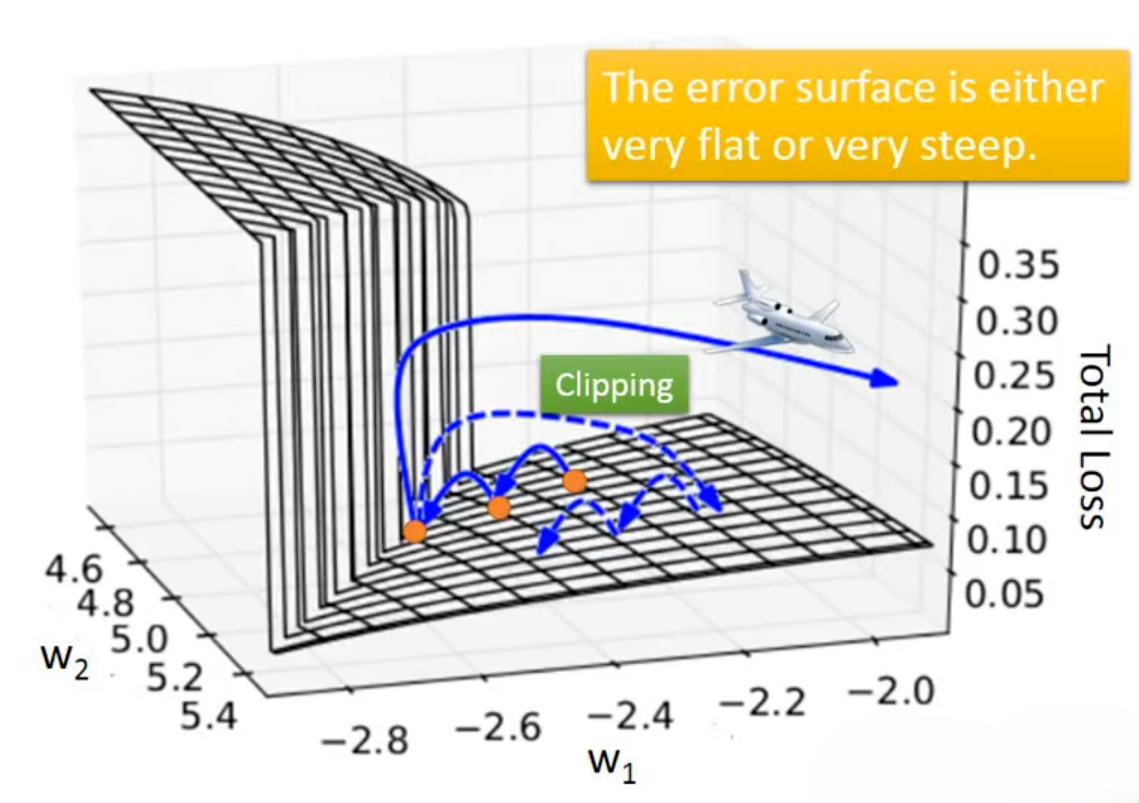
下图是RNN模型参数与损失关系图(以两个参数为例)。展现了RNN 训练崩溃(梯度爆炸 / 消失)的几何本质,RNN训练时经常出现这种曲面局部极陡以及曲面局部极平的问题,从而导致训练崩溃。
之所以会出现这种局部极陡及局部极平的情况,是因为 RNN 在 BPTT 训练时
在上面介绍分析句子 “I love AI”的示例时,我们在最后得出了总损失对参数的梯度,即
其中
即
其中
这两项可以通过损失函数和模型结构算出,
就是激活函数tanh的导数,这也是已知的。累乘特性体现在
这一项中,之所以没有直接给出,是因为这是一个复杂的公式。下面我们只介绍它的累乘特性,不会给出详细的公式:
RNN隐藏状态公式是
,这意味着
,形成一条
的链式依赖。对于
,根据
,你可能会认为
,但实际上这是一个嵌套公式,
看似是一个线性公式,实际上
仍是一个与
也仍是一个与
是一个很复杂的式子,其中
是激活函数tanh的导数,每出现一次
都会乘一次
足够大的话,累乘项会指数级放大 / 缩小梯度,直接导致梯度爆炸 / 消失。具体体现为:
:曲面局部极陡,引发梯度爆炸,训练崩溃。
:曲面局部极平,引发梯度消失,模型无法学习。
针对梯度爆炸问题,工程上常使用梯度裁剪(Gradient Clipping)的方法,核心思路是给梯度的最大模长设一个「刹车阈值」,一旦梯度超过这个阈值,就把它按比例剪到阈值以内,防止参数更新步长失控。主流的梯度裁剪方法包括范数裁剪(Norm Clipping)和值裁剪(Value Clipping),这里不做过多介绍。
关于其他解决方法,下面会一一介绍。
(选读)多维输入下 RNN梯度消失 / 爆炸 的问题出现的原因(矩阵版):
下面通过公式推导说明 普通 RNN 在处理长序列时会出现梯度消失 / 爆炸 的问题:标准 RNN 前向传播公式:
:输入→隐藏层权重
:隐藏→输出层权重
根据求导链式法则,要计算总损失
对循环权重

由于
,这将直接影响
,除此之外还会影响后续所有隐藏状态
,间接影响
。所以:
写成递推形式,即:
- 当
时,无后续步骤,故
由式
得:
表示两个同维度矩阵 / 向量,对应位置的元素分别相乘。
- 对于多维输入输出,上式的
均为
维向量,则
为
的矩阵,
是
相乘。
就是
向量的对应元素相乘。
梯度递推公式:
- 这里为了方便表示,省略当前步梯度
,只保留未来步回传,不影响核心结论
将上式递推展开(从
):
所以任意早期步
将上述
总损失对
是隐藏状态对循环权重的梯度,由前向公式求导得到。
求解
tanh 的导数为逐元素运算:
是
也是
- 两个列向量之间求偏导,得到的是雅可比矩阵(
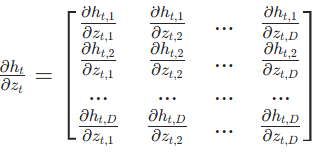
- 由于 tanh 是逐元素独立的激活函数,即
,
仅由
决定,所以雅可比矩阵的非对角元全为0,仅对角元为 tanh 的导数:
的作用就是把向量转成对角矩阵。我们先算出tanh的导数向量:
就是将向量
放在矩阵对角线上,其余位置补 0,得到的
对
,因此对
项:
个元素为
,因此对
的偏导为:
对其他的偏导为 0。
- 克罗内克积(Kronecker Product)
是两个矩阵的张量积,用于将矩阵维度扩展。
若,则
。举一个简单的例子:
,
,根据矩阵求导规则,
应该是一个
的三阶向量(每个
,克罗内克积后得到
的矩阵
所以用矩阵表示这个关系就是。
所以
- 根据克罗内克积的核心性质
,得:
- 因矩阵转置不改变梯度更新的本质,所以直接使用外积形式
将所有时间步(从
参数更新公式为:
观察式子,其中
(最大特征值的绝对值)决定了乘积的趋势:
- 如果
,随着
增大,乘积项指数级衰减,最终趋近于 0,导致梯度消失
- 如果
,随着
普通 RNN 只有一个隐藏状态
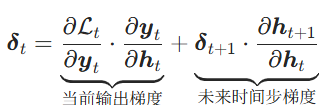
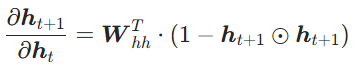

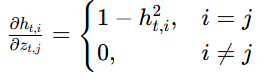
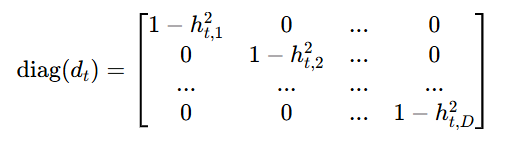

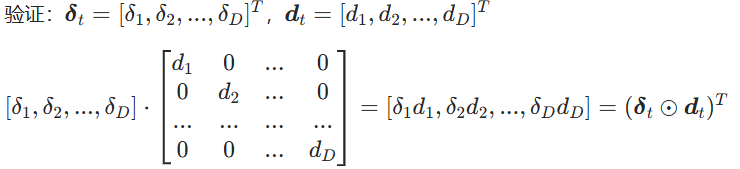
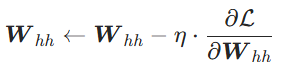
RNN的应用场景
Many-to-Many(多对多,等长序列):输入序列 → 等长输出序列。输入输出一一对应,每个时间步的输入对应一个时间步的输出,RNN 在每个时间步都输出结果。
例如,槽位填充(Slot Filling)任务中,用户输入语句序列(arrive、Taipei、on、November、2nd),RNN经过处理后分别预测每个词在槽位中的概率(如「Taipei」对应「目的地」槽位,「November」对应「时间」槽位)。
Many-to-One(多对一):输入序列 → 单个输出。输入是长度为 T 的向量序列,输出仅为1 个向量 / 1 个分类结果,RNN 会将整个序列的信息压缩到最后一个时间步的隐藏状态中,再做后续预测。
例如,情感分析(Sentiment Analysis)任务中,用户输入一段文字“这部电影太糟了”,经过RNN处理后输出单个情感分类结果(Positive/Negative)。
再比如,关键词提取(Key Term Extraction)任务中,输入整篇文档(document),使用双向 LSTM(图中上下两条 RNN 链)分别建模正向 / 反向上下文,最后一个时间步整合全文信息;下方注意力层(
)自动学习每个词的重要性权重,最后输出单个全局向量,用于提取文档的核心关键词。
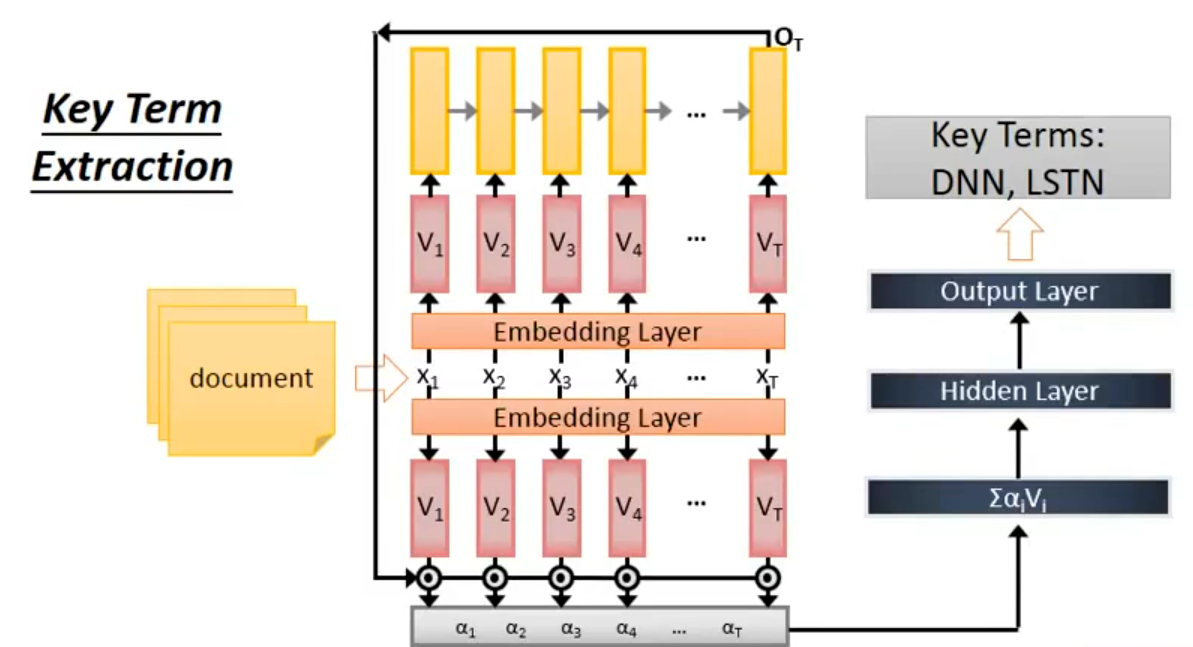
Many-to-Many(多对多,不等长序列):
案例一:语音识别任务。输入长时序语音特征序列(如 MFCC、FBank 特征,对应下方图的波形→蓝色向量序列),长度远大于输出文本长度(语音采样率高,1 秒语音对应上百帧特征)。输出是更短的文本字符序列(如中文「好棒」),输入输出长度不固定、无严格对齐关系。
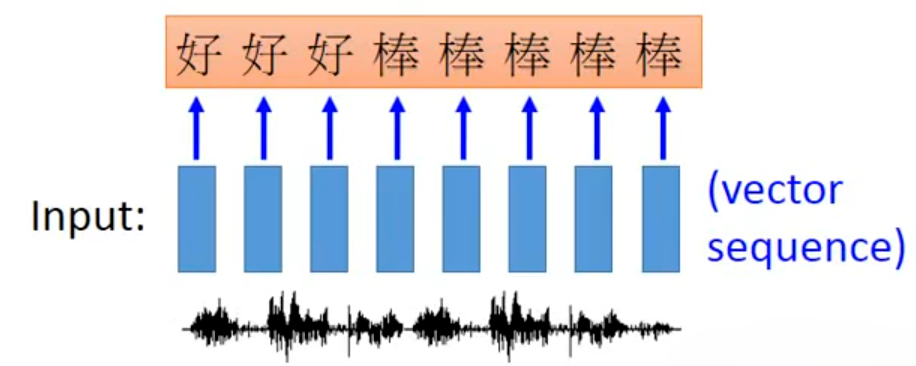
普通 RNN 等长 Many-to-Many 要求输入输出一一对应,但语音识别中语音帧和文字没有天然的硬对齐关系(比如「好」可能对应 3 帧语音,「棒」对应 5 帧,且不同人发音时长不同),直接训练无法收敛。如上图所示输入 8 帧语音特征,RNN 逐帧输出「好 好 好 棒 棒 棒 棒 棒」,为了提取出输出,简单的方法是直接去重,称为Trimming,最终得到输出「好棒」
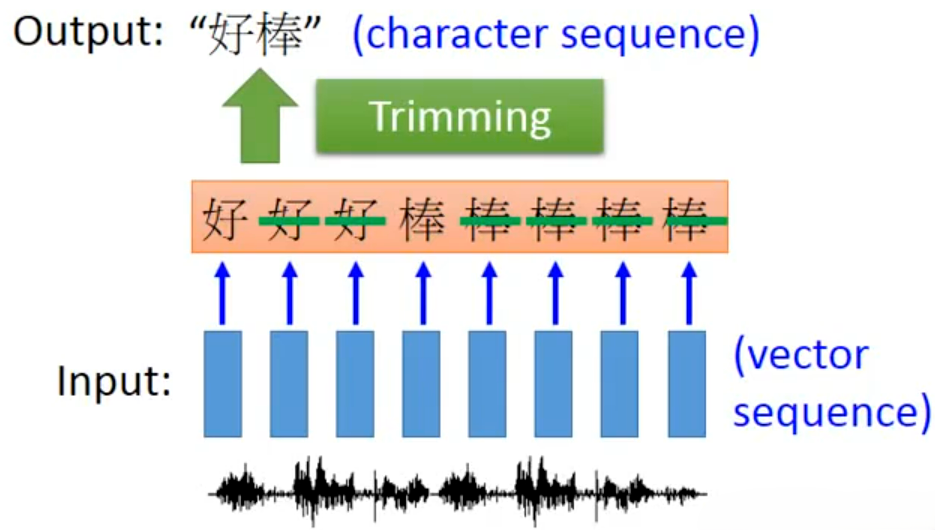
这种直接去重有明显缺陷,它无法处理连词,如“绿油油”会直接被处理为“绿油”。
CTC是解决语音识别对齐问题的核心技术,它在字符集里新增一个特殊符号「空白符 φ」(空白符不代表任何实际字符,只用来表示 “这一帧没有对应有效字符”),对于目标标签 Y = [好, 棒],任何满足 “去重 + 删空白符后等于 Y” 的中间序列,都被视为正确路径(CTC 在训练时,会把所有合法路径的概率加起来,作为模型输出标签 Y 的总概率),例如(语音输入为 6 帧):
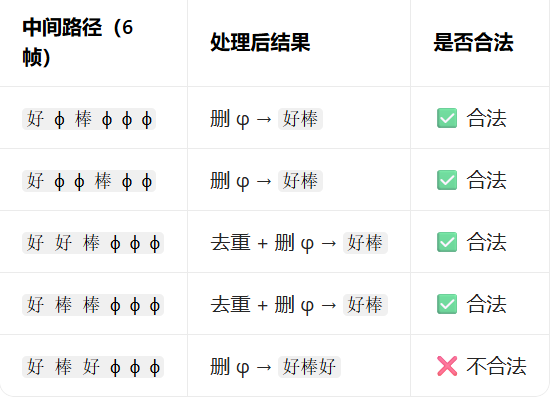
训练完成后,模型会输出每帧的「字符 / 空白」概率分布,解码时取每帧概率最高的符号(比如好 φ 好 φ 棒 φ φ 棒),然后合并连续相同的非空白字符并删除所有空白符,最终得到目标文本(“好棒”)。
CTC完整流程如下:
- 训练阶段:模型自主学习 “什么时候输出什么”。
以语音识别 “好棒”为例,输入 8 帧语音特征:- 输入语音帧
,RNN 输出每帧的「字符 / 空白」概率分布
(比如:
好0.8,φ0.1,棒0.1) - 枚举所有合法路径。所有能拼成
好棒的中间序列(比如好 φ φ 棒 φ φ φ φ、好 好 φ 棒 φ φ φ φ等) - 累加所有合法路径的概率,得到模型输出
好棒的总概率。 - 计算CTC损失。
,其中
是所有合法路径的概率之和
- 反向传播更新参数,调整 RNN 权重,让合法路径的总概率最大化(损失最小化)
- 迭代训练,模型逐渐学会
好的语音帧输出好,棒的语音帧输出棒,过渡帧输出φ
- 输入语音帧
- 推理阶段:训练完成后,输入新的语音帧
- RNN输出每帧概率,得到 8 帧的「字符 / 空白」概率分布
- 贪心取每帧最高概率得到中间序列:
好 好 φ 棒 棒 φ φ φ - 合并连续重复字符,得到
好 φ 棒 φ φ φ - 删除所有空白符,最终输出
好棒
通过训练模型会自己发现只有当字符出现在对应语音帧、空白出现在过渡帧时,合法路径的总概率最大,损失最小。所以模型会自发地在对应字符的语音帧,输出该字符的高概率,在字符的过渡、静音、重复发音帧,输出空白符的高概率。
对于目标标签 “好棒”,模型会学习到中间序列好 φ 棒 φ φ φ,去重删空白后是好棒;
对于目标标签“好棒棒”,模型会学习到中间序列好 φ 棒 φ 棒 φ φ,去重删空白后是好棒棒;
因为不同标签的合法路径集合完全不同,损失函数会驱动模型输出对应标签的路径。
案例二:机器翻译。输入任意长度的源语言序列(如英文 machine learning、how much is the breakfast?),任意长度的目标语言序列(如中文 机器学习、法语 combien coûte le petit déjeuner?)。输入和输出长度完全不固定、无强制对应关系,是最通用的序列建模场景,也被称为 Sequence-to-Sequence (Seq2Seq) 学习。
以英文 “machine learning” 翻译为中文 “机器学习” 为例:
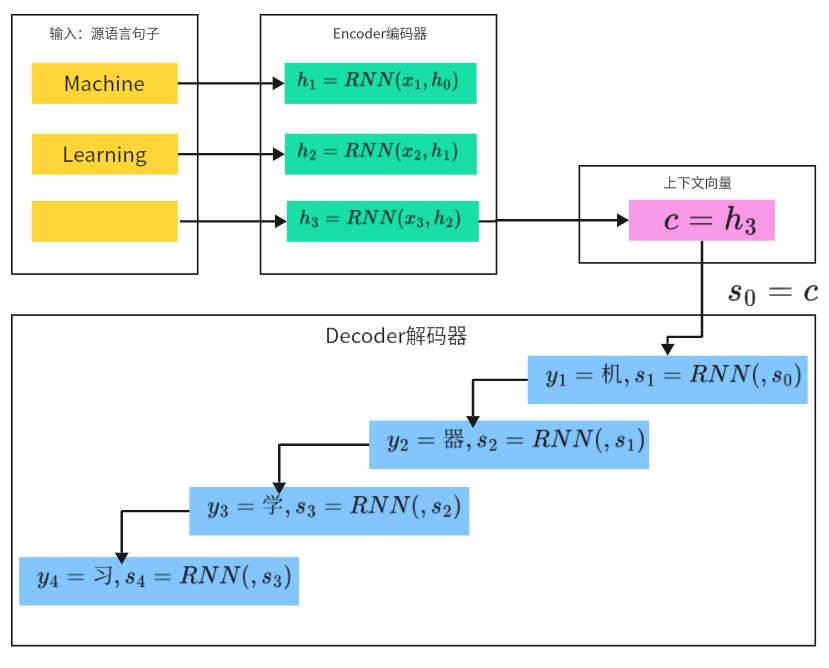
- Encoder(编码器):作用是把源语言序列压缩为全局上下文向量。
英文词序列machine,learning依次输入双向 / 单向 RNN(LSTM/GRU),RNN 逐时间步传递隐藏状态,最后一个时间步的隐藏状态,就是整合了整句语义的上下文向量(Context Vector)。(额外添加断句符号===(<sos>/<eos>),标记源语言序列的结束,通知编码器完成编码) - Decoder(解码器):作用是从上下文向量生成目标语言序列。
以编码器的上下文向量为初始状态,逐时间步生成目标语言词。每一步的输入是上一步生成的词(如第一步输入<sos>,生成机;第二步输入 机,生成 器,以此类推),直到生成<eos>结束符,停止解码
但是上述这种只使用基础Seq2Seq的方法,会有一个核心缺陷,即只能处理短序列信息,因为编码器把整句信息压缩到一个固定长度的上下文向量中,对于长句子而言上下文向量无法承载全部信息,早期输入的信息会被后期信息覆盖,导致翻译错误。为了解决这个问题,通常在Seq2Seq的基础上加上注意力机制(Attention),这个我们后续介绍。
案例三:句法分析(Syntactic Parsing)。句法分析是自然语言处理(NLP)的基础任务,目标是给一段自然语言句子,分析出它的语法结构(句法树),明确句子中单词的词性、短语成分和层级关系。
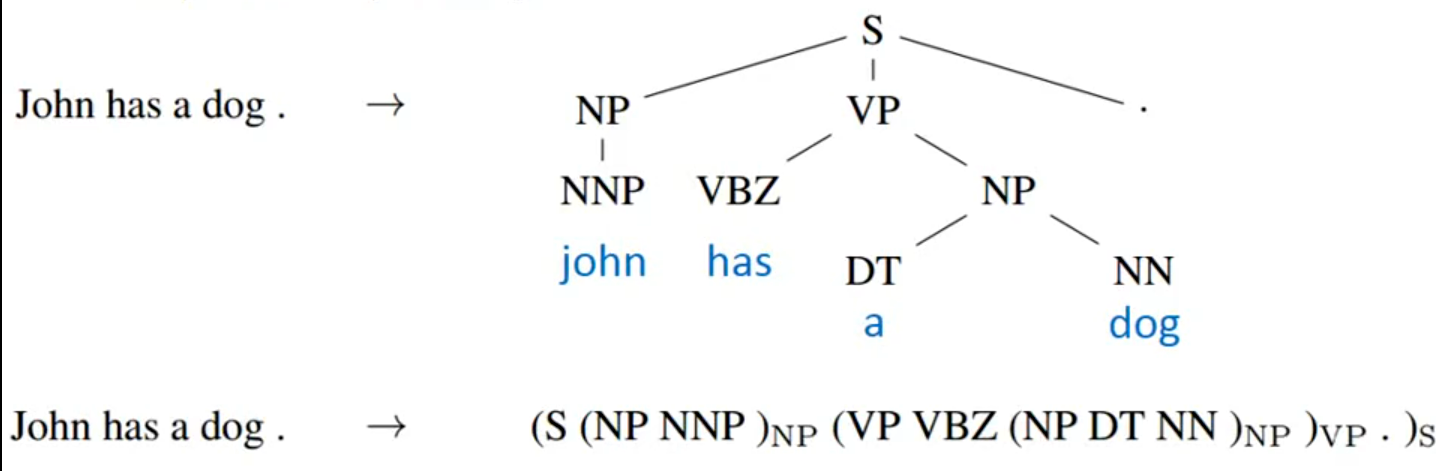
例如,输入句子“John has a dog”。下面给出了两种结构表示方式:
- 树形结构表示:用层级树展示语法结构。
根节点 s 代表整个句子;分支节点代表短语成分,NP表示名词短语,VP表示动词短语;叶子节点表示 单词+词性 标签,NNP表示专有名词(对应John),VBZ表示动词第三人称单数(对应has),DT表示限定词(对应a),NN表示普通名词(对应dog),.表示标点符号。 - 括号序列表示:为了让深度学习模型能处理,把树形结构线性化成括号序列。用括号嵌套表示层级关系,比如
(NP NNP )NP表示「名词短语包含专有名词」
Sequence-to-sequence(简称 Seq2Seq,序列到序列) 是一类输入为序列、输出也为序列的深度学习建模框架,核心是用 “编码器 - 解码器(Encoder-Decoder)” 结构,将一个任意长度的输入序列,映射为另一个任意长度的输出序列,完美适配自然语言、时序信号等非固定长度的序列数据。上述介绍的案例二与案例三均为Seq2Seq的使用示例。
Seq2Seq可以解决词序不同导致的语义不同的问题,具体如下:
- 句子一:
white blood cells destroying an infection(白细胞消灭感染)
句子一为正面语义,描述免疫系统的正常功能。- 句子二:
an infection destroying white blood cells(感染消灭白细胞)
句子二是负面语义,描述感染入侵的病理状态。上述两个句子的词袋(Bag-of-Words)完全相同,即单词集合完全一致,仅词序不同。但是词义确是相反的。对于传统的词袋模型(Bag-of-Words) 完全忽略词序,仅统计单词出现频率,因此无法区分这两个语义完全相反的句子。而 Seq2Seq(基于 RNN/LSTM 的序列建模) 可以建模词序依赖,精准捕捉句子的上下文语义,完美解决词袋模型的致命缺陷,这是 Seq2Seq 在 NLP 领域的核心价值。
基础版 Seq2Seq 自编码器(Sequence-to-sequence Auto-encoder):使用 RNN/LSTM 实现 “编码 - 解码”,目标是把输入句子压缩为语义向量,再还原出原句子,从而学习句子的语义表示。
自编码器的训练目标是最小化 “输入句子” 和 “解码输出句子” 的重构误差,让编码器学习到能精准还原原句的语义向量,从而实现句子的语义表示。
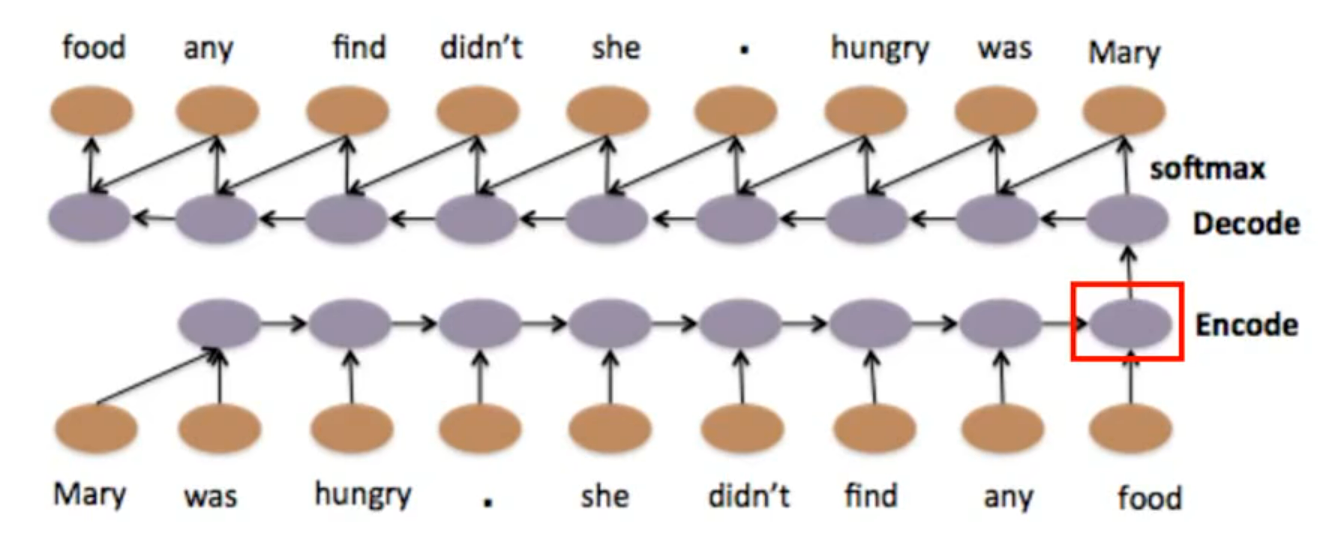
- Encoder(编码器):
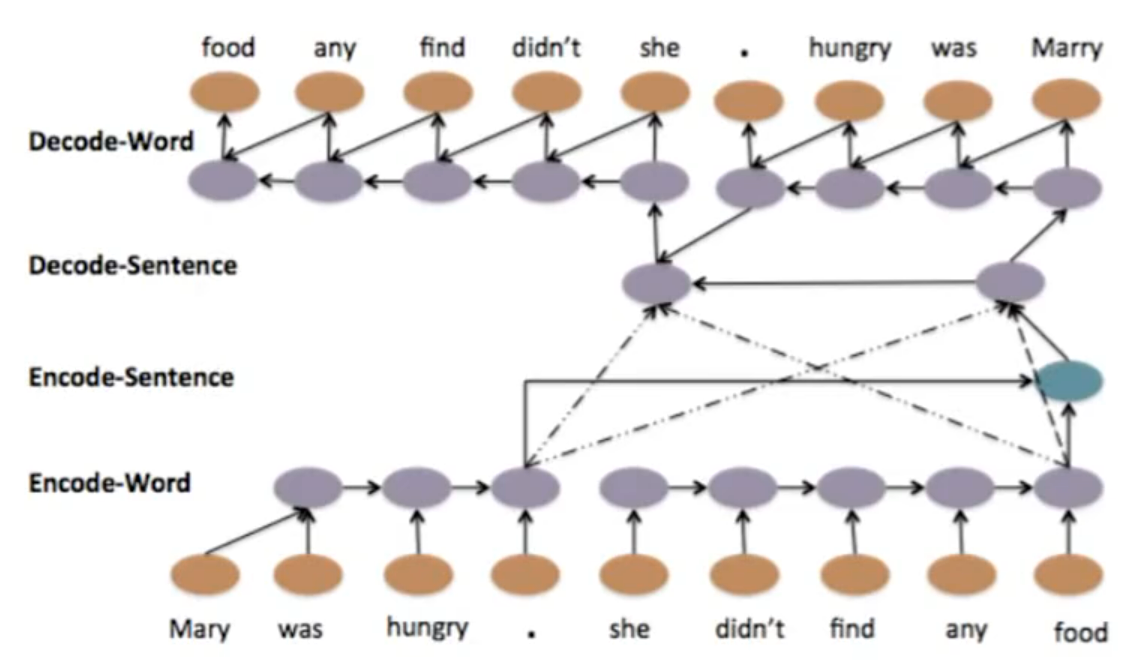
输入原句Mary was hungry . she didn’t find any food(9 个词的序列)
用 RNN 逐时间步处理输入序列,将整句的语义压缩为最后一个时间步的隐藏状态(红框标注的紫色块),这个隐藏状态就是句子的语义向量(Context Vector),承载了整句的全部语义信息。- Decoder(解码器):
以编码器的语义向量为初始隐藏状态
用 RNN 逐时间步生成输出序列,最终还原出原句food any find didn’t she . hungry was Mary(词序反转,是 RNN 解码的典型特性)softmax层,将解码器的隐藏状态映射为单词概率,逐词生成输出。层级化 Seq2Seq 自编码器(Hierarchical Seq2Seq Auto-encoder):
基础版 Seq2Seq 自编码器只能处理单句,而层级化 Seq2Seq 自编码器(来自论文《A hierarchical neural autoencoder for paragraphs and documents》)可以处理长文档 / 段落,通过 ”词 - 句 - 段“ 的双层编码,实现长文本的语义建模。
训练目标是最小化 “输入段落” 和 “解码输出段落” 的重构误差(交叉熵损失),让编码器学习到精准的层级化语义表示。
与基础版 Seq2Seq 自编码器的单层编码单层解码的结构不同,层级化 Seq2Seq 自编码器使用 “词级 - 句级” 双层编码 + “句级 - 词级” 双层解码结构。
以输入段落
Mary was hungry . she didn’t find any food. She went to the restaurant.(2 个句子,共 16 个单词)为例说明其工作过程:
- Encode-Word(词级编码):
- 输入段落中所有单词的序列(棕色块)
[Mary, was, hungry, ., she, didn’t, find, any, food, ., She, went, to, the, restaurant, .]- 按词序依次输入 词级RNN ,每一步接收当前单词的词向量 + 上一步的隐藏状态(捕捉单词的上下文依赖,完整保留词序信息)
- 逐时间步生成词级隐藏状态,每个单词对应一个隐藏向量
- 输出长度为 16 的词级隐藏状态序列
[h₁, h₂, ..., h₁₆]- Encode-Sentence(句级编码):
- 输入词级隐藏状态序列,按句子拆分:
句子 1:[h₁(Mary), h₂(was), ..., h₉(food), h₁₀(.)]
句子 2:[h₁₁(She), h₁₂(went), ..., h₁₆(.)]- 对每个句子的词级状态序列,用 句级 RNN 逐时间步处理,取每个句子最后一个时间步的隐藏状态,作为该句子的 句级语义向量
- 输出长度为 2 的句级语义向量序列
[s₁(句1), s₂(句2)],承载了整个段落的层级化语义- Decode-Sentence(句级解码):
- 输入句级语义向量序列
[s₁, s₂]- 以句向量为初始状态,用 句级2RNN 逐时间步生成句级解码隐藏状态
- 每个句级状态对应一个句子的词级状态序列,还原句子的结构信息(将句向量还原为词级状态,为最终单词生成做准备)
- 输出长度为 16 的词级解码隐藏状态序列
[d₁, d₂, ..., d₁₆]- Decode-Word(词级解码):
- 输入词级解码隐藏状态序列
[d₁, d₂, ..., d₁₆]- 对每个词级状态,用 Softmax 计算词汇表中所有单词的概率
- 取概率最大的单词作为输出,逐词生成完整段落
- 最终输出:
food any find didn’t she . hungry was Mary . restaurant the to went She .(RNN 解码的典型反转词序,可通过双向 RNN 修正)
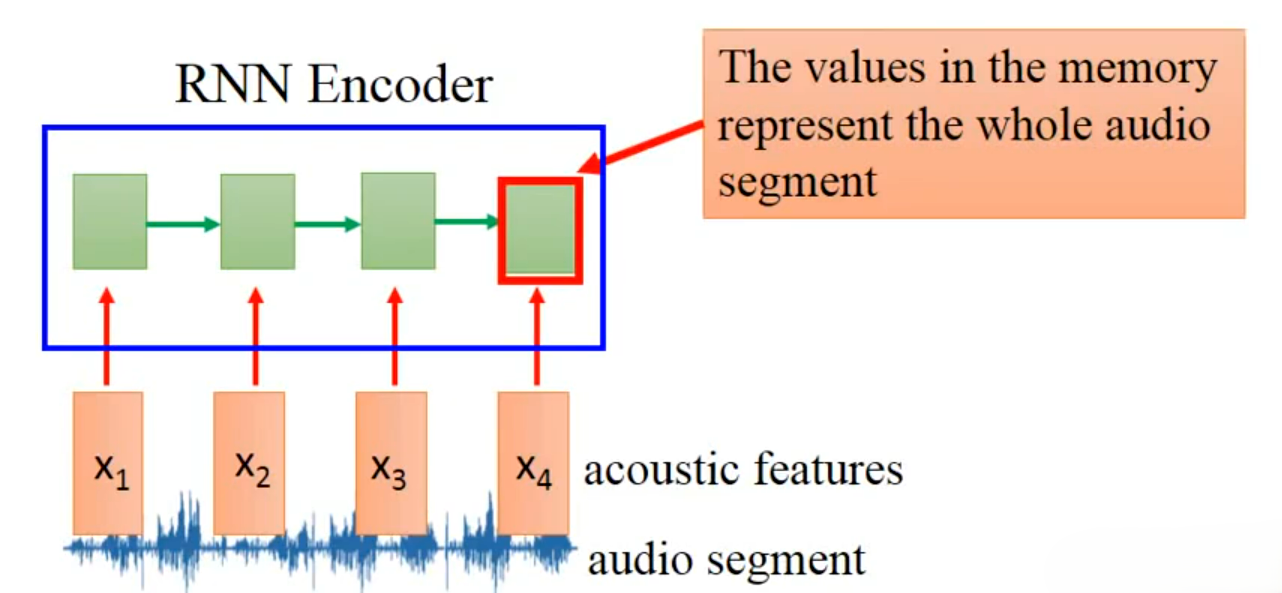
基于 Seq2Seq 自编码器的语音特征提取与检索系统:
语音数据是天然的变长序列,同一个单词(如
dog),不同人发音、不同语速,对应的语音片段长度完全不同;传统手工特征(如固定帧长截断、MFCC 统计量)无法适配变长输入,也无法有效保留语音的语义 / 发音相似性。
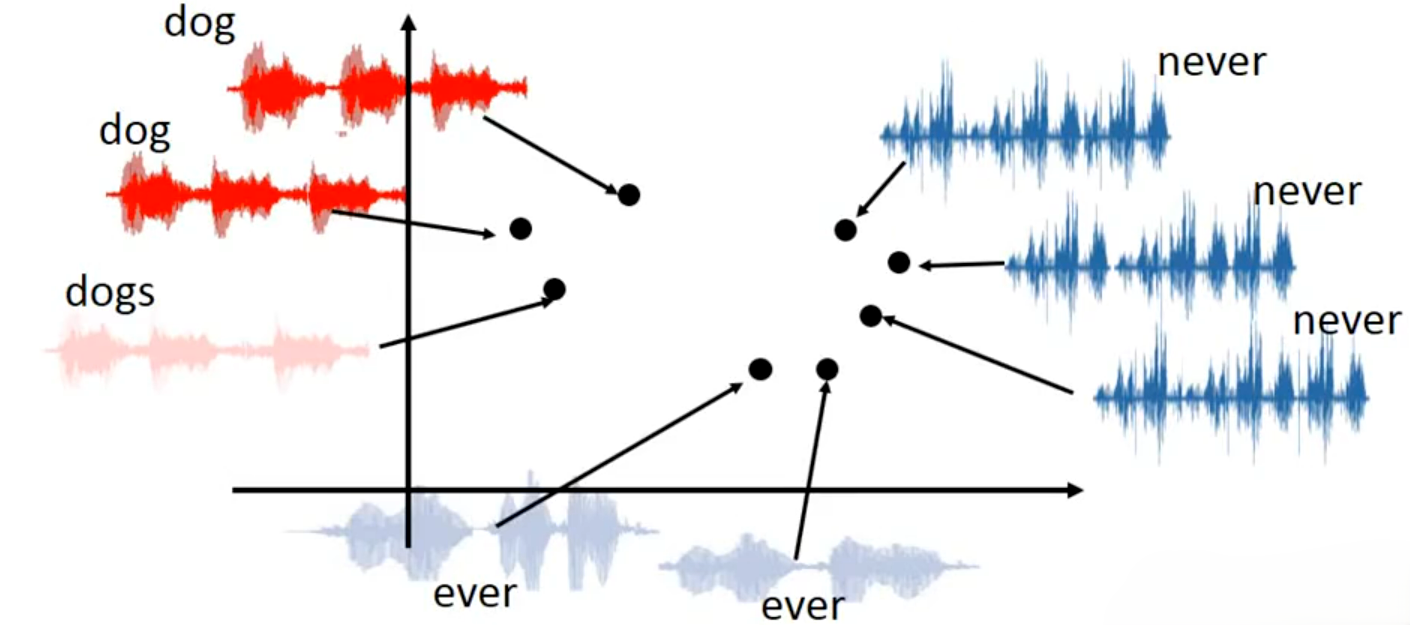
下图展示了输入多组变长语音片段(左:
dog/dog/dogs,右:never/never/never,下:ever/ever)(每个片段是不同长度的语音波形),在通过 Seq2Seq 自编码器处理后,将每个变长语音片段映射为一个固定长度的向量(图中黑色圆点,每个点是一个 D 维向量,维度 D 固定,与输入语音长度无关)。可以看到所有dog相关语音的向量聚集在左上区域,所有never相关语音的向量聚集在右上区域,ever相关语音的向量聚集在下方区域,相似语音的向量距离近,不同语音的向量距离远,完美保留了语音的相似性。
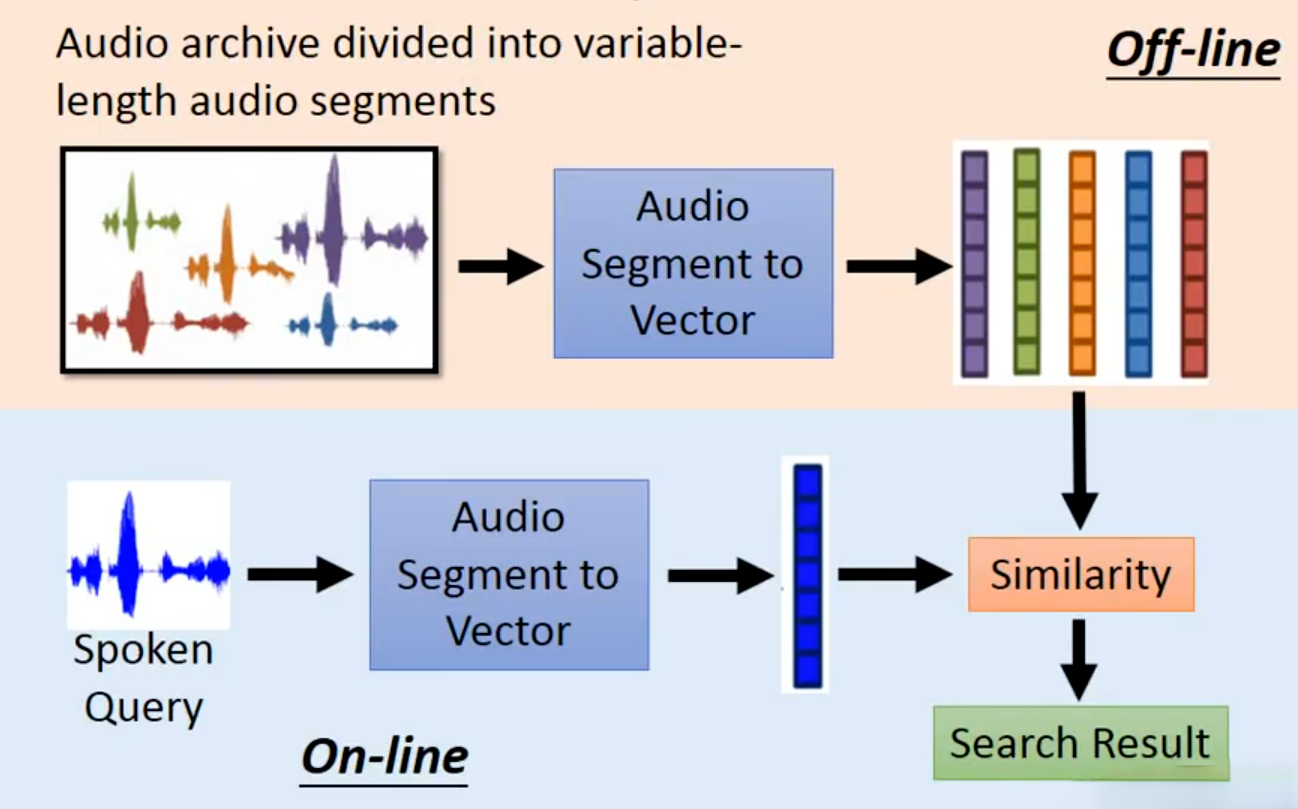
语音检索系统的完整落地架构,分为 “离线建库” 和 “在线检索” 两个阶段:
- 离线阶段(Off-line)构建语音向量库:
- 输入大规模音频档案(Audio archive),包含大量变长语音片段(如语音库中的单词、语句片段)。
- 通过
Audio Segment to Vector模块(即 Seq2Seq 自编码器的 RNN 编码器),将每个变长语音片段转换为固定长度的向量,存储为向量库(图中彩色竖条,每个竖条对应一个语音片段的向量)。(一次性处理所有存档语音,生成可快速检索的向量索引。)- 在线阶段(On-line)语音查询与检索:
- 输入用户的语音查询(Spoken Query),是一个变长语音片段(如用户说
dog,检索库中所有dog相关语音)。- 用同一个
Audio Segment to Vector模块,将查询语音转换为固定长度向量。- 将查询向量与离线向量库的所有向量计算相似度(如余弦相似度、欧氏距离)
- 输出相似度最高的语音片段,作为搜索结果(Search Result)。
编码器结构(变长语音→固定向量):
对于一个语音片段(蓝色波形),首先提取声学特征序列(如 MFCC、FBank、Log-Mel 谱),将语音波形转换为帧序列
,每个
编码器由 RNN/LSTM/GRU 单元 组成(绿色方块,循环结构),逐时间步处理声学特征序列,输入
和上一步
,依此类推,最后生成最终隐藏状态
Seq2Seq 自编码器的联合训练流程(编码器和解码器联合训练,同时优化参数):
- RNN Encoder(编码器):输入声学特征序列
,输出最终隐藏状态(固定长度向量),承载整个语音的信息。
- RNN Decoder(解码器):由 RNN 单元组成(黄色方块,循环结构),以编码器的最终隐藏状态为初始状态,逐时间步生成输出序列
。
解码器的核心目标尽可能精准地还原编码器的输入声学特征序列,即让
。
训练完成后,解码器可直接丢弃,仅保留编码器,输入任意变长语音片段,编码器的最终隐藏状态就是我们需要的固定长度语音向量,该向量可直接用于语音检索、相似度计算、语音分类、说话人识别等下游任务。
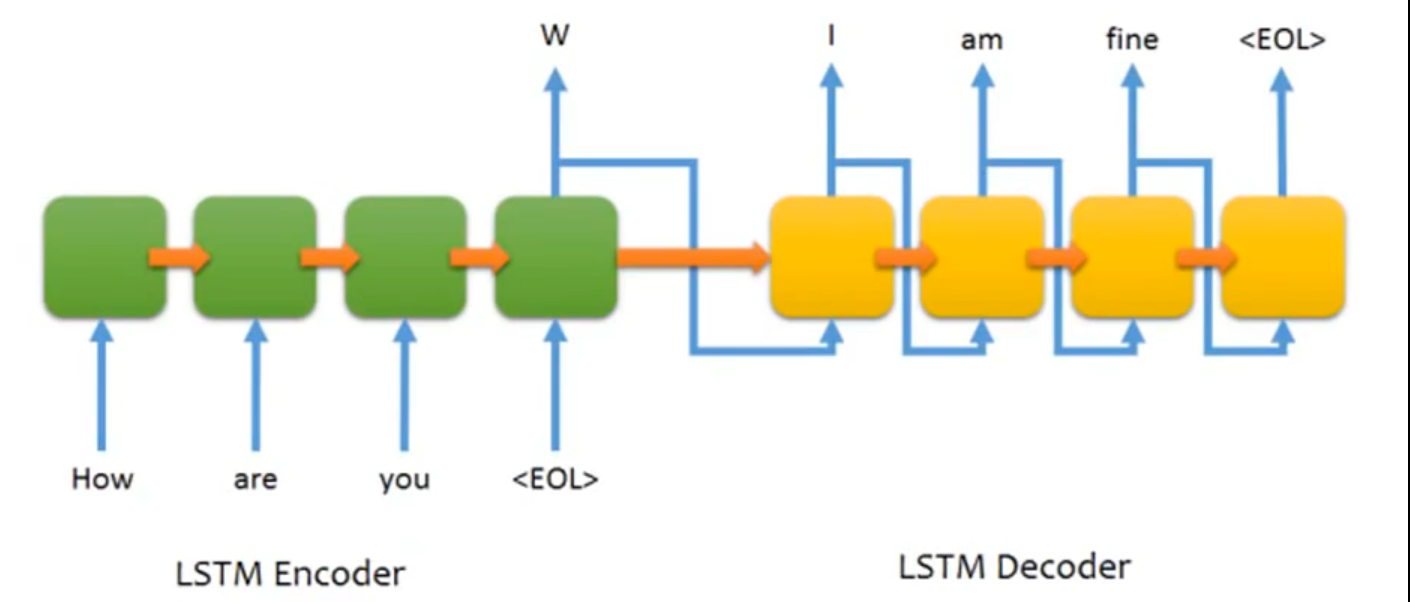
下图即为使用语音向量的一种应用场景,Seq2Seq 架构在对话系统领域的经典应用,用 LSTM 作为编码器和解码器,实现 “用户输入问句 → 机器人自动生成回复” 的端到端对话:
这类基于 LSTM 的 Seq2Seq 聊天机器人,是 Transformer 大模型(如 ChatGPT)的前身,后续的大模型用 Transformer 的注意力机制替代了 LSTM,解决了长序列的并行计算和长依赖问题,但核心的「编码器 - 解码器」Seq2Seq 架构,依然是当前大语言模型的基础结构。

Bi-RNN
普通单向 RNN(比如 Elman、Jordan)只能 从左到右(或从右到左) 处理序列,处理到第 个词
时,只能利用
的信息(过去 / 左边的上下文),完全看不到
的信息(未来 / 右边的上下文)。但在很多任务里,一个词的含义 / 标签需要同时由前后文共同决定。为了解决这个问题,于是出现了双向循环神经网络(Bi-RNN),双向循环神经网络(Bidirectional RNN, Bi-RNN)是对普通单向 RNN 的改进,核心是让模型在处理序列时,同时利用 “过去(左边)” 和 “未来(右边)” 的上下文信息。
它的设计思路是用两个独立的单向 RNN,一个正向(从左到右)处理序列,一个反向(从右到左)处理序列,然后把两个方向的隐藏状态合并,让每个位置的输出都能看到完整的上下文(过去 + 未来):
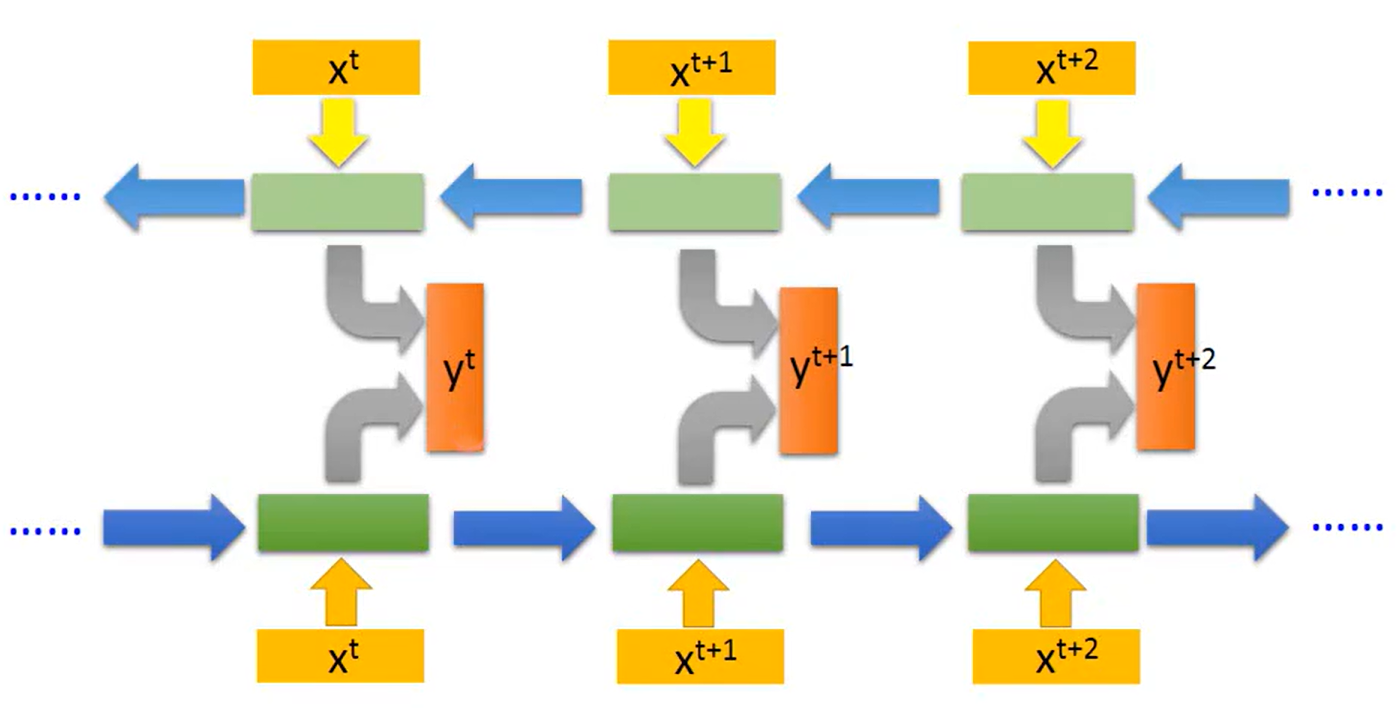
正向RNN:
![]()
反向RNN:
![]()
状态合并:
![]()
最终输出:
![]()
虽然双向Bi-RNN可以完整感知上下文,但这同时意味着计算量翻倍(需要训练两个独立的 RNN,参数量和计算量约为单向 RNN 的 2 倍),并且必须拿到完整序列才能计算反向 RNN 的状态,不适合实时 / 在线任务(比如实时语音识别,需要边接收边输出)。
LSTM
LSTM(Long Short-Term Memory,长短期记忆网络) 是一种特殊的循环神经网络(RNN),专门为解决普通 RNN 无法处理长期依赖的问题而设计。
普通 RNN 在处理长序列时会出现梯度消失 / 爆炸,导致模型记不住太久远的信息;而 LSTM 通过门控机制精细控制信息的流动,能有效保留重要的长期记忆,同时丢弃无用的短期噪声。
普通 RNN 只有一个隐藏状态,所有信息都混在一起,梯度在反向传播时会快速衰减,无法记住太久远的信息。LSTM 的核心创新是:
- 引入独立的 “记忆细胞(Memory Cell)” :记忆库,负责长期保存信息。只有门控能修改它,避免信息被随意覆盖。
- 设计三个 “门控(Gate)”:
- 遗忘门(Forget Gate):决定要丢弃哪些旧记忆
- 输入门(Input Gate):决定要加入哪些新信息
- 输出门(Output Gate):决定要输出哪些记忆到当前隐藏状态
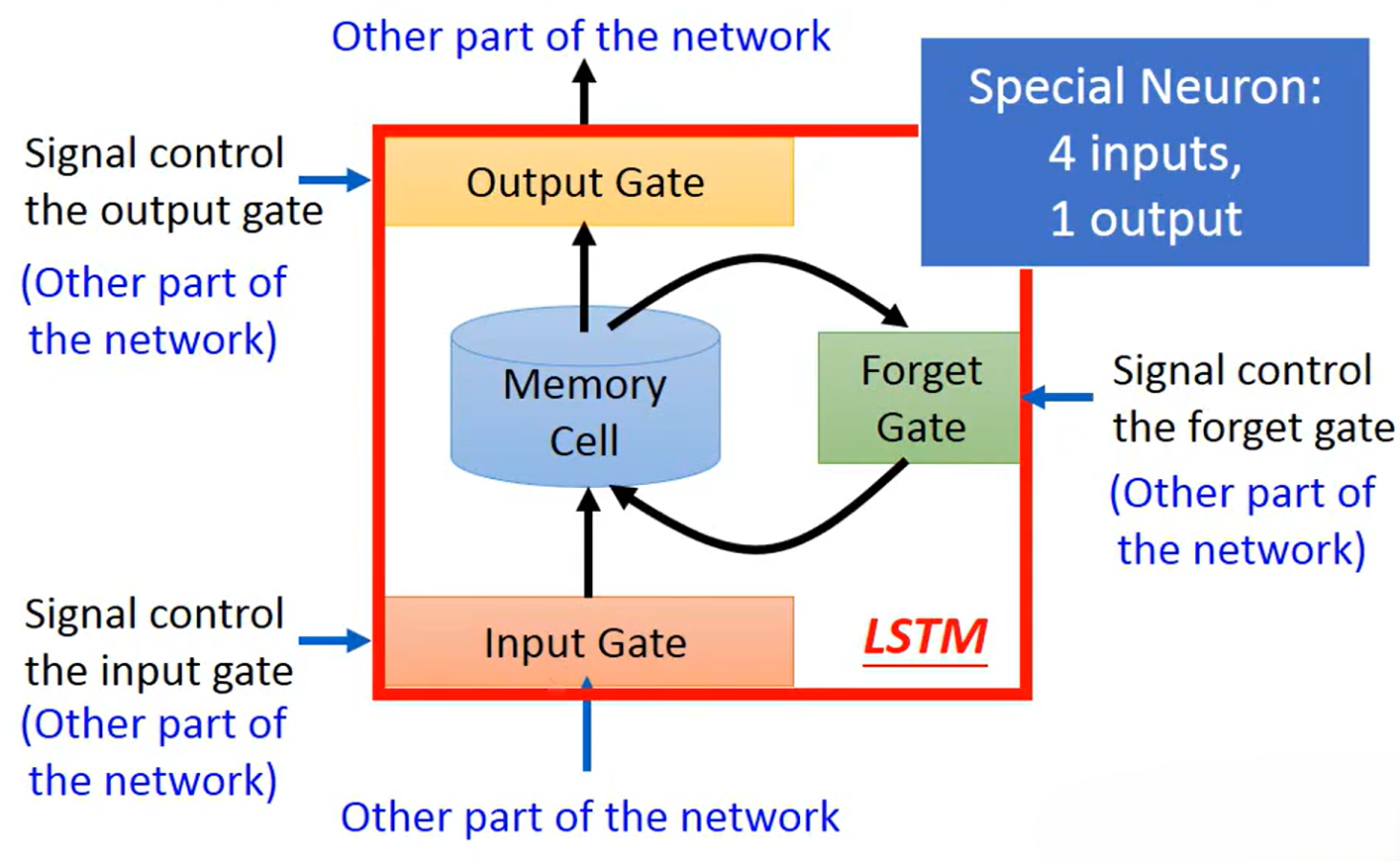
通过这三个门,LSTM 实现了 "选择性记忆" ,只保留对任务有用的长期信息,过滤掉无关的短期干扰,从根本上解决了 RNN 的长期依赖问题。
LSTM计算流程
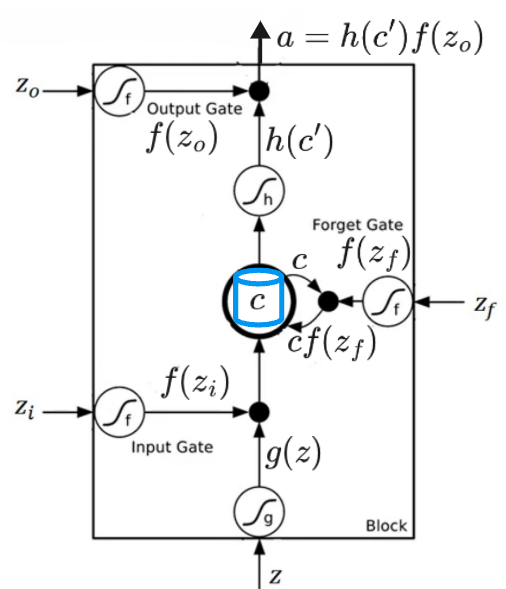
为候选状态输入,用于生成存储细胞状态
为输入门输入,控制输入门的开关,决定新信息的流入量;
为遗忘门输入,控制遗忘门的开关,决定旧细胞状态的保留量;
为输出门输入,控制输出门的开关,决定当前隐藏状态的输出量。
是 LSTM 单元的线性变换输入,由当前时刻输入
所有参数均通过反向传播学习得到。
- LSTM 的核心是细胞状态 c(图中蓝色圆柱),它像一条 “信息传送带”,在序列中传递长期信息;三个门控(遗忘门、输入门、输出门)负责控制信息的流入、保留与流出,各门均采用Sigmoid作为激活函数,取值在
,表示门的开关程度。
- 输入门与候选细胞状态:输入
(通常为 tanh函数,输出范围
。输入门输入
(Sigmoid函数),输出
,代表 “新信息的流入比例”。
- 遗忘门:输入
,代表 “保留比例”。将将上一时刻的细胞状态
逐元素相乘(图中
),决定保留多少历史信息。若
表示完全保留该维度的历史信息;若
表示完全遗忘该维度的历史信息。
- 细胞状态更新:将遗忘后的旧状态与输入门过滤后的新候选状态相加,得到当前时刻的细胞状态
,计算式为:
- 输出门:输入
,代表 “细胞状态的输出比例”
- 隐藏状态(输出)计算:先对更新后的新细胞状态
),再与输出门
逐元素相乘,得到当前时刻的隐藏状态
)。
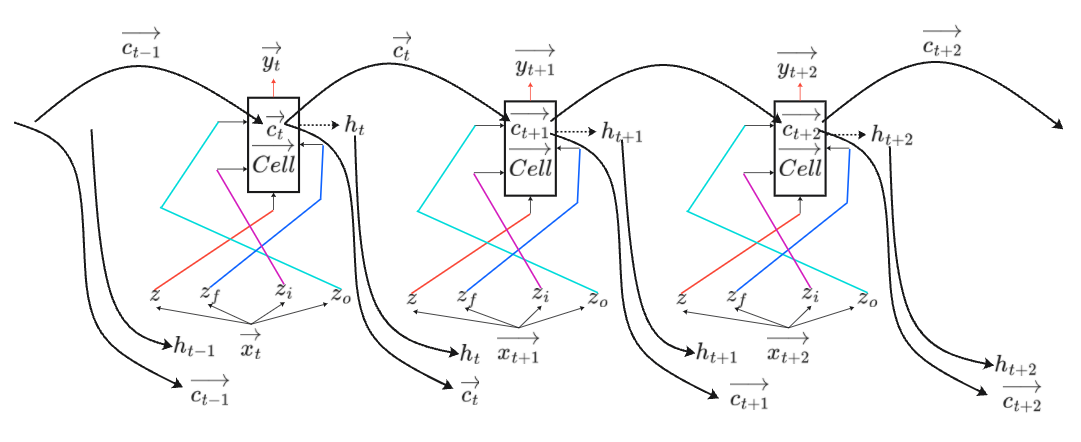
为了方便表示,将LSTM的图像简化如下:
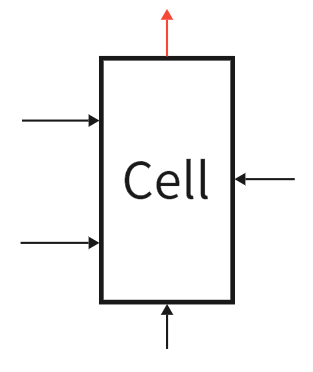
LSTM网络结构:LSTM实际上是将每个传统神经元替换为一个完整的 LSTM Block。假设输入只有三个特征,即,将
经过线性变换后得到向量
,这几个向量的特征均为3,将其分别输入到单层神经网络模型中,最终得到输出
。
LSTM Block就是一个神经元,与传统的神经元相比它的输入有4个,也就是说LSTM的参数量是普通RNN的四倍。
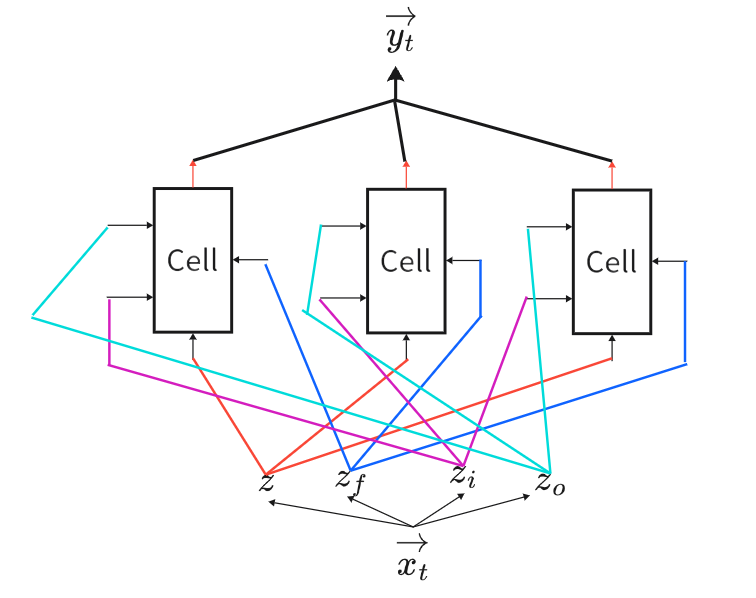
为了方便表示,将上图网络结构改成下图所示。将上述并联处理三维向量的三个LSTM Block用一个来LSTM Block来表示,其内部细胞状态值为。
LSTM处理序列:每个时间步 对应一个 LSTM Block,共享同一组参数
。共传递两种状态给下一个时间步:
- 细胞状态
,沿时间轴传递长期记忆,解决长序列依赖。
- 隐藏状态
,沿时间轴传递短期上下文,作为下一时间步的输入。
多层LSTM:多层 LSTM 的每一层都是一个独立的标准 LSTM 单元。
第 层输入 = 第
层在同一时间步
的隐藏状态输出
+ 第 k 层上一时间步
的隐藏状态
。并且每一层都需要独立计算4 组线性变换(遗忘门、输入门、候选状态、输出门),拥有独立的权重矩阵和偏置,层间参数不共享。(下图以两层LSTM为例)
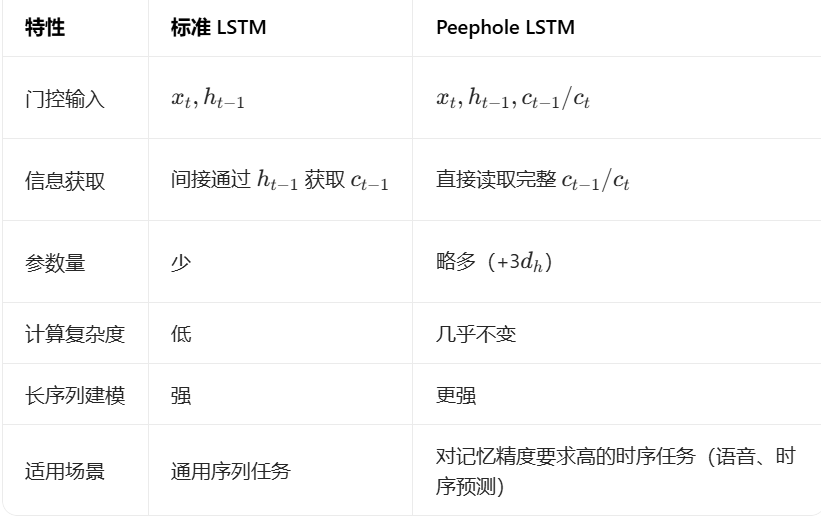
LSTM Peephole Connection(窥视孔连接):
Peephole(窥视孔连接)是标准 LSTM 的一种经典扩展结构,核心改进是 让三个门控(遗忘门、输入门、输出门)可以直接 “窥视” 上一时刻的细胞状态
(以及当前时刻的细胞状态
),而不再仅依赖输入
标准LSTM连接的门控公式:
Peephole LSTM(带窥视孔)的门控公式在每个门控中,新增了细胞状态的线性投影项,让门控直接感知细胞状态:
在图像上就是第
时间步的门控,同理接入
对于超长序列,细胞状态
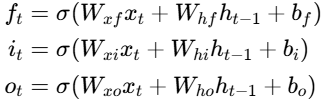
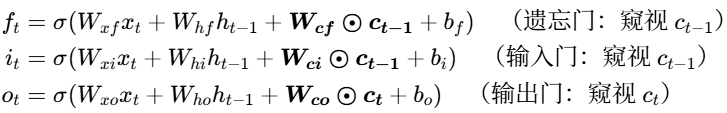
LSTM 主要解决的是 RNN 的「梯度消失问题」,同时能显著缓解梯度爆炸,但无法从根本上消除梯度爆炸。
传统 RNN 的隐藏状态更新为
,每出现一次
而LSTM 的细胞状态更新为加法形式(
表示逐元素相乘),与
决定:
其中后三项中的
是门控 / 候选状态对
的间接耦合,根据公式得
,其大小由
决定,当
很大时,
,
,因此
,即后三项趋近于0,
;当
中(即
大),因此在长序列的梯度传递中,后三项的影响远小于第一项。
因此上式可近似为:
对于长度为
传递到
,但 LSTM 会通过学习让长依赖相关的信息对应的
(即 “记住” 长序列中的关键信息),当
,不会随时间步指数衰减。
工程上仍需配合梯度裁剪(Gradient Clipping) 彻底解决梯度爆炸问题。

GRU
GRU(Gated Recurrent Unit,门控循环单元)是 LSTM 的轻量化简化变体,同为改良版 RNN,解决 RNN BPTT 梯度消失、无法建模长距离时序依赖问题;相比 LSTM参数更少、计算更快、训练更省资源,效果多数场景和 LSTM 持平。
LSTM 有 3 个门(遗忘门、输入门、输出门)+ 独立细胞态 ,结构冗余、参数量大、前向反向计算开销高、小数据集易过拟合。GRU的思路是把LSTM 遗忘门 和 输入门 合并为一个,称为更新门 (Update gate),并废除独立细胞态
,只用单一隐藏态
承载长期记忆。其具体结构区别如下:
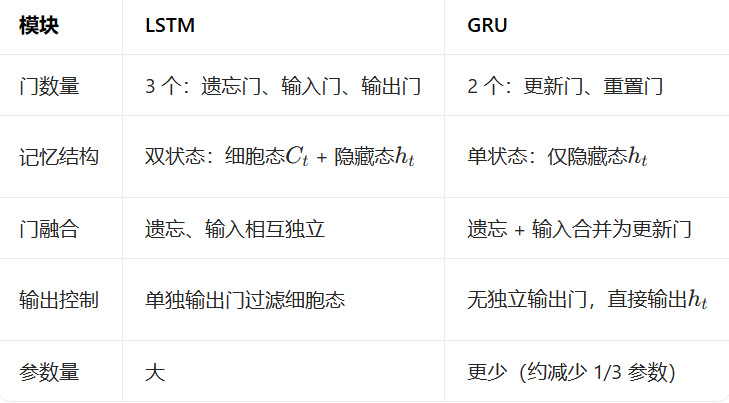
其工作过程如下( 表示当前时刻输入,
表示上一时刻隐藏状态):
- 重置门(Reset gate,
):控制对上一刻旧记忆的遗忘程度,捕捉短期依赖
,清空过往隐藏信息,重开短期记忆
,完整保留过往隐藏信息
- 候选隐藏状态
:用重置门筛选后的旧记忆,生成当前新候选记忆
- 更新门(Update gate,
- 当前时刻最终隐藏态
,其中
表示保留大部分历史长期记忆,
表示掺入当前新的候选信息
模型可自主学到:关键长依赖位置

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 13
13 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)