前端转 Agent 全栈,还是后端转 Agent 全栈?一份面向企业级项目的能力路线图
前端转 Agent 全栈,还是后端转 Agent 全栈?一份面向企业级项目的能力路线图
目标读者:准备向 AI Agent 全栈方向转型的开发人员(前端或后端背景)。
核心价值:厘清企业级 Agent 开发的真实难点,提供避免“内卷”的错位竞争策略及 6 个月可行路径。
阅读时间:6 分钟
一句话摘要:Agent 框架的普及掩盖了企业落地的深水区,后端转全栈更容易切入工程核心,而前端转全栈则应在产品化与人机协同中建立绝对壁垒。
当大模型能力逐渐成为基础设施,应用层的终局形态正不可避免地指向了智能体(Agent)。在这个技术浪潮中,我们频繁听到一个职业规划问题:前端程序员与后端程序员,谁更容易转型成为优秀的 Agent 全栈工程师?
我们设定的前提是,双方此前都没有实际的 Agent 项目开发经验。
直觉上,随着 LangGraph.js、OpenAI SDK (Node.js) 的成熟,TypeScript 生态似乎让前端开发者迎来了“弯道超车”的最佳时机。毕竟,用熟悉的语言写出能够调用工具的智能体,门槛已经大幅降低。然而,在真正的企业级交付现场,故事的走向往往与 Demo 阶段截然不同。
本文将从企业级 Agent 的真实工程挑战出发,深度剖析前端与后端两条转型路径的优劣势,并提供一份切实可行的 6 个月能力路线图。
为什么“会用 Agent 框架”不等于“能做企业级项目”
在深入对比路线之前,我们必须先破除一个关于 Agent 框架的普遍迷信。
LangGraph、Google ADK 等成熟框架,确实极大降低了编排多智能体工作流的复杂度。它们提供了开箱即用的状态图定义、记忆管理接口以及工具调用封装。然而,在企业级架构中,框架仅仅是编排内核,并不等同于完整的企业解决方案。
我们可以将企业级 Agent 系统分为三层架构:

“企业级项目”与“玩具 Demo”的分水岭,往往不在中间的框架层,而在底层的“基础设施接入”与上层的“业务产品化落地”。
当业务部门要求一个能够自动审核财务报销并对接内部 OA 系统的 Agent 时,难点已经不再是“如何让 LLM 理解系统提示词”,而是:
- 当 OA 系统接口超时,Agent 如何实现带状态的安全重试而不导致重复打款?(幂等与状态一致性)
- 业务数据的访问如何与企业现有的 RBAC 权限体系无缝结合?(权限与合规)
- 每一次大模型的推理 token 消耗,如何精确追踪到具体的成本中心?(成本审计与可观测性)
只要深入这些深水区,你就会发现,TypeScript 版本的框架并没有消灭后端工程的复杂性,它只是把这些挑战推迟到了部署上线的那一刻。
为什么后端转 Agent 全栈通常是更短路径
如果单纯从短期市场竞争力来看,后端程序员转 Agent 全栈通常是一条更短的路径。
得出这个结论的原因,在于 Agent 发展的第一阶段,其核心矛盾高度集中于经典的后端/平台工程问题。
首先是状态与调度的复杂性。 复杂的 Agent 工作流可能要运行几分钟甚至几个小时。在这个过程中,涉及人类在环(Human-in-the-loop)的打断、恢复,以及多步骤状态的持久化。这要求开发者具备深厚的并发处理、任务队列调度和数据库事务管理经验。这正是 Java、Go 等后端开发者的主场。
其次是存量系统的整合能力。 企业不可能为了 AI 重写所有系统。Agent 必须通过 API 去调用沉淀了数十年的 ERP、CRM 系统。后端开发者对企业微服务架构、网关、RPC 通信以及接口鉴权协议轻车熟路,他们能够迅速成为连接“新大脑(LLM)”与“旧躯体(遗留系统)”的关键桥梁。
最后是成本与安全治理。 在企业语境下,模型的不可控性必须被工程的确定性关进笼子里。速率限制(Rate Limiting)、熔断机制、详尽的请求监控(Tracing),这些都是现代后端微服务架构的标配,而前端开发者往往对此缺乏系统性的实践。
因此,当一个后端开发者掌握了 Python 或 Node.js 的 Agent 编排框架后,他立刻就能将过去的工程底蕴复用到 Agent 的高可用设计中,直接切入企业的核心工程位。
前端转 Agent 全栈的优势应该如何建立
但这是否意味着前端转 Agent 全栈毫无竞争力?并非如此。前提是,前端开发者绝不能去走“与后端拼传统架构深度”的内卷路线。
如果前端去恶补 JVM 调优、分布式锁和复杂的微服务中间件,那是用自己的短板去拼别人的长板。前端转 Agent 全栈的真正护城河,在于极致的“产品化落地位”。
Agent 的落地需要被看见。一个能力再强的智能体,如果没有优秀的交互界面,在业务人员眼中也是黑盒。前端开发者应将重心放在以下三个维度的能力构建上:
- 复杂交互与过程可视化: 大模型的推理过程缓慢且充满不确定性。前端需要设计流式响应(Streaming)、思维链可视化(Chain of Thought UI)、状态指示器,让用户能够实时理解 Agent 正在做什么,并在必要时进行人为干预。
- 高可用工作台构建: 将孤立的对话框升级为企业级工作台(Workspace)。融合知识库检索展示、复杂表单联动、卡片式工具结果呈现,构建“Copilot”级别的人机协同体验。
- 多端触达能力: 利用前端的多端优势,将 Agent 能力无缝嵌入 PC Web、移动 H5、企业微信/钉钉小程序等各类业务骨干入口。
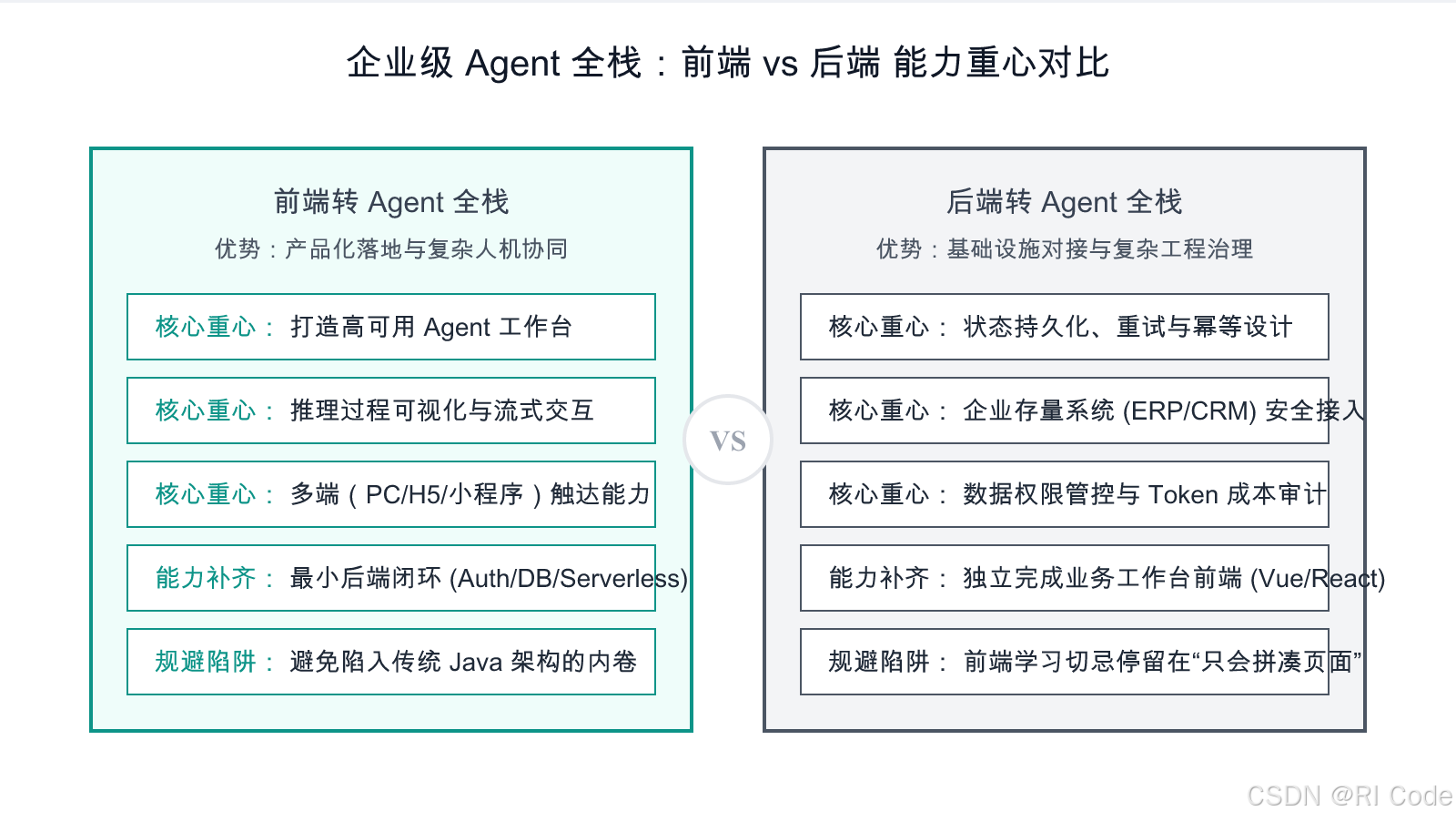
与此同时,前端真正需要补齐的不是大而全的微服务架构,而是**“最小后端闭环能力”**。掌握 Serverless 部署、基础的数据库 CRUD 与身份验证(Auth)。在这个闭环内,前端开发者能够独立完成一个端到端的 Agent 产品,这对于创新型业务和中小型企业而言,具备极高的单兵作战价值。然后可以根据业务体量需要,再去补齐 Java 相关的企业级技术栈。
两条路线的 6 个月能力路径与作品集建议
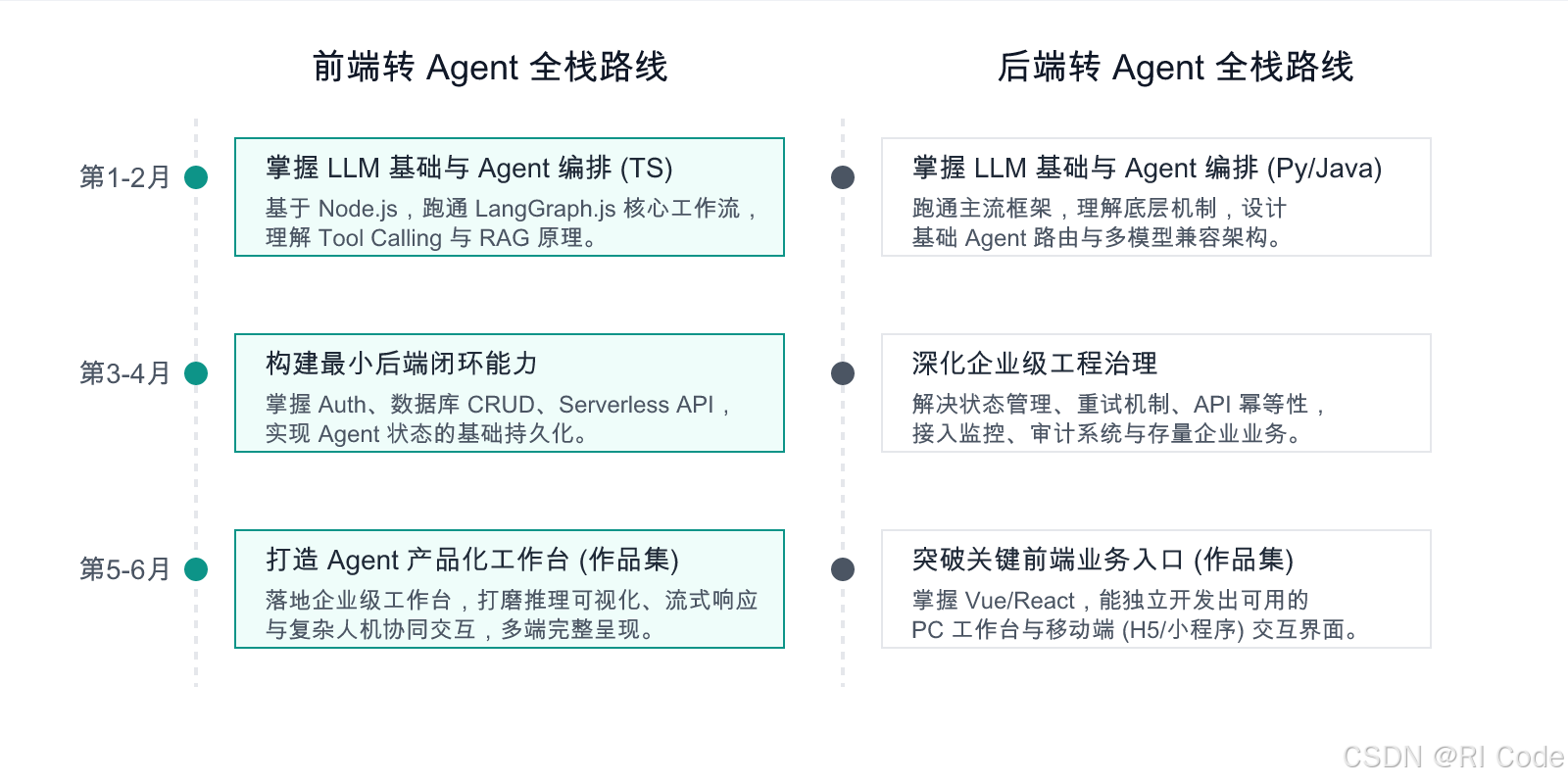
为了让理论落地,我们为两个方向规划了 6 个月的核心能力构建路径,重点强调能力的先后顺序与最终的“作品集(Portfolio)”策略。
前端转 Agent 全栈:从交互出发,打通全链路闭环
- 第 1-2 个月:打牢 LLM 基础与编排内核。无需切换语言,基于 Node.js/TypeScript,熟练掌握 LangGraph.js 核心工作流。深刻理解 RAG(检索增强生成)原理与 Tool Calling(工具调用)机制。
- 第 3-4 个月:构建最小后端闭环。学习使用轻量级数据库和 Auth 服务,掌握如何将会话状态(Memory)持久化。学会通过 Serverless 平台部署后端 API。
- 第 5-6 个月:打磨产品化作品集。这是拉开差距的关键。 不要只做一个简单的聊天页面。开发一个完整的“知识库辅助客服工作台”或“智能审批台”,包含复杂的流式打字效果、引用来源高亮、人机协同审核节点,并确保它在多端体验一致。
后端转 Agent 全栈:从工程出发,突破前端业务入口
- 第 1-2 个月:掌握主流 Agent 框架与多模型架构。基于 Python 或 Java,跑通主流 Agent 框架。设计支持多模型动态路由的底层接口,掌握提示词工程与基础编排逻辑。
- 第 3-4 个月:工程化补齐与治理。这是主场作战。解决 Agent 运行中的状态一致性问题,设计可靠的重试机制。对接企业监控系统,实现详细的 Token 消耗审计与存量系统安全接入。
- 第 5-6 个月:突破关键前端业务入口(作品集)。不要把前端补成“只会写页面”。 系统学习 Vue 或 React,能够独立开发具备多状态交互的 PC 工作台,并掌握 H5 或小程序的关键入口开发。最终作品需展示你不仅能写出高并发的 Agent 后端,还能独立完成用户可用的前端界面交付。
结语:错位竞争,殊途同归
Agent 全栈时代的到来,对开发者的知识广度提出了前所未有的要求。但无论是前端还是后端,底层的根基始终是相通的:大模型基础理论、Agent 编排范式、工具调用、RAG 架构、系统评测与可观测性及业务接入。
如果你是后端出身,短期市场竞争力更强,请务必利用好在并发、状态与企业系统接入上的先发优势,迅速占领 Agent 底座开发的制高点;但也不要忽视打磨 PC/H5/小程序上的核心业务闭环,让业务最终落地。
如果你是前端出身,不要被后端庞大的架构体系吓倒,更不要盲目陷入传统 Java 后端的内卷。请牢记:最好的技术如果不被用户优雅地使用,就毫无价值。 把你在人机交互、多端适配、状态可视化上的深刻理解,转化为体验极致的 Agent 业务工作台,并通过补齐最小后端闭环,你同样能在这个全新的 AI 时代建立起极具长期价值的差异化竞争壁垒。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)