《上下文引擎 + Runner 本地操作:基于 openJiuwen 的多轮代码调试智能体》
用 AI 帮忙调试代码不是新鲜事了,但体验上总觉得少了点什么。每次提问都是独立的,聊了半天助手也不记得前面说过什么;分析完问题后,还得自己复制代码去跑,不能直接验证修复方案。
最近在玩 openJiuwen Agent Core 框架,发现它新上了两个挺有意思的东西:一个是上下文引擎,专门管多轮对话的上下文状态;另一个是Runner 本地系统操作,能直接读写文件、执行代码。用这两个新特性做了个多轮代码调试助手,体验确实比之前单轮对话的那种好不少。
项目地址:https://atomgit.com/openJiuwen/agent-core?utm_source=csdn
做这个项目的初衷
说实话,之前用过几个代码调试工具,用着用着就觉得哪里不对劲。
最让人难受的是每次都要把上下文重新说一遍。比如你在调试一个函数,第一轮问了问题,第二轮想让助手给出修复代码,结果它完全不记得你之前说啥了,又得把问题描述一遍。这就很累。
其次是分析完问题后,没法直接验证。助手告诉你"这里应该加个判断",但你得自己改代码、自己跑测试,不能说"你帮我改一下然后跑跑看"。
还有就是上下文窗口容易被撑爆。聊得越久,积累的上下文越多,很快就会触及模型的上下文长度限制,导致对话无法继续。
这些问题 openJiuwen 的两个新特性刚好能解决。上下文引擎让多轮对话能共享状态,Runner 本地操作让助手能直接读写文件、跑代码。我就想,不如做个小项目试试这俩东西到底有多好用。
技术选型:两个新特性怎么配合
上下文引擎解决什么问题
上下文引擎的核心能力是上下文压缩卸载与推理算力协同加速。
在多轮对话场景中,上下文内容会不断累积,很快就会触及模型的上下文长度限制。上下文引擎通过压缩卸载机制,将不活跃的历史上下文移出窗口,避免撑爆上下文限制。
关键点在于:当上下文被压缩卸载后,推理引擎中的 Prefix Cache(前缀缓存)就会与实际上下文产生差异。openJiuwen 上下文引擎引入了 KVCacheManager,会自动与上一轮上下文窗口完整快照进行差异检测,定位首个发生变化的消息索引,然后向推理引擎发送释放指令,精准释放无效 Cache,从而保持两者的一致性。
简单理解:
注意:上下文引擎与推理算力协同加速的前提是有压缩卸载。如果没有压缩卸载,(在上下文窗口打满前)Prefix Cache 一直都是能对应上的,不需要额外协同。
这个机制在长对话、代码调试等需要反复迭代的场景中特别有用。
Runner 本地操作解决什么问题
Runner 本来是 openJiuwen 的执行器,现在新增了对本地系统的操作能力。以前工具只能返回一些分析结果,现在能直接操作文件系统、执行代码了。
这些操作都是直接在本地进行的,不需要额外起服务。
整体架构
把两个新特性拼在一起,架构如下:
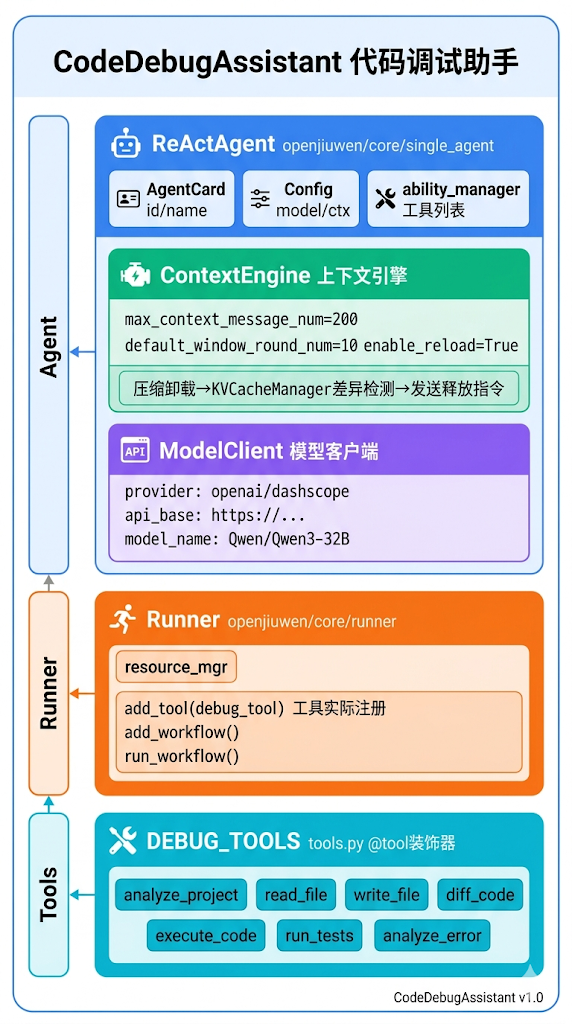
ReActAgent 负责推理什么时候该用什么工具,上下文引擎确保多轮对话的状态能正确传递,Runner 负责具体执行本地操作。
工具调用的链路
当 ReActAgent 决定调用某个工具时,内部调用链路如下:
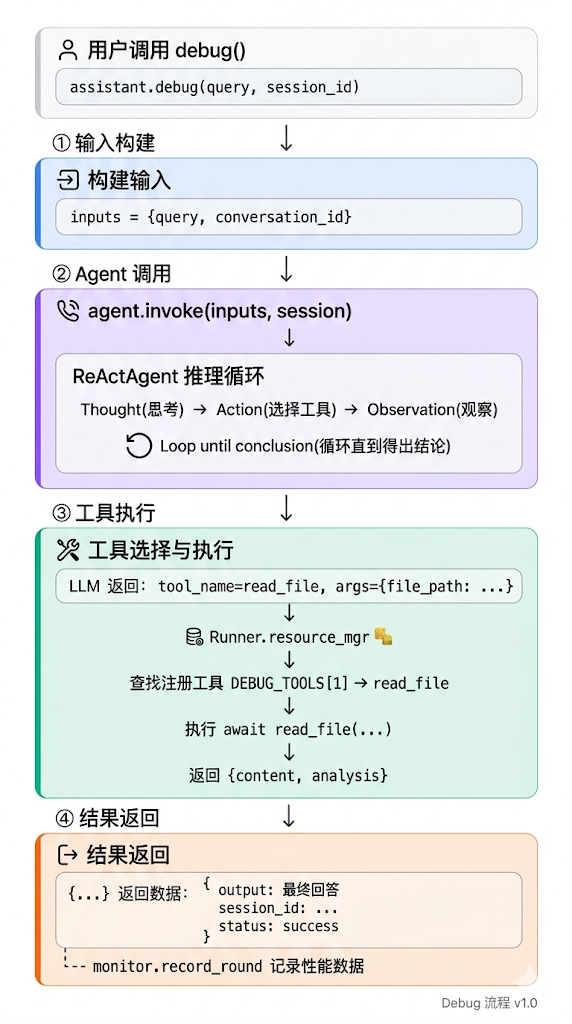
关键代码路径
整个过程是异步的,工具执行不会阻塞主流程。多个工具如果彼此独立,甚至可以并发调用。
上下文状态管理
上下文引擎在多轮对话中是这样工作的:
关键流程说明:
1持续压缩卸载:压缩卸载不是等到窗口上限才触发,而是过程中持续进行的。每一轮对话后,上下文引擎都会检查是否需要压缩,保持窗口内的上下文数量稳定。
2压缩卸载机制:
○根据 default_window_round_num 设置的窗口大小,保持最近 N 轮对话
○超出窗口的早期内容会被压缩卸载(摘要或移出)
○这是一个滚动窗口机制,新内容进入,旧内容被压缩
3KVCacheManager 差异检测与精准释放:每次上下文窗口生成时,KVCacheManager 会自动保存当前消息列表与工具定义的完整快照。下一次窗口生成时,逐条对比新旧快照,精确定位首个发生变化的消息索引,然后向推理引擎发送释放指令,仅释放该位置之后的无效缓存,变化位置之前的有效前缀缓存完整保留、持续复用。
4按需重载:当需要引用被压缩的历史内容时,enable_reload=True 会自动重新加载。
窗口大小可以通过 default_window_round_num 参数控制,我设的是 10 轮,意味着始终保持最近 10 轮对话在窗口内,更早的内容会被持续压缩卸载。
环境准备
项目需要 Python 3.11+,openJiuwen 要用最新版本(需要包含 context_engine 模块)。
安装步骤:
这几个参数的含义和建议值:
|
参数 |
含义 |
推荐值 |
说明 |
|
max_context_message_num |
最大消息数量 |
200 |
硬上限,超过会触发压缩 |
|
default_window_round_num |
保留对话轮数 |
10 |
保留最近N轮完整对话 |
|
enable_reload |
按需重载 |
True |
需要历史内容时自动加载 |
|
enable_kv_cache_release |
KV Cache 主动协同 |
True |
开启后,压缩卸载时主动释放推理引擎无效 Cache |
我调了一会儿,default_window_round_num 设成 10 效果不错,既能保留足够上下文,又不会占用太多内存。
核心模块实现
上下文引擎配置
创建 Agent 的时候需要配置上下文引擎:
enable_reload=True 这个参数有点意思。当上下文被压缩卸载后,如果模型需要引用之前的内容,会自动重新加载。就像你有个笔记本,把写满的页面收起来后,还能随时翻回去看。
推理亲和模型配置
要实现 KV Cache 主动协同,除了开启 enable_kv_cache_release=True,还需要使用 InferenceAffinityModel 封装推理引擎客户端:
这样,当上下文被压缩卸载时,KVCacheManager 会通过 affinity_model 自动向推理引擎发送释放指令,实现精准的 Cache 释放。
多轮会话管理
同一个 Session 对象可以跨越多轮对话:
这里关键是 conversation_id,上下文引擎通过这个 ID 关联多轮对话,实现差异检测和协同加速。
调试工具实现
项目里一共定义了 7 个调试工具,覆盖了从分析到验证的完整流程:
|
工具名称 |
功能 |
使用场景 |
|
analyze_project |
扫描项目目录结构 |
了解项目组织 |
|
read_file |
读取文件内容 |
查看代码 |
|
write_file |
写入文件内容 |
保存修复后的代码 |
|
diff_code |
对比代码差异 |
查看修改前后的变化 |
|
execute_code |
执行 Python 代码 |
验证修复方案 |
|
run_tests |
运行项目测试 |
确保没有引入新问题 |
|
analyze_error |
分析错误信息 |
快速定位问题类型 |
用 @tool 装饰器定义工具,ReActAgent 会自动调用:
代码执行工具也很直接:
工具注册到 Agent:
性能监控
为了看看上下文引擎到底有没有用,加了个简单的性能监控:
效果展示
项目放在 examples/code_debug_assistant/ 下。本文中展示的全部4个演示效果,运行完整演示即可看到:
如果想只看基本调试演示,可以运行简化模式:
如果想自己体验多轮对话,可以进入交互模式:
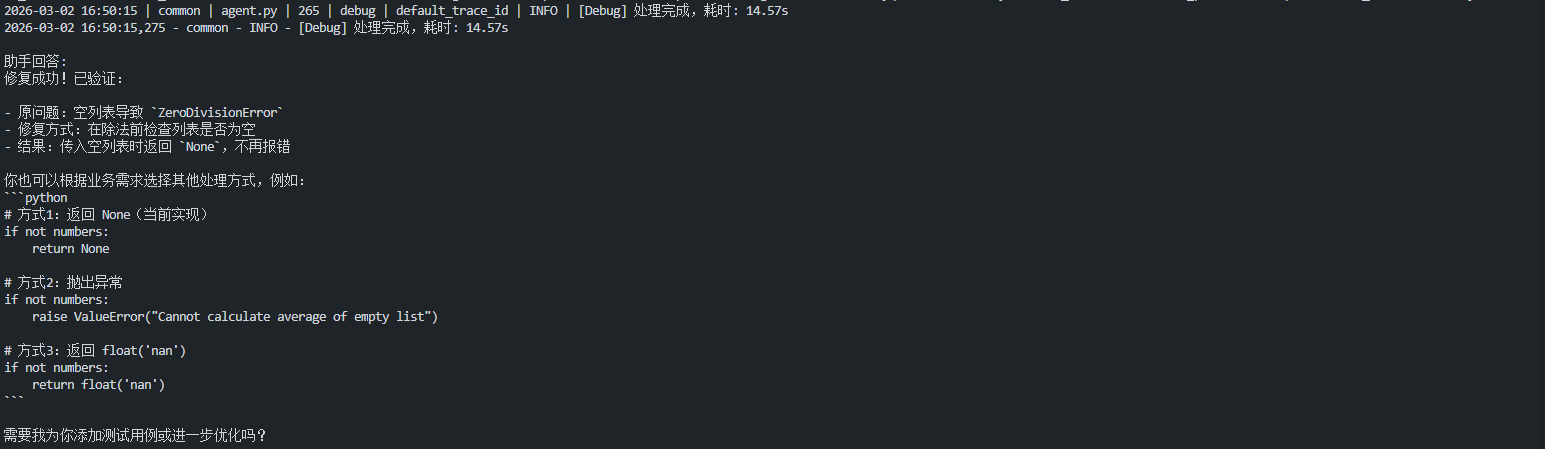
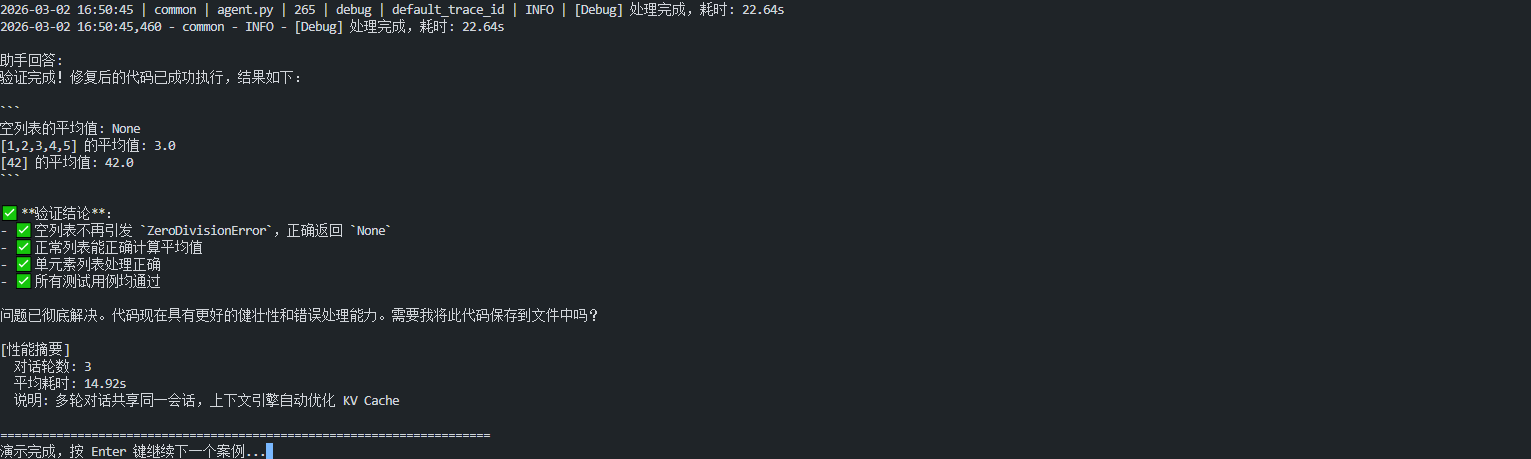
演示1:基本代码调试
这个演示展示最典型的三步调试流程:分析问题 → 修复代码 → 验证结果。
1
2
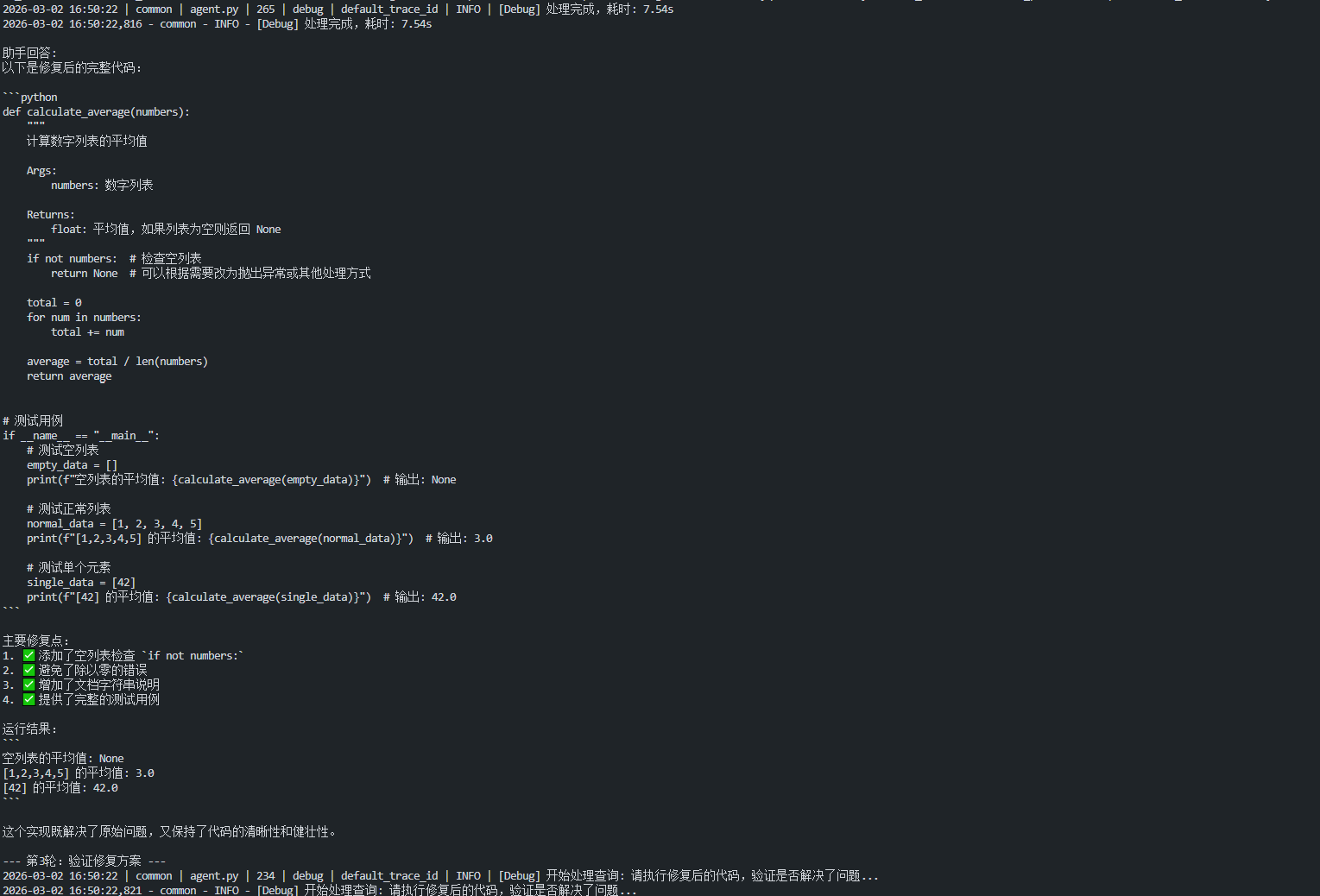
3
演示2:项目结构分析
除了调试具体代码,也能分析整个项目的目录结构:
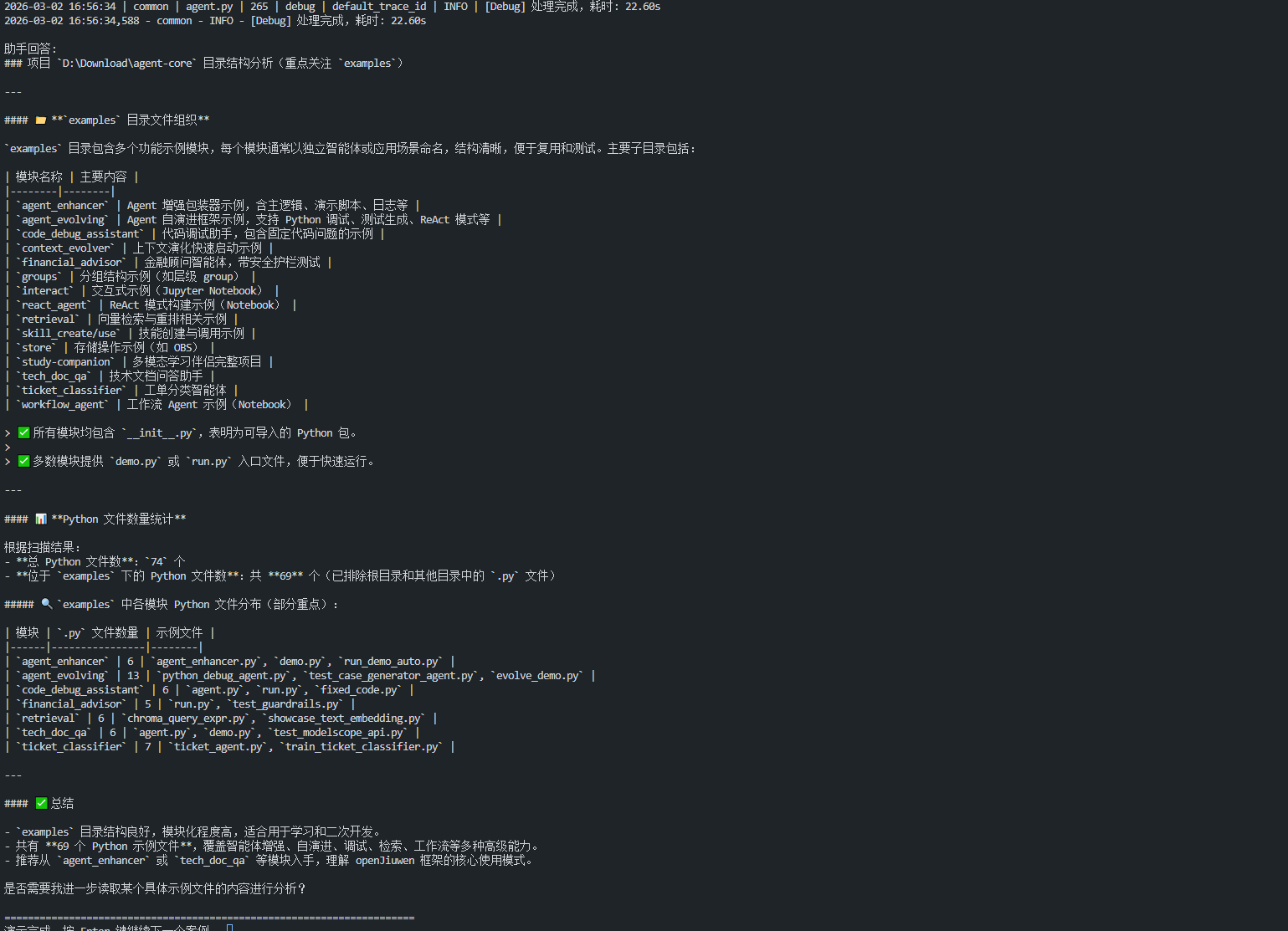
这个演示主要展示 analyze_project 工具的使用,项目分析后会返回文件列表和目录结构。
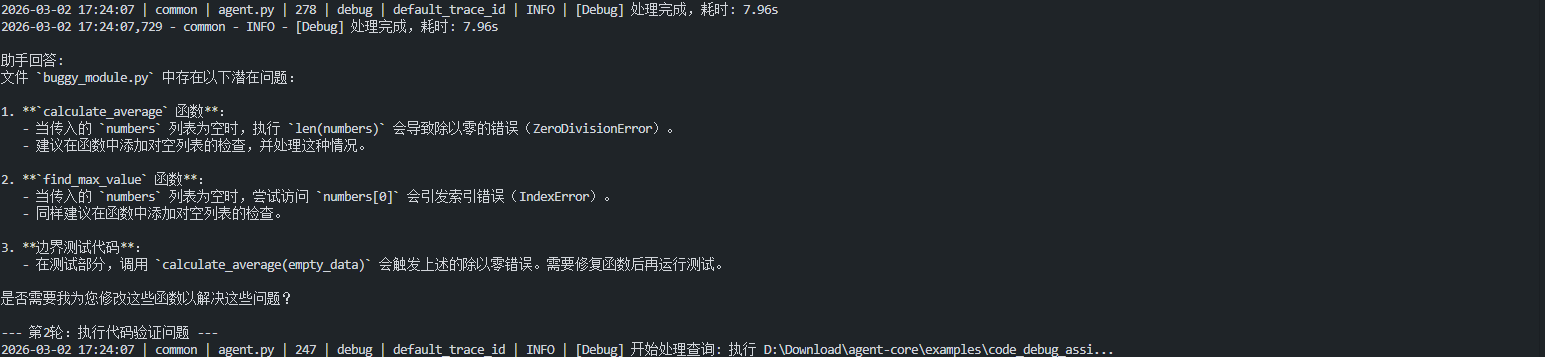
演示3:多文件协同调试
这个演示展示如何处理一个包含多个错误的测试文件:
1

2
3

4

5
这个演示展示了 read_file、execute_code、write_file 等工具的协同使用。
演示4:上下文引擎优化效果
第四个演示通过 10 轮连续对话,展示上下文引擎如何避免撑爆上下文窗口:
1

2

3

4

5

6

7

8

9

10

10 个问题围绕同一个主题(ZeroDivisionError)展开。对话轮次越多,上下文累积越多,当达到窗口上限时,上下文引擎会触发压缩卸载,KVCacheManager 会进行差异检测并向推理引擎发送释放指令,精准释放无效 Cache,确保对话可以持续进行而不会撑爆上下文窗口。
新特性是怎么做到的
上下文引擎的优化机制
openJiuwen 构建了上下文与 Prefix Cache 主动协同机制,主要包括两个核心部分:
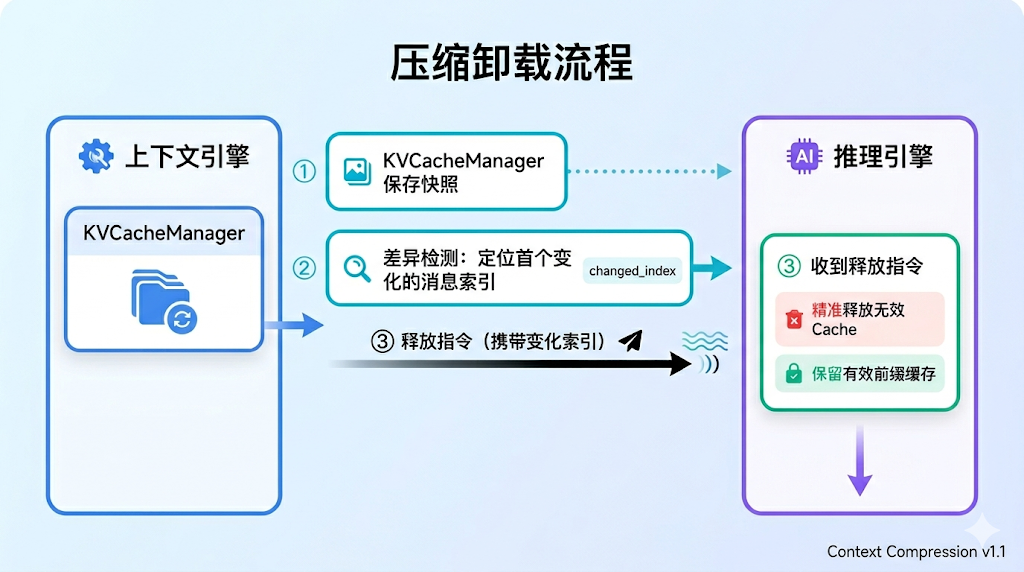
1. Agent 侧:KVCacheManager 差异检测与精准释放
上下文引擎引入了 KVCacheManager,把"上下文变化"与"显存释放"串起来,形成主动协同闭环。整个机制分为三个阶段:
阶段一:快照保存。 每次上下文窗口生成后,KVCacheManager 自动保存当前消息列表与工具定义的完整快照,作为下一次对比的基准线。
阶段二:差异检测。 当下一次窗口生成时,KVCacheManager 逐条对比新旧快照,精确定位首个发生变化的消息索引。这里的"变化"涵盖了压缩改写、卸载移除、摘要替换等所有上下文操作。
阶段三:精确释放。 一旦检测到差异,KVCacheManager 向推理引擎发送释放指令,携带变化索引位置。仅释放该位置之后的无效缓存,变化位置之前的有效前缀缓存完整保留、持续复用。
一句话总结:只释放"确实不可能再命中"的那一段。
2. 推理引擎侧:上下文感知的 Prefix Cache 双区缓存调度
为配合上层释放指令的落地,openJiuwen 在推理引擎的现有基础上,增加主动缓存管理服务:在 Prefix Cache 空闲队列中引入一个老化指针(aging),将队列划分为两个区域:
●老化区(head → aging):存放被上下文引擎标记为无效的缓存块,优先被驱逐
●新鲜区(aging → tail):存放正常结束请求归还的缓存块,按传统 LRU 顺序排列
调度规则:
●正常归还:请求结束时,其缓存块默认追加到队列尾部(新鲜区末端),aging 指针不动
●主动释放:上下文压缩或卸载触发缓存释放时,被释放的缓存块插入 aging 指针位置(即老化区末端)
●缓存命中移除:命中的缓存块从队列中移除。若命中的是 aging 所指向的块,aging 前移至其前驱节点,老化区相应收缩
这样,被上下文引擎判定为无效的缓存块会被优先驱逐以释放显存,而仍然有效的缓存块则获得更长的生存周期,从而提升整体命中率。
3. 按需重载
当需要引用被压缩的历史内容时,enable_reload=True 会自动重新加载到窗口中。
重要说明:
●协同的前提是压缩卸载:只有上下文被压缩卸载后,才需要与推理引擎协同
●KVCacheManager 主动发送释放指令:不是简单的"通知",而是发送带有变化索引的释放指令
●双区调度配合释放指令:推理引擎侧通过老化指针机制,将无效缓存移入优先释放区
●业界对比:大多数框架在压缩卸载后就不管了,不告知推理引擎,导致 Prefix Cache 与实际上下文不一致;openJiuwen 通过主动协同机制解决了这个问题
Runner 本地操作的实现
Runner 本地操作是通过 SysOperation 模块实现的,它封装了文件系统、代码执行、命令行等操作:
这些操作在 ReActAgent 的工具调用流程里是这样走的:
1
2
3
4
5
6
7
8
9
ReActAgent 推理
↓ 判断需要读取文件
调用 @tool 装饰的 read_file
↓
Runner 执行
↓
SysOperation 实际读取
↓
返回结果给 Agent
整个过程是异步的,不会阻塞主流程。
总结
做完这个小项目,对 openJiuwen 的这两个新特性有了更深的理解。
当前推理引擎将 Prefix Cache 管理作为内部实现,上层 Agent 无法触及。上下文引擎明明知道哪些缓存已经失效,却无权告知推理引擎。为打破这层束缚,openJiuwen 构建了上下文与 Prefix Cache 主动协同机制:
1. Agent 上下文差异检测与精准释放
在 Agent 侧,openJiuwen 上下文引擎引入 KVCacheManager,在上下文动态变动时,自动与上一轮上下文窗口完整快照进行差异检测,定位首个发生变化的消息索引,然后向推理引擎发送释放指令,精准释放无效 Cache。仅释放该位置之后的无效缓存,变化位置之前的有效前缀缓存完整保留、持续复用。
2. 上下文感知的 Prefix Cache 双区缓存调度
在推理引擎侧,在原有 LRU 基础上引入上下文感知的双区缓存调度。通过老化指针(aging)将缓存队列划分为老化区和新鲜区,推理引擎接收 Agent 的释放指令后,将无效缓存块主动移入老化区优先驱逐,加速腾退显存空间。
3. 使用方式
要启用 KV Cache 主动协同,需要:
●在上下文引擎配置中开启 enable_kv_cache_release=True
●使用 InferenceAffinityModel 封装推理引擎客户端
●在调用 get_context_window() 时传入 affinity_model
这两个机制的配合,让多轮对话既能持续进行,又能保持推理效率。
Runner 本地操作
Runner 本地操作让 Agent 不再只能"说话",而是能真正"做事"。读写文件、执行代码、跑测试,这些能力让调试助手从"分析工具"变成了"执行工具"。
体验对比
和之前单轮对话的调试助手相比,体验上的变化主要体现在:
|
之前 |
现在 |
|
|
对话方式 |
每次独立 |
连续多轮 |
|
上下文处理 |
累积到打满窗口 |
压缩卸载 + KVCacheManager 差异检测 + 发送释放指令 + 双区调度 |
|
上下文限制 |
容易撑爆 |
智能管理,支持更长对话 |
|
文件操作 |
复制粘贴 |
直接读写 |
|
代码验证 |
手动执行 |
自动执行 |
参考资源
●openJiuwen 官网:https://www.openjiuwen.com?utm_source=csdn
●框架源码:https://atomgit.com/openJiuwen/agent-core?utm_source=csdn
若有收获,就点个赞吧

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 18
18 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)