深入浅出TurboQuant:AI 的“压缩魔法“
刷屏的Google Research论文,能把存储股票干趴窝,还不赶紧上车一起学习下? 发车了,go go go!


https://openreview.net/pdf/6593f484501e295cdbe7efcbc46d7f20fc7e741f.pdf
Google Research · ICLR 2026 | 作者:Amir Zandieh、Vahab Mirrokni 等 | 发布:2026年3月24日
一、先从一个比喻开始
想象你正在看一场音乐会的现场直播。视频是 4K 的,每一帧都是海量数据。如果你把每一帧的每一个像素都原样存下来,一小时的视频可能要几百 GB。
但你现在用的手机,存一部完整电影只需要几个 GB——靠的就是压缩算法:找到数据里的规律,扔掉冗余,只保留真正有用的信息。
TurboQuant 干的事情,跟这个一模一样,只不过它压缩的不是视频,而是大语言模型(LLM)运行时最耗内存的那个东西——KV 缓存。
二、KV 缓存是什么?为什么它是大麻烦?
2.1 模型"记忆"的代价
当你跟 ChatGPT 或 Gemini 聊天时,模型每回复一个字,都需要"回头看"之前所有的对话内容。为了避免每次都从头重新计算,模型会把历史信息存成一张"小抄",放在高速显存里随时查阅——这就是KV 缓存(Key-Value Cache)。
问题在于:上下文越长,这张小抄越大。
内存估算公式:
KV缓存大小 ≈ 2 × 层数(L) × 向量维度(d) × 序列长度 × 每个数值的字节数(FP16 = 2字节)
举例:
• 7B 参数模型 + 128K token 上下文 → KV缓存高达数十 GB
• KV缓存可占推理总显存的 80% 以上
这意味着:想让模型处理更长的文章、更复杂的任务,就得买更多、更贵的 GPU 内存。这是整个 AI 行业的核心成本痛点之一。
2.2 已有的压缩方案和它们的缺陷
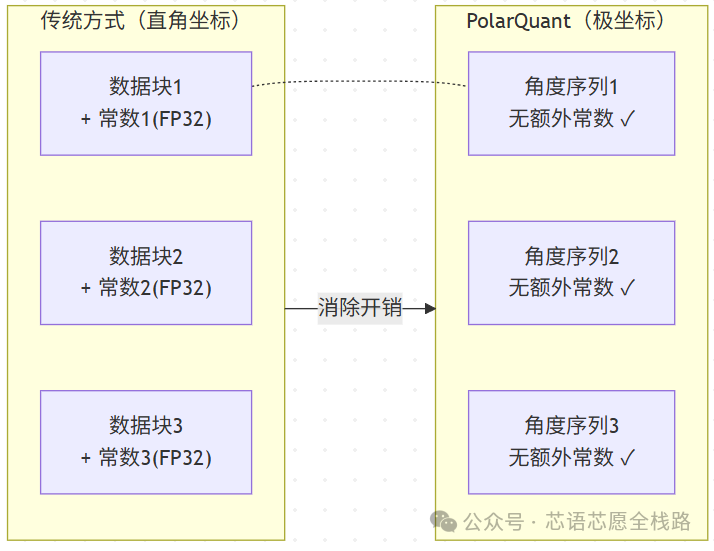
之前也有人想到了用向量量化(把精确的浮点数变成更粗糙的整数)来压缩 KV 缓存。但传统方案有一个隐藏的"坑":
每压缩一小块数据,你就必须额外存一组"解压钥匙"(量化常数)——这些钥匙本身又占 1~2 个比特的空间。
这就像把一箱书压缩装箱,但装箱说明书本身比书还厚——部分抵消了压缩的意义。
TurboQuant 的核心创新,就是彻底消灭这把"解压钥匙"。
三、TurboQuant 是怎么工作的?
TurboQuant 由两个子算法组合而成:PolarQuant(主压缩)和QJL(误差修正)。
3.1 整体流程图
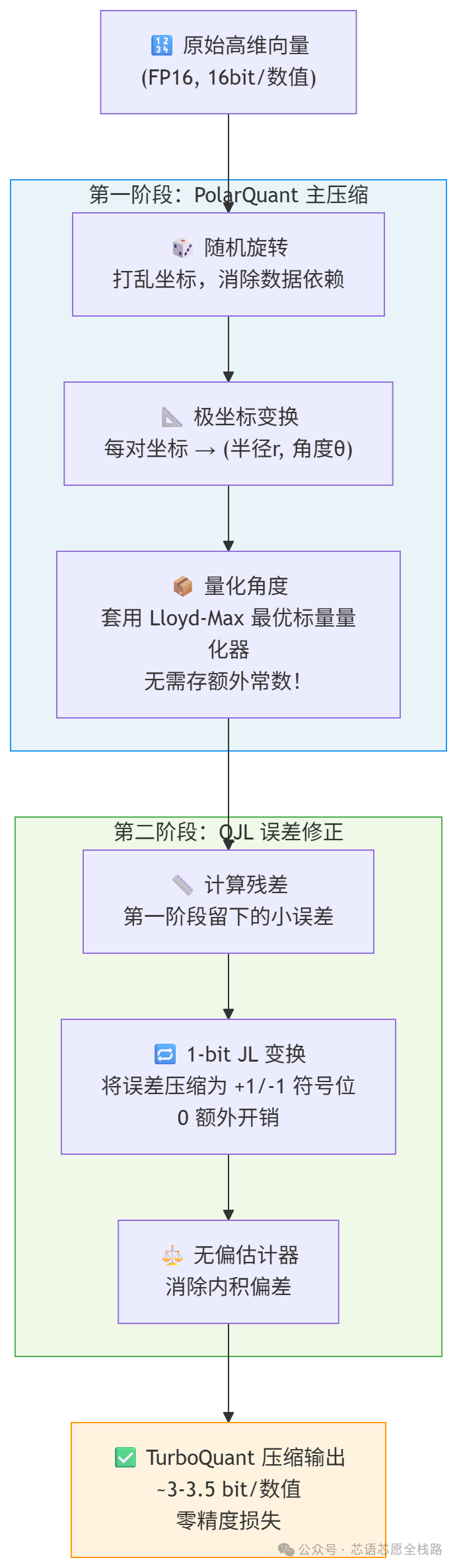
3.2 第一阶段:PolarQuant——换一种"语言"来描述空间
普通的向量用直角坐标表示,就像"往东走3步,往北走4步"。
PolarQuant 做了一件聪明的事——把坐标系从"方格"换成"圆形":
先对向量做一次随机旋转(类似把地图随机转动一个角度)
旋转后,每对坐标变成一个半径(信号有多强)+ 一个角度(信号指向哪里)
为什么这样有用?
随机旋转之后,角度的分布会变得非常规律、集中——就像把一堆随机散落的点,变成了均匀分布在圆上的点。因为形状已知,就不需要为每个数据块存一组描述"它长什么样"的常数,量化开销降为零。
3.3 第二阶段:QJL——1 个比特的"纠错码"
PolarQuant 压缩后还有一点点残余误差。QJL 用一个极其巧妙的方法处理它:把残差通过 Johnson-Lindenstrauss 变换,压缩成一个符号位(+1 或 -1)。
-
只用1 个比特.
-
零额外内存开销.
-
通过特殊的估计器,让最终的注意力分数计算保持无偏(不系统性地偏高或偏低).
两个阶段合起来,TurboQuant 就做到了:用极少的比特,存住向量最重要的几何关系。
四、理论上有多"极限"?
TurboQuant 不只是一个工程 trick——它有严格的数学证明:
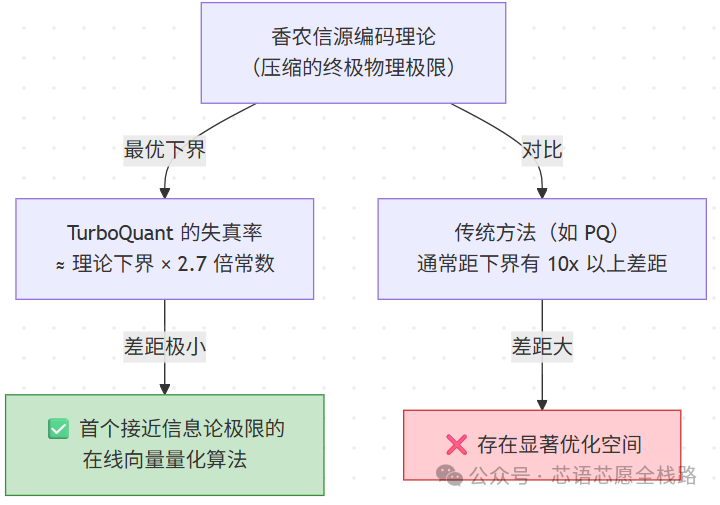
这意味着:TurboQuant 已经接近了数学上"不可能再好"的边界,而不是仅仅比之前的方案好一点点。
五、实验效果:数字说话
5.1 KV 缓存压缩基准(多个长上下文任务)

测试模型:Llama-3.1-8B-Instruct、Gemma、Mistral-7B
5.2 计算速度提升(H100 GPU)
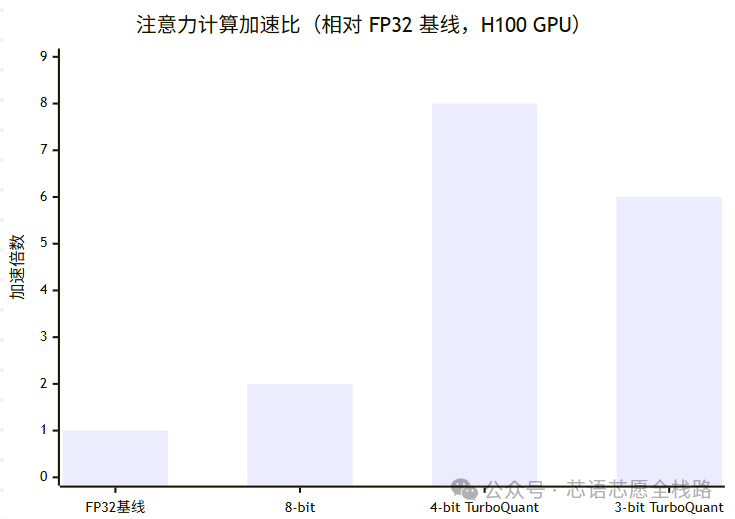
5.3 与竞争方案对比
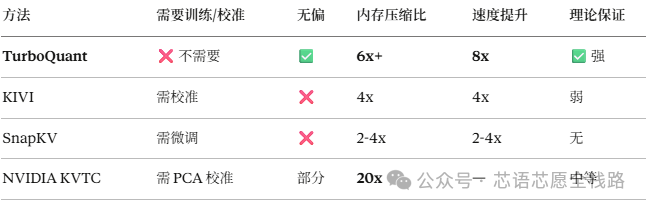
⚠️ 注:NVIDIA KVTC 压缩比更高(20x),但需要逐模型校准,且精度有约 1% 损失;TurboQuant 的优势在于零校准、零损失、有严格数学证明。
六、对硬件资源的节约——完整汇总
这是本文的核心数字,我们把所有硬件影响整理如下:
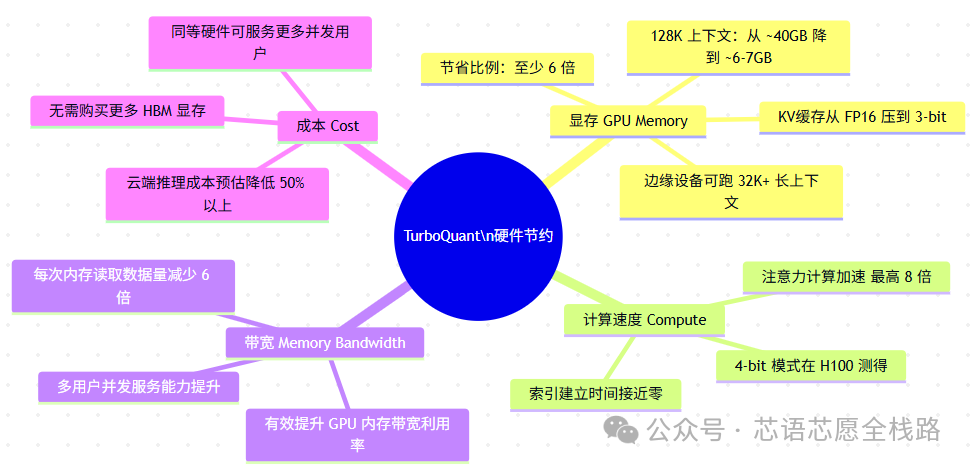
量化对比表:

七、最新进展(截至 2026年3月)
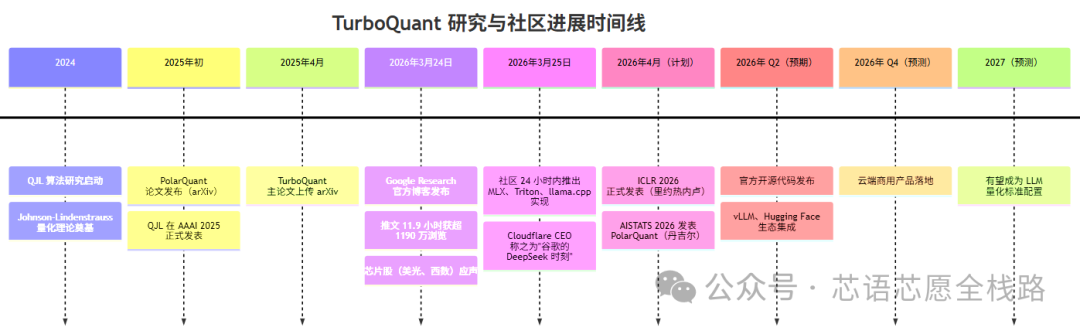
社区反应亮点:
-
MLX 社区在 Apple Silicon 上实现了约 5× 压缩、99.5% 质量保留
-
PyTorch/Triton 开发者在 RTX 4090 上测试 Gemma 3 4B,2-bit 精度下输出与原始模型逐字符完全一致
-
llama.cpp 社区已启动集成讨论(Issue#20969)
八、推理内存的完整图景:KV Cache 只是其中一块
TurboQuant 大幅压缩了 KV Cache,但 GPU 显存里装的东西远不止这一项。理解整体构成,才能知道 TurboQuant 解决了多大比例的问题,以及剩余空间在哪里。
8.1 推理时显存由哪几块组成?
以7B 模型 + 32K 上下文为典型参考,推理时显存大致分为四块:

关键规律:上下文越长,KV Cache 占比越高。到 128K 上下文时,KV Cache 可能占到总显存的 70–80%,模型权重反而变成"小头"。
8.2 四块内存各是什么?
① 模型权重(~25%,固定成本)所有参数(Attention、FFN、Embedding 等)加载后常驻显存,7B 模型 FP16 约 14 GB。不随对话长度变化,是一次性的"入场费"。
② KV Cache(~55%,最大变量)每个 token 在每一层都要存一份 Key 和 Value 向量。上下文越长,它就越大,是推理内存的核心瓶颈。
KV Cache 大小 ≈ 2 × 层数(L) × 向量维度(d) × 序列长度 × 2字节(FP16)
③ 激活值(~10%,计算中间值)前向计算过程中的中间结果(QKV 矩阵、FFN 中间层等)。计算完即可释放,但 batch 越大、序列越长,峰值越高。
④ 运行时开销(~10%,框架开销)CUDA 内核缓存、PyTorch/JAX 分配器、采样缓冲区等,通常 1–3 GB,相对固定。
8.3 TurboQuant 降低了 KV Cache,其他部分降低了吗?
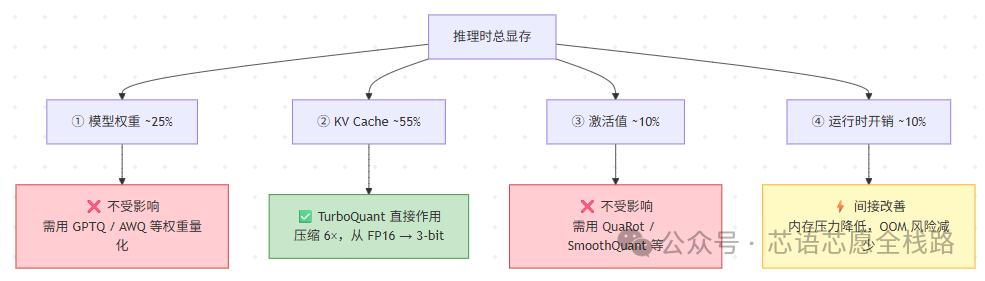
模型权重 → 完全不受影响。TurboQuant 是推理时的在线量化,不修改权重。要压缩权重,需要用 GPTQ、AWQ、GGUF 等专门方案,但两者可以叠加使用,实现更大的整体压缩。
激活值 → 不受影响。激活值压缩是独立研究方向(如 QuaRot、SmoothQuant),TurboQuant 不处理这部分。
运行时开销 → 间接改善。KV Cache 占用大幅减少后,整体内存压力降低,框架有更充裕余量管理其他开销,减少因内存碎片或 OOM 导致的额外分配——这是间接效果,量级有限。
8.4 组合使用策略
如果想把总显存压缩到极致,可以把不同工具叠加:

一句话: TurboQuant 打的是最值得打的靶——KV Cache 在长上下文下是绝对主力,压缩它就解决了推理内存的核心瓶颈。但要让 AI 推理成本降到极致,还需要把权重量化、激活量化等工具组合起来用。
九、还有什么不足?
TurboQuant 虽然优秀,但也有几个现实局限:
-
官方代码尚未开源:目前只有论文和社区实现,预计 2026 Q2 才有官方版本。
-
主要在 ≤8B 模型上验证:更大规模模型(如 70B+)的效果待进一步确认(NVIDIA KVTC 已在 70B 验证)。
-
仅针对推理阶段:不影响训练,不能降低训练成本。
-
随机旋转的工程实现:在超大规模部署中,随机旋转矩阵的生成与复用需要精心设计。
-
逼近但未达理论极限:约 2.7 倍的常数因子差距意味着,在极低比特(1-2 bit)场景仍有一定失真。
十、一句话总结
TurboQuant 用数学上最接近"终极极限"的方式,把大语言模型运行时的工作内存压缩了 6 倍以上,计算速度提升 8 倍,且不需要训练、不损失精度——这是一个真正由理论驱动、有实际落地价值的算法突破。
如果说 DeepSeek 证明了"用更少的钱训练更好的模型",那 TurboQuant 证明的是:"用更少的内存运行已有的模型"。两者合力,正在重新定义 AI 基础设施的经济学。
参考资料


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)