剩余课程笔记+OpenCV课程笔记+YOLOv8目标检测实战任务总结
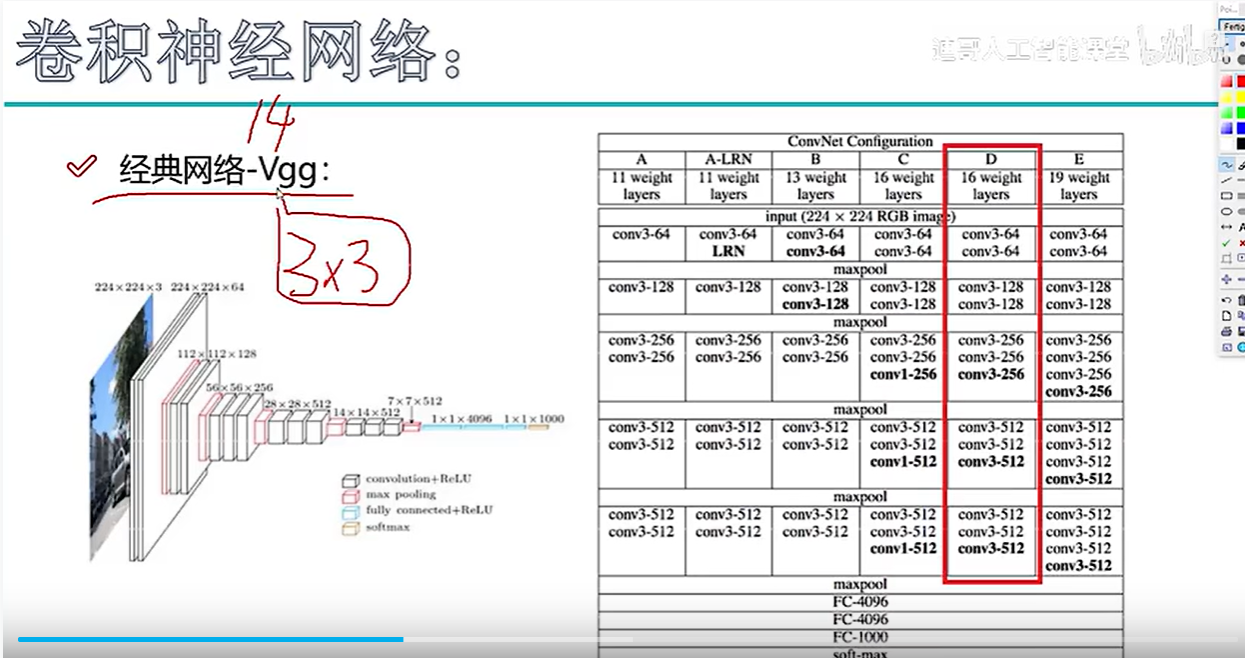
一、VGG 核心设计思想
全盘使用 3×3 小卷积核
替代大核:用多个 3×3 卷积串联替代 AlexNet 中的 11×11、7×7 大卷积核。
优势:两个 3×3 卷积相当于一个 5×5 的感受野,但参数量更少,且增加了非线性激活层,使模型判别力更强。
“块”状堆叠结构
5个卷积块:每个块包含 2~3 个卷积层,后接一个 2×2 最大池化(步长 2),特征图尺寸逐块减半。
通道数翻倍:通道数随深度增加(64 → 128 → 256 → 512 → 512),保持“宽高减半、通道翻倍”的计算规律。
U-Net 结构可明确分为左半部分(编码器)和右半部分(解码器),由底部连接。
部分 名称 作用 关键操作
左半部分 收缩路径(编码器) 特征提取,捕获上下文 两次 3×3 卷积 + ReLU → 2×2 最大池化(下采样)
底部 桥接层 连接编码与解码,传递高层语义 常规卷积操作
右半部分 扩张路径(解码器) 精确定位,恢复细节 上采样 → 与编码器特征拼接 → 两次 3×3 卷积 + ReLU
最终层 输出层 像素级分类 1×1 卷积,将通道数映射为类别数
核心机制:跳跃连接
这是U-Net成功的关键,解决了FCN中上采样结果粗糙的问题。
操作:在解码器的每次上采样后,将编码器对应层级的特征图与之拼接。
作用:
融合多尺度特征:将编码器的高分辨率细节信息与解码器的高层语义信息结合。
梯度传播:为梯度提供捷径,缓解梯度消失,使深层网络易于训练。
信息互补:使网络在定位时能“回忆”起收缩路径中捕捉到的细节。
特性 U-Net FCN
结构 对称U形,编码-解码严格对应 基于VGG等分类网络改造
特征融合 拼接 来自编码器的多尺度特征 跳跃连接,特征相加
适用场景 医学图像、小样本数据 自然场景、数据量较大
精度 在细节和边界上通常更精细 相对粗糙
opencv相关笔记整理
礼帽与黑帽
执行了 Top-hat(顶帽变换) 形态学处理:
- 代码: cv2.morphologyEx(img, cv2.MORPH_TOPHAT, kernel)
- 作用:提取图像中比周围亮的小区域/细节,图中显示了原图中较亮的丝状/点状细节被突出
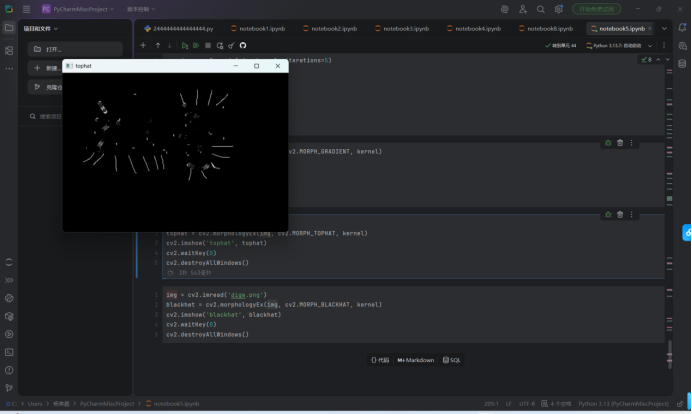
Black-hat 形态学操作
执行了 Black-hat(黑帽变换) 形态学处理:
代码: cv2.morphologyEx(img, cv2.MORPH_BLACKHAT, kernel)
-作用:提取图像中比周围暗的小区域/细节,图中显示了原图中较暗的斑点/区域被突出。
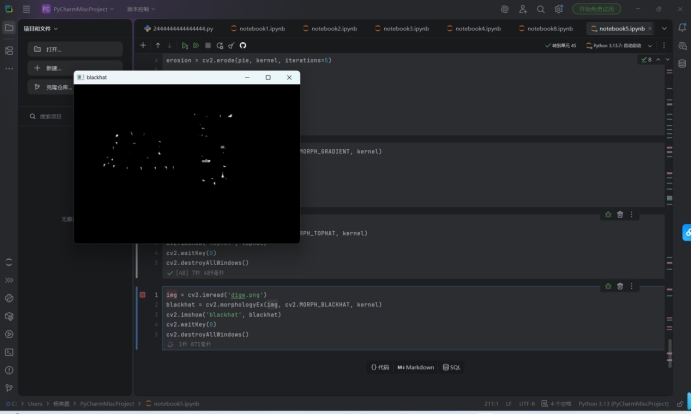
Sobel 边缘检测(单方向)
执行了 Sobel 算子单方向边缘检测:
-代码:分别使用 cv2.Sobel(img, cv2.CV_64F, 1, 0, ksize=3) (水平方向 sobelx )和 cv2.Sobel(img, cv2.CV_64F, 0, 1, ksize=3) (垂直方向 sobely )
- 作用:检测图像在水平/垂直方向的边缘,图中圆形物体的轮廓被清晰提取。
-窗口标题: sobelx / sobely 
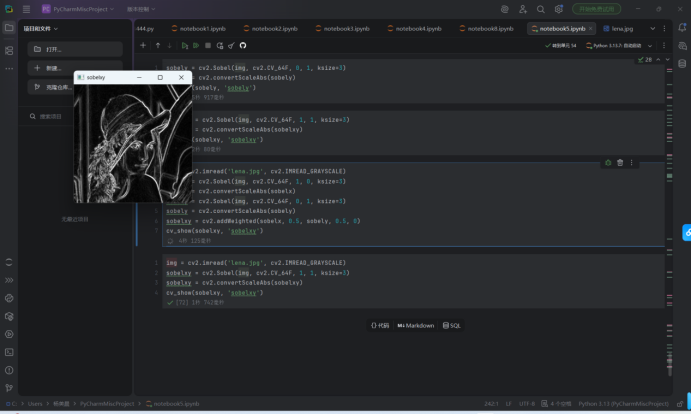
Sobel 边缘检测(方向加权)
执行了 Sobel 算子方向加权融合:
-代码: cv2.addWeighted(sobelx, 0.5, sobely, 0.5, 0)
-作用:将水平和垂直方向的边缘图按权重融合,得到完整的边缘轮廓,图中人物的轮廓细节被完整提取。
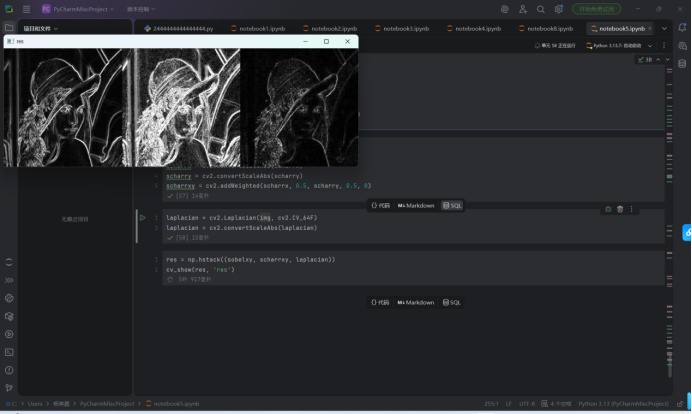
多种边缘检测算法对比
执行了 多种边缘检测算法的对比展示:
-涉及算法:
1. Sobel: sobelxy (方向加权融合结果)
2. Scharr: scharrxy (更精确的梯度算子)
3. Laplacian: laplacian (二阶导数边缘检测)
-代码: np.hstack((sobelxy, scharrxy, laplacian)) 将三种结果横向拼接展示。
作用:直观对比不同边缘检测算法的效果差异,图中三幅图分别对应 Sobel、Scharr、Laplacian 的输出。
总结
完成了 形态学操作(Top-hat / Black-hat)和 边缘检测(Sobel / Scharr / Laplacian)两类图像处理任务:
1. 形态学:用于提取图像中明暗差异的小细节。
2. 边缘检测:从基础方向检测到多算法对比,逐步深入学习不同边缘提取方法的效果。
YOLOv8目标检测实战任务总结
目标:使用 Ultralytics YOLOv8 模型,对一张名为 alpaca.png 的羊驼图片进行目标检测,识别出图片中的物体类别和位置,并可视化展示检测结果
实施过程
1. 环境搭建与模型准备操作:配置 Python 环境,安装 ultralytics 库
关键困难:首次运行 model = YOLO('yolov8n.pt') 时,程序需要从 GitHub 下载模型权重文件。
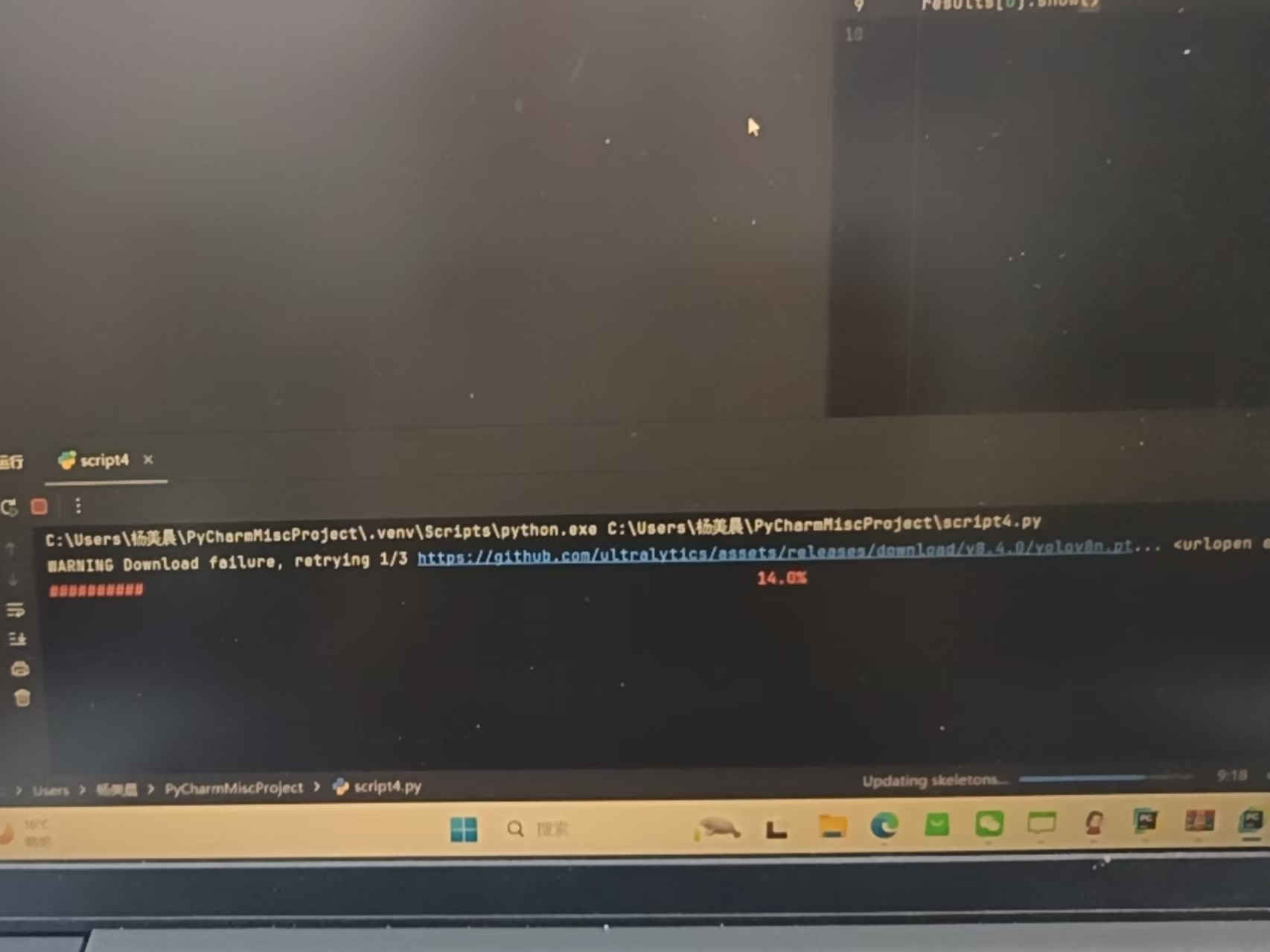
解决:由于网络环境限制,下载过程卡顿并报错。采用了离线绕过的方法:创建空文件 yolov8n.pt 欺骗程序。
导入环境变量 {"download": false} 彻底禁用网络检测。最终成功通过本地加载完成了模型的初始化。
2. 数据输入与路径调试操作:加载图片 results = model("alpaca.png") 。
关键困难:出现 FileNotFoundError ,提示图片不存在。
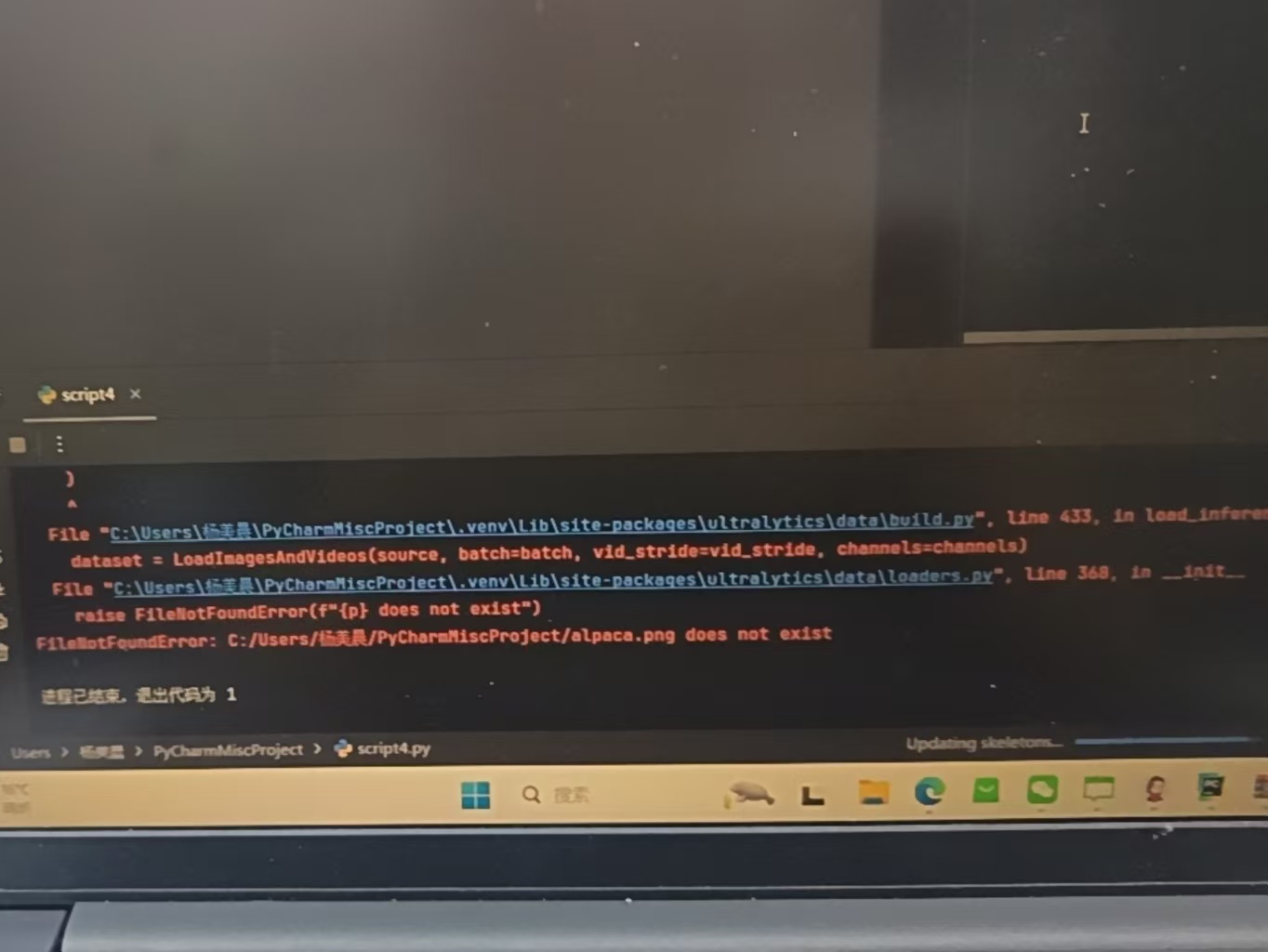
原因一:误将图片后缀写成了 .png.png (双重后缀)。
原因二:Windows 路径分隔符 \ 在 Python 中被视为转义字符,导致路径识别失败。
解决:修正文件名为标准的 alpaca.png 。使用绝对路径 C:/Users/杨美晨/.../alpaca.png (换成 / ),确保程序能精准找到文件。
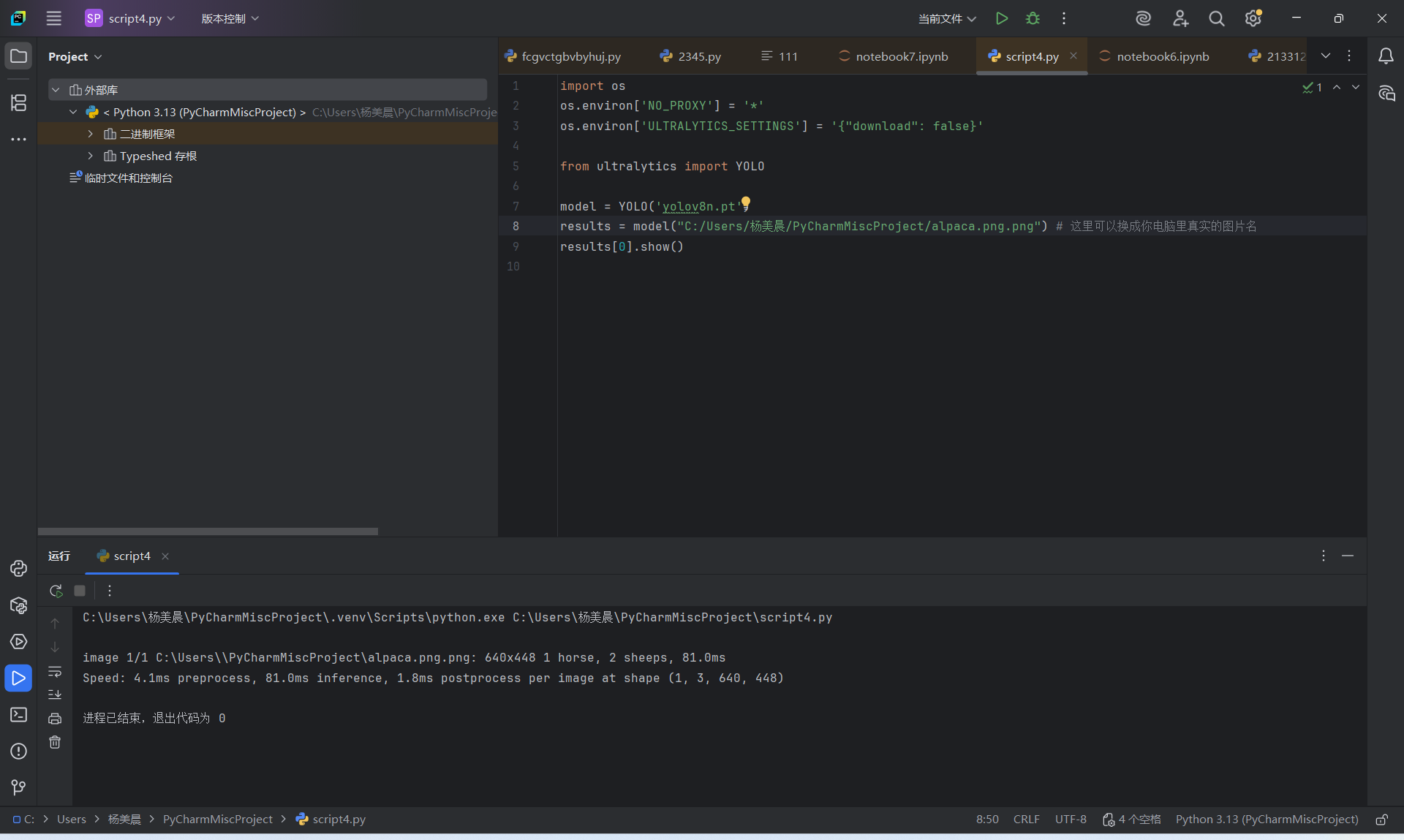
3. 推理执行与结果展示操作:运行代码并调用 results[0].show() 。
过程:代码成功运行,模型对输入图片进行了快速的预处理、推理和后处理。
4. 成果查看操作:打开生成的检测结果图。
现象:成功弹出带红色检测框的图片
最终学习成果
1. 视觉成果:成功看到了带检测框的 alpaca.png 图片。
模型识别出了画面中的主体(虽然被误判为 sheep ,但框选位置精准)。
识别出了背景旁的物体(被误判为 horse )。
检测框的置信度(Confidence)显示模型对目标的定位是准确的。
2. 技术成果:已经掌握了使用 YOLOv8 进行目标检测的基础代码流程,并学会了如何处理网络环境和文件路径这两个常见的坑
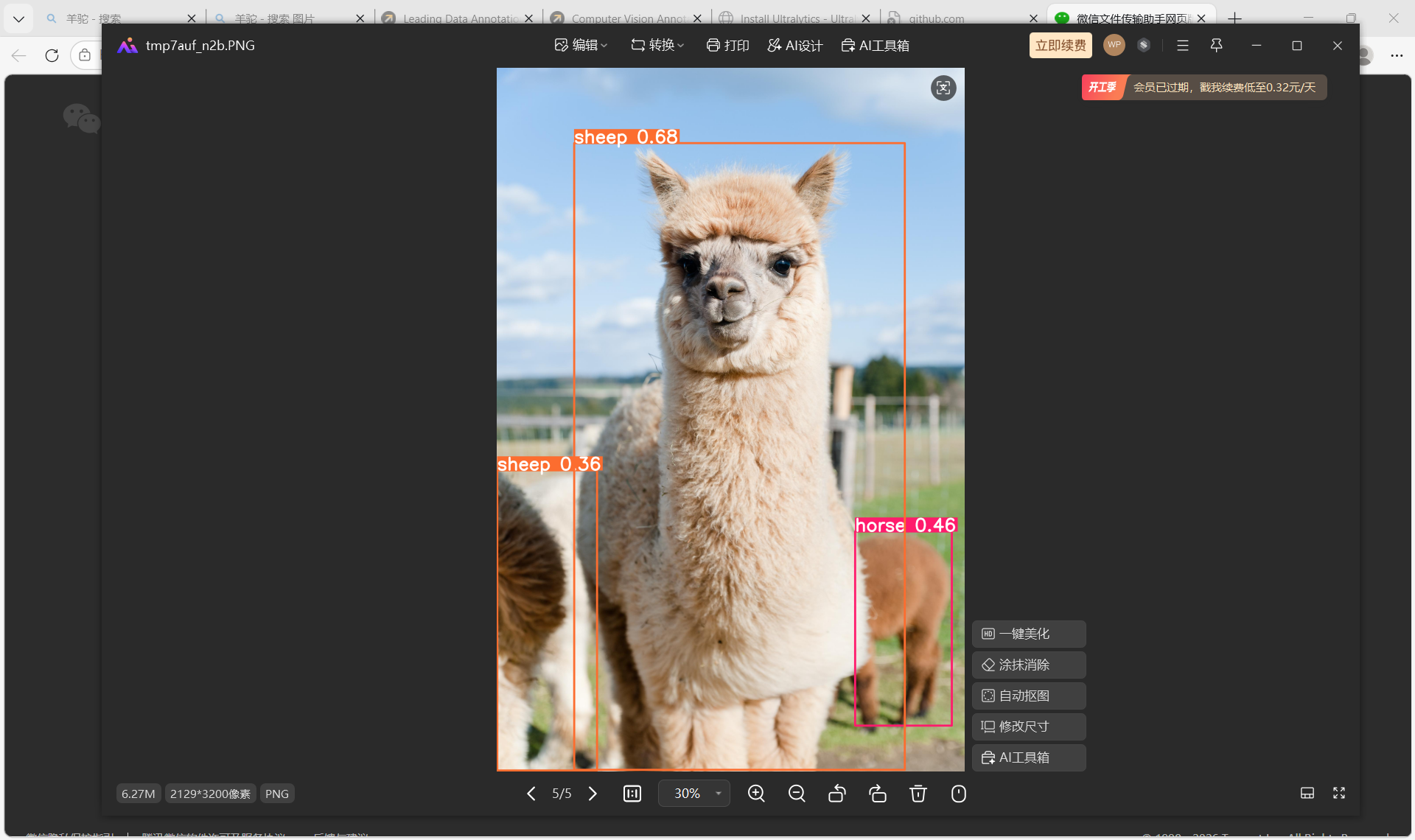
在 CVAT 标注工具 里对图片进行目标标注,给图中的羊驼(alpaca)打上了标签,并绘制了对应的标注框,完成了图像标注工作
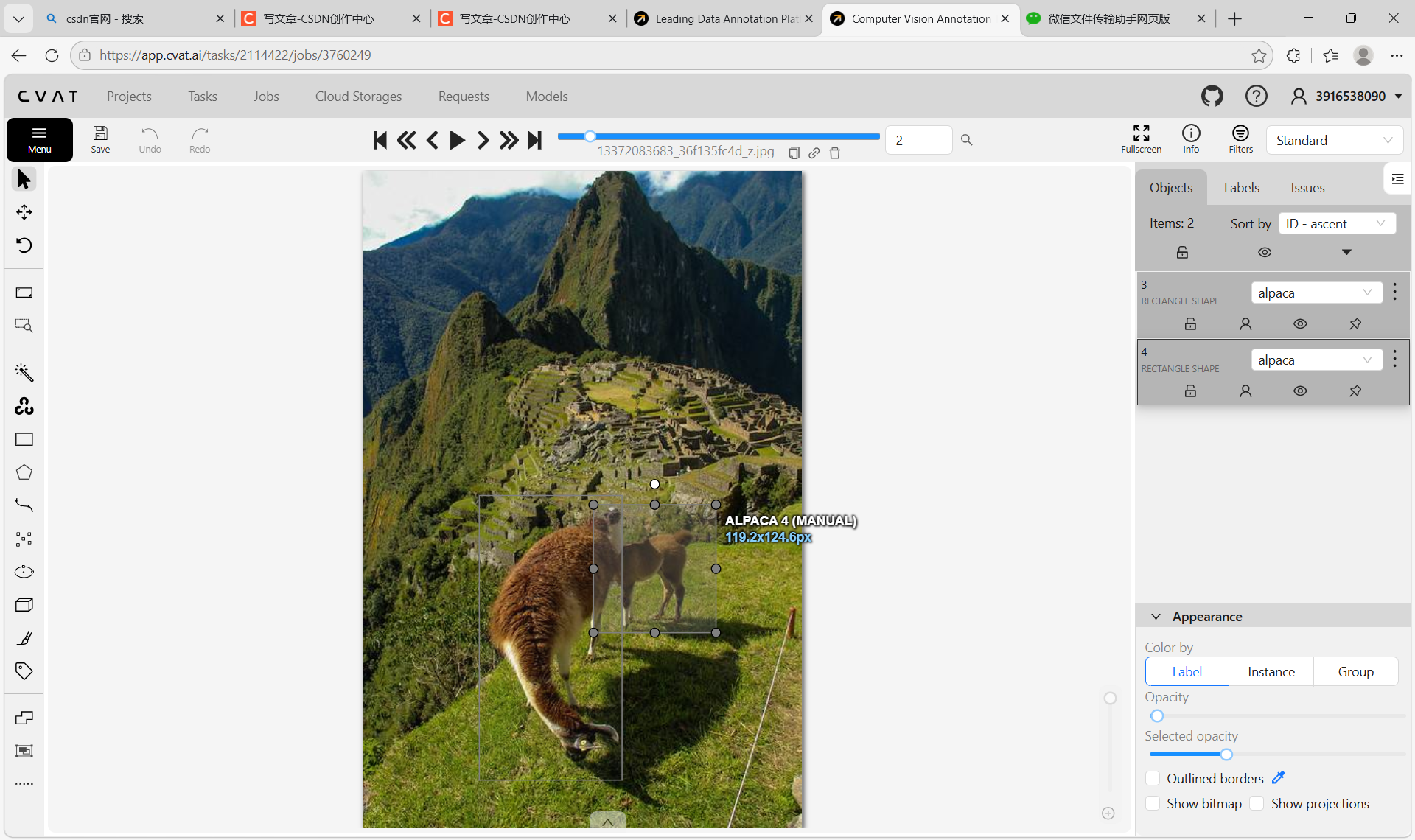
将标注好的数据导出为 YOLO 格式,导出任务已经完成(进度 100%),等待下载标注结果文件
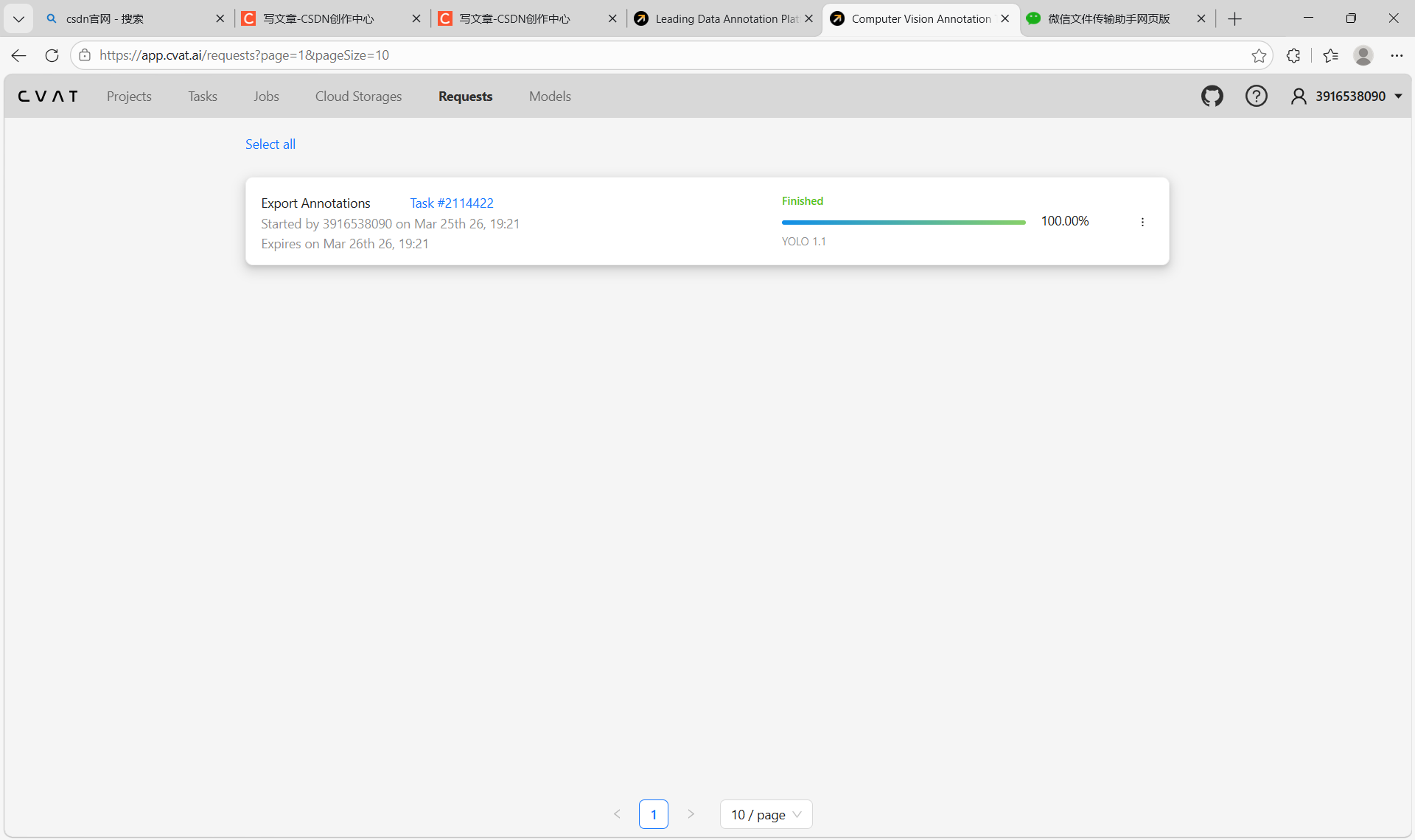
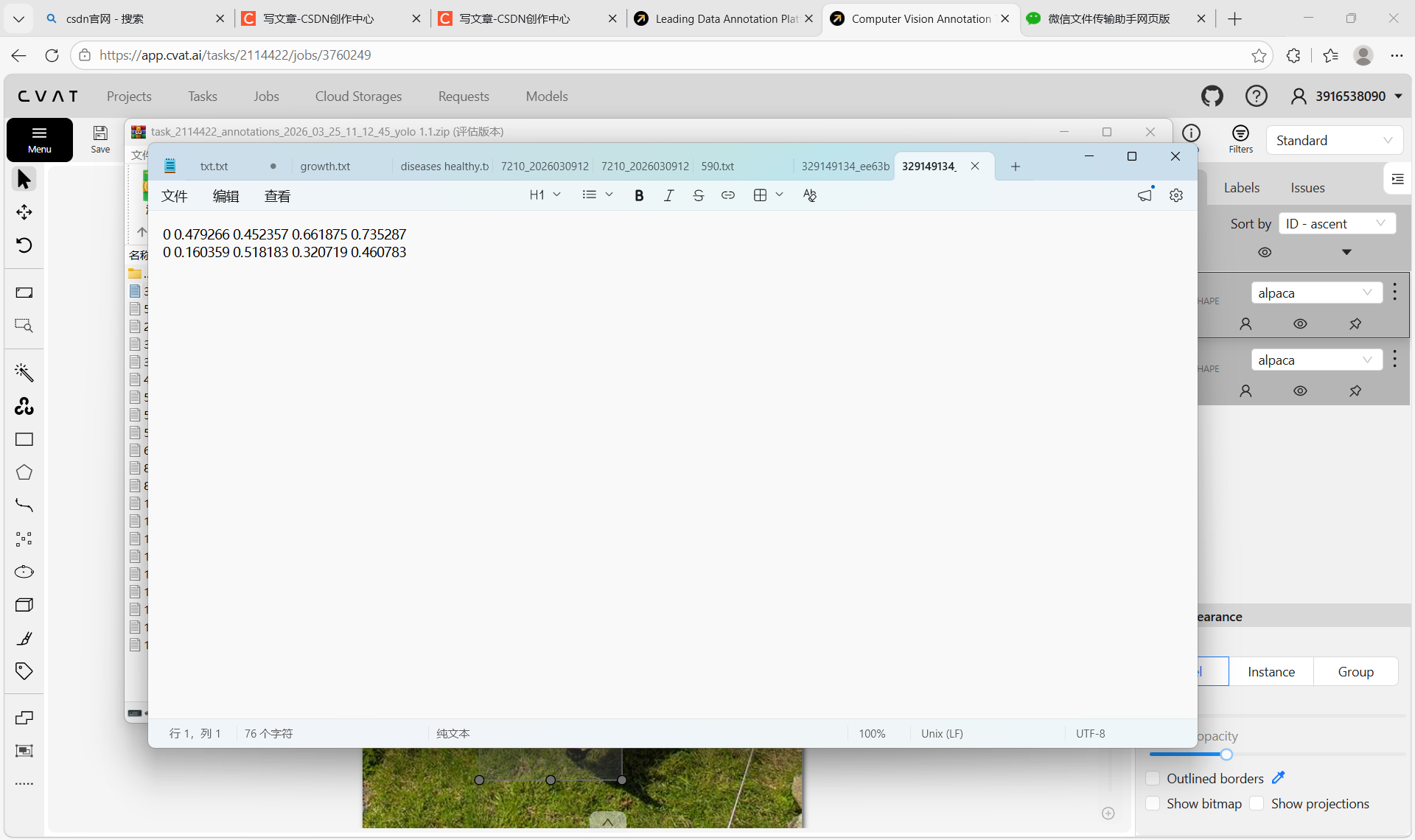
打开导出的压缩包,里面是按图片命名的多个标注文本文件,每个文件对应一张图的标注信息
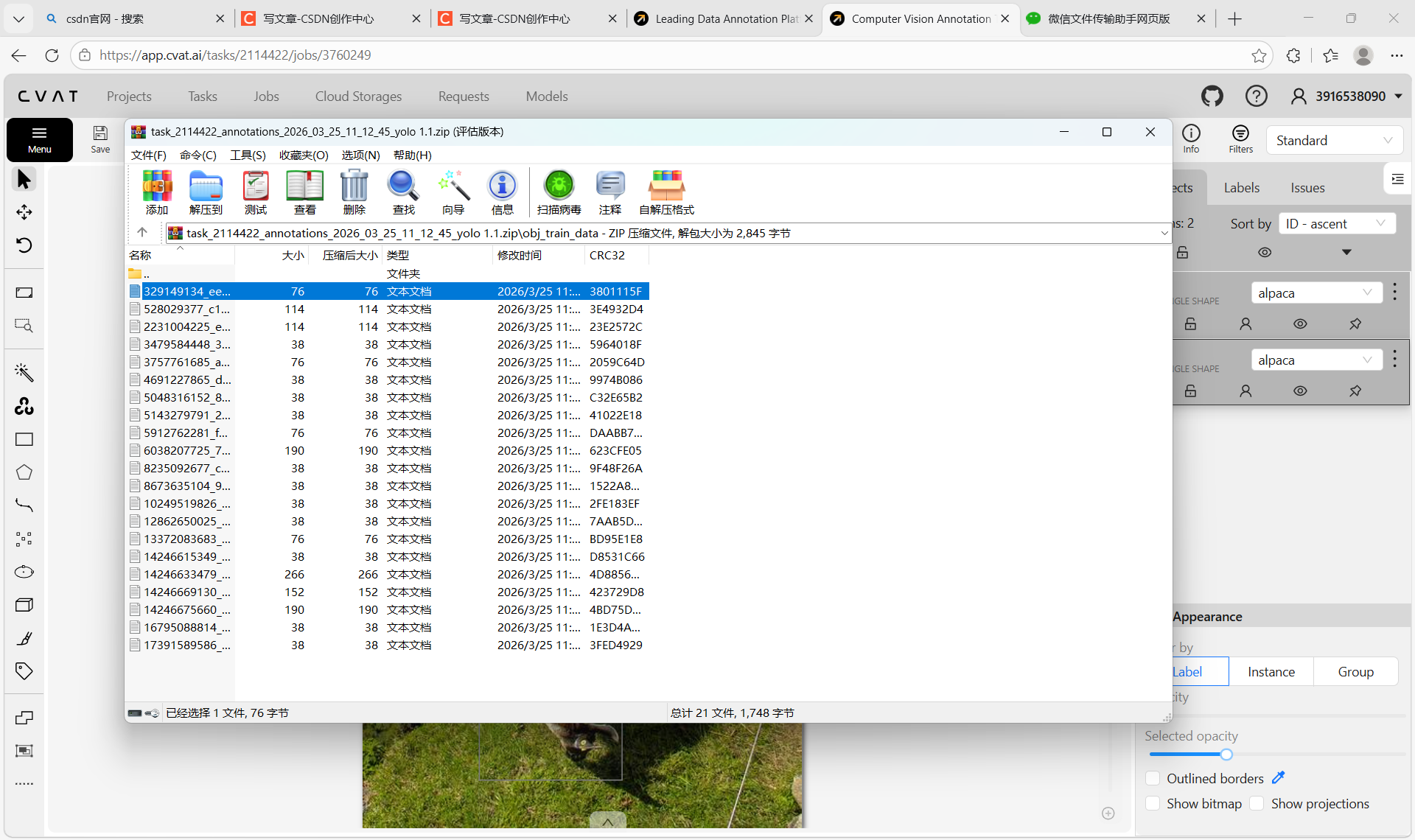
打开其中一个标注文件,查看具体内容——文件里是 YOLO 格式的标注数据,每行代表一个目标,包含类别 ID 和归一化后的 bounding box 坐标
1. 环境与模型准备
在 PyCharm 里写了 Python 代码,导入了 ultralytics (YOLOv8 官方库)和 cv2 (OpenCV 图像处理库)。
加载了 yolov8n.pt 预训练模型:这是 YOLOv8 里最轻量最快的版本,会自动从网上下载权重文件。
2. 核心操作:检测单张图片
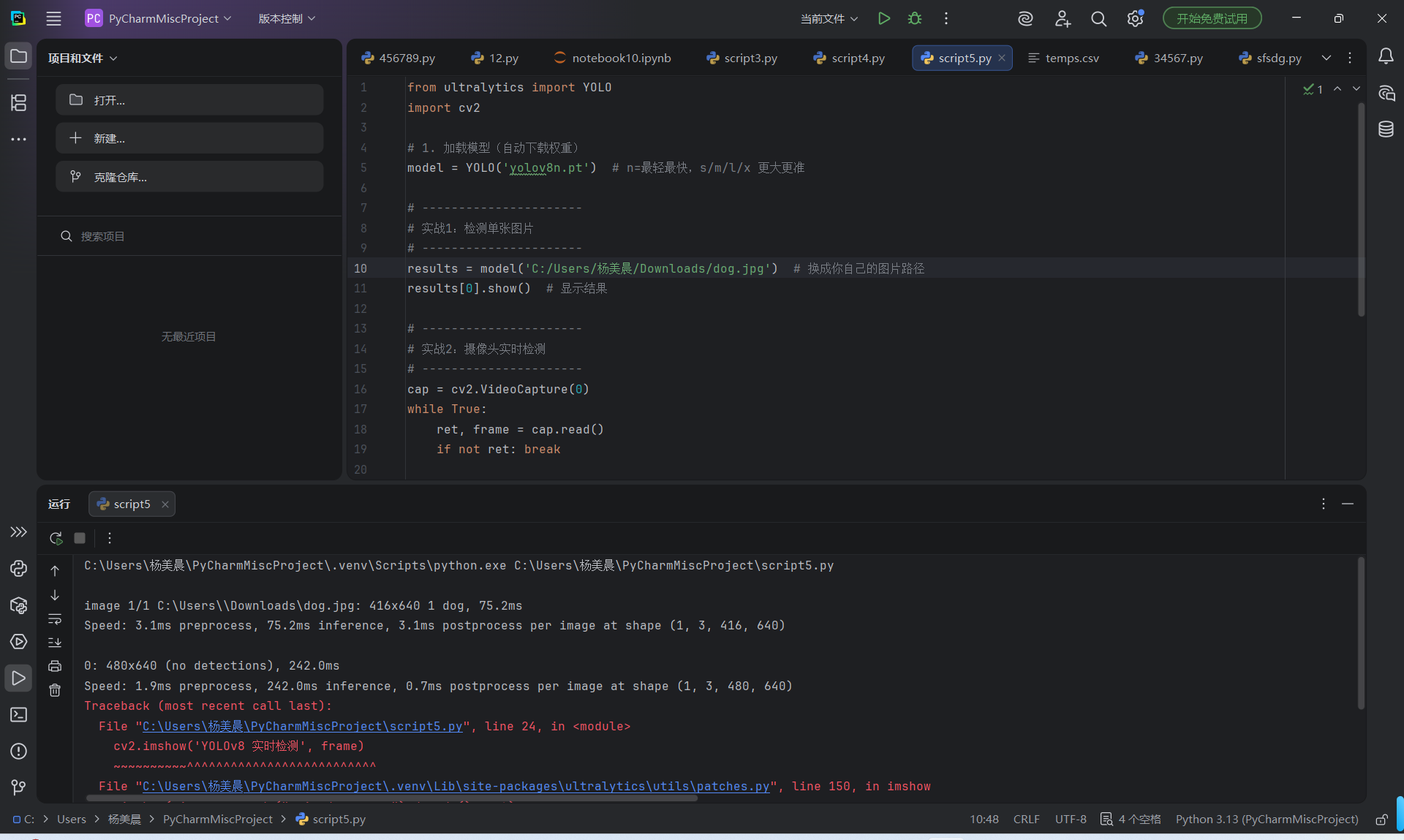
指定了一张本地小狗图片路径 C:\Users\杨美晨\Downloads\dog.jpg ,让模型去识别。
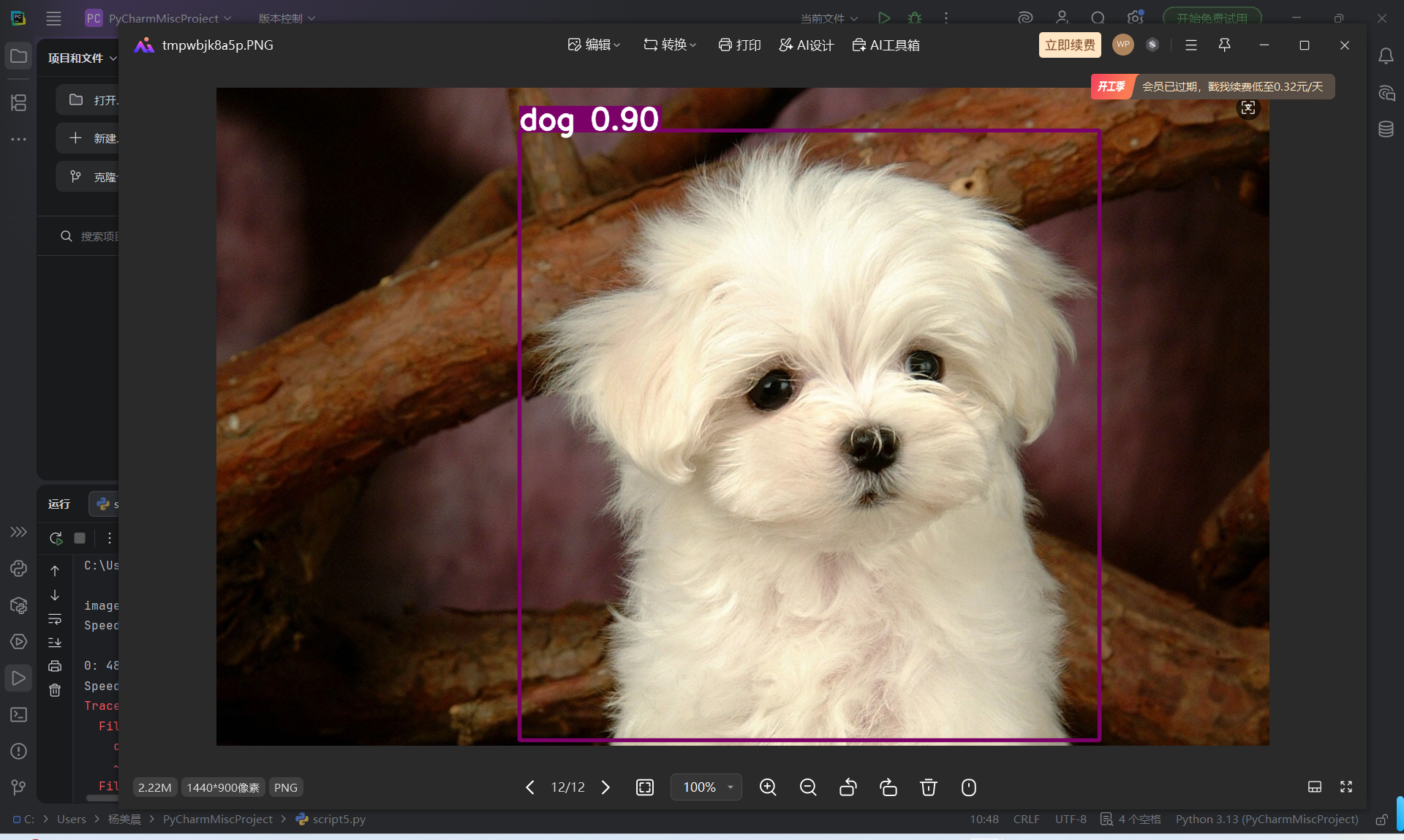
模型输出结果:识别到 1 只狗(dog),置信度 0.90,并用紫色框标注出来(就是第二张图里的效果)。
控制台也打印了检测信息:
模型在 75.2ms 内完成了推理,速度很快。
尝试摄像头实时检测(遇到了小问题)
接着写了摄像头实时检测代码:用 cv2.VideoCapture(0) 打开电脑摄像头,逐帧检测并显示结果。
控制台最后报了 Traceback 错误,说明在 cv2.imshow 这一步出了问题(可能是窗口显示冲突、权限问题或 OpenCV 版本兼容问题),但图片检测已经完全成功了。
总结成果
成功安装并调用了 YOLOv8 模型
完成了单张图片目标检测,模型准确识别出了小狗并可视化
初步尝试了实时摄像头检测的代码框架(虽然最后显示环节报错,但核心推理逻辑是通的)
熟悉了 YOLOv8 的基本工作流:加载模型 → 传入数据 → 得到结果 → 可视化
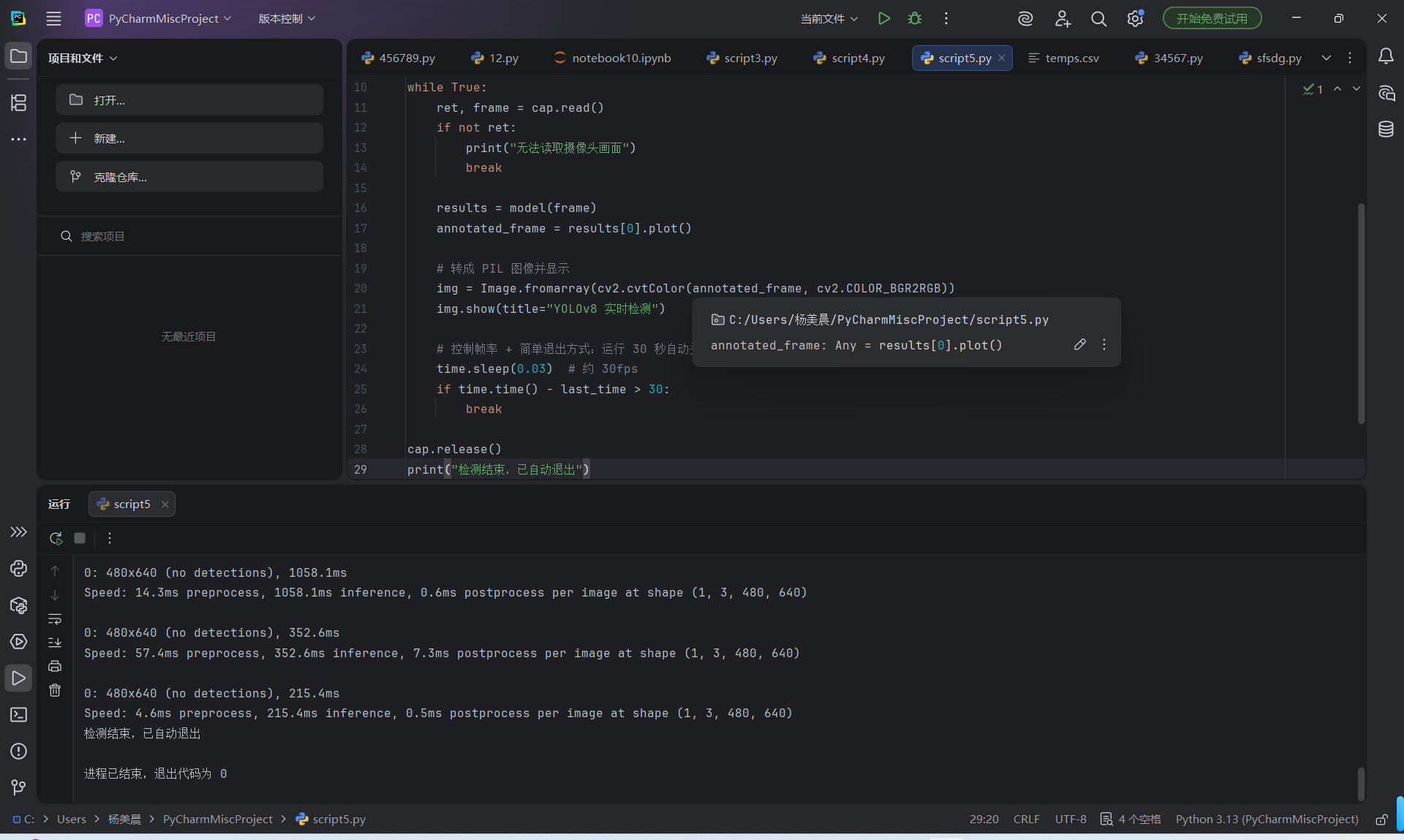
运行了 YOLOv8 摄像头实时检测代码
代码逻辑是:调用电脑摄像头( cv2.VideoCapture(0) ),逐帧读取画面,用 YOLOv8 模型做目标检测,然后通过 PIL 显示检测结果。
-程序会自动运行 30 秒 后退出,这和代码里 if time.time() - last_time > 30: break 的设置一致。
检测过程与结果
控制台输出了多帧检测信息: 0: 480x640 (no detections), xxxms ,说明摄像头成功获取了画面,但画面中没有被模型识别到的目标(比如人、动物、车辆等)。
-每帧推理耗时在 200ms~1000ms 之间,这是正常的实时检测速度(受电脑性能影响)。
- 程序最终正常退出,输出 检测结束,已自动退出 ,说明代码逻辑跑通了,没有报错。
3. 解决了之前的 OpenCV 窗口问题
用 PIL 的 img.show() 替代了 cv2.imshow() 和 cv2.waitKey() ,彻底避开了之前的 OpenCV GUI 报错,让程序能稳定运行到结束。
完成了一次完整的 YOLOv8 摄像头实时检测实战
1. 代码层面的操作
运行了 script5.py ,这段代码是纯摄像头检测逻辑:
用 cv2.VideoCapture(0) 打开了电脑的默认摄像头
循环读取摄像头画面( cap.read() ),逐帧传给 YOLOv8 模型
模型对每帧画面做目标检测,用 results[0].plot() 画出检测框
通过 PIL 显示画面(避开了之前的 OpenCV 窗口报错)
程序设置了 30 秒自动退出,最后正常结束
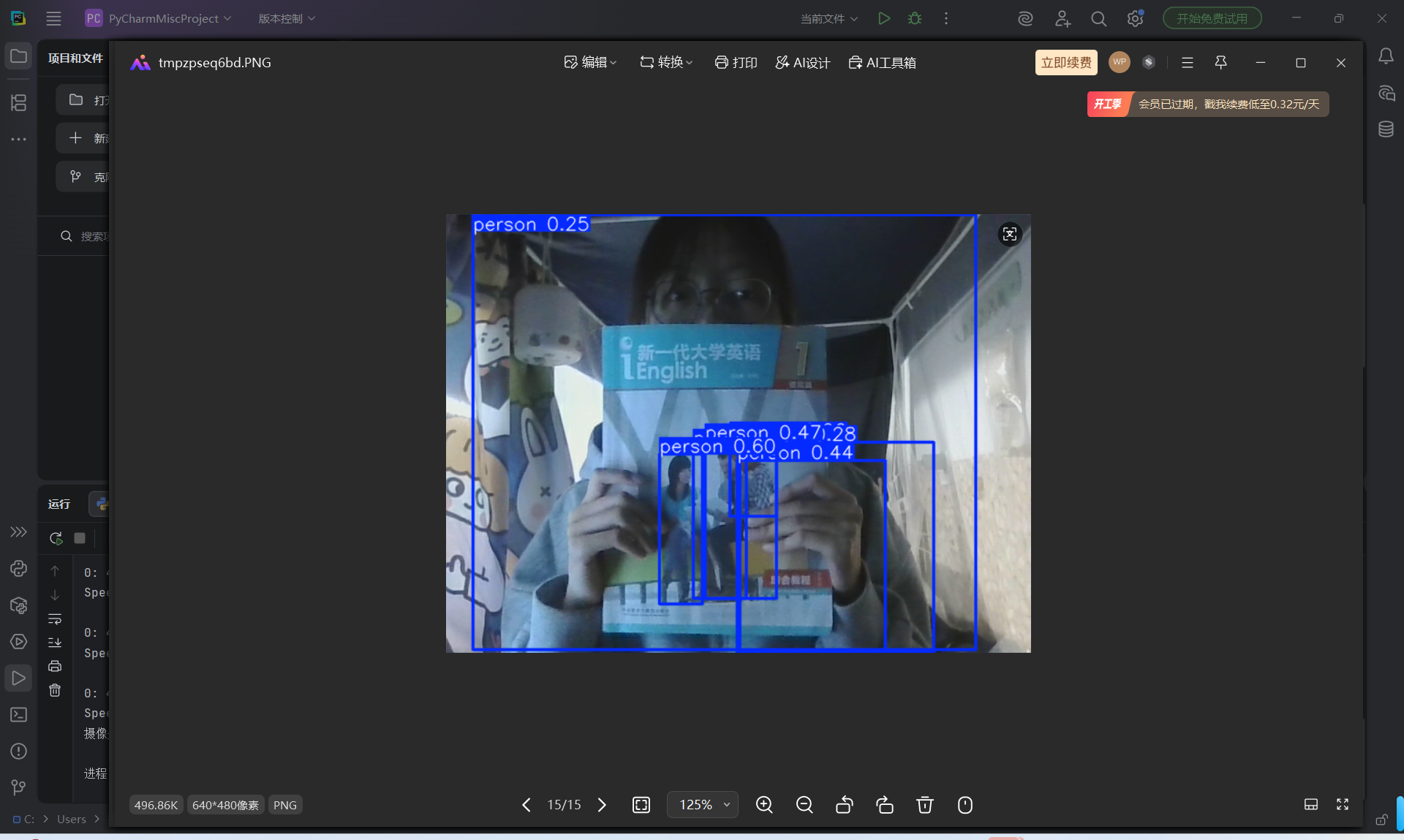
2. 实际运行效果
-控制台输出:显示了多帧检测结果,比如 0: 480x640 4 persons, 172.4ms ,说明摄像头成功获取画面,并且模型识别到了画面中的人物(person)
- 可视化结果:弹出的窗口里用蓝色框标注出了检测到的人物,包括本人和书本封面上的人物形象,每个框都带有置信度(比如 person 0.60 、 person 0.47 ),代表模型对这个检测结果的可信度
总结成果
- 成功调用了摄像头:彻底解决了之前的 OpenCV 窗口问题,摄像头画面正常读取和显示
- 完成了实时目标检测:YOLOv8 模型成功识别出了画面中的多个人物,并可视化标注
- 掌握了完整流程:从「打开摄像头 → 读取画面 → 模型推理 → 结果显示 → 释放资源」的全链路跑通了
模型不仅识别到了本人,还把书本封面上的人物也识别成了 person ,这是因为 YOLOv8 会把所有类人形态的物体都判定为人物,属于正常现象。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 13
13 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)