卷完提示词卷上下文,2026年卷“赛道“:AI程序员时代来了
OpenAI 最近做了个实验:3个工程师,5个月,写了100万行代码。
听起来不算啥?等等,这100万行代码,一行都不是人写的。
全是AI写的。
而且这不是Demo,不是玩具项目。这是一个有真实用户、能上线、会出Bug也能修的生产级产品。
OpenAI说,这个实验的目的不是炫技。他们想知道一件事:AI程序员到底需要什么环境,才能大规模可靠地工作?
答案让很多人意外:不是模型不够强,是环境没准备好。

OpenAI实验数据:3人5个月,AI产出100万行代码
程序员的世界,正在发生一次静默革命
如果你是个程序员,或者身边有程序员朋友,你一定听过这些词:
- Prompt Engineering(提示词工程)
- Context Engineering(上下文工程)
- RAG、Agent、Copilot…
过去三年,这个行业对"怎么让AI干好活"的理解,换了三次底层逻辑。
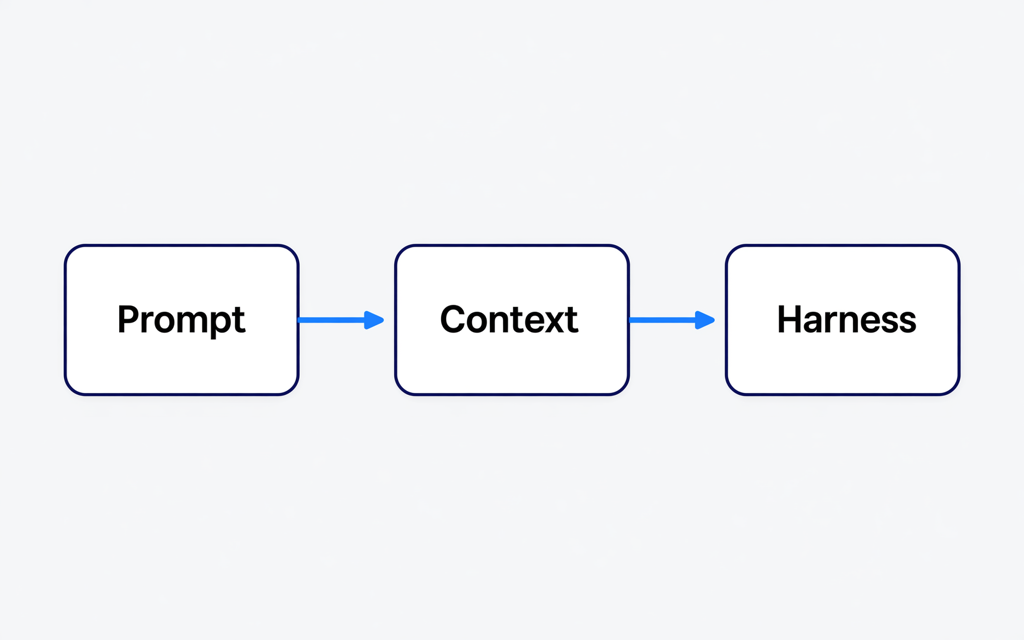
AI工程化的三次演进
第一阶段:卷提示词(2023年)
最早的时候,所有人都在研究怎么问AI问题。
Few-shot、Chain-of-Thought、角色扮演…各种技巧满天飞。大家相信一个道理:问对问题,就能拿到好答案。
这在聊天场景确实管用。你跟ChatGPT聊,问得好,它答得好。
但问题是,AI一旦要从"回答问题"进化到"独立干活",光靠一条指令就不够用了。
就像你请了个助理,你告诉他"做个PPT",他问你"什么主题",你说"就那个项目",他说"哪个项目?"…聊20轮还没开始干。
提示词能告诉AI"做什么",但拦不住AI"做错"。
第二阶段:卷上下文(2025年)
于是大家开始卷上下文。
OpenAI的大神Karpathy提出了Context Engineering。简单说,就是把所有相关信息——文档、历史对话、工具输出——动态组装起来喂给AI。
这确实让AI变强了。但很快,一个要命的悖论出现了:
就算模型支持100万Token,性能衰减在25万Token左右就出现了。
更吓人的是,有人的AI Agent陷入无限循环,一次事故烧了5万美元。
上下文能告诉AI"知道什么",但拦不住AI"做不该做的事"。
2026年,卷的是"赛道"
今年2月,HashiCorp联合创始人Mitchell Hashimoto写了一篇博客,给缺失的那块拼图命了名:
Harness Engineering(线束工程)。
他说了一句话,我觉得简洁到可以刻在墙上:
“每当Agent犯了一个错误,你就花时间设计一个解决方案,使Agent永远不再犯同样的错误。”
什么意思?
Prompt Engineering管的是"说什么",Context Engineering管的是"知道什么",Harness Engineering管的是"在什么环境里做事"。
人类的角色,从"直接干活的"变成了"设计赛道的"。
你不再亲手跑每一步,而是把围栏、弯道、刹车全部提前造好,然后让AI自己跑。

人类设计赛道,AI自主奔跑
OpenAI的实验,到底发现了什么?
回到开头那个实验。
3个工程师,5个月,AI写了100万行代码。平均每人每天合并3.5个PR。
这个产出量,人类QA根本跟不上。但OpenAI的做法很绝:他们没有招更多测试,而是让AI自己"看见"运行时。
他们给AI接上了Chrome DevTools Protocol,AI可以直接启动应用、截屏、操作网页、重现Bug。再把日志、指标全部暴露给AI,它可以直接查询。
于是"确保服务启动在800毫秒内"这种以前只有人才能判断的事,AI也能执行了。
团队经常让AI通宵跑任务,跑六个小时。通常是在人类睡觉的时候。
人睡觉了,AI还在干活。
给地图,别给百科全书
OpenAI学到的第一课,跟很多人想的不一样:
指令文件太长,AI反而表现更差。
一个巨大的说明文件会挤占真正重要的信息空间。当所有内容都"重要"时,什么都不重要了。
所以他们把AI的说明书从"百科全书"变成了"目录"。大约100行,只告诉AI"接下来去哪里找信息",具体内容全在文档目录里。
这叫渐进式披露。先给入口,再按需深入。
还有一个反直觉的发现:架构约束越严,AI跑得越快。
团队给应用搭了非常严格的架构:每个业务领域固定分层,依赖方向严格校验,跨领域只能通过统一接口进入。违反了就报错。
这种架构约束,一般大公司到几百人的时候才会搞。但他们在3个人的时候就上了。
因为AI在有明确规则的环境里,跑得比"自由发挥"快得多。规则对AI来说就是导航,不是枷锁。
Hashimoto的六步:从怀疑到离不开
Hashimoto(就是命名Harness Engineering那位)把自己的AI采用之路拆成了六步。
我觉得前三步最有借鉴意义:
第一步:扔掉聊天机器人
很多人用AI,就是打开ChatGPT,问一句答一句。
Hashimoto试过,效果惊艳,但换个任务就不行了。尤其是老项目,AI产出的东西改起来比自己写还慢。
关键转折:必须用Agent,不是Chatbot。
Agent能读文件、跑命令、发请求。Chatbot只能聊天。
第二步:同一件事做两遍
这步最狠。他强迫自己先手动完成任务,再让AI独立做一遍。
“极其痛苦”,他自己说的。
但逼出了三个关键发现:
-
拆任务要拆细
-
模糊需求先规划再执行
-
给AI自我验证的手段,它会自己修Bug
还有一个很多人忽略的点:搞清楚什么时候不该用AI。
第三步:下班前30分钟,启动AI
每天下班前,给AI布置任务,让它通宵跑。
三类任务特别适合:
- 深度调研(比如扫描某个领域所有库的优缺点)
- 并行探索模糊想法
- Issue分诊(批量处理GitHub问题)
第二天早上直接看报告。这叫"第二天的热启动"。
Hashimoto还分享了一条心态建议:关掉AI的桌面通知。你的职责是控制何时中断AI,而非被它中断。
从怀疑,到共处,到离不开。采用任何有意义的工具都是这个曲线。
LangChain的实验:不换模型,排名从第30涨到第5
如果你觉得上面的例子都是大厂才能玩的,LangChain的故事可能更有说服力。
他们的AI编码Agent参加测试,只改了Harness,没碰底层模型,排名从全球第30跳到第5。
改了什么?四件事:
-
强制闭环:AI说"做完了"不算数,必须跑验证才算
-
环境注入:启动时告诉AI目录结构、工具路径、评测标准
-
死循环检测:追踪文件编辑次数,AI空转就强制停
-
推理三明治:规划和验证用强模型,执行用便宜的
没换引擎,只改了赛道。成绩就上去了。
“环境比模型重要”,看完这个案例就不用再争了。
对普通程序员意味着什么?
如果你也是一个天天跟代码打交道的开发者,Harness Engineering对你到底意味着什么?
第一,核心竞争力在转移
从"写代码的速度"到"理解系统的深度"。
有人描述OpenClaw创始人用AI的方式:只聊架构和重大决策,完全不碰具体实现。
他脑子里装着项目全貌,AI负责把想法变成代码。
这些年积累的架构经验、对系统瓶颈的直觉、踩过的坑,这些东西以前觉得"不如会写代码值钱",现在反过来了。
你理解得越深,Harness就建得越好,AI的产出质量就越高。
第二,今天就可以开始建自己的Harness
不用等什么最佳实践。
在你的项目里建一份AGENTS.md,从最基本的内容写起:
- 核心架构说明
- 常见AI错误
- 测试命令
- AI不能碰的东西
每次AI犯错,回来补一条规则。日积月累,这份文件就是你的Harness。
Hashimoto就是这么干的,OpenAI也是。
第三,别让新人跳过"手写代码"这一关
有个尖锐的问题:如果新人一上来就用AI写所有代码,从来没经历过手动开发的磨练,将来谁来建Harness?
你得先知道代码怎么写、系统怎么崩、Bug怎么藏,才知道赛道的护栏应该装在哪。
写在最后
2026年最值得关注的技术辩论之一:Big Model vs Big Harness。
短期简单任务,模型够强就行。但长期复杂项目,没有Harness,再强的模型也会漂移、失控、腐化。
Hashimoto那句话我越想越觉得精准:
“每当Agent犯错,就设计一个方案让它永远不再犯。”
这不就是工程的本质吗?把经验编码成系统,让错误只发生一次。
只不过这一次,你编码的对象不是业务逻辑,而是AI运行的整个世界。
这里给大家精心整理了一份全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!
👇👇扫码免费领取全部内容👇👇
1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。
2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2026行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

7. 资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献63条内容
已为社区贡献63条内容

所有评论(0)