扩散模型(DDPM)经典论文推荐(二):Scalable Diffusion Models with Transformers
在生成式AI爆发的浪潮中,扩散模型早已成为图像生成领域的核心力量——从Stable Diffusion到DALL·E 2,几乎所有主流模型都沿用着经典的U-Net架构。但在2022年底,由UC Berkeley和New York University联合发表、并入选ICCV 2023 Oral的论文《Scalable Diffusion Models with Transformers》(简称DiT),却提出了一个大胆的想法:用Transformer彻底替换扩散模型中的U-Net backbone。
这篇论文不仅打破了“扩散模型必须依赖U-Net”的固有认知,更证明了纯Transformer架构的扩散模型具备极强的可扩展性,为后续Sora等多模态生成模型奠定了重要基础。今天,我们就来深度拆解这篇“颠覆式”论文,看懂它如何让扩散模型实现“算力越多,性能越强”的突破。
一、背景:U-Net的统治与Transformer的“跨界机会”
在DiT出现之前,扩散模型领域长期存在一种“架构割裂”:自然语言处理(NLP)早已被Transformer一统天下,凭借并行处理能力和长距离依赖建模能力,展现出惊人的Scaling Laws(缩放定律)——简单来说,只要增加算力、扩大参数量,模型性能就会稳步提升;而扩散模型则始终被U-Net架构“绑定”,即便经过多次优化,仍存在难以突破的瓶颈。
U-Net之所以能成为扩散模型的“标配”,核心在于其强大的归纳偏置——通过下采样、上采样和跳跃连接,能高效捕捉图像的局部特征,在小数据场景下表现出色。但这种强归纳偏置也带来了局限:
-
可扩展性差:当模型参数量和计算量增加到一定程度,性能会陷入瓶颈,无法像GPT系列那样通过“堆算力”持续提升;
-
计算效率低:在高分辨率图像生成任务中,U-Net的卷积操作会带来巨大的计算开销,难以平衡速度与质量;
-
泛化能力有限:强归纳偏置使其对陌生场景的适配性不足,跨分辨率、跨领域迁移困难。
与此同时,Transformer的“弱归纳偏置”反而成为了优势——它不预设图像的空间关系,将图像视为序列进行处理,这种通用性在数据量爆发的时代,能更好地挖掘数据中的潜在规律。更关键的是,扩散模型的“非自回归生成范式”(同时对所有像素去噪),恰好规避了Transformer长期存在的“错误累积”问题,为两者的融合提供了完美的技术前提。
DiT论文的核心动机,正是要回答一个关键问题:如果用Transformer替换U-Net,扩散模型能否复刻GPT的成功,实现“算力与性能正相关”的可扩展特性?
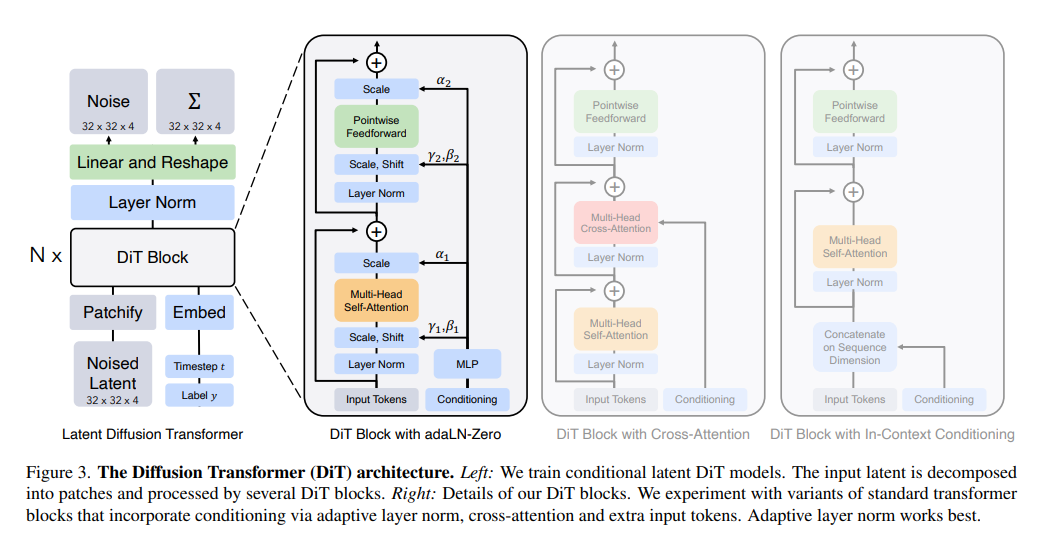
二、核心创新:DiT架构的三大关键设计
DiT并非简单地将U-Net换成Transformer,而是围绕“可扩展性”和“计算效率”,设计了一套完整的架构方案。其核心思路是:在Latent空间(潜空间)中,用处理图像补丁(Patch)的Transformer,替代传统U-Net的卷积骨干网络,同时通过创新的条件注入和模块设计,兼顾性能与训练稳定性。
1. 潜空间优先:降低Transformer的计算负担
Transformer的计算复杂度与序列长度的平方成正比,若直接在像素空间处理高分辨率图像(如512×512),序列长度会达到百万级,计算量将无法承受。DiT借鉴了Latent Diffusion Models(LDM)的两阶段策略,先通过预训练的VAE(自动编码器)将高维像素图像压缩到低维潜空间,再在潜空间中进行扩散训练。
这种处理方式的优势十分明显:潜空间的特征图尺寸远小于原始像素图像(例如将512×512图像压缩为64×64的潜特征),极大减少了Transformer需要处理的序列长度,让大规模Transformer在扩散模型中变得计算可行且高效。
2. Patchify序列化:让Transformer“看懂”图像
与ViT(Vision Transformer)处理图像的方式类似,DiT会将潜空间的特征图切分成不重叠的Patch(图像补丁),再通过Patch Embedding(补丁嵌入)将每个Patch映射为一个Token(令牌),从而将2D的潜特征图转化为1D的Token序列,适配Transformer的输入格式。
Patch尺寸是一个关键超参数——尺寸越小,Token数量越多,模型能捕捉的细节越丰富,但计算量也会增加;尺寸越大,计算效率越高,但细节捕捉能力会下降。DiT提供了多种Patch尺寸配置(2×2、4×4、8×8),适配不同分辨率和性能需求,为可扩展性提供了基础。
3. adaLN-Zero:稳定且高效的条件注入
扩散模型的训练需要结合两个关键条件:时间步(Timestep,即噪声添加的程度)和类别标签(Class Label,用于条件生成)。DiT探索了三种条件注入方式,最终选择了创新的adaLN-Zero模块,这也是其训练稳定、性能出色的核心原因之一。
adaLN-Zero基于自适应层归一化(Adaptive Layer Norm),不仅能动态调整归一化的缩放(Scale)和偏移(Shift)参数,还引入了一个门控参数(Gate)。更巧妙的是,该模块被初始化为零,使得DiT Block在初始状态下近似为恒等映射,有效缓解了深层Transformer的训练不稳定性,让模型能够轻松堆叠更多层,实现性能的持续提升。
三、实验验证:可扩展性拉满,刷新SOTA纪录
DiT论文的核心贡献之一,就是通过大量实验,验证了纯Transformer扩散模型的可扩展性——即模型性能(以FID指标衡量)与计算量(以Gflops衡量)之间存在强相关的幂律关系:计算量越大(通过增加Transformer的深度/宽度、增加输入Token数量),FID分数越低,生成图像的质量越好。
关键实验结果
-
SOTA性能突破:最大的DiT-XL/2模型在ImageNet数据集的类条件生成任务中,超越了所有先前的扩散模型。在256×256分辨率下,实现了2.27的SOTA FID分数;在512×512分辨率下,同样表现领先,证明了纯Transformer架构的优越性。
-
计算效率优势:在同等或更低的计算量下,DiT的性能显著优于基于U-Net的扩散模型(如ADM、LDM)。例如,DiT-XL/2的计算量为118.6 Gflops,远低于ADM的1120 Gflops,但FID分数却更低,展现出极高的参数效率和计算效率。
-
可扩展性验证:实验显示,随着Transformer深度从6层增加到28层、宽度从128维增加到1024维,模型的FID分数持续下降,没有出现性能瓶颈,完美契合Scaling Laws,证明了DiT的可扩展性潜力。
注:FID(Fréchet Inception Distance)是衡量生成模型质量的黄金标准,分数越低,生成图像的真实感和多样性越好——它通过比较真实图像和生成图像的高层特征分布,避免了单纯比较像素的局限性。
四、开源实践与应用场景
为了让研究者和开发者快速上手,Facebook Research(现Meta AI)基于该论文,开源了完整的PyTorch实现,提供了预训练的类条件DiT模型、训练脚本和多种优化选项,支持256×256和512×512分辨率的图像生成,还提供了Hugging Face空间和Google Colab笔记本,降低了实践门槛。
借助其高效性和可扩展性,DiT的应用场景十分广泛,已渗透到多个领域:
-
高质量图像生成:适用于艺术创作、游戏开发、设计等领域,能生成细节丰富、真实感强的图像,甚至可支持更高分辨率的定制化生成;
-
数据增强:在机器学习任务中,生成高质量的标注数据,帮助提升模型的泛化能力,尤其适用于数据稀缺的场景;
-
图像修复与编辑:可用于修复损坏的图像、实现风格迁移,甚至完成细粒度的图像编辑任务;
-
多模态与视频生成:作为Sora等视频生成模型的核心基础,DiT的可扩展性的设计,为处理视频序列的长距离依赖提供了可能,推动了多模态生成技术的发展。
此外,开源项目还引入了梯度检查点、混合精度训练等优化技术,实现了高达95%的训练速度提升和60%的内存节省,让大规模DiT模型能在有限的硬件资源下运行。
五、总结与未来展望
《Scalable Diffusion Models with Transformers》这篇论文的价值,远不止“用Transformer替换U-Net”这一个创新——它更像是一次“范式革命”,证明了扩散模型可以摆脱对强归纳偏置架构的依赖,通过纯Transformer架构,实现“算力驱动性能提升”的可扩展特性,为生成式AI的发展提供了新的思路。
DiT的核心启示的是:在数据和算力充足的时代,“通用性”远比“针对性”更有潜力。Transformer的弱归纳偏置,看似在小数据场景下有劣势,但在大规模数据和算力的支撑下,反而能更灵活地挖掘数据规律,实现性能的无限突破。
展望未来,DiT的架构理念还将继续延伸:在图像领域,会朝着更高分辨率、更精细的条件控制方向发展;在多模态领域,将进一步融合文本、音频、视频等信息,推动通用生成模型的落地;在工程化层面,随着硬件的升级和优化技术的迭代,DiT的计算效率还将进一步提升,让大规模扩散模型走进更多实际应用场景。
对于AI研究者和开发者而言,DiT不仅是一篇值得精读的论文,更是一个极具实践价值的框架——它告诉我们,打破固有认知,将成熟的架构跨界融合,往往能带来意想不到的突破。如果你也在关注扩散模型的发展,不妨去试试DiT的开源项目,亲手体验一下纯Transformer扩散模型的强大魅力~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 11
11 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)