同样是16B大模型,为什么它只用2.8B算力?DeepSeek MoE揭秘
目录
1 MoE概述
1.1 MoE发展过程

MoE (Mixture of Experts)模型发展的关键阶段与代表性成果从上图中可以看到,MoE技术的发展大致可分为以下几个阶段:
-
萌芽期(2017–2020):基础架构探索
1)Google提出了最早的MoE结构(MoE/GShard),随后Switch Transformer推动了稀疏激活MoE的实用化; 2)Facebook (Meta) 推出M2M-100多语言翻译模型,为MoE在NLP领域落地打下基础; 3)出现了早期的V-MoE、Meta-MoE、CPM-2-MoE等创新实践。 -
体系化发展(2021–2022):多家巨头展开布局
1) 微软、Meta、Google等公司陆续推出DeepSpeed-MoE、AdaMix、ST-MoE、LIMoE、Expert-Choice MoE等; 2) MoE开始扩展到多模态任务(如LIMoE、MoA),并进入视觉与推荐领域(如Swin-MoE、PLE)。 -
爆发期(2023–2024):千模竞发,性能突破
1)MoE模型从学术探索走向工业级部署,多个SOTA成果涌现 2)Mixtral-8x7B、Mixtral-8x22B(Mistral) 3)LLaMA-MoE、LLaMA-MoE-v2(Meta) 4)DeepSeekMoE,DeepSeek-v2, DeepSeek-v3(DeepSeek) 5) Qwen1.5-MoE-A2.7B, Qwen2.5-MoE(阿里) 6) WizardLM-2-8×22B、JetMoE(清华) 7) OpenMoE、MoLE、MoD、DS-MoE 等来自不同机构的新探索
MoE模型全面迈入参数规模百亿至千亿级别,在推理效率与效果平衡上具备突出优势,特别适合边缘部署和大模型压缩。从图谱的演进路径可以看出,MoE技术正在成为通用大模型的重要架构选择之一。无论是多模态集成、个性化推荐、语言理解,还是AI Agent系统,MoE都展示出极高的适应性和扩展潜力。未来,随着动态专家选择、路由策略优化以及硬件友好型稀疏计算的进一步进展,MoE有望在AI生产力应用中扮演核心角色。
我们可以看几个经典MoE模型:
Mixtral-8x22B:2024年火出圈的MoE代表作,性能媲美GPT-4;
DeepSeekMoE:来自国内团队的性能突破,后面DeepSeek-V2以及DeepSeek-V3都使用了MoE框架
LLaMA-MoE-v2:Meta开源代表,引爆社区使用热潮。
1.2 什么是MoE
大模型基本都是基于 Transformer 架构, MoE(Mixture of Experts)并不在于改变 Transformer 的整体结构,而是在 Transformer 中某些子模块上引入了“稀疏激活”的机制。
以标准 Transformer 为例,每个 Block 通常包含两个主要子模块:
- Multi-Head Attention 子层
- Feed-Forward Network (FFN) 子层
其中:
Transformer Block:
→ LayerNorm
→ Multi-Head Attention
→ Add & Norm
→ Feed-Forward Network (FFN)
→ Add & Norm
MoE 是在 FFN 子层的位置引入多个 Experts 并稀疏激活其中的少数几个,而不是使用单一 Dense FFN。那什么是MoE?
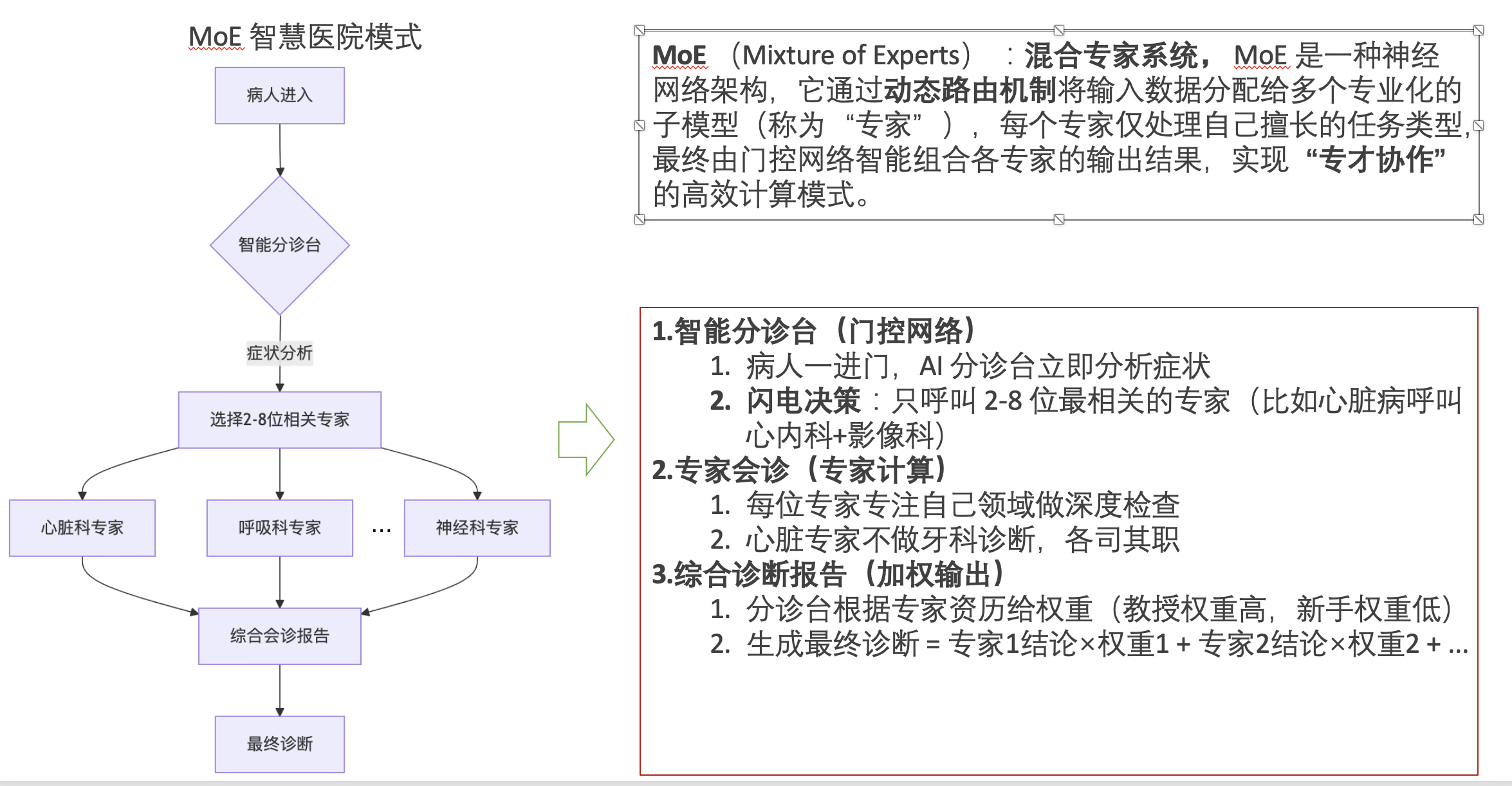
2 MoE原理
2.1 MoE结构
下面对标准 Transformer 与 MoE-Transformer 的结构差异进行对比分析: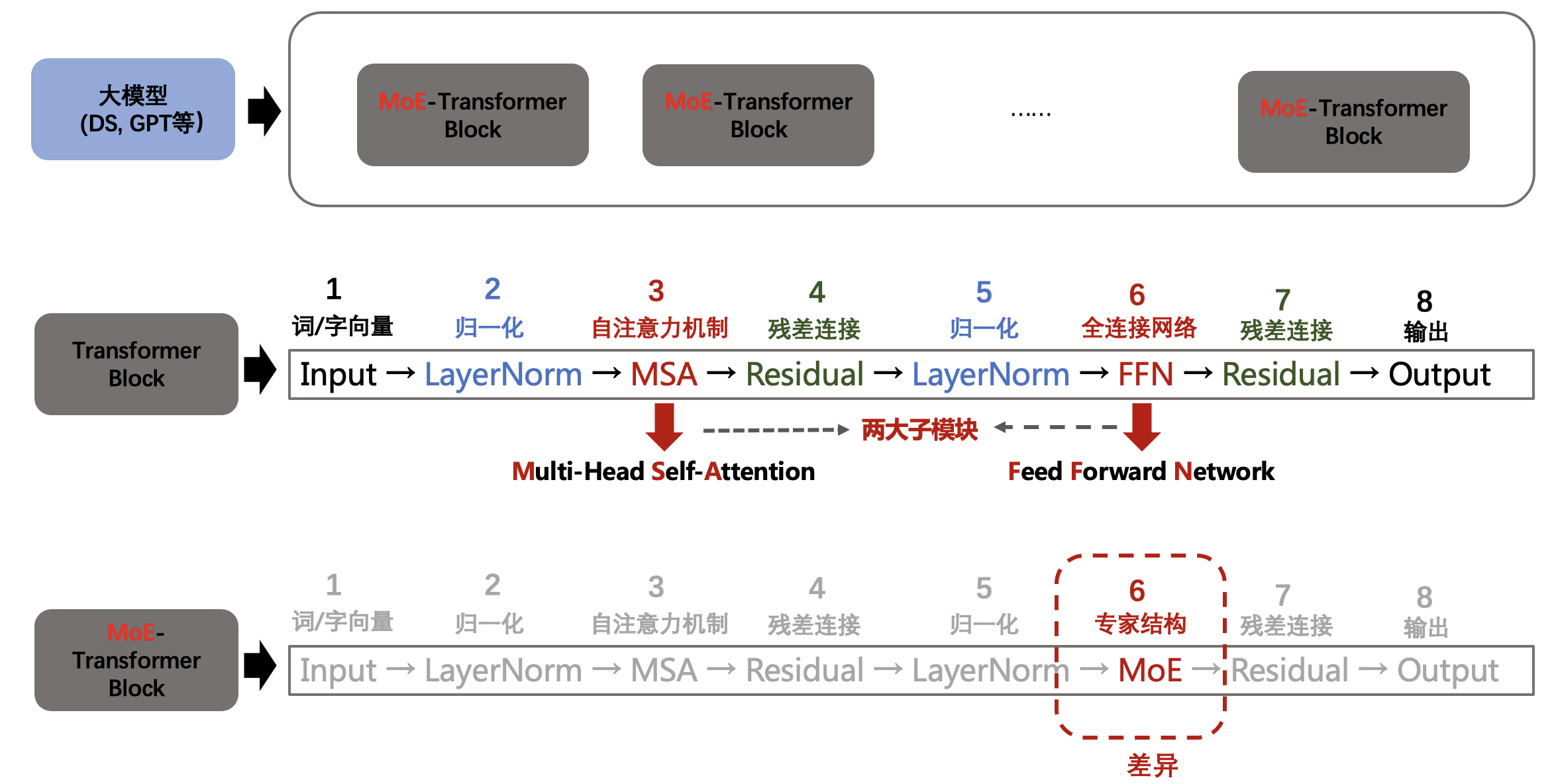
MoE 的代码实现其实并不复杂,本质上可以看作是对 FFN 结构的扩展: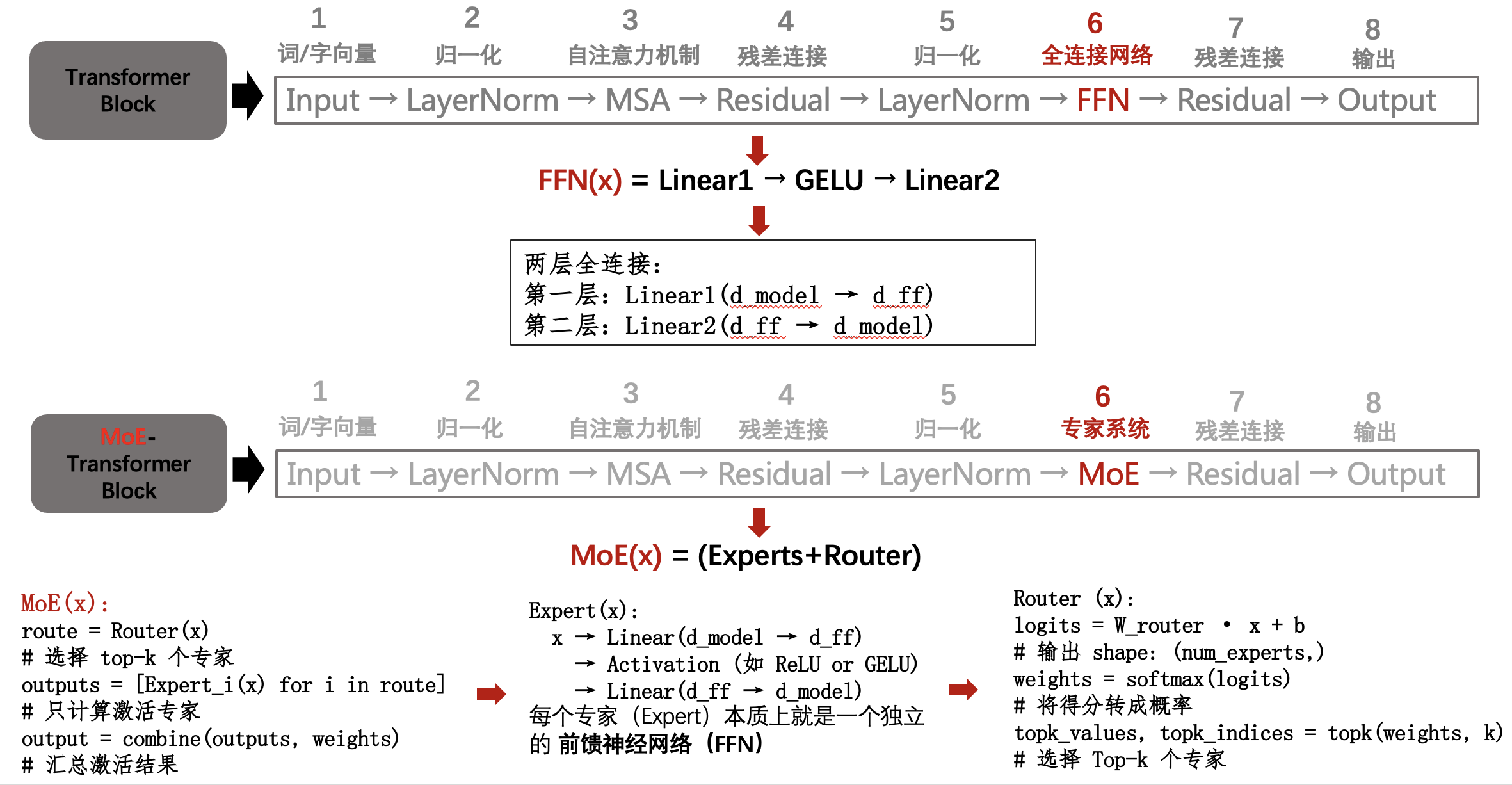
2.2 MoE FFN与Dense FFN对比
MoE 的计算流程如下: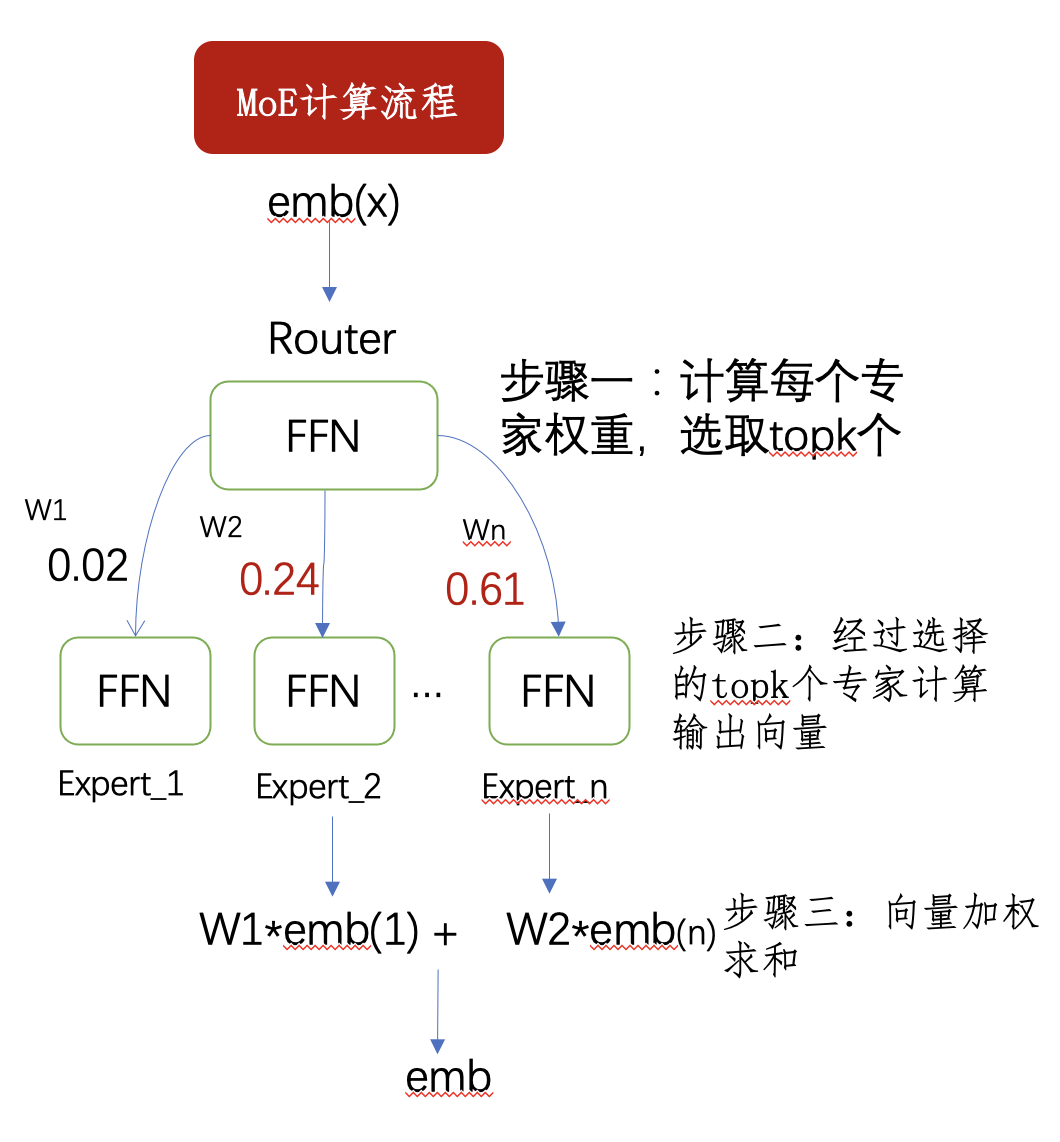
MoE 的主要优势如下: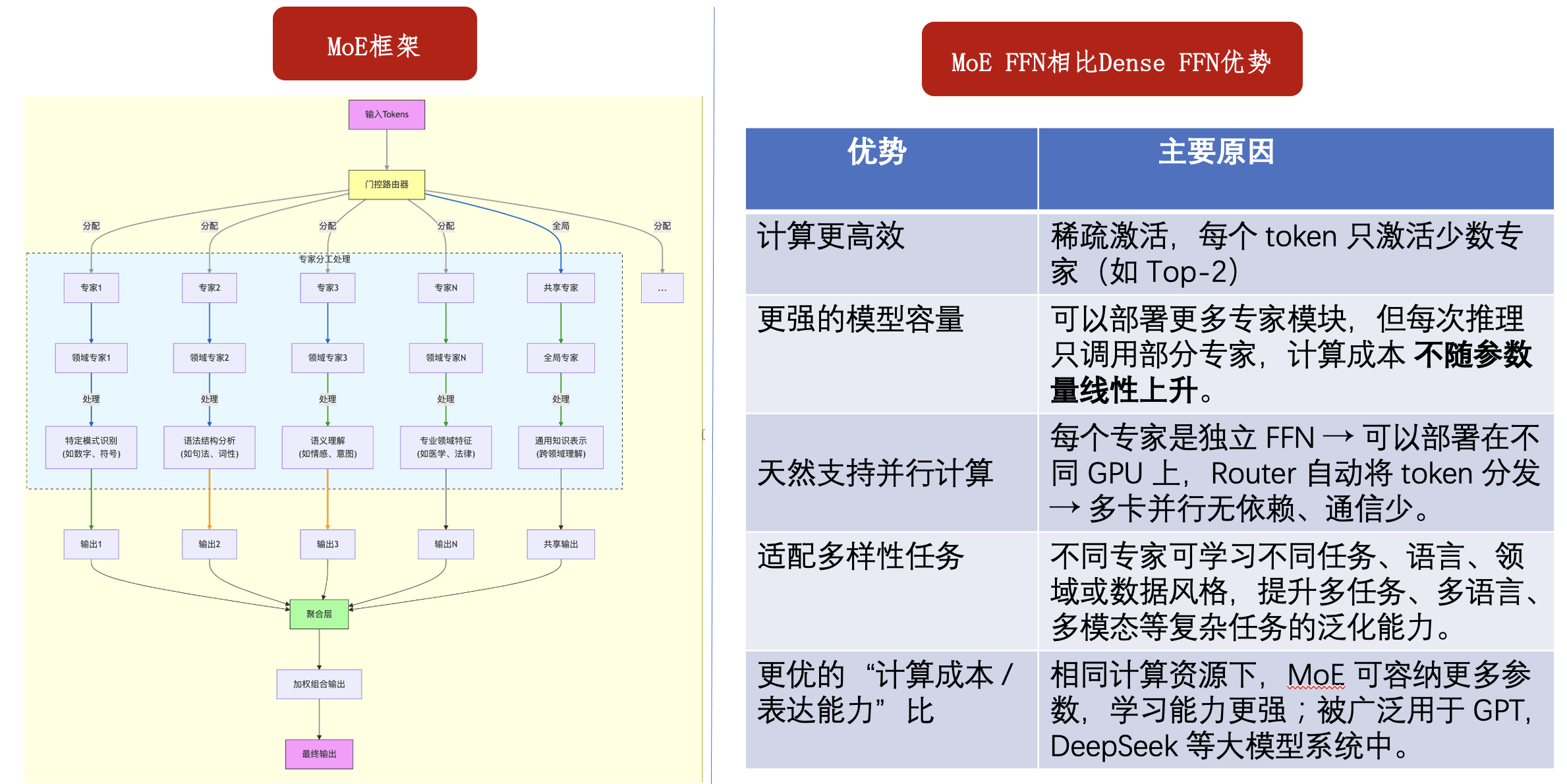
3 DeepSeek中的MoE实现
3.1 16B大模型参数具体怎么计算
我们以 DeepSeek-MoE 16B 为例,大家有没有想过这个“16B”到底是怎么计算出来的?下面我手动带你一步步算清楚:
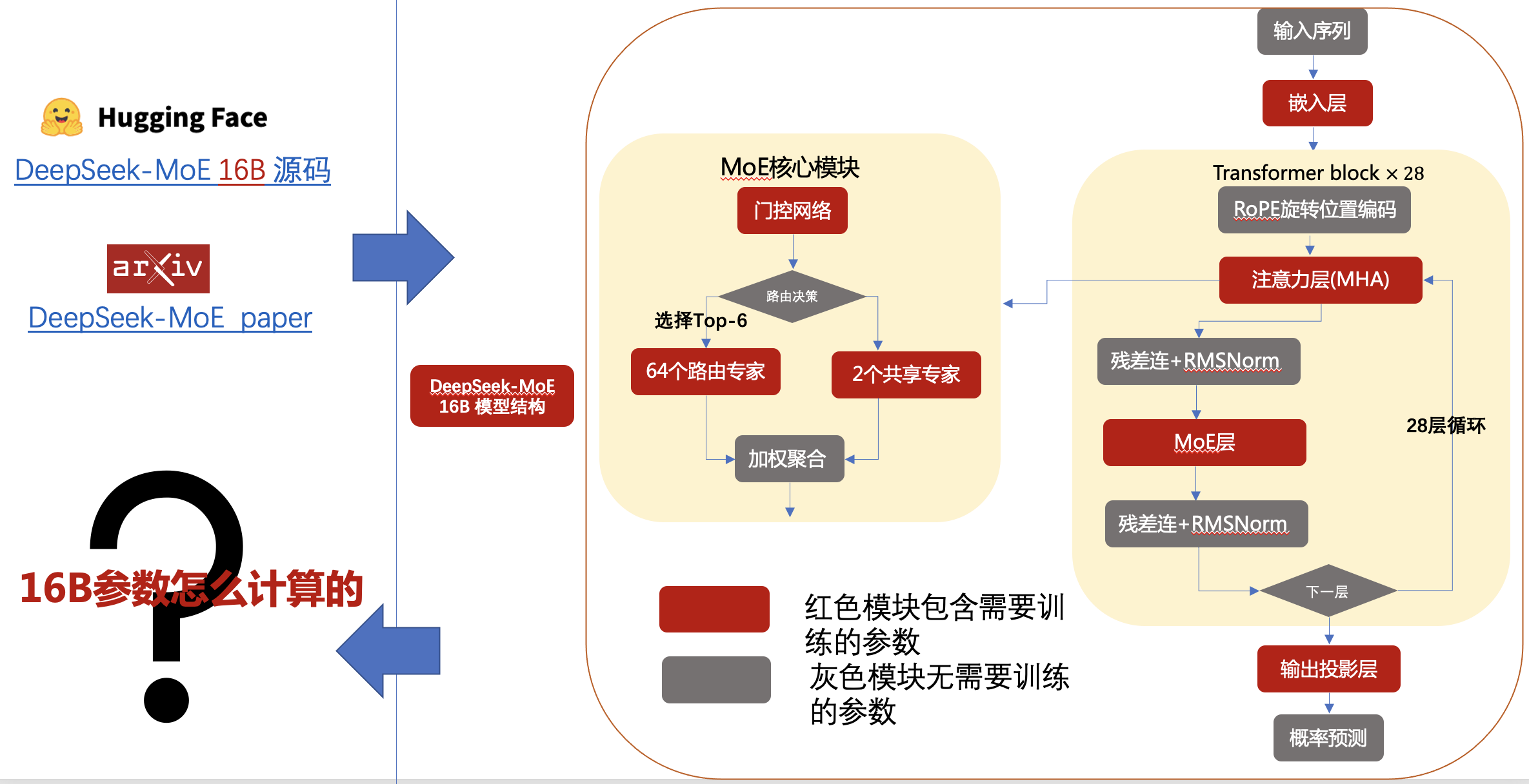
下面开始手动计算各个模块的具体参数量,仔细看:
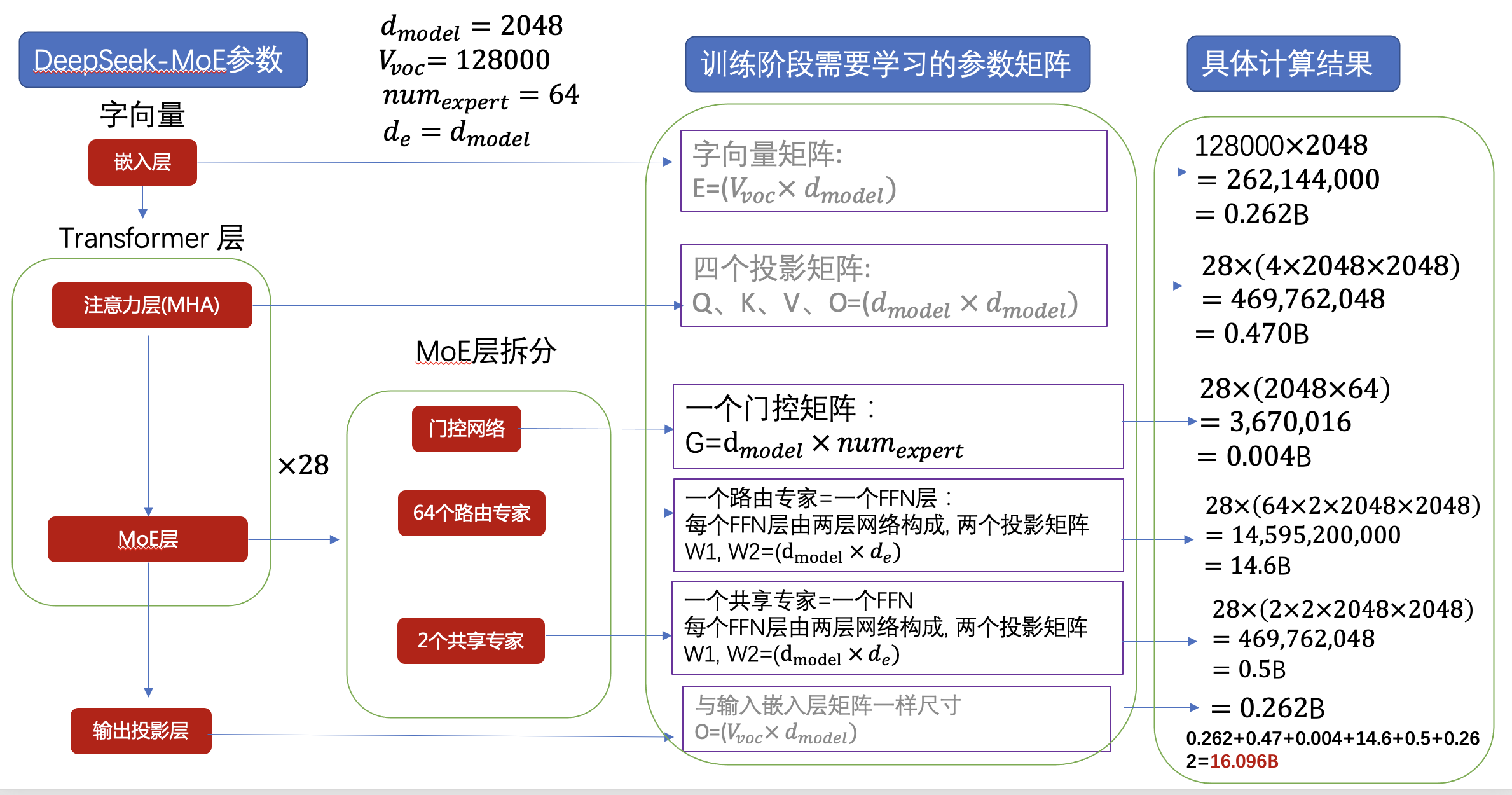
具体计算过程如下,我们一步一步来解析:
模型矩阵参数
-
字向量矩阵(Embedding)
E = ( V v o c × d m o d e l ) E=(V_{voc} \times d_{model}) E=(Vvoc×dmodel)
规模:
128000 × 2048 = 262 , 144 , 000 ≈ 0.262 B 128000 \times 2048 = 262,144,000 \approx 0.262B 128000×2048=262,144,000≈0.262B -
四个投影矩阵(Attention)
Q , K , V , O = ( d m o d e l × d m o d e l ) Q,K,V,O = (d_{model} \times d_{model}) Q,K,V,O=(dmodel×dmodel)
规模:
28 × ( 4 × 2048 × 2048 ) = 469 , 762 , 04 ≈ 0.470 B 28 \times (4 \times 2048 \times 2048) = 469,762,04 \approx 0.470B 28×(4×2048×2048)=469,762,04≈0.470B -
门控矩阵(Gate)
G = d m o d e l × n u m e x p e r t G = d_{model} \times num_{expert} G=dmodel×numexpert
规模:
KaTeX parse error: Undefined control sequence: \appro at position 40: …4) = 3,670,016 \̲a̲p̲p̲r̲o̲ ̲0.004B -
路由专家(MoE Expert)
W t 1 , W t 2 = ( d m o d e l × d e ) W_{t1}, W_{t2} = (d_{model} \times d_e) Wt1,Wt2=(dmodel×de)
规模:
KaTeX parse error: Undefined control sequence: \appro at position 69: …14,595,200,000 \̲a̲p̲p̲r̲o̲ ̲14.6B -
共享专家(Shared Expert)
一个共享专家等于一个 FFN 层:
W s 1 , W s 2 = ( d m o d e l × d e ) W_{s1}, W_{s2} = (d_{model} \times d_e) Ws1,Ws2=(dmodel×de)
规模:
28 × ( 2 × ( 2 × 2048 × 2048 ) ) = 469 , 762 , 048 ≈ 0.5 B 28 \times (2 \times (2 \times 2048 \times 2048)) = 469,762,048 \approx 0.5B 28×(2×(2×2048×2048))=469,762,048≈0.5B -
输出层(Output Embedding)
O = ( V v o c × d m o d e l ) O=(V_{voc} \times d_{model}) O=(Vvoc×dmodel)
规模:
≈ 0.262 B \approx 0.262B ≈0.262B -
总参数量(16B)
0.262 + 0.470 + 0.004 + 14.6 + 0.5 + 0.262 = 16.098 B ≈ 16 B 0.262+0.470+0.004+14.6+0.5+0.262=16.098B \approx 16B 0.262+0.470+0.004+14.6+0.5+0.262=16.098B≈16B
也就是说,这个模型的 16B 参数就是通过上述方式逐项计算得到的。掌握这种方法后,只要给出模型结构和相关配置,你就可以快速估算出模型的整体规模。这些参数都是训练阶段需要参与优化的。
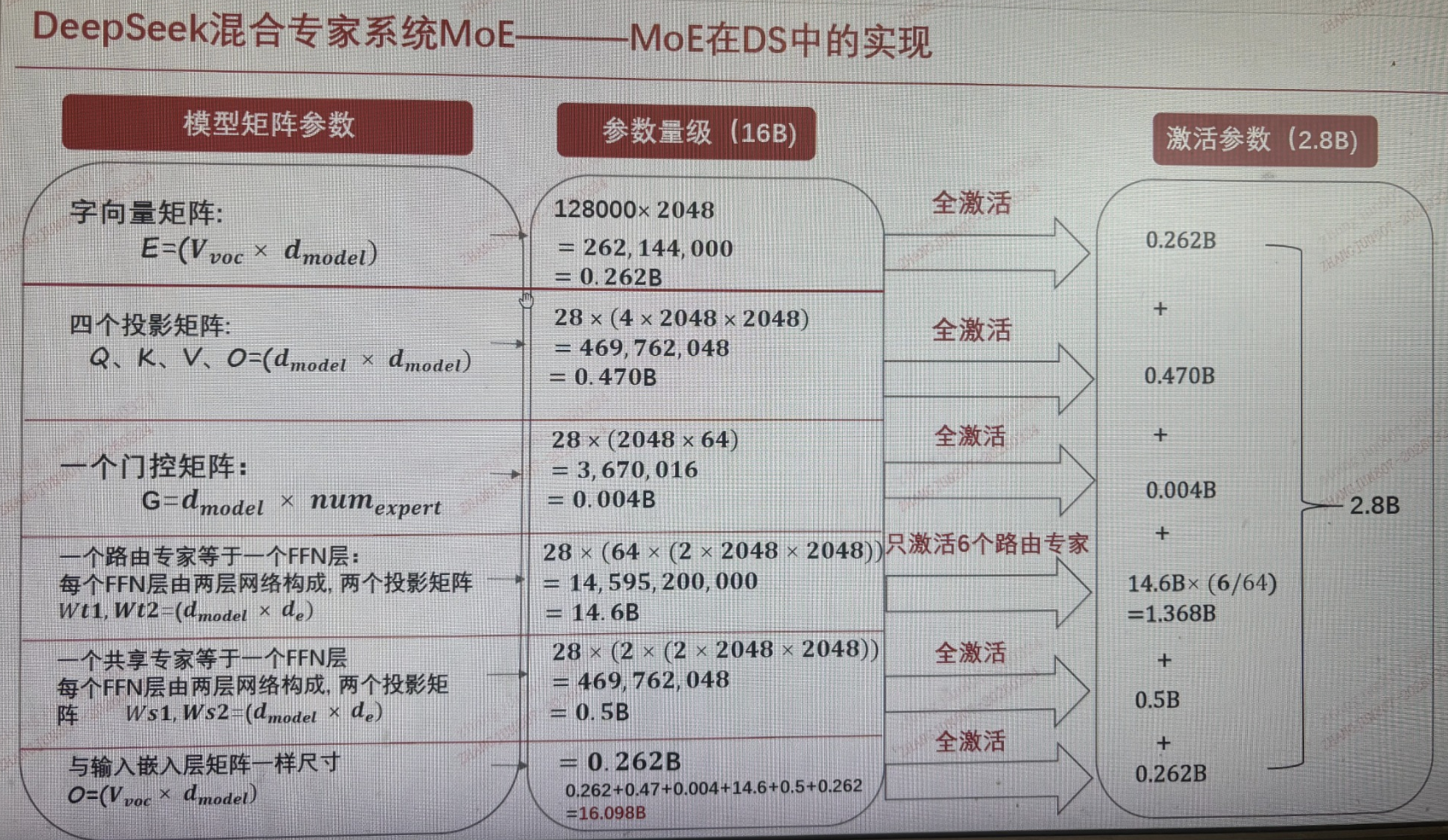
那么问题来了:推理时真的会用到全部 16B 参数吗?其实并不会,接下来我们来看一下推理阶段实际激活的参数量,约为 2.8B:
3.2 MoE在DS中的代码实现
MoE实现源码参考 MoE 实现源码(HuggingFace 提供的 modeling_deepseek.py),可以从代码层面对 MoE 的具体实现过程进行梳理:
- 路由决策
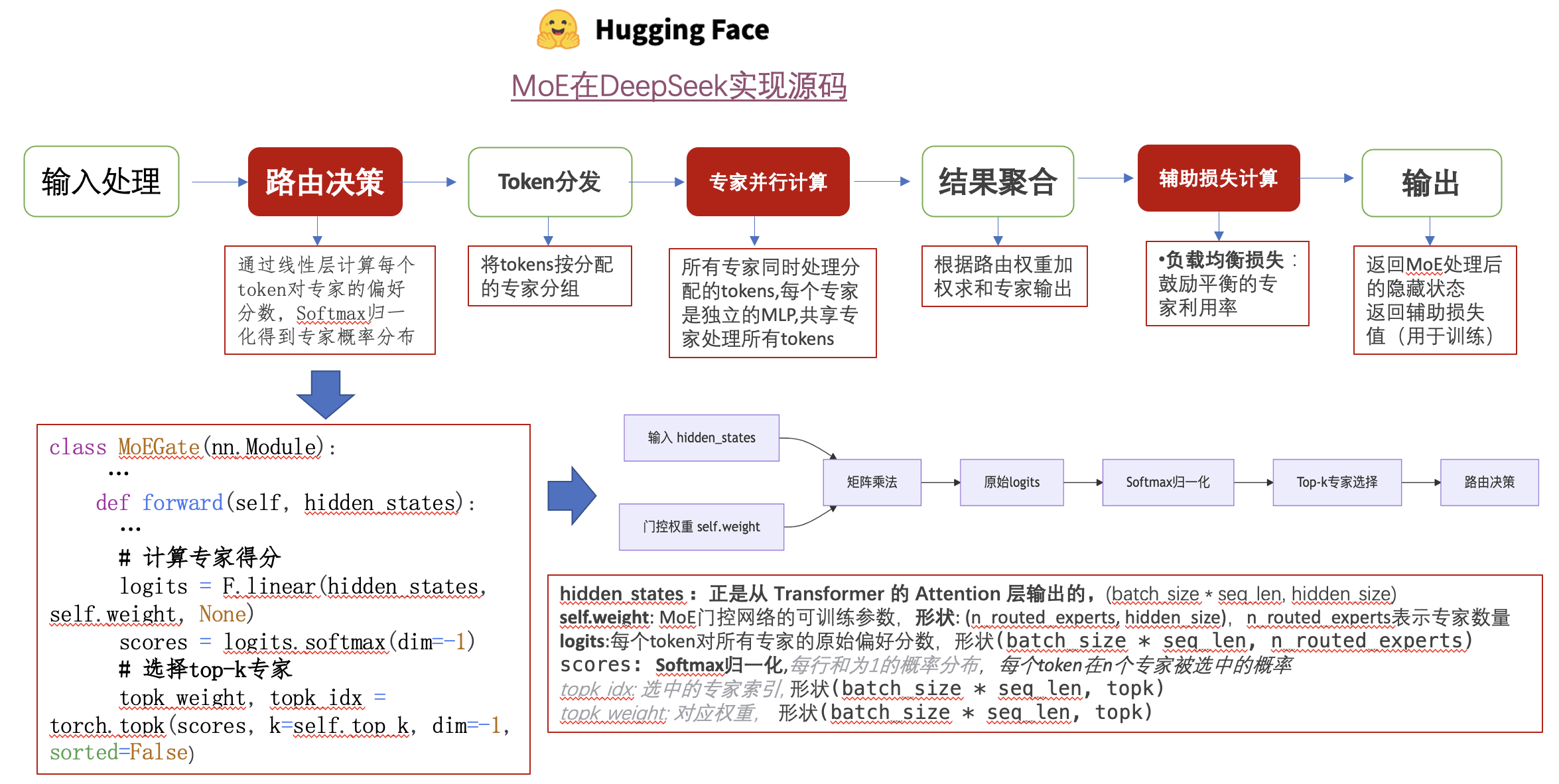
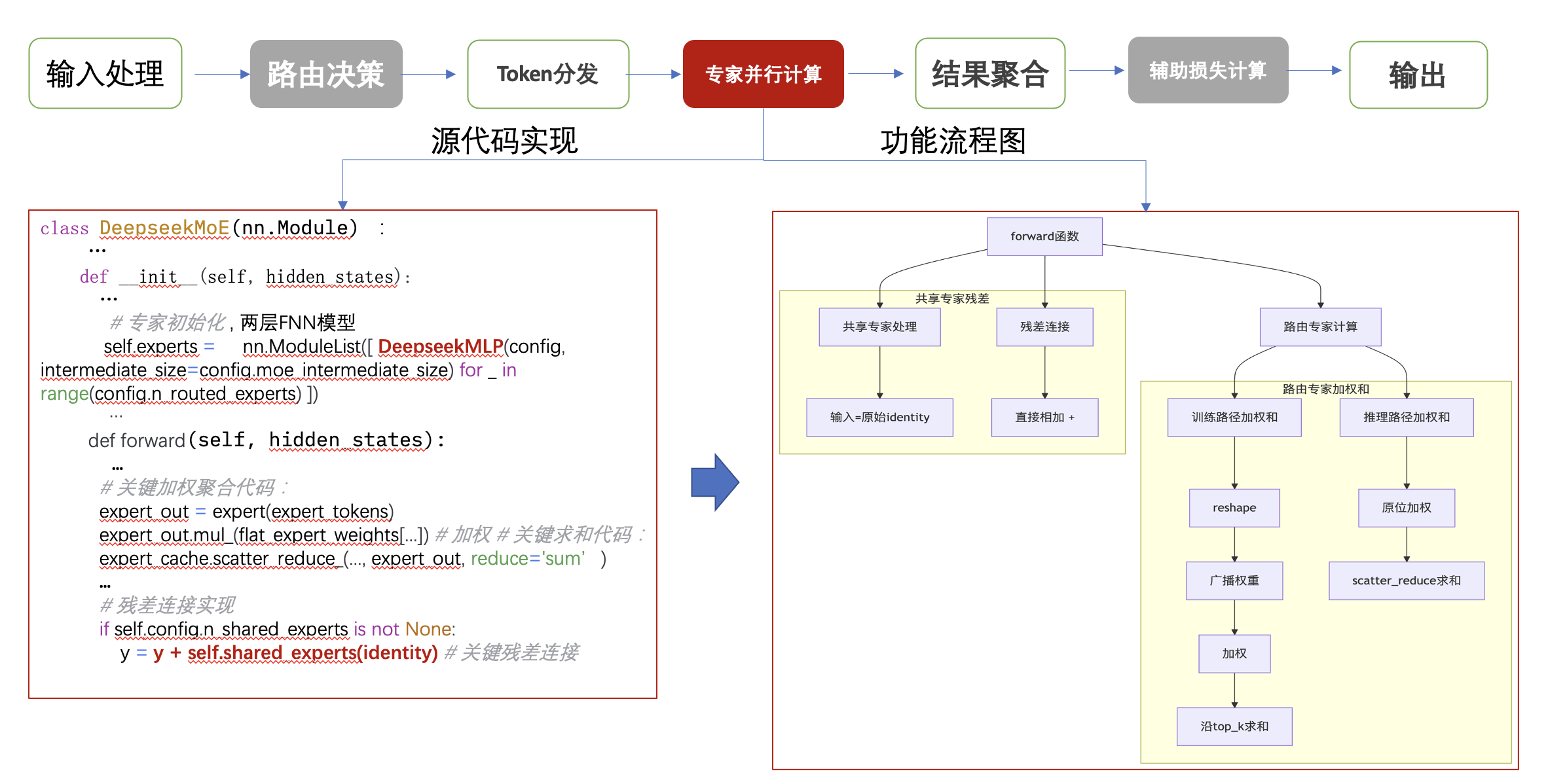
- 专家并行计算
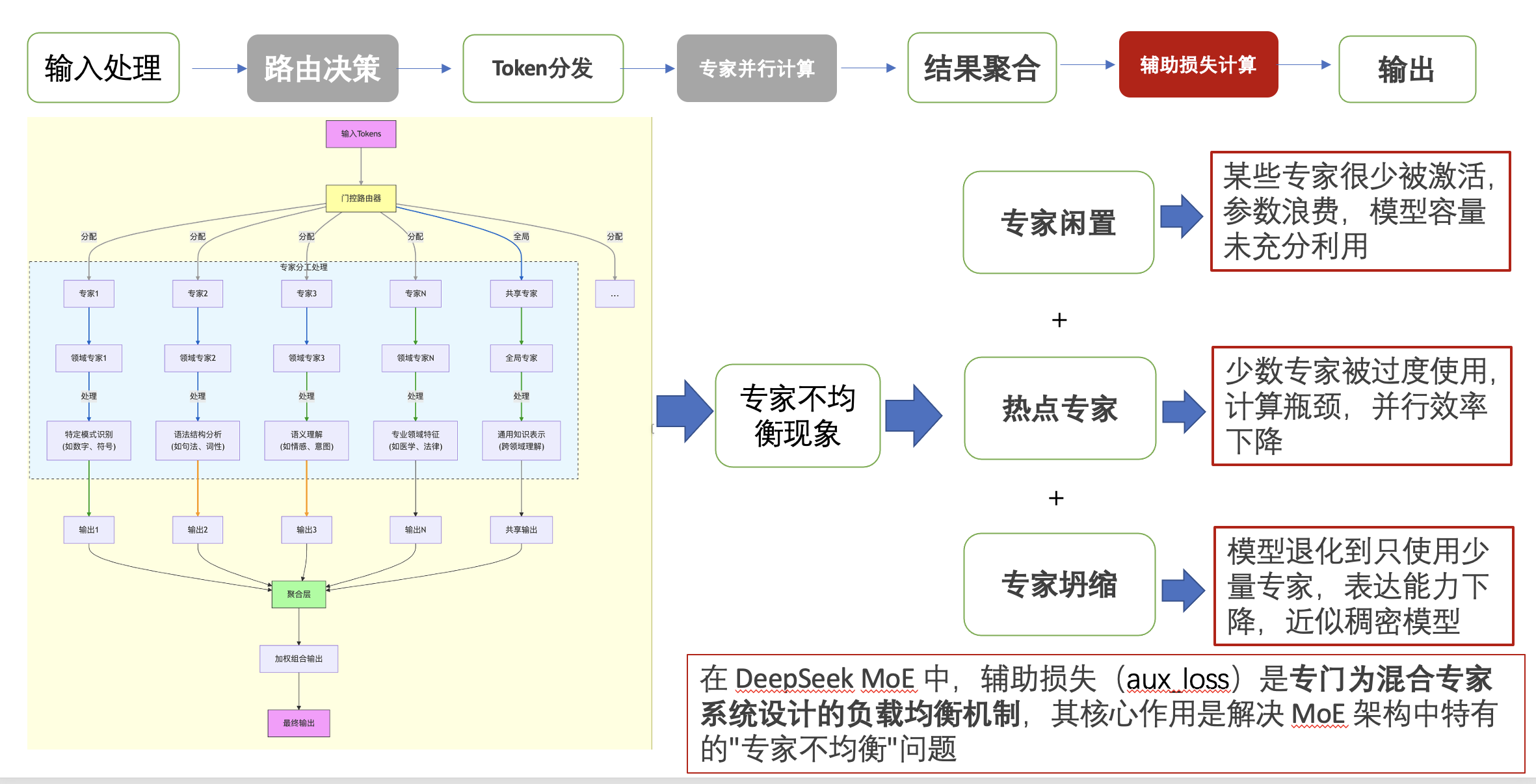
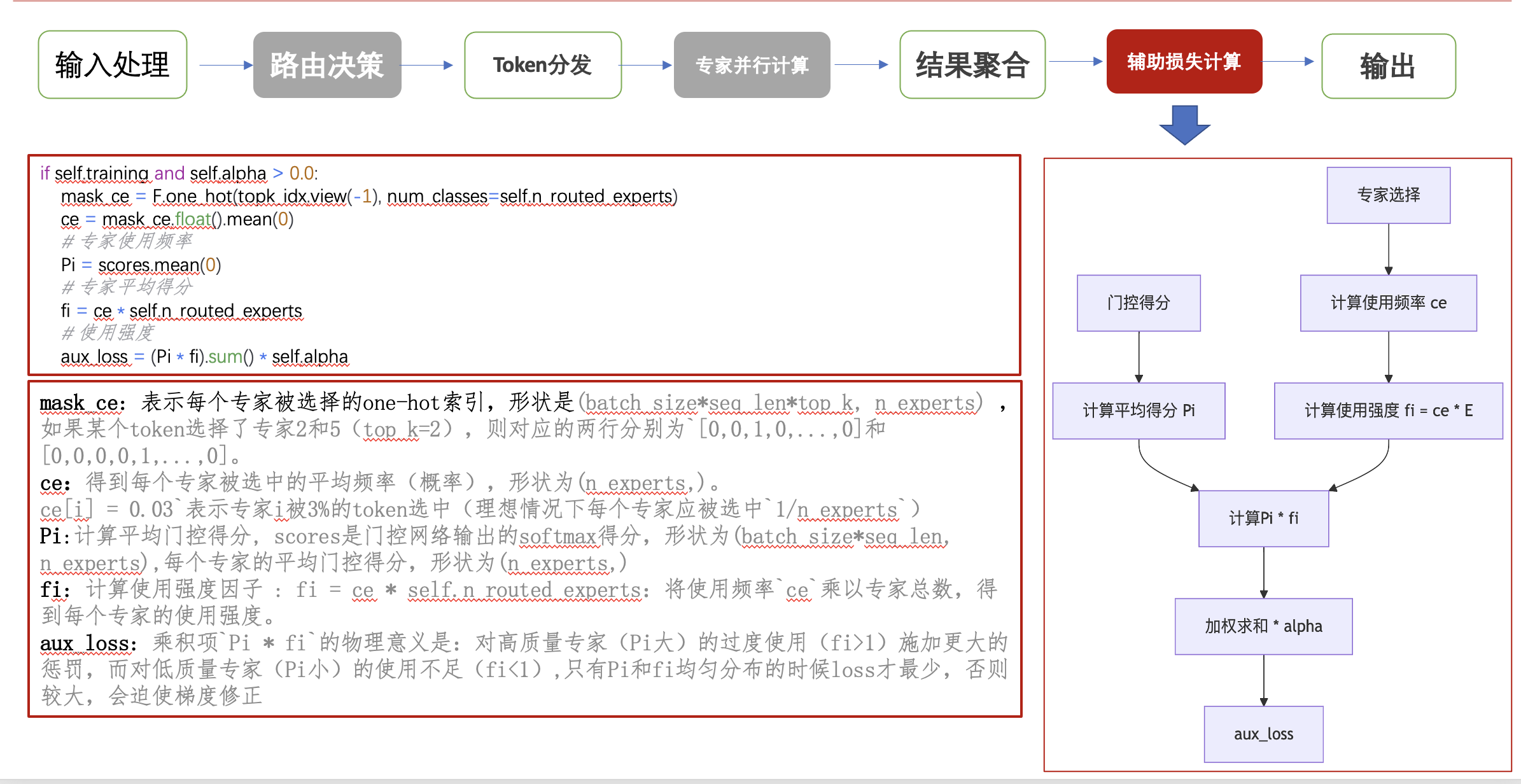
- 辅助损失计算
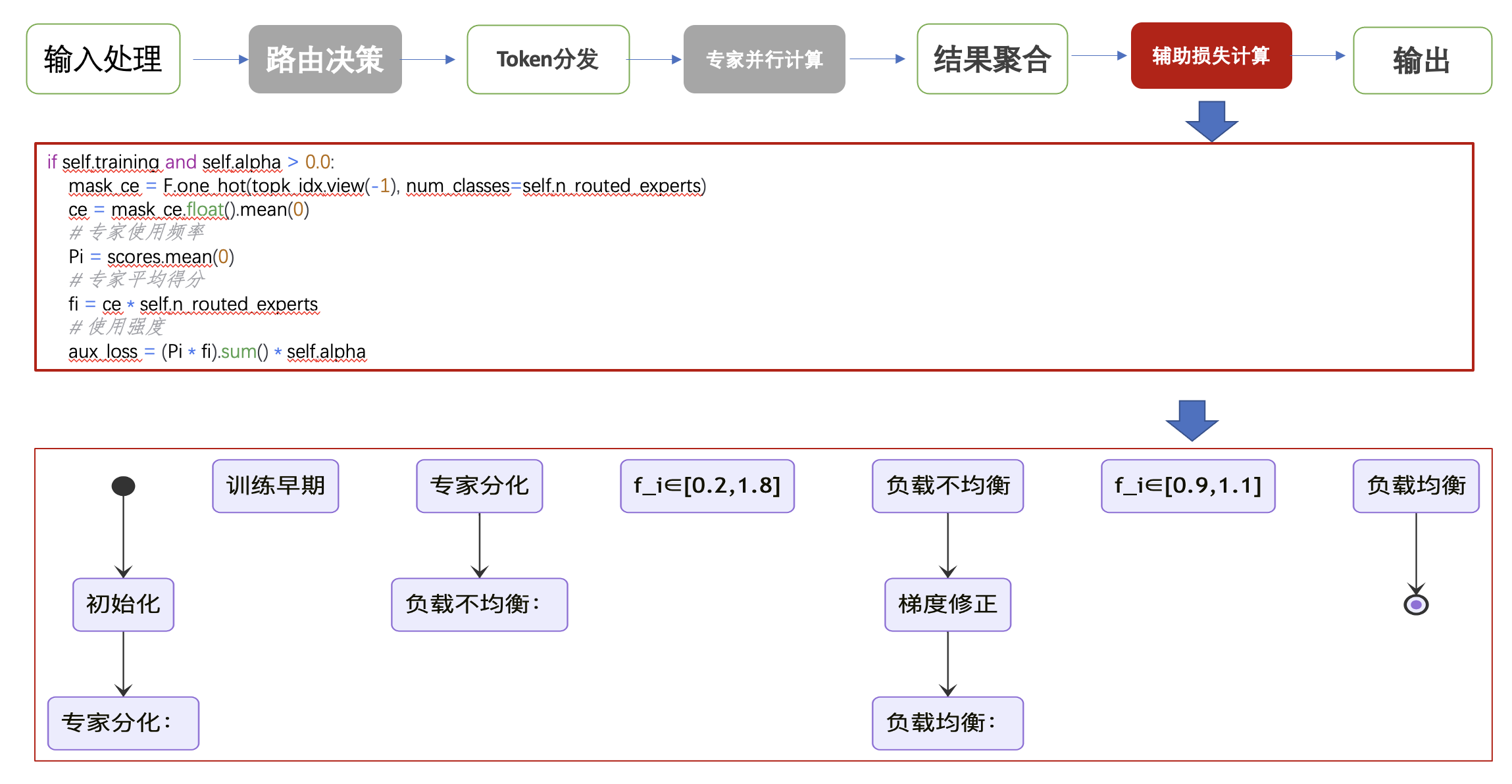
4 总结
MoE(Mixture of Experts)的核心在于通过“稀疏激活”机制,将原本需要全部参与计算的 Dense 模型,转变为每次只激活少量专家,从而在显著提升模型参数规模(能力)的同时,控制计算成本(效率)。以 DeepSeek-MoE 16B 为例,总参数达到 16B,但推理时仅激活约 2.8B 参数,本质上实现了“用更少的计算,获得更强的模型表达能力”,这也是当前大模型从“单一大模型”走向“专家协同架构”的关键方向。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)