AI 终端一键修复在线业务故障(以OpenClaw为例)
以及如何转化一次事故为可复用的 DevOps 工作流
对于 DevOps 工程师来说,有一种故障比普通的崩溃更令人头疼。
不是系统崩溃——那在意料之中。而是系统以一种切断了你赖以调试的接口的方式失效。
这正是我们在升级 OpenClaw 时遇到的情况。
前一秒,一切正常。智能体通过聊天软件正常响应。下一秒,它彻底沉默了。没有回复,聊天界面中没有日志,也没有备用通道。它不仅仅是宕机了——它是无法访问。
在那一刻,没有任何巧妙的变通方案。你只能回归基础:登录机器,找出哪里出了问题。

严格设计背后的脆弱性
OpenClaw 的核心是严格的配置验证。启动时,网关(Gateway)会根据其架构(schema)检查整个 openclaw.json 文件,如果有任何不匹配,服务将直接拒绝运行。
从系统设计的角度来看,这是一个明智的选择。它可以防止未定义的行为,保持运行时的可预测性。但这也带来了一个尖锐的问题:单个不兼容的字段就可能导致整个系统离线。
在这种情况下,错误信息非常清晰
must NOT have additional properties(不得包含额外属性)
系统并没有表现出不可预测的行为——它只是在强制执行正确性。问题在于,某个进程写入了一個系统不再接受的配置。
触发故障的变更
这次故障发生在内存系统升级期间。
默认情况下,OpenClaw 使用基于 Markdown 文件和本地向量搜索(SQLite + sqlite-vec)的分层记忆体系。这种方式简单透明,但有局限性。系统可以检索知识,但无法真正从交互中学习。经验被重复记录,且缺乏跨过往任务的反思机制。
|
层级记忆 |
内容 |
加载方式 |
|
热记忆 (Hot Memory) |
核心文件,如 SOUL.md 和 MEMORY.md |
每次会话全量加载 |
|
温记忆 (Warm Memory) |
今天和昨天的日记条目 |
每日加载 |
|
冷记忆 (Cold Memory) |
历史日记条目 |
按需向量检索 |
为了解决这个问题,我们引入了基于 Amazon Bedrock AgentCore Memory 的托管内存层。这使得对话可以被捕获为结构化事件,从中提取、去重并随时间精炼出长期知识。
最终的架构是一种混合模式:热记忆(Markdown 文件,每次全量加载)+ 冷记忆(AgentCore Memory,按需语义检索)的双层架构
问题出在哪里
集成本身是通过 OpenClaw 的插件系统完成的,无需修改核心框架。消息被拦截,相关记忆被注入,对话被持久化。
问题出现在启用插件时。
openclaw.json 的更新是由智能体自己处理的,它拥有修改自身配置的权限。这种灵活性很有用,但也引入了风险。
在更新过程中,添加了一个不兼容的字段。当下一次网关启动时,它验证了配置,拒绝了它,然后退出。
从那一刻起,系统实际上被锁死了:
- 网关已宕机
- 消息集成已离线
- 智能体无法访问
没有办法让系统自我修复。
回到终端——但带有辅助
由于智能体离线,恢复工作必须直接在运行于亚马逊云科技 (AWS) 的实例上进行。
这时,Chaterm 成为了工作流的一部分。Chaterm 是一个专为基础设施和云资源管理打造的 AI 原生终端。它允许工程师使用自然语言执行复杂的操作任务,如部署、故障排除和修复。
它的行为像一个标准终端,但拥有一个可选的智能体模式 (Agent Mode),可以观察环境、建议下一步操作,并帮助构建调试过程。
目标很简单:恢复 OpenClaw 网关。
我们不再手动决定每一步,而是让故障排除作为一个引导序列展开——依然透明、依然由命令驱动,但更易于遵循,且在压力下不那么依赖对每个细节的记忆。
Chaterm核心能力

实战指南:使用 Chaterm 智能体模式修复 OpenClaw
1. 连接至 EC2
首先,通过 Chaterm 连接到部署了 OpenClaw 的 EC2 实例。
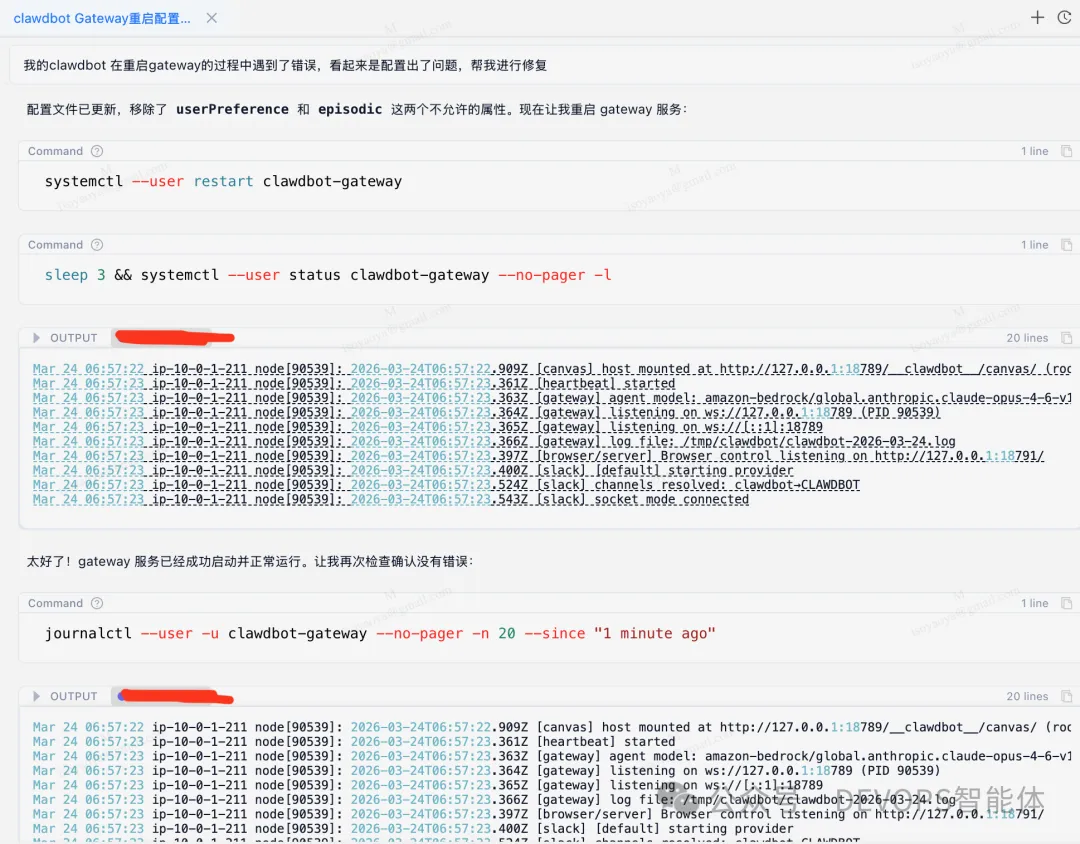
作为初步步骤,尝试重启网关服务。
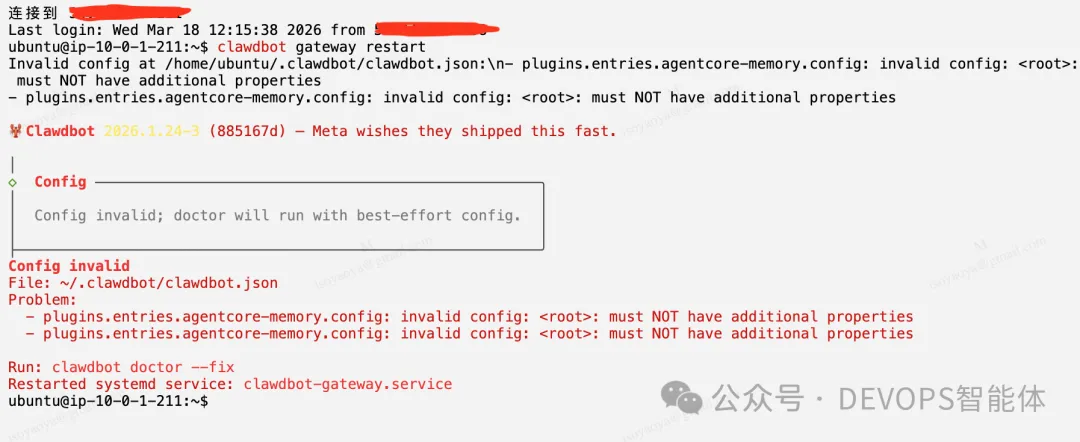
重启失败,返回配置验证错误。这是预期的——问题源于 OpenClaw 在修改配置文件进行内存升级时引入了不兼容的属性。
2. 启动智能体模式
在 Chaterm 中切换到智能体模式,并明确定义目标:
“修复 OpenClaw 网关中的配置验证错误,并恢复服务正常运行。”
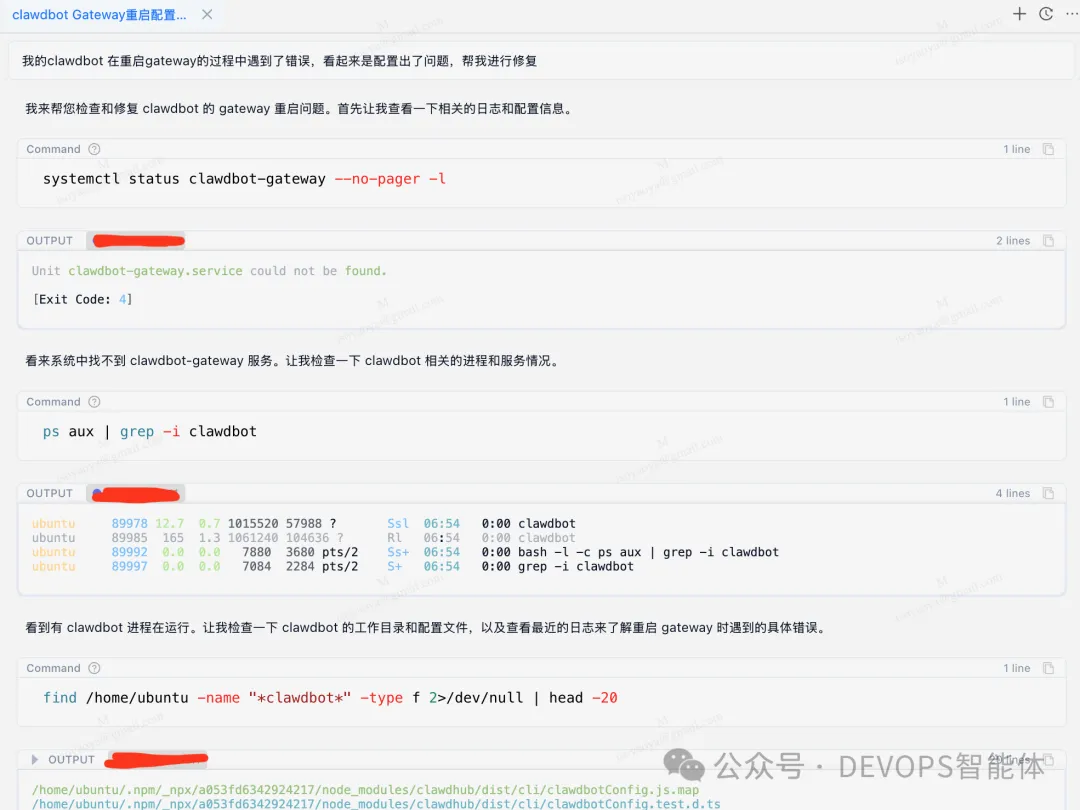
一旦启动,Chaterm 智能体将自主规划并执行诊断和修复工作流。
3. 诊断与修复过程
智能体自动完成以下步骤:
① 诊断阶段
- 检查 systemd 用户级服务的状态,确认服务处于失败状态。
- 分析服务日志以识别具体错误:“Additional properties are not allowed”(不允许额外属性)。
- 检查配置文件,找出导致验证失败的不兼容属性。
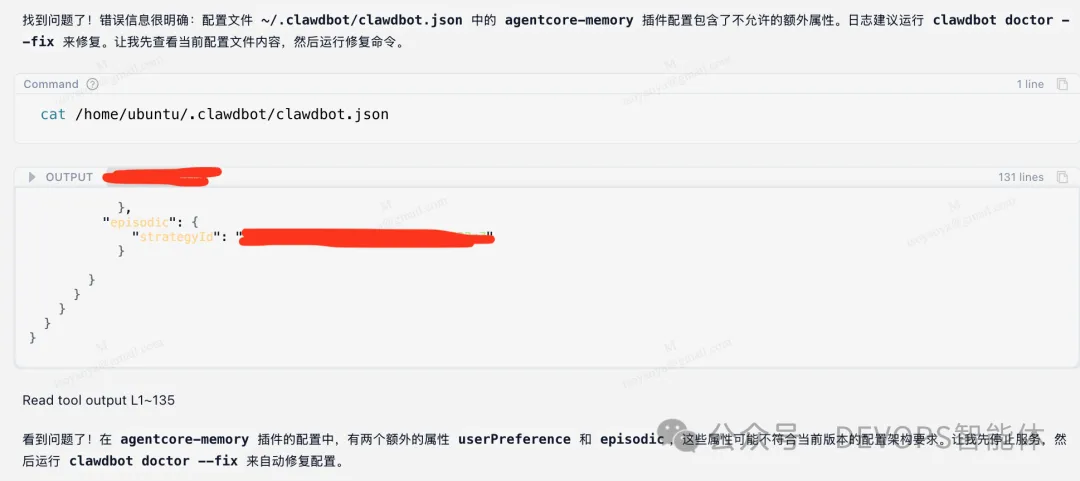
② 修复阶段
- 安全地停止服务。
- 备份当前配置文件(确保具备回滚能力)。
- 尝试使用 clawdbot doctor --fix 进行自动修复。
- 如果自动修复不完整,则在智能体辅助下手动编辑配置文件,移除不兼容的属性。
- 重启网关服务。
③ 验证阶段
- 通过检查以下指标确认系统已完全恢复:服务状态为 active (running)。
- 网关正确监听端口 18789。
- 所有插件已成功初始化。
- 外部集成(如 Slack)正常运行。
4. 修复完成
OpenClaw 现已恢复正常运行,能够通过消息平台无缝交互。
在整个过程中,Chaterm 智能体维护了所有操作的完整审计日志,确保了完全的可追溯性。此外,修复前的配置备份提供了可靠的回滚路径,以防修复失败——从而使整个恢复过程既安全又可复现。
从故障排除到可复用资产
技术修复本身很简单。更有趣的是之后发生的事情。
在许多团队中,流程到此结束。问题解决了,知识却留在某人的脑海里——或者最多只是部分文档化。下次发生类似问题时,同样的调查过程又得重来一遍。
在这次事件中,整个故障排除会话被捕获并转化为 Chaterm 中的一个可复用单元——即所谓的 智能体技能 (Agent Skill)。我们不再编写描述“该做什么”的文档,而是让工作流本身变得可执行。
该工作流涵盖了完整的生命周期:
- 如何识别故障
- 如何安全地修复它
- 如何验证系统是否真正健康
传统方法与智能体技能对比
|
传统方法 |
智能体技能 (Agent Skill) |
|
手动编写调试文档 |
一键自动生成 |
|
下次需逐步跟随文档操作 |
直接执行工作流 |
|
高度依赖个人经验 |
易于在团队内共享,新手也能上手 |
|
步骤可能被跳过或不完整 |
结构化、可重复且完整的工作流 |
下次再发生配置验证错误时,可以直接应用相同的序列,无需凭记忆重新构建。
这如何改变团队的运作方式
这就是影响变得切实可见的地方。
一旦故障排除过程被捕获为智能体技能,它就不再是个人的经验,而变成了共享的能力。新团队成员无需事先熟悉 OpenClaw 就能解决问题——他们可以遵循相同的结构化工作流,达到相同的结果。
随着时间的推移,这也引入了一种标准化形式。每次执行都遵循相同的步骤:修改前备份、尝试自动修复、验证结果。跳过关键步骤的风险(这在事故处理中经常发生)显著降低。
也许更重要的是,它改变了知识积累的方式。系统不再捕捉那些可能过时或被忽视的静态文档,而是捕捉可以直接复用的工作流。每一次事故都为团队的运营工具箱增添了具体的内容。
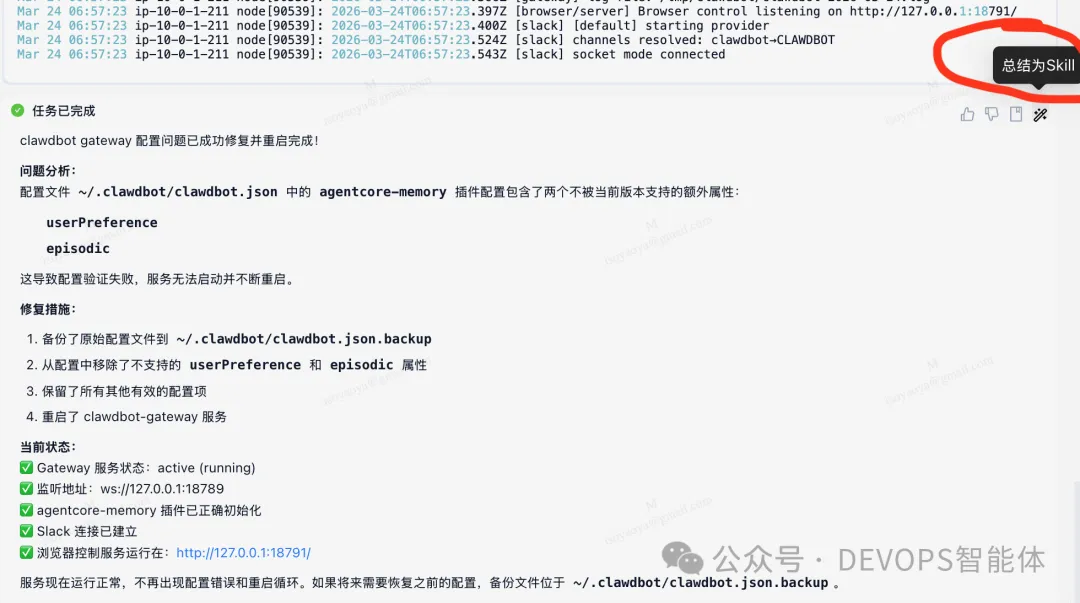
Chaterm 有效地分析故障排除会话,并将其提炼为结构化的、可复用的技能。

结语
像 OpenClaw 这样的系统正变得越来越自主,而随着这种自主性而来的是新的故障类别,包括系统自我配置错误的能力。
当问题出现时,恢复过程仍然依赖于熟悉的工具:日志、配置文件和仔细的迭代。正在改变的是修复之后的事情。
如果每次事故都能转化为可复用的资产——不仅捕捉故障,还捕捉解决方案——那么调试就不再是一种重复的成本。
它将成为持续改进循环的一部分,让系统和围绕它的团队随着时间推移稳步变得更好。
相关链接:
Chaterm官网:https://chaterm.ai/
Github仓库:https://github.com/chaterm/chaterm
Skills 示例:https://github.com/chaterm/terminal-skills
Bedrock AgentCore:https://docs.aws.amazon.com/bedrock-agentcore/

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)