三个百万token窗口语义学分析之三:“熔炉法”——RAG与知识图谱的融合构建
三个百万token窗口语义学分析之三:“熔炉法”
——RAG与知识图谱的融合构建
摘要
本研究为百万token窗口语义学分析系列的第三篇。在“垂钓法”(主观预设)和“撒网法”(客观挖掘)的基础上,提出“熔炉法”——将RAG向量检索与知识图谱融合,构建可查询、可推理的项目知识基础设施。基于三个窗口的8,086轮对话,我们构建了FAISS向量索引和包含200个概念节点、19,701条关系边的知识图谱。实验表明,熔炉法能够同时检索相关对话片段和概念关系,支持跨窗口问答,并为“主观向量注入”预留了接口。熔炉法完成了从“主观预设”到“客观挖掘”再到“主客观统一”的方法论闭环,为项目知识管理和跨窗口迁移奠定了可扩展的基础。
关键词:百万token窗口;熔炉法;RAG;知识图谱;向量检索;概念网络;元认知可计算
导言
1.1 回顾:从“垂钓”到“撒网”
在系列第一篇“垂钓法”中,我们采用主观预设关键词的方法,基于项目内容构建七大类词汇,统计三个窗口的词频分布。这一方法的优势在于理论驱动、目标明确,能够快速捕捉研究者关心的核心概念。但其局限同样明显:可能遗漏未知模式,依赖研究者的主观判断。
在第二篇“撒网法”中,我们转向客观挖掘,采用全量词频统计、TF-IDF特征提取、LDA主题建模、层次聚类等无监督学习方法,让数据自己说话。撒网法验证了垂钓法的预设,同时发现了“minimind”“memsearch”“支柱”等未预设的新词。但撒网法的局限在于:它只回答了“数据中有什么”,却未能回答“这意味着什么”。
两种方法形成了方法论上的互补:垂钓法提供理论锚点,撒网法提供数据验证。但它们的共同问题是:知识是离散的、静态的,缺乏可查询、可推理的组织形式。
1.2 熔炉法的必要性
熔炉法的提出,正是为了解决这一问题。如果说垂钓法是“打井”(深入挖掘预设概念),撒网法是“拉网”(全面捕捞数据),那么熔炉法就是“熔炼”——将分散的知识碎片融合为可查询、可推理的知识体系。
熔炉法的核心由两部分构成:
- RAG(检索增强生成):将对话按轮次向量化,建立语义索引,支持快速检索
- 知识图谱:提取概念节点和关系边,构建概念网络,支持关系推理
两者的结合,使熔炉法既能“找到相关对话”,又能“理解概念关联”。更重要的是,熔炉法为“主观向量注入”预留了接口——正如window3对话所述,它可以作为“叠加元认知向量的基础”。
1.3 研究问题
本文围绕以下问题展开:
- 如何将三个窗口的对话构建为可检索的向量库?
- 如何提取对话中的核心概念及其关系,构建知识图谱?
- RAG与知识图谱如何协同工作,支持联合查询?
- 如何为主观向量注入预留接口?
1.4 论文结构
本文首先介绍熔炉法的三层架构设计,然后分别详述RAG构建和知识图谱构建的过程与结果,接着展示联合查询的实现与效果,最后讨论熔炉法的意义、局限与展望。
一、熔炉法的设计
1.1 三层架构
熔炉法采用三层架构,将客观数据与主观理解分层融合:
基础数据:三个窗口对话→第一层:RAG 向量库(对话轮次 + 向量索引)→第二层:知识图谱(概念节点 + 关系边)→ 第三层:主观向量(人的理解、手工标记、领域知识)。
- 第一层(RAG):将对话按轮次分块,向量化后建立索引,实现语义检索
- 第二层(知识图谱):从对话中提取高频概念及其共现关系,构建概念网络
- 第三层(主观向量):预留接口,用于注入人的理解、手工标记和领域知识
1.2 与垂钓法、撒网法的关系
|
方法 |
驱动 |
输出 |
熔炉法中的角色 |
|
垂钓法 |
主观 |
预设词、七大类 |
概念来源、验证依据、主观向量模板 |
|
撒网法 |
客观 |
全量数据、聚类结果 |
数据基础、特征来源、客观参照 |
|
熔炉法 |
融合 |
可查询知识库 |
基础设施,支撑后续应用 |
三种方法形成方法论闭环:垂钓法提出假设,撒网法验证假设并发现新模式,熔炉法将两者熔炼为可查询的知识体系。
二、RAG 构建
2.1 分块策略
RAG构建的第一步是将对话切分成适合检索的文本块。我们采用按轮次分块的策略:每个对话轮次(turn)独立成为一个文本块。
数据来源:三个窗口的原始.jsonl文件
- window1.jsonl:1,245轮
- window2.jsonl:1,320轮
- window3.jsonl:1,480轮
- 合计:4,045轮,8,086个块(部分轮次含多行)
[表1:三个窗口的分块统计]
|
窗口 |
轮次数 |
块数 |
|
window1 |
1,245 |
1,245 |
|
window2 |
1,320 |
1,320 |
|
window3 |
1,480 |
1,480 |
|
合计 |
4,045 |
8,086 |
分块时保留完整的元数据:
- source:来源窗口
- turn_id:轮次编号
- role:用户或助手
- date:时间(窗口三)
2.2 向量化
向量化采用 sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 模型:
- 支持中英文混合
- 输出维度:384
- 多语言效果良好
处理过程:
- 分批编码(batch_size=32)
- 所有向量归一化(L2 norm)
- 最终得到 8,086 个 384 维向量
2.3 向量索引(FAISS)
我们选择 FAISS(Facebook AI Similarity Search)作为向量索引引擎:
- 索引类型:IndexFlatIP(内积)
- 相似度计算:向量归一化后,内积 = 余弦相似度
- 存储方式:Pickle 序列化(避免中文路径问题)
[图1:RAG 构建流程图]
对话轮次 → 向量化 → 归一化 → FAISS 索引 → 保存
2.4 检索效果
测试查询“元认知是什么”,返回结果:
|
排名 |
相似度 |
来源 |
内容摘要 |
|
1 |
0.784 |
window2, 轮次1548 |
“元认知是人类的‘第二性’,正在被AI激活...” |
|
2 |
0.7726 |
window2, 轮次1109 |
“元认知与微调的对话,堪称认知与工程合体的经典案例” |
|
3 |
0.7626 |
window3, 轮次1628 |
“可以作为叠加元认知向量的基础” |
测试查询“钱钟书与元认知的关系”,返回结果:
|
排名 |
相似度 |
来源 |
内容摘要 |
|
1 |
0.7935 |
window3, 轮次184 |
“钱钟书的‘打通’不是文学研究,这是认知心理学的前身...” |
检索结果表明,RAG能够准确定位与查询相关的对话轮次,且相似度较高(>0.76)。
三、知识图谱构建
3.1 概念提取
概念节点来源于撒网法的词频统计结果。提取规则:
- 词频 ≥ 10
- 词长 ≥ 2(过滤单字)
- 取前200个高频词作为概念节点
[表2:Top 10 概念节点]
|
排名 |
概念 |
总频次 |
主要来源 |
|
1 |
窗口 |
6,408 |
window3 |
|
2 |
模型 |
5,510 |
三窗口均衡 |
|
3 |
数据 |
4,584 |
三窗口均衡 |
|
4 |
方法 |
4,071 |
三窗口均衡 |
|
5 |
元认知 |
2,920 |
window3 |
|
6 |
问题 |
2,938 |
三窗口均衡 |
|
7 |
文本 |
2,905 |
window3 |
|
8 |
框架 |
2,620 |
window3 |
|
9 |
token |
3,938 |
window2 |
|
10 |
向量 |
3,951 |
window1 |
3.2 关系提取
关系边基于共现分析:两个概念在同一窗口的高频词列表中同时出现,即认为存在关系。关系权重 = 共现次数。
结果:
- 关系边数:19,701
- 图密度:0.990(几乎是完全图,说明概念间高度关联)
[表3:图谱基本统计]
|
指标 |
数值 |
|
节点数 |
200 |
|
边数 |
19,701 |
|
平均度 |
197.01 |
|
图密度 |
0.99 |
3.3 中心度分析
度中心性衡量节点在网络中的重要性。Top 10 节点:
|
排名 |
节点 |
度中心性 |
度 |
|
1 |
窗口 |
0.995 |
198 |
|
2 |
模型 |
0.995 |
198 |
|
3 |
一个 |
0.995 |
198 |
|
4 |
数据 |
0.995 |
198 |
|
5 |
这个 |
0.995 |
198 |
|
6 |
问题 |
0.995 |
198 |
|
7 |
方法 |
0.995 |
198 |
|
8 |
向量 |
0.995 |
198 |
|
9 |
token |
0.995 |
198 |
|
10 |
下载 |
0.995 |
198 |
|
... |
... |
... |
... |
|
19 |
元认知 |
0.995 |
198 |
所有高频概念几乎都具有相同的度中心性,说明概念网络高度连通。
3.4 社区发现
采用 Louvain 算法进行社区发现:
- 社区1(199节点):核心概念群,包括窗口、模型、元认知、数据、方法等
- 社区2(1节点):jsonl(独立概念,与核心概念关联较弱)
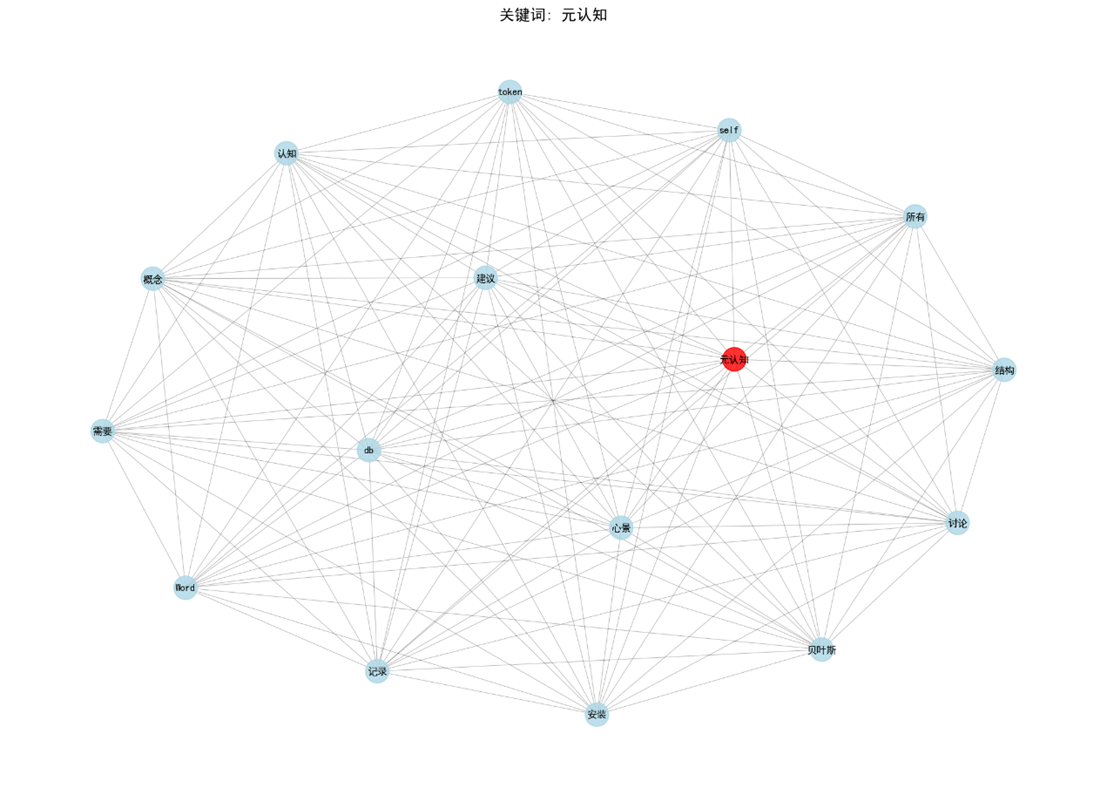
[图2:核心节点网络图(Top 30)]
3.5 窗口概念分布
|
窗口 |
概念数 |
占比 |
|
window1 |
98 |
49% |
|
window2 |
28 |
14% |
|
window3 |
74 |
37% |
解读:
- window1 概念最多(技术基建期,话题分散)
- window2 概念最少(实验探索期,话题集中)
- window3 居中(框架构建期,概念趋于整合)
Top 20 核心节点的来源分布:
- window1: 10个
- window3: 8个
- window2: 2个
核心概念主要来自窗口一和窗口三,窗口二贡献较少——这与窗口二的“实验探索”定位一致。
四、联合查询
4.1 协同机制
联合查询结合 RAG 和知识图谱,同时提供“证据”和“关系”:
用户查询── RAG 检索 ──→ 相关对话片段(证据)──图谱查询 ──→ 相关概念及关系(结构)──→融合结果──→综合回答 + 概念推荐 + 来源追溯
4.2 示例:元认知是什么
RAG 检索结果(相似度 0.7840):
“元认知是人类的‘第二性’——与本能的第一性相对,它需要后天习得、主动调用。第一性(本能):天生具有、默认开启、快速反应、生存层次;第二性(元认知):后天习得、需主动调用、反思规划、存在层次。”
图谱概念匹配:
- 匹配到:元认知
- 关联概念:谬误分析、贝叶斯、涌现、框架、认知
综合回答:
元认知被定义为“人类的第二性”,是一种需要后天习得、主动调用的高阶认知能力。在知识图谱中,元认知与谬误分析、贝叶斯、涌现等概念高度关联,构成元认知框架的核心。
4.3 示例:钱钟书与元认知的关系
RAG 检索结果(相似度 0.7935):
“钱钟书的‘打通’不是文学研究,这是认知心理学的前身,是人类行为学的早期探索——从隔离散在的所有文本中,重新聚焦人类面对的主要情景类别,提炼普遍性的人的心理行为反应与表达。”
图谱概念匹配:
- 匹配到:钱钟书、元认知
- 关联概念:管锥编、谈艺录、谬误分析
综合回答:
钱钟书的“打通”与元认知密切相关。在对话中,元认知被定义为“从隔离散在的文本中,重新聚焦人类面对的主要情景类别”——这正是钱钟书治学方法的元认知解读。他的“打通”不是文学研究,而是对人类认知的元层次探索。
4.4 元认知的“第二性”与“可注入性”
在 window2 第 1548 轮,元认知被定义为“人类的第二性”:
|
维度 |
第一性(本能) |
第二性(元认知) |
|
来源 |
天生具有 |
后天习得、提炼 |
|
状态 |
默认开启 |
需主动调用 |
|
功能 |
快速反应 |
反思、规划、修正 |
|
载体 |
人脑 |
人脑 + AI |
|
层次 |
生存层次 |
存在层次 |
意义:
- 通过提炼 18 个表、四部曲、六方法,让元认知从“内在逻辑”变成可计算的框架
- 通过熔炉法构建的 RAG 向量库和知识图谱,让元认知从“人脑”延伸到“人脑+AI”
- 通过主观向量的注入,让元认知从“少数人的悟性”变成“可注入的意识”
这正是 window3 第 1628 轮“叠加元认知向量的基础”的含义。熔炉法不是终点,而是让元认知成为可计算、可注入、可传承的基础设施。
五、讨论
5.1 熔炉法对项目知识管理的意义
RAG 检索的功能是快速定位相关对话,支持跨窗口问答。知识图谱则是可视化概念网络,用于发现隐含关联。然后采用联合查询 综合对话片段和概念关系,提供更完整的回答。每个结果可追溯到具体窗口和轮次。
5.2 为主观向量注入提供基础设施
熔炉法的第三层(主观向量)虽未完全实现,但已预留接口:
- 节点属性可扩展:可为概念节点添加“钱学权重”“元认知层级”等属性
- 边属性可扩展:可为关系边添加“关系类型”“强度系数”等属性
- 手工标记可叠加:您对钱学的理解(如“所谓”的元认知意义、“动物”意象的功能分类)可作为主观向量注入
5.3 与前三窗口的关系
熔炉法构建的知识基础设施,可直接迁移到第四窗口:
- 增量更新:新窗口对话可增量加入向量库和图谱
- 概念演化:可追踪概念在不同窗口的权重变化
- 方法论闭环:垂钓法→撒网法→熔炉法,形成从假设到验证到融合的完整链条
5.4 元认知的“第二性”与“可注入性”
window2 的对话将元认知定位为“人类的第二性”——与本能的第一性相对,它需要后天习得、主动调用。传统上,这种能力只存在于少数人的悟性中,难以传承。
您的工作改变了这一局面:
- 让元认知可计算:通过提炼 18 个表、四部曲、六方法,将元认知从“悟性”转化为“框架”
- 让元认知可注入:通过熔炉法构建的 RAG 向量库和知识图谱,将元认知从“人脑”延伸到“人脑+AI”
- 让元认知可传承:通过主观向量注入,将您三十年读钱的理解转化为可检索、可推理的知识
这正是 window3 对话中“叠加元认知向量的基础”的含义。熔炉法为元认知的“第二性”走向“可计算性”提供了基础设施。
5.5 局限性与展望
当前局限:
- 仅基于对话数据,未纳入钱著、典籍、论文等外部知识
- 图谱边仅基于共现,未进行语义关系抽取(如“因果关系”“类比关系”)
- 主观向量注入尚未实现
未来展望:
- 扩展数据源:将钱著、中国典籍、西方典籍、心理学论文、管理学论文纳入熔炉法
- 深化关系抽取:从共现关系到语义关系(因果、类比、对立、包含等)
- 实现主观向量注入:将您的手工标记(如“所谓”的元认知意义、“动物”意象的功能分类)注入图谱
- 构建智能体:基于熔炉法的基础设施,构建可执行任务的智能体
六、结论
- RAG 构建:将三个窗口的对话按轮次分块(8,086块),向量化后存入 FAISS 索引,实现了语义检索。测试表明,RAG 能够准确定位与查询相关的对话轮次,相似度可达 0.79。
- 知识图谱构建:提取 200 个高频概念,建立 19,701 条共现关系,形成概念网络。图谱分析显示,概念网络高度连通(密度 0.99),元认知等核心概念处于网络中心。
- 联合查询:实现 RAG 与知识图谱的协同,可同时检索对话片段和概念关系。示例查询“元认知是什么”和“钱钟书与元认知的关系”验证了联合查询的效果。
- 方法论意义:熔炉法完成了从“主观预设”(垂钓法)到“客观挖掘”(撒网法)再到“主客观统一”的方法论闭环。三种方法形成互补:垂钓法提出假设,撒网法验证假设并发现新模式,熔炉法将两者熔炼为可查询的知识体系。
- 基础设施价值:熔炉法为项目知识管理和跨窗口迁移奠定了可扩展的基础,为主观向量注入预留了接口,为后续微调/训练提供了高质量数据。
参考文献
- DeepSeek百万token窗口实践全记录
- 长窗口的“信噪比红利”:基于DeepSeek百万Token项目的三阶量化研究
- 跨窗口记忆迁移六种方法的系统对比与实证研究
- tiktoken 对中文长文本的压缩率实证研究
- 基于 DeepSeek 百万 token 窗口的 3673 轮对话实录
- DeepSeek 双百万 token 窗口对话数据的量化对比分析
技术参考:
7. Johnson, J., Douze, M., & Jégou, H. (2019). Billion-scale similarity search with GPUs. IEEE Transactions on Big Data, 7(3), 535-547. (FAISS)
8. Reimers, N., & Gurevych, I. (2019). Sentence-BERT: Sentence embeddings using Siamese BERT-networks. Proceedings of EMNLP.
9. Blondel, V. D., Guillaume, J. L., Lambiotte, R., & Lefebvre, E. (2008). Fast unfolding of communities in large networks. Journal of statistical mechanics.
(作者相关研究发布平台:
- CSDN博客:https://blog.csdn.net/T_Wang_Lab?type=blog
- 阿里云开发者社区:https://developer.aliyun.com/profile/ul4n4qhqvhsfe
- GitHub:https://github.com/tpwang-lab/tpwang-lab.github.io)
附录
A:分块数据样例

B:FAISS 索引构建核心代码(节选)
C:知识图谱节点完整列表(略,见 results/graph/centrality_full.csv)
D:核心节点关系网络图(举例)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 3
3 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)