RLVR post-train和 RFT在本质上很接近,最主要差异是规模不同 这句话是什么意思
RLVR post-train和 RFT在本质上很接近,最主要差异是规模不同 这句话是什么意思
这句话本质是在说:
RLVR(Reinforcement Learning with Verifiable Rewards)和 RFT(Reinforcement Fine-Tuning)在“训练范式”上是同一类东西,本质都是“用奖励信号优化模型”,区别主要在“规模、自动化程度和奖励来源”。
我给你拆到“面试级理解”。
一、先给结论(建议直接背)
RLVR 和 RFT 的核心都是 policy optimization(策略优化),
本质差别不在算法,而在:
- 奖励是否可自动验证
- 数据规模是否可扩展到工业级
- 是否需要人工参与
二、什么是 RFT(Reinforcement Fine-Tuning)
RFT 本质是:
模型输出 → 人类/模型打分 → 用奖励优化模型
典型形式:
- RLHF(人类反馈)
- DPO(偏好学习)
- PPO(策略梯度)
👉 特点:
| 特征 | RFT |
|---|---|
| 奖励来源 | 人 / 偏好数据 |
| 成本 | 高 |
| 数据规模 | 小~中 |
| 泛化 | 受限 |
三、什么是 RLVR(Reinforcement Learning with Verifiable Rewards)
RLVR 的核心是:
奖励是“可程序验证的”,不需要人类打分
例如:
- 代码是否通过测试 ✔
- 数学题答案是否正确 ✔
- SQL 是否执行正确 ✔
模型输出 → 自动验证器 → reward(0/1)
👉 特点:
| 特征 | RLVR |
|---|---|
| 奖励来源 | 自动验证 |
| 成本 | 低 |
| 数据规模 | 极大 |
| 可扩展性 | 强 |
四、为什么说“本质很接近”
因为两者优化的目标是一样的:
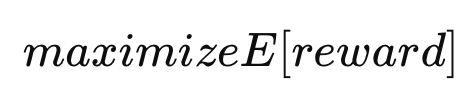
maximizeE[reward]maximize E[reward] maximizeE[reward]
无论是:
- 人类打分(RFT)
- 程序验证(RLVR)
👉 本质都是:
用 reward 信号优化 policy(模型)
五、真正差异:规模(Scale)
这句话的关键就在这里👇
1️⃣ RFT 的瓶颈
需要人类标注 → 成本高 → 数据量小
👉 结果:
- 难覆盖 long-tail
- 学习效率低
2️⃣ RLVR 的优势
reward 可自动计算 → 无限生成数据
👉 例如:
- 代码:生成100万题 + 自动跑测试
- 数学:自动验证答案
👉 结果:
可以做到 大规模强化学习(million-level rollouts)
六、一个直观对比(非常好用)
| 维度 | RFT | RLVR |
|---|---|---|
| 本质 | RL | RL |
| reward | 人类 / 偏好 | 程序验证 |
| scale | 小 | 极大 |
| 成本 | 高 | 低 |
| 典型任务 | 对话、安全 | 数学、代码 |
七、你可以怎么回答(面试高分版)
你可以这样说:
RLVR 和 RFT 在优化目标上是一样的,都是通过 reward signal 来优化模型策略,本质上都是 reinforcement learning。
但它们的关键差异在于 reward 的来源:
- RFT 依赖人类或偏好数据,导致数据规模受限
- RLVR 使用可验证的 reward function,使得训练可以自动化并扩展到大规模
因此可以理解为:
RFT 是小规模、高成本的 reinforcement learning,而 RLVR 是可扩展到工业级的大规模 reinforcement learning。
八、更深一层理解(拉开差距)
你可以再加一句(很加分):
从优化角度看,RLVR 本质上把 reward model learning 这个问题“绕开了”,直接使用 ground-truth verifier,避免了 reward model bias。
👉 这句话很关键:
- RLHF/RFT:需要训练 reward model(有偏差)
- RLVR:直接用“真值”
九、再往上一个层次(研究视角)
RLVR 可以看作是:
在一个可计算环境(verifiable environment)中的强化学习
而 RFT 更像:
在一个不可完全观测的偏好环境中的强化学习
十、一句话总结
RLVR 和 RFT 本质相同,都是用 reward 优化模型;
最大区别在于:
RLVR 的 reward 可自动验证,从而把强化学习从“小规模人工驱动”升级为“大规模自动化训练”。
如果你要更深入,我可以帮你补这几个非常加分的点:
- RLVR vs DPO vs PPO 的数学区别
- RLVR 为什么特别适合 code / math
- 怎么把 RLVR 用到 agent(非常高级)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)