从零理解大语言模型蒸馏:用小模型复刻大模型能力,AI 轻量化落地的核心路径
当下的 AI 行业,始终被一个无法回避的矛盾困扰:一边是千亿、万亿参数的超大模型,能力边界持续突破,却有着极高的训练与推理成本,只能在高端 GPU 集群中运行,无法落地到端侧、边缘场景与高并发业务中;另一边是参数量小巧、推理高效的轻量模型,部署门槛极低,却始终存在能力短板,无法满足复杂场景的需求。
绝大多数人都陷入了一个认知误区:想要提升小模型的能力,只能把它做得更大,或是用极其复杂的预训练方法从零重构。但大语言模型蒸馏(LLM Distillation)给出了一个更简单、更高效、更具落地价值的答案:你无需堆高参数量,无需搭建庞大的训练基建,只需让小模型向能力强大的大模型 “拜师学习”,就能实现能力的跨越式提升。
这个过程的核心逻辑极其直白:从强大的教师大模型中提取分步拆解的高质量解答,将其转化为标准化的训练样本,再用这些样本训练轻量化的学生模型,最终让小模型在保持轻量化优势的同时,复刻大模型的核心推理能力与知识储备。而它的效果也足够震撼:一个轻量小模型在数学基准测试中的准确率,能从 15.2% 提升至 33.6%,搭配更高质量的训练数据后,甚至能达到 45.0%,直接追平参数量远超自身的大模型。
这也是为什么合成数据与大模型蒸馏,正在成为 AI 模型优化的核心方向 —— 决定模型上限的,从来不止是参数量,更是它学习的内容质量。
一、LLM 蒸馏的本质:师生范式下的知识迁移,打破 “参数 = 能力” 的固有认知
大语言模型蒸馏,是经典的知识蒸馏技术在大模型时代的落地与进化,它的核心是一套 “教师 - 学生” 的学习范式:
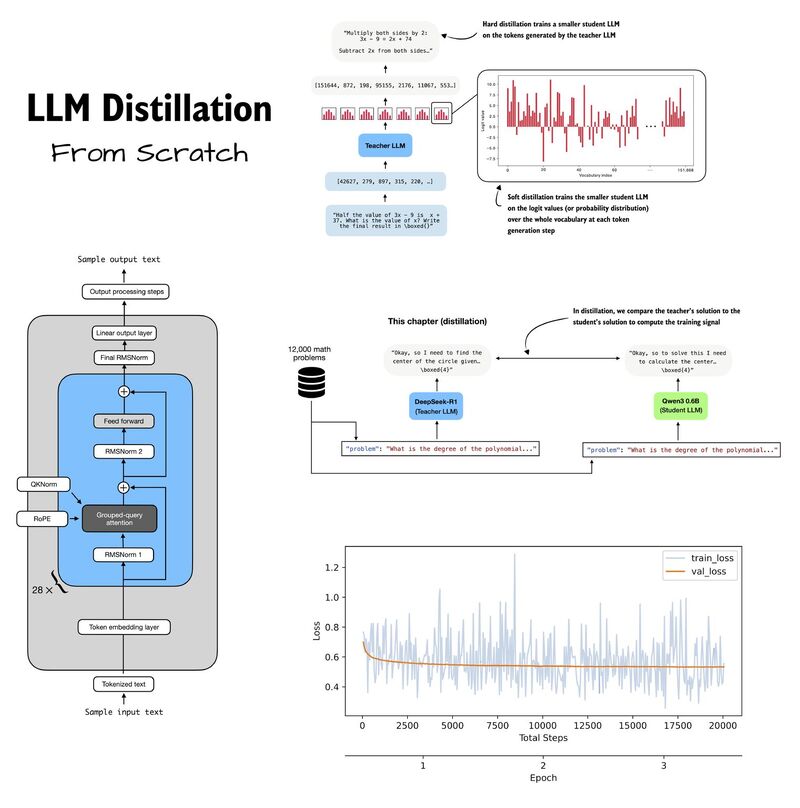
- 教师模型(Teacher LLM):通常是参数量庞大、预训练充分、能力强大的通用大模型(比如图中的 DeepSeek-R1),它拥有完整的知识储备、强大的推理能力与稳定的输出质量,是知识的来源;
- 学生模型(Student LLM):通常是参数量更小、结构更轻量化的小模型(比如图中的 Qwen3 0.6B),它推理速度更快、部署成本更低,但原生能力存在短板,是知识的接收方;
- 蒸馏的核心目标:将教师模型的知识、推理逻辑、输出模式、语义理解能力,完整地迁移到学生模型中,让小模型在不显著增加参数量的前提下,最大限度复刻大模型的核心能力。
从 Transformer 架构的底层逻辑来看,大模型的所有能力,最终都沉淀在模型的参数与 token 生成的概率分布中。蒸馏的过程,本质上就是把教师模型从海量数据中学到的 “隐性知识”,通过标准化的训练样本,转化为学生模型可以学习的 “显性知识”,最终完成能力的跨模型迁移。
图中展示的 Transformer Decoder 架构,正是蒸馏技术的硬件基础:无论是教师大模型还是学生小模型,主流的大语言模型都基于 Transformer 的 Decoder-only 架构,包含 Token 嵌入层、多层注意力模块、前馈网络、RMSNorm 归一化等核心组件。这种架构的同源性,保证了教师模型的知识可以顺畅地迁移到学生模型中,让蒸馏的落地成为可能。
二、蒸馏的两大核心范式:硬蒸馏与软蒸馏,适配不同的落地场景
根据知识迁移的粒度与训练方式的不同,LLM 蒸馏分为两大核心范式,分别适配不同的算力条件、业务场景与落地需求,二者没有绝对的优劣,只有是否适配场景的区别。
1. 硬蒸馏(Hard Distillation):最易落地的蒸馏方案,也是工业界的主流选择
硬蒸馏是最直观、门槛最低、落地性最强的蒸馏方式,也是图中案例采用的核心方案。它的核心逻辑,是让学生模型学习教师模型最终输出的确定性 token 序列,也就是教师模型针对输入问题生成的完整、高质量的标准答案。
它的完整执行流程非常清晰:
- 针对目标场景,构建标准化的输入问题集(如图中的 12000 道数学题),输入到教师模型中;
- 教师模型针对每个问题,生成分步拆解、逻辑完整、质量最优的输出内容,比如数学题的完整推理步骤与最终答案;
- 将 “输入问题 + 教师生成的标准答案” 整理成标准化的监督训练样本,构建蒸馏数据集;
- 用这套数据集,以标准的有监督微调(SFT)方式训练学生模型,让学生模型学习教师模型的输出逻辑与推理方式。
硬蒸馏的核心优势极其突出:它的训练逻辑与常规的 SFT 完全一致,无需复杂的训练基建,对算力的要求极低,中小团队甚至个人开发者都能快速落地;同时训练过程可控,输出效果可预期,非常适合垂直场景的能力迁移,是目前工业界落地的主流方案。
2. 软蒸馏(Soft Distillation):更深度的知识迁移,适配极致的能力复刻
如果说硬蒸馏是让学生学习教师的 “最终答案”,那么软蒸馏就是让学生学习教师的 “完整思考过程”。它的核心逻辑,不是只对齐最终的输出 token,而是对齐教师模型在每一个 token 生成步骤中,对整个词表的概率分布(logits 值)。
简单来说,教师模型在生成每一个字时,都会给词表中的所有 token 计算一个 “出现概率”:正确的答案概率最高,相关的同义词汇概率次之,无关词汇概率最低。软蒸馏会把这个完整的概率分布完整传递给学生模型,不仅告诉学生 “应该输出什么”,还告诉学生 “每个选项的可能性是多少”,把大模型对语言的理解、推理的不确定性、语义的细微差异,都完整迁移给学生。
软蒸馏的知识迁移更彻底,学生模型能复刻更接近教师的语义理解能力,但它的短板也同样明显:训练复杂度极高,需要存储教师模型每一步的完整 logits 数据,对算力、存储的要求呈指数级上升,落地门槛远高于硬蒸馏,通常用于参数量级差距不大的模型之间的能力迁移。
三、从零实现 LLM 蒸馏:四步完成小模型的能力跃升
无论是硬蒸馏还是软蒸馏,一套完整的蒸馏流程都遵循着标准化的工程逻辑,四个核心步骤环环相扣,其中训练数据的质量,直接决定了蒸馏的最终效果。
第一步:选定师生模型,搭建基础架构
蒸馏的第一步,是根据目标场景,选定适配的教师模型与学生模型,搭建基础的训练架构。
- 教师模型的选择核心标准:能力强大、输出稳定、在目标场景有突出表现。比如数学推理场景选择 DeepSeek-R1、代码场景选择 DeepSeek-Coder、通用场景选择 GPT-4o、Claude 3.7 Opus 等,保证教师模型能生成高质量的训练样本;
- 学生模型的选择核心标准:轻量化、部署适配、架构同源。优先选择和教师模型架构同源的 Decoder-only 模型,保证知识迁移的顺畅度,同时根据部署场景选择参数量级:端侧部署通常选择 0.5B-2B 模型,服务器部署选择 7B-13B 模型,在保证能力的同时,满足推理速度与成本要求。
第二步:构建高质量蒸馏数据集,这是蒸馏成败的核心
行业里有一句公认的结论:蒸馏的效果上限,由训练数据的质量决定,而不是模型的大小。图中的案例也清晰证明了这一点:同样的学生模型,用更优质的训练数据,准确率直接从 33.6% 提升到 45.0%,实现了质的飞跃。
一套合格的蒸馏训练数据集,必须满足三个核心要求:
- 场景精准覆盖:数据集必须完整覆盖目标场景的核心需求,比如企业客服场景,要覆盖所有常见的用户问题、业务规则、应答规范;数学推理场景,要覆盖不同难度、不同类型的数学题型,保证学生模型能学到完整的场景能力;
- 高质量的分步输出:教师模型的输出,不能只有最终答案,必须包含完整的推理步骤、逻辑拆解、思考过程。比如数学题要写清每一步的计算逻辑与原理,代码任务要包含需求分析、思路拆解、代码实现、注释说明、测试用例,让学生模型不仅学到 “结果是什么”,更学到 “怎么思考得到这个结果”;
- 标准化的格式统一:所有训练样本的格式必须统一,输入输出的结构必须固定,避免杂乱的格式干扰学生模型的学习过程,保证训练的稳定性与收敛效果。
第三步:定义训练信号,构建损失函数
蒸馏的核心,是通过对比教师模型与学生模型的输出,计算出优化学生模型的训练信号(损失函数),让学生模型的输出越来越接近教师模型。
- 硬蒸馏的损失函数:采用标准的语言模型交叉熵损失,直接对比学生模型的输出与教师模型生成的标准答案,优化学生模型的 token 生成准确率,和常规的 SFT 训练完全一致;
- 软蒸馏的损失函数:在交叉熵损失的基础上,加入 KL 散度损失,对齐教师模型与学生模型在每个 token 生成步骤的词表概率分布,让学生模型不仅学到最终的输出,更学到教师模型的语义理解逻辑。
图中的训练损失曲线,直观展示了蒸馏的训练过程:随着训练步数与训练轮次的增加,训练损失(train_loss)与验证损失(val_loss)持续下降并最终收敛,证明学生模型正在持续学习教师模型的知识,能力稳步提升。
第四步:模型训练、收敛验证与效果评估
完成数据集与损失函数的构建后,就可以启动蒸馏训练,通过梯度下降反向传播优化学生模型的参数。训练过程中,需要持续监控训练损失与验证损失,确保模型正常收敛,避免过拟合。
训练完成后,必须通过标准化的基准测试,验证模型的能力提升效果。比如数学场景用 GSM8K、MATH 基准测试,代码场景用 HumanEval、MBPP 基准测试,通用场景用 MMLU、CMMLU 基准测试,量化对比蒸馏前后学生模型的能力变化,同时验证模型的推理速度、显存占用等部署指标,确保模型在能力提升的同时,依然保持轻量化的部署优势。
三、LLM 蒸馏的核心价值:解决 AI 落地的核心矛盾,实现能力的普惠化
LLM 蒸馏之所以成为当下 AI 行业的核心技术方向,本质是因为它完美解决了 AI 落地的核心矛盾:大模型用不起,小模型不好用。它为企业与开发者提供了一条低成本、高回报的 AI 模型落地路径,带来了四个不可替代的核心价值。
1. 极致的成本与效率平衡,打破算力垄断
超大模型的训练与推理,需要庞大的高端 GPU 集群支撑,单次推理的成本是小模型的几十上百倍,绝大多数中小企业根本无法承担。而蒸馏后的小模型,参数量只有大模型的几十分之一,推理速度提升几十倍,算力成本下降 90% 以上,却能复刻大模型 80% 以上的核心能力,甚至在垂直场景中超越通用大模型。
更重要的是,蒸馏的训练门槛极低,硬蒸馏的训练逻辑和常规 SFT 完全一致,无需庞大的预训练基建,中小团队甚至用消费级显卡,就能完成小规模的蒸馏训练,彻底打破了 “只有大厂才能做好 AI 模型” 的算力垄断。
2. 垂直场景的精准能力复刻,打造 “小而精” 的专属模型
通用大模型虽然能力全面,但在医疗、法律、企业内部业务、工业制造等垂直场景中,往往存在知识盲区、输出不规范、不符合行业要求等问题。而通过蒸馏,我们可以让教师模型专门生成垂直场景的高质量输出,把行业知识、业务规范、推理逻辑、专业术语,精准迁移给小模型,打造出 “小而精” 的垂直场景专属模型。
这种方式,远比从零训练垂直大模型成本更低、效率更高、效果更好,能快速适配企业的专属业务需求,让 AI 能力真正融入业务流程。
3. 实现 AI 的全场景落地,打通从云端到端侧的最后一公里
当下 AI 落地的最大瓶颈之一,就是部署场景的限制:超大模型只能在云端数据中心运行,无法在手机、边缘设备、工业终端、离线环境中部署。而蒸馏后的轻量化小模型,对硬件的要求极低,可以直接部署在端侧设备上,实现离线推理、低延迟响应,完美适配自动驾驶、智能硬件、工业边缘计算、离线办公等场景。
蒸馏技术,真正让高性能的 AI 能力,突破了云端数据中心的限制,实现了全场景的落地覆盖。
4. 合成数据 + 蒸馏,形成模型优化的正向闭环
当下 AI 模型优化的核心趋势,就是合成数据与蒸馏技术的深度结合。过去,我们想要训练一个高质量模型,需要花费巨大的成本人工标注数据,数据质量与数量都存在明显的天花板。而现在,我们可以通过大模型生成高质量的合成数据,作为蒸馏的训练样本,无需人工标注,就能快速构建大规模、高质量的数据集。
这种 “大模型生成合成数据→蒸馏训练小模型→小模型落地验证→优化合成数据→再次蒸馏迭代” 的正向闭环,让模型优化的成本大幅下降,效率大幅提升,成为了中小团队打造专属 AI 模型的主流方式。
结语:提升小模型,教得好远比做得大更有价值
回到文章开头的核心问题:你会如何提升一个小模型?是把它做得更大,还是把它教得更好?
行业的发展已经给出了清晰的答案:堆参数的军备竞赛,永远只有少数大厂能参与,而通过蒸馏,让小模型向更强的模型学习,用高质量的训练数据完成能力跃升,是所有企业与开发者都能走通的路。
LLM 蒸馏的本质,是 AI 能力的普惠化。它打破了 “参数 = 能力” 的固有认知,让我们看到,AI 模型的核心竞争力,从来不是参数量的多少,而是它学到的知识质量、解决实际问题的能力。它让每个开发者、每个企业,都能站在顶尖大模型的肩膀上,打造出属于自己的、轻量化、高性能的 AI 模型,真正让 AI 技术从实验室的 demo,变成落地到千行百业的生产力工具。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 14
14 0
0- 0



 已为社区贡献45条内容
已为社区贡献45条内容

所有评论(0)