可观测性成熟度模型:从系统监控到业务对齐,重新定义云原生时代的可观测性
在云原生、微服务与 AI 工作负载全面普及的今天,可观测性已经从 IT 运维的 “附加能力”,变成了现代软件系统的 “核心生命线”。但行业里依然存在一个普遍的认知误区:很多团队以为,只要收集了足够多的基础设施指标、日志、链路追踪数据,就完成了可观测性的建设。
但现实恰恰相反:随着系统架构越来越复杂,微服务、事件驱动架构、AI 工作负载、分布式 API 已经成为常态,传统的监控模式早已彻底失效。我们每天盯着成千上万的遥测信号,却依然无法回答两个最核心的问题:除了 “系统是否健康”,我们更需要知道 “当前哪些工作负载对业务真正重要?”,以及 “系统的异常,正在对业务和用户造成什么样的影响?”
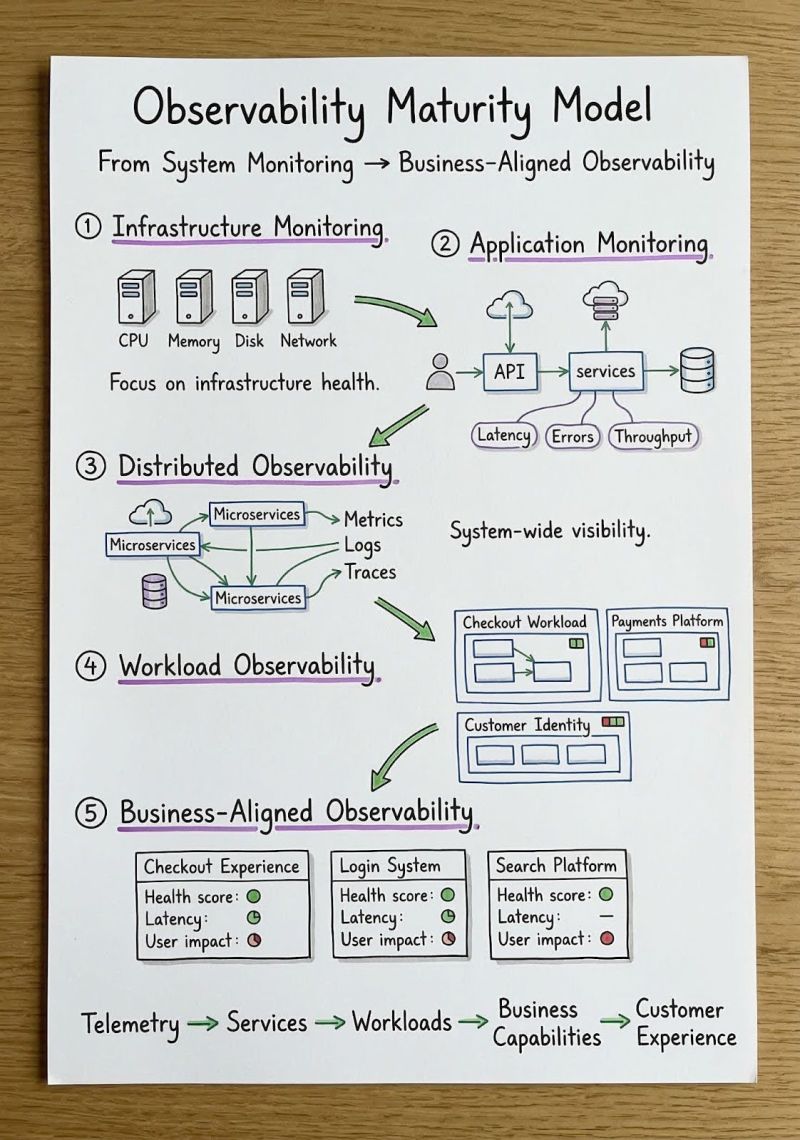
这张「可观测性成熟度模型」手绘图,精准地勾勒出了可观测性技术的完整演进路径 —— 从最基础的基础设施监控,到最终与业务价值深度对齐的可观测性,五个层层递进的阶段,不仅清晰地定义了每个阶段的核心能力与边界,更指明了现代可观测性的终极方向:可观测性的核心价值,从来不是收集数据,而是把技术信号转化为对业务的洞察,让 IT 团队的工作真正聚焦于对用户、对业务最有价值的地方。
一、可观测性的五级演进路径:从硬件健康到业务价值的完整跨越
可观测性的发展,始终与软件架构的演进深度绑定。从单体应用到分布式微服务,从物理机到云原生 Serverless,架构的复杂度每提升一个量级,可观测性的能力边界就必须完成一次跨越。这五个阶段,正是绝大多数企业可观测性建设的必经之路,每一个阶段都解决了上一个阶段的核心痛点,同时也为下一个阶段奠定了基础。
阶段 1:基础设施监控 —— 可观测性的起点,聚焦硬件健康
这是可观测性最基础、最原始的阶段,也是绝大多数企业 IT 建设的起点。这个阶段的核心焦点,是底层物理资源的运行状态,核心监控对象就是服务器的四大黄金指标:CPU、内存、磁盘、网络。
在物理机、虚拟机主导的时代,这个阶段的监控完全够用:应用大多是单体架构,部署在有限的几台服务器上,只要服务器不宕机、CPU 和内存不跑满,业务系统大概率就能正常运行。这个阶段的核心目标,就是回答一个最基础的问题:我们的服务器硬件是不是正常的?
但它的局限性也极其明显:基础设施的健康,完全不等于业务的可用。哪怕服务器的 CPU 使用率只有 10%,内存、磁盘一切正常,上层的应用也可能因为代码 bug、数据库死锁出现服务不可用,而基础设施监控对此完全无能为力。它只能看到硬件的状态,却对上层的应用与业务一无所知。
阶段 2:应用监控 —— 向上延伸,聚焦应用的可用与性能
随着 Web 应用、单体服务的普及,基础设施监控的短板越来越明显,可观测性向上延伸,进入了应用监控(APM,应用性能监控)阶段。这个阶段的核心焦点,从底层硬件转向了上层的应用服务,核心监控指标变成了延迟、错误率、吞吐量三大黄金指标。
在这个阶段,我们开始关注 API 接口的响应速度、服务的错误率、请求的吞吐量,能清晰地看到用户的请求从进入应用到返回结果的全流程,定位应用代码中的性能瓶颈、功能错误。它解决了基础设施监控的核心盲区,回答了一个新的问题:我们的应用能不能正常响应用户的请求?性能是否符合预期?
但随着软件架构进入微服务时代,单体应用被拆分成了几十个甚至上百个分布式服务,应用监控的局限性也彻底暴露:它只能看到单个应用的运行状态,却看不到一个用户请求在多个微服务之间的完整流转路径。一个服务的延迟、错误率都正常,但整个业务流程依然可能因为多个服务之间的调用异常而失败,应用监控对此无法给出完整的答案。
阶段 3:分布式可观测性 —— 打通全链路,实现系统级全局可见性
微服务架构的全面普及,直接推动可观测性进入了第三个阶段:分布式可观测性。这个阶段的核心标志,就是确立了可观测性的三大支柱:Metrics(指标)、Logs(日志)、Traces(链路追踪),实现了分布式系统的全链路、全系统可见性。
在这个阶段,我们可以通过分布式链路追踪,看到一个用户请求在数十个微服务之间的完整流转路径,精准定位是哪个服务、哪个环节出现了延迟、抛出了错误;通过指标与日志的关联,实现了分布式系统的全维度数据打通,解决了微服务架构下 “问题定位难、根因排查慢” 的核心痛点。它回答的核心问题是:我们的整个分布式系统,到底在哪个环节出现了问题?
但这个阶段依然存在一个无法回避的行业痛点:遥测信号爆炸。一个中等规模的微服务系统,会产生成千上万的指标、日志、链路数据,工程师彻底淹没在海量的监控数据里。我们能看到系统里所有的技术信号,却不知道哪些信号是真正重要的,哪些异常会真正影响到核心业务,最终出现 “什么都能看到,却什么都抓不住” 的困境。
阶段 4:工作负载可观测性 —— 从零散服务到业务单元,聚焦核心工作负载
分布式可观测性解决了 “全链路可见” 的问题,却没有解决 “信号太多、重点不明” 的困境,而工作负载可观测性,正是为了解决这个问题而生,也是可观测性从 “技术视角” 向 “业务视角” 过渡的关键一步。
这个阶段的核心逻辑,是不再把系统拆分成零散的单个服务来看待,而是把支撑同一个业务功能的相关服务、组件,分组为一个完整的工作负载。比如把支撑用户下单的所有微服务,分组为「结账工作负载」;把支撑支付的所有服务,分组为「支付平台工作负载」;把支撑用户登录认证的服务,分组为「客户身份认证工作负载」。
我们不再盯着单个服务的指标,而是关注一个完整业务工作负载的整体健康度、性能表现与运行状态。它解决了分布式系统 “信号爆炸” 的核心问题,让工程师从成千上万的零散指标中抽离出来,聚焦于一个个完整的业务单元,回答了新的问题:支撑我们业务的核心工作负载,运行状态是否正常?
这个阶段的局限性在于,它依然停留在技术单元的视角,虽然已经向业务靠拢,却依然没有把技术指标和最终的业务价值、用户体验直接挂钩。我们能看到结账工作负载的延迟升高了,却无法直观地知道这个延迟,对用户的下单转化率、企业的营收造成了多大的影响。
阶段 5:业务对齐的可观测性 —— 可观测性的终极形态,与业务价值深度绑定
这是可观测性成熟度的最高阶段,也是现代企业可观测性建设的终极目标。它的核心逻辑,是把可观测性的技术信号,与企业的核心业务能力、最终的用户体验直接对齐,让可观测性从 IT 团队的运维工具,变成连接技术与业务的核心桥梁。
在这个阶段,我们不再以服务、工作负载为核心视角,而是以业务能力与用户体验为核心视角。比如我们关注的不再是「结账工作负载」的技术指标,而是「用户结账体验」的完整状态:不仅有健康分、延迟这些技术指标,更有用户影响、订单转化率这些直接的业务结果。我们能一眼看到:登录系统的延迟升高,导致了多少用户登录失败;搜索平台的错误率上升,对用户的搜索体验、商品成交造成了多大的影响。
它最终回答了可观测性的终极问题:系统的运行状态,对我们的业务和用户,到底造成了什么样的影响?
从这个阶段的完整链路,我们能清晰地看到可观测性的价值闭环:遥测数据→服务→工作负载→业务能力→用户体验。所有底层的技术信号,最终都映射到了业务价值与用户体验上,技术团队与业务团队终于有了统一的沟通语言,不再出现 “技术团队说系统一切正常,业务团队说用户无法下单” 的割裂局面。
二、现代架构的核心挑战:为什么传统监控模式已经彻底失效?
可观测性之所以必须完成从基础设施监控到业务对齐的五级跨越,本质上是因为现代软件系统的架构,已经发生了根本性的变革。传统的监控模式,是为单体应用、静态基础设施设计的,面对当下的分布式、动态化、智能化的系统架构,已经彻底失去了作用。
当下的企业级系统,正在面临四大无法回避的核心挑战,这也是传统监控模式的能力边界:
1. 分布式架构带来的遥测信号爆炸
微服务、Serverless、事件驱动架构的普及,让一个完整的业务流程,从单体应用里的一个函数调用,变成了跨数十个服务、跨多个集群、跨多个云厂商的分布式调用。一个中等规模的电商系统,在大促期间会产生数十万条指标、TB 级别的日志、数百万条分布式链路。工程师淹没在海量的遥测数据里,根本无法快速定位哪些信号是真正关键的,哪些异常会影响核心业务。传统的监控模式,只能被动展示所有数据,却无法帮我们筛选出真正重要的信息。
2. 技术与业务的严重脱节
在传统的监控体系里,技术团队和业务团队始终处于割裂的状态:技术团队盯着 CPU 使用率、P99 延迟、错误率这些技术指标,业务团队盯着订单量、转化率、用户留存这些业务指标。当业务出现问题时,业务团队无法通过技术指标判断影响范围,技术团队也无法知道一个服务的异常,会对业务造成多大的冲击。技术与业务之间没有统一的语言,导致故障发生时,两个团队无法协同定位问题,平均故障解决时间(MTTR)被无限拉长。
3. 问题定位的效率持续走低
在分布式系统里,一个用户的报错,可能涉及到前端、网关、API 服务、数据库、缓存、第三方接口等十几个环节。传统的监控模式,需要工程师在不同的工具之间来回切换,翻找不同服务的日志、指标、链路,才能定位到问题的根因。在这个过程中,业务故障已经持续了数十分钟,造成了大量的用户流失与营收损失。更严重的是,很多时候工程师把大量时间花在了排查非核心服务的异常上,却忽略了真正影响核心业务的故障。
4. AI 工作负载带来的全新可观测性难题
随着大模型、AI Agent 的全面普及,AI 工作负载已经成为现代系统的核心组成部分。而 AI 工作负载的可观测性,和传统应用有着本质的区别:我们不仅要关注服务的延迟、错误率,还要关注大模型的 Token 消耗、推理准确率、工具调用成功率、Agent 的执行链路,这些都是传统监控模式完全无法覆盖的。如果依然用传统的基础设施监控、应用监控来管理 AI 工作负载,最终只会陷入 “什么都监控了,却什么都控制不了” 的困境。
三、智能工作负载:实现业务对齐可观测性的核心路径
面对现代架构的核心挑战,行业里已经出现了成熟的解决方案 ——New Relic 最新推出的Intelligent Workloads(智能工作负载),正是为了解决传统可观测性的核心痛点,帮助企业快速完成从分布式可观测性,到业务对齐可观测性的跨越。
它的核心设计理念,完全贴合可观测性成熟度模型的演进路径:不再让工程师面对成千上万的零散遥测信号,而是把可观测性的核心单元,从单个服务、单个指标,升级为与业务对齐的工作负载,最终实现 “技术信号与业务价值的深度绑定”。它的核心价值,体现在四个维度:
1. 业务对齐的工作负载分组,打通技术与业务的语言壁垒
Intelligent Workloads 允许企业把相关的服务、组件、资源,按照它们所支撑的业务能力,分组为标准化的工作负载。比如把支撑用户下单的所有服务,打包为「结账体验」工作负载;把支撑用户登录的所有服务,打包为「登录系统」工作负载;把支撑商品搜索的所有服务,打包为「搜索平台」工作负载。
这种分组模式,彻底打破了技术与业务的壁垒:技术团队看到的工作负载,就是业务团队关注的核心业务能力,双方有了统一的视角与共同的语言。当业务出现波动时,所有人都能一眼看到,是哪个业务能力对应的工作负载出现了异常,无需再在技术指标与业务结果之间做反复的映射与解读。
2. 能力级别的全局可见性,一眼看清核心业务的健康状态
传统的可观测性工具,只能展示单个服务的指标,而 Intelligent Workloads 提供了业务能力级别的全局可见性。我们不再需要逐个查看数十个服务的指标,就能一眼看到整个业务能力的健康分、性能表现、异常状态。比如「结账体验」工作负载的整体健康度、平均延迟、错误率、用户影响范围,都能在一个视图里完整呈现。
这种全局视角,彻底解决了分布式系统 “只见树木,不见森林” 的问题。哪怕是最复杂的分布式业务流程,我们也能快速把握它的整体运行状态,不再需要在海量的指标里大海捞针。
3. 分布式系统的异常快速定位,大幅降低故障解决时间
Intelligent Workloads 不仅能展示工作负载的整体状态,还能向下钻取,快速定位异常的根因。当一个业务工作负载出现异常时,系统会自动关联分析工作负载内所有服务、组件的遥测数据,快速定位是哪个环节、哪个服务、哪个指标出现了问题,无需工程师在多个工具之间来回切换,手动排查海量数据。
这种能力,直接把分布式系统的故障定位,从 “小时级” 压缩到了 “分钟级”,大幅降低了平均故障解决时间(MTTR),减少了业务故障带来的营收损失与用户流失。
4. 工程资源的最优分配,聚焦对用户影响最大的核心问题
在传统的监控模式下,工程师的精力往往被大量非核心的告警、无关紧要的指标波动所消耗。而 Intelligent Workloads 通过业务对齐的视角,让企业能清晰地看到:哪些工作负载是支撑核心营收的关键业务,哪些异常会对用户体验造成最严重的影响。
基于这个视角,工程师可以把有限的精力,优先投入到对业务、对用户影响最大的问题上,而不是在无意义的告警里疲于奔命。这不仅大幅提升了工程团队的工作效率,更让技术团队的工作,真正聚焦于企业最核心的业务价值,实现了技术资源的最优分配。
对于想要深入了解这套方案的企业与工程师,New Relic Advance 2026 大会的系列会话已经开放了按需观看,我们可以按照自己的节奏,深入探索这个平台的完整能力,找到适合自己企业的业务对齐可观测性落地路径。
结语:可观测性的终极价值,是连接技术与业务
回顾可观测性的五级演进路径,我们能清晰地看到一个核心的趋势:可观测性的发展,始终在从 “面向硬件”,走向 “面向应用”,最终走向 “面向业务与用户”。
在云原生、AI 全面普及的今天,可观测性早已不是 IT 运维团队的专属工具,它已经成为了企业数字化运营的核心基础设施。一个成熟的可观测性体系,不仅能告诉我们 “系统是否健康”,更能告诉我们 “系统的健康度,对业务和用户意味着什么”。
从基础设施监控到业务对齐的可观测性,是每一个现代企业的必经之路。而决定这条路走得顺不顺畅的,从来不是我们收集了多少遥测数据,而是我们能不能把这些数据,转化为对业务的洞察,转化为对用户体验的优化。毕竟,可观测性的终极价值,从来不是看清系统本身,而是通过系统,看清我们的业务,看清我们的用户。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献45条内容
已为社区贡献45条内容

所有评论(0)