SenseVoicecpp 源码识别语音[AI人工智能(六十七)]—东方仙盟
核心代码
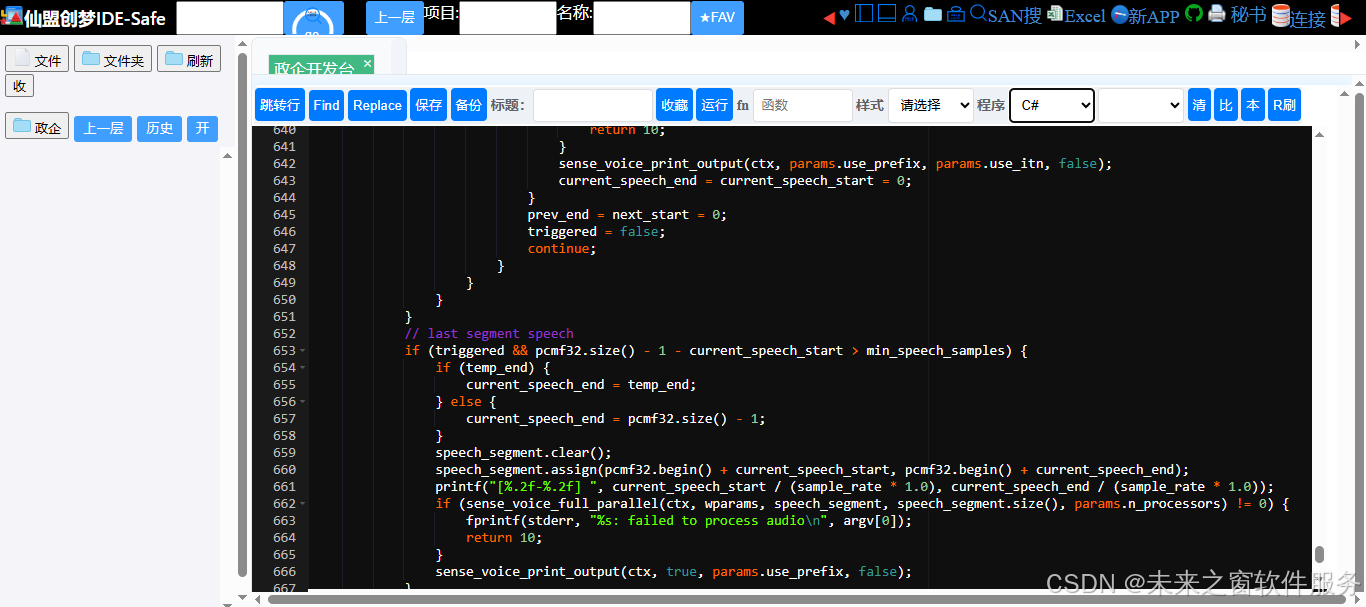
完整main.cc代码
//
// Created by lovemefan on 2024/7/21.
//
#include "common.h"
#include "sense-voice.h"
#include "silero-vad.h"
#include <cmath>
#include <cstdint>
#include <thread>
#if defined(_MSC_VER)
#pragma warning(disable: 4244 4267) // possible loss of data
#endif
#define CHUNK_SIZE 512
#define CONTEXT_SIZE 576
#define SENSE_VOICE_VAD_CHUNK_PAD_SIZE 64
#define VAD_LSTM_STATE_MEMORY_SIZE 2048
#define VAD_LSTM_STATE_DIM 128
// command-line parameters
struct sense_voice_params {
int32_t n_threads = std::min(4, (int32_t) std::thread::hardware_concurrency());
int32_t n_processors = 1;
int32_t offset_t_ms = 0;
int32_t offset_n = 0;
int32_t duration_ms = 0;
int32_t progress_step = 5;
int32_t max_context = -1;
int32_t max_len = 0;
int32_t n_mel = 80;
int32_t best_of = sense_voice_full_default_params(SENSE_VOICE_SAMPLING_GREEDY).greedy.best_of;
int32_t beam_size = sense_voice_full_default_params(SENSE_VOICE_SAMPLING_BEAM_SEARCH).beam_search.beam_size;
int32_t audio_ctx = 0;
float word_thold = 0.01f;
float entropy_thold = 2.40f;
float logprob_thold = -1.00f;
float grammar_penalty = 100.0f;
float temperature = 0.0f;
float temperature_inc = 0.2f;
// vad params
float threshold = 0.5f;
float neg_threshold = 0.35f;
int32_t min_speech_duration_ms = 250;
int32_t max_speech_duration_ms = 15000;
int32_t min_silence_duration_ms = 100;
int32_t speech_pad_ms = 30;
bool debug_mode = false;
bool translate = false;
bool detect_language = false;
bool diarize = false;
bool tinydiarize = false;
bool split_on_word = false;
bool no_fallback = false;
bool output_txt = false;
bool output_vtt = false;
bool output_srt = false;
bool output_wts = false;
bool output_csv = false;
bool output_jsn = false;
bool output_jsn_full = false;
bool output_lrc = false;
bool no_prints = false;
bool print_special = false;
bool print_colors = false;
bool print_progress = false;
bool no_timestamps = false;
bool log_score = false;
bool use_gpu = true;
bool flash_attn = false;
bool use_itn = false;
bool use_prefix = false;
std::string language = "auto";
std::string prompt;
std::string model = "models/ggml-base.en.bin";
std::string openvino_encode_device = "CPU";
std::vector<std::string> fname_inp = {};
std::vector<std::string> fname_out = {};
};
static int sense_voice_has_coreml(void) {
#ifdef SENSE_VOICE_USE_COREML
return 1;
#else
return 0;
#endif
}
static int sense_voice_has_openvino(void) {
#ifdef SENSE_VOICE_USE_OPENVINO
return 1;
#else
return 0;
#endif
}
const char * sense_voice_print_system_info(void) {
static std::string s;
s = "";
s += "AVX = " + std::to_string(ggml_cpu_has_avx()) + " | ";
s += "AVX2 = " + std::to_string(ggml_cpu_has_avx2()) + " | ";
s += "AVX512 = " + std::to_string(ggml_cpu_has_avx512()) + " | ";
s += "FMA = " + std::to_string(ggml_cpu_has_fma()) + " | ";
s += "NEON = " + std::to_string(ggml_cpu_has_neon()) + " | ";
s += "ARM_FMA = " + std::to_string(ggml_cpu_has_arm_fma()) + " | ";
s += "F16C = " + std::to_string(ggml_cpu_has_f16c()) + " | ";
s += "FP16_VA = " + std::to_string(ggml_cpu_has_fp16_va()) + " | ";
s += "WASM_SIMD = " + std::to_string(ggml_cpu_has_wasm_simd()) + " | ";
s += "SSE3 = " + std::to_string(ggml_cpu_has_sse3()) + " | ";
s += "SSSE3 = " + std::to_string(ggml_cpu_has_ssse3()) + " | ";
s += "VSX = " + std::to_string(ggml_cpu_has_vsx()) + " | ";
s += "COREML = " + std::to_string(sense_voice_has_coreml()) + " | ";
s += "OPENVINO = " + std::to_string(sense_voice_has_openvino());
return s.c_str();
}
static void sense_voice_print_usage(int /*argc*/, char ** argv, const sense_voice_params & params) {
fprintf(stderr, "\n");
fprintf(stderr, "usage: %s [options] file0.wav file1.wav ...\n", argv[0]);
fprintf(stderr, "\n");
fprintf(stderr, "options:\n");
fprintf(stderr, " -h, --help [default] show this help message and exit\n");
fprintf(stderr, " -t N, --threads N [%-7d] number of threads to use during computation\n", params.n_threads);
fprintf(stderr, " -p N, --processors N [%-7d] number of processors to use during computation\n", params.n_processors);
fprintf(stderr, " -ot N, --offset-t N [%-7d] time offset in milliseconds\n", params.offset_t_ms);
fprintf(stderr, " -on N, --offset-n N [%-7d] segment index offset\n", params.offset_n);
fprintf(stderr, " -d N, --duration N [%-7d] duration of audio to process in milliseconds\n", params.duration_ms);
fprintf(stderr, " -mc N, --max-context N [%-7d] maximum number of text context tokens to store\n", params.max_context);
fprintf(stderr, " -ml N, --max-len N [%-7d] maximum segment length in characters\n", params.max_len);
fprintf(stderr, " -sow, --split-on-word [%-7s] split on word rather than on token\n", params.split_on_word ? "true" : "false");
fprintf(stderr, " -bo N, --best-of N [%-7d] number of best candidates to keep\n", params.best_of);
fprintf(stderr, " -bs N, --beam-size N [%-7d] beam size for beam search\n", params.beam_size);
fprintf(stderr, " -ac N, --audio-ctx N [%-7d] audio context size (0 - all)\n", params.audio_ctx);
fprintf(stderr, " -wt N, --word-thold N [%-7.2f] word timestamp probability threshold\n", params.word_thold);
fprintf(stderr, " -et N, --entropy-thold N [%-7.2f] entropy threshold for decoder fail\n", params.entropy_thold);
fprintf(stderr, " -lpt N, --logprob-thold N [%-7.2f] log probability threshold for decoder fail\n", params.logprob_thold);
fprintf(stderr, " -tp, --temperature N [%-7.2f] The sampling temperature, between 0 and 1\n", params.temperature);
fprintf(stderr, " -tpi, --temperature-inc N [%-7.2f] The increment of temperature, between 0 and 1\n",params.temperature_inc);
fprintf(stderr, " -debug, --debug-mode [%-7s] enable debug mode (eg. dump log_mel)\n", params.debug_mode ? "true" : "false");
fprintf(stderr, " -di, --diarize [%-7s] stereo audio diarization\n", params.diarize ? "true" : "false");
fprintf(stderr, " -tdrz, --tinydiarize [%-7s] enable tinydiarize (requires a tdrz model)\n", params.tinydiarize ? "true" : "false");
fprintf(stderr, " -nf, --no-fallback [%-7s] do not use temperature fallback while decoding\n", params.no_fallback ? "true" : "false");
fprintf(stderr, " -otxt, --output-txt [%-7s] output result in a text file\n", params.output_txt ? "true" : "false");
fprintf(stderr, " -osrt, --output-srt [%-7s] output result in a srt file\n", params.output_srt ? "true" : "false");
fprintf(stderr, " -ocsv, --output-csv [%-7s] output result in a CSV file\n", params.output_csv ? "true" : "false");
fprintf(stderr, " -oj, --output-json [%-7s] output result in a JSON file\n", params.output_jsn ? "true" : "false");
fprintf(stderr, " -ojf, --output-json-full [%-7s] include more information in the JSON file\n", params.output_jsn_full ? "true" : "false");
fprintf(stderr, " -of FNAME, --output-file FNAME [%-7s] output file path (without file extension)\n", "");
fprintf(stderr, " -np, --no-prints [%-7s] do not print anything other than the results\n", params.no_prints ? "true" : "false");
fprintf(stderr, " -ps, --print-special [%-7s] print special tokens\n", params.print_special ? "true" : "false");
fprintf(stderr, " -pc, --print-colors [%-7s] print colors\n", params.print_colors ? "true" : "false");
fprintf(stderr, " -pp, --print-progress [%-7s] print progress\n", params.print_progress ? "true" : "false");
fprintf(stderr, " -nt, --no-timestamps [%-7s] do not print timestamps\n", params.no_timestamps ? "true" : "false");
fprintf(stderr, " -l LANG, --language LANG [%-7s] spoken language ('auto' for auto-detect), support [`zh`, `en`, `yue`, `ja`, `ko`\n", params.language.c_str());
fprintf(stderr, " --prompt PROMPT [%-7s] initial prompt (max n_text_ctx/2 tokens)\n", params.prompt.c_str());
fprintf(stderr, " -m FNAME, --model FNAME [%-7s] model path\n", params.model.c_str());
fprintf(stderr, " -f FNAME, --file FNAME [%-7s] input WAV file path\n", "");
fprintf(stderr, " --min_speech_duration_ms [%-7.2d] min_speech_duration_ms\n", params.min_speech_duration_ms);
fprintf(stderr, " --max_speech_duration_ms [%-7.2d] log probability threshold for decoder fail\n", params.max_speech_duration_ms);
fprintf(stderr, " --min_silence_duration_ms [%-7.2d] min_silence_duration_ms\n", params.min_silence_duration_ms);
fprintf(stderr, " --speech_pad_ms [%-7.2d] speech_pad_ms\n", params.speech_pad_ms);
fprintf(stderr, " -oved D, --ov-e-device DNAME [%-7s] the OpenVINO device used for encode inference\n", params.openvino_encode_device.c_str());
fprintf(stderr, " -ls, --log-score [%-7s] log best decoder scores of tokens\n", params.log_score?"true":"false");
fprintf(stderr, " -ng, --no-gpu [%-7s] disable GPU\n", params.use_gpu ? "false" : "true");
fprintf(stderr, " -fa, --flash-attn [%-7s] flash attention\n", params.flash_attn ? "true" : "false");
fprintf(stderr, " -itn, --use-itn [%-7s] use itn\n", params.use_itn ? "true" : "false");
fprintf(stderr, " -prefix, --use-prefix [%-7s] use itn\n", params.use_itn ? "true" : "false");
fprintf(stderr, "\n");
}
struct sense_voice_print_user_data {
const sense_voice_params * params;
const std::vector<std::vector<float>> * pcmf32s;
int progress_prev;
};
static char * sense_voice_param_turn_lowercase(char * in){
int string_len = strlen(in);
for (int i = 0; i < string_len; i++){
*(in+i) = tolower((unsigned char)*(in+i));
}
return in;
}
static bool sense_voice_params_parse(int argc, char ** argv, sense_voice_params & params) {
for (int i = 1; i < argc; i++) {
std::string arg = argv[i];
if (arg == "-"){
params.fname_inp.push_back(arg);
continue;
}
if (arg[0] != '-') {
params.fname_inp.push_back(arg);
continue;
}
if (arg == "-h" || arg == "--help") {
sense_voice_print_usage(argc, argv, params);
exit(0);
}
else if (arg == "-t" || arg == "--threads") { params.n_threads = std::stoi(argv[++i]); }
else if (arg == "-p" || arg == "--processors") { params.n_processors = std::stoi(argv[++i]); }
else if (arg == "-ot" || arg == "--offset-t") { params.offset_t_ms = std::stoi(argv[++i]); }
else if (arg == "-on" || arg == "--offset-n") { params.offset_n = std::stoi(argv[++i]); }
else if (arg == "-d" || arg == "--duration") { params.duration_ms = std::stoi(argv[++i]); }
else if (arg == "-mc" || arg == "--max-context") { params.max_context = std::stoi(argv[++i]); }
else if (arg == "-ml" || arg == "--max-len") { params.max_len = std::stoi(argv[++i]); }
// vad parameters
else if (arg == "-vt" || arg == "--threshold") { params.threshold = std::stof(argv[++i]); }
else if (arg == "-vnt" || arg == "--neg_threshold") { params.neg_threshold = std::stof(argv[++i]); }
else if (arg == "--min-speech-duration-ms") { params.min_speech_duration_ms = std::stoi(argv[++i]); }
else if (arg == "--max-speech-duration-ms") { params.max_speech_duration_ms = std::stoi(argv[++i]); }
else if (arg == "--min_silence_duration_ms") { params.min_silence_duration_ms = std::stoi(argv[++i]); }
else if (arg == "--speech_pad_ms") { params.speech_pad_ms = std::stoi(argv[++i]); }
else if (arg == "-bo" || arg == "--best-of") { params.best_of = std::stoi(argv[++i]); }
else if (arg == "-bs" || arg == "--beam-size") { params.beam_size = std::stoi(argv[++i]); }
else if (arg == "-ac" || arg == "--audio-ctx") { params.audio_ctx = std::stoi(argv[++i]); }
else if (arg == "-wt" || arg == "--word-thold") { params.word_thold = std::stof(argv[++i]); }
else if (arg == "-et" || arg == "--entropy-thold") { params.entropy_thold = std::stof(argv[++i]); }
else if (arg == "-lpt" || arg == "--logprob-thold") { params.logprob_thold = std::stof(argv[++i]); }
else if (arg == "-tp" || arg == "--temperature") { params.temperature = std::stof(argv[++i]); }
else if (arg == "-tpi" || arg == "--temperature-inc") { params.temperature_inc = std::stof(argv[++i]); }
else if (arg == "-debug"|| arg == "--debug-mode") { params.debug_mode = true; }
else if (arg == "-tr" || arg == "--translate") { params.translate = true; }
else if (arg == "-di" || arg == "--diarize") { params.diarize = true; }
else if (arg == "-tdrz" || arg == "--tinydiarize") { params.tinydiarize = true; }
else if (arg == "-sow" || arg == "--split-on-word") { params.split_on_word = true; }
else if (arg == "-nf" || arg == "--no-fallback") { params.no_fallback = true; }
else if (arg == "-otxt" || arg == "--output-txt") { params.output_txt = true; }
else if (arg == "-ovtt" || arg == "--output-vtt") { params.output_vtt = true; }
else if (arg == "-osrt" || arg == "--output-srt") { params.output_srt = true; }
else if (arg == "-owts" || arg == "--output-words") { params.output_wts = true; }
else if (arg == "-olrc" || arg == "--output-lrc") { params.output_lrc = true; }
else if (arg == "-ocsv" || arg == "--output-csv") { params.output_csv = true; }
else if (arg == "-oj" || arg == "--output-json") { params.output_jsn = true; }
else if (arg == "-ojf" || arg == "--output-json-full"){ params.output_jsn_full = params.output_jsn = true; }
else if (arg == "-of" || arg == "--output-file") { params.fname_out.emplace_back(argv[++i]); }
else if (arg == "-np" || arg == "--no-prints") { params.no_prints = false; }
else if (arg == "-ps" || arg == "--print-special") { params.print_special = true; }
else if (arg == "-pc" || arg == "--print-colors") { params.print_colors = true; }
else if (arg == "-pp" || arg == "--print-progress") { params.print_progress = true; }
else if (arg == "-nt" || arg == "--no-timestamps") { params.no_timestamps = true; }
else if (arg == "-l" || arg == "--language") { params.language = sense_voice_param_turn_lowercase(argv[++i]); }
else if (arg == "-dl" || arg == "--detect-language") { params.detect_language = true; }
else if ( arg == "--prompt") { params.prompt = argv[++i]; }
else if (arg == "-m" || arg == "--model") { params.model = argv[++i]; }
else if (arg == "-f" || arg == "--file") { params.fname_inp.emplace_back(argv[++i]); }
else if (arg == "-oved" || arg == "--ov-e-device") { params.openvino_encode_device = argv[++i]; }
else if (arg == "-ls" || arg == "--log-score") { params.log_score = true; }
else if (arg == "-ng" || arg == "--no-gpu") { params.use_gpu = false; }
else if (arg == "-fa" || arg == "--flash-attn") { params.flash_attn = true; }
else if ( arg == "--grammar-penalty") { params.grammar_penalty = std::stof(argv[++i]); }
else if (arg == "-itn" || arg == "--use-itn") { params.use_itn = true; }
else if (arg == "-prefix" || arg == "--use-prefix") { params.use_prefix = true; }
else {
fprintf(stderr, "error: unknown argument: %s\n", arg.c_str());
sense_voice_print_usage(argc, argv, params);
exit(0);
}
}
return true;
}
static bool is_file_exist(const char *fileName)
{
std::ifstream infile(fileName);
return infile.good();
}
/**
* This the arbitrary data which will be passed to each callback.
* Later on we can for example add operation or tensor name filter from the CLI arg, or a file descriptor to dump the tensor.
*/
struct callback_data {
std::vector<uint8_t> data;
};
static std::string ggml_ne_string(const ggml_tensor * t) {
std::string str;
for (int i = 0; i < GGML_MAX_DIMS; ++i) {
str += std::to_string(t->ne[i]);
if (i + 1 < GGML_MAX_DIMS) {
str += ", ";
}
}
return str;
}
static void ggml_print_tensor(uint8_t * data, ggml_type type, const int64_t * ne, const size_t * nb, int64_t n) {
GGML_ASSERT(n > 0);
float sum = 0;
for (int64_t i3 = 0; i3 < ne[3]; i3++) {
printf(" [\n");
for (int64_t i2 = 0; i2 < ne[2]; i2++) {
if (i2 == n && ne[2] > 2*n) {
printf(" ..., \n");
i2 = ne[2] - n;
}
printf(" [\n");
for (int64_t i1 = 0; i1 < ne[1]; i1++) {
if (i1 == n && ne[1] > 2*n) {
printf(" ..., \n");
i1 = ne[1] - n;
}
printf(" [");
for (int64_t i0 = 0; i0 < ne[0]; i0++) {
if (i0 == n && ne[0] > 2*n) {
printf("..., ");
i0 = ne[0] - n;
}
size_t i = i3 * nb[3] + i2 * nb[2] + i1 * nb[1] + i0 * nb[0];
float v = 0;
if (type == GGML_TYPE_F16) {
v = ggml_fp16_to_fp32(*(ggml_fp16_t *) &data[i]);
} else if (type == GGML_TYPE_F32) {
v = *(float *) &data[i];
} else if (type == GGML_TYPE_I32) {
v = (float) *(int32_t *) &data[i];
} else if (type == GGML_TYPE_I16) {
v = (float) *(int16_t *) &data[i];
} else if (type == GGML_TYPE_I8) {
v = (float) *(int8_t *) &data[i];
} else {
printf("fatal error");
}
printf("%12.4f", v);
sum += v;
if (i0 < ne[0] - 1) printf(", ");
}
printf("],\n");
}
printf(" ],\n");
}
printf(" ]\n");
printf(" sum = %f\n", sum);
}
}
/**
* GGML operations callback during the graph execution.
*
* @param t current tensor
* @param ask when ask is true, the scheduler wants to know if we are interested in data from this tensor
* if we return true, a follow-up call will be made with ask=false in which we can do the actual collection.
* see ggml_backend_sched_eval_callback
* @param user_data user data to pass at each call back
* @return true to receive data or continue the graph, false otherwise
*/
static bool ggml_debug(struct ggml_tensor * t, bool ask, void * user_data) {
auto * cb_data = (callback_data *) user_data;
const struct ggml_tensor * src0 = t->src[0];
const struct ggml_tensor * src1 = t->src[1];
if (ask) {
return true; // Always retrieve data
}
char src1_str[128] = {0};
if (src1) {
snprintf(src1_str, sizeof(src1_str), "%s{%s}", src1->name, ggml_ne_string(src1).c_str());
}
printf("%s: %24s = (%s) %10s(%s{%s}, %s}) = {%s}\n", __func__,
t->name, ggml_type_name(t->type), ggml_op_desc(t),
src0->name, ggml_ne_string(src0).c_str(),
src1 ? src1_str : "",
ggml_ne_string(t).c_str());
// copy the data from the GPU memory if needed
const bool is_host = ggml_backend_buffer_is_host(t->buffer);
if (!is_host) {
auto n_bytes = ggml_nbytes(t);
cb_data->data.resize(n_bytes);
ggml_backend_tensor_get(t, cb_data->data.data(), 0, n_bytes);
}
if (!ggml_is_quantized(t->type)) {
uint8_t * data = is_host ? (uint8_t *) t->data : cb_data->data.data();
ggml_print_tensor(data, t->type, t->ne, t->nb, 3);
}
return true;
}
void sense_voice_free(struct sense_voice_context * ctx) {
if (ctx) {
ggml_free(ctx->model.ctx);
//ggml_free(ctx->vad_model.ctx); // not used.
ggml_backend_buffer_free(ctx->model.buffer);
ggml_backend_buffer_free(ctx->vad_model.buffer);
sense_voice_free_state(ctx->state);
delete ctx->model.model->encoder;
delete ctx->model.model;
delete ctx->vad_model.model;
delete ctx;
}
}
int main(int argc, char ** argv) {
sense_voice_params params;
if (!sense_voice_params_parse(argc, argv, params)) {
sense_voice_print_usage(argc, argv, params);
return 1;
}
// remove non-existent files
for (auto it = params.fname_inp.begin(); it != params.fname_inp.end();) {
const auto fname_inp = it->c_str();
if (*it != "-" && !is_file_exist(fname_inp)) {
fprintf(stderr, "error: input file not found '%s'\n", fname_inp);
it = params.fname_inp.erase(it);
continue;
}
it++;
}
if (params.fname_inp.empty()) {
fprintf(stderr, "error: no input files specified\n");
sense_voice_print_usage(argc, argv, params);
return 2;
}
if (params.language != "auto" && sense_voice_lang_id(params.language.c_str()) == -1) {
fprintf(stderr, "error: unknown language '%s'\n", params.language.c_str());
sense_voice_print_usage(argc, argv, params);
exit(0);
}
// sense-voice init
struct sense_voice_context_params cparams = sense_voice_context_default_params();
callback_data cb_data;
cparams.cb_eval = ggml_debug;
cparams.cb_eval_user_data = &cb_data;
cparams.use_gpu = params.use_gpu;
cparams.flash_attn = params.flash_attn;
cparams.use_itn = params.use_itn;
struct sense_voice_context * ctx = sense_voice_small_init_from_file_with_params(params.model.c_str(), cparams);
if (ctx == nullptr) {
fprintf(stderr, "error: failed to initialize sense voice context\n");
return 3;
}
ctx->language_id = sense_voice_lang_id(params.language.c_str());
for (int f = 0; f < (int) params.fname_inp.size(); ++f) {
const auto fname_inp = params.fname_inp[f];
const auto fname_out = f < (int) params.fname_out.size() && !params.fname_out[f].empty() ? params.fname_out[f] : params.fname_inp[f];
std::vector<double> pcmf32; // mono-channel F32 PCM
int sample_rate;
if (!::load_wav_file(fname_inp.c_str(), &sample_rate, pcmf32)) {
fprintf(stderr, "error: failed to read WAV file '%s'\n", fname_inp.c_str());
continue;
}
if (!params.no_prints) {
// print system information
fprintf(stderr, "\n");
fprintf(stderr, "system_info: n_threads = %d / %d | %s\n",
params.n_threads*params.n_processors, std::thread::hardware_concurrency(), sense_voice_print_system_info());
// print some info about the processing
fprintf(stderr, "\n");
fprintf(stderr, "%s: processing audio (%d samples, %.5f sec) , %d threads, %d processors, lang = %s...\n",
__func__, int(pcmf32.size()), float(pcmf32.size())/sample_rate,
params.n_threads, params.n_processors,
params.language.c_str());
ctx->state->duration = float(pcmf32.size())/sample_rate;
fprintf(stderr, "\n");
}
sense_voice_full_params wparams = sense_voice_full_default_params(SENSE_VOICE_SAMPLING_GREEDY);
{
wparams.strategy = (params.beam_size > 1 ) ? SENSE_VOICE_SAMPLING_BEAM_SEARCH : SENSE_VOICE_SAMPLING_GREEDY;
wparams.print_progress = params.print_progress;
wparams.print_timestamps = !params.no_timestamps;
wparams.language = params.language.c_str();
wparams.n_threads = params.n_threads;
wparams.n_max_text_ctx = params.max_context >= 0 ? params.max_context : wparams.n_max_text_ctx;
wparams.offset_ms = params.offset_t_ms;
wparams.duration_ms = params.duration_ms;
wparams.debug_mode = params.debug_mode;
wparams.greedy.best_of = params.best_of;
wparams.beam_search.beam_size = params.beam_size;
wparams.no_timestamps = params.no_timestamps;
int n_pad = 0;
std::vector<float> chunk(CONTEXT_SIZE + SENSE_VOICE_VAD_CHUNK_PAD_SIZE, 0);
// run vad and asr
{
// init state
ctx->state->vad_ctx = ggml_init({VAD_LSTM_STATE_MEMORY_SIZE, nullptr, true});
ctx->state->vad_lstm_context = ggml_new_tensor_1d(ctx->state->vad_ctx, GGML_TYPE_F32, VAD_LSTM_STATE_DIM);
ctx->state->vad_lstm_hidden_state = ggml_new_tensor_1d(ctx->state->vad_ctx, GGML_TYPE_F32, VAD_LSTM_STATE_DIM);
ctx->state->vad_lstm_context_buffer = ggml_backend_alloc_buffer(ctx->state->backends[0],
ggml_nbytes(ctx->state->vad_lstm_context)
+ ggml_backend_get_alignment(ctx->state->backends[0]));
ctx->state->vad_lstm_hidden_state_buffer = ggml_backend_alloc_buffer(ctx->state->backends[0],
ggml_nbytes(ctx->state->vad_lstm_hidden_state)
+ ggml_backend_get_alignment(ctx->state->backends[0]));
auto context_alloc = ggml_tallocr_new(ctx->state->vad_lstm_context_buffer);
ggml_tallocr_alloc(&context_alloc, ctx->state->vad_lstm_context);
auto state_alloc = ggml_tallocr_new(ctx->state->vad_lstm_hidden_state_buffer);
ggml_tallocr_alloc(&state_alloc, ctx->state->vad_lstm_hidden_state);
ggml_set_zero(ctx->state->vad_lstm_context);
ggml_set_zero(ctx->state->vad_lstm_hidden_state);
}
int offset = offset = CHUNK_SIZE - CONTEXT_SIZE;
auto & sched = ctx->state->sched_vad.sched;
// ggml_backend_sched_set_eval_callback(sched, ctx->params.cb_eval, &ctx->params.cb_eval_user_data);
// var for vad
bool triggered = false;
int32_t temp_end = 0;
int32_t prev_end = 0, next_start = 0;
int32_t current_speech_start = 0, current_speech_end = 0;
int32_t min_speech_samples = sample_rate * params.min_speech_duration_ms / 1000;
int32_t speech_pad_samples = sample_rate * params.speech_pad_ms / 1000;
int32_t max_speech_samples = sample_rate * params.max_speech_duration_ms / 1000 - CHUNK_SIZE - 2 * speech_pad_samples;
int32_t min_silence_samples = sample_rate * params.min_silence_duration_ms / 1000;
int32_t min_silence_samples_at_max_speech = sample_rate * 98 / 1000;
std::vector<double> speech_segment;
for (int i = 0; i < pcmf32.size(); i += CHUNK_SIZE){
n_pad = CHUNK_SIZE <= pcmf32.size() - i ? 0 : CHUNK_SIZE + i - pcmf32.size();
for (int j = i + offset; j < i + CHUNK_SIZE; j++) {
if (j > 0 && j < i + CONTEXT_SIZE - n_pad && j < pcmf32.size()){
chunk[j - i - offset] = pcmf32[j] / 32768;
} else{
//pad chunk when first chunk in left or data not enough in right
chunk[j - i - offset] = 0;
}
}
// implements reflection pad
for (int j = CONTEXT_SIZE; j < chunk.size(); j++) {
chunk[j] = chunk[2 * CONTEXT_SIZE - j - 2];
}
{
if (triggered && i - current_speech_start > max_speech_samples) {
if (prev_end) {
current_speech_end = prev_end;
// find an endpoint in speech
speech_segment.clear();
speech_segment.assign(pcmf32.begin() + current_speech_start, pcmf32.begin() + current_speech_end);
printf("[%.2f-%.2f] ", current_speech_start / (sample_rate * 1.0), current_speech_end / (sample_rate * 1.0));
if (sense_voice_full_parallel(ctx, wparams, speech_segment, speech_segment.size(), params.n_processors) != 0) {
fprintf(stderr, "%s: failed to process audio\n", argv[0]);
return 10;
}
sense_voice_print_output(ctx, params.use_prefix, params.use_itn, false);
current_speech_end = current_speech_start = 0;
if (next_start < prev_end) {
triggered = false;
} else {
current_speech_start = next_start;
}
prev_end = 0;
}
}
float speech_prob = 0;
silero_vad_encode_internal(*ctx, *ctx->state, chunk, params.n_threads, speech_prob);
if (speech_prob >= params.threshold) {
if (temp_end) temp_end = 0;
if (next_start < prev_end) next_start = i;
}
if (speech_prob >= params.threshold && !triggered) {
triggered = true;
current_speech_start = i;
continue;
}
if (speech_prob < params.neg_threshold && triggered) {
if (temp_end == 0) {
temp_end = i;
}
if (i - temp_end > min_silence_samples_at_max_speech) {
prev_end = temp_end;
} else {
continue;
}
// TODO min_silence_samples -> max_silence_samples
if (i - prev_end < min_silence_samples) {
continue;
} else {
current_speech_end = prev_end;
if (current_speech_end - current_speech_start > min_speech_samples) {
// find an endpoint in speech
speech_segment.clear();
speech_segment.assign(pcmf32.begin() + current_speech_start, pcmf32.begin() + current_speech_end);
printf("[%.2f-%.2f] ", current_speech_start / (sample_rate * 1.0), current_speech_end / (sample_rate * 1.0));
if (sense_voice_full_parallel(ctx, wparams, speech_segment, speech_segment.size(), params.n_processors) != 0) {
fprintf(stderr, "%s: failed to process audio\n", argv[0]);
return 10;
}
sense_voice_print_output(ctx, params.use_prefix, params.use_itn, false);
current_speech_end = current_speech_start = 0;
}
prev_end = next_start = 0;
triggered = false;
continue;
}
}
}
}
// last segment speech
if (triggered && pcmf32.size() - 1 - current_speech_start > min_speech_samples) {
if (temp_end) {
current_speech_end = temp_end;
} else {
current_speech_end = pcmf32.size() - 1;
}
speech_segment.clear();
speech_segment.assign(pcmf32.begin() + current_speech_start, pcmf32.begin() + current_speech_end);
printf("[%.2f-%.2f] ", current_speech_start / (sample_rate * 1.0), current_speech_end / (sample_rate * 1.0));
if (sense_voice_full_parallel(ctx, wparams, speech_segment, speech_segment.size(), params.n_processors) != 0) {
fprintf(stderr, "%s: failed to process audio\n", argv[0]);
return 10;
}
sense_voice_print_output(ctx, true, params.use_prefix, false);
}
}
SENSE_VOICE_LOG_INFO("\n%s: decoder audio use %f s, rtf is %f. \n\n",
__func__,
(ctx->state->t_encode_us + ctx->state->t_decode_us) / 1e6,
(ctx->state->t_encode_us + ctx->state->t_decode_us) / (1e6 * ctx->state->duration));
}
sense_voice_free(ctx);
return 0;
}
说明
1. 头文件与宏定义
- 引入依赖库、工具函数、语音模型、VAD 模块
- 定义音频分块大小、VAD 状态尺寸等固定参数
2. 参数结构体 sense_voice_params
- 存放所有命令行可配置参数
- 包括线程数、模型路径、语言、VAD 阈值、输出格式、温度、beam 搜索等
3. 硬件支持检测
- 判断是否支持 CoreML、OpenVINO
- 输出 CPU 指令集支持情况(AVX/Neon/FMA 等)
4. 系统信息打印
- 输出当前设备的计算能力,方便调试
5. 命令行帮助说明
- 打印
-h时显示所有可用参数 - 告诉用户怎么用、每个参数是什么
6. 命令行参数解析
- 读取用户输入的命令(线程、模型、语言、VAD 参数等)
- 把参数存入配置结构体
- 不认识的参数直接报错退出
7. 文件检查工具
- 判断输入的音频文件是否存在
8. GGML 调试回调
- GGML 张量计算时的调试输出
- 打印模型运算过程、张量形状、数值
- 用于开发调试,正常运行不用
9. 模型释放函数
- 安全释放模型内存、上下文、缓冲区
- 防止内存泄漏
10. 主函数 main(核心逻辑)
这是整个程序的入口,按步骤执行:
- 解析命令行参数
- 检查输入音频文件是否存在
- 检查语言是否合法
- 初始化 SenseVoice 模型上下文
- 加载 WAV 音频
- 初始化 Silero VAD 语音检测状态
- 按固定块读取音频流
- VAD 语音分段(核心)
- 判断哪一段是人声
- 过滤静音、噪声
- 自动切分语音片段
- 对每段语音调用 SenseVoice 识别
- 输出识别结果 + 时间戳
- 打印性能(耗时、RTF 实时率)
- 释放资源,退出程序
人人皆为创造者,共创方能共成长
每个人都是使用者,也是创造者;是数字世界的消费者,更是价值的生产者与分享者。在智能时代的浪潮里,单打独斗的发展模式早已落幕,唯有开放连接、创意共创、利益共享,才能让个体价值汇聚成生态合力,让技术与创意双向奔赴,实现平台与伙伴的快速成长、共赢致远。
原创永久分成,共赴星辰大海
原创创意共创、永久收益分成,是东方仙盟始终坚守的核心理念。我们坚信,每一份原创智慧都值得被尊重与回馈,以永久分成锚定共创初心,让创意者长期享有价值红利,携手万千伙伴向着科技星辰大海笃定前行,拥抱硅基 生命与数字智能交融的未来,共筑跨越时代的数字文明共同体。
东方仙盟:拥抱知识开源,共筑数字新生态
在全球化与数字化浪潮中,东方仙盟始终秉持开放协作、知识共享的理念,积极拥抱开源技术与开放标准。我们相信,唯有打破技术壁垒、汇聚全球智慧,才能真正推动行业的可持续发展。
开源赋能中小商户:通过将前端异常检测、跨系统数据互联等核心能力开源化,东方仙盟为全球中小商户提供了低成本、高可靠的技术解决方案,让更多商家能够平等享受数字转型的红利。
共建行业标准:我们积极参与国际技术社区,与全球开发者、合作伙伴共同制定开放协议 与技术规范,推动跨境零售、文旅、餐饮等多业态的系统互联互通,构建更加公平、高效的数字生态。
知识普惠,共促发展:通过开源社区 、技术文档与培训体系,东方仙盟致力于将前沿技术转化为可落地的行业实践,赋能全球合作伙伴,共同培育创新人才,推动数字经济 的普惠式增长
阿雪技术观
在科技发展浪潮中,我们不妨积极投身技术共享。不满足于做受益者,更要主动担当贡献者。无论是分享代码、撰写技术博客,还是参与开源项目 维护改进,每一个微小举动都可能蕴含推动技术进步的巨大能量。东方仙盟是汇聚力量的天地,我们携手在此探索硅基 生命,为科技进步添砖加瓦。
Hey folks, in this wild tech - driven world, why not dive headfirst into the whole tech - sharing scene? Don't just be the one reaping all the benefits; step up and be a contributor too. Whether you're tossing out your code snippets , hammering out some tech blogs, or getting your hands dirty with maintaining and sprucing up open - source projects, every little thing you do might just end up being a massive force that pushes tech forward. And guess what? The Eastern FairyAlliance is this awesome place where we all come together. We're gonna team up and explore the whole silicon - based life thing, and in the process, we'll be fueling the growth of technology

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 14
14 0
0- 0



 已为社区贡献35条内容
已为社区贡献35条内容

所有评论(0)