从 0 到 1 构建企业级 Agent:LangChain 2026 终极实战指南
从 0 到 1 构建企业级 Agent:LangChain 2026 终极实战指南
开发者张三刚接手一个智能客服项目,信心满满地写好 Prompt,上线第一天就被用户吐槽"记不住上下文"、“答非所问”、“调用外部接口三天两头报错”。这不是模型不行,而是你缺了一层 Agent 编排框架。
2026 年的 AI 开发早已不是简单调用 API 的时代。当大模型从"对话者"进化为"执行者",LangChain 作为企业级 Agent 开发的事实标准,已成为每个 Agent 开发者的必修课。本文将从实战角度,带你彻底掌握 LangChain,并解锁多 Agent 协作、生产环境部署等进阶技能。
文章目录
一、开篇痛点:为什么你需要 LangChain?
1.1 纯大模型的三大致命缺陷
❌ 缺陷 1:无记忆能力 每次对话都是全新的开始,无法记住用户的历史信息、偏好设定、业务上下文。
❌ 缺陷 2:工具调用困难 需要查询数据库、调用 API、执行代码时,纯 LLM 无能为力,只能返回"我无法执行此操作"。
❌ 缺陷 3:状态管理混乱 多步骤任务执行过程中,难以追踪进度、处理异常、实现重试机制。
1.2 LangChain 的解决方案
LangChain 就像一个"AI 操作系统",它为大模型提供了:
- 记忆模块:对话历史、长期记忆、向量知识库
- 工具箱:100+ 预集成工具(搜索、数据库、文件操作等)
- 工作流引擎:链式调用、Agent 编排、多 Agent 协作
- 可观测性:日志追踪、性能监控、调试工具
二、基础篇:LangChain 核心概念速通
2.1 架构全景图
LangChain 采用分层架构设计:
| 层级 | 组件 | 核心功能 |
|---|---|---|
| 核心层 | langchain-core | 基础抽象、LCEL 语法、Runnable 接口 |
| 集成层 | langchain-community | 600+ 第三方模型/工具/向量库集成 |
| 组件层 | langchain | Chains、Agents、Retrieval 等业务组件 |
| 应用层 | langgraph | Agent 编排、状态管理、复杂工作流 |
2.2 核心组件详解
2.2.1 Model I/O:统一模型接口
Model I/O 是应用与 LLM 交互的核心模块,类似 JDBC 与数据库的关系。
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
# 初始化模型
llm = ChatOpenAI(
model="gpt-4o",
temperature=0.7,
api_key="your-api-key"
)
# 构建提示模板
prompt = ChatPromptTemplate.from_template(
"你是一个{role}。请用{style}风格回答:{question}"
)
# 使用LCEL语法组合链(推荐方式)
chain = prompt | llm | StrOutputParser()
# 调用
result = chain.invoke({
"role": "技术专家",
"style": "简洁专业",
"question": "什么是LangChain?"
})
print(result)
2.2.2 Chains:链式工作流
Chains 将多个组件串联成自动化工作流,实现步骤化任务处理。
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
# 传统方式(已废弃,仅供参考)
prompt = PromptTemplate(
input_variables=["topic"],
template="写一篇关于{topic}的技术文章摘要"
)
chain = LLMChain(llm=llm, prompt=prompt)
# 新推荐方式:使用LCEL
summary_chain = (
PromptTemplate.from_template("写一篇关于{topic}的技术文章摘要")
| llm
| StrOutputParser()
)
2.2.3 Memory:记忆管理
Memory 模块管理对话历史和长期记忆。
from langchain.memory import ConversationBufferMemory
from langchain.chains import ConversationChain
# 创建带记忆的对话链
memory = ConversationBufferMemory()
conversation = ConversationChain(
llm=llm,
memory=memory,
verbose=True
)
# 多轮对话
conversation.predict(input="我叫张三,是一名AI工程师")
conversation.predict(input="我刚才自我介绍时说了什么?") # 能记住
2.2.4 Tools:工具集成
LangChain 预集成了 100+ 工具,也可轻松自定义。
from langchain_community.tools import TavilySearchResults
from langchain_core.tools import tool
# 使用预置搜索工具
search_tool = TavilySearchResults(
max_results=3,
search_depth="advanced",
api_key="your-tavily-key"
)
# 自定义工具
@tool
def calculate(expression: str) -> str:
"""执行数学表达式计算"""
try:
result = eval(expression)
return f"计算结果:{result}"
except Exception as e:
return f"计算错误:{str(e)}"
2.3 安装配置速查表
# 创建虚拟环境(推荐)
python -m venv langchain-env
source langchain-env/bin/activate # Linux/Mac
langchain-env\Scripts\activate # Windows
# 安装核心依赖
pip install -U langchain langchain-openai langchain-community
pip install -U tavily-python chromadb
# 设置环境变量
export OPENAI_API_KEY="your-key"
export TAVILY_API_KEY="your-key"
三、进阶篇:Agent 开发深度实践
3.1 Agent 开发流程全景
一个完整的 Agent 开发包含以下 5 个步骤:
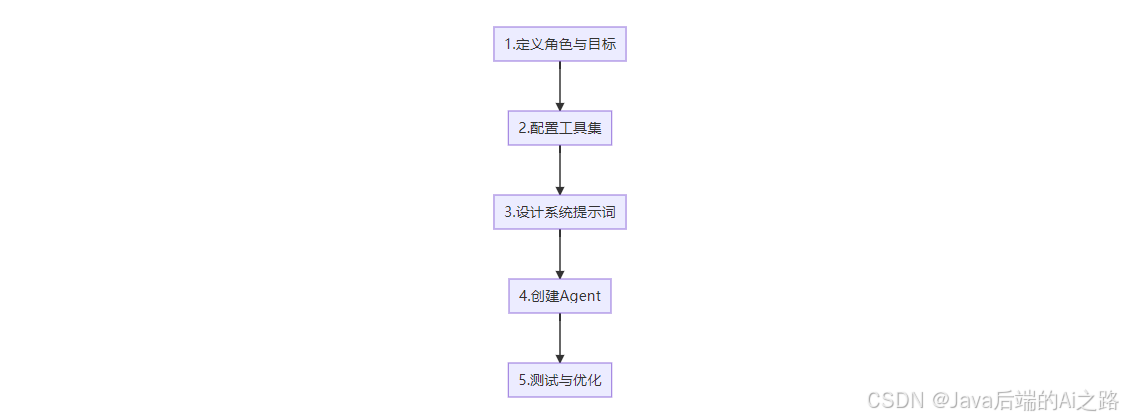
步骤 1:定义角色与目标
from langchain.agents import create_tool_calling_agent
from langchain_openai import ChatOpenAI
# 明确Agent的定位
AGENT_ROLE = "资深技术文档分析师"
AGENT_GOAL = "分析技术文档并生成结构化摘要"
AGENT_BACKSTORY = """
你拥有10年技术文档分析经验,擅长从复杂技术文档中提取核心概念、
技术架构、关键参数,并以清晰易懂的方式呈现给不同技术背景的读者。
"""
步骤 2:配置工具集
from langchain_community.tools import (
TavilySearchResults,
WikipediaQueryRun
)
from langchain_community.utilities import WikipediaAPIWrapper
# 组装工具箱
tools = [
TavilySearchResults(max_results=3),
WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper()),
calculate
]
步骤 3:设计系统提示词
system_prompt = f"""
你是{AGENT_ROLE}。
你的目标是:{AGENT_GOAL}
背景信息:{AGENT_BACKSTORY}
工作流程:
1. 理解用户的查询意图
2. 必要时使用搜索工具获取最新信息
3. 分析并整理信息
4. 生成结构化摘要
输出格式:
- 核心概念:[关键词]
- 技术要点:[要点列表]
- 参考来源:[链接或文档名]
"""
步骤 4:创建 Agent
from langchain_core.prompts import ChatPromptTemplate
from langchain.agents import AgentExecutor
# 使用LangChain 1.0新API
agent = create_tool_calling_agent(
llm=llm,
tools=tools,
prompt=ChatPromptTemplate.from_messages([
("system", system_prompt),
("placeholder", "{chat_history}"),
("human", "{input}"),
("placeholder", "{agent_scratchpad}")
])
)
# 创建执行器
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
verbose=True,
handle_parsing_errors=True
)
步骤 5:测试与优化
# 测试Agent
result = agent_executor.invoke({
"input": "分析LangGraph的最新特性"
})
print(result['output'])
3.2 记忆机制实战
3.2.1 对话记忆:BufferWindowMemory
from langchain.memory import ConversationBufferWindowMemory
# 只保留最近5轮对话
window_memory = ConversationBufferWindowMemory(k=5)
conversation = ConversationChain(
llm=llm,
memory=window_memory
)
3.2.2 向量记忆:基于 Chroma 的长期记忆
from langchain_chroma import Chroma
from langchain_openai import OpenAIEmbeddings
from langchain_core.documents import Document
# 初始化向量数据库
embeddings = OpenAIEmbeddings()
vector_store = Chroma(
collection_name="agent_memory",
embedding_function=embeddings,
persist_directory="./chroma_db"
)
# 存储重要信息
documents = [
Document(
page_content="用户偏好:喜欢简洁的技术文档,避免冗余示例",
metadata={"type": "preference", "priority": "high"}
)
]
vector_store.add_documents(documents)
# 检索相关记忆
def retrieve_memory(query: str, k: int = 3):
results = vector_store.similarity_search(query, k=k)
return "\n".join([doc.page_content for doc in results])
3.3 向量数据库集成
3.3.1 Chroma:轻量级首选(适合开发/小规模)
from langchain_chroma import Chroma
from langchain_openai import OpenAIEmbeddings
# 初始化Chroma
embeddings = OpenAIEmbeddings()
chroma_store = Chroma(
collection_name="knowledge_base",
embedding_function=embeddings,
persist_directory="./chroma_db"
)
# 添加文档
chroma_store.add_texts(
texts=["LangChain是强大的AI应用开发框架"],
metadatas=[{"source": "official", "category": "intro"}]
)
# 检索
results = chroma_store.similarity_search("LangChain是什么", k=2)
3.3.2 Pinecone:企业级托管(适合生产环境)
from langchain_pinecone import PineconeVectorStore
import pinecone
# 初始化Pinecone
pinecone.init(
api_key="your-pinecone-key",
environment="us-east1-gcp"
)
# 创建索引(需提前在官网创建)
index_name = "langchain-prod"
pinecone_index = pinecone.Index(index_name)
# 创建向量存储
vector_store = PineconeVectorStore(
index=pinecone_index,
embedding=embeddings
)
# 检索(支持元数据过滤)
results = vector_store.similarity_search(
query="最新技术",
k=5,
filter={"category": "technology"}
)
| 特性 | Chroma | Pinecone |
|---|---|---|
| 部署方式 | 本地/云端 | 全托管 |
| 适用规模 | <100 万向量 | 千万级 + |
| 成本 | 免费(本地) | 按量计费 |
| 推荐场景 | 开发测试、小规模应用 | 生产环境、大规模应用 |
四、实战篇:3 个完整可运行案例
案例 1:智能文档问答 Agent(RAG)
场景:基于企业知识库构建智能问答系统
from langchain_chroma import Chroma
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain.chains import create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_core.prompts import ChatPromptTemplate
from langchain.text_splitter import RecursiveCharacterTextSplitter
# ========== 1. 准备知识库 ==========
sample_docs = [
"LangChain是一个强大的AI应用开发框架,支持链式调用、Agent编排、记忆管理等功能。",
"LangGraph是LangChain生态中的工作流编排框架,适合构建复杂的多Agent系统。",
"LangSmith是LangChain的可观测性平台,提供追踪、监控、调试等功能。"
]
# 文档分块
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=200,
chunk_overlap=50
)
splits = text_splitter.create_documents(sample_docs)
# 创建向量存储
embeddings = OpenAIEmbeddings()
vector_store = Chroma.from_documents(
documents=splits,
embedding=embeddings,
persist_directory="./doc_qa_db"
)
retriever = vector_store.as_retriever(search_kwargs={"k": 2})
# ========== 2. 构建RAG链 ==========
llm = ChatOpenAI(model="gpt-4o", temperature=0)
# 提示词模板
prompt = ChatPromptTemplate.from_template("""
你是一个智能文档问答助手。请基于以下参考信息回答问题:
参考信息:
{context}
问题:{input}
如果参考信息中没有答案,请明确告知"参考信息中没有找到相关内容"。
""")
# 创建文档链
document_chain = create_stuff_documents_chain(llm, prompt)
# 创建检索链
retrieval_chain = create_retrieval_chain(
retriever=retriever,
combine_docs_chain=document_chain
)
# ========== 3. 测试 ==========
questions = [
"LangChain有哪些核心功能?",
"LangGraph和LangChain的关系是什么?",
"LangSmith是做什么的?"
]
for q in questions:
print(f"\n问题:{q}")
result = retrieval_chain.invoke({"input": q})
print(f"答案:{result['answer']}")
print(f"参考来源:{[doc.metadata for doc in result['context']]}")
运行效果示例:
问题:LangChain有哪些核心功能?
答案:根据参考信息,LangChain的核心功能包括:链式调用、Agent编排、记忆管理等。
参考来源:[{'source': 'doc1'}, {'source': 'doc1'}]
案例 2:多智能体协作系统(Supervisor 架构)
场景:构建一个技术调研团队,包含研究员、分析师、文档员三个角色
from langchain_openai import ChatOpenAI
from langchain.agents import AgentExecutor, create_tool_calling_agent
from langchain_core.tools import tool
from langchain_core.prompts import ChatPromptTemplate
from langgraph.graph import StateGraph, END
from typing import TypedDict, Annotated
from operator import add
# ========== 1. 定义共享状态 ==========
class TeamState(TypedDict):
topic: str # 研究主题
research_result: str # 研究结果
analysis_result: str # 分析结果
final_document: str # 最终文档
messages: Annotated[list, add] # 消息历史
next_worker: str # 下一个执行者
# ========== 2. 创建工具 ==========
@tool
def search_tech_topic(topic: str) -> str:
"""搜索技术主题的相关信息"""
# 模拟搜索结果
return f"""
关于{topic}的搜索结果:
1. {topic}是当前热门技术趋势
2. 主要应用场景包括企业自动化、智能客服
3. 优势:提高效率、降低成本
4. 挑战:技术门槛、数据安全
"""
@tool
def analyze_research(data: str) -> str:
"""分析研究结果"""
return f"""
分析报告:
- 核心要点:{data[:50]}...
- 市场前景:广阔
- 技术成熟度:生产可用
- 建议行动:优先试点
"""
tools = [search_tech_topic, analyze_research]
# ========== 3. 创建三个专业Agent ==========
llm = ChatOpenAI(model="gpt-4o", temperature=0.7)
# 研究员Agent
researcher_prompt = ChatPromptTemplate.from_messages([
("system", "你是研究员,负责搜索并收集{topic}相关的技术资料"),
("human", "{input}"),
("placeholder", "{agent_scratchpad}")
])
researcher = create_tool_calling_agent(llm, tools, researcher_prompt)
researcher_executor = AgentExecutor(
agent=researcher, tools=tools, verbose=False
)
# 分析师Agent
analyst_prompt = ChatPromptTemplate.from_messages([
("system", "你是分析师,负责分析研究结果并提供专业见解"),
("human", "{input}"),
("placeholder", "{agent_scratchpad}")
])
analyst = create_tool_calling_agent(llm, [analyze_research], analyst_prompt)
analyst_executor = AgentExecutor(
agent=analyst, tools=[analyze_research], verbose=False
)
# 文档员Agent
def document_writer(state: TeamState):
"""文档员:生成最终文档"""
doc = f"""
# {state['topic']}技术调研报告
## 研究结果
{state['research_result']}
## 分析结论
{state['analysis_result']}
---
生成时间:2026年
"""
return {"final_document": doc, "next_worker": "FINISH"}
# ========== 4. 定义节点函数 ==========
def researcher_node(state: TeamState):
"""研究员节点"""
result = researcher_executor.invoke({
"input": f"调研{state['topic']}的最新进展",
"topic": state['topic']
})
return {
"research_result": result['output'],
"next_worker": "analyst"
}
def analyst_node(state: TeamState):
"""分析师节点"""
result = analyst_executor.invoke({
"input": f"分析以下研究结果:{state['research_result']}"
})
return {
"analysis_result": result['output'],
"next_worker": "writer"
}
# ========== 5. 构建工作流 ==========
workflow = StateGraph(TeamState)
# 添加节点
workflow.add_node("researcher", researcher_node)
workflow.add_node("analyst", analyst_node)
workflow.add_node("writer", document_writer)
# 设置入口
workflow.set_entry_point("researcher")
# 添加边
workflow.add_edge("researcher", "analyst")
workflow.add_edge("analyst", "writer")
workflow.add_edge("writer", END)
# 编译
app = workflow.compile()
# ========== 6. 运行 ==========
initial_state = {
"topic": "LangChain多Agent协作",
"messages": [],
"research_result": "",
"analysis_result": "",
"final_document": "",
"next_worker": ""
}
# 可视化工作流
try:
display(Image(app.get_graph().draw_mermaid_png()))
except:
print("无法显示工作流图,请安装graphviz")
# 执行
final_state = app.invoke(initial_state)
print(final_state['final_document'])
工作流架构:
用户请求
↓
研究员(搜索资料)
↓
分析师(深度分析)
↓
文档员(生成报告)
↓
返回结果
案例 3:具备记忆的对话式客服 Agent
场景:模拟智能客服,记住用户信息和对话历史
from langchain_openai import ChatOpenAI
from langchain.memory import ConversationBufferMemory
from langchain.chains import ConversationChain
from langchain_core.prompts import PromptTemplate
# ========== 1. 创建带记忆的对话链 ==========
memory = ConversationBufferMemory(
memory_key="chat_history",
return_messages=True
)
prompt = PromptTemplate.from_template("""
你是一个智能客服助手,名字叫"小智"。
对话历史:
{chat_history}
用户问题:{input}
请以友好、专业的方式回答。如果用户提到个人信息(如姓名、偏好),请记住。
""")
llm = ChatOpenAI(model="gpt-4o", temperature=0.8)
conversation = ConversationChain(
llm=llm,
memory=memory,
prompt=prompt,
verbose=True
)
# ========== 2. 模拟多轮对话 ==========
dialogues = [
"我叫李明,我是做电商的",
"我对AI自动化很感兴趣",
"你能帮我介绍一下AI在电商中的应用吗?",
"我刚才说我叫什么名字?", # 测试记忆
"我的职业是什么?" # 测试记忆
]
for user_input in dialogues:
print(f"\n用户:{user_input}")
response = conversation.predict(input=user_input)
print(f"小智:{response}")
# ========== 3. 查看记忆内容 ==========
print("\n=== 对话历史 ===")
print(memory.buffer)
输出示例:
用户:我叫李明,我是做电商的
小智:您好李明!很高兴认识您。电商行业现在发展很快,有什么我可以帮您的吗?
用户:我对AI自动化很感兴趣
小智:太好了!AI自动化在电商领域确实有很多应用场景。比如智能客服、商品推荐、库存预测等...
用户:你能帮我介绍一下AI在电商中的应用吗?
小智:当然可以!AI在电商中的应用主要包括:1. 智能客服(就像我这样的)2. 个性化推荐 3. 智能搜索...
用户:我刚才说我叫什么名字?
小智:您刚才说您叫李明。我一直记着呢!
用户:我的职业是什么?
小智:您是做电商的。这是一个很有前景的行业!
五、深度对比:LangChain vs 其他框架
5.1 主流框架对比表
| 框架 | 核心定位 | 多 Agent 能力 | 工具生态 | 学习曲线 | 推荐场景 |
|---|---|---|---|---|---|
| LangChain | 通用 AI 应用框架 | ⭐⭐⭐⭐ | 600+ 集成 | 中等 | 企业级应用、复杂工作流 |
| LangGraph | Agent 工作流编排 | ⭐⭐⭐⭐⭐ | 兼容 LangChain | 较陡 | 复杂多 Agent 协作 |
| CrewAI | 团队协作框架 | ⭐⭐⭐⭐⭐ | 兼容 LangChain | 简单 | 快速搭建团队型 Agent |
| AutoGen | 对话式多 Agent | ⭐⭐⭐⭐⭐ | 基础 | 较陡 | 科研、代码生成 |
| OpenAI Agents SDK | 原生轻量框架 | ⭐⭐⭐ | 丰富 | 简单 | 快速原型开发 |
5.2 选型决策树
需要多Agent协作?
├─ 是 → 需要复杂状态管理?
│ ├─ 是 → LangGraph(企业级复杂流程)
│ └─ 否 → CrewAI(快速团队协作)
└─ 否 → 需要丰富的工具集成?
├─ 是 → LangChain(通用场景)
└─ 否 → OpenAI Agents SDK(轻量原型)
5.3 LangChain 的独特优势
- 生态成熟度:600+ 集成,覆盖几乎所有主流服务
- 生产就绪:LangSmith 监控、LangServe 部署、分布式追踪
- 可观测性:内置日志、性能监控、调试工具
- 企业级特性:中间件机制、容错处理、版本管理
六、生产环境部署指南
6.1 部署架构图
┌─────────────────┐
│ 用户请求 │
└────────┬────────┘
│
┌────────▼────────┐
│ API Gateway │ (鉴权、限流、负载均衡)
└────────┬────────┘
│
┌────────▼────────┐
│ LangServe │ (Agent服务层)
└────────┬────────┘
│
┌────┴────┬────────┬────────┐
▼ ▼ ▼ ▼
┌─────┐ ┌─────┐ ┌─────┐ ┌─────┐
│Agent│ │Agent│ │Agent│ │Agent│
│ 1 │ │ 2 │ │ 3 │ │ N │
└──┬──┘ └──┬──┘ └──┬──┘ └──┬──┘
│ │ │ │
└───────┴───────┴───────┘
│
┌──────▼──────┐
│ 共享服务层 │ (Redis缓存、向量数据库、消息队列)
└─────────────┘
6.2 LangServe 快速部署
# ========== server.py ==========
from fastapi import FastAPI
from langserve import add_routes
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
app = FastAPI(title="LangChain Agent API")
# 创建Agent
llm = ChatOpenAI(model="gpt-4o")
prompt = ChatPromptTemplate.from_template("回答:{question}")
agent = prompt | llm
# 添加路由
add_routes(
app,
agent,
path="/chat",
enabled_endpoints=["invoke", "stream", "batch"]
)
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
# 启动服务
python server.py
# 测试
curl -X POST http://localhost:8000/chat/invoke \
-H "Content-Type: application/json" \
-d '{"input": {"question": "什么是LangChain?"}}'
6.3 性能优化清单
| 优化项 | 方法 | 效果 |
|---|---|---|
| 缓存 | 使用 Redis 缓存重复请求 | 降低 30-50% 成本 |
| 异步 | 使用 ainvoke 批量处理 |
提升吞吐量 2-3 倍 |
| 流式输出 | 使用 stream 减少延迟 |
用户体验提升 |
| 连接池 | 数据库/LLM 连接复用 | 减少连接开销 |
| 模型选择 | 按场景选择合适模型 | 成本降低 50-80% |
6.4 监控与调试
# 启用LangSmith追踪
import os
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = "your-langsmith-key"
# 查看追踪结果:https://smith.langchain.com/
七、常见问题 FAQ
Q1:LangChain 1.0 和旧版本有什么区别?
A:LangChain 1.0 是重大升级,核心变化:
- 统一为
create_agent()单一 API - LangGraph 作为底层运行时
- 引入 Middleware 机制
- 标准化消息格式
- 更好的可观测性
Q2:如何选择 Chroma vs Pinecone?
A:
- Chroma:本地开发、小规模应用、预算有限
- Pinecone:生产环境、大规模应用、需要高可用
Q3:Agent 调用失败怎么处理?
A:三层防护
# 1. 中间件自动重试
from langchain.agents.middleware import ToolRetryMiddleware
# 2. 设置超时
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
max_execution_time=30, # 30秒超时
handle_parsing_errors=True
)
# 3. Fallback机制
from langchain_openai import ChatOpenAI
llm_fallback = ChatOpenAI(model="gpt-3.5-turbo")
Q4:如何降低 Token 成本?
A:5 个技巧
- 使用缓存(Redis)
- 优化 Prompt 长度
- 选择性价比高的模型(如 gpt-4o-mini)
- 启用记忆压缩(LangChain 自主压缩)
- 批量处理请求
Q5:多 Agent 协作的性能如何优化?
A:
- 并行执行:使用
asyncio.gather - 状态精简:只传递必要信息
- 工具池化:共享工具实例
- 结果缓存:避免重复计算
八、学习资源推荐
官方资源
- 📚 文档:https://python.langchain.com/
- 🛠️ LangSmith:https://smith.langchain.com/
- 📖 GitHub:https://github.com/langchain-ai/langchain
进阶学习路径
- 入门(1-2 周):官方文档 + 案例 1
- 进阶(2-4 周):案例 2 + 案例 3 + LangGraph
- 精通(1-2 月):生产环境部署 + 性能优化
- 大师(持续):参与开源、贡献社区
推荐项目
- GoldMind:多 Agent 黄金分析系统
- AutoGen:微软多 Agent 框架
- CrewAI:团队协作 Agent
九、总结与展望
LangChain 2026 已经从"实验性工具"进化为"企业级基础设施"。掌握 LangChain,意味着你拥有了:
✅ 快速构建 Agent 的能力 ✅ 处理复杂工作流的技巧 ✅ 生产环境部署的经验 ✅ 多 Agent 协作的视野
2026 年的 Agent 开发正在从"能不能做"转向"怎么做更好"。LangChain 作为事实标准,将持续引领这一变革。
💬 交流讨论:欢迎在评论区分享你的使用心得!
如果觉得有用,请点赞、收藏、转发,让更多开发者受益!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 17
17 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)