SenseVoicecpp 启动命令解释[AI人工智能(六十六)]—东方仙盟
sense-voice-main.exe
error: no input files specified
usage: sense-voice-main.exe [options] file0.wav file1.wav ...
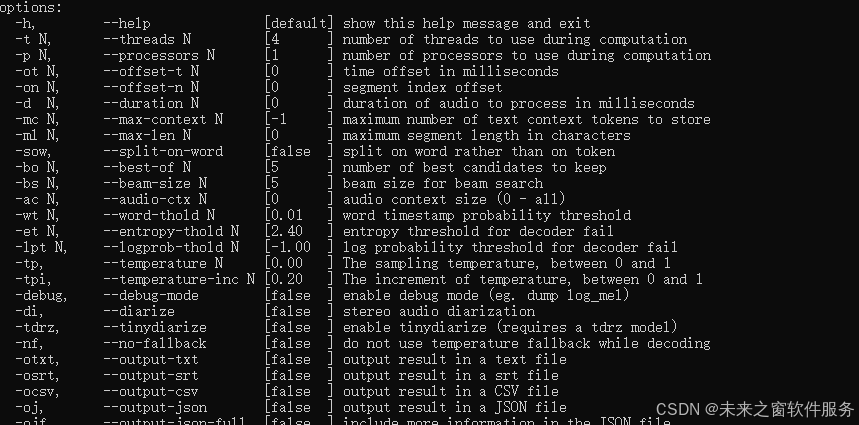
options:
-h, --help [default] show this help message and exit
-t N, --threads N [4 ] number of threads to use during computation
-p N, --processors N [1 ] number of processors to use during computation
-ot N, --offset-t N [0 ] time offset in milliseconds
-on N, --offset-n N [0 ] segment index offset
-d N, --duration N [0 ] duration of audio to process in milliseconds
-mc N, --max-context N [-1 ] maximum number of text context tokens to store
-ml N, --max-len N [0 ] maximum segment length in characters
-sow, --split-on-word [false ] split on word rather than on token
-bo N, --best-of N [5 ] number of best candidates to keep
-bs N, --beam-size N [5 ] beam size for beam search
-ac N, --audio-ctx N [0 ] audio context size (0 - all)
-wt N, --word-thold N [0.01 ] word timestamp probability threshold
-et N, --entropy-thold N [2.40 ] entropy threshold for decoder fail
-lpt N, --logprob-thold N [-1.00 ] log probability threshold for decoder fail
-tp, --temperature N [0.00 ] The sampling temperature, between 0 and 1
-tpi, --temperature-inc N [0.20 ] The increment of temperature, between 0 and 1
-debug, --debug-mode [false ] enable debug mode (eg. dump log_mel)
-di, --diarize [false ] stereo audio diarization
-tdrz, --tinydiarize [false ] enable tinydiarize (requires a tdrz model)
-nf, --no-fallback [false ] do not use temperature fallback while decoding
-otxt, --output-txt [false ] output result in a text file
-osrt, --output-srt [false ] output result in a srt file
-ocsv, --output-csv [false ] output result in a CSV file
-oj, --output-json [false ] output result in a JSON file
-ojf, --output-json-full [false ] include more information in the JSON file
-of FNAME, --output-file FNAME [ ] output file path (without file extension)
-np, --no-prints [false ] do not print anything other than the results
-ps, --print-special [false ] print special tokens
-pc, --print-colors [false ] print colors
-pp, --print-progress [false ] print progress
-nt, --no-timestamps [false ] do not print timestamps
-l LANG, --language LANG [auto ] spoken language ('auto' for auto-detect), support [`zh`, `en`, `yue`, `ja`, `ko`
--prompt PROMPT [ ] initial prompt (max n_text_ctx/2 tokens)
-m FNAME, --model FNAME [models/ggml-base.en.bin] model path
-f FNAME, --file FNAME [ ] input WAV file path
--min_speech_duration_ms [250 ] min_speech_duration_ms
--max_speech_duration_ms [15000 ] log probability threshold for decoder fail
--min_silence_duration_ms [100 ] min_silence_duration_ms
--speech_pad_ms [30 ] speech_pad_ms
-oved D, --ov-e-device DNAME [CPU ] the OpenVINO device used for encode inference
-ls, --log-score [false ] log best decoder scores of tokens
-ng, --no-gpu [false ] disable GPU
-fa, --flash-attn [false ] flash attention
-itn, --use-itn [false ] use itn
-prefix, --use-prefix [false ] use itn
用法
plaintext
usage: sense-voice-main.exe [options] file0.wav file1.wav ...
翻译:用法 → 程序名 [参数选项] 音频文件 1 音频文件 2...正确示例:
plaintext
sense-voice-main.exe -l zh test.wav
常用参数 中文解释(最实用)
我只挑你一定会用到的,其他是高级调试用的,不用管:
表格
| 参数 | 全称 | 默认值 | 中文意思 |
|---|---|---|---|
-h |
--help |
默认 | 显示帮助信息 |
-l LANG |
--language LANG |
auto | 设置语言:zh = 中文,en = 英文,yue = 粤语,ja = 日语,ko = 韩语 |
-m FNAME |
--model FNAME |
models/... | 模型文件路径(必须放对) |
-f FNAME |
--file FNAME |
- | 输入音频路径(wav 格式) |
-osrt |
--output-srt |
false | 输出 SRT 字幕文件 |
-otxt |
--output-txt |
false | 输出纯文本文件 |
-nt |
--no-timestamps |
false | 不输出时间戳 |
-di |
--diarize |
false | 说话人分离(区分谁在说话) |
-np |
--no-prints |
false | 只输出结果,不打印多余信息 |
你最后问的那几个特殊参数
plaintext
-itn, --use-itn [false ] use itn
-prefix, --use-prefix [false ] use itn 意思
-
-itn / --use-itn- ITN = Inverse Text Normalization
- 意思:数字 / 符号标准化
- 作用:把语音识别的口语转成书面语比如:识别出 “一百二十三” → 自动转成 123“百分之五十” → 50%
-
-prefix / --use-prefix- 前缀提示功能
- 意思:给识别加固定开头文字
- 作用:比如你知道音频开头一定是 “大家好”,加上这个能提高识别准确率
最简可用命令(直接复制改文件名就能用)
1. 识别中文,输出字幕(最常用)
plaintext
sense-voice-main.exe -l zh -osrt -f 音频.wav
2. 识别粤语
plaintext
sense-voice-main.exe -l yue -osrt -f 音频.wav
3. 识别英文
plaintext
sense-voice-main.exe -l en -osrt -f 音频.wav
人人皆为创造者,共创方能共成长
每个人都是使用者,也是创造者;是数字世界的消费者,更是价值的生产者与分享者。在智能时代的浪潮里,单打独斗的发展模式早已落幕,唯有开放连接、创意共创、利益共享,才能让个体价值汇聚成生态合力,让技术与创意双向奔赴,实现平台与伙伴的快速成长、共赢致远。
原创永久分成,共赴星辰大海
原创创意共创、永久收益分成,是东方仙盟始终坚守的核心理念。我们坚信,每一份原创智慧都值得被尊重与回馈,以永久分成锚定共创初心,让创意者长期享有价值红利,携手万千伙伴向着科技星辰大海笃定前行,拥抱硅基 生命与数字智能交融的未来,共筑跨越时代的数字文明共同体。
东方仙盟:拥抱知识开源,共筑数字新生态
在全球化与数字化浪潮中,东方仙盟始终秉持开放协作、知识共享的理念,积极拥抱开源技术与开放标准。我们相信,唯有打破技术壁垒、汇聚全球智慧,才能真正推动行业的可持续发展。
开源赋能中小商户:通过将前端异常检测、跨系统数据互联等核心能力开源化,东方仙盟为全球中小商户提供了低成本、高可靠的技术解决方案,让更多商家能够平等享受数字转型的红利。
共建行业标准:我们积极参与国际技术社区,与全球开发者、合作伙伴共同制定开放协议 与技术规范,推动跨境零售、文旅、餐饮等多业态的系统互联互通,构建更加公平、高效的数字生态。
知识普惠,共促发展:通过开源社区 、技术文档与培训体系,东方仙盟致力于将前沿技术转化为可落地的行业实践,赋能全球合作伙伴,共同培育创新人才,推动数字经济 的普惠式增长
阿雪技术观
在科技发展浪潮中,我们不妨积极投身技术共享。不满足于做受益者,更要主动担当贡献者。无论是分享代码、撰写技术博客,还是参与开源项目 维护改进,每一个微小举动都可能蕴含推动技术进步的巨大能量。东方仙盟是汇聚力量的天地,我们携手在此探索硅基 生命,为科技进步添砖加瓦。
Hey folks, in this wild tech - driven world, why not dive headfirst into the whole tech - sharing scene? Don't just be the one reaping all the benefits; step up and be a contributor too. Whether you're tossing out your code snippets , hammering out some tech blogs, or getting your hands dirty with maintaining and sprucing up open - source projects, every little thing you do might just end up being a massive force that pushes tech forward. And guess what? The Eastern FairyAlliance is this awesome place where we all come together. We're gonna team up and explore the whole silicon - based life thing, and in the process, we'll be fueling the growth of technology

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 5
5 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)