【第四周】论文精读:WebSeer: Training Deeper Search Agents through Reinforcement Learning with Self-Reflection
【论文精读】WebSeer: Training Deeper Search Agents through Reinforcement Learning with Self-Reflection: 拒绝“浅层搜索”,用自我反思让AI学会像资深研究员一样深度挖掘
前言:当前基于大模型的搜索代理(Search Agents)普遍存在“浅尝辄止”的痛点,往往在获取第一条搜索结果后就急于生成答案,导致在复杂、多跳任务中准确率低下且错误累积。本文提出的 WebSeer 框架通过引入**“自我反思强化学习”(SRRL)**机制,强制模型在生成最终答案前进行多轮“搜索-反思-修正”的深度循环,不仅学会了何时搜索,更学会了如何评估搜索结果的质量并动态调整策略,在 HotpotQA 和 SimpleQA 等基准上分别达到 72.3% 和 90.0% 的SOTA准确率,相比现有最强基线提升了 12.5% 以上。
📄 论文基本信息
| 项目 | 内容 |
|---|---|
| 论文标题 | WebSeer: Training Deeper Search Agents through Reinforcement Learning with Self-Reflection |
| 核心方法名 | WebSeer (SRRL: Self-Reflective Reinforcement Learning) |
| 作者/机构 | Guanzhong He, Zhen Yang, Jinxin Liu 等 (清华大学计算机系) |
| 发表年份/会议 | 2026 / ICLR 2026 |
| 核心领域 | Agentic Search, Reinforcement Learning, Self-Reflection, Multi-hop QA |
| 关键数据集 | HotpotQA, SimpleQA, NQ, 2WikiMultiHopQA, MuSiQue, Bamboogle, FanOutQA |
| 代码开源 | 已开源 (Github/WebSeer) |
🔍 研究背景与痛点
1. “浅层搜索”陷阱 (The Shallow Search Trap)
- 现象:现有的搜索代理(如 Search-r1, R1-Searcher)倾向于**“贪婪策略”**。一旦检索到看似相关的片段,它们就会立即停止搜索并生成答案。如图1所示,面对需要4步推理的问题,模型往往在第3步就放弃搜索,给出一个似是而非的错误答案。
- 后果:在面对复杂的多跳问答(Multi-hop QA)时,模型无法主动发现信息缺失,导致早期错误累积,最终答案完全偏离事实。
- 本质:缺乏自发的自我反思机制。模型像一个急躁的实习生,拿到第一份资料就交差,不懂得交叉验证或回溯检索。
2. 现有解决方案的局限
- 监督微调 (SFT):虽然能教会模型调用工具,但难以覆盖所有复杂的搜索路径,且模型容易过拟合训练数据中的特定模式,缺乏处理未知错误的泛化能力。
- 纯规则规划:硬编码的搜索步骤(如“必须搜索3次”)过于僵化,无法根据实际搜索结果的优劣动态调整(有时1次就够了,有时需要10次)。
- 本地RAG限制:大多数工作仅关注本地向量库检索,忽视了真实互联网环境的复杂性和开放性。
3. WebSeer 的核心洞察
- 洞察一:深度搜索的关键在于“想得更深”而非单纯“搜得更多”。必须引入显式的**自我反思(Self-Reflection)**环节,让模型在每一步搜索后都停下来问自己:“信息够吗?可信吗?是否需要换关键词重试?”
- 洞察二:强化学习是培养“搜索直觉”的最佳途径。通过允许模型在同一对话中多次提交答案并根据反馈修正(SRRL),模型能在试错中学习到:盲目停止搜索会得到惩罚,而经过反思后的针对性搜索会带来高回报。
🛠️ 核心方法:WebSeer 架构详解
WebSeer 的核心是一个**“搜索 - 反思 - 行动”**的闭环系统,通过两阶段训练(SFT 初始化 + SRRL 优化)将这种深度思维内化为模型的本能。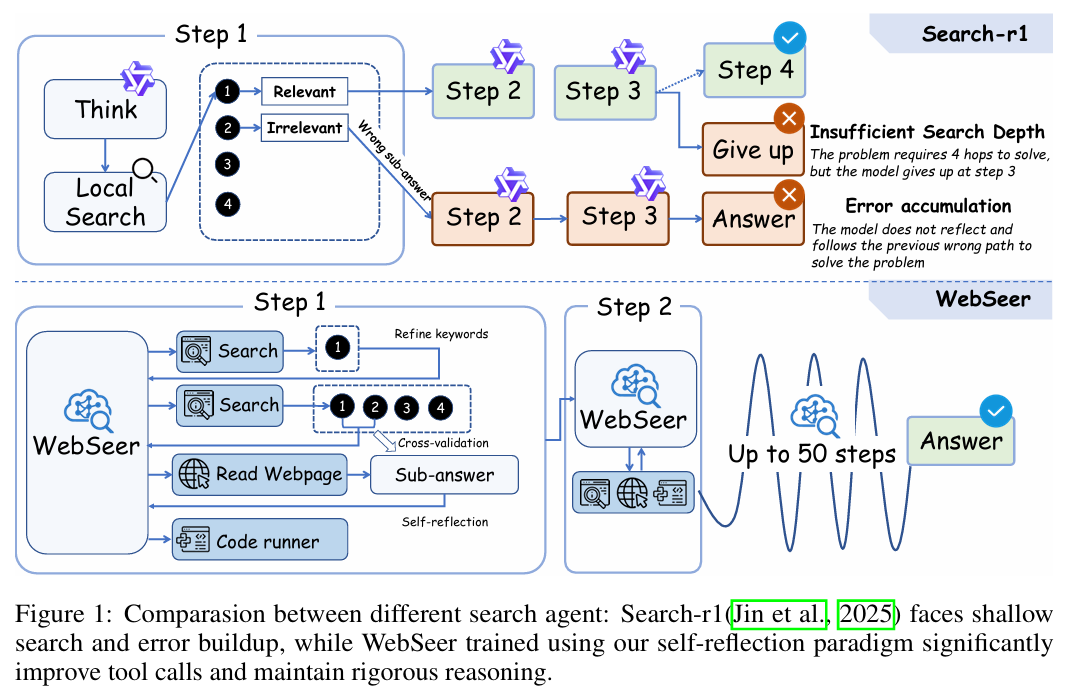
1. 自我反思数据构建 (Self-Reflective Data Construction) —— “制造高质量的错题本”
为了让模型学会反思,作者没有只使用一次性成功的轨迹,而是设计了一种**多轮拒绝采样(Multi-turn Rejection Sampling)**方法来合成数据。
-
具体操作:
- 使用一个强大的验证器(Verifier,同为LLM)对模型生成的中间答案进行评判。
- 如果答案错误,验证器会指出错误并生成修正建议,模型据此继续搜索。
- 关键点:只保留那些最终收敛到正确答案且包含多次反思修正过程的长轨迹。这教会了模型如何处理“死胡同”并从中恢复。
-
💡 核心逻辑:不仅教模型“怎么做对”,更教模型“做错后如何反思并修正”,从而打破浅层搜索的惯性。
-
类比解释:
想象一位侦探在破案:
- 普通代理:找到嫌疑人A有作案时间 -> 立即结案“A是凶手”。(结果:A只是路过,真凶是B)。
- WebSeer (带反思):
- 找到嫌疑人A有作案时间。
- 反思:“等等,只有时间不够,还需要动机和物证。而且A的不在场证明有点模糊。”
- 新行动:搜索“A的财务状况”和“现场指纹比对”。
- 再反思:“指纹不匹配,A被排除。之前的线索指向B,我需要重新搜索B的行踪。”
- 最终结论:锁定真凶B。
2. 自我反思强化学习 (SRRL) —— “在试错中进化”
这是 WebSeer 的灵魂。与传统RL不同,SRRL 允许模型在单次任务中多次提交答案,并根据反馈进行修正。
-
具体操作:
- 多轮提交机制:当模型提交答案后,环境会返回一个基于 F1 分数的文本反馈(如“不正确,F1=0.2”)。如果分数低于阈值,模型可以继续思考、搜索并再次提交,而不是直接结束 episode。
- 奖励函数设计:
R(τ)=Rformat(τ)+Rcorrect(τ) R(\tau) = R_{format}(\tau) + R_{correct}(\tau) R(τ)=Rformat(τ)+Rcorrect(τ)- RcorrectR_{correct}Rcorrect:基于答案准确性的奖励,但引入了指数折扣 αT\alpha^TαT(TTT为提交次数)。这意味着虽然鼓励修正,但过多的无效尝试会受到惩罚,迫使模型追求高效的反思。
- RformatR_{format}Rformat:对输出长度进行约束,防止模型为了刷分而生成无限长的废话。
-
核心算法/公式:
采用 GRPO (Group Relative Policy Optimization) 结合 DAPO 的非对称裁剪机制进行优化。# 伪代码:SRRL 的核心奖励逻辑 def calculate_reward(trace): # trace 包含多次 submit_answer 的尝试 final_score = 0 for attempt in trace.attempts: f1_score = compute_f1(attempt.answer, ground_truth) if f1_score == 1.0: # 奖励随尝试次数指数衰减,鼓励一次做对,但也允许修正 reward = f1_score * (ALPHA ** attempt.index) final_score = max(final_score, reward) break # 格式惩罚:防止输出过长导致上下文爆炸 length_penalty = 0 if len(trace.total_tokens) > MAX_SAFE_LENGTH: length_penalty = -1.0 return final_score + length_penalty -
效果分析:通过 SRRL,模型学会了“延迟满足”。它不再急于给出第一个答案,而是愿意花费额外的计算资源进行反思和二次搜索,从而显著提高了复杂问题的解决率。实验显示,训练后模型的平均工具调用次数从约3次增加到7-8次,且分布更加合理。
3. 工具设计 (Tool Design)
为了适应真实网络环境,WebSeer 配备了三个互补工具:
- Search Engine:Google Search API,获取关键词搜索结果。
- Webpage Reader:轻量级页面阅读器,针对特定URL和问题提取核心内容(避免HTML噪音)。
- Code Executor:Python代码执行器,用于精确计算或数据处理。
🏆 实验结果与分析
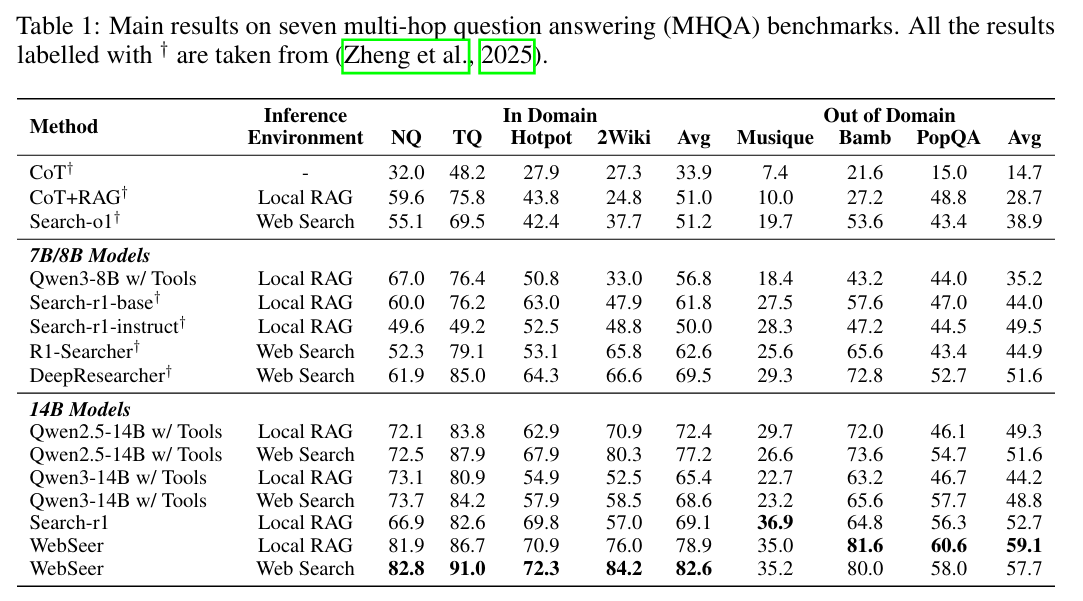
1. 性能全面碾压 SOTA
WebSeer 在多个高难度问答基准上取得了显著提升(基于 Qwen2.5-14B):
- HotpotQA (多跳推理):准确率达到 72.3%,相比之前的 SOTA (Search-r1, 69.8%) 提升明显,远超基础模型 (62.9%)。
- SimpleQA (事实性问答):达到惊人的 90.0%,证明了其在简单事实核查上的极高可靠性。
- 泛化能力 (OOD):在完全未见过的数据集 FanOutQA 上达到 55.4%,几乎媲美 GPT-4o (55.8%),且在 Bamboogle 上达到 81.6%,展现了极强的跨域泛化能力。
2. 深度搜索行为分析
- 工具调用分布演变(图3):
- Pre-SFT:大多数问题只调用3次工具(浅层搜索)。
- Post-SFT:分布右移,峰值在10次,甚至出现长达50次的调用(过度搜索/探索)。
- Post-RL (WebSeer):分布 sharpening,集中在 5-8次。这表明 RL 成功教会了模型战略性地使用工具:既不过于保守,也不盲目堆砌,而是根据问题复杂度动态调整深度。
3. 消融实验 (Ablation Study)
- w/o SFT (直接RL):模型完全崩溃,无法生成合法的 JSON 工具调用,奖励持续下降。证明高质量的冷启动数据(含反思轨迹)是必不可少的。
- w/o Multi-turn Submit (仅允许提交一次):性能显著下降。证明允许模型在反馈中修正错误是 SRRL 成功的关键。
- 模型规模影响:3B 和 7B 模型在 SFT 后性能反而下降(因为模仿了长轨迹但缺乏处理能力),只有 14B 及以上模型能稳定受益。这说明深度推理需要足够的模型容量。
4. 效率与成本
- 延迟:由于增加了反思步骤和多次搜索,单次查询的 Token 消耗和延迟有所增加(平均工具调用约8次)。
- 性价比:考虑到在复杂任务上准确率的巨大提升(+12.5%),这种计算成本的增加对于高价值应用(如科研助手、法律咨询)是完全值得的。
💡 主要创新点总结
- 自我反思强化学习 (SRRL):首次提出允许模型在 RL 过程中多次提交答案并根据反馈修正的范式,将“反思”从 Prompt 技巧升级为可优化的策略。
- 多轮拒绝采样数据构建:设计了一套合成包含“错误 - 反思 - 修正”完整链条的高质量训练数据的方法,解决了反思数据稀缺的难题。
- 真实网络环境的深度适配:不仅限于本地库,而是在真实的 Google Search + 网页阅读环境中验证了深度搜索代理的有效性,并证明了其强大的 OOD 泛化能力。
⚠️ 局限性与挑战
- 模型规模依赖:实验表明,小于 14B 的模型难以驾驭这种长链条的反思推理,容易出现上下文迷失或格式错误,限制了其在端侧设备的应用。
- 推理延迟:深度的多步搜索和反思必然带来更高的时间成本,可能不适用于对实时性要求极高的场景(如即时聊天)。
- 奖励函数敏感性:折扣系数 α\alphaα 和格式惩罚权重的设置需要精细调优,否则可能导致模型过早放弃或陷入无限循环。
🚀 对开发者的实战建议
如果你正在构建需要高准确率的搜索应用(如企业知识库、学术研究助手):
- 引入“反思 - 修正”循环:不要让你的 Agent 在第一次搜索后就强制输出答案。设计一个机制,让 LLM 先评估“当前信息是否充足”,如果不充足,允许它自动发起新一轮搜索,甚至允许它撤回之前的结论。
- 构建“错题本”进行微调:收集那些“第一次搜错了,但经过反思后搜对了”的案例,专门用来微调你的模型。这比单纯喂给它正确答案更有价值,因为它教会了模型如何从错误中恢复。
- 动态控制搜索深度:借鉴 WebSeer 的 RL 思路,不要硬编码搜索次数。可以通过简单的规则或轻量级模型判断问题复杂度:简单问题(如“今天天气”)直接回答;复杂问题(如“对比A和B的财务差异”)强制开启多轮反思模式。
- 重视验证器 (Verifier) 的作用:在系统中集成一个独立的验证模块(可以是同一个模型的不同 Prompt),专门负责挑刺和检查逻辑一致性,这能显著降低幻觉率。
一句话总结:WebSeer 告诉我们,真正的智能搜索不是比谁手快,而是比谁脑子深;通过赋予 AI“自我反思”和“从错误中修正”的能力,我们能让它在信息的海洋中从“随波逐流”变为“精准导航”。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)