不平衡模型性能分析
文章目录
背景
看到一篇文献,在做结构互作模型在训练时使用了加权损失函数来处理类别不平衡,而对比的AlphaFold模型没有经过微调(即权重一致)。在做benchmark时,用了一个SE增强的加权二分类交叉熵,然后性能声称比alphafold高。

这个损失函数比较好理解,就是一个加权的交叉熵,然后外面套了一个调节因子,乘上了一项

先回顾一下几个分类指标
https://en.wikipedia.org/wiki/Receiver_operating_characteristic
公式我就不列了。
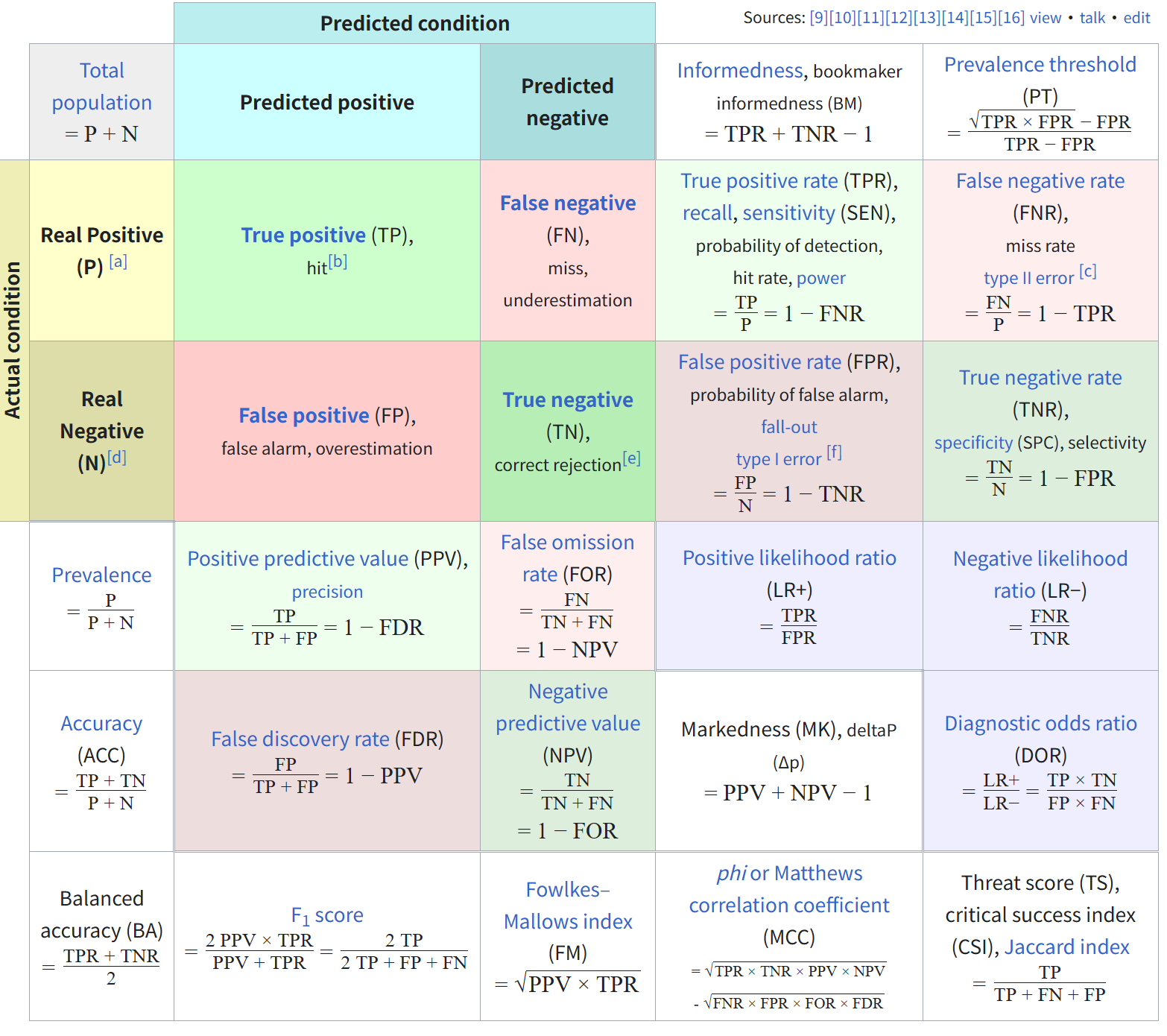
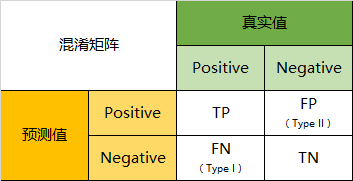
关于分类任务的指标,我们一切理解的基础都是4个基本数,也就是混淆矩阵中的4个维度。

- 准确率Accuracy:Accuracy = (TP + TN) / 总数
- 我们猜对的比例(无论是正样本还是负样本),如果正样本很少,哪怕全猜负类,Accuracy也可能很高,也就是说Accuracy指标其实在1个类别不平衡的分类任务中是一个可以作弊的指标(就是我们只需要猜类别主导的那一类就行了,所以指标容易虚高,光看这个没意义)
- 精确率Precision:Precision = TP / (TP + FP)
- 模型预测为阳性的样本里,有多少是真正的阳性。很显然,假阳性越高,精确率就越低
- 召回率Recall:Recall = TP / (TP + FN)
- 所有真正为阳性的样本里,被模型预测为阳性的,或者说模型找回了多少。很显然,假阴性越多,召回率越低
- F1 score:精确率与召回率的调和平均(也就是各自倒数的平均,再取倒数),F1 = 2 × (Precision × Recall) / (Precision + Recall)
- 精确率和召回率的调和平均,综合看模型在正类上的表现
- AUROC:横轴是假阳性率,纵轴是真阳性率,AUC是曲线下面积

- 真阳性率其实就是召回率(在所有ground truth为阳性的样本中,预测为模型找回为阳性的样本比例,在所有真实为阳性的样本中真阳性的比例),假阳性率(在所有真实为阴性的样本中假阳性的比例)。真阳性率-假阳性率,真阳比全真阳,假阳比全真阴。
- 不看阈值,只看模型把正类排在负类前面的能力。对不平衡数据也稳健
为什么评估指标与训练目标不匹配?
我们的训练目标
我们给损失函数加权重,一般通常是给正类样本更高的权重(因为一般数据稀缺,是阳性样本数目少),这意味着模型不会放过任何一个阳性样本,也就是说一个真实阳性样本,模型预测分为真阳性(预测对)、假阴性(预测错),模型会对后者也就是漏掉正类的惩罚变重,也就是说模型会拼命减少假阴性,严厉惩罚假阴性。
- 模型会拼命减少 FN(漏掉正类的惩罚变重)
- 代价是可能增加 FP(因为模型更敢猜正类)
训练目标 = 优先降低假阴性。
评估指标如果只看Accuracy或Precision
- Accuracy 对 FP 和 FN 一视同仁。我们虽然减少了 FN,但增加了 FP,Accuracy 可能不变甚至下降。
- Precision 只关心 FP。我们 FP 多了,Precision 就会下降。
结果就是:我们的模型明明“更努力找正类”,但用 Accuracy 或 Precision 去量,它却“变差了”。
这就是指标和训练目标不匹配——我们用召回率换来了精确率的损失,但评估指标只看精确率或整体准确率,我们的努力就被埋没了。
所以本质上,加权操作(对正类加权重)做的是一件什么事情呢?
从结果上而言,加权操作本质上就是在做“精确率换召回率”的权衡,从而改变模型的决策偏好,让模型从原本的保守预测变为去更加积极地预测阳性样本。
用精确率换召回率
假设我们有一个不平衡的数据集(正类很少)。
- 不加权训练:模型更“保守”,倾向于预测负类 → 假阴性(FN)多,假阳性(FP)少 → 召回率低,精确率高。
- 加权训练(给正类更大权重):模型更“积极”去预测正类 → 假阴性减少,但假阳性增加 → 召回率升高,精确率下降。
所以从“指标变化”来看,确实是用精确率的下降换来了召回率的提升。
所以说,如果同样1个任务(类别数据不平衡),两个模型在比较,1个是损失函数对类别进行加权,另外1个不是,
那么最后从召回率上讲,前者的性能会比后者高,这样做benchmark是虚高,作弊;
从精确率上来讲,前者的性能会比后者低,这样做benchmark是虚低,作弊。
如何让评估指标与训练目标相互匹配?
道理很简单,在做benchmark时,只报告单一指标可能是不全面的。
所谓的作弊怎么权衡判定呢,作弊与否取决于是否隐瞒信息或误导,除非刻意挑选对自己有利的指标并隐瞒其他指标,虽然有很多文章是这么做的。
我们只是需要反思一下,性能的好坏(比如说要确保我们的model比SOTA好),并不是简单地选择指标,而是需要在合理的评估框架下去展示。
从单一指标看,算不算作弊?
- 如果 benchmark 固定使用召回率,而你通过加权训练人为拉高召回率 → 这不叫作弊,这是针对性优化。只要规则允许任何训练策略,你完全可以在召回率指标上“肯定比 AlphaFold 高”。但是有一点是确定的,就是我们是一定有办法可以在一个场景中在某个指标中超过SOTA的(通过统计学)
- 如果 benchmark 固定使用精确率,你加权后精确率下降 → 这叫“表现差”,不是作弊,是你选错了优化方向。
- 如果 benchmark 要求报告多个指标(如 Precision + Recall + F1),而你只挑自己最高的那个指标说“我更好”,这属于选择性报告,学术上是不诚信的,可以算“软作弊”。现实虽然有很多这样的暗箱操作,但是现在也是越来越少了,基本上简单的分类任务很多工作会把所有的指标都扔出来。
让加权model肯定比AlphaFold好?
如果我们训练时给正类权重w+,评估时也使用相同权重的加权准确率,也就是评估指标 = 加权准确率(权重与训练时一致)。
那么我们的模型会在该指标上必然高于或等于未加权的alphafold,因为我们的训练目标直接优化了这个指标。



训练时加权 = 在“练”的时候告诉模型什么更重要
评估时用相同权重的加权准确率 = 在“考”的时候用同一把尺子去量
这样练和考一致,结果才能真实反映模型的优化方向,而不是被不匹配的指标掩盖。
核心就是:训练目标要和评估指标对齐,这样我们的模型在评估时必然占优,也就是教什么考什么。
也就是说:


有没有一种情况,能让加权后的模型“百分之百”比未加权的 AlphaFold 表现更好?
理论上不存在绝对的百分之百,但是可以通过选择评估方式让加权模型的优势必然体现出来。
关键在于:评估指标与训练目标一致,并且比较条件对双方公平(或偏向加权模型)。


还有一个就是前面提到过的暗箱操作(直接训练目标,评估指标就是训练目标的无偏度量)


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)