Agent Harness:2026年AI架构师必须掌握的“操作系统级“技术,万字长文深度解析!
导读:2025年是Agent的元年,而2026年将是Agent Harness的爆发之年。为什么OpenAI、Anthropic等顶级AI公司都在疯狂投入Harness Engineering?为什么说不掌握Harness,你的Agent永远只能是个"玩具"?本文将从架构师视角,深度解析Agent Harness的底层原理、核心组件和实战应用。
一、颠覆认知:为什么模型再强,也需要Harness?
1.1 一个令人震惊的事实
2026年2月,OpenAI公开了一个实验:一个仅3人的工程师团队,使用Harness Engineering方法,在5个月内构建了超过100万行代码的代码库,人均每天提交3.5个PR,且零手动编码。
这不是魔法,而是Harness的力量。
更令人深思的是:Anthropic的实验显示,即使是Opus 4.5这样的顶级模型,在没有Harness的情况下,也无法从零构建一个生产级的Web应用。
为什么?
1.2 模型的"先天缺陷"
让我们直面一个残酷现实:LLM本质上是 stateless(无状态)的。
每次调用,模型都是"失忆"的——它不记得上一次会话做了什么,不知道当前的项目进度,也无法持久化存储任何信息。
想象一下:你雇佣了一个超级聪明的工程师,但他每次开会前都会失忆,需要你重新介绍项目背景。这就是没有Harness的Agent。
具体失败模式包括:
- • Context Rot(上下文腐烂):随着工具调用和历史记录的累积,上下文窗口被填满,模型逐渐"忘记"原始指令
- • Hallucinated Tool Calls(工具调用幻觉):模型调用不存在的API或传递错误参数类型,没有验证机制就会无限循环失败
- • Lost State on Failure(失败时状态丢失):任何网络超时或服务器重启都会导致进度清零
- • Early Stopping(过早停止):模型在任务未完成时就宣称成功,缺乏自验证机制
1.3 Harness的价值主张
Agent Harness就是解决这些问题的"操作系统"。
正如Philipp Schmid在《The importance of Agent Harness in 2026》中的经典比喻:
- **模型 = CPU**:提供原始算力- **上下文窗口 = RAM**:有限的易失性工作内存 - **Agent Harness = 操作系统**:管理上下文、提供驱动、调度资源- **Agent = 应用程序**:运行业务逻辑
没有操作系统,CPU再强也无法运行应用。同理,没有Harness,模型再智能也无法完成长期复杂任务。
二、核心定义:Agent Harness到底是什么?
2.1 权威定义
LangChain在《The Anatomy of an Agent Harness》中给出了最简洁的定义:
“If you’re not the model, you’re the harness.”
(如果你不是模型,那你就是Harness。)
Agent = Model + Harness
Harness包含了除了模型本身之外的所有代码、配置和执行逻辑。
2.2 功能定义
Salesforce的定义更具体:
“Agent Harness是包裹AI模型的软件基础设施,负责管理其生命周期、上下文、以及与外部世界的交互。”
核心职责包括:
- • 工具执行(Tool Execution)
- • 内存管理(Memory Management)
- • 状态持久化(State Persistence)
- • 错误恢复(Error Recovery)
- • 上下文编排(Context Orchestration)
2.3 与Framework的区别
这是最容易混淆的概念。让我们用一张图说明:

关键区别:
| 维度 | Agent Framework | Agent Harness |
|---|---|---|
| 抽象层级 | 低层构建块 | 高层封装 |
| 定位 | 开发工具包(零件库) | 运行时系统(操作系统) |
| 特点 | 模块化、可组合、需自行组装 | 开箱即用、内置默认配置 |
| 代表产品 | LangChain、LlamaIndex | Claude Code、OpenAI Codex、DeepAgents |
| 用户 | 开发者 | Agent本身 |
比喻:
- • Framework像是乐高积木,给你零件自己搭建
- • Harness像是成品玩具,拿来就能用
LangChain的DeepAgents就是一个典型的Harness,它构建在LangChain Framework之上,提供了预设提示词、文件系统、子代理管理等"电池 Included"功能。
三、六大核心组件:构建生产级Harness的完整蓝图
一个完整的Agent Harness包含以下核心组件。我们将逐一深入解析。
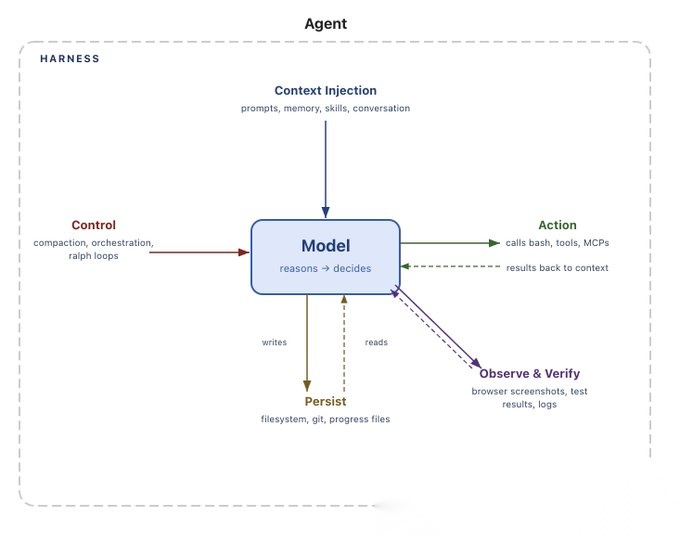
3.1 文件系统(Filesystem):持久化存储的基石
为什么需要文件系统?
模型只能在上下文窗口内操作信息。在此之前,用户需要手动复制粘贴内容——这对自主Agent来说完全不可行。
文件系统的三大价值:
- 工作空间:Agent可以读取数据、代码和文档
- 上下文卸载:将中间结果和状态持久化,避免占用宝贵的上下文窗口
- 协作表面:多个Agent和人类可以通过共享文件协作
实践建议:
# 典型的Harness文件系统结构project/├── AGENTS.md # Agent指令文件(持续学习)├── PLAN.md # 任务计划├── PROGRESS.json # 进度追踪├── src/ # 源代码├── tests/ # 测试文件└── .git/ # 版本控制
AGENTS.md模式:这是Harness Engineering的关键实践。每当发现一个Agent失败模式,就在此文件中添加一条规则。文件会随时间增长,形成组织的Agent知识库。
3.2 Bash + 代码执行:通用问题解决器
核心理念:与其为每个可能的动作预定义工具,不如给Agent一个通用工具——Bash。
为什么Bash如此强大?
- • 自主性:模型可以按需编写并执行代码,自行设计工具
- • 通用性:几乎可以完成任何任务
- • 生态:可以调用现有CLI工具、脚本和程序
Harness实现示例:
class AgentHarness: def execute_bash(self, command: str) -> str: # 1. 验证命令(安全策略) if not self._is_allowed(command): raise SecurityError("Command not allowed") # 2. 在沙箱中执行 result = self.sandbox.run(command) # 3. 清理输出并返回 return self._sanitize_output(result)
安全注意事项:
- • 必须在沙箱环境中执行
- • 实施命令白名单
- • 网络隔离
- • 资源限制(CPU、内存、时间)
3.3 沙箱环境(Sandbox):安全执行的保障
问题:在本地执行Agent生成的代码极其危险。一个恶意或错误的命令就可能摧毁整个系统。
解决方案:沙箱
沙箱的核心能力:
- • 隔离的代码执行环境
- • 预装运行时(Python、Node.js等)
- • 预装工具链(git、测试框架、浏览器等)
- • 按需创建和销毁
- • 可扩展到大规模并行执行
架构示意图:
┌─────────────────────────────────────┐│ Agent Harness ││ ┌──────────────────────────────┐ ││ │ Tool Call Interceptor │ ││ └──────────┬───────────────────┘ ││ │ ││ ▼ ││ ┌──────────────────────────────┐ ││ │ Sandbox Orchestrator │ ││ └──────────┬───────────────────┘ ││ │ │└─────────────┼───────────────────────┘ │ ▼ ┌────────────────┐ │ Sandbox #1 │ ← 按需创建 ├────────────────┤ │ - Python 3.11 │ │ - Node.js 20 │ │ - Git │ │ - Chrome │ └────────────────┘
主流沙箱方案:
- • Docker容器
- • E2B沙箱
- • Modal Labs
- • AWS Firecracker
3.4 工具集成层(Tool Integration):连接外部世界
Harness需要为Agent提供丰富的工具集。根据LangChain的研究,核心工具包括:
工具分类:
- 文件系统工具:读写文件、目录操作
- 代码执行工具:Bash、Python REPL
- 网络工具:Web搜索、API调用
- 浏览器工具:自动化测试、截图、网页交互
- 版本控制:Git操作
- 数据库工具:SQL查询、ORM
- MCP(Model Context Protocol)服务器:标准化上下文访问
工具注册表模式:
class ToolRegistry: def __init__(self): self.tools = { "read_file": ReadFileTool(), "write_file": WriteFileTool(), "bash": BashTool(sandbox=self.sandbox), "web_search": FirecrawlTool(api_key="..."), "test_runner": TestRunnerTool(), } def execute(self, tool_name: str, args: dict): tool = self.tools[tool_name] # 验证参数 tool.validate(args) # 执行 return tool.run(args)
实战案例:Firecrawl集成
Firecrawl是一个优秀的Web数据获取工具,完美解决了现代网页抓取的复杂性(JavaScript渲染、反机器人、动态内容)。
# 一键安装并集成到所有主流Agent Harnessnpx -y firecrawl-cli@latest init --all --browser
安装后,Agent可以直接使用:
def web_search(query: str) -> list: """搜索并返回结构化数据""" return firecrawl.search(query, limit=5, scrape_options={"formats": ["markdown"]})def fetch_page(url: str) -> str: """抓取网页并返回Markdown""" return firecrawl.scrape(url, formats=["markdown"]).markdown
Harness会将这些函数注册到工具注册表,Agent就可以像调用本地函数一样使用它们。
3.5 内存与搜索(Memory & Search):持续学习系统
内存的三层架构:
1. 工作上下文(Working Context)
- • 当前提示词和会话历史
- • 易失性,每次调用重置
2. 会话状态(Session State)
- • 当前任务的持久化日志
- • 记录工具调用结果、完成的子任务
3. 长期记忆(Long-term Memory)
- • 跨任务的知识积累
- • 可以是向量数据库、结构化文件或专门的记忆层
记忆文件格式:
Anthropic实验发现,JSON比Markdown更适合状态追踪,因为模型不太可能意外覆盖或重新格式化JSON。
{ "project": "Claude.ai Clone", "features": [ {"id": 1, "name": "User Auth", "status": "completed", "commit": "abc123"}, {"id": 2, "name": "Chat UI", "status": "in_progress", "notes": "..."} ], "learnings": [ "Use NextAuth for authentication", "Avoid using useEffect for chat polling" ]}
RAG(检索增强生成)模式:
Harness不应一次性加载所有知识,而应根据当前步骤按需检索相关文档,避免上下文污染。
3.6 上下文工程(Context Engineering):对抗Context Rot
问题:上下文窗口是有限的,随着任务推进,窗口会被工具输出、历史记录和推理填满,导致性能下降。
Lost in the Middle现象:斯坦福大学Liu等人的研究发现,当关键内容埋没在长提示词中间时,LLM性能显著下降。
Harness的三大策略:
1. 压缩(Compaction)
当上下文窗口接近满载时,Harness需要智能地压缩历史:
- • 将早期对话摘要为简短笔记
- • 保留关键决策和结果
- • 丢弃中间推理步骤
def compact_context(self): """压缩上下文的策略""" # 1. 提取关键信息 summary = self.llm.summarize( self.context.history, max_tokens=2000 ) # 2. 保留最近N轮对话 recent = self.context.history[-5:] # 3. 重建上下文 self.context.rebuild( prefix=summary, recent=recent )
2. 工具输出卸载(Tool Call Offloading)
大型工具输出会噪音般充斥上下文窗口。Harness应:
- • 保留输出的头部和尾部(各N个token)
- • 将完整输出写入文件系统
- • 仅在Agent需要时检索
3. 技能(Skills):渐进式披露
问题:启动时加载过多工具/MCP服务器会降低性能。
解决方案:Skills机制
- • 初始阶段仅加载核心工具
- • 当Agent需要特定能力时,Harness动态加载对应Skill
- • Skill包含工具、提示词前缀和示例
3.7 验证与防护(Verification & Guardrails):确保正确性
核心原则:生产级Harness必须验证输出,而非盲目信任Agent。
验证机制:
1. 自验证循环(Self-Verification Loop)
def execute_with_verification(self, task: Task): # 1. Agent执行 result = self.agent.execute(task) # 2. 运行测试 test_result = self.test_runner.run(task.test_suite) # 3. 验证失败则循环 if not test_result.passed: error_msg = f"Tests failed: {test_result.errors}" # 注入错误信息,要求修复 self.context.inject(error_msg) return self.execute_with_verification(task) return result
2. Ralph Loops(持续工作循环)
这是LangChain提出的一种模式:
当Agent尝试退出时,Harness通过钩子拦截,并在干净的上下文窗口中重新注入原始提示,强制Agent继续工作直到完成目标。
def ralph_loop(self): """Ralph Loop实现长周期任务""" while not self.is_complete(): # 1. 加载当前状态 state = self.load_state() # 2. 在新鲜上下文中执行 with fresh_context(state): result = self.agent.run(self.goal) # 3. 保存进度 self.save_state() # 4. 检查是否完成 if self.verify_completion(result): break
3. 人类介入(Human-in-the-Loop)
对于敏感操作(生产数据库写入、外部通信),Harness应暂停并等待人类批准。
def execute_sensitive_action(self, action: str): # 暂停并请求批准 approval = self.human_approval(action) if approval.granted: return self.execute(action) else: raise PermissionError("Action denied by human reviewer")
四、架构模式:三种主流Harness设计范式
根据任务复杂度和需求,Harness有三种主流架构模式。
4.1 单代理监督者(Single-Agent Supervisor)
适用场景:边界明确的任务(如客服机器人、数据录入)
架构:
┌─────────────────────────────────┐│ Harness ││ ┌───────────────────────────┐ ││ │ Agent (LLM + Tools) │ ││ └───────────────────────────┘ ││ │ │ ││ Memory Tools │└─────────────────────────────────┘
特点:
- • 一个模型在循环中
- • Harness管理初始化、上下文注入、工具调度、状态持久化
- • 简单直接
4.2 初始化器-执行器分离(Initializer-Executor Split)
适用场景:长期编码任务、复杂项目开发
这是Anthropic推荐的模式。
两阶段架构:
阶段一:初始化器(运行一次)
def initializer(): """设置持久化项目环境""" # 1. 创建目录结构 fs.create_structure([ "src/", "tests/", "docs/" ]) # 2. 编写功能列表 fs.write("FEATURES.json", [ {"id": 1, "status": "pending"}, ... ]) # 3. 初始化脚本 fs.write("init.sh", """ npm install npm run build """) # 4. 初始Git提交 git.commit("Initial setup")
阶段二:执行器(多次运行)
def executor(): """增量完成单个任务""" # 1. 读取进度 state = fs.read("FEATURES.json") next_task = state.find_next_pending() # 2. 执行任务 agent.execute(next_task) # 3. 运行测试 run_tests() # 4. 提交并更新进度 git.commit(f"Complete {next_task}") state.mark_completed(next_task) fs.write("FEATURES.json", state)
关键优势:
- • 每个会话从持久化状态启动
- • 无需记住历史会话
- • 项目环境成为跨会话的共享记忆
4.3 多代理协调(Multi-Agent Coordination)
适用场景:超复杂项目、需要专业分工
架构:
┌─────────────────────────────────────┐│ Harness Orchestrator ││ ┌─────────┐ ┌───────── ││ │Research │ │ Writer │ ││ │ Agent │→│ Agent │ ││ └───────── └─────────┘ ││ ↓ ↓ ││ ┌─────────────────────────┐ ││ │ Reviewer Agent │ ││ └─────────────────────────┘ │└─────────────────────────────────────┘
Harness职责:
- • 分派专业代理(研究员、写作者、审核员)
- • 管理交接(确保每个代理获得相关上下文)
- • 过滤无关历史
ICML 2025研究:在GPT-4级模型上测试了可分离的感知、记忆和推理模块。配备Harness的模型在所有测试游戏中 consistently 优于无Harness模型。
五、Harness Engineering:从失败中提炼工程智慧
5.1 什么是Harness Engineering?
Mitchell Hashimoto提出的核心理念:
“将每个Agent失败视为系统工程问题,而非提示词重试问题。”
传统做法:Agent出错 → 调整提示词 → 重试
Harness Engineering:Agent出错 → 分析失败模式 → 工程化修复 → 永久防止
5.2 两大核心实践
实践一:渐进式规则文件
维护一个AGENTS.md文件,每条规则对应一个观察到的失败:
# AGENTS.md## Rules (accumulated from failures)1. Always run tests after writing code2. Use `firecrawl scrape` for web data, not curl3. Check for existing functions before creating new ones4. Commit to git after each completed feature5. Use JSON for state files, not Markdown...
文件随时间增长,形成组织的Agent知识库。
实践二:机械可验证工具
如果Agent反复失败,就构建工具使其机械性地强制执行正确行为。
案例:
- • 问题:Agent不测试UI交互
- • 解决:构建截图工具,每次UI变更后自动截图
- • 问题:Agent不验证API响应
- • 解决:构建响应验证器,自动检查状态码和schema
5.3 Harness Engineering vs Context Engineering
关键区别:
| 维度 | Context Engineering | Harness Engineering |
|---|---|---|
| 焦点 | 模型看到什么信息 | 模型在什么环境中运行 |
| 手段 | 优化输入 | 控制环境、工具、验证 |
| 目标 | 提供正确上下文 | 防止错误、强制执行 |
| 示例 | RAG检索相关文档 | 构建测试工具强制验证 |
比喻:
- • Context Engineering:给司机提供清晰的地图
- • Harness Engineering:给汽车安装安全带和气囊
5.4 模型-Harness协同进化
OpenAI和Anthropic的产品(如Codex、Claude Code)采用模型与Harness协同训练。
循环过程:
1. 发现原语(如Skills、Compaction) ↓2. 添加到Harness并标准化 ↓3. 用Harness训练下一代模型 ↓4. 模型在Harness中表现提升 ↓5. 回到步骤1
副作用:模型可能对特定Harness过拟合。例如,Codex对apply_patch工具逻辑高度依赖,更换工具逻辑会导致性能下降。
六、实战案例:从零构建一个生产级Coding Agent Harness
让我们实战构建一个完整的Harness。
6.1 需求分析
目标:构建一个能自主开发Web应用的Coding Agent Harness
要求:
- • 长期运行(跨多个会话)
- • 自主编写和测试代码
- • 持久化进度
- • 安全可靠
6.2 架构设计
采用Initializer-Executor模式:
class CodingAgentHarness: def __init__(self, model: str = "gpt-4"): self.model = load_model(model) self.sandbox = create_sandbox() self.fs = VirtualFilesystem() self.git = GitInterface() self.tools = ToolRegistry() def initialize(self, project_spec: str): """初始化项目环境""" # 1. 创建目录结构 self.fs.create_structure([ "src/", "tests/", "docs/", "public/" ]) # 2. 编写AGENTS.md self.fs.write("AGENTS.md", """# Project Guidelines## Rules1. Always write tests for new features2. Use TypeScript for all code3. Run `npm test` before committing4. Update PROGRESS.json after each task """) # 3. 初始化package.json self.fs.write("package.json", { "name": "agent-project", "scripts": { "test": "jest", "build": "tsc" } }) # 4. 创建PROGRESS.json self.fs.write("PROGRESS.json", { "tasks": parse_tasks(project_spec), "current": 0, "completed": [] }) # 5. 初始提交 self.git.commit("Initial project setup") def execute(self): """执行单个任务""" # 1. 加载状态 progress = json.loads(self.fs.read("PROGRESS.json")) current_task = progress["tasks"][progress["current"]] # 2. 构建上下文 context = self._build_context( task=current_task, progress=progress, agents_md=self.fs.read("AGENTS.md") ) # 3. Agent执行 result = self.model.generate( context=context, tools=self.tools.all() ) # 4. 运行测试 test_result = self.sandbox.run("npm test") if not test_result.success: # 5. 测试失败,注入错误信息 error_context = f"Tests failed:\n{test_result.output}" return self._retry_with_error(context, error_context) # 6. 更新进度 progress["completed"].append(current_task["id"]) progress["current"] += 1 self.fs.write("PROGRESS.json", json.dumps(progress)) # 7. Git提交 self.git.commit(f"Complete: {current_task['name']}") return result
6.3 工具集成示例
集成Firecrawl用于Web数据获取:
class FirecrawlTool: def __init__(self, api_key: str): self.client = Firecrawl(api_key=api_key) def search(self, query: str, limit: int = 5) -> list: """搜索网络并返回结构化结果""" result = self.client.search( query=query, limit=limit, scrape_options={"formats": ["markdown"]} ) return result.web def scrape(self, url: str) -> str: """抓取网页并返回Markdown""" result = self.client.scrape( url=url, formats=["markdown"] ) return result.markdown def extract(self, prompt: str) -> dict: """自主导航并提取数据""" result = self.client.agent(prompt=prompt) return result.data# 注册到Harnesstools.register("web_search", FirecrawlTool(api_key="...").search)tools.register("fetch_page", FirecrawlTool(api_key="...").scrape)
6.4 上下文管理
实现智能压缩:
def compact_context(self, context: Context) -> Context: """压缩上下文策略""" # 1. 如果未超过阈值,直接返回 if context.token_count < self.max_tokens * 0.8: return context # 2. 提取关键决策 decisions = context.extract_decisions() # 3. 摘要早期历史 summary = self.model.summarize( context.history[:-5], # 保留最近5轮 max_tokens=1000 ) # 4. 工具输出卸载 for call in context.tool_calls: if len(call.output) > 5000: # 保存到文件 file_path = f".harness/tool_outputs/{call.id}.txt" self.fs.write(file_path, call.output) # 仅保留头部和尾部 call.output = f"[Output truncated. See {file_path}]" # 5. 重建上下文 return Context( system_prompt=context.system_prompt, prefix=summary, decisions=decisions, recent_history=context.history[-5:], current_task=context.current_task )
6.5 验证机制
实现自验证循环:
def execute_with_verification(self, task: Task) -> Result: """执行并验证""" max_retries = 3 for attempt in range(max_retries): # 1. 执行 result = self.agent.execute(task) # 2. 运行测试套件 test_output = self.sandbox.run("npm test") # 3. 验证 if test_output.exit_code == 0: return result # 4. 测试失败,注入错误信息 error_msg = f"""Tests failed on attempt {attempt + 1}:```bash{test_output.stdout}{test_output.stderr}
Please fix the issues and try again.
“”"
self.context.inject(error_msg)
# 超过重试次数,抛出异常raise MaxRetriesExceeded(f"Failed after {max_retries} attempts")
``````plaintext
### **6.6 运行Harness**```python# 初始化Harnessharness = CodingAgentHarness(model="gpt-4")# 初始化项目harness.initialize("""Build a todo app with:1. User authentication2. Create/read/update/delete todos3. Filter by status4. Dark mode UI""")# 循环执行直到完成while not harness.is_complete(): result = harness.execute() print(f"Completed task: {result.task_name}")print("Project completed!")
七、未来趋势:Harness将如何重塑AI开发范式?
7.1 Harness Engineering的崛起
2026年,Harness Engineering已成为AI开发的核心竞争力。
趋势一:从Prompt Engineering到Harness Engineering
- • Prompt Engineering:优化单次调用
- • Harness Engineering:构建整个运行系统
随着模型能力提升,简单的提示词调整收益递减,而系统工程优化收益递增。
趋势二:Harness标准化
类似Web开发的React/Vue,Agent开发将出现标准Harness:
- • OpenAI Codex Harness
- • Anthropic Claude Code Harness
- • LangChain DeepAgents
- • Microsoft Agent Framework Harness
趋势三:Harness即产品
公司将不再"构建Agent",而是"配置Harness":
- • 选择Harness(如选择操作系统)
- • 配置工具和策略
- • 注入领域知识
- • 部署运行
7.2 Harness的演进方向
根据LangChain的研究,未来Harness将聚焦:
方向一:超大规模多Agent编排
挑战:如何协调数百个Agent在共享代码库上并行工作?
方案:
- • 基于Git的分布式协作协议
- • 智能冲突检测和解决
- • 任务自动分解和分配
方向二:自诊断Harness
Harness能够:
- • 分析自身追踪数据
- • 识别失败模式
- • 自动调整配置
- • 生成新的规则
def self_diagnose(self, trace: ExecutionTrace): """Harness自诊断""" # 1. 分析失败模式 failure_mode = self.analyzer.identify_pattern(trace) # 2. 生成修复策略 fix = self.planner.generate_fix(failure_mode) # 3. 应用修复 self.apply_fix(fix) # 4. 更新规则 self.agents_md.add_rule(fix.rule)
方向三:即时工具组装(Just-in-Time Tool Assembly)
当前Harness预配置工具集。未来Harness将:
- • 根据任务动态组装工具
- • 按需加载MCP服务器
- • 最小化上下文污染
7.3 Harness会消失吗?
问题:随着模型变强,Harness是否会变得不必要?
答案:不会,但会演进。
理由:
- 模型永远需要接口:即使模型内置规划和验证能力,仍需要Harness提供文件系统、沙箱、工具等基础设施
- Harness能力会被吸收:当前Harness中的原语(如Skills、Compaction)会被吸收到模型训练中,但这会释放Harness去解决更高层次问题
- 类比Prompt Engineering:尽管模型越来越强,Prompt Engineering仍然有价值。Harness Engineering同理。
未来Harness工程师的核心技能:
- • 系统设计
- • 上下文架构
- • 工具编排
- • 验证策略
- • 失败分析
八、资源清单:工具、框架与学习路径
8.1 主流Harness产品
生产级Harness:
- OpenAI Codex:OpenAI内部使用的Coding Agent Harness
- Claude Code:Anthropic的通用Coding Harness
- Manus:专注于长期任务的Harness
- LangChain DeepAgents:开源Harness,batteries included
8.2 开发工具和框架
Framework层:
- • LangChain(Python/JS)
- • LlamaIndex(Python)
- • Microsoft Semantic Kernel(C#/Python)
- • CrewAI(Python)
Harness层:
- • LangChain DeepAgents
- • Anthropic Claude Agent SDK
- • OpenAI Agents SDK
- • Microsoft Agent Framework
工具集成:
- • Firecrawl:Web数据获取(CLI一键集成)
- • E2B:沙箱环境
- • MCP Servers:标准化上下文协议
- • Docker:容器化执行
结语:Harness——AI时代的"操作系统革命"
回顾计算机发展史:
- • 1960s-70s:硬件为王(CPU)
- • 1980s-90s:操作系统为王(Windows、Linux)
- • 2000s-10s:应用为王(iPhone App)
- • 2020s:模型为王(LLM)
- • 2026+:Harness为王(Agent OS)
Harness Engineering的本质:我们不再编写确定性的程序,而是设计围绕非确定性智能体的系统。
最后的话:
“模型是马,Harness是缰绳。没有缰绳的马会失控,没有Harness的模型是玩具。”
—— Harness Engineering的核心理念
2026年,Harness不是可选项,而是必选项。
现在,开始构建你的Harness吧!
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献163条内容
已为社区贡献163条内容

所有评论(0)