RLT——VLA引导的在线RL:极简MLP结构的Actor-Critic在“VLA浓缩Token感知与VLA参考动作先验”的双重加持下进行在线快速微调,最终从粗到细搞定拧螺丝和充电器插入
前言
如今VLA可以在某部分场景下,达到“开箱即用”地学习执行多样的操作技能,但要达到实际应用任务所要求的精度和速度,仍然需要进一步微调——例如通过RL
对此,世界知名具身公司PI提出了一种轻量级方法,使得仅凭几小时的真实世界练习,就能对预训练 VLA 进行样本效率很高的在线 RL 微调(不然,RL去微调一个6B的VLA,是比较夸张的事)

具体而言,他们
- 对 VLA 做出改造,使其输出一个“RL token”,即一种紧凑的读出表征,既保留与任务相关的预训练知识,同时又作为在线 RL 的高效接口
- 在该 RL token 之上训练一个小型 actor-critic 头,对动作进行精炼,同时将学到的策略锚定在原有 VLA 上
如此,基于 RL token 的在线 RL 使得即便是规模很大的 VLA,也能通过 RL 进行快速而高效的微调
对此,本文来解读下该工作
- 毕竟PI公司发的论文,那是基本都是会详尽细致解读的,哪怕该思想暂不开源
但只要价值高,国内便会有不少研究机构/团体受其启发,而复现继而开源出相关工作- 所谓博客必读
是缘于:我博客内解读的国内外最新具身论文,以及分享的我司实践落地经验,价值高
值得读
第一部分 RL Token: Bootstrapping Online RL withVision-Language-Action Models
1.1 引言、相关工作、预备知识
1.1.1 引言
如原论文所说,通用的VLA模型可以通过数据学习到范围广泛、形式多样的操作技能。然而,它们往往在执行的“最后一毫米”阶段表现不佳:动作可能缓慢,成功完成可能需要停顿和多次重试,而在精确任务的关键阶段出现的小错误会逐步累积并导致失败
一个自然的应对方式是使用RL对 VLA 进行微调。通过在目标任务上进行练习,RL 可以针对那些对成功最为关键的任务阶段进行精确改进,而这些阶段往往正是对小误差最为敏感、也最难仅靠示范就能可靠覆盖的阶段
然而,现实世界中的机器人系统运行在严格的成本约束之下:每一次实验都需要时间,每一次失败都会消耗人力与设备磨损,而有意义的适应与调整往往必须在数小时以内的练习中完成
总之,对 VLA 进行样本高效的微调面临重大挑战
- 一方面,此前的RL没法微调快
传统的针对基础模型的RL训练方法 [1–3] 依赖大规模数据,对快速的在线适应往往效率不高 - 另一方面,此前RL一般微调小模型,但微调出来的结果是泛化性有限
现实世界中样本高效的强化学习方法 [4,5] 通常只训练规模小得多的模型,这类模型可以在数小时内取得改进,但会牺牲 VLA 的泛化能力
总之
- 直接在现实世界中, RL 微调包含数十亿参数的 VLA 基础模型,不仅计算成本高昂,而且样本效率极低(机器人收集数据非常耗时且容易产生磨损)
- 另一方面,传统的轻量级 RL 方法通常从头训练小模型,这又会丧失 VLA 强大的通用泛化能力
因此,核心问题在于:如何在保持 VLA 泛化能力的同时,实现轻量级在线 RL 的速度和样本效率
对此,来自Physical Intelligence (π)公司的研究者提出了一种实用方案,用从预训练 VLA 策略中获得的表示来引导快速的在线强化学习『其对应论文为《RL Token: Bootstrapping Online RL with Vision-Language-Action Models》』
- 他们的关键思想是对 VLA 进行适配,使其暴露出一个可被样本高效的在线强化学习利用的紧凑接口
为此,作者训练 VLA 以暴露一个 RL token,这是一种压缩表示,使与任务相关的预训练知识能够被一个轻量级的在线RL 策略访问 - 使用这个 RL token(RLT)运行强化学习,形成了一个简单的分工:冻结的 VLA 提供广泛的感知理解和动作建议,而轻量级的 actor 和 critic则在线地调整策略,以在任务中最困难的部分取得成功
为了在样本利用率至关重要的真实世界场景中保持实用性,作者采用了一种样本高效的在线强化学习算法,来训练使用 RL token 表示的小型 actor 和 critic 网络,并加入额外的正则项将 actor 锚定在 VLA 动作上,从而使在线强化学习是在已有的潜在有效行为基础上进行细化,而不是从零开始学习
1.1.2 相关工作
首先,对于视觉-语言-动作模型
- 基于大规模示范数据集的行为克隆(behavioral cloning)近来已成为训练通用机器人操作策略的主流范式(参见例如 [6–11])
支撑这一成功的两个关键要素是:动作分块(actionchunking)[12],即一次预测多个动作用于顺序的开环执行;
- 进一步的进展来自将大型预训练视觉-语言模型作为语言条件通用策略的骨干网络,形成视觉-语言-动作(VLA)模型[6,7]
这些模型将大规模网络数据上的先验知识引入到闭环机器人策略中。近期工作将 VLA 骨干与分块动作生成相结合,通过扩散模型 [8] 或自回归tokenization [14,15] 的方式,实现了当前最先进的通用操作能力
然,尽管这些策略展现出令人印象深刻的泛化能力 [9,16],但其在任一具体任务上的表现最终仍受限于其训练所用遥操作数据的质量和覆盖范围——当示范本身存在噪声或不一致时,要在对精度要求极高的任务上获得可靠成功仍然十分困难
其次,对于真实世界强化学习
- 强化学习为超越示范数据的性能上限提供了一种自然途径:通过在任务上反复练习,智能体可以发现那些从未被示范过的、更快速、更精确或更稳健的策略
在实践中,面向机器人领域的真实世界强化学习通常受到严格的样本预算约束,因为每一次机器人执行都会带来时间消耗和硬件磨损 - 离线(off-policy)的actor-critic方法,例如 [17–20]
17- Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor
18- Continuous control with deep reinforcement learning
19-Addressing function approximation error in actor-critic methods
20-Maximum a Posteriori Policy Optimisation
通过反复利用存储在重放缓冲区中的状态转移来应对这一问题,而通过提高“更新次数与数据量”的比率 [21- Dissecting deep rl with high update ratios: Combatting value divergence]
可以在一定程度上进一步提升样本效率,尽管可能需要正则化以避免不稳定性 [22-Randomized ensembled double q-learning: Learning fast without a model]
关键在于,off-policy 方法还可以利用人类示范数据来启动学习过程『例如 [23- Efficient online reinforcement learning with offline data]』
从而结合模仿学习与强化学习(RL)的优势
且越来越多的工作提出了在实体机器人上部署强化学习的实用方案,包括
自动化数据采集流程 [24- The ingredients of real-world robotic reinforcement learning]
高效的学习框架(如 SERL [4-即Hil-SERL,25] 和RL100 [5])
以及允许操作员在自主执行过程中进行干预并提供纠正的人类参与(human-in-the-loop)变体 [4-HiL-SERL]
这些系统已经证明,将 off-policy actor-critic 方法与示范和人类纠正结合起来,可以在数小时的机器人运行时间内解决高度接触(contact-rich)的操作任务
然而,它们通常是在标准预训练视觉编码器(例如 ResNet)之上,从零开始训练小规模策略,从而放弃了现代 VLA 模型中可用的丰富行为先验
RLT 通过使用冻结的 VLA 作为轻量级在线 RL策略的感知骨干和行为先验,弥合了这一差距
最后,关于对 VLA 模型进行强化学习微调
当前有一条快速发展的研究方向,探讨如何通过强化学习(RL)改进预训练的 VLA。这些方法的主要差异在于:更新哪些部分,以及如何融合 RL 信号
- 在这一谱系的一端,有若干方法会更新整个 VLA 模型
RECAP [3] 训练完整的 π∗0.6 利用基于优势的离线强化学习对模型进行端到端训练——条件化策略提取:使用分布式价值函数来估计逐时间步的优势(advantage),并在所有收集到的数据——示范、机器人自主 rollout 以及人工干预——上训练 VLA,同时引入一个最优性指示器,对高优势动作进行更高权重的强调
通过在机器人在线数据收集与离线强化学习更新之间反复迭代,RECAP 在复杂的长时序任务(如制作浓缩咖啡、叠衣服和装箱)上将吞吐量提高了两倍以上
其他工作将近端策略优化(PPO)或其变体应用于 VLA 的微调(如[1,26,27]),但 on-policy 方法很难以采样高效且可扩展的方式推广到真实世界的强化学习 - 另一端,一些轻量级方法避免更新整个 VLA,而是仅在冻结模型之上训练一个小型辅助模块
ConRFT [28] 冻结VLA 编码器,并使用基于一致性的训练目标配合一个学习得到的二元奖励分类器,只对动作头进行微调,但其在短时序任务中仅对单步动作进行操作而不进行分段(chunking)
Policy Decorator [29] 学习一个残差策略,其输出通过手工调节的超参数进行缩放后加到冻结 VLA 的预测上,但仅在仿真环境中被验证,且需要极高的样本量(数量级达数百万步)
Probe-Learn-Distill(PLD)[30] 先在基础策略rollout 上使用 Cal-QL [31] 预训练一个 critic,然后在冻结 VLA 之上学习单步残差策略,并可选择通过有监督微调将结果蒸馏回 VLA
GR-RL [2] 采用多阶段方法,将通用 VLA 专门化到长时序的系鞋带任务:
DSRL [32] 同样在扩散噪声空间中运行,学习一种潜在策略,该策略调节去噪过程,引导动作朝向高回报区域
RLT 与这些方法共享同一目标:在不承担全模型强化学习(full-model RL)代价的前提下改进一个预训练的VLA,但在若干关键设计选择上有所不同
- 首先,RLT引入了一个 RL token
这是一种经过训练用于压缩VLA 内部嵌入表示的紧凑读出表示——作为轻量级actor-critic 的状态观测,从而在保留 VLA 预训练感知结构的同时,实现高效的在线学习 - 其次,RLT 在与VLA 原生动作接口对齐的分块动作(chunked actions)上运行,在高控制频率且奖励稀疏的设定下,缩短了时序差分学习的有效决策视野;这与单步方法
28- Conrft: A reinforced fine-tuning method for vla models via consistency policy
29- Policy decorator: Modelagnostic online refinement for large policy model
30 -Selfimproving vision-language-action models with data generation via residual rl,详见此文《PLD——自我改进的VLA:先通过离策略RL学习一个轻量级的残差动作策略,然后让该残差策略收集专家数据,最后蒸馏到VLA中》
形成对比,后者面临更长的信用分配(credit-assignment)问题 - 第三,RLT 的 actor 并非预测残差或潜在噪声,而是直接以 VLA 采样得到的参考动作块(reference action chunk)为条件,并通过正则化将其约束在该参考动作附近,从而把在线强化学习从无约束搜索或对扩散过程的隐式调制,转变为对一个良好 VLA 先验行为策略的局部细化
总体而言,这些设计选择使得在真实机器人上进行样本效率很高的在线强化学习成为可能——在数小时的练习内就能同时提升成功率和执行速度
1.1.3 预备知识
首先,对于视觉-语言-动作模型
大规模VLA 模型从多样化的人类示范数据集中学习操作行为,这些数据集跨度达数万小时,在某些情况下还结合了非机器人视觉-语言数据[7, 9,16]
一个典型的VLA 包括两个组件:
- 一个VLM 骨干网络
即将多模态输入(图像、语言指令和本体感觉状态)编码为共享token 序列的视觉-语言模型 - 一个动作专家
即一个基于扩散的模块,它关注骨干网络的tokens 并通过迭代去噪生成连续动作
作者基于π0.6 模型[33] 构建
- 给定最多四张相机图像、一条语言指令
,以及本体感觉状态
, π0.6生成一个动作序列(称为一个动作块):
一个长度为H = 50 的动作序列,对应1 s 的控制 - 且作者用
表示由预训练VLA 产生的分块策略
在实践中,机器人仅以开环方式执行该动作块的前缀(例如前20 步),然后再从新的观测重新规划
由于某些任务的难度(例如高精度任务),为这些任务在大规模上收集大量高质量的模仿学习数据是具有挑战性的,这限制了VLA 在这些任务上的性能
其次,对于强化学习和actor-critic 方法
作者将机器人控制形式化为一个马尔可夫决策过程(MDP)
其中
是状态观测空间
是连续动作空间
表示转移动力学
是奖励函数
是折扣因子
RL 的目标是学习一个策略,使期望折扣回报最大化:
其中
表示由策略π 诱导的轨迹分布
- 作者仅能获得稀疏的二值奖励:人工监督者在每个episode 结束时将其标记为成功或失败,对于成功我们设定
,否则
进一步,策略π 的动作价值函数为
- 在作者的设置中,策略和评论家都作用在动作块
上,其中
表示RL 的块长度(
表示由VLA 预测的块时域)
且选择以赋予策略更强的反应能力,以及将块化策略定义为
,并配以相应的基于块的C 步价值估计
- 且作者基于经典的离策略actor-critic 方法[17, 19, 34],联合训练随机actor
和评论家
关键在于,学习是离策略的,使用存储在重放缓冲区(replaybuffer)中的转移数据,而不考虑生成这些数据的策略
作者强调,这一特性在他们的设置中至关重要,其中B 聚合来自VLA 策略、RL 学习器以及人类遥操作干预的数据
1.2 基于 RL Token 的强化学习
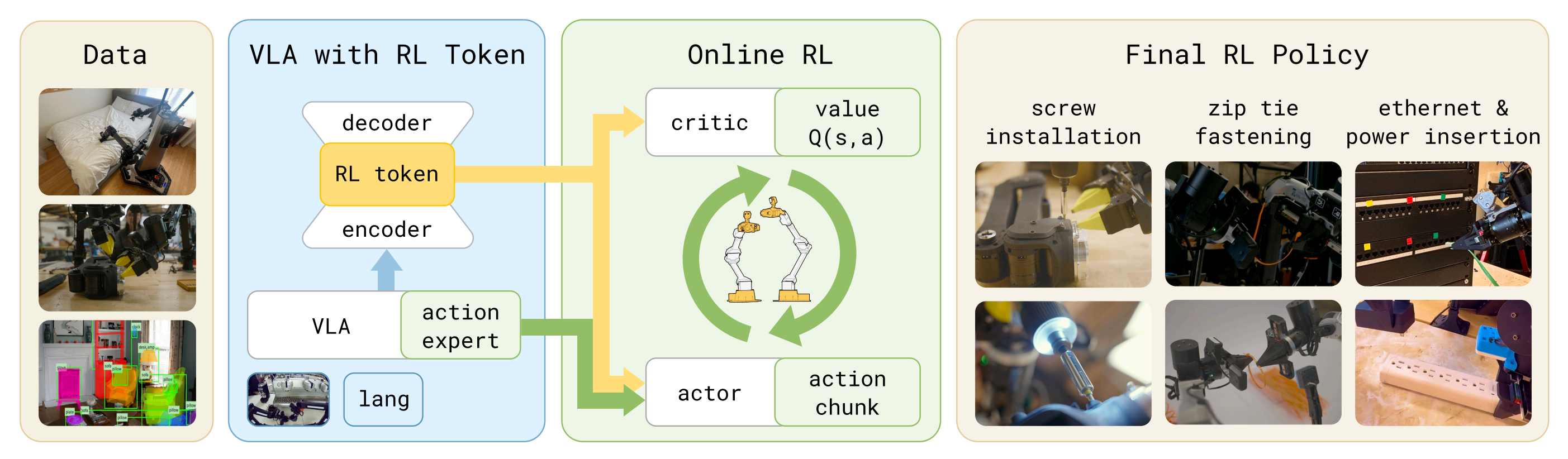
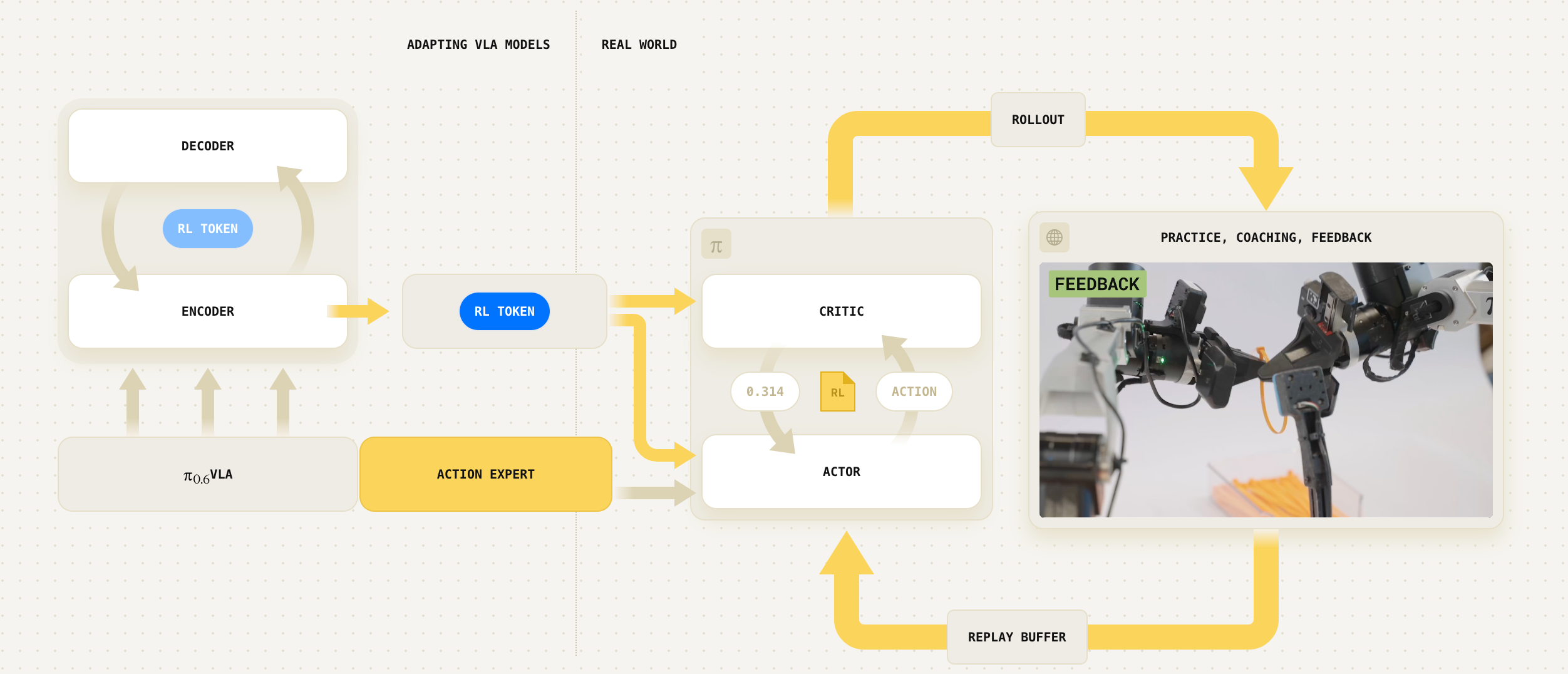
下图总结了作者利用 RLT 使预训练 VLA 模型实现快速且稳定的在线强化学习(online RL)的整体方案
核心思想是在最大程度上利用预训练 VLA,以提升强化学习训练过程的效率
直接用在线 RL 训练整个 VLA,可能在算力和样本效率上都极其低下,难以在短短数小时内获得性能更优的策略。相反,作者使用冻结的VLA 来提供强化学习的状态表征、提供参考动作,并引导探索朝向接近其自身预测的动作,同时只使用一个小规模的 actor 网络和 critic 网络
- 首先在少量任务特定的示范数据上对 VLA 进行适配,一方面改进其初始任务策略,另一方面为后续 RL 暴露一个 RL token作为下游强化学习的输入
- 随后,作者冻结 VLA,并在线训练轻量级的、基于离策略(off-policy)的 actor和 critic 网络,这些网络以 RL token 表征以及 VLA 的参考动作为条件,同时对学得的策略进行正则化,使其保持接近 VLA 模型
————
作者的方法将在线 RL 从“无约束搜索”转化为对一系列有前景行为的“局部细化”
这种设计使在线 RL 具备小型 actor-critic 算法的高效率,同时保留预训练 VLA 模型的表征能力和行为模式
1.2.1 将 VLA 适配为暴露一个 RL 接口
样本高效的在线强化学习在很大程度上依赖于状态表示的选择。将强化学习直接应用于完整的 VLA 模型并不适合快速的真实世界自适应:其表示维度很高,而且对这个拥有数十亿参数的模型进行在线更新在计算上代价高昂、在样本利用上也很低效
- 与此同时,作者又希望利用经过预训练后已经包含在 VLA 内部的表示,因为它是在大规模网页和机器人数据上训练得到的,已经蕴含了对许多任务的动作生成有用的信息
- 然而,对于基于Transformer的VLA中的哪些特征能构成适用于在线强化学习的良好表示,这点并不明显,而且每个转换器层中的嵌入都是高维的
因此,作者的目标是将 VLA 表示压缩成一种紧凑的强化学习嵌入,在保持与任务相关信息的同时,又足够小,以支持轻量
通过添加一个RL token(图2)来实现这一点:这是一个学习得到的读出嵌入,用于将VLA 的知识汇总为一个小向量,作为RL 状态『RLT 在预训练的 VLA 上添加了一个编码器-解码器 Transformer。它生成 VLA 表征的压缩嵌入(即 RL token)。这种表征随后支持在在线RL过程中进行数据高效和参数高效的微调』
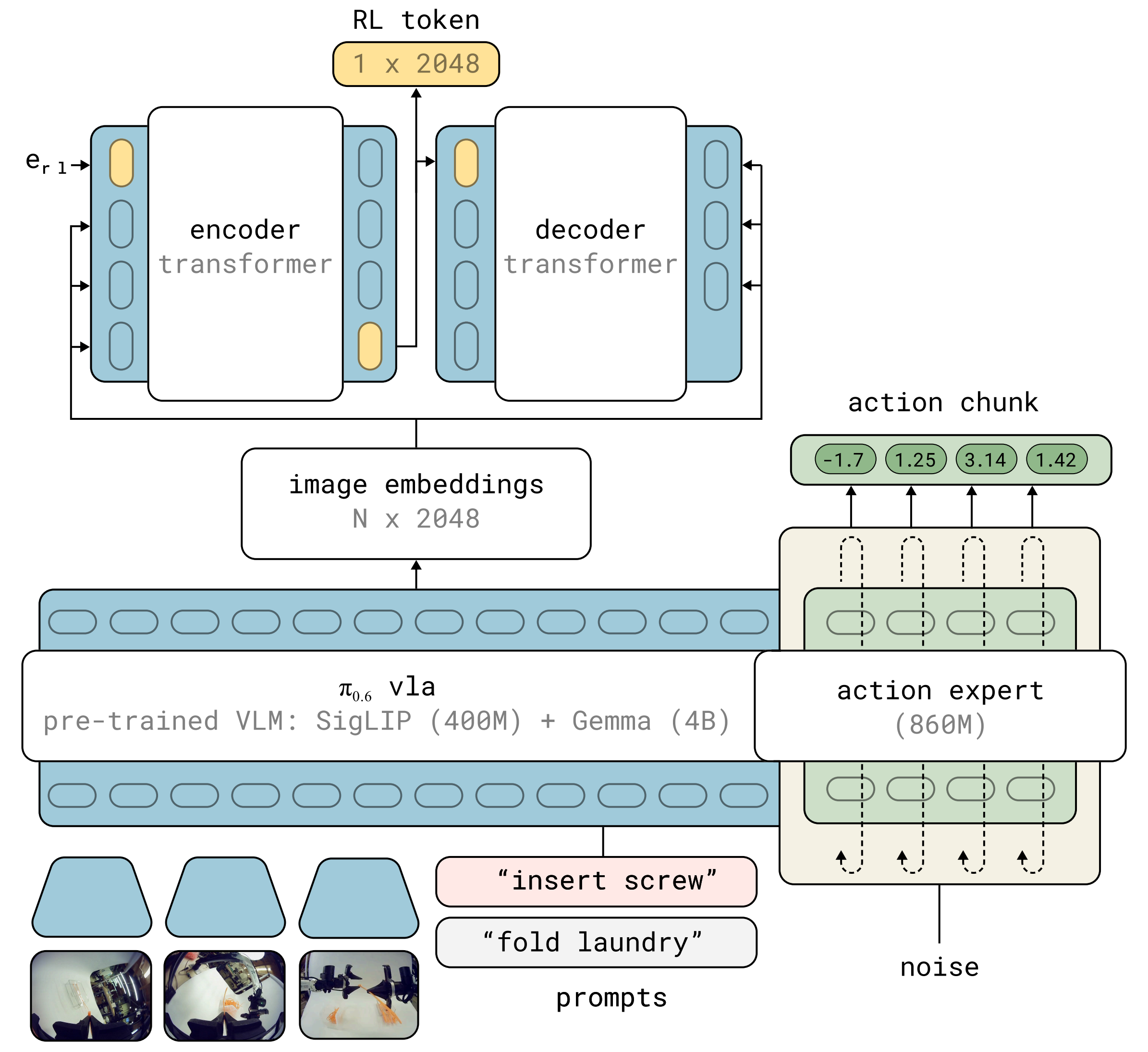
- 具体来说,作者通过在预训练VLA 上添加一个小型的额外transformer 来获得RL token
且以encoder-decoder [35] 的方式训练这个transformer,其中encoder 的最后一个输入是RL token
由于RL token的表示必须保留足够的信息以使decoder 能够重构输入,它起到了瓶颈的作用
————
说白了,这个模式类似VAE,就是为了训练学习出一个RL token,可以表示VLA上有用的信息,即encoder 把 N 个 2048 维的 token embedding 压缩成一个 2048 维的向量——这就是 RL Token。decoder 负责从这个 RL Token 重建原始的 embedding 序列,确保压缩过程中没有丢失关键信息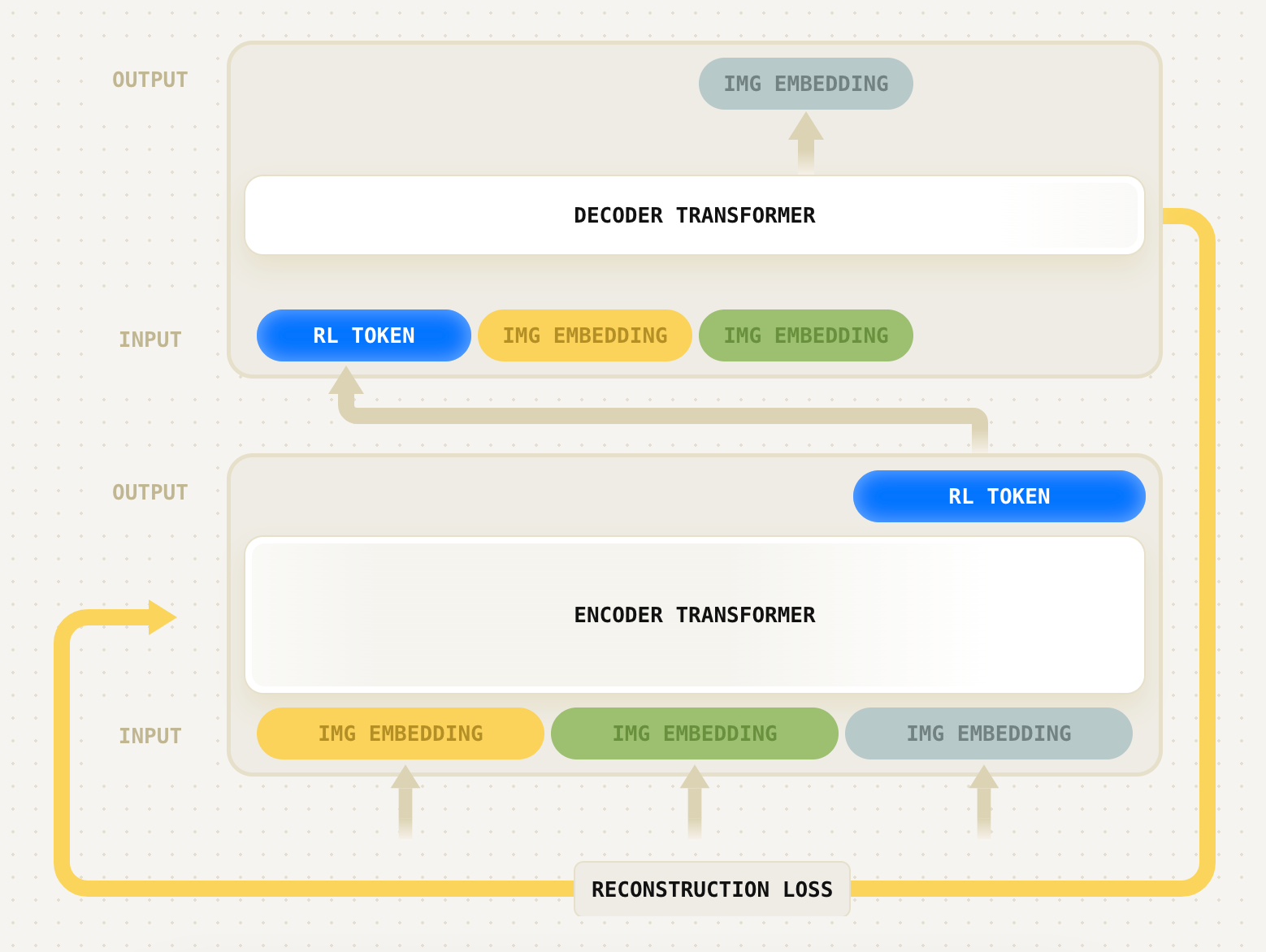
- 令
表示预训练VLA 在状态
和语言指令
下产生的最终层token 嵌入
嵌入分解为
,其中每个
对应一个输入token 的嵌入
作者将一个学习得到的嵌入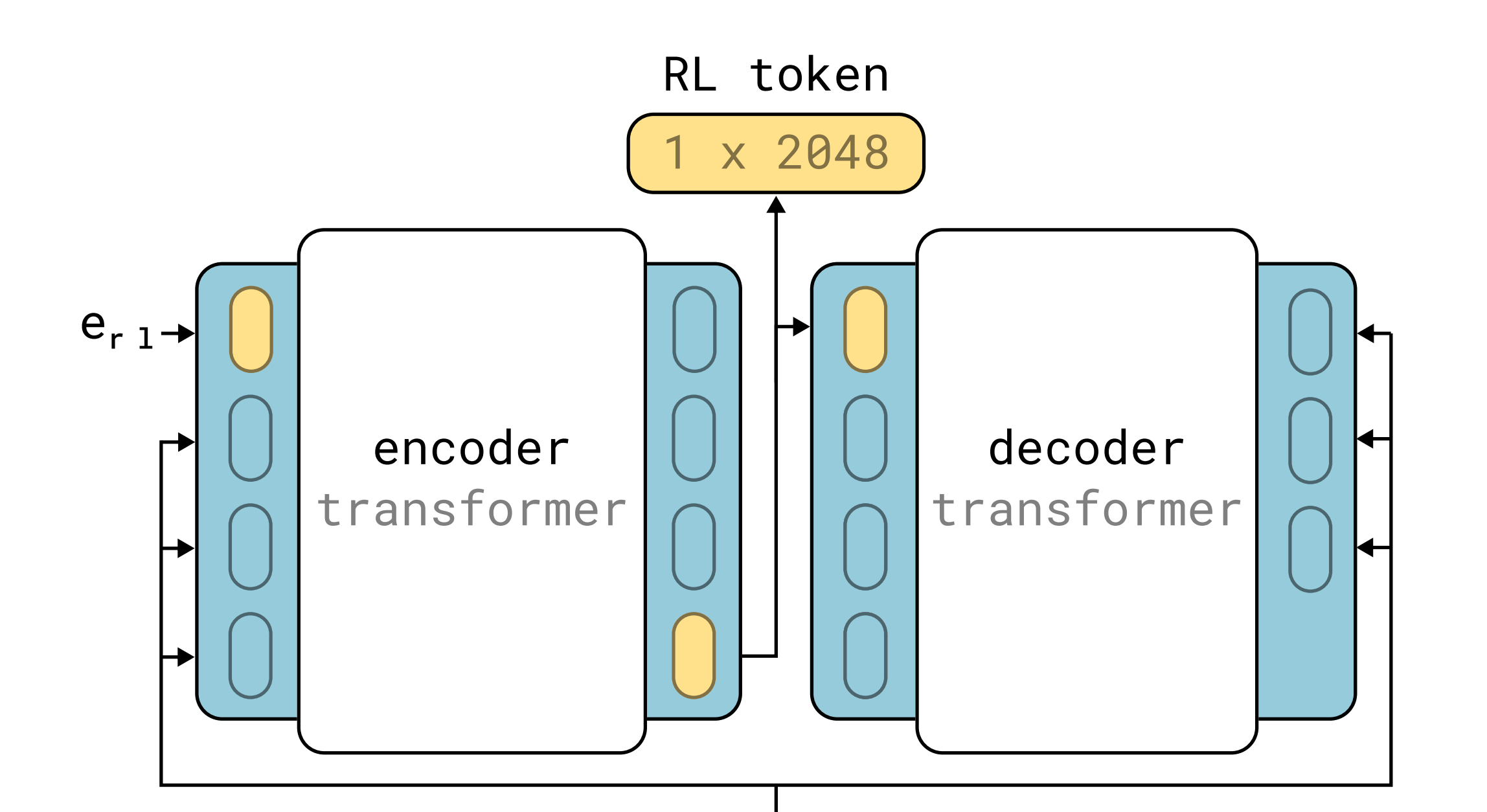
附加到序列后面
处理这一扩展序列
encoder 在该特殊token位置的输出,记为,就是RL token
的解码器Transformer
,从
令表示应用于 VLA 嵌入的停止梯度操作,那么在演示数据集 D 上的自回归重构目标可表示为
作者在一个小规模的任务特定示例数据集上训练参数,同时将VLA 相对于
视为冻结状态,并(可选地)将其与对VLA (
) 的监督微调结合起来
之后,
1.2.2 使用在线RL优化 VLA 动作块:先训练critic,再训练RL Policy
在初始适应阶段之后,作者冻结VLA 和RL token表示。然后作者在线训练轻量级的actor () 和critic (
) 网络
- 它两都有一个输入
,该
一方面是RL token
二方面是与任何有助于实现闭环控制的额外信息结合在一起(例如机器人的本体感受状态)
- 值得注意的是
不是从零生成动作,而是被训练去改进由VLA 提出的动作序列
(称为参考动作块),最终输出实际动作块
,其估计状态和动作的价值:
——相当于是预测的
说白了,Actor 的输入
- 不仅包括状态
- 还直接输入 VLA 生成的参考动作块
最终输出实际动作块
,这使得 RL 变成对优秀初始方案的“局部微调”,而不是盲目的从头搜索
首先,训练评论器
作者的评论器以状态和实际动作块
作为输入『Our critic Qψ(x, a1:C ) takes as input the state and the action chunk a1:C』
作者使用标准的离策略时序差分学习,在从回放缓冲区B 中采样的动作块转移上训练评论器——定义为公式3:
- 上面第一行 代表真实的
表示下一个输入状态
表示从RL 策略中采样
- 上面第二行 代表真实
与 预测的
之间 建loss
其中输入状态为
如上面提到的,其中表示为状态
为了帮助大家更好的理解,我还是针对上面的公式3 再给解释说明下
首先,先计算“真实目标分”
这行公式是在算:机器人在当前状态
下,执行完这一套包含
前半部分(落袋为安的真实奖励):
这套动作块执行期间,机器人实打实拿到的反馈分数的总和 。因为有时间先后,所以乘上了折扣因子后半部分(对未来的预期估值):
动作块执行完后,机器人来到了一个新状态,需要让目标网络(一个更新较慢、更稳重的 Critic)评估一下,在
大白话总结
其次,计算“打脸程度”并修正
这行就是 Critic 的更新目标了
:我们从经验回放池
大白话总结
: 让 Critic 对照着事后诸葛亮算出来的“真实目标分”,去反思自己之前的“预测分”错得有多离谱,然后通过反向传播调整自己的参数,力求下次打分更准
在实践中,作者遵循TD3 [19-Addressing function approximation error in actor-critic methods],并且ψ′ 是目标网络的参数
论文里提到的 TD3(Twin Delayed Deep Deterministic Policy Gradient),是RL用来解决 Critic 网络“盲目自信”问题的一个经典算法
TD3 最核心的是“保守派”机制,用大白话解释就是:双重审查,取最低分
- 请两个“评论家”: 系统里不是只训练一个 Critic 网络,而是同时训练两个独立的 Critic 网络(Two Q functions)
- 打分取保守值: 当需要评估机器人未来的动作能拿多少分(即计算目标 Target 值)时,让这两个 Critic 分别打分,然后强制取两者中较低的那个分数
为什么要这么折腾?
- 在强化学习的探索阶段,Critic 网络特别容易“盲目乐观”(学术上叫 Overestimation 过高估计)。比如机器人在练习插以太网线时,偶然间用了一个极其怪异的姿势碰巧插进去了,Critic 就会给这个充满水分的动作打极高的分
如果 Actor 听信了这个虚高的分数,就会去死记硬背这个华而不实的废动作,导致训练跑偏甚至崩溃- 采用 TD3 的这种“取最小值”策略,相当于给打分系统加了一个“防盲目乐观”的阀门:只有当两个独立的评论家都觉得这个动作靠谱时,系统才会真正认可它
其次,训练RL 策略
当上面训练好了Critic,便可以用其训练策略了
作者的actor 网络在动作块上产生高斯动作分布。它接收
- 输入状态
- 一个参考动作块
如上文说过的,Actor 的输入
- 不仅包括状态
- 还直接输入 VLA 生成的参考动作块
最终输出实际动作块
并生成该动作分布——定义为公式4:
- 其中,如前所述,
上进行条件化使得actor 可以直接接触到VLA 预测的动作
从而在线RL是在一个强有力的初始方案基础上进行精炼,而不是从零开始学习 - 第二个好处是,被采样的参考片段保留了VLA 多模态动作分布中的模态信息,否则对于单峰高斯actor 来说将很难恢复这些信息[36]
且作者进一步通过将其动作正则化到参考动作来稳定学习
- 具体来说,作者在使actor 最大化critic 价值的同时,优化其保持接近VLA 参考片段
这 5 篇论文都深入探讨了带有 KL 散度正则化(或相对熵)的RL策略搜索。在咱们这篇 RLT 论文里,作者为了防止小模型(Actor)在探索时瞎跑,强制要求它生成的动作不能偏离 VLA 大模型给出的“参考动作”太远
这种“不要离先验知识太远”的数学思想,正是来源于这几篇奠基性的老论文
————
这实际上将在线RL转化为围绕 VLA 生成的动作分布进行局部动作编辑,而非在高维动作块上进行无约束搜索 - 而用于学习该RL策略的目标函数为——定义为公式5
其中系数β 控制着行为者被正则化到采样VLA 动作的强度
说白了,让 Actor 在力求拿高分(最大化 Q 值)的同时,必须老老实实待在参考动作附近(BC 正则化)
最后,对于参考动作 dropout
- 参考动作条件化的一个实际失效模式是:actor 可能只是简单地复制
- 为防止这种情况,作者采用参考动作 dropout:对每个训练 batch 中的一个随机子集的轨迹,在将参考片段传入 actor 之前,用零替换该参考片段
这样会强制 actor 维持一条独立的动作生成路径
“这是一个很巧妙的 trick。训练时随机把一部分 batch 的参考动作置零,强迫 actor 维持独立的动作生成能力。否则 actor 会偷懒,直接复制 VLA 的动作,什么都学不到”
同时在参考片段存在时,仍然允许其利用 VLA 的动作分布
在实践中,一旦 critic 能提供有用信号,actor 就会自然地在偏离参考动作能够提高预测价值时偏离该参考动作
1.3 RLT的完整算法流程
1.3.1 RLT的完整训练循环(算法1的逐行解读)
算法 1 总结了作者的完整训练循环

为了方便大家更好的理解,我再给上述算法1 一行一行的解读下
开局准备 (Require): 把该准备的物料都备齐:冻结的 VLA 基础大模型
、之前跑的少量演示数据
、用来存经验的回放池
等各种超参数
第一阶段:提取“浓缩精华” (第 1-3 行)
- Line 1-2: 我们的目标是训练出 RL Token,如果需要的话顺便微调一下 VLA
- Line 3: 这是一个自编码器(Encoder-Decoder)的训练过程
就是强迫一个小网络,仅仅通过一个极小维度的 Token,就能还原出 VLA 庞大的内部特征
,这就像是把一本厚厚的字典压缩成了一页摘要
训练好之后,这个网络参数第二阶段:实机运行与“军师”干政 (第 4-12 行)
- Line 4-5: 轻量级打工仔入场。初始化我们要在线训练的 Actor 策略网络
- Line 6: 开始在真实环境里循环干活
注意,这里的时间步是按动作块长度
),而不是一步一停 。这极大缓解了高频控制(比如 50Hz)带来的计算压力
- Line 7-8: 每次动手前,先问 VLA 两个问题:
第一,你建议这步该怎么做?(拿到参考动作块);
第二,现在的局势浓缩成 Token 是啥样?——拿到,然后把 Token 和机器人的关节、末端姿态等本体感觉
拼在一起,作为 RL 的完整输入状态
————
此,即如上所说的,Actor 的输入- Line 9: 这是决定“到底听谁的”关键时刻
系统按优先级做判断:)
),用来往回放池里垫点底
)
- Line 10: 机械臂真正去执行这套动作块,并看看拿到什么奖励
,来到了什么新状态
- Line 11: 偷师小贴士。如果这一步是人类接管的,系统会偷偷把本该是 VLA 给的“参考动作”,强制替换成人类的动作 。这样在后续复盘时,Actor 就会直接向人类专家看齐
- Line 12: 把刚才这一回合发生的所有事(当前状态、执行的动作、参考动作、拿到的奖励、下一个状态),统统打包丢进经验回放池
第三阶段:脑内复盘与极速学习 (第 13-19 行)
- Line 13: 机器人每在现实里执行一次动作块,脑子里就要循环复盘
次 。这种高频更新(高 Update-to-Data ratio)是让模型在物理世界用少量数据快速变聪明的关键机制
- Line 14-16: 先从经验回放池
先按照第15行 计算出“真实目标分”
然后按照我们之前聊过的公式 3,即第16行 让 Critic 去修正自己的打分误差,让自己看动作越来越准
- Line 17: 按照公式 5 更新 Actor
用大白话说就是:让 Actor 在力求拿高分(最大化 Q 值)的同时,必须老老实实待在参考动作- Line 18-19: 结束脑内循环和这一个执行步骤,进入下一轮迭代


1.3.2 算法1的外循环、内循环的更多细节
在最初的预热阶段,作者使用基础 VLA 策略收集若干个 episode,之后训练过程在“在机器人上收集经验 ”与“从重放缓冲区执行基于回放的 actor-critic 更新 ”之间交替进行
重放缓冲区汇总了 VLA 预热数据、在线强化学习 rollout,以及可选的人类干预数据。此外,一名人工监督者会提供稀疏的成功/失败标签
- 首先是预热
在训练RL token表示(Sec. IV-A)之后,作者通过在环境中运行VLA 参考策略步来预先填充重放缓冲区
这为评论器提供了初始学习信号,并确保在线RL 从表现良好的VLA 行为开始 - Rollout
在在线收集过程中,在每个动作块边界处,冻结的VLA 生成一个参考动作块,而RL token 模块提取
然后actor 输出一个动作块
且为了加速接触丰富或安全关键行为的学习,人类操作员可以选择性地通过提供遥操作指令进行干预,在干预期间这些指令会覆盖actor 的输出
发生这种情况时,干预会在回放缓冲区中替换VLA 参考——相当于人工干预是被视为最权威的
————
在所有情形下,存储在 - 子采样动作块
虽然RL 策略使用动作块长度
因此,可以通过将中间步骤存入重放缓存来增加数据量并提升学习效率
具体来说,作者选择步长为 2,并将对应于等的转换保存到重放缓冲区中
需要注意的是,由于该强化学习算法是离策略(off-policy)的,作者可以使用所有的动作块(包括 VLA 生成的动作和人工干预产生的动作)
相当于,虽然 RL 策略每 10 步决策一次,但中间的每 2 步都会存一个 transition 到 replay buffer 里,这样同样的经验可以产生更多的训练数据
- 更新
策略更新依据算法 1,从重放缓冲区以离策略方式进行。为在训练过程中保持计算和时间效率,作者异步地执行 rollout 和学习过程
在实践中,作者为每一次actor 更新执行两次 critic 更新,并在预热阶段结束后不久就开始学习。且使用较高的更新与数据比率,这在低数据的在线设置中至关重要 - 针对关键阶段的定向改进
为兼顾学习的实用性和效率,作者将 RLT 应用于每个任务的关键阶段——即那些最困难、需要高精度的部分——并让基础 VLA 完成任务中较为简单的部分
具体来说,每个 episode 都从执行基础模型开始。在数据收集过程中,人类操作员可以选择在何处将控制权从基础 VLA 交接给 RL 策略。这类似于交互式模仿学习 [41] 中的人类干预决策
随后,系统对所选任务片段应用 RL,在该关键阶段存储并利用状态转移进行训练,直至从人类操作员处接收到表示 RL 任务成功或失败的终止信号
这样就将数据收集与责任分配集中在在线适应性最为重要的行为部分
————
另,为了在测试时实现自主执行,作者可以在训练结束时对 VLA 进行一次简短的最终微调阶段,要求它额外预测何时应将执行权移交给 RL 策略(使用人为干预作为标签)
随后,作者便可以在测试时自动触发策略切换
第二部分 真实世界实验
作者在四个真实世界的操作任务上评估 RLT,这些任务都需要灵巧控制和亚毫米级精度
- 一个预训练的 VLA 为这些任务的大部分步骤提供了有力的初始策略,但最终的成功率和执行速度取决于对关键的、接触密集且最需精确度的阶段进行精细化调整
- 且作者的实验旨在检验在促使该方法产生的实际限制条件下,方法是否能够带来这样的改进:机器人交互时间有限、人类监督稀少以及在线学习轻量
且作者围绕以下问题来组织评估:
- Q1.RLT 能否在操作任务上提升相对于基础 VLA 模型的性能?
- Q2.RLT 在这些任务上与其他 RL 方法相比表现如何?
- Q3. 方法的各个组成部分——RL token、分块动作预测、策略正则化,以及参考动作透传——分别对方法的性能有多大贡献?
- Q4. RLT 是否能够使策略发现更优的策略?其所得策略与原始示范数据相比如何?
2.1 任务设置
2.1.1 4个具体的任务与对应的关键阶段评估、全任务评估
首先,作者在以下任务上对他们的方法进行评估(见图 3):

- 螺钉安装
机器人必须使用电动螺丝刀将一颗 M3螺钉旋入带有螺纹的螺纹孔中。这需要在螺钉头部与螺丝刀尖之间实现亚毫米级的对准
该任务尤其困难,原因在于:
1) 螺钉可能并不总是完全垂直站立
2) 在握持螺丝刀时,由于螺丝刀尖端与夹持点之间相距 10 cm,末端执行器的任何微小转动都会被放大
3) 关键的视觉线索主要来自对侧机械臂上安装的广角腕部相机,因此在感知上构成了极大挑战 - 扎带固定
机器人必须将扎带尾端穿过其狭窄的锁扣槽。该任务涉及在严格公差约束下,对一件可变形物体进行协调的双臂控制
成功插入需要仅通过腕部摄像头推断出针尖和插槽的位置,并以毫米级精度执行操作 - 以太网插拔
机器人必须将以太网连接器插入一个凹陷的端口中。这需要精确的空间位置和角度对准,随后进行一次有力且果断的插入力度动作
即便是很小的姿态误差或犹豫的接触,通常也会导致连接器卡在外壳上而不是插入端口,从而使得任务的成功对精度和接触动力学都极为敏感 - 充电器插入
机器人必须将充电器对准并插入插线板。该任务较为困难,因为策略必须在插头与插座并非始终清晰可见的情况下,实现厘米级的对准精度,轻微的对准误差往往会导致反复试探或插入失败
每个任务都包括抓取、重新放置和对齐三个阶段,持续时间为 30–120 秒(在 50 Hz 控制频率下约对应 1500–6000 个控制步)
对于每个任务,作者都会识别其关键阶段——即插入、紧固或旋转过程——在这一阶段对精度的要求最高,也是基础 VLA最常减速或失败的部分。这些关键阶段通常持续 5–20 秒(250–1000 个控制步)
其次,对于关键阶段评估
- 由于作者的方法正是为了改进这些关键阶段而设计的,故作者首先将评估重点放在仅针对关键阶段的方法比较和消融实验上
在这一设置下,每个 episode在重置到关键阶段前的部分完成任务状态后开始,初始构型会做轻微随机化 - 例如,在扎带紧固任务中,在插入尝试开始之前,机器人就已经抓住扎带的两端
这样的设置将评估集中在对精度要求最严格的片段上,在该片段中预期 RL 的作用最大,同时减少来自任务早期阶段(如抓取和搬运)的混杂方差,而这些阶段已经能被基础 VLA 相对良好地处理
在这一受控设置中,每个智能体在每个任务上均评估 50 个 episode
最后,对于全任务评估
受控的关键阶段评估有助于隔离作者的方法所针对的瓶颈,但它无法涵盖长时间跨度执行过程中全部的变动性
- 因此,作者还在更为真实的设置下评估完整任务的性能:机器人从其“初始位置”开始,先用基础策略执行任务的前置阶段,并在该执行所引起的状态变化下进入关键阶段
- 在这种设置下问题显著更难,因为通过 RL 改进的行为必须在由前序策略生成的更宽广状态分布下仍然保持有效
对于完整任务的训练,作者首先让 RL 在带有小幅随机扰动的关键阶段上进行学习,然后再转入完整任务设置
2.1.2 实验细节:包含轻量级Actor-Critic背后的模型结构——MLP
RL 策略的输入由RL token(由两个腕部相机图像和一个基座相机图像生成),以及额外的本体感受状态组成
有两点值得强调一下
第一,在实验中,RL Token 的源头数据就是机器人身上的三个摄像头(两个腕部相机、一个底座相机)拍到的实时画面
第二,更准确的讲,应该如上文说过的,Actor 的输入
- 不仅包括状态
- 还直接输入 VLA 生成的参考动作块
最终输出实际动作块
且根据任务不同,该辅助状态可能包括关节位置(螺丝)、末端执行器位姿(扎带、以太网和充电器)
作者使用π0.6 [33] 作为基础VLA 策略,机器人以 50 Hz 的控制频率运行。由于每个时间步的动作空间为 14 维,这对应于强化学习(RL)策略的一段 140 维分块动作。更多实现细节见附录 B
如原论文附录B 其他实验细节所述
- 首先,作者在目标任务上收集一个示范数据集;随后,在该单任务数据上对基础 VLA 模型进行微调,并训练 RL token,训练步数在 2000 到 10000 个梯度步之间
- 之后,在在线强化学习训练阶段,VLA 模型保持冻结不再更新
在在线RL 过程中,作者从头开始初始化RL actor 和critic
- 对于扎紧扎带、以太网以及充电器插入任务使用两层MLP(隐藏维度为256)
对于更具挑战性的螺丝安装任务,使用由三层MLP 组成、隐藏维度为512 的更大网络。两个网络都将由冻结的基础VLA 模型产生的RL token、本体位置和速度作为输入
critic 使用由两个Q 函数构成的ensemble 进行训练,遵循Fujimoto 等人[19] 的方法,并使用这两个Q 函数的最小值来计算目标值- actor还额外接收由VLA 模型产生的参考动作块,在训练过程中以50 % 的概率被mask 掉,而在推理时始终提供
actor 被参数化为高斯策略,具有较小的固定标准差,从当前观测中输出一个动作块,其中
这意味着一个 20 秒的任务,RL 只需要做大约 100 次决策,而不是 1000 次。信用分配的难度直接降了一个数量级
- 且如上文所说过的,为了提高样本效率,作者在训练过程中以相隔2 个控制步长的方式对动作块进行子采样,因此每秒数据大约为RL 网络产生25 个样本
在训练期间,当RL 任务完成时,操作员会提供稀疏的+1 奖励对于螺丝安装和扎带固定这两类任务,作者
- 首先仅在关键阶段(critical-phase)设置下启动强化学习(RL)训练
- 随后再推进到完整任务阶段:先运行基础模型完成任务的非关键阶段,一旦进入关键阶段则切换为执行 RL 策略
这种两阶段训练策略在提高训练效率的同时,确保 RL 策略对由基础策略在任务前半段所诱导的初始分布具有足够的鲁棒性。在收集约 5 小时的数据后,作者对策略性能进行评估和报告
为方便大家一目了然,我再用一个表格总结下
维度 / 模块 Actor(执行者 / 策略网络)
Critic(评论家 / 价值网络)
基础骨架 多层感知机 (MLP)
多层感知机 (MLP)
网络规模
(按任务难度分)
常规任务(如插网线、充电器、扎线带):2 层网络,隐藏层维度 256
困难任务(如拧螺丝):3 层网络,隐藏层维度 512
同左侧 Actor,根据任务难度保持一致的设计结构 共享输入端
(看清局势)
1. VLA 浓缩 Token(提取的高维视觉与操作特征)
2. 机器人本体感觉(当前的关节位置、运动速度等)
1. VLA 浓缩 Token
2. 机器人本体感觉
独有输入端
(各自的依据)
VLA 参考动作块
Actor 执行的动作块
输出端格式
(最终产物)
高斯策略分布:输出一组包含 10 步控制指令的动作块(
)
动作估值(Q 值):输出一个标量分数,预测这套动作未来的总收益
工程优化核心
(实机求稳的 Trick)
参考动作 Dropout:训练时有 50% 的概率遮挡参考动作,倒逼 Actor 独立思考,不能死抄答案
双重审查 (TD3机制):内部实际包含 2 个平行的 Q 网络,打分时取两者的最小值,防止盲目乐观
相当于,VLA 大模型已经把最吃算力的“高维视觉特征提取”做完了,所以 RL 的 Actor 和 Critic 只需要用最薄的 2~3 层全连接网络(MLP)就能跑满 50Hz 的物理高频控制 ,在不拖慢硬件响应速度的前提下,实现极低成本的“最后一毫米”精准微调
2.2 基线方法与消融实验
作者从一个预训练的 VLA 模型 π₀.6[33] 出发
- 对于每个任务,作者收集 1–10 小时的遥操作示教数据
随后,作者在训练 RL token 表征的同时对该 VLA 模型进行微调。这一过程产生了他们在所有实验中使用的基础 VLA 策略 - 根据任务难度不同,作者运行400 到 1000 个回合的强化学习训练
除去重置和各种额外开销,每个实验大约产生 15 分钟到 5 小时的真实机器人数据。最终以每个任务上的成功率来度量性能,该成功率由人类操作员给出的二值奖励信号判定
- 且作者还报告吞吐量,即在每 10 分钟时间间隔内成功完成任务的次数,以便从鲁棒性和速度两个维度评估性能提升
- 此外,作者在各任务的关键阶段进行评估,并在完整任务设置下,对两个更具挑战性的任务——拧螺丝任务和扎扎带(扎带)任务——进行评估
作者将 RLT 与四种从经验中改进策略的基线方法进行比较。为保证公平比较,作者为每种强化学习方法使用相同数量的数据进行训练(见附录 C,比如对于所有基线方法,作者使用与他们方法相同的环境和动作空间设置——策略以 50 Hz 的频率在 delta 动作空间中执行)
- HIL-SERL[4]
与作者的方法类似,HIL-SERL 使用经验与干预相结合的方式训练一个小型 actor 和 critic
但不同于 RLT,它不使用来自预训练 VLA 的表征,而是使用一个为标准计算机视觉任务预训练的简单 ResNet 编码器
详见此文《HIL-SERL——结合“人类离线演示、在线策略数据、人工在线干预”的RL方法:直接真实环境中RL开训,可组装电脑主板和插拔USB》
————
且按照原始实现,作者使用 20 个示范轨迹来初始化 RLPD 训练,并在整个训练过程中提供干预。然而,在作者的设置中它未能成功,原因是作者的控制频率更高(50 Hz,相比原系统的 10Hz),并且缺少用于缩减探索空间的动作空间边界框 - Probe-Learn-Distill[30]:PLD 学习一个残差策略,该策略为每个单步动作输出一个残差。它将该残差按一个超参数进行缩放,并与冻结的 VLA 的一步动作预测结果相加后执行
详见《PLD——自我改进的VLA:先通过离策略RL学习一个轻量级的残差动作策略,然后让该残差策略收集专家数据,最后蒸馏到VLA中》
————
且按照原始论文中的方法,首先使用 Cal-QL [31]在 50 条基础策略(base policy)的 rollout 上预训练评论家网络(critic network),以提高样本效率。随后进入在线强化学习阶段 - DSRL[32]:DSRL 在流式 VLA 模型的潜在噪声空间中学习一个在线强化学习策略。它通过选择输入到冻结 VLA 模型动作生成器中的噪声来“引导”VLA 的动作生成。该方法以隐式方式将探索限制在那些可以由VLA 生成的动作上,并在其各个模式之间进行探索
————
且按照原始实现,作者的实现预测一个维度为(1, 32) 的潜在动作,并在第一维上重复 50 次,以匹配作者的 action-chunk VLA 的噪声输入空间 - DAgger[41,42]:作者在训练过程中收集到的人类干预数据上对基础 VLA 模型进行微调
且用示范数据与在在线强化学习训练过程中收集的同一批干预数据的混合来微调作者的 VLA π0.6
此外,作者还通过分别移除本方法的各个组件,来分离并分析每个组件的贡献:
- 无RL token
将RL token 替换为来自[25] 的冻结的、在ImageNet 上预训练的ResNet-10 编码器 - 无Chunk
RL 策略输出单步动作(C = 1) 而不是动作块。由于该策略需要以50 Hz 运行,而以50 Hz 查询基础VLA 模型是不可行的,作者必须将RL token 替换为ResNet-10 编码器 - 无BC 正则项
在Eq. (5) 中
设定β = 0;策略仅通过Q函数进行训练 - 无Pass-Through
从策略输入中移除
即RL actor 仅根据(本体)状态和 RL token 生成动作,没有VLA生成的参考动作
————
毕竟本来是
Actor 的输入,不仅
最终输出实际动作块
2.3 实验结果
2.3.1 在线强化学习(online RL)是否优于基础 VLA 策略
Q1:在线强化学习(online RL)是否优于基础 VLA 策略?
作者在两种情形下评估他们的方法:
- 一种是受控设定(the controlled setting),用于剥离并单独考察关键阶段
- 另一种是完整任务设定(the full-task setting),要求RL 策略具备更高的鲁棒性
在线 RL 在这两种设定下都提升了基础模型的成功率和执行速度
- 在受控设定中
RLT在四个任务的关键阶段都带来了持续性的改进
即便是在相对容易的充电器(charger)和以太网(Ethernet)任务上,基础策略已经具有较好可靠性,由 RLT 学得的策略在关键阶段仍然快约 3 倍
下图体现的是吞吐率/执行速度『与基础 VLA 策略相比,RLT 显著提高了吞吐量,从而同时提升了每个任务关键阶段的速度和一致性。对于那些更困难、VLA 策略更容易出错的任务,这种提升尤为明显』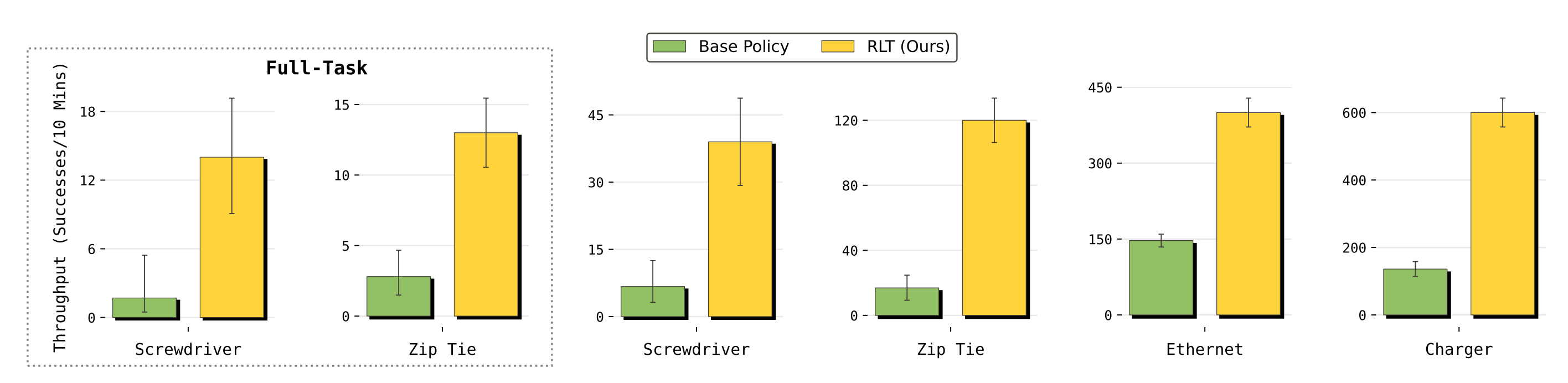
在难度更高的扎带和螺丝刀任务中,成功率的提升更为显著 - 在完整任务评估中
由于任务早期阶段(如抓取/抬起物体等)产生的误差不断累积,整体成功率会更低,但是在螺丝刀任务上,RLT 仍然将成功率提高了 40%,在扎带任务上则提高了 60%
下图体现的是成功率的提升『RLT 能够在多种任务上提高成功率。当 VLA 已经具备较强能力时(例如 Ethernet 任务),它可以保持成功率并提升吞吐量。而对于对基础 VLA 策略而言更具挑战性的任务(螺丝刀和扎带任务),RLT 则显著提升了成功率』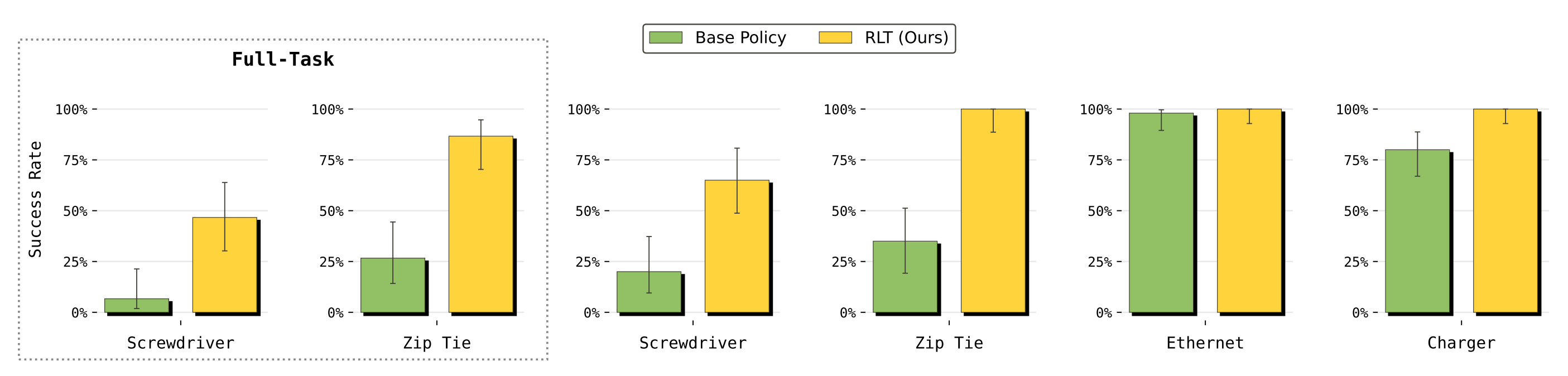
2.3.2 RLT 与其他方法相比如何?
如图 6 所示,相比各个基线方法,RLT 在吞吐量上带来了显著提升『与其他强化学习算法的比较。作者将 RLT 与近期强化学习文献中的若干基线方法进行了对比。只考虑单一步动作而非动作块的方法(HIL-SERL、PLD)表现较差。DSRL 虽然成功率较高,但在吞吐量方面显著落后』
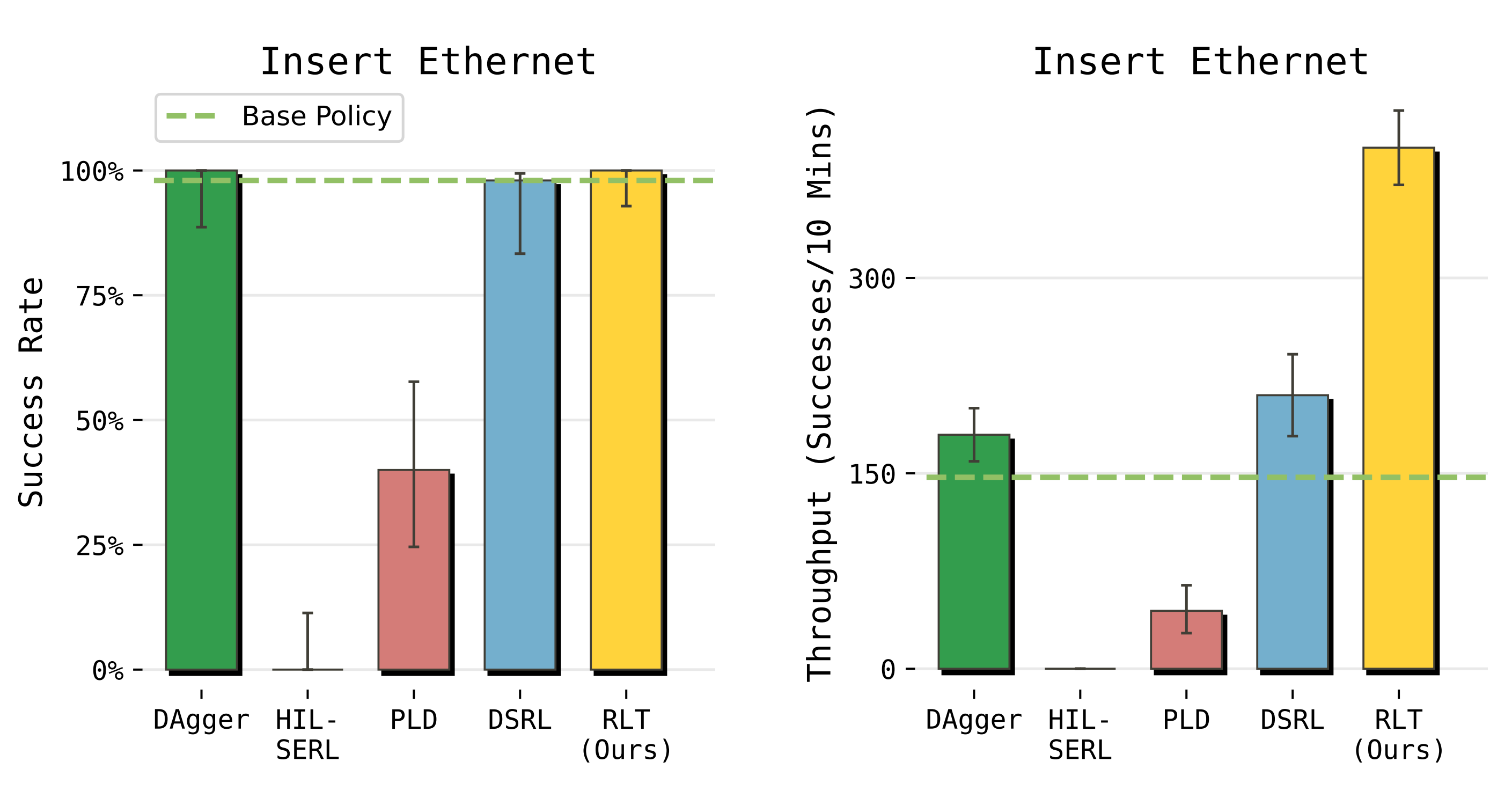
作者在以太网任务上与四个基线方法进行比较
- HIL-SERL和 PLD——这两种都是单步在线强化学习方法——在该任务上都未能有效学习,因为该任务跨度达数百步且奖励稀疏
如果不进行 action chunking,该任务的时间跨度(horizon)非常长,价值函数更新难以有效传播稀疏的奖励信号 - 对于这个相对简单的任务,DAgger 和 DSRL 在成功率上能与 RLT 相当(见图6),但在速度提升方面的改进却明显较少
相比之下,RLT在保持与基础策略同样高成功率的同时,将完成任务的平均步数在基础策略的基础上减少了 2 倍
2.3.3 每个组件的贡献有多大?
所有四个设计选择——RL token、action chunks、BC 正则项以及参考动作透传——都具有实质性贡献
- 作者宣称,他们验证了在他们的方案中,每个组件都带来了正向收益(图 7):将 RL token 替换为一个ResNet-10 编码器将吞吐量降低了50 %
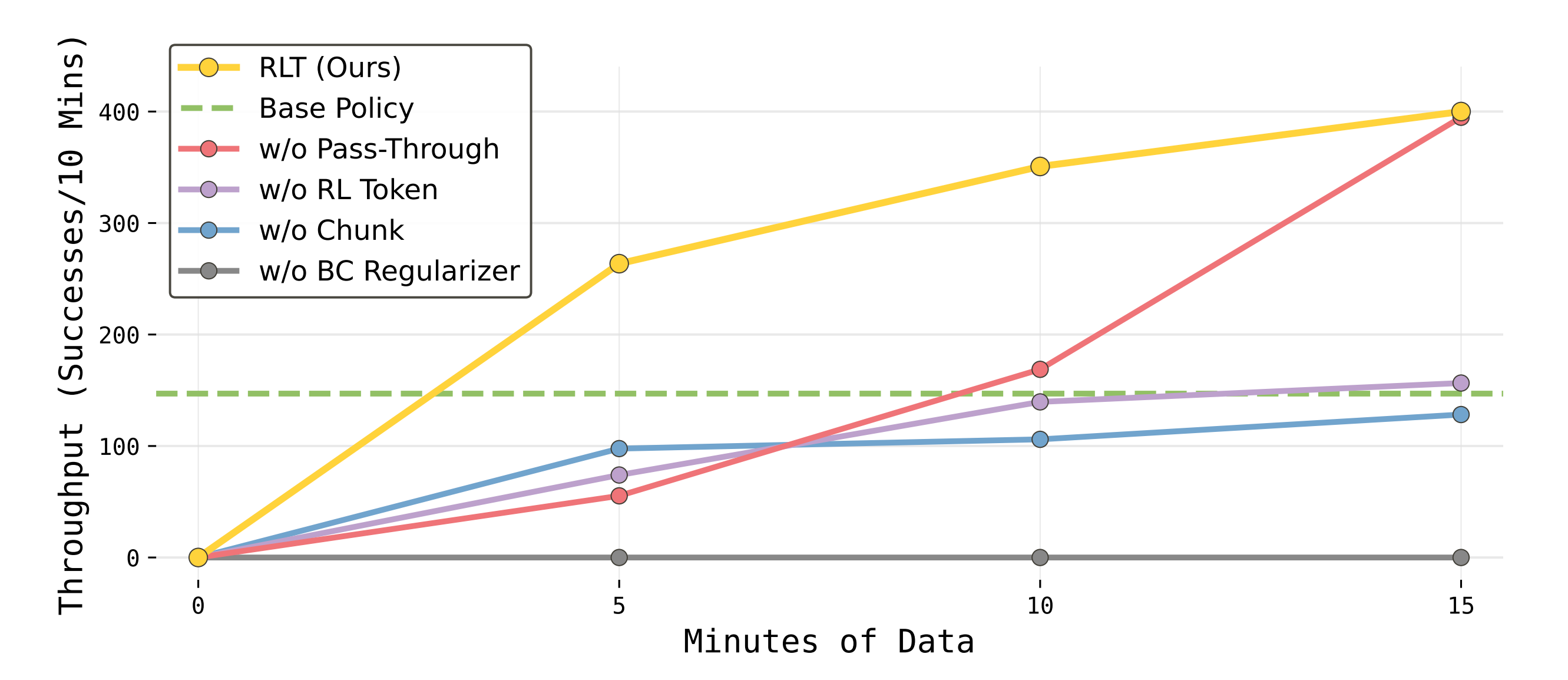
这验证了token 编码了与操作相关的结构,而一个在标准计算机视觉任务上训练的现成编码器并不具备这种能力
所有的强化学习算法中,无论你要输出什么动作(Action),都必须基于当前的环境状态
- 而RL Token,就是 Actor 的这双“眼睛”
它把 VLA 庞大的视觉特征(看了几万小时视频学来的对物理世界的理解)压缩成了一个极其精简的向量
Actor 看着这个 Token(当前局势),再拿着参考动作(原定计划),才能决定:“哦,原本计划下探 2 厘米,但我看局势有点偏,我微调成下探 1.9 厘米吧”- 你可能会问:那 Actor 为什么不自己带个小摄像头网络(比如 ResNet)去看当前局势,非要用 VLA 浓缩出来的 Token 呢?
所以你看到上面的实验结果了
如果把 RL Token 扔掉,换成一个在普通图像(ImageNet)上训练过的标准化视觉编码器(ResNet-10),任务吞吐量直接暴跌了 50%原因揭秘: 普通的视觉网络只能认出“这是一颗螺丝”,但 VLA 的底层特征里不仅包含“这是螺丝”,还包含了“这个螺丝该怎么被抓取”、“它和夹爪的相对空间关系”等极其丰富的“可供性(Affordance)和操作结构”信息 。RL Token 把这些只有通用大模型才懂的“操作直觉”原封不动地传递给了 Actor
- 而用单步动作替换chunk (C = 10) 会显著增加任务的有效时间跨度,因为价值函数需要在更长的时间跨度上执行信用分配。这也会使他们的方法在使用RL token 时变得不可行
在实践中,单步变体无法可靠地匹配基础策略的性能 - 移除BC正则项(β = 0) 会导致性能出现最大幅度的单次下降,因为这迫使actor 仅依赖来自Q 函数的梯度在整个动作空间中进行探索
- 移除参考动作 直通会减慢学习速度,导致早期探索偏移,并偶尔产生退化行为
该消融最终确实在这个更简单的任务上达到了与RLT 相同的性能,但在训练过程中经历了更多失败,如图7 中的学习曲线所示
说白了,“参考动作”可以扔,但“RL Token”绝不能扔!比如,论文里还有一个极其反直觉的对比实验(w/o Pass-Through)
如果我们在训练 Actor 时,不给它 VLA 的参考动作,只给它 RL Token,会发生什么?
答案是:它虽然学得慢一点、早期失败多一点,但最终依然能学出来,并达到极高的成功率
这就证明了:RL Token(大模型提取的环境局势)才是支撑系统完成高精度微调的绝对基石
2.3.4 RLT 是否会带来更有效的涌现策略?
除了总体指标之外,在线强化学习的影响还体现在机器人执行任务方式的质变上。针对以太网任务的关键阶段,作者可视化了遥操作示范、基础策略以及最终 RL 策略的速度分布(如图 9 所示)
- 基础VLA 在接触附近经常表现出“探测式”的行为:它先接近目标,再略微后退,重新调整后再次尝试——有时在成功之前会反复经历多次这样的尝试
- 相比之下,RLT 会直接朝端口运动,并以一个连贯流畅的动作插入连接器。即使第一次尝试失败,RLT 也会施加压力并轻微晃动连接器以利用顺应性,从而实现更快速的插入
这种行为在演示数据中并未出现,而是完全通过在线探索自行涌现出来,说明该方法能够超越对人类策略的简单模仿
毕竟当机器人在进行高精度微调时(比如插充电器的那几秒钟),VLA 并没有闲着,它在后台持续输出一组参考动作块
- 这组动作就是“全局计划”: 它告诉轻量级 Actor:“根据我的大模型常识,你现在的大方向应该是往下压,然后再往左转一点”
- Actor 顺水推舟: 轻量级 Actor 拿到这个全局指示后,就不需要去试错到底该往上还是往下,它只需要结合 RL Token(看到的毫米级偏差),在 VLA 给定的这个大方向上,决定是下压 1 毫米还是 1.5 毫米
这就把一个“大海捞针”的无约束搜索问题,变成了一个简单的“局部精修”问题

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 12
12 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)