在高通跃龙IQ-9100上实现振荡电流故障预测(2): LSTM模型训练与边缘部署
💡前言
在上一篇文章中,我们完成了振动与电流传感器的硬件接入与数据采集,实现了从传感器到CSV文件的完整数据通道。
本文将进一步介绍如何利用采集到的数据(或公开数据集)训练LSTM故障分类模型,并将其部署到高通跃龙IQ-9100边缘设备上,完成“采集 → 推理 → 告警”的闭环。
整个链路包括:
数据预处理 → PyTorch训练LSTM → 导出ONNX → QNN编译 → 板端推理
1. 整体边缘推理架构
1.1 数据集准备(CWRU轴承数据集)
本文使用CWRU(凯斯西储大学)轴承故障数据集,这是工业故障诊断领域的经典公开数据集,包含正常、内圈故障、外圈故障、滚珠故障等多种工况,每种故障包含不同尺寸和负载。
- 下载地址:搜索“CWRU bearing data”即可找到
- 数据格式:按工况分目录存放的
.mat文件 - 我们只使用驱动端(DE)振动通道,采样率为 12kHz
目录结构示例:
CWRU/
├── 0_normal/
├── 1_inner_7/
├── 2_inner_14/
├── 3_outer_7/
└── ...
💡 如果使用上篇自采的CSV数据,只需按行构造
[ax, ay, az, current_ma, label]格式即可,后续处理流程完全相同。
1.2 边缘推理系统架构
系统整体架构如下:
传感器采集 → 数据预处理 → QNN推理引擎 → 故障告警
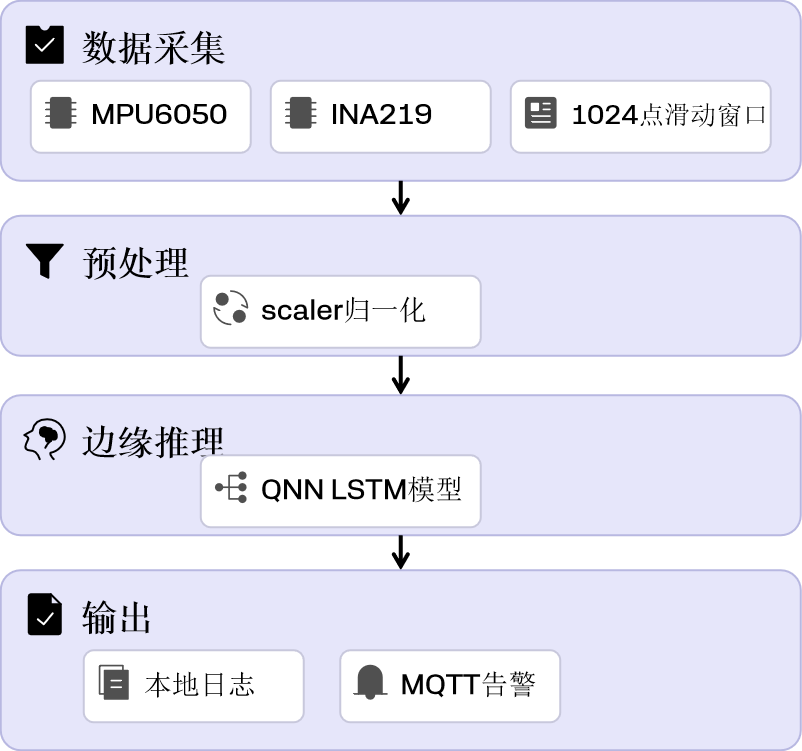
从数据准备到边缘部署的完整流程如下:
CWRU/自采数据 → 滑窗切片 → 归一化 → LSTM训练 → ONNX导出 → QNN编译 → 板端推理

2. 数据预处理与滑窗
2.1 加载CWRU并构造样本
我们使用 1024点 作为每个样本的长度,步长 512,形成重叠窗口,增强样本多样性。
# prep_data.py
import os
import numpy as np
from scipy.io import loadmat
WIN_LEN = 1024 # 每个样本长度
WIN_STEP = 512 # 滑动步长
SR = 12000 # 采样率 12kHz
def load_mat_label(path):
"""从路径推断标签(根据实际目录结构调整)"""
parts = path.replace('\\', '/').split('/')
folder = parts[-2]
return int(folder)
def load_cwru_samples(data_root, channels=['DE_time']):
X, y = [], []
for label_dir in sorted(os.listdir(data_root)):
d = os.path.join(data_root, label_dir)
if not os.path.isdir(d):
continue
label = load_mat_label(d)
for fn in os.listdir(d):
if not fn.endswith('.mat'):
continue
mat = loadmat(os.path.join(d, fn))
sig = mat[channels[0]].flatten()
for i in range(0, len(sig) - WIN_LEN, WIN_STEP):
X.append(sig[i:i + WIN_LEN])
y.append(label)
return np.array(X, dtype=np.float32), np.array(y, dtype=np.int64)
2.2 归一化与数据集划分
对每个样本进行 Z-score 归一化,并划分训练集与测试集。
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
X, y = load_cwru_samples('/path/to/CWRU')
scaler = StandardScaler()
X = scaler.fit_transform(X.reshape(-1, WIN_LEN)).reshape(-1, WIN_LEN)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, stratify=y
)
⚠️ 部署到边缘时,需要保存
scaler的均值和标准差,在推理时使用相同的归一化参数。
3. LSTM 模型定义与训练
3.1 模型结构
我们定义一个双层LSTM分类器,输入为单通道振动序列,输出为故障类别。
# model_lstm.py
import torch
import torch.nn as nn
class LSTMClassifier(nn.Module):
def __init__(self, input_size=1, hidden_size=64, num_layers=2, num_classes=4):
super().__init__()
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, num_classes)
def forward(self, x):
# x: (B, T) → (B, T, 1)
x = x.unsqueeze(-1)
out, _ = self.lstm(x)
out = out[:, -1, :] # 取最后一个时间步
return self.fc(out)
- 输入形状:
(batch, seq_len),这里seq_len = 1024 - 若需要融合多通道(如振动+电流),可将
input_size改为通道数,输入形状为(B, T, C)
3.2 训练脚本
# train.py
import torch
import torch.nn as nn
from torch.utils.data import TensorDataset, DataLoader
from model_lstm import LSTMClassifier
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = LSTMClassifier(input_size=1, hidden_size=64, num_layers=2, num_classes=4).to(device)
opt = torch.optim.Adam(model.parameters(), lr=1e-3)
criterion = nn.CrossEntropyLoss()
# 将数据调整为 (N, 1, T) 便于 LSTM 输入
X_tr = torch.FloatTensor(X_train).unsqueeze(1)
ds = TensorDataset(X_tr, torch.LongTensor(y_train))
loader = DataLoader(ds, batch_size=32, shuffle=True)
for epoch in range(20):
model.train()
for batch_x, batch_y in loader:
batch_x, batch_y = batch_x.to(device), batch_y.to(device)
out = model(batch_x.squeeze(1))
loss = criterion(out, batch_y)
opt.zero_grad()
loss.backward()
opt.step()
print(f"Epoch {epoch}, loss={loss.item():.4f}")
# 保存模型权重
torch.save(model.state_dict(), 'lstm_fault.pt')
# 保存归一化器
import pickle
with open('scaler.pkl', 'wb') as f:
pickle.dump(scaler, f)
3.3 导出 ONNX
QCS9100 使用高通 QNN 工具链,需要先将模型导出为 ONNX 格式。
# export_onnx.py
import torch
from model_lstm import LSTMClassifier
model = LSTMClassifier(input_size=1, hidden_size=64, num_layers=2, num_classes=4)
model.load_state_dict(torch.load('lstm_fault.pt', map_location='cpu'))
model.eval()
dummy_input = torch.randn(1, 1024) # batch_size=1, seq_len=1024
torch.onnx.export(
model,
dummy_input,
"lstm_fault.onnx",
input_names=['input'],
output_names=['output'],
dynamic_axes={'input': {0: 'batch_size'}, 'output': {0: 'batch_size'}}
)
4. 边缘部署与推理
4.1 QNN 编译
将 ONNX 模型通过高通 QNN 工具链编译为适用于 QCS9100 的格式:
qnn-onnx-converter --input_model lstm_fault.onnx --output_model lstm_fault.cpp
qnn-model-lib --model lstm_fault.cpp --target x86_64-linux-clang
实际命令根据 QNN SDK 版本和目标平台略有差异,请参考官方文档。
4.2 板端推理示例
在 QCS9100 上,推理服务通常采用 C++ 实现,Python 负责采集与调度。以下为简化示例,展示推理流程:
# inference_example.py
import pickle
import numpy as np
# 1. 加载 scaler
with open('scaler.pkl', 'rb') as f:
scaler = pickle.load(f)
# 2. 加载 QNN 模型并创建 context(实际使用 QNN API)
def run_inference(win):
# 归一化
win = scaler.transform(win.reshape(1, -1)).reshape(1, 1024)
# 调用 QNN 推理,返回 logits
logits = qnn_forward(win) # 伪代码
pred = np.argmax(logits)
return pred
在实际项目中,推荐使用 C++ 实现 QNN 推理,Python 负责数据采集与任务调度,也可通过 QAIRT 集成方式实现端到端推理。
5. 小结
至此,我们已经完成了以下工作:
- 使用 CWRU 公开数据集(或自采CSV)进行滑窗切片与归一化
- 基于 PyTorch 训练 LSTM 故障分类模型
- 将模型导出为 ONNX,并通过 QNN 工具链编译
- 在 QCS9100 边缘设备上完成“采集 → 预处理 → 推理 → 告警”的闭环
✅ 落地建议:先在 PC 端完成数据质量验证与模型精度调优,再迁移至板端进行实际部署。
系列文章回顾
- (一)硬件接入与数据采集 ✅
- (二)LSTM模型训练与边缘部署 ✅
- (三)边缘推理与实时告警系统实现
下一篇文章将介绍:
边缘推理服务的工程化实现、告警机制设计、以及实际工业场景中的性能优化经验。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 4
4 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)