大数据运维项目一 大数据分布式集群
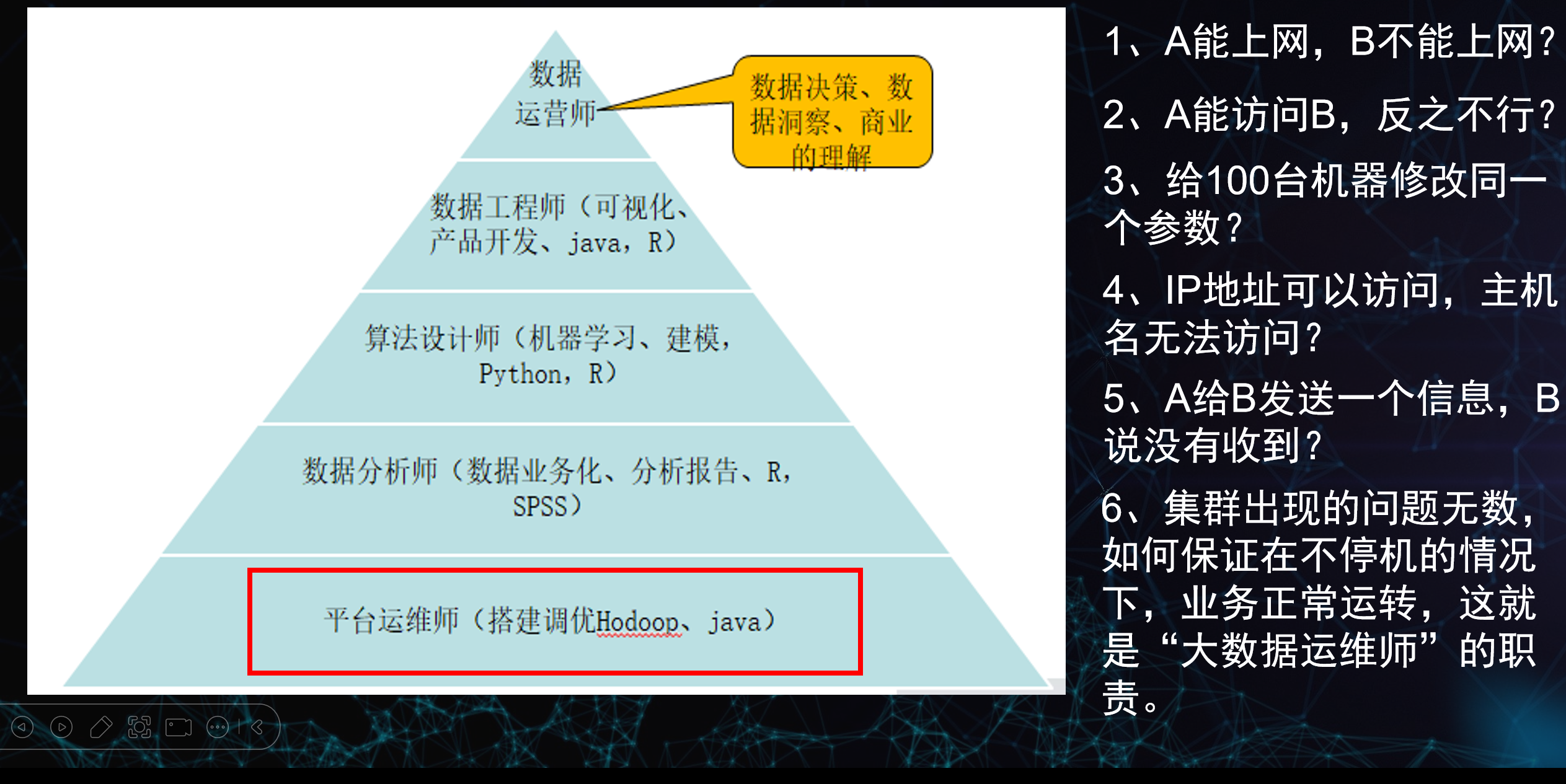
图1 构成结构
平台运维师:是整个结构的基础,支撑整个结构稳定,需要时刻保证系统运行稳定。
技术栈:Hadoop、Java、Linux、集群管理、监控告警、故障排查。
价值:保证整个大数据集群7×24 小时稳定运行,是所有上层数据应用的基石。
数据分析师:时刻分析平台后台数据的变化情况,输出业务报告。
工具:R、SPSS、SQL、Excel、可视化工具
价值:用数据回答业务问题,比如 “用户留存率为什么下降”
算法设计师:做机器学习建模,从数据中挖掘预测性规律。
工具:Java、R、Spark、Flink、BI 工具、数据仓库。
价值:把原始数据清洗、加工成可分析、可查询的数据集。
数据工程师:核心职责:做数据管道、可视化、数据产品开发。
工具:Java、R、Spark、Flink、BI 工具、数据仓库。
价值:把原始数据清洗、加工成可分析、可查询的数据集。
数据运维师:核心职责:数据决策、数据洞察、商业理解。
价值:站在业务视角,用数据驱动战略和运营决策,是数据价值的最终体现。
-
A 能上网,B 不能上网
- 排查方向:B 的网络配置(IP/DNS/ 网关)、防火墙 / ACL 策略、MAC 地址过滤、网卡故障、端口封禁等
-
A 能访问 B,反之不行
- 排查方向:单向防火墙规则、路由不对称、B 的安全组 /iptables 策略、端口监听状态、NAT 配置问题
-
给 100 台机器修改同一个参数
- 解决方式:用自动化运维工具(Ansible、SaltStack、Puppet)批量下发配置,避免手动操作
-
IP 地址可以访问,主机名无法访问
- 排查方向:DNS 解析失败、hosts 文件配置错误、DNS 服务器不可达、域名拼写错误
-
A 给 B 发送一个信息,B 说没有收到
- 排查方向:网络丢包、防火墙拦截、消息队列堆积、应用层消费延迟、协议不兼容
-
集群问题无数,如何保证不停机、业务正常运转
- 这正是大数据运维师的核心职责:
- 做高可用架构(主备、副本、容灾)
- 完善监控告警体系
- 灰度发布 / 滚动升级
- 故障自动转移与自愈
- 这正是大数据运维师的核心职责:
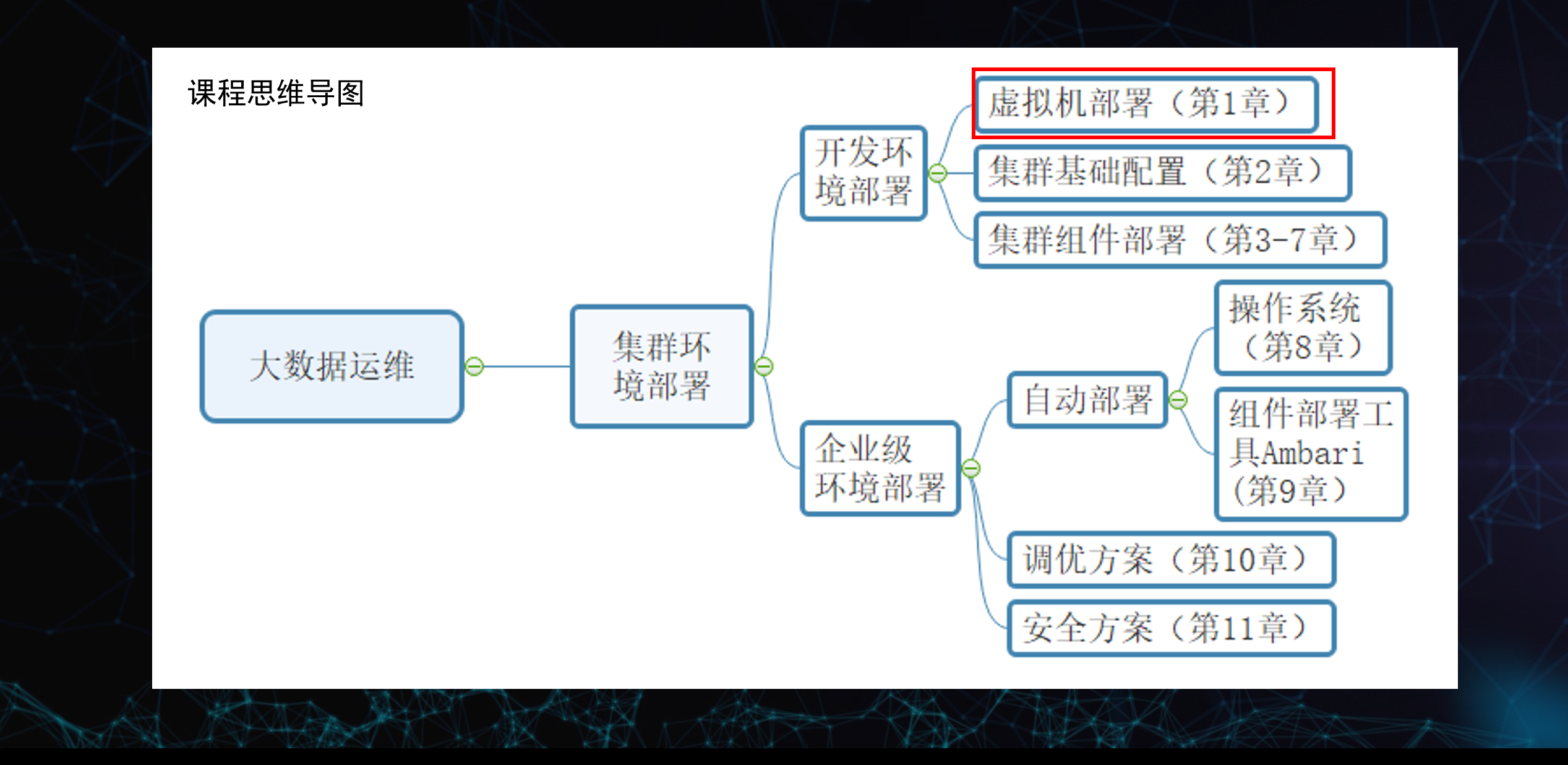
图二 课程思维导图
一、核心主线:大数据运维 → 集群环境部署
整个课程围绕搭建、管理、优化大数据集群展开,核心目标是让你掌握从开发环境到企业级生产环境的全流程运维能力。
二、第一分支:开发环境部署(学习 / 测试用)
这部分是入门阶段,对应课程前 7 章:
- 虚拟机部署(第 1 章)
- 用 VMware/VirtualBox 等工具创建 Linux 虚拟机,是整个大数据环境的基础载体。
- 学习内容:虚拟机创建、网络配置(NAT / 桥接)、快照管理、Linux 系统安装。
- 集群基础配置(第 2 章)
- 对多台虚拟机做统一基础配置: hostname、hosts 解析、SSH 免密登录、时间同步、JDK 环境等。
- 目的:让多台机器能互相通信,为后续分布式组件做准备。
- 集群组件部署(第 3-7 章)
- 手动部署大数据核心组件:Hadoop(HDFS/YARN)、Hive、Spark、ZooKeeper、HBase 等。
- 目的:理解每个组件的角色、配置文件、启动方式和依赖关系,掌握 “从 0 到 1” 搭建集群的能力。
三、第二分支:企业级环境部署(生产环境用)
这部分是进阶阶段,对应课程第 8-11 章,解决大规模、高可用、自动化的生产场景:
- 自动部署
- 操作系统(第 8 章):用 PXE/ Cobbler 等工具批量装机,替代手动安装,适合上百台服务器的场景。
- 组件部署工具 Ambari(第 9 章):用 Apache Ambari 等自动化工具,可视化、一键式部署、管理和监控整个大数据集群,大幅提升效率和可靠性。
- 调优方案(第 10 章)
- 针对 Hadoop、Spark、HBase 等组件做性能调优:内存配置、参数优化、磁盘 IO 优化、GC 调优等。
- 目的:让集群在高并发、大数据量下稳定高效运行。
- 安全方案(第 11 章)
- 集群安全加固:Kerberos 认证、ACL 权限控制、数据加密、审计日志等。
- 目的:保障企业数据和服务的安全性,符合合规要求。
四、整体学习逻辑
- 从简单到复杂:先在虚拟机上手动搭小集群,理解原理;再用自动化工具管理大规模生产集群。
- 从开发到生产:开发环境侧重 “能跑通”,企业级环境侧重 “稳定、高效、安全、可扩展”。
- 从手动到自动:从手动敲命令部署,过渡到用工具批量管理,符合真实企业运维工作流。
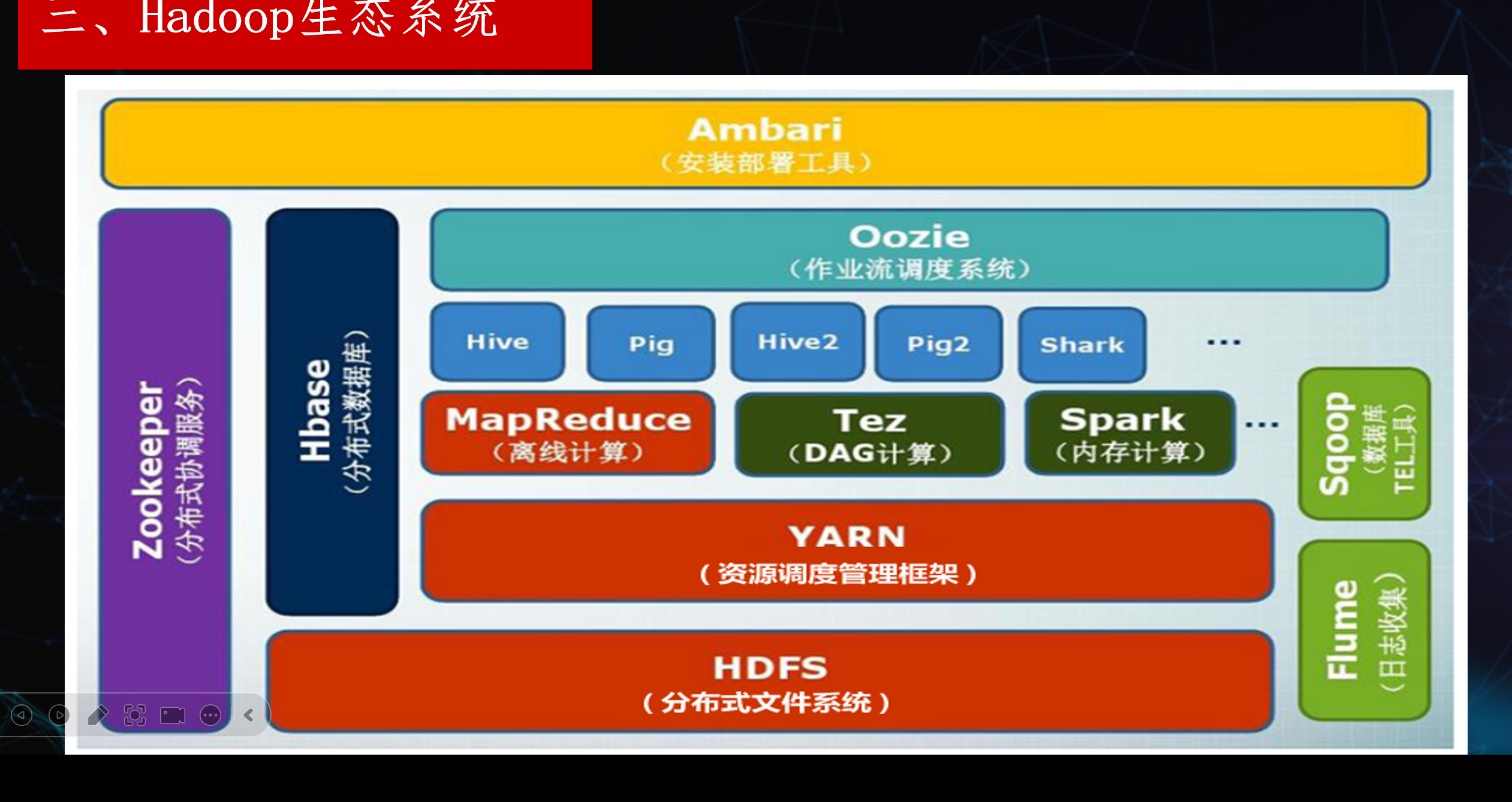
图三 生态系统
一、最底层:大数据的 “地基”(HDFS + YARN)
所有上层计算都依赖这两个框架,是 Hadoop 生态的核心:
- HDFS(分布式文件系统)
- 角色:存数据。
- 作用:把超大文件拆分存储在集群的多台机器上,提供高容错性、高吞吐能力。
- YARN(资源调度框架)
- 角色:管资源 / 分任务。
- 作用:统一管理集群的 CPU、内存资源,负责给计算任务(如 MapReduce、Spark)分配资源,是集群的 “资源管家”。
二、核心计算层:数据处理的 “引擎”
基于 HDFS 和 YARN 提供的存储和资源能力,执行具体的计算任务:
- MapReduce(离线计算)
- 角色:Hadoop第一代计算引擎。
- 特点:适合大规模离线批处理,但速度慢,磁盘 IO 开销大。
- Tez(DAG 计算)
- 角色:提速引擎。
- 特点:基于 YARN,支持 DAG 有向无环图计算,减少中间磁盘落地,比 MapReduce 快,常作为 Hive 的底层执行引擎。
- Spark(内存计算)
- 角色:新一代通用计算引擎。
- 特点:基于内存计算,速度是 MapReduce 的 10~100 倍,支持批处理、流处理、SQL、机器学习等,是目前主流计算引擎。
三、数据仓库 / 应用层:面向业务的 “工具”
基于计算引擎处理数据,供分析师 / 工程师使用:
- Hive + Hive2
- 角色:数据仓库。
- 作用:把结构化数据映射成表,提供类 SQL(HiveQL)查询,将 SQL 转换为 MapReduce/Tez/Spark 任务执行。
- Pig + Pig2
- 角色:数据流分析。
- 作用:适合处理复杂的 ETL 流程,用 Pig Latin 语言处理大规模数据集。
- Shark
- 角色:Hive on Spark 的前身,实现 Hive 的 SQL 查询与 Spark 计算结合。
四、支撑与周边工具:生态的 “辅助”
解决集群协调、存储、数据采集、部署调度等问题:
- Zookeeper(分布式协调服务)
- 作用:统一管理集群配置、服务发现、分布式锁、选举(如 HMaster、NameNode 高可用),是集群的 “神经中枢”。
- HBase(分布式数据库)
- 作用:基于 HDFS 的NoSQL 数据库,适合随机读写、实时访问海量数据,做大数据的快速查询。
- Flume(日志收集)
- 作用:实时采集服务器日志、业务数据,将数据发送到 HDFS 或 Kafka,是数据入口。
- Sqoop(数据传输工具)
- 作用:在关系型数据库(MySQL/Oracle) 和 Hadoop(HDFS/Hive) 之间进行数据批量导入导出。
五、运维与调度层:生态的 “管理”
- Oozie(作业流调度系统)
- 作用:工作流调度,把多个 Hadoop/Spark 任务按顺序 / 依赖关系编排执行,实现自动化定时运行。
- Ambari(安装部署工具)
- 作用:可视化、一键式部署和管理 Hadoop 集群,大幅降低手动搭建集群的复杂度,对应你上一张思维导图里的企业级环境部署。
六、整体逻辑总结
- 最底层:HDFS 存数据,YARN 分资源。
- 中间层:MapReduce/Tez/Spark 做计算。
- 业务层:Hive/Pig 做数据仓库分析,HBase 做实时查询。
- 辅助层:Zookeeper 协调,Flume/Sqoop 负责数据采集,Ambari/Oozie 负责运维调度。
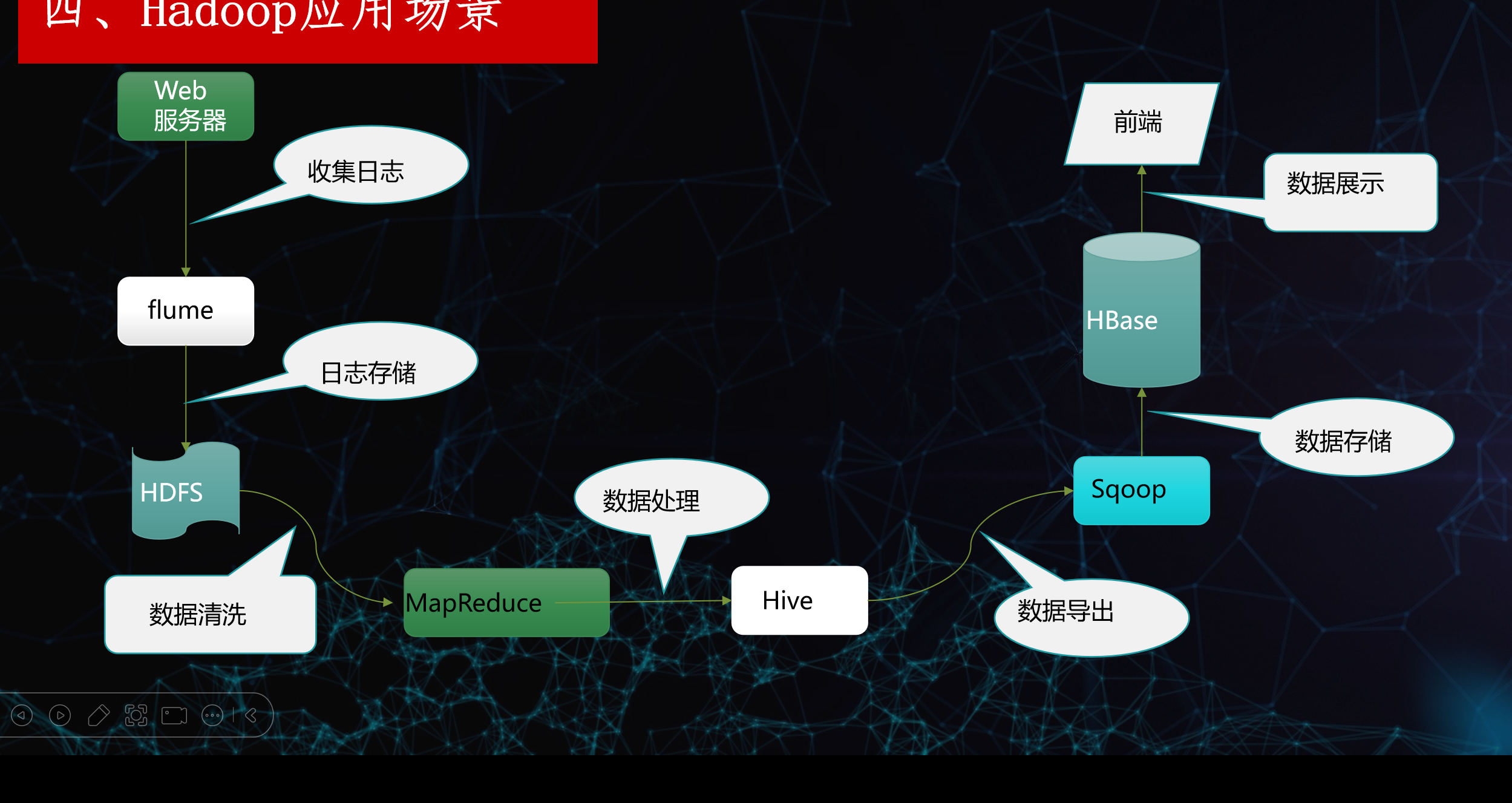
图四 应用场景
1. 数据采集阶段
- Web 服务器:产生用户访问日志、行为日志等原始数据。
- Flume:负责实时采集这些日志数据,把日志从 Web 服务器传输到 HDFS。
- HDFS:作为分布式文件系统,将采集到的日志持久化存储,为后续处理做准备。
2. 数据清洗与处理阶段
- MapReduce:对 HDFS 上的原始日志进行数据清洗(过滤无效数据、格式规整、去重等),完成初步的离线计算处理。
- Hive:在清洗后的数据基础上,通过类 SQL(HiveQL)进行数据分析、统计、聚合,生成业务需要的结果表(比如用户访问量、页面 PV/UV 等)。
3. 数据导出与存储阶段
- Sqoop:把 Hive 中分析好的结果数据导出到 HBase 中,实现从离线计算到实时查询的过渡。
- HBase:作为分布式 NoSQL 数据库,负责高并发、低延迟的数据存储,支撑前端快速查询。
4. 数据展示阶段
- 前端:通过接口查询 HBase 中的统计结果,进行可视化展示(比如做报表、仪表盘、用户行为分析大屏)。
整体流程总结
plaintext
Web日志 → Flume采集 → HDFS存储 → MapReduce清洗 → Hive分析 → Sqoop导出 → HBase存储 → 前端展示
这个流程是企业级大数据分析的经典场景,比如:
- 网站 / APP 的用户行为分析
- 流量统计、用户留存分析
- 广告投放效果分析等
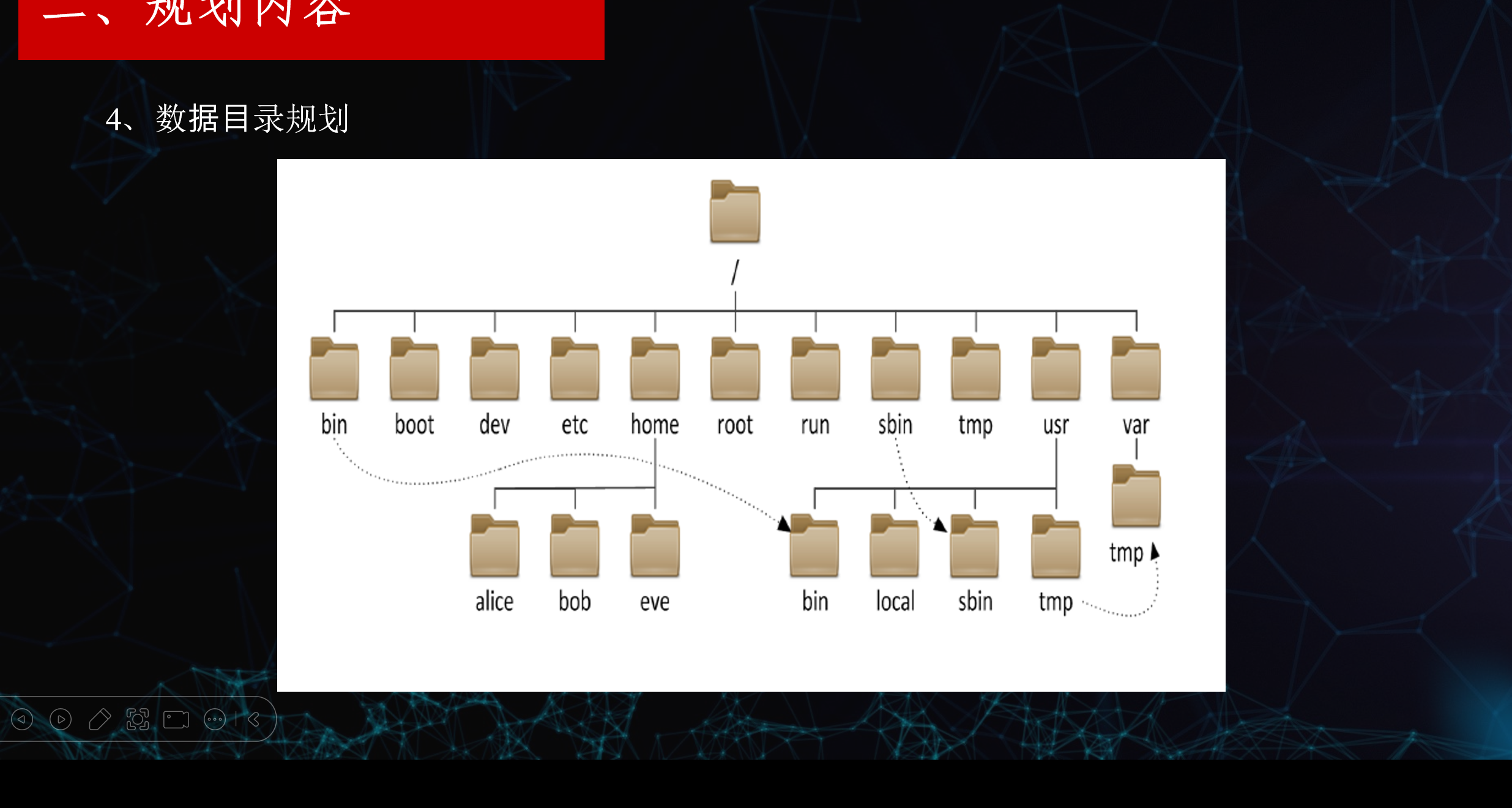
图五 规划内容
一、根目录 /:所有目录的起点
Linux 系统以 / 为唯一根节点,所有文件、目录都从这里开始,没有 Windows 那样的 C/D/E 盘概念。
二、一级核心目录(根下的主要文件夹)
表格
| 目录 | 作用 |
|---|---|
/bin |
存放基础命令(如 ls、cp、mv),所有用户都可执行 |
/boot |
存放系统启动相关文件(内核、引导程序) |
/dev |
存放设备文件(硬盘、键盘、显示器等硬件抽象为文件) |
/etc |
存放系统 / 应用配置文件(如 hosts、ssh、hadoop 配置) |
/home |
普通用户的家目录(如 alice、bob),每个用户有独立子目录 |
/root |
超级管理员(root)的家目录 |
/run |
存放系统运行时的临时数据(进程 PID、锁文件) |
/sbin |
存放系统管理员命令(如 ifconfig、reboot),仅 root 可执行 |
/tmp |
存放临时文件,系统重启后会清空 |
/usr |
存放用户安装的程序 / 资源(类似 Windows 的 Program Files) |
/var |
存放可变数据(日志、缓存、队列、数据库数据) |
三、关键子目录展开
-
/home下的用户目录- 每个普通用户(如
alice、bob、eve)都有自己的家目录,用于存放个人文件、配置、脚本等。 - 例如:
/home/alice是 alice 的专属工作目录。
- 每个普通用户(如
-
/usr下的子目录/usr/bin:用户安装的可执行命令/usr/local:管理员手动安装的软件(推荐大数据组件如 Hadoop、JDK 放这里)/usr/sbin:系统级用户命令/usr/tmp:用户级临时文件(和/tmp类似)
-
/var/tmp- 也是临时文件目录,但生命周期比
/tmp更长,不会在每次重启时都清空。
- 也是临时文件目录,但生命周期比
四、在大数据运维中的意义
这张图是服务器目录规划的基础:
- 数据存储:HDFS、HBase 等数据通常规划在
/var/data或独立挂载的/data目录下,避免和系统目录混放。 - 组件安装:Hadoop、Spark 等一般安装在
/usr/local或/opt目录,便于统一管理。 - 日志存放:组件日志(如
hadoop.log)放在/var/log下,方便运维排查问题。 - 安全隔离:将系统目录、用户目录、数据目录分开挂载,防止某个目录占满导致系统宕机。
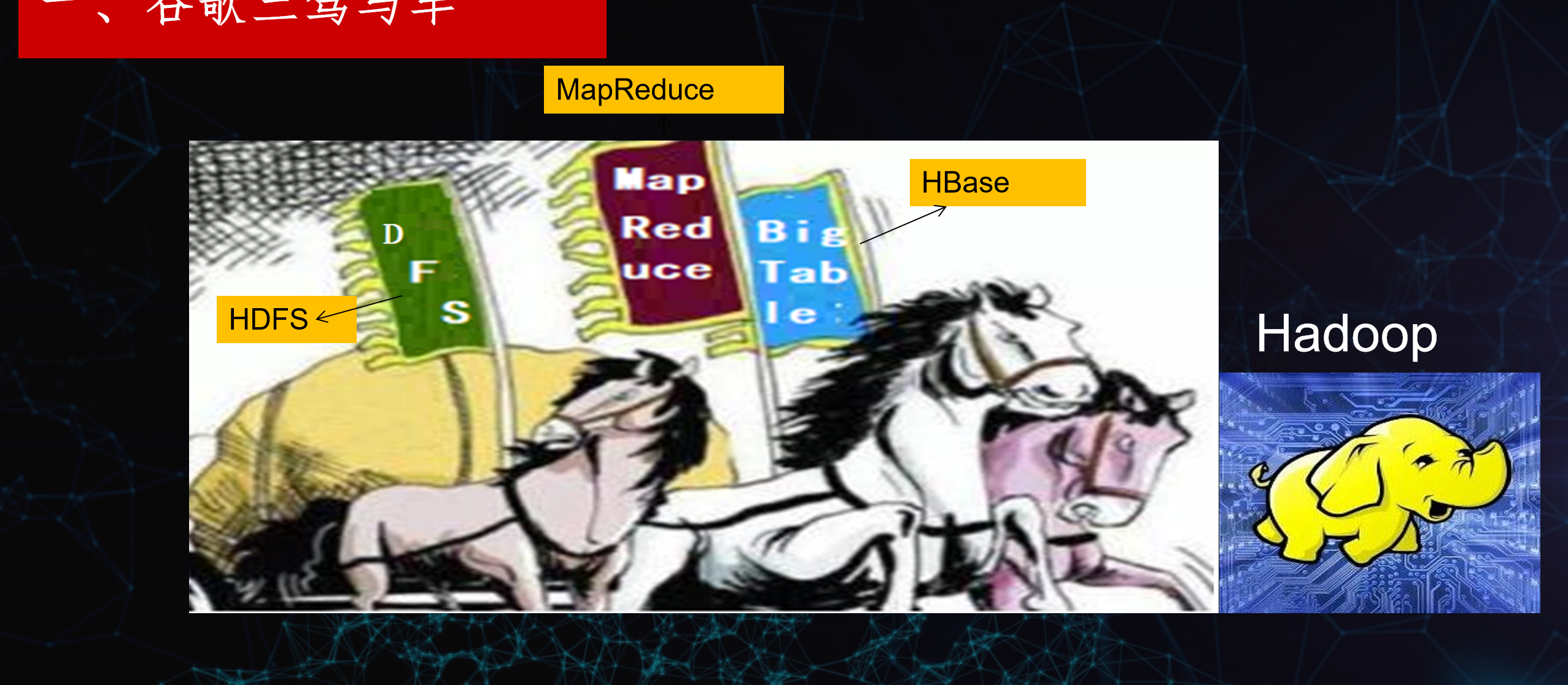
图六 谷歌三驾马车
三驾马车的比喻
图里的三匹马分别对应 Hadoop 最核心的三个组件,它们共同拉着 “大数据这辆车”:
- HDFS(绿色旗帜):对应谷歌的 GFS(Google File System)
- 角色:存储层,负责把海量数据分布式存在多台机器上,是整个系统的 “底盘”,保证数据不丢、高可靠。
- MapReduce(红色旗帜):对应谷歌的 MapReduce 论文
- 角色:计算层,负责把大数据拆成小任务,并行计算,最后汇总结果,是早期大数据的核心计算引擎。
- HBase(蓝色旗帜,BigTable):对应谷歌的 BigTable
- 角色:分布式 NoSQL 数据库,在 HDFS 之上提供实时、随机读写的能力,适合海量结构化 / 半结构化数据。
2. 整体逻辑
- HDFS 是地基,负责存数据;
- MapReduce 是引擎,负责算数据;
- HBase 是上层数据库,提供更灵活的实时查询;
- 这三个组件共同构成了 Hadoop 生态的核心,就像三匹马拉着一辆车,缺一不可,协同驱动大数据处理。
3. 延伸:和 Hadoop 的关系
右下角的黄色大象是 Hadoop 的吉祥物,代表整个 Hadoop 生态:
- HDFS 和 MapReduce 是 Hadoop 最原始的两个核心组件;
- HBase 是基于 HDFS 构建的重要上层应用,属于 Hadoop 生态的关键成员。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)