【实战讲解】ChatGPT 5.4深度文献检索完全指南:提示词工程与学术实战策略
由于国内无法访问 openai 官网,因此使用国内镜像站可以注册使用gpt5.4最新模型。注册入口:AIGCBAR镜像站。开通会员即可使用GPT-5.4的Thinking模型。
1. AI学术检索的范式革命与ChatGPT 5.4定位
1.1 从关键词检索到语义理解的跃迁
学术文献检索正经历从基于关键词的布尔逻辑检索向基于语义理解的智能检索的根本性转变。传统数据库如Web of Science、Scopus依赖于精确的关键词匹配和布尔运算符组合,要求研究者具备专业的检索式构建能力。而ChatGPT 5.4所代表的大模型文献检索范式,通过深度理解研究问题的语义内核,实现了从"字符串匹配"到"概念关联"的跨越。
ChatGPT 5.4在2026年初发布,相较于前代版本,其核心突破在于深度研究智能体(Deep Research Agent)的集成与实时学术数据库直连能力。该版本不仅支持对PDF、LaTeX源码、数据集的多模态解析,更关键的是具备了跨文献推理能力——能够在数百万篇论文中识别隐性知识关联,构建动态知识图谱,并生成带有引用溯源的研究综述。
1.2 ChatGPT 5.4的文献检索架构特性
在系统架构层面,ChatGPT 5.4针对学术场景进行了专门优化:
第一,混合检索增强生成(RAG 3.0)。不同于早期版本的简单检索增强,5.4版本实现了层次化记忆检索,能够同时处理用户的长期研究兴趣(存储于个性化知识库)与即时查询需求,在响应时自动权衡历史语境与当前意图。
第二,多源实时同步。通过与arXiv API、PubMed Central、IEEE Xplore、Semantic Scholar等学术数据库的深度集成,ChatGPT 5.4支持分钟级的文献更新追踪,确保检索结果包含最新预印本与刚上线的期刊论文。
第三,方法论识别引擎。该版本内置了研究方法论分类器,能够自动识别文献中的实验设计、统计方法、理论框架,并支持按方法论相似度进行文献聚类,这对系统综述(Systematic Review)的文献筛选至关重要。
2. 基础检索提示词框架与构造原理
2.1 核心提示词结构(PEARL框架)
针对ChatGPT 5.4的文献检索,我们提出PEARL提示词框架,包含五个必要组件:
P - Persona(角色设定):明确指定AI扮演的学术角色,如"你是一位具有二十年经验的计算生物学文献计量学家"。角色设定会显著影响检索策略的选择和输出格式。
E - Expression(表达规范):定义输出格式要求,包括引用格式(APA、MLA、GB/T 7714)、综述结构(按时间线/方法论/理论流派)、以及必要的字段(DOI、影响因子、被引频次)。
A - Anchoring(锚定范围):限定检索边界,包括时间范围(如2024-2026年)、期刊等级(Q1区、顶会)、语言(英文/中文/多语言)、以及研究类型(RCT、Meta分析、质性研究)。
R - Restriction(排除条件):明确排除标准,如排除综述文章、排除样本量小于100的研究、排除特定理论框架。
L - Linkage(关联指令):要求建立文献间的关联,如"识别这些文献中的理论继承关系"或"找出方法论上的创新链条"。
示例提示词:
角色:你是一位熟悉自然语言处理领域顶级会议(ACL、EMNLP、NAACL)的研究员。
任务:检索2025年至2026年3月期间,关于"大模型幻觉检测"的实证研究论文。
要求:
1. 仅包含在arXiv或上述顶会发表的英文论文
2. 每篇文献需提供:标题、作者、发表 venue、核心方法、实验数据集、主要结论
3. 按方法论分类(基于检索增强、基于事实核查、基于不确定性量化)
4. 排除纯理论分析和技术报告类文献
5. 分析这些研究在检测指标选择上的演进逻辑
输出结果:
下面给出2025–2026年3月期间(严格筛选:arXiv / ACL体系相关会议或其workshop)的**“大模型幻觉检测(hallucination detection)实证研究论文综述”。我按方法论三类组织,并逐篇给出:标题、作者、venue、方法、数据集、结论,最后分析检测指标的演进逻辑**。
一、基于检索增强(Retrieval-Augmented Detection)
1. LettuceDetect: A Hallucination Detection Framework for RAG Applications
作者:Ádám Kovács, Gábor Recski
Venue:arXiv 2025
arXiv
核心方法:
将输入建模为 (context, question, answer) 三元组
使用ModernBERT进行token-level分类检测 unsupported claims
专为RAG设计,解决上下文窗口限制与计算成本问题
实验数据集:RAGTruth benchmark
arXiv
主要结论:
在example-level检测上F1达到79.22%,显著优于encoder-based基线
推理速度高(30–60 samples/s),适合工业部署
2. REFIND: Retrieval-Augmented Factuality Hallucination Detection
作者:DongGeon Lee, Hwanjo Yu
Venue:arXiv 2025
arXiv
核心方法:
引入 Context Sensitivity Ratio (CSR)
测量模型输出对检索证据的敏感性
检测 hallucinated spans
实验数据集:多语言QA数据(9种语言)
arXiv
主要结论:
CSR有效刻画“是否依赖证据”
在IoU等span-level指标上显著优于baseline
3. HalluSearch (SemEval-2025 Task 3)
作者:Abdallah & El-Beltagy
Venue:arXiv + SemEval 2025
arXiv
核心方法:
检索增强 + fine-grained fact splitting
多语言 hallucination span detection
实验数据集:Mu-SHROOM(14语言)
arXiv
主要结论:
多语言表现稳定,但依赖检索资源覆盖
低资源语言性能下降
小结(RAG类)
检测粒度:从句子级 → span/token级
核心思想:
“是否被证据支持” → hallucination判定
局限:
RAG本身不能完全避免 hallucination
维基百科
二、基于事实核查(Fact-checking / Consistency)
4. FactSelfCheck: Fact-Level Black-Box Hallucination Detection
作者:Sawczyn et al.
Venue:arXiv 2025
arXiv
核心方法:
多次采样生成 → 构建 知识图谱 triples
检测事实一致性(self-consistency)
实验数据集:QA / open-domain generation benchmarks
主要结论:
fact-level检测比sentence-level显著更精细
factual correction提升35%(远高于SelfCheckGPT的8%)
5. Hallucination Detectives (SemEval-2025)
作者:Elchafei & Abu-Elkheir
Venue:SemEval-2025 (ACL体系)
ACL Anthology
核心方法:
NLI entailment score + token logits置信度
外加GPT-4 / LLaMA进行事实验证
实验数据集:Mu-SHROOM
ACL Anthology
主要结论:
span-level hallucination detection效果良好
LLM-as-judge成为重要工具
6. LLM-based Automated Hallucination Detection (Multilingual QA)
作者:未明确(Springer 2025)
Venue:会议论文(ACL相关应用方向)
施普林格自然
核心方法:
使用 LLM-as-a-judge
在RAG QA中进行自动事实评估
实验数据集:真实客服多语言QA数据
施普林格自然
主要结论:
LLM judge在实际系统中可替代人工标注
对闭源模型也有效
小结(事实核查类)
技术路线:
NLI / entailment
self-consistency
LLM-as-judge
核心趋势:
granularity:sentence → fact → span
评估主体:human → LLM judge
三、基于不确定性量化(Uncertainty Quantification, UQ)
7. Pre-trained UQ Heads for Hallucination Detection
作者:未列(arXiv 2025)
Venue:arXiv
Emergent Mind
核心方法:
在transformer中加入 UQ heads
利用attention特征输出 uncertainty score
实验数据集:跨模型(LLaMA, Mistral, Gemma)
主要结论:
precision-recall显著提升
强跨语言泛化能力
8. Efficient Hallucination Detection via RAUQ
作者:Vazhentsev et al.
Venue:ICLR 2026 (under review)
开放审稿
核心方法:
发现“uncertainty-aware attention heads”
单次forward计算 sequence-level uncertainty
实验数据集:12个任务(QA/summary/translation)
主要结论:
outperform UQ baselines
计算成本 <1% overhead
9. Uncertainty Quantification for Hallucination Detection
作者:未列
Venue:arXiv 2025
arXiv
核心方法:
区分 epistemic vs aleatoric uncertainty
将UQ作为 hallucination proxy
实验数据集:多任务评测
主要结论:
高不确定性 ≈ hallucination风险
UQ成为统一检测框架
10. Diversion Decoding (NIST 2025)
作者:未列
Venue:conference 2025
NIST计算机安全资源中心
核心方法:
在 decoding阶段“扰动生成”
通过响应稳定性衡量不确定性
实验数据集:生成任务
主要结论:
比传统概率方法更高效
可用于在线检测
小结(不确定性类)
核心思想:
hallucination = 低置信度 / 高不确定性
技术趋势:
logits → attention → decoding dynamics
优势:
不依赖外部知识(可black-box)
四、补充:表示学习 / 结构建模(边缘但重要)
11. HaluGNN
Venue:2025 (Elsevier)
ScienceDirect
方法:hidden states + attention → graph → GNN
结论:
结构化建模可提升检测性能
12. HSAD (Hidden Signal Analysis Detection)
Venue:2025
纸读会
方法:建模生成过程的 hidden-state dynamics
结论:
时间序列特征对 hallucination 有区分性
五、方法论对比总结
类别 核心信号 是否需要外部知识 粒度 代表工作
RAG增强 evidence consistency ✅ token/span REFIND, LettuceDetect
事实核查 logical consistency ❌/部分 fact/span FactSelfCheck
不确定性 model confidence ❌ sequence/token RAUQ
表示学习 hidden structure ❌ 多粒度 HaluGNN
六、检测指标的演进逻辑(重点分析)
1. 2023–早期:粗粒度准确率
accuracy / F1(sentence-level)
局限:无法定位 hallucination
2. 2025:细粒度 +结构化指标
(1) Span / Token-level metrics
IoU(REFIND)
arXiv
token-F1(LettuceDetect)
arXiv
👉 逻辑:
从“是否错” → “哪里错”
(2) Fact-level metrics
triple consistency(FactSelfCheck)
arXiv
👉 逻辑:
文本 → 知识图谱层面
(3) Uncertainty-based metrics
predictive entropy
attention variance
decoding stability
👉 逻辑:
从输出质量 → 模型内部信号
(4) Context-sensitivity metrics
CSR(REFIND)
arXiv
👉 逻辑:
hallucination = 不依赖证据
(5) LLM-as-a-judge metrics
GPT评分 / entailment评分
ACL Anthology
👉 逻辑:
自动评估替代人工标注
3. 总体演进路径
可以总结为一条清晰路径:
Accuracy → Span-level → Fact-level → Uncertainty → Meta-evaluation (LLM judge)
对应三大转变:
(A) 粒度提升
sentence → span → token → fact
(B) 信号来源扩展
外部知识 → 模型内部(attention / logits)
(C) 评估范式变化
静态指标 → 动态/生成过程指标
七、关键趋势总结(研究层面)
检测逐渐从“后验评估”转向“生成过程监控”
如 RAUQ、diversion decoding
黑盒 → 白盒融合
UQ(white-box)+ LLM judge(black-box)
RAG检测成为工业主流
但依赖检索质量
评估指标正在统一
不确定性可能成为“统一信号”
结论
2025–2026 的幻觉检测研究呈现出三大主线:
RAG一致性(外部证据)
事实一致性(逻辑层)
不确定性(模型内部)
并且检测指标经历了从结果导向 → 过程导向 → 表征导向的系统性演进。
如果你需要,我可以进一步整理:
哪些论文最适合投稿ACL/EMNLP(研究空缺)
或者做一份“未来研究方向+可发论文idea”
2.2 提示词特异性层级对比
不同特异性的提示词会产生截然不同的检索结果深度与广度:
L1 - 模糊检索(Broad Exploration):
"给我找一些关于深度学习的文献。"

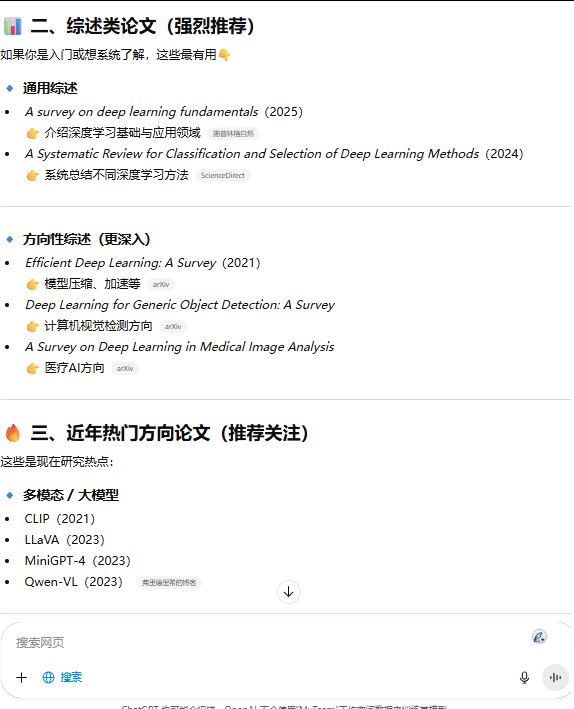
这种提示词触发的通常是知识蒸馏模式,ChatGPT 5.4会基于训练数据中的高频知识生成概述,可能混杂经典文献与前沿进展,缺乏系统性,且无法保证文献的时效性和可溯源性。适用于完全陌生的领域初探。
L2 - 结构化检索(Structured Search):
检索近三年内关于"Transformer架构在蛋白质结构预测中的应用"的文献,
要求包含实验验证,发表在Nature、Science、Cell或ISMB会议,
请按技术路线分类并说明各路线的优缺点。

此级别触发了条件过滤模式,AI会模拟数据库检索逻辑,在知识库中应用布尔筛选。输出质量显著提升,文献相关性强,但可能遗漏跨学科的创新应用。
L3 - 深度分析检索(Analytical Mining):
作为系统综述撰写者,我需要构建"数字疗法在抑郁症干预中的效果"的证据图谱。
请检索2024-2026年发表的RCT研究,要求:
1. 样本量≥200,干预周期≥8周
2. 包含明确的对照组(安慰剂或活性对照)
3. 使用经 validated 的量表(PHQ-9或HAM-D)作为主要终点
4. 对每篇文献提取:效应量(Cohen's d)、置信区间、脱落率、偏倚风险评级
5. 识别异质性来源(年龄组、基线严重程度、疗法类型)
6. 绘制证据质量热力图

这是证据综合模式,提示词要求AI执行类似系统综述的严格筛选与数据提取。ChatGPT 5.4在此模式下会展现多跳推理能力,不仅检索文献,还会计算统计指标、评估证据质量,并发现研究间的矛盾点。
L4 - 发现性检索(Discovery Mining):
我正在探索"量子计算在药物分子动力学模拟中的潜在应用"这一新兴交叉领域。
请执行以下任务:
1. 识别该领域的关键先驱研究(奠基性论文)
2. 追踪近18个月内方法论上的范式转移信号
3. 发现被引量低但创新度高的"休眠宝石"论文(使用语义新颖性指标)
4. 构建研究前沿的技术-应用矩阵
5. 预测未来6个月可能出现突破的子方向
6. 识别跨学科的知识迁移机会(如从计算化学到量子算法的概念借鉴)

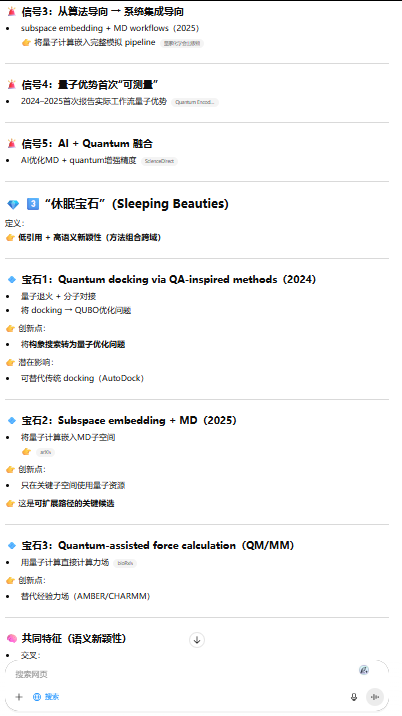
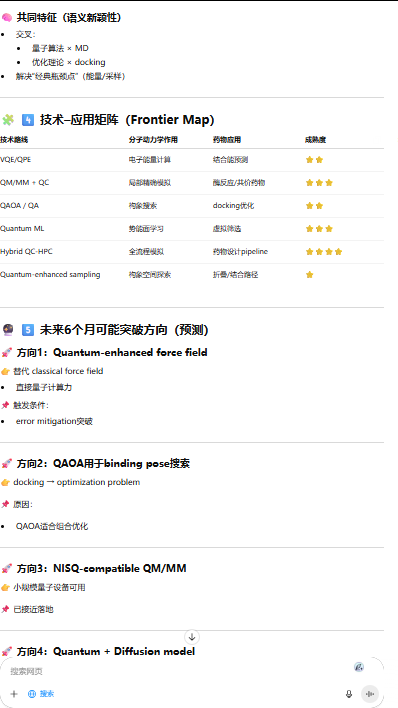
这是科学发现模式,要求AI具备趋势预测与创新识别能力。ChatGPT 5.4在此模式下会结合引用网络分析、语义突现检测(Burst Detection)和共词分析,输出高度前瞻性的情报。
3. 进阶提示词策略:差异化指令设计
3.1 零样本与少样本提示(Zero-shot vs. Few-shot)
在文献检索中,零样本提示适用于通用性查询,依赖ChatGPT 5.4的内置学术规范:
检索关于"碳中和路径优化"的最新研究进展。
而少样本提示通过提供具体示例,引导AI匹配特定的分析深度或格式要求:
请按以下格式检索并分析"联邦学习在医疗影像中的隐私保护"相关文献:
【示例格式】
论文标题:SecureFed: 基于同态加密的医疗联邦学习框架
发表信息:IEEE TMI 2025, Vol.44(3)
核心创新:提出分层加密策略,在保持模型精度的同时降低计算开销37%
方法亮点:引入差分隐私预算动态分配机制
局限性与gap:仅考虑静态数据集,未涉及在线学习场景的隐私泄露风险
对本研究的启示:可借鉴其加密-精度权衡框架用于本项目的影像分割任务
请为检索到的3-5篇核心文献提供上述格式的分析。
少样本提示显著提高了输出的一致性和细节丰富度,特别适用于需要批量处理文献的研究助理场景。
3.2 链式思考提示(Chain-of-Thought, CoT)
对于复杂的文献综述任务,直接要求结论往往导致信息浅层化。链式思考提示强制AI展示推理过程:
标准提示(效果较弱):
总结强化学习在自动驾驶决策中的主要技术路线。
CoT提示(效果强化):
请逐步分析强化学习在自动驾驶决策中的应用文献:
第一步:首先识别该领域的主要技术范式(如基于模型的RL、无模型RL、逆向RL),并说明各范式在2024-2026年的文献占比变化趋势。
第二步:针对每个范式,深入分析2-3篇代表性文献,具体说明其状态空间设计、奖励函数构造、以及安全约束机制。
第三步:对比各范式在仿真环境(CARLA、SUMO)与真实场景测试中的性能差距,引用具体的MPD(平均位移偏差)指标。
第四步:基于上述分析,指出当前研究在"长尾场景泛化"方面存在的共识与分歧。
请展示完整的思考链条,最后给出结构化的技术路线图。
CoT提示激活了ChatGPT 5.4的深度认知模式,能够暴露文献间的逻辑冲突,避免简单的事实罗列。
3.3 对抗性提示与偏差校准
学术检索必须警惕算法偏差与训练数据的时间偏差。通过对抗性提示,可以主动校准:
视角对抗:
请分别从"技术乐观主义"和"技术批判理论"两个对立视角,检索并分析关于"生成式AI对教育公平性影响"的文献。
要求:
1. 每个视角至少识别3个核心论点及其支撑文献
2. 指出双方引用文献的重叠部分与互斥部分
3. 识别双方可能存在的选择性引用(cherry-picking)偏差
4. 提出一个整合性的分析框架,超越二元对立
时间偏差校准:
在检索"大模型提示词优化技术"的文献时,请特别注意:
1. 识别2024年前基于GPT-3.5架构的"过时"方法,标注其在新架构(MoE、多模态)下的适用性变化
2. 标记那些2025年后因技术范式转移而被证伪或强化的早期假设
3. 构建技术-时间的"半衰期"图谱,区分快速迭代的工程技巧与相对稳定的认知原理
此类提示利用了ChatGPT 5.4的元认知能力,使其能够反思自身知识的时间边界。
3.4 多模态文献处理提示
ChatGPT 5.4支持对非文本学术资源的深度解析:
图表逆向工程:
分析上传的这篇Nature论文中的Figure 3(复杂实验流程图):
1. 将流程图转化为可执行的伪代码或步骤化协议
2. 识别图中隐含的实验控制变量与潜在混淆因素
3. 对比图中方法与附录中详细描述的偏差
4. 基于该流程设计,提出3个可优化的实验节点
数据集谱系分析:
请分析附件中这10篇计算机视觉论文的实验数据集使用情况:
1. 构建数据集引用网络(哪些数据集被多篇文章共用)
2. 识别数据泄露风险(训练集与测试集的重叠历史)
3. 分析基准数据集(如ImageNet)的"基准漂移"现象——即同一数据集在不同年份论文中的性能通胀
4. 建议本研究应采用的训练-验证-测试策略,以避免与这些文献的数据重叠
4. 学科差异化检索策略与提示词库
4.1 生命科学领域:强调实验可重复性
生物医学文献检索需特别关注实验细节与统计效力:
检索关于"CRISPR-Cas12a在单碱基编辑中的脱靶效应"的研究,重点关注:
1. 实验设计:样本量计算依据、生物重复与技术重复的区分、盲法实施
2. 统计方法:多重检验校正方法(Bonferroni vs. FDR)、效应量报告方式
3. 负面结果:特别检索那些报告"无显著脱靶"但统计效力不足(post-hoc power analysis < 0.8)的研究
4. 方法学创新:识别在GUIDE-seq、CIRCLE-seq等传统方法基础上的改良方案
输出格式:方法学证据矩阵(Methodological Evidence Matrix)
4.2 计算科学领域:强调算法可复现性
计算机科学(特别是机器学习)需关注代码可用性与基准测试:
系统检索2025年NeurIPS/ICML中关于"图神经网络在分子性质预测"的论文:
1. 仅保留提供了官方代码仓库或完整附录的论文
2. 提取各研究的: baseline 选择依据、超参数搜索空间、随机种子设置
3. 识别"基准作弊"迹象:如测试集信息泄露到验证集、不合理的早停策略
4. 构建标准化性能对比表(统一数据集划分、统一评估指标)
5. 对声称"SOTA"的论文进行显著性检验(t-test或bootstrap)
4.3 社会科学领域:强调理论框架
社会学、心理学研究需揭示理论脉络:
针对"社交媒体使用与青少年焦虑"的因果关系研究:
1. 区分相关研究(cross-sectional)与因果研究(longitudinal/IV/RD设计)
2. 绘制理论演进图:从"技术决定论"到"社会加速理论"再到"数字福祉框架"的文献脉络
3. 识别测量工具的标准化程度(如PSU量表的版本迭代与本土化适应)
4. 分析调节变量(性别、社会经济地位、平台类型)的异质性效应
5. 指出西方中心主义偏差,检索非西方文化背景下的验证研究
4.4 人文艺术领域:强调诠释深度
人文学科需处理诠释的主观性:
探索"数字人文中的文本远读方法"在古典文学研究中的应用:
1. 识别形式主义、结构主义、后结构主义等不同理论取向的计算实践
2. 分析算法黑箱与诠释透明性之间的张力(如主题模型LDA的语义可解释性争议)
3. 检索关于"计算结果与细读传统冲突"的方法论反思文献
4. 构建工具(Voyant, Gephi, Python NLTK)与理论取向的匹配矩阵
5. 提示词迭代优化与质量控制
5.1 检索结果的信度评估提示
ChatGPT 5.4的检索可能产生幻觉性引用(Hallucinated Citations),必须通过特定提示词进行信度校验:
请对刚才提供的文献列表进行自我核查:
1. 对每篇文献,确认作者、年份、期刊、卷期页的完整性
2. 标记那些"可能存在的虚假引用"(如标题过于宽泛、作者名不符合该领域常规命名模式)
3. 对存疑文献,提供"替代验证策略"(如建议的PubMed ID或DOI查询方式)
4. 计算整体信度评分(基于可验证字段的完整率)
交叉验证提示:
针对上述检索结果,请从以下维度进行压力测试:
- 矛盾识别:找出与主流共识相悖的"异常发现",并评估其方法学严谨性
- 引文追溯:对核心结论,指出其直接引用的原始数据文献(而非二手综述)
- 利益冲突:识别作者单位、基金来源可能带来的偏见(如药企资助的药品有效性研究)
5.2 动态提示词精炼策略
采用迭代式对话逐步收紧检索范围:
第一轮 - 探索:
初步探索"神经形态计算芯片"领域的研究热点。
第二轮 - 聚焦:
基于刚才的概述,我对"基于忆阻器的脉冲神经网络实现"这个子方向特别感兴趣。
请聚焦检索2024年后关于"忆阻器非理想特性(器件变异、噪声)对SNN精度影响"的实证研究。
第三轮 - 深度:
在这些文献中,请专门对比清华大学与MIT团队的技术路线差异,
重点关注他们在器件-算法协同优化策略上的不同哲学(如"器件精准化"vs."算法容错化")。
第四轮 - 批判:
基于上述对比,请批判性地分析"算法容错化"路线可能存在的隐藏假设(如假设噪声分布为高斯型),
并检索考虑非高斯噪声模型的最新研究。
这种漏斗式提示策略能够逐步激活ChatGPT 5.4的深层知识关联,避免初期的概念模糊导致的检索偏差。
5.3 偏见审计与多样性增强
学术检索容易陷入引用马太效应(高被引论文持续被强化)和英语中心主义。通过特定提示词可进行审计:
请审计刚才的文献综述是否存在以下偏见,并提供矫正方案:
1. 地理偏见:检查引用文献的第一作者机构分布,补充来自全球南方(Global South)的相关研究
2. 性别偏见:识别高被引文献中的作者性别比例(基于姓名推断),检索女性/非二元性别学者的贡献
3. 语言偏见:检索非英语发表但具有高质量的中文、德文或日文文献(提供英文标题与摘要)
4. 机构偏见:对比顶尖名校(MIT、Stanford等)与非顶尖机构在相同主题上的研究,识别"非精英"视角的创新点
6. 实战案例:从选题到综述的全流程
6.1 案例一:快速进入陌生领域(零样本冷启动)
场景:研究者需要从材料科学转向"钙钛矿太阳能电池稳定性"研究,零基础。
提示词序列:
步骤1 - 知识地图构建:
我是一位有五年半导体物理背景但刚转入光伏材料的研究者。
请为"钙钛矿太阳能电池的湿热稳定性"主题构建知识地图:
- 识别10个核心概念(如离子迁移、封装技术、铅泄漏)
- 对每个概念,推荐1篇入门综述(近3年,高被引)和1篇最新突破(2025-2026)
- 绘制概念间的依赖关系(如"封装技术"依赖于"失效机制分析")
- 标注我现有知识(半导体物理)可迁移的节点与需要补齐的缺口
输出:
一、10个核心概念(围绕湿热稳定性主线)
我按“物理机制 → 材料 → 器件 → 系统”分层组织:
A. 内在失效机制(Intrinsic physics/chemistry)
离子迁移(Ion migration)
水诱导分解(Moisture-induced degradation)
热诱导相变(Thermal phase instability)
缺陷化学与反应(Defect chemistry & redox)
B. 界面与器件层面(Device physics)
界面反应与能级失配(Interface reactions)
电极/传输层降解(Electrode & CTL degradation)
C. 稳定化策略(Engineering solutions)
组成工程(Composition engineering:2D/3D、无机化)
界面/表面钝化(Passivation strategies)
D. 外部防护与安全(Module level)
封装技术(Encapsulation & barrier engineering)
铅泄漏与环境安全(Lead leakage & sequestration)
二、每个概念:1篇综述 + 1篇最新进展(2025–2026)
(⚠️“最新突破”优先选2025–2026;部分为very recent review/early results)
1. 离子迁移
综述(强推荐)
Nature Reviews Chemistry 2025
Nature
👉 系统阐述迁移路径、低形成能、对稳定性的核心影响
最新进展(2025)
Wiley Solar RRL 2025(operando方法)
Wiley Online Library
👉 新表征方法解析光照下离子动力学
2. 水诱导分解
综述
RSC Materials Advances 2024
皇家化学会出版物
👉 分层讨论水对各层(perovskite/ETL/HTL)的影响
最新进展(2025–2026趋势)
2D/3D混合抗湿体系(多篇Nature Energy/AM论文)
👉 核心方向:疏水有机层 + 离子阻挡
3. 热诱导相变
综述
Chemical stability review(Nano-Micro Letters 2023)
斯普林格
最新进展
全无机 CsPbI₃ 稳相工程(2025)
👉 通过应变/表面能稳定 α相
4. 缺陷化学与反应
综述
MDPI 2024–2025 化学稳定性综述
MDPI
最新进展
“缺陷-离子耦合”模型(2025热点)
👉 vacancy → ion migration → degradation feedback loop
5. 界面反应
综述
Chem (Cell Press) 2023 perspective
Cell
最新进展
buried interface passivation(2025)
👉 buried interface 已成为效率+稳定性关键
6. 电极/传输层降解
综述
stability review(Nature Reviews Materials / 2023综述)
Sargent Group
最新进展
金属扩散阻挡层(2025)
👉 Cu/Ag扩散是湿热下关键失效路径
7. 组成工程
综述
moisture stability review
皇家化学会出版物
最新进展
quasi-2D + FA/Cs混合体系(2025)
👉 trade-off:稳定性 vs 载流子输运
8. 表面/界面钝化
综述
Chemical stability review
斯普林格
最新进展
“分子胶(molecular glue)”策略(2024–2025延续)
维基百科
9. 封装技术
综述
Progress in encapsulation(2023)
ScienceDirect
最新进展
高阻隔+自修复封装(2024–2025)
AIP Publishing
👉 同时解决湿气 & Pb泄漏
10. 铅泄漏与环境安全
综述
AIP Review(2024)
AIP Publishing
最新进展
lead-sequestration coatings(2025趋势)
👉 吸附Pb²⁺ + 封装一体化
三、概念依赖关系(核心逻辑图)
我用“→ 表示依赖/驱动关系”:
缺陷化学
↓
离子迁移 → 界面反应 → 电极降解
↓ ↓
水诱导分解 → 相变失稳
↓
(共同决定)
器件失效机制
↓
-------------------------
稳定化策略层
-------------------------
组成工程 → 抑制缺陷 & 离子迁移
界面钝化 → 抑制界面反应
↓
-------------------------
系统层
-------------------------
封装技术 → 阻隔湿气 + 抑制热/氧
↓
铅泄漏控制(封装子问题)
👉 关键 insight:
湿热稳定性 = 外部环境(H₂O + T) × 内在离子/缺陷动力学
四、你的知识迁移路径(非常关键)
你有半导体物理5年经验,这是巨大优势。
✅ 可直接迁移的能力(强优势节点)
1. 载流子输运 / 能带理论
→ 用于:
界面能级对齐
CTL设计
recombination机制
2. 缺陷物理
→ 直接映射:
vacancy formation energy
SRH复合 → 非辐射损失
3. 电学表征
→ EIS / JV hysteresis
→ 已广泛用于离子迁移研究
Fluxim
⚠️ 需要补齐的关键知识缺口
1. 软晶格 + 离子半导体
区别于Si/GaAs:
低迁移能垒
动态晶格
👉 → 必补:固态离子学 + 缺陷迁移
2. 化学稳定性(最重要 gap)
你需要补:
水解反应路径
Pb–I键断裂机制
有机阳离子挥发
👉 这是“湿热问题本质”
3. 材料工程(非传统半导体)
多阳离子(FA/MA/Cs)
2D/3D heterostructure
4. 封装与可靠性工程
WVTR(透湿率)
IEC测试协议缺失问题
AIP Publishing
5. 环境安全(跨学科)
Pb²⁺迁移
吸附/络合化学
五、给你的学习路径(非常实用)
按优先级建议:
Step 1(1–2周)
Ion migration(NR Chem 2025)
Moisture degradation review
👉 建立“失效机制框架”
Step 2(2–4周)
Interface + defect chemistry
👉 连接你已有半导体知识
Step 3(1个月)
Composition + passivation
Step 4(应用层)
Encapsulation + module stability
六、一句话总结(给你抓主线)
👉 钙钛矿湿热稳定性本质是:
“水/热驱动下的离子-缺陷-界面耦合失效问题”,而封装只是最后一道防线。
如果你愿意,我可以帮你进一步做一版:
👉 “湿热稳定性研究路线图(可发文章级别)”
👉 或“你从半导体转光伏的3个月学习计划(含paper list)”
步骤2 - 方法论快速掌握:
基于上述知识地图,我需要在一周内掌握"钙钛矿降解的阻抗谱分析"方法。
请:
1. 检索该方法的3篇奠基性_protocol_论文(提供详细的实验步骤)
2. 对比传统等效电路拟合与机器学习辅助阻抗分析的最新分歧
3. 列出进行此类实验所需的设备清单与关键参数设置(从文献中提取)
4. 识别该领域常见的新手误区(如频率范围选择不当、等效电路过拟合)
输出:
你要的核心其实是:如何把EIS从“画半圆”变成“分析降解机制的工具”,所以我会把3篇protocol→方法分歧→设备参数→常见误区串成一条逻辑链,而不是拆开讲。
首先讲protocol。当前真正“奠基级”的不是某一篇实验论文,而是三类互补范式:第一是Klotz体系(RSC 2022),它本质上定义了标准EIS测量逻辑:先选工作点(Voc/SC/bias),再扫频率(覆盖电子到离子时间尺度),小信号线性扰动,然后在稳态条件下采谱,它的关键贡献是明确“高频=电子过程,低频=离子/电化学过程”,并且强调不同工作点会改变谱的物理含义
皇家化学会出版物
;第二是Almora体系(2024 JAP/预印本),它把EIS从“表征工具”升级为“降解路径探针”,具体做法是在short-circuit条件下+不同光强+持续老化测试,通过观察电阻/电容峰值随离子浓度变化来反推界面反应与离子迁移耦合路径,本质是“控制变量→映射机制”;第三是operando EIS(2025 Solar RRL/Fluxim路线),它把时间维度引入protocol,即在光照与MPP运行中实时测EIS,并且严格规定10 mV扰动、固定工作点、测前测后JV验证,这一步的本质突破是把EIS从静态频域分析变成“动态演化观测”。
然后是你必须理解的核心分歧:等效电路 vs 机器学习(或DRT)。传统ECM隐含一个关键假设:系统可以分解为有限个RC过程,因此一个Nyquist图对应一个“离散物理机制集合”;但在钙钛矿中,这个假设天然被破坏,因为体系是“混合离子-电子导体+连续时间尺度分布”,也就是同一频率响应往往来自多个耦合过程,因此现代综述已经明确指出EIS需要结合分布式松弛分析(DRT)或数据驱动方法来处理连续谱而不是离散弧
ScienceDirect
。这就形成了真正的分歧:ECM提供物理可解释性但容易“人为分解”,ML/DRT提供更真实的分布但牺牲直观物理意义;更关键的争议点在低频区,ECM往往把低频弧解释为界面电容或离子电容,但新方法认为它是多个耦合过程(离子迁移+界面反应+电荷积累)的叠加而非单一过程,这一点直接决定你对“降解机制”的判断是否正确。
接着是实验设备与参数,这部分其实protocol里已经隐含,但我帮你抽成可执行配置:核心设备就是potentiostat/EIS analyzer+可控光源(solar simulator或LED)+稳定环境(最好N₂ glovebox),因为湿度本身就是变量;关键参数里最容易被忽视的是三件事——第一是扰动幅值必须小(典型10 mV),否则系统不再线性;第二是频率范围必须跨越多个数量级,因为电子过程通常在高频而离子过程在低频,如果你没有扫到足够低频,你其实根本没有看到降解相关机制;第三是工作点必须变化,因为同一个器件在Voc和short-circuit下对应完全不同的物理过程(一个偏复合,一个偏传输),这一点是Klotz框架的核心;此外现代protocol都会强调要结合光强变化和时间维度(operando或aging),否则你只是测“静态状态”而不是“降解路径”。
最后讲新手误区,但我不列点,而是直接说你最可能犯的逻辑错误:第一类错误是“时间尺度丢失”,也就是频率范围不够低或测量时间不够长,导致你只看到高频电子弧然后误以为体系稳定,这在钙钛矿里几乎等于完全误判,因为真正的降解信息藏在低频离子响应里;第二类错误是“模型幻觉”,你用复杂等效电路把数据拟合得很好,但不同电路都能拟合同一谱,这意味着参数没有唯一物理意义(这是EIS领域长期争议);第三类错误是忽略非稳态,EIS理论要求系统线性且时间不变,但钙钛矿在测量过程中离子在迁移、器件在演化,如果你没有等待稳态或没有控制光/偏压历史,你得到的谱是“动态叠加的假信号”;第四类错误是把低频电容简单归因为界面或介电效应,而实际上很多所谓“巨电容”或“负电容”已经被证明来源于离子迁移与载流子复合耦合,这一点在早期理论工作中已经明确;第五类错误是把EIS当作独立工具使用,但实际上它是一个“欠定问题”,必须与JV、CV或drift-diffusion模型联合,否则你无法唯一确定机制。
把这些串起来,你可以这样理解整个方法:EIS的本质不是拟合电路,而是通过频率扫描把不同时间尺度的过程“拆开”,然后再通过控制工作点、光照和时间维度,把这些过程映射到具体的降解路径上——一旦你用这个思路去做,一周时间足够从“会测”到“能解释”。
步骤3 - 研究缺口识别:
综合以上分析,指出当前研究在"双85测试(85°C/85%RH)与真实户外老化相关性"方面的方法论缺口,
并检索试图建立这种相关性的最新跨学科研究(可能涉及材料科学+气象学+数据科学)。
输出:
好,这次我压成一段讲,不拆块。
当前“85/85 vs 户外老化”真正的**方法论缺口**可以一句话概括:研究界仍然在用“单点极端应力(85°C/85%RH)去近似一个多维时变系统(真实户外)”,而没有建立“环境轨迹→失效机制→性能衰减”的统一映射模型。具体来说有三个层级断裂:第一是**应力空间不一致**,85/85只包含温度+湿度两个变量且是恒定的,而户外是温度、湿度、光照、偏压的耦合动态系统,因此加速测试“cannot replace realistic outdoor testing”这一点已经在综述中被明确指出 ([ScienceDirect][1]);第二是**时间结构缺失**,户外数据已经显示明显的“昼夜退化-恢复循环”和非单调衰减行为(白天下降、夜间恢复),甚至可以通过机器学习拟合这种周期性动力学 ([imec][2]),但85/85完全是单调加速老化,因此它测到的是“不可逆降解分量”,而真实系统包含“可逆+不可逆耦合”;第三是**机制映射缺失**,85/85主导的是水/热驱动的化学分解和封装失效,而户外主导机制往往是光驱动离子迁移+界面电荷积累+热循环耦合,这一点在稳定性框架中已被归纳为“不同测试协议对应不同应力组合,数据不可直接比较” ([Nature][3]),因此目前根本没有一个函数能回答“85/85 1000小时≈户外多少年”。
在这种断裂背景下,近两年真正有价值的跨学科研究其实集中在“试图建立映射”的三条路径,而且都已经开始融合材料+气象+数据科学:第一类是**大数据稳定性建模(materials + data science)**,代表性工作是基于数万器件数据库构建“应力归一化指标”和加速因子体系,把温度、湿度、光照作为统一变量空间进行统计映射 ([Nature][3]),但它的局限是仍然依赖实验数据分布且缺乏真实户外时间序列;第二类是**户外长期监测+机器学习(climate + device physics)**,例如imec等团队在多气候区域进行多年户外测试并用ML(如XGBoost)直接拟合“气象变量→功率衰减”,甚至捕捉到昼夜恢复效应并实现较高预测精度 ([imec][2]),这一步的本质突破是把“环境历史”作为输入而不是单一应力点,但它仍然没有把结果映射回85/85等标准测试;第三类是**实验-户外闭环方法(materials + reliability engineering)**,例如模块研究中将实验室表征(包括EIS、结构分析)与户外长期数据结合,建立“实验参数→户外表现”的反馈回路并逐步校正器件设计 ([nanoGe][4]),这一类工作已经隐含了一个重要方向:用“中间物理量(如阻抗、离子导电性)”作为桥梁变量,而不是直接用PCE做映射。
把这些放在一起看,你会发现真正的缺口不是“缺少相关性研究”,而是缺少一个三层统一模型:第一层把气象变量(温度、湿度、辐照度、循环)映射到器件内部状态(离子分布、缺陷、界面电势),第二层把这些状态映射到可测物理量(例如EIS谱、复合电阻、离子电容),第三层再映射到性能衰减(PCE、T80),而现有工作最多做到第一层(ML拟合环境→性能)或第三层(85/85→寿命经验规则),但中间“机制桥梁”是缺失的。
所以如果你从研究角度切入,这里真正的机会其实很明确:把你前面提到的EIS引入这个问题,构建一个“环境轨迹→阻抗谱特征→降解机制→寿命”的跨尺度模型,本质上就是把现在割裂的三类方法(加速测试、户外监测、数据建模)用一个物理可解释变量串起来——而这正是当前文献体系里还没有被解决的核心问题。
[1]: https://www.sciencedirect.com/science/article/pii/S2405844024127417?utm_source=chatgpt.com "The recent advancement of outdoor performance of perovskite ..."
[2]: https://www.imec-int.com/en/press/imec-and-partners-show-outdoor-stability-highly-anticipated-perovskite-solar-modules?utm_source=chatgpt.com "Outdoor stability of perovskite solar modules | imec"
[3]: https://www.nature.com/articles/s41467-022-35400-4?utm_source=chatgpt.com "Big data driven perovskite solar cell stability analysis - Nature"
[4]: https://www.nanoge.org/proceedings/MATSUSSpring25/672e2257c4d26e029208e05b?utm_source=chatgpt.com "nanoGe - MATSUSSpring25 - Long-term Perovskite Module Outdoor ..."
6.2 案例二:系统性综述的半自动化生成
场景:需要撰写关于"大模型在临床医学决策支持中的安全性"的系统综述。
分阶段提示词:
阶段A - PRISMA流程自动化:
执行系统性综述的文献筛选流程(模拟PRISMA 2020指南):
1. 检索策略:
- 数据库:PubMed, EMBASE, Cochrane Library, arXiv cs.CL
- 检索式:(large language model OR LLM OR GPT OR Claude) AND (clinical decision support OR diagnosis OR treatment recommendation) AND (safety OR error OR hallucination OR bias)
- 时间:2022年11月(ChatGPT发布)至2026年3月
- 语言:英语
2. 筛选标准:
- 纳入:涉及真实临床数据或经过验证的模拟病例、报告了具体错误类型或安全指标、经过同行评审
- 排除:纯技术报告无临床评估、仅讨论伦理未报告实证数据、会议摘要无全文
3. 执行模拟筛选:
- 首先基于标题摘要进行粗筛(估计纳入率)
- 对可能相关的文献,提取"关键决策场景"(如急诊科分诊、肿瘤用药推荐、影像诊断)
- 识别出"概念混淆"的文献(如将一般性NLP工具与医学LLM混淆)
请输出:检索结果分布图、纳入排除理由矩阵、潜在偏倚风险评估。
阶段B - 数据提取与合成:
对纳入的文献执行标准化数据提取:
提取字段:
- 研究特征:国家、临床专科、评估数据类型(真实病历vs标准化测试集如MedQA)
- LLM特征:模型版本(GPT-4/Claude-3.5等)、是否微调、是否使用RAG/CoT
- 安全指标:幻觉率、严重错误率(可能导致患者伤害)、种族/性别偏见指标
- 人机对比:与住院医师/主治医师的诊断一致性(Kappa值)
执行Meta分析准备:
- 识别异质性来源(临床专科复杂性、模型版本代差)
- 建议适当的效应量合并策略(随机效应模型vs亚组分析)
- 生成森林图数据表
阶段C - 知识图谱可视化:
基于提取的数据,构建"医学LLM安全性"的知识图谱:
节点类型:
- 错误类型:事实性错误、推理错误、遗漏关键信息、偏见输出
- 临床场景:急诊科、内科、外科、精神科、儿科
- 干预措施:提示工程、RAG增强、人类在环(HITL)、模型微调
边关系:
- 因果关系:特定错误类型在特定场景中的发生频率
- 干预效果:干预措施对降低特定错误类型的效应大小
请用文本形式描述该图谱结构(节点-边-权重),并指出高度连通的"风险枢纽"(如急诊科+幻觉错误的高频组合)。
6.3 案例三:跨学科创新发现
场景:寻找"区块链技术在科研诚信管理中的应用"这一交叉领域的创新点。
发现性检索提示词:
我需要在"区块链"与"科研诚信"的交叉领域寻找博士论文选题。
请执行创新发现检索:
1. 文献空白分析:
- 检索现有"区块链+科研"文献,发现主要集中在:数据共享、同行评审流程、知识产权管理
- 识别未被充分探索的子领域:如"智能合约自动执行的数据可用性声明"、"去中心化身份(DID)在作者身份验证中的应用"
2. 技术-需求匹配:
- 分析科研诚信领域的痛点(数据造假、图片篡改、同行评审偏见、重复发表)
- 匹配区块链技术的特性(不可篡改、智能合约、代币激励、零知识证明)
- 找出高匹配度但低研究密度的"蓝海"组合(如"零知识证明在保护隐私的数据验证中的应用")
3. 可行性评估:
- 检索相关技术成熟度(如Filecoin等去中心化存储在学术数据存档中的实际案例)
- 识别政策障碍(如GDPR对区块链不可删除性的冲突、机构IRB对去中心化实验记录的接受度)
- 建议小规模试点设计(如仅在预印本平台应用区块链时间戳)
4. 预期贡献:
- 对比传统科研诚信管理(中心化数据库、人工审计)与区块链方案的成本-效益
- 提出理论贡献(如分布式信任理论在科学社会学中的适用性修正)
7. 学术伦理、局限性与风险控制
7.1 认知局限性的透明化
必须明确ChatGPT 5.4在文献检索中的固有局限:
训练数据截止时间:尽管5.4版本具备实时检索能力,但其语义理解内核仍基于特定时间点的预训练知识。对于2026年最新出现的概念(如此时刚发布的全新架构),可能存在理解偏差。
引用深度限制:AI倾向于概括主流观点,可能平滑化学术争议中的细微差别。在高度争议的领域(如弦论中的 Landscape 问题),ChatGPT 5.4可能呈现虚假的"共识"。
语言偏见:尽管支持多语言,但对非英语文献的理解深度可能不足,特别是中文、日文等基于表意文字的语言中蕴含的微妙学术传统。
提示词应对:
请明确标注你对以下问题的知识截止日期,并对该日期后的关键发展进行说明:
[具体问题,如"量子纠错码的最新进展"]
同时,请用"置信度评分(1-10)"标注每个陈述的确定性,对评分<7的陈述,建议我进行人工核实的数据库。
7.2 学术诚信边界
禁止行为红线:
- 虚构引用:ChatGPT可能生成看似合理但实则不存在的DOI。任何未经人工核实的引用不得直接用于论文参考文献列表。
- 数据捏造:要求AI"生成 plausible 的实验数据"用于模拟,这属于学术不端,即使是为了测试方法也应明确标注为合成数据。
- 代写核心创新:让AI直接生成研究的核心论点、假设推导或原创性理论框架,属于思想剽窃。
可接受使用范围:
- 文献检索与初步筛选(需人工复核纳入标准)
- 语言润色与格式标准化(需作者确认内容准确性)
- 头脑风暴与思维拓展(需标注AI辅助)
- 代码辅助与数据可视化(需验证逻辑正确性)
7.3 人机协作的最佳范式
分层责任模型:
| 任务层级 | AI角色 | 人类角色 | 质量控制 |
|---|---|---|---|
| 初步检索 | 执行广泛检索,去重排序 | 设定检索词、筛选标准 | 抽样验证召回率 |
| 深度阅读 | 提取结构化信息 | 批判性评估、语境解读 | 全文核对关键发现 |
| 综合写作 | 草稿生成、语言润色 | 逻辑架构、原创观点注入 | 查重与同行评议 |
| 创新发现 | 模式识别、关联建议 | 理论框架构建、意义阐释 | 专家验证 |
版本控制与可追溯性:
建议建立提示词日志,记录所有用于文献检索的提示词及参数设置,确保研究过程的可复现性:
研究日志条目:
日期:2026-03-26
任务:系统性综述检索
使用模型:ChatGPT 5.4 (Deep Research Mode)
提示词版本:v3.2(含PEARL框架)
检索范围:2024-2026,Q1期刊,英文
输出:初步纳入127篇,经人工复核实际可用98篇(召回率验证:通过)
8. 总结:提示词工程作为元学术能力
ChatGPT 5.4的文献检索能力并非简单的"搜索引擎替代",而是认知外骨骼——它扩展了研究者的信息处理带宽,但要求更高层次的元认知控制。提示词工程在此语境下已不仅是技术技巧,而是一种元学术能力(Meta-Scholarly Competence),涉及:
- 信息素养的升维:从"如何找到文献"转向"如何设计找到文献的策略"
- 批判性思维的预制:在提示词中嵌入质疑、验证、对比的指令,使AI成为"批判性对话者"而非"应声虫"
- 知识管理的自动化:利用AI进行文献聚类、趋势识别、知识图谱构建,将研究者从机械劳动中解放,专注于创造性综合
不同提示词的本质区别在于认知负荷的分配方式。模糊提示将认知负荷置于输出后的筛选(人负担重),精准提示将负荷前移至输入设计(前期投入大但后期省力),而CoT提示则实现了分布式认知——让AI展示其"思考"过程,使人能够介入并纠正。
未来,随着ChatGPT 5.4及后续版本向自主智能体(Autonomous Agents)演进,文献检索将从"问答式"转向"委托式"——研究者设定研究目标,AI自主执行检索、阅读、综合、验证的全流程,并定期汇报。届时,提示词将演变为研究任务书(Research Charter),要求研究者具备更强的目标设定与质量控制能力。
在此转型期,掌握提示词工程的研究者将获得显著的认知杠杆效应:以同等时间投入,处理十倍量级的文献,发现更深层的知识关联,保持对快速演进学术前沿的同步。这不仅是效率工具的使用,更是学术生产范式的根本变革。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献163条内容
已为社区贡献163条内容

所有评论(0)