EdgeCrafter:10M 参数达到 51.7 AP,姿态估计超越 YOLO26-Pose——让紧凑 ViT 在边缘端一打三

导读:
———————————————————————————————————————————
边缘设备上的密集预测任务(目标检测、实例分割、人体姿态估计)至今仍被 YOLO 等 CNN 架构主导,紧凑型 Vision Transformer(ViT)即使经过大规模预训练,在小参数量下也难以与之匹配。问题出在哪里?EdgeCrafter 给出的回答是:不是 ViT 天生不适合边缘密集预测,而是通用预训练在小模型上提供的任务特定表征不够充分。为此,该工作提出一套以目标检测为中心的紧凑 ViT 框架,通过任务专用蒸馏(Task-Specialized Distillation)将 DINOv3 大模型的检测表征注入轻量学生骨干 ECViT,再配合卷积 stem 和简单插值构建多尺度特征金字塔。最终,ECDet-S 仅 10M 参数即达到 51.7 AP(COCO val2017),ECPose-X 以 50.6M 参数达到 74.8 AP,超过依赖 Objects365 预训练的 YOLO26-Pose-X(71.6 AP)达 +3.2 AP,ECInsSeg-S仅 10.3M 参数便达到 43.0 AP。蒸馏得到的检测表征可直接迁移至分割和姿态估计,无需针对每个任务重新设计骨干。
论文信息
标题:EdgeCrafter: Compact ViTs for Edge Dense Prediction via Task-Specialized Distillation
机构:Intellindust AI Lab
代码:https://intellindust-ai-lab.github.io/projects/EdgeCrafter/
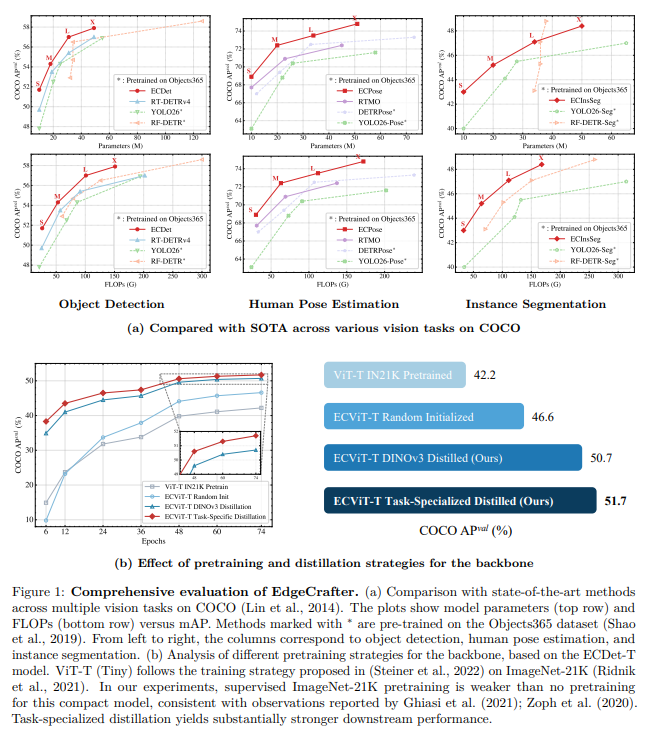
一、紧凑 ViT 在边缘密集预测中为何掉队?
———————————————————————————————————————————
目标检测、实例分割和人体姿态估计是计算机视觉中最核心的密集预测任务。在边缘部署场景中,这些任务长期由 YOLO 系列等基于 CNN 的架构把持,原因很直接:CNN 架构天然适合构建多尺度特征金字塔,而且在小参数量下有成熟的设计经验。
ViT 近年来在大模型上展现出了强大的表征能力,DINOv2、DINOv3 等自监督预训练方法进一步释放了这种潜力。然而,当模型缩小到边缘可用的尺寸时(如 ViT-Tiny,约 5-10M 参数),情况就不同了。论文中的实验直接说明了这一点:
ViT-T + ImageNet-21K 监督预训练:42.2 AP
ECViT-T 随机初始化:46.6 AP
ECViT-T + DINOv3 通用蒸馏:50.7 AP
ECViT-T + 任务专用蒸馏(EdgeCrafter 方案):51.7 AP
一个值得注意的现象是,对于紧凑 ViT,ImageNet-21K 的监督预训练甚至不如从头训练。这与此前 Ghiasi et al.(2021)和 Zoph et al.(2020)的观察一致:通用监督预训练在小模型上的收益有限。EdgeCrafter 的核心观点是,紧凑 ViT 的性能瓶颈不在于架构本身,而在于任务特定表征学习的不足。
二、EdgeCrafter:从教师准备到任务训练的三阶段 pipeline
———————————————————————————————————————————
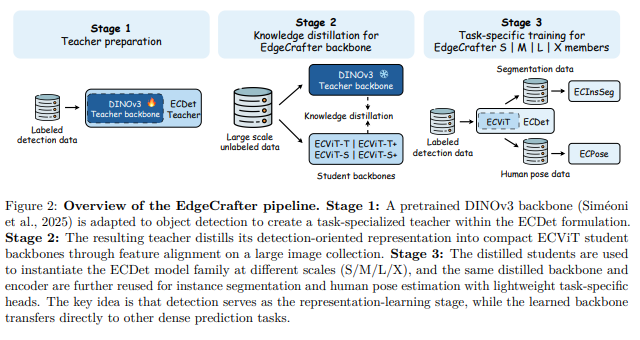
EdgeCrafter 的整体流程分为三个阶段(Figure 2):
阶段一:教师准备(Teacher Preparation)。 将预训练的 DINOv3 模型适配为目标检测器,使其成为一个与下游学生任务直接对齐的"任务专用教师"。论文使用两种教师规模:ECTeacher-S(基于 DINOv3-S)供 S 模型使用,ECTeacher-B(基于 DINOv3-B)供 M/L/X 模型使用。
阶段二:知识蒸馏(Knowledge Distillation)。 通过特征对齐蒸馏将教师的检测表征注入紧凑的 ECViT 学生骨干。蒸馏目标刻意保持简单:学生最后一层 Transformer block 的输出通过一个线性适配器映射到教师特征维度,然后与教师最后两层的特征做 L2 对齐。蒸馏使用 ImageNet-1K 和 COCO 的图像,并采用 LARS 优化器和 1 个 register token。
阶段三:任务训练(Task-Specific Training)。 蒸馏完成的 ECViT 骨干用于构建四种规模的检测器 ECDet(S/M/L/X),同一骨干和编码器直接复用于实例分割模型 ECInsSeg 和姿态估计模型 ECPose,仅更换任务专用的预测头。所有下游模型仅使用 COCO 标注训练。
ECViT 骨干设计
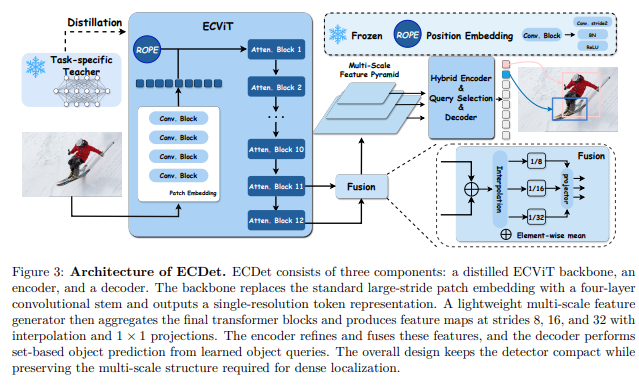
ECViT 的设计针对边缘密集预测做了两处关键改动:
-
卷积 stem 替代标准 patch embedding。 标准 ViT 使用单个 16x16 大步长投影,虽然对分类有效,但会丢弃密集定位所需的精细空间细节。ECViT 使用 4 个 3x3 卷积(stride 2)逐步扩大感受野,保留局部结构信息。
-
轻量多尺度特征金字塔。 ViT 本身不产生层级特征。ECViT 将最后两个 Transformer block 的输出取平均,得到 stride 16 的特征图,再通过双线性插值和 1x1 卷积投影生成 stride 8、16、32 三个尺度的特征金字塔,避免了 FPN 等重量级模块的开销。
检测器架构(ECDet)
ECDet 由三部分组成:ECViT 骨干、RT-DETR 风格的编码器(含 AIFI 自注意力和 CCFF 跨尺度融合)、以及 DETR 风格的解码器(4 层解码器、300 个查询)。四种规模的模型配置如下(Table 1):
| 模型 | ECViT 变体 | Embed Dim | Attention Heads | FFN Ratio | 教师 | 编码器 Hidden Dim | 解码器 FFN Dim |
|---|---|---|---|---|---|---|---|
|
S |
T |
192 |
3 |
4 |
ECTeacher-S |
192 |
512 |
|
M |
T+ |
256 |
4 |
4 |
ECTeacher-B |
256 |
1024 |
|
L |
S |
384 |
6 |
4 |
ECTeacher-B |
256 |
1024 |
|
X |
S+ |
384 |
6 |
6 |
ECTeacher-B |
256 |
2048 |
姿态估计(ECPose)与实例分割(ECInsSeg)
ECPose 直接复用蒸馏得到的 ECDet 骨干和编码器,将检测头替换为姿态预测头。参考 DETRpose 的设计,解码器维护一组固定的 person query,每个 query 包含一个实例 token 和 K 个关键点 token,通过自注意力和可变形交叉注意力同时预测人体实例及其关键点。
ECInsSeg 同样复用 ECDet 的骨干、编码器和解码器,仅在检测头之外增加一个轻量的 query-based mask head。mask head 基于 stride 8 的特征图,通过深度可分离卷积和 MLP 生成像素级嵌入,再与解码器查询的投影做点积得到 mask logits。
三、实验结果:三个任务全面对标 YOLO 和 DETR 系列
———————————————————————————————————————————
所有实验在 COCO val2017 上评估,延迟在 NVIDIA T4 GPU(FP16,batch size 1)上使用 TensorRT v10.6 测量。
目标检测(Table 2)
| 模型 | 额外数据 | 参数量 | GFLOPs | 延迟 (ms) | AP |
|---|---|---|---|---|---|
|
YOLO26-S |
- |
10M |
21 |
2.59 |
47.8 |
|
RT-DETRv4-S |
- |
10M |
25 |
3.60 |
50.7 |
|
D-FINE-S |
- |
10M |
25 |
3.60 |
48.5 |
| ECDet-S | - | 10M | 26 | 5.41 | 51.7 |
|
YOLO26-M |
80 ep O365 |
20M |
68 |
4.54 |
52.5 |
|
RT-DETRv2-M |
- |
31M |
92 |
6.91 |
49.9 |
| ECDet-M | - | 18M | 53 | 7.98 | 54.3 |
|
YOLO26-L |
60 ep O365 |
25M |
86 |
6.20 |
51.3 |
|
D-FINE-L |
- |
31M |
91 |
8.10 |
54.0 |
| ECDet-L | - | 31M | 101 | 10.49 | 57.0 |
|
RT-DETRv4-X |
O365 |
31M |
97 |
10.47 |
57.0 |
|
D-FINE-X |
- |
62M |
202 |
12.90 |
55.8 |
| ECDet-X | - | 49M | 151 | 12.70 | 57.9 |
关键发现:
ECDet-S 仅用 COCO 标注,以 10M 参数达到 51.7 AP,比同参数量的 YOLO26-S(47.8 AP)高 +3.9 AP,也超过 RT-DETRv4-S(50.7 AP)+1.0 AP。
ECDet-M 以 18M 参数达到 54.3 AP,超越使用了 Objects365 预训练的 YOLO26-M(52.5 AP)+1.8 AP。
ECDet-X 达到 57.9 AP,在不使用额外数据的模型中位列前列,与使用 Objects365 的 RT-DETRv4-X(57.0 AP,需额外 58 epochs 预训练)相比高 +0.9 AP。
人体姿态估计(Table 3)
| 模型 | 额外数据 | 参数量 | GFLOPs | 延迟 (ms) | AP |
|---|---|---|---|---|---|
|
YOLO11-Pose-S |
- |
9.9M |
23.2 |
4.54 |
58.9 |
|
DETRPose-S |
O365 |
11.5M |
33.1 |
5.12 |
67.0 |
| ECPose-S | - | 9.9M | 30.4 | 5.54 | 68.9 |
|
YOLO11-Pose-M |
- |
20.9M |
71.7 |
6.65 |
64.9 |
| ECPose-M | - | 19.8M | 62.8 | 9.25 | 72.4 |
|
YOLO11-Pose-L |
- |
26.2M |
90.7 |
7.95 |
66.1 |
|
DETRPose-L |
O365 |
62.8M |
107.1 |
11.31 |
72.5 |
| ECPose-L | - | 34.3M | 111.7 | 11.83 | 73.5 |
|
YOLO26-Pose-X |
O365 |
57.6M |
201.7 |
11.05 |
71.6 |
|
DETRPose-X |
O365 |
73.3M |
239.5 |
18.89 |
73.3 |
| ECPose-X | - | 50.6M | 172.2 | 14.31 | 74.8 |
关键发现:
ECPose-S 以 9.9M 参数达到 68.9 AP,大幅超越 YOLO11-Pose-S(58.9 AP)+10.0 AP,也超过使用 Objects365 的 DETRPose-S(67.0 AP)+1.9 AP。
ECPose-X 达到 74.8 AP,超越依赖 Objects365 预训练的 YOLO26-Pose-X(71.6 AP)+3.2 AP,且参数量更少(50.6M vs 57.6M)。
检测蒸馏得到的表征不仅适用于框预测,也能有效迁移到细粒度关键点定位。
实例分割(Table 4)
| 模型 | 额外数据 | 参数量 | GFLOPs | 延迟 (ms) | AP |
|---|---|---|---|---|---|
|
YOLO11-Seg-S |
- |
10.1M |
35.5 |
7.20 |
37.8 |
|
RF-DETR-Seg-S |
O365+SAM2 |
33.7M |
70.6 |
4.81 |
43.1 |
| ECInsSeg-S | - | 10.3M | 33.1 | 6.96 | 43.0 |
|
YOLO11-Seg-M |
- |
22.4M |
113.2 |
9.18 |
41.5 |
|
RF-DETR-Seg-M |
O365+SAM2 |
35.7M |
102.0 |
6.35 |
45.3 |
| ECInsSeg-M | - | 20.1M | 64.2 | 9.85 | 45.2 |
|
RF-DETR-Seg-L |
O365+SAM2 |
36.2M |
151.1 |
9.42 |
47.1 |
| ECInsSeg-L | - | 33.6M | 110.8 | 12.56 | 47.1 |
|
RF-DETR-Seg-X |
O365+SAM2 |
38.1M |
269.0 |
15.42 |
48.8 |
| ECInsSeg-X | - | 49.9M | 168.1 | 14.96 | 48.4 |
关键发现:
ECInsSeg-S 仅 10.3M 参数即达到 43.0 AP,超越 YOLO11-Seg-S(37.8 AP)+5.2 AP,接近使用 Objects365 + SAM2 伪标签的 RF-DETR-Seg-S(43.1 AP),但后者参数量是前者的 3 倍以上(33.7M vs 10.3M)。
ECInsSeg-L 以 33.6M 参数达到 47.1 AP,与 RF-DETR-Seg-L(47.1 AP)持平,但后者依赖 Objects365 + SAM2 额外监督。
检测蒸馏的表征同样能有效支持 mask 预测,无需为分割任务单独设计骨干。
四、消融实验:蒸馏配方中什么最关键?
———————————————————————————————————————————
论文通过 Table 5-9 系统分析了蒸馏和架构设计中的关键选择,以下消融均基于 ECViT-T+ 骨干、评估 ECDet-M 的检测 AP。
教师设计与蒸馏数据(Table 5)
| 教师架构 | COCO 预训练 | 蒸馏数据集 | AP (%) |
|---|---|---|---|
|
DINOv3-S |
是 |
IN-1K + COCO |
54.0 |
| DINOv3-B | 是 | IN-1K + COCO | 54.3 |
|
DINOv3-L |
是 |
IN-1K + COCO |
52.6 |
|
DINOv3-B |
否 |
IN-1K + COCO |
53.5 |
|
DINOv3-B |
是 |
IN-1K |
54.1 |
三个关键结论:
教师容量需与学生匹配,DINOv3-B 最优(54.3 AP),过大的 DINOv3-L 反而下降至 52.6 AP,表明过强教师会造成学生无法有效吸收的表征鸿沟。
教师需经过任务适配,未经 COCO 检测适配的 DINOv3-B 仅 53.5 AP,适配后提升 +0.8 AP。
蒸馏数据中加入 COCO 有益,从纯 IN-1K(54.1 AP)到 IN-1K + COCO(54.3 AP)提升 +0.2 AP。
特征对齐深度(Table 6)
对齐学生最后 1 层与教师最后 2 层(即 one-to-many 对齐)在所有 ECViT 变体上表现最稳定。例如 ECViT-T+ 上,对齐教师 2 层达到 54.3 AP,仅对齐 1 层降至 53.6 AP。对齐 3 层在 ECViT-T+ 上达到 54.6 AP,但在更大的 ECViT-S 和 ECViT-S+ 上不再有优势(56.9 vs 57.0, 57.5 vs 57.9),因此最终选择对齐 2 层作为默认配置。
优化器与 register token(Table 7)
-
LARS 优于 AdamW:54.3 AP vs 54.0 AP,LARS 更适合紧凑学生对齐强教师特征。
-
1 个 register token 最优:无 register 降至 53.8 AP,2 个或 4 个 register 均为 54.2 AP,无额外增益。
Patch Embedding 设计(Table 8)
| Patch Embedding | 参数量 (M) | GFLOPs | AP | AP_S |
|---|---|---|---|---|
|
Vanilla (16x16) |
19.0 |
50.7 |
53.5 |
33.7 |
| ConvStem (d=1) | 19.2 | 53.1 | 54.3 | 35.9 |
|
ConvStem (d=2) |
19.2 |
53.1 |
53.0 |
33.7 |
|
ConvStem (d=3) |
19.2 |
53.1 |
53.6 |
33.2 |
卷积 stem(d=1)比标准 patch embedding 提升 +0.8 AP,小物体上提升 +2.2 AP_S。增大 dilation rate 反而降低性能,说明适度的感受野比过大的感受野更适合密集定位。
特征融合策略(Table 9)
取最后两层的均值融合(Mean, L_{10→11})以 19.2M 参数、53.1 GFLOPs 达到 54.3 AP,是最佳精度-效率平衡。拼接(Concat)和 STA 融合模块虽然也能达到类似精度,但分别增加了参数(19.5M)或计算量(54.5 GFLOPs),无一致性优势。
五、总结与思考
———————————————————————————————————————————
EdgeCrafter 的核心贡献在于提出了一条清晰的路径:通过任务专用蒸馏将大型 ViT 基础模型的检测能力压缩进紧凑骨干,配合面向边缘的架构设计(卷积 stem + 轻量多尺度特征),让紧凑 ViT 在边缘密集预测任务上达到与 CNN 模型可比甚至更优的精度-效率平衡。
从实验结果看,这一方案有几个值得关注的特点:
统一表征的跨任务迁移能力。 以检测为中心蒸馏得到的骨干表征,在姿态估计和实例分割上均不需要重新设计或重新蒸馏,仅需更换轻量预测头。这意味着在边缘设备上部署多任务系统时,骨干可以共享,降低整体参数和存储开销。
仅用 COCO 标注即可与依赖额外数据的方案竞争。 ECDet、ECPose、ECInsSeg 全系列均仅使用 COCO 标注训练,而许多对比方法(如 YOLO26-Pose-X、RF-DETR-Seg)需要 Objects365 预训练甚至 SAM2 伪标签。这对标注成本和数据获取有现实意义。
教师-学生容量匹配的实验发现。 消融实验表明,过大的教师(DINOv3-L)反而会降低蒸馏效果,这为后续紧凑模型的蒸馏方案选择提供了实证参考。
不过也应注意到,ECDet 系列的延迟并不总是同类中最低的(如 ECDet-S 的 5.41ms 对比 YOLO26-S 的 2.59ms),这主要受限于当前 ViT 架构在推理引擎上的优化程度。论文也坦承这一点,并指出边缘部署的约束不仅是延迟,还包括参数量和存储预算,而紧凑 ViT 在这些维度上的优势仍然显著。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 32
32 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)