Interpreting Attention Heads for Image-to-Text Information Flow in Large Vision–Language Models阅读笔记
一、论文简介
|
期刊: (发表日期: 2025-09-22) 论文链接:https://arxiv.org/abs/2509.17588 |
|
摘要翻译: 大型视觉语言模型 (LVLMs) 通过一系列 'Attention heads'(注意力头)将信息从图像传输到文本,从而回答视觉问题。虽然这种图像到文本的 'Information flow'(信息流)是视觉问答的核心,但由于众多 'Attention heads' 同时运作,其底层机制仍然难以解释。为了应对这一挑战,我们提出了一种受组件归因方法启发的 'Head attribution'(注意力头归因)技术,以识别在信息传输中发挥关键作用的 'Attention heads' 之间的一致模式。 利用 'Head attribution',我们调查了 LVLMs 如何依赖特定的 'Attention heads' 来识别和回答关于图像中主要对象的问题。我们的分析揭示了 'Attention heads' 的一个特定子集促进了图像到文本的信息流。值得注意的是,我们发现这些头的选择是由输入图像的语义内容(Semantic content)而不是其视觉外观(Visual appearance)所决定的。 我们进一步在 'Token' 级别检查了信息流,并发现: (1)文本信息在接收图像信息之前,首先传播到与角色相关的 'Tokens'(Role-related tokens)和最终的 'Token'; (2)图像信息被嵌入在与对象相关的和背景的 'Tokens' 中。 我们的工作提供了证据,证明图像到文本的信息流遵循一个结构化的过程,并且在 'Attention-head' 级别的分析为理解 LVLMs 的机制提供了一个极具潜力的方向。 |
二、核心问题
在多模态大语言模型(LVLMs)中,如何打破跨模态 'Information flow' 的“黑盒”,精准定位并解释究竟是哪些底层的 'Attention heads' 负责将缺乏显式语义的图像 'Soft prompts' 结构化地传递并转化为最终的文本输出?
三、思路
作者首先提出大型视觉语言模型(LVLM)在广泛的视觉和语言任务中取得了显著的成功,引出解释LVLM。然而解释LVLM,面临着许多挑战,作者提到了以前的工作主要集中在 'Layer level'(层级)并未探索特定 'Attention heads'(注意力头)在促进这种信息传递中的作用。
于是,作者试图识别负责图像到文本 'Information flow'(信息流)的关键 'Attention heads'(注意力头),识别后,将通过追踪信息起源的视觉 'Tokens'(词元)和接收信息的语言 'Tokens',来分析这些 'Attention heads' 是如何介导图像信息传递的。
首先作者最开始为了确定哪些注意头对图像到文本信息流重要,做了消融单个头的实验。在做消融实验时,作者专门强调使用基线平均值,而不是粗暴置零。因为后者其实对于模型来说是一个异常数据,模型容易出现异常反应,反而前者则是平庸的无特征数据,可以起到消融实验的作用。但是发现logit的差异并不是很明显。基于此作者假设,图像到文本的信息流是一个涉及多个注意力头的分布式过程。在这个假设下,消融单个头带来的logit差异不明显也可以解释,即自我修复机制,其他头部可以通过自我修复机制来补偿被消融的头部。
为了更准确的评估每个头在图像到文本信息流的贡献,作者采取多头同时随机消融。作者定义一个二元状态向量 ,其中
是层数,
是每层的头数。向量中的每个元素代表对应的注意力头是保持完整(1)还是被消融(0)。通过大量的随机消融组合及其对应的输出logit
![]() ,作者拟合了一个简单的线性回归模型来预测logit:
,作者拟合了一个简单的线性回归模型来预测logit:
![]()
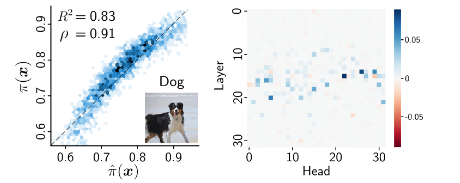
左图是真实的logit和预测的logit
![]() ,右图是每个 注意力头 的 Attribution coefficients(归因系数)
,右图是每个 注意力头 的 Attribution coefficients(归因系数)。每个系数代表了相应分量头对模型预测结果的贡献程度。
可以发现该模型可以准确地预测logit,即可以准确地估计每个注意头部的贡献。
后面作者分别从以下两个角度证明被估计贡献大的注意力头确实贡献大:
(1)忠实度(Faithfulness):定义为 ,衡量所选头在多大程度上能解释模型的实际性能。
(2)完备性(Completeness):定义为 ,评估所选头是否捕捉到了所有关键头。换言之,如果剩余的其他头可以补偿(Compensate)已选头的功能,则该方法的完备性会受损。理想的忠实度(即模型实际性能)应为
,理想的完备性应为
。
通过逐步激活(Progressive Activation)的因果实验,验证归因系数 是否真正识别了不可或缺的注意力头。
四、背景知识
(一)logit
1.logit是什么
在神经网络的最后一层(全连接层),模型会输出一个向量。对于一个分类任务(例如判断图片里是“猫”、“狗”还是“鸟”),每一个类别都会对应一个实数值。这个原始的、范围在 之间的实数值就是 Logit。
2.为什么用logit
因为softmax是一个会放大大的。缩小小的过程。举个例子,模型输出狗的分数由于消融实验从20下降到12,但是由于其他类别的分数都太小,所以softmax之后,其实输出狗的百分比变化并不大,因此很难观察到模型消融所带来的影响和变化,所以选用logit。
(二)忠实度和完备性
1.忠实度
解释方法找出的“重要特征/组件”,是否真的是驱动模型做出当前预测的真正原因,用来证明“你是真的重要”。
-
操作逻辑:假设归因算法告诉你,网络中的 Head 5 和 Head 12 是输出“猫”的最关键注意力头。我们在验证时,只保留这两个头,强行关闭(或屏蔽)其他所有被认为不重要的头。
-
评估标准:观察此时模型的预测输出得分(如 Logit)是否能逼近原始完整模型的输出。
-
学术直觉:如果只激活这两个头,模型依然能以极高的置信度输出“猫”,说明你的归因算法没有撒谎,它找出的确实是核心逻辑——这就是高忠实度。反之,如果模型输出变成了“狗”,说明归因算法找出的特征根本不能支撑原有的预测,解释是不忠实的。
2.完备性
解释方法找出的“重要特征/组件”,是否包含了维持该预测所需的全部信息,是否存在遗漏,用来证明“除了你,别人都不行”。
-
操作逻辑:这是一种反向验证。我们剔除掉被归因算法评为“最重要”的 Head 5 和 Head 12,而保留其余所有被认为“不重要”的注意力头。
-
评估标准:观察模型的预测性能是否会产生灾难性的下降(即相关 Logit 趋近于 0)。
-
学术直觉:如果剔除了最核心的头,模型依然稳稳地输出“猫”,这就说明 Head 5 和 Head 12 并不能涵盖所有的决策逻辑。系统内一定存在其他冗余或替代通路(例如 Head 18 也能识别“猫”,但被你的算法漏掉了)。此时,该归因方法就是不完备的。
五、思考
读完这篇论文,感觉这篇论文很扎实,因为作者在提出“头部归因(Head Attribution)”方法时,并没有直接把公式拍在读者脸上,而是构建了一个坚不可摧的逻辑链条:
第一步:证伪现有范式 (Falsifying the Baseline)。大家习惯用单一头部消融(Single Head Ablation,即直接关掉某个 Attention Head)来找关键头 。但作者首先通过实验证明,在 MLLM 中这种方法失效了,因为没有任何一个单一头部的缺失会导致 Logit 出现显著下降 。这引出了模型具有“分布式信息流”和“自我修复(Self-repair)”机制的假设 。
第二步:顺理成章地提出新方法 (Proposing the Method)。既然一次关一个头没用,那就必须同时干预多个头。作者顺势将“组件归因(Component Attribution)”技术引入,用线性回归模型来评估多头协同的贡献 。
第三步:建立黄金验证标准 (Rigorous Validation)。你提出一个新系数,凭什么说它比别的指标好?作者通过引入因果推断中的忠实度(Faithfulness)和完备性(Completeness) ,证明了按
选出的头,确实比随机选、按注意力权重选、按因果效应选都要高效 。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)