发文快准狠!强化学习+卡尔曼滤波,这套组合拳竟成顶会发文录用秘籍
该方向在机器人、自动驾驶、无人机、金融等对状态估计精度要求高的领域应用广泛,顶会成果频出,如登顶 Nature 封面的 Swift 系统、一区准确率近 100% 的 AdaRL-MD 模型。
若目标为二三区,可聚焦具体应用问题,如用卡尔曼滤波作为 RL 的状态估计器,解决噪声环境下的性能下降,在视觉伺服、机器人定位等任务中展示比纯 RL 更高的稳定性和收敛速度。
若冲击高区,则需深入理论探索,如结合部分可观马尔可夫决策过程、卡尔曼滤波与值函数/策略更新等。
为帮大家紧跟前沿、激发灵感,我整理了 12 种创新思路,含原文与源码,一起来看!
发文快准狠!强化学习+卡尔曼滤波,这套组合拳竟成顶会发文录用秘籍
Kalman Filter Enhanced Group Relative Policy Optimization for Language Model Reasoning
关键词: 大语言模型, 强化学习, 卡尔曼滤波, 奖励估计, 数学推理
研究方法
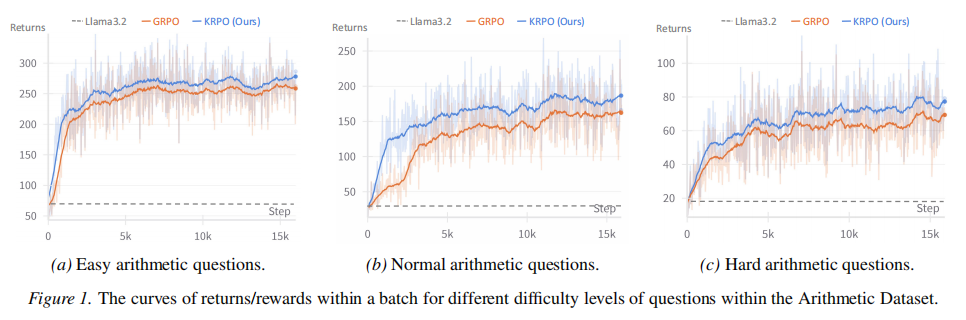
针对现有GRPO(Group Relative Policy Optimization)算法在处理复杂推理任务时,因简单使用“组均值”作为基线而导致优势函数估计方差过大、奖励信号不准确的问题,论文提出了KRPO。该方法不依赖额外的价值网络,而是引入轻量级的一维卡尔曼滤波器,将环境奖励视为含噪观测值,动态估计潜在的真实奖励基线及其方差,实现更自适应的优势归一化。

论文创新点
- 提出/构建了 KRPO算法,利用卡尔曼滤波动态估计潜在奖励基线,实现了比传统组均值更精准的优势计算。
- 创新地引入/设计了 基于滤波后验方差的不确定性归一化机制,解决了奖励信号剧烈波动导致的训练不稳定问题。
- 通过 非参数化的滤波方法,在不增加任何模型参数和额外训练开销的情况下,显著提升了策略优化效率。
- 首次将 卡尔曼滤波与GRPO结合应用于数学推理,验证了其在复杂任务上大幅超越GRPO和PPO的性能。
论文链接: https://arxiv.org/abs/2505.07527
KARL: Kalman-Filter Assisted Reinforcement Learner for Dynamic Object Tracking and Grasping
关键词: 机器人抓取, 动态物体追踪, 手眼系统, 强化学习, 状态估计
研究方法
针对“手眼系统”(Eye-on-Hand)在抓取快速移动物体时,常因物体移出视野或被遮挡导致追踪丢失(Tracking Loss)从而任务失败的问题,论文提出了KARL框架。该框架在视觉感知模块与RL控制策略之间嵌入了一个扩展卡尔曼滤波(EKF)层。当视觉追踪失效时,EKF层能根据历史信息持续输出物体位姿的不确定性估计,引导RL策略在“盲区”中也能预判物体轨迹。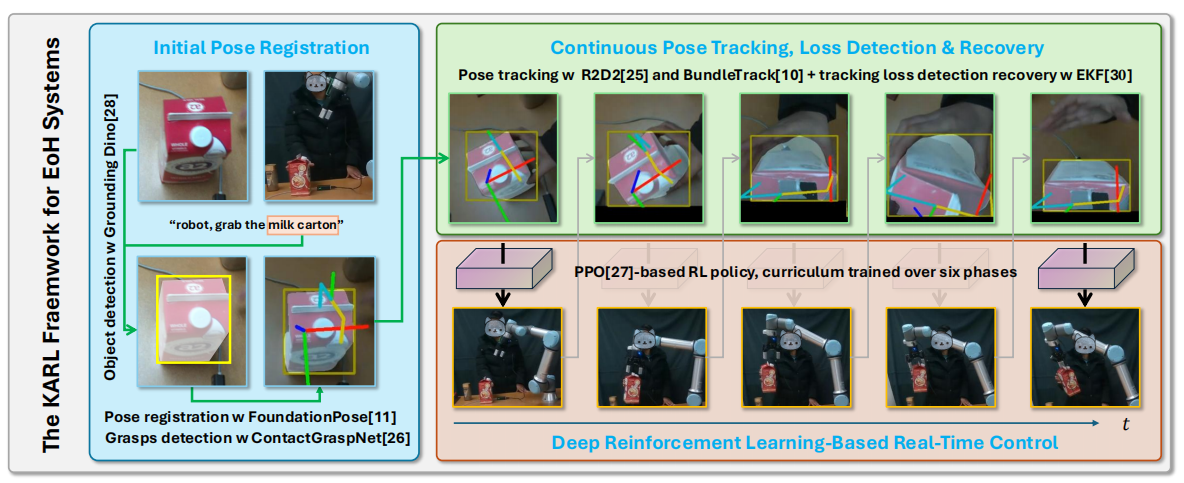
论文创新点
- 提出/构建了 包含EKF中间层的KARL框架,实现了在视觉追踪丢失情况下对动态物体的持续位姿估计与控制。
- 创新地引入/设计了 6阶段强化学习课程与重试机制,解决了单一策略难以应对高速物体及抓取滑脱的难题。
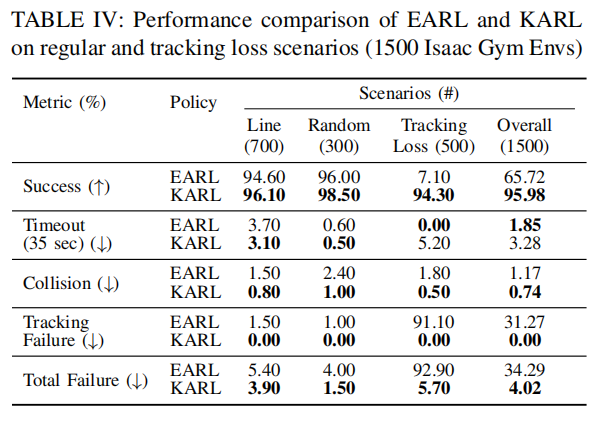
- 通过 结合EKF预测与不确定性感知策略,将动态抓取的有效工作空间扩大了近2倍,机器人执行速度提升20%。
- 首次将 状态估计恢复机制与端到端RL抓取结合,验证了在物体移出视野时仍能保持94.3%的抓取成功率。
论文链接: https://arxiv.org/abs/2506.15945

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 10
10 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)