智能体论文:Performance Comparison of IBN orchestrationusing LLM and SLMs 翻译
原文网址:[2603.06647] Performance Comparison of IBN orchestration using LLM and SLMs
免责声明:包括后面的名词解释都是AI写的
原文翻译:
摘要
5G和6G网络的演进正在推动全自主网络管理的发展,将基于意图的网络(IBN)置于这一转型的中心。本文介绍了一种用于5G和6G IBN编排的新型框架,该框架利用有状态的、分层的多智能体架构,使用SLM(小型语言模型)和LLM(大型语言模型)来实现全自动化。这两个模型都在翻译准确性(使用BLEU、METEOR和ROUGE-L等指标)以及计算复杂度方面进行了评估。实验结果表明,两种模型表现出相似的准确性。然而,结果显示,SLM可以将IBN生命周期的整体完成速度提高20%。
关键词——IBN,编排,SLM,LLM
引言
移动网络技术的快速演进(特别是在5G的驱动下)正在赋能多样化的垂直应用。这些应用包括增强型移动宽带(eMBB)、超可靠低延迟通信(URLLC)和海量机器类型通信(mMTC)。同时,对由OTT(Over-The-Top)平台提供的并发服务的需求不断增加 [1]。不断扩大的、多样化的客户群体要求达到新的网络管理水平。服务定制和资源分配等能力对于处理复杂的、异构的服务需求,同时优化持续的容量利用率至关重要[1][2]。然而,(工业)物联网和关键基础设施中的传统网络管理主要依赖于基于规则的、不频繁的配置更改[3]。传输网络中的这种僵化在大型电信系统中很常见。这通常被严格的安全和监管合规需求(如满足FISMA和NIST标准)所证明是合理的。这种僵化严重限制了适应动态性的能力[3][4]。为了克服这些限制,网络工程领域拥抱了软件化。这一趋势催生了软件定义网络(SDN)及其衍生技术——基于意图的网络(IBN)[1]。IBN通过简化网络管理代表了一种转变,它将高层用户目标或意图转化为可执行的网络配置。这减少了对详细手动步骤的需求。高度可编程的网络现在使用基于RESTful API的交互来简化配置和部署[1][4][5]。建立在可编程性和抽象性之上,最近的网络管理研究转向了先进的人工智能(AI)解决方案。这些有助于自动化和增强编排[2]。生成式AI(GenAI)和大型语言模型(LLMs)现在提供了一个将自然语言需求转化为文本网络配置的机会。这使得复杂的IBN部署成为可能[1][2]。LLM在推理、上下文理解和生成类似人类的文本方面表现出色。这使它们成为解释用户意图的强大工具[6][7]。它们的能力推动了研究界对基于LLM的网络编排的兴趣[1][2]。然而,LLM的随机性使其难以训练。它们可能难以提供可靠控制和基础设施配置所需的一致、稳健的结果[8]。为了解决这一可靠性差距,该领域现在正转向智能体AI(Agentic AI)[1]。智能体AI使用分布式智能,部署被称为智能体的受限自主学习器。在多智能体系统中,专门的智能体分解意图、计划行动,并使用外部工具可靠地执行任务。本文介绍了一种用于自主5G/6G IBN编排的新型分层多智能体框架。它集成了专门经过LoRA微调的小型语言模型(SLM)和LLM。本文还对它们的准确性和时间复杂度进行了实验评估。结果表明,SLM实现了与LLM相当的准确性,同时将IBN生命周期完成速度提高了约20%,为网络自动化提供了一条有效的途径。
本文的其余部分结构如下。第二节概述了网络自动化中的智能体AI,重点关注SLM和LLM的贡献。第三节介绍了我们有状态的多智能体架构以及各智能体的角色。第四节详细说明了实验设置、SLM微调和智能体性能评估。第五节总结并展望了未来的工作。
网络自动化中智能体AI的最新进展
由智能体AI增强的IBN引入了分布式多智能体系统,其中由LLM驱动的智能体分解用户意图,并通过基础设施即代码(IaC)调整配置[1]。协作智能体处理多租户6G网络中跨业务、服务和网络平面的协商和冲突解决[9],而像ChatNet这样经过领域适应的LLM则桥接了自然语言和网络特定语言,整合外部工具进行容量规划和策略翻译[10]。这些系统提供了网络具身化的智能,用于自动问答、代码生成、事件管理,以及跨移动、车载、云和边缘网络的AI驱动的监控、规划、部署和优化[11]。
LLM精通文本生成和复杂推理,但受到大参数规模和计算需求的困扰。SLM通过提供更低的延迟和降低的成本来解决这些局限性,使其成为边缘设备和移动平台等环境的理想选择 [12]。虽然知识蒸馏(KD)是通过训练较小的模型来复制较大的“教师”LLM的“软标签”输出从而创建SLM的常用方法 [13],但它需要大量的GPU计算能力,并且存在传播教师固有的偏见和幻觉的风险。相比之下,我们在实际数据集而不是近似数据集上训练SLM。这种直接的专业化使SLM能够在其目标任务上实现更高的准确性 [14]。
在网络领域,LLM正在改变5G和6G网络管理的自动化。用于流量预测和异常检测的传统AI/ML网络解决方案缺乏泛化能力,并且难以处理日志和遥测等非结构化数据[10][15]。最近的调查提出了一种统一的LLM工作流程,包含任务定义、数据表示、提示工程、模型演进、工具集成和验证[16]。像NetConfEval这样的基准测试证明了LLM能够将高级需求转化为网络规范,生成路由算法,并以高精度配置设备[6]。
尽管先前的工作证明了由LLM驱动的智能体在网络自动化方面的潜力,但它主要强调意图翻译、提示驱动的配置或集中式编排。这并没有为跨分布式领域的结构化智能体间协作或上下文感知的知识交换定义一个标准化的框架。此外,对大型通用LLM的依赖在实时网络环境中引入了延迟和可扩展性限制。
为了解决这些差距,提出了一种分布式多智能体架构,该架构建立在专用的智能体到智能体(A2A)协议和模型上下文协议(MCP)之上,实现了专门智能体之间模块化、异步和上下文感知的协调。与依赖于知识蒸馏或提示LLM的现有方法不同,该框架利用了SLM。这些基于SLM的智能体在路由即服务(RaaS)[26]内协作,以跨异构SDN和遗留基础设施提供统一的控制平面。A2A协议、基于MCP的上下文管理、专门的SLM智能体以及RaaS集成的结合,通过实现基于意图的网络自动化,推进了现有技术水平。
提出的智能体AI网络架构
A. 多智能体架构
有状态的分层多智能体架构已经作为一种常见且有效的设计模式出现,它倾向于使用协调的专门智能体团队而不是单一模型。这种结构实现了明确的职责划分,并允许每个智能体应用特定领域的专业知识[1][3]。
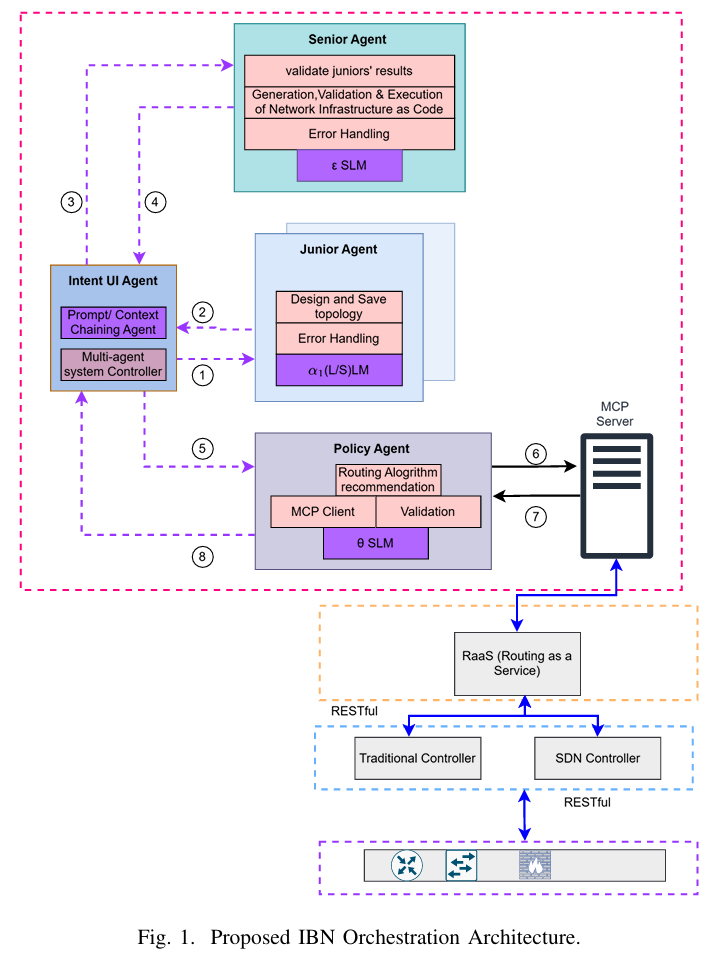
在图1中,意图UI智能体(Intent UI Agent)作为与用户和可用智能体交互的入口点。它包含一个提示链接多智能体系统控制器,该控制器通过接口检索用户意图并启动初始的提示链接序列。它将用户的请求并行发送给初级智能体(Junior Agents)以构建拓扑和服务,并间接循环回到高级智能体(Senior Agent)进行检查和验证。这个经过验证的输出被转发给策略智能体(Policy Agent),后者然后根据用户的意图建议路由协议。用于策略驱动验证的MCP客户端可以使用SLM或LLM,并与MCP服务器接口,通过RaaS元素、数据平面控制器和相关协议部署配置。
初级智能体负责解释用户需求以生成相应的网络拓扑和服务配置。这些智能体利用SLM或LLM处理请求、合成网络配置并维护相关信息的持久存储。完成后,它们的输出通过意图UI智能体中继给高级智能体进行验证。
使用两个初级智能体实现了一个受双模块冗余(DMR)启发的基于比较的故障检测模型 [17]。而不是通过多数投票掩盖故障,这种设计侧重于故障检测,非常适合正确配置有明确界定的确定性网络工程任务。两个智能体的匹配输出表明具有高置信度,而任何分歧都发出不确定性的信号并触发升级。
冲突由高级智能体(Senior Agent)解决,它充当推理比较器。它根据策略智能体(Policy Agent)的约束评估相互竞争的配置,并选择最佳解决方案,而不需要第三个投票实体。然后,高级智能体将经过验证的设计转化为确定性的基础设施代码。
仿真环境作为最终验证器。如果实例化失败,它会提供明确的失败信号,有效地充当终极的冗余伙伴。通过验证、错误处理和代码生成,高级智能体确保最终网络配置的正确性和可靠性。
策略智能体被分配用来分析网络拓扑以进行配置验证,并根据从MCP服务器获取的实时网络状态数据生成智能路由建议。MCP服务器保持与RaaS组件以及底层传统和SDN控制器的连接。最后,该系统解决了常用于AI系统安全和优化的“人在回路”(Human-in-the-Loop, HITL)策略的普遍依赖问题[1][19]。虽然承认HITL在创造性或敏感操作中的价值[20],但我们的方法缓解了重复性任务中人为干预造成的瓶颈。
高级智能体负责确保网络基础设施配置的正确性和可靠性。它验证初级智能体的拓扑生成结果,并生成适当的拓扑权重以指导网络优化决策。高级智能体实施错误处理,并将网络基础设施生成、验证和部署为可执行代码。
RaaS通过分布式控制平面跨SDN和传统IP域提供统一路由。特定领域的控制器(SDN 通过 OpenFlow,IP 路由器通过 SSH)将本地拓扑聚合成一个全局网络图。RaaS服务器应用用户定义的路由逻辑,如SPF(RFC2328)、DUAL(RFC7868) 以及负载、可靠性和延迟等指标。跨域拓扑通过中央伪节点合并,生成的路径可以转换为SDN流表项或传统路由器的IP路由映射(Route-Maps)。
B. 消息序列
当用户通过接口提交意图请求时,意图UI智能体(Intent UI Agent)通过将请求传递给初级智能体1和初级智能体2来触发该过程。系统协同工作,生成一组初始的拓扑建议。接下来,系统进入验证阶段。高级智能体使用可配置的重试机制(最多尝试三次)启动验证。此验证过程最多进行三次迭代尝试,研究表明该配置在准确性提升与资源利用率之间取得了平衡,从而支持了这一设定[21]。如果验证通过,工作流将继续进行到网络策略系统组件。如果失败,初级智能体将生成备选的拓扑建议,并重复相同的验证过程,直到找到有效的配置或重试次数耗尽。
一旦拓扑通过初始验证,系统就会进入网络实例化阶段。在此,生成并执行配置脚本以部署所需的拓扑。然后进行第二个验证周期,同样最多尝试三次。此阶段包括收集实时拓扑数据、计算图权重、将它们与拓扑集成以及分析路由算法性能。结果决定部署是有效的还是需要进一步修改。在整个这些阶段中,系统维护详细的日志,存储所有输出和确认信息。这有助于追踪拓扑生成、验证和策略执行管道中的每一步。
性能评估
A. 实验设置
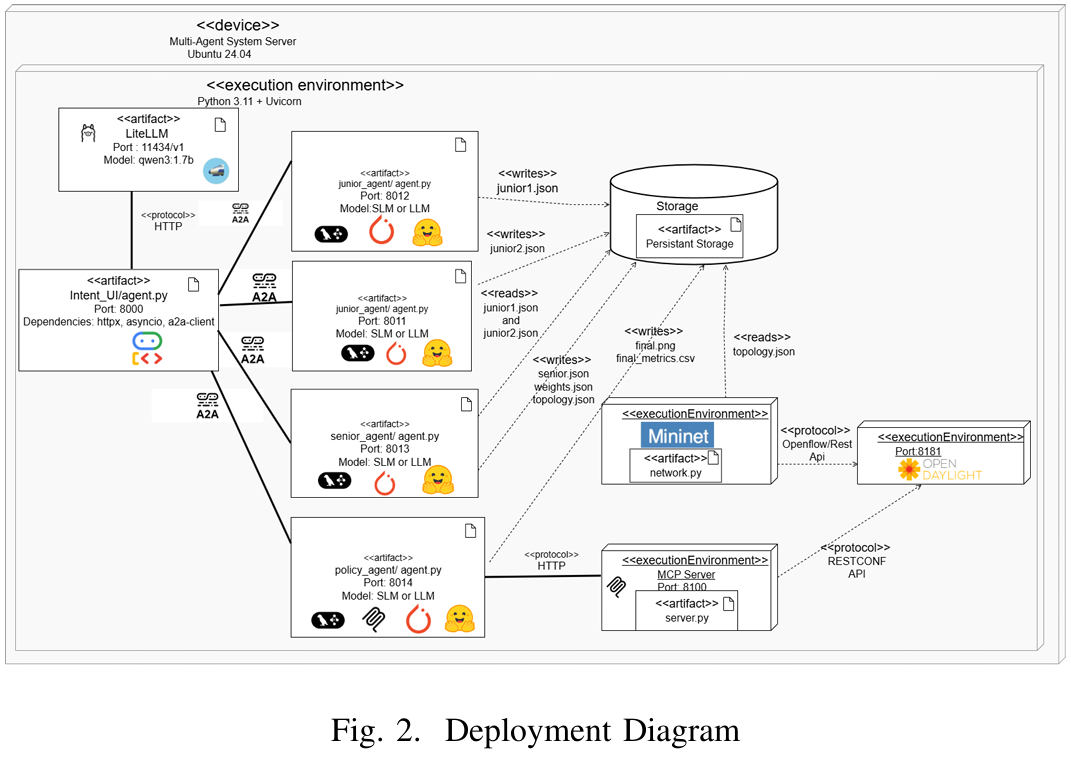
图2说明了所提出的多智能体系统,该系统使用Python和Uvicorn部署在Ubuntu服务器上。系统以一个意图UI智能体为中心,该智能体编排四个专门的智能体:两个初级智能体、一个高级智能体和一个策略智能体。中央UI智能体利用通过Ollama提供并通过LiteLLM在TCP端口8000访问的Qwen3:1.7B模型。专门的智能体结合使用SLM或LLM,具体取决于任务复杂性和性能要求。
该系统遵循分布式部署架构,每个智能体在不同的端口上运行:初级智能体在8011和8012,高级智能体在8013,策略智能体在8014。这种设计允许将智能体托管在独立的物理或虚拟服务器上,从而实现水平扩展。智能体使用A2A标准协议通过HTTP进行异步通信,并与外部服务(包括Mininet仿真和MCP服务器)进行交互。所有数据(包括智能体输出和网络配置)均以JSON格式存储和管理。
实验设置在一个GPU集群上运行,该集群包含4块GeForce RTX 2080 Ti 11 GB GDDR6显卡,搭配一台Intel(R) Core(TM) i9-9820X CPU @ 3.30GHz处理器和32 GB系统内存。
表I说明了所评估的网络场景。对eMBB和URLLC等应用强制执行服务质量(Quality-of-service)策略路由要求,而mMTC应用可以使用更简单的基于连通性的路由方案,如SPF。
B. 模型的微调
为了降低微调SLM(小型语言模型)的计算成本,本工作应用了低秩自适应(LoRA)技术,冻结预训练权重,并将可训练的低秩矩阵注入到Transformer中,以降低内存和参数要求[14]。选择TinyLlama-1.1B进行微调,因为它在同等规模的模型中表现出色,并在1至3万亿个token上进行了预训练,且采用了FlashAttention等优化技术[22]。通过提示工程(prompt engineering)将GPT-5-Nano和Mistral-Small(24B)作为比较基准使用。结果表明,在TinyLlama-1.1B上进行LoRA微调实现了相对于经过提示优化的LLM具有竞争力的准确性和效率。
C. 性能评估方法
以下小节描述了我们在对模型进行基准测试时利用的各种性能评估指标。
1) 双语评估替补 (BLEU): 为了评估LLM和SLM的性能,使用了双语评估替补(BLEU)分数(等式 1),因为它是自动机器翻译评估的标准指标[23]。
BLEU分数通过结合简短惩罚(Brevity Penalty,)(用于惩罚比参考译文短的译文)与修正的
-gram精确度(
,其中
,且权重
)的几何平均值来评估翻译质量。在我们的实验设置中,我们取
。这一核心精确度指标测量候选译文和参考译文之间词序列的重叠,使用截断机制(clipping mechanism)以避免由于过度生成的短语而导致人为的偏高分数。通过计算几何平均值,BLEU确保了对充分性(通过unigram评估词汇选择)和流畅性(通过较长的
-gram评估词序)的平衡评估。
2) 具有明确词序的翻译评估指标 (METEOR): METEOR通过首先在候选译文的unigram与一个或多个参考译文的unigram之间创建对齐来评估候选译文。这种对齐过程是灵活的,不仅适应精确的词语匹配,还适应词干形式和同义词。基于这种对齐,计算unigram的精确率()和召回率(
)[24]。METEOR分数的核心是精确率和召回率的加权调和平均值,称为
,它更加强调召回率,其计算方式如(等式 2)所示。这确保了成功捕捉参考译文内容的翻译更受青睐。
为了解释翻译的流畅性和语法正确性,引入了一个惩罚项。该惩罚项基于匹配词的连续语块(chunks)数量进行计算(等式 3)
其中是语块(chunks)的数量,定义为在候选句子和参考句子中以相同顺序出现的匹配词的连续序列;而
是候选句子和参考句子之间匹配的unigram总数。对于给定数量的匹配词而言,较少的语块数量意味着更好的词序,因此产生较小的惩罚。然后通过用此惩罚项调节
来计算最终的METEOR分数(等式 4)。
3) 面向召回率的摘要评估替补 (ROUGE): 为了评估文本生成智能体的性能,使用了ROUGE-L指标 [25],该指标基于最长公共子序列(Longest Common Subsequence, )的概念(等式 5)。该指标测量同时出现在机器生成文本(候选译文,
)和人工编写的标准文本(参考译文,
)中的最长词序列,同时保持它们的相对顺序,但不要求它们是连续的。ROUGE-L召回率量化了候选文本中成功捕获了多少参考文本的内容和结构。
选择ROUGE-L是因为与ROUGE中基于-gram的指标相比,它在灵活性和结构评估方面提供了一种平衡。虽然
-gram指标对词序不敏感或过于严格,但ROUGE-L能有效地奖励句子级别的连贯性。这一特性对于智能体来说尤为重要,因为它们必须生成在语义上合理且在逻辑上结构化的理由,而不仅仅是匹配特定的短语。
结果表明,轻量级模型在得到适当编排时,可以提供可靠且确定性的网络自动化。与主要依赖大型通用LLM(存在高计算成本和不可预测的行为)的现有方法不同,我们的工作展示了经过领域适应的SLM如何在多智能体系统中协作,从而为IBN提供具有成本效益的解决方案。
D. 时间分布
表 I 场景(LLM 和 SLM 以及网络拓扑)
| 模型 | 智能体类型 | 角色 | 拓扑选项 | 5G 服务类型 | 路由策略 |
| TinyLlama-1.1B (SLM) | 初级智能体 1 (Junior Agent 1) | 拓扑与服务分析 (Topology & Service Analysis) | 全网状 (Full-mesh), 部分网状 (Partial-mesh), 轴辐式 (Hub-and-spoke) | eMBB, URLLC, MMTC | – |
| 初级智能体 2 (Junior Agent 2) | 拓扑与服务分析 | 全网状, 部分网状, 轴辐式 | eMBB, URLLC, MMTC | – | |
| 高级智能体 (Senior Agent) | 生成拓扑与权重 (Generate topology & weights) | – | – | – | |
| 策略智能体 (Policy Agent) | 决定路由策略 (Decide routing strategy) | – | – | OSPF 或 Dual | |
| SmolLM-1.7B (SLM) | 初级智能体 1 | 拓扑与服务分析 | 全网状, 部分网状, 轴辐式 | eMBB, URLLC, MMTC | – |
| 初级智能体 2 | 拓扑与服务分析 | 全网状, 部分网状, 轴辐式 | eMBB, URLLC, MMTC | – | |
| 高级智能体 | 生成拓扑与权重 | – | – | – | |
| 策略智能体 | 决定路由策略 | – | – | OSPF 或 Dual | |
| gpt-5-nano | 初级智能体 1 | 拓扑与服务分析 | 全网状, 部分网状, 轴辐式 | eMBB, URLLC, MMTC | – |
| 初级智能体 2 | 拓扑与服务分析 | 全网状, 部分网状, 轴辐式 | eMBB, URLLC, MMTC | – | |
| 高级智能体 | 生成拓扑与权重 | – | – | – | |
| 策略智能体 | 决定路由策略 | – | – | OSPF 或 Dual | |
| mistral-small 3.1:24b | 初级智能体 1 | 拓扑与服务分析 | 全网状, 部分网状, 轴辐式 | eMBB, URLLC, MMTC | – |
| 初级智能体 2 | 拓扑与服务分析 | 全网状, 部分网状, 轴辐式 | eMBB, URLLC, MMTC | – | |
| 高级智能体 | 生成拓扑与权重 | – | – | – | |
| 策略智能体 | 决定路由策略 | – | – | OSPF 或 Dual |
表 II 跨智能体和模型的 BLEU-2 分数比较(每组N = 500)。BLEU-2 是在语料库级别计算的,赋予一元语法和二元语法相等的权重(无平滑处理)。
| 智能体类型 | 模型 | μ | σ |
| 高级智能体 (Senior Agent) | TinyLlama-1.1B(SLM) | 0.8884 | 0.08 |
| mistral-small3.2:24b | 0.8240 | 0.09 | |
| gpt-5-nano | 0.7621 | 0.10 | |
| 策略智能体 (Policy Agent) | TinyLlama-1.1B(SLM) | 0.8080 | 0.11 |
| gpt-5-nano | 0.7886 | 0.14 | |
| mistral-small3.2:24b | 0.7226 | 0.14 | |
| 初级智能体 (Junior Agent) | TinyLlama-1.1B(SLM) | 0.7886 | 0.11 |
| gpt-5-nano | 0.7679 | 0.13 | |
| mistral-small3.2:24b | 0.4507 | 0.34 |
表 III 跨智能体和模型的 METEOR 分数比较(每组N = 500)。METEOR:使用 NLTK 实现的句子级平均值。
| 智能体类型 | 模型 | μ | σ |
| 高级智能体 (Senior Agent) | TinyLlama-1.1B(SLM) | 0.8884 | 0.08 |
| mistral-small3.2:24b | 0.8240 | 0.09 | |
| gpt-5-nano | 0.7621 | 0.10 | |
| 策略智能体 (Policy Agent) | TinyLlama-1.1B(SLM) | 0.8080 | 0.11 |
| gpt-5-nano | 0.7886 | 0.14 | |
| mistral-small3.2:24b | 0.7226 | 0.14 | |
| 初级智能体 (Junior Agent) | TinyLlama-1.1B(SLM) | 0.7886 | 0.11 |
| gpt-5-nano | 0.7679 | 0.13 | |
| mistral-small3.2:24b | 0.4507 | 0.34 |
表 V、VI、VII 显示了每个智能体(高级、初级和策略)针对三个指标(BLEU、METEOR 和 ROUGE-L)的时间消耗。总体时间分布主要集中在高级智能体上,占据了 50%。这一高比例来自于验证和生成网络拓扑及其相关权重的任务。初级智能体负责识别 5G 服务类型并选择适当的拓扑,其所占比例最小,始终消耗最少的处理时间。
通过测量跨三次迭代的完整处理管道的总执行时间来评估三种语言模型的效率。实验结果表明,SLM 实现了最短的处理时长,第一次迭代记录为 58 秒,第二次迭代为 67 秒,第三次迭代为 89 秒。GPT-5-nano 的执行时间为第一次迭代 80 秒,第二次迭代 94 秒,
结论
本文展示了一项性能评估,将通用型大型语言模型(LLM)与使用 LoRA 技术微调的轻量级、特定领域的小型语言模型(SLM)进行了比较。使用 BLEU、METEOR 和 ROUGE-L 等指标的评估结果表明,在处理基于意图的网络(IBN)任务时,SLM 在准确性和时间复杂度方面均优于较大的模型。
自主网络的未来将由模块化的智能体 AI(Agentic-AI)框架来驱动,这些框架整合了适合在网络边缘进行本地部署的紧凑型、专用语言模型。这种范式的转变意味着将摆脱对通用 LLM 的依赖,转而走向一个支持实时编排和闭环自动化的、联邦式的、上下文感知的生态系统。
名词解释:
LLM和SLM的区别:
| 特性 | 大模型 (LLM) | 小模型 (SLM) |
| 参数量与算力 | 极大(数百亿到万亿)。需要庞大的 GPU 集群(数据中心)来运行。 | 较小(数亿到百亿)。可以在单台服务器、甚至手机等边缘设备上运行。 |
| 优点 | 泛化能力极强: 懂得多,推理能力强。能够理解极其复杂、模棱两可的自然语言指令。 | 轻量且极速: 推理延迟极低,计算成本低。对单一任务的响应可以说是“肌肉记忆”。 |
| 缺点 | 成本高、延迟高,且具有幻觉。由于 LLM 本质是基于概率的文字接龙,它很难保证每次输出都绝对一致。 | 认知局限: 缺乏广泛的世界知识,处理跨领域的复杂推理逻辑时容易崩溃。必须经过高质量的针对性训练(微调)才能胜任工作。 |
eMBB (Enhanced Mobile Broadband) - 增强型移动宽带
解释: 主要侧重于提供极高的数据传输速率和极大的网络容量,以满足人类对多媒体内容(如4K/8K高清视频、VR/AR)的极致体验需求。在论文中的背景: 这类业务对网络带宽要求极高,所以论文里提到,对于 eMBB,需要专门配置服务质量(QoS)策略路由,以保证网速。
URLLC (Ultra-Reliable Low-Latency Communications) - 超可靠低延迟通信
解释: 要求极低的网络端到端延迟(通常在1毫秒级别)和极高的可靠性(99.999%)。主要用于对时间和安全性要求极其苛刻的场景,比如自动驾驶、远程医疗手术、工业机器人控制。在论文中的背景: 与 eMBB 类似,需要最高优先级的 QoS 路由策略来保障其严苛的延迟要求。
mMTC (Massive Machine-Type Communications) - 海量机器类通信
解释: 侧重于在单位面积内连接海量的物联网(IoT)设备(例如每平方公里百万级连接)。这些设备通常发送的数据量很小,且对实时性要求不高,但要求电池能用很久。比如智能水表、共享单车锁、农田温湿度传感器。在论文中的背景: 论文提到,相比于前两者,mMTC 的要求没那么苛刻,所以可以使用更简单的路由方案(比如 SPF,最短路径优先算法)。
OTT (Over-The-Top)
解释: 指互联网公司越过传统的电信运营商(如移动、联通、电信),直接向用户提供的各种应用服务。典型的OTT服务包括微信、Netflix、Skype 等。在论文中的背景: 论文引言中提到,正是因为OTT平台带来的并发服务需求暴增,传统的、死板的网络管理方式不够用了,逼迫着网络必须走向更加智能、灵活的自动化管理(也就是本文研究的 IBN)。
RESTful API (Representational State Transfer Application Programming Interface)
解释: 这是一种软件架构风格,用于在网络上的两个计算机系统之间安全地交换信息。它基于 HTTP 协议(就是你上网用的那个协议),使用标准的动作(如 GET 获取、POST 新建、PUT 更新、DELETE 删除)来操作资源。在论文中的背景: 以前配置网络,网管需要一行行敲枯燥的命令行代码;现在,上层的 AI 智能体可以直接通过这种标准的 API 接口,用极其简便、自动化的方式将配置参数“推送”给底层的路由器和交换机。
基础设施即代码 (Infrastructure as Code, IaC)
这是现代云计算和网络运维的核心理念。
解释: 以前配置服务器、路由器、防火墙,工程师需要手动登录到每一台设备上的管理界面,挨个点击或者敲命令。IaC则是把这些物理设备的配置、路由策略、网络拓扑等,全部写成一段段可读的“代码文件”(比如YAML、JSON或Python脚本)。系统一旦运行这段代码,就会自动去配置成百上千台设备。在论文中的背景: 在这篇论文的架构中,那几个AI智能体(初级、高级、策略智能体)讨论完毕后,最终的高级智能体(Senior Agent)干的活儿,就是把大家的讨论结果“翻译”成这套机器能看懂的IaC代码,然后下发给底层设备自动执行。这样就彻底取代了人工敲命令的环节。
A2A 协议 (Agent-to-Agent Protocol)
解释: 以前的网络协议(比如我们前面提到的 RESTful API)主要是为了让人类的软件和机器对话设计的。但当系统里全是AI智能体(Agent)时,它们之间也需要高效沟通。A2A协议就是专门为 AI 智能体之间协同工作、交换上下文、异步通信而设计的一套标准化“语言”和规则。在论文中的角色: 图 2 的部署图里,中央的意图 UI 智能体就是通过 A2A 协议,把用户的需求精准地“派单”给下面的两个初级智能体和一个高级智能体。
MCP 协议 (Model Context Protocol, 模型上下文协议)
解释:AI模型(哪怕是微调过的SLM)本身是一个“大脑”,它虽然聪明,但它是被锁在小黑屋里的,不知道当前真实世界的网络长什么样(比如哪条网线刚好断了,哪台路由器现在最堵)。MCP协议是一种标准化的接口协议,它允许AI安全、统一地连接到外部的数据源和工具上,获取最新的“上下文(Context)”。在论文中的角色: 在论文中,负责管大局的“策略智能体(Policy Agent)”就是通过 MCP 客户端,连接到了外部的MCP服务器。通过这个协议,智能体能拿到实时的网络状态数据,从而生成最合适的路由建议,然后再把指令下发给底层的控制器。
DMR (Dual-Modular Redundancy, 双模块冗余) —— “防呆防错的双重审计”
解释: 这是航空航天和高可靠性工程里极其经典的设计。冗余(Redundancy)就是“多备一份”。双模块冗余,就是用两个完全一样的(或功能等价的)系统,同时去执行同一个任务。执行完后,把两者的结果拿来对比(Comparator)。如果结果一致,说明没问题;如果结果有分歧,说明其中一个出错了,系统就会立刻报警或移交给更高层处理,绝不盲目执行。在论文中的角色: 论文在第三节 A 部分明确提到,设计两个Junior Agent(初级智能体)就是受了DMR的启发。在网络配置这种“错一个代码可能导致大面积断网”的严苛环境里,这种“交叉验证”机制是防止AI犯蠢的最后一道防线。
HITL (Human-in-the-Loop)
解释: “人在回路”或“人机共驾”。指的是在 AI 或自动化系统做出决策到最终执行之间,必须加入人类的干预、审查或批准。这通常用于高风险、高价值或 AI 容易产生“幻觉”的场景,以确保安全底线。在论文中的背景: 在这篇论文的第 III 节提到,以前的 AI 网络系统因为不敢100%信任 AI 的输出,极其依赖人类网络工程师在最后一步敲回车确认(HITL)。这在瞬息万变的 5G/6G 网络里成了巨大的效率瓶颈。这篇论文的创新点就在于:通过多个小模型(SLM)互相交叉验证(DMR),并在仿真环境(Mininet)里先试运行一遍,从而极大程度地替代了重复性任务中的人类审查环节,实现了真正的机器全自动闭环。
SPF (Shortest Path First, 对应 RFC2328)
解释: 最短路径优先算法。这里的RFC2328 指的是大名鼎鼎的 OSPF (开放最短路径优先) 路由协议。它使用的是经典的 Dijkstra(迪杰斯特拉)算法。简单来说,网络里的每台路由器都会向全网广播自己身边的连接情况,最终每台路由器脑子里都有一张完整的“全网地图”,然后各自计算出到达目的地的“最短(或代价最小)”路径。在论文中的背景: 我们前面讲过 mMTC(海量机器通信,比如几万个水表发数据)。水表发的数据很小,也不差那一两秒。所以论文中提到,对于这类要求不高的服务,策略智能体(Policy Agent)就会给它们分配 SPF 这种简单粗暴、算力消耗低的基础路由策略,保障基本连通性就行了。
DUAL (Diffusing Update Algorithm, 对应 RFC 7868)
解释: 扩散更新算法。这里的RFC7868指的是思科开发的EIGRP (增强型内部网关路由协议)。它比普通的SPF更聪明、更进阶。DUAL算法在计算最优路径的同时,还会极其严谨地计算出一条“绝对无环路(不会死循环)的备用路径”(称为可行后继路由器)。一旦主干道断了,它不需要重新全网计算,而是毫秒级直接切换到备用路径。在论文中的背景: 在复杂的5G/6G场景中,除了要求最快,有时还要求极高的可靠性(比如自动驾驶、远程手术的URLLC 场景)。论文提到,RaaS(路由即服务)层会根据延迟、可靠性等不同指标,由 AI 决定是应用SPF 还是DUAL等更高级的算法,以满足不同业务极其苛刻的定制化需求。
RaaS (Routing as a Service)
解释: 路由即服务。传统的网络中,每台路由器都是一个独立的“孤岛”,自己算自己的路。RaaS 则是把计算网络路径的大脑抽离出来,放到云端或集中的服务器上作为一个“服务”来提供。上层应用(或者这里的 AI 智能体)只需要通过 API 告诉 RaaS “我要什么样的网络质量”,RaaS 就会结合全局视野,计算出最佳路径,并把配置下发给底层的 SDN 控制器或传统路由器。在论文中的角色: 它是连接“聪明的 AI 大脑”和“笨重的物理设备”的桥梁。AI 智能体算出高级策略后,交由 RaaS 去完成跨越传统网络和现代 SDN 网络的统一下发。
BLEU, METEOR, ROUGE
这篇论文的核心是让 AI 生成“网络配置代码/指令”(本质上是文本)。那么,怎么判断 AI 写的代码对不对呢?就需要用到自然语言处理(NLP)和机器翻译领域最经典的三大自动评分指标。
BLEU (Bilingual Evaluation Understudy)
解释: 主要评估精确度(Precision)。它通过计算机器生成的文本和标准参考文本之间,连续字词(n-gram)的完全重合程度来打分。它还会惩罚“为了不出错而写得特别短”的回答(简短惩罚)。
METEOR (Metric for Evaluation of Translation with Explicit ORdering)
解释: 为了弥补 BLEU 太死板的缺陷而生。它引入了同义词词典和词干提取(比如知道 running 和 run 是一个意思)。它不仅看重精确度,更看重召回率(Recall),并对词序的流畅性进行评估。
ROUGE-L (Recall-Oriented Understudy for Gisting Evaluation)
解释: 主要评估召回率(Recall)。论文中特指的 ROUGE-L 是基于“最长公共子序列(LCS)”来计算的。它不需要字词连续匹配,只要能在 AI 的回答中找到按相对顺序排列的“标准答案的关键词”就行





AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)