Agent原理架构与工程实践全解(非常详细),从入门到精通,收藏这一篇就够了!
Agent 这两年几乎成了 AI 圈最容易被“说大了”的词。
有人把它理解成“会调用工具的 LLM”,
有人把它理解成“多轮自动执行任务的系统”,
还有人把它包装成“能自己雇自己、自己管理自己的数字员工”。
这些说法都沾边,但都不够准。
更准确的理解是:Agent 不是一个模型能力名词,而是一种系统设计范式。
它的本质不是“更会聊天”,而是让模型在明确目标、可用工具、状态记忆和安全边界内,替用户完成一个完整工作流。
OpenAI 将 agent 定义为“能代表用户独立完成任务的系统”,并强调它需要由 LLM 管理流程执行和决策、能够动态使用工具;
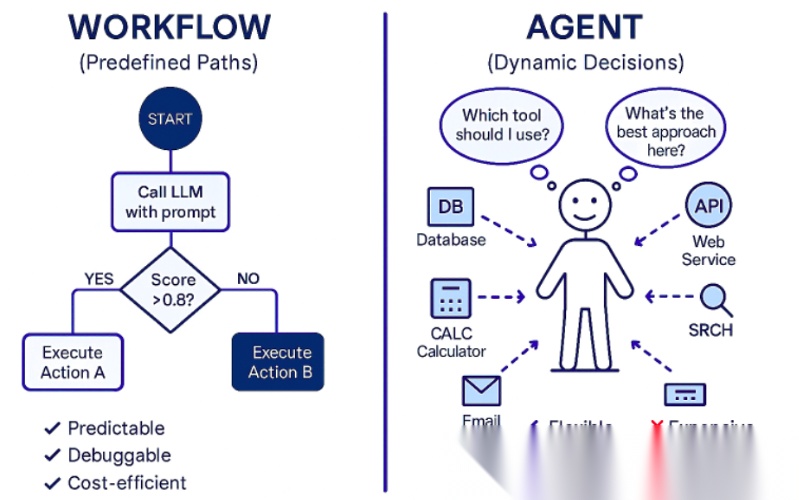
Anthropic 则进一步区分了workflow与agent:前者是预定义代码路径中的 LLM 编排,后者则由 LLM 动态决定过程与工具使用。
所以,真正值得讨论的问题不是“Agent 神不神”,而是它到底解决什么问题:
- 它和传统自动化、RPA、聊天机器人有什么本质区别?
- 一个靠谱的 Agent 系统到底由哪些层组成?
- 为什么很多 Agent Demo 很惊艳,一上生产就翻车?
- 工程上怎样把它做成一个可控、可测、可维护的系统?
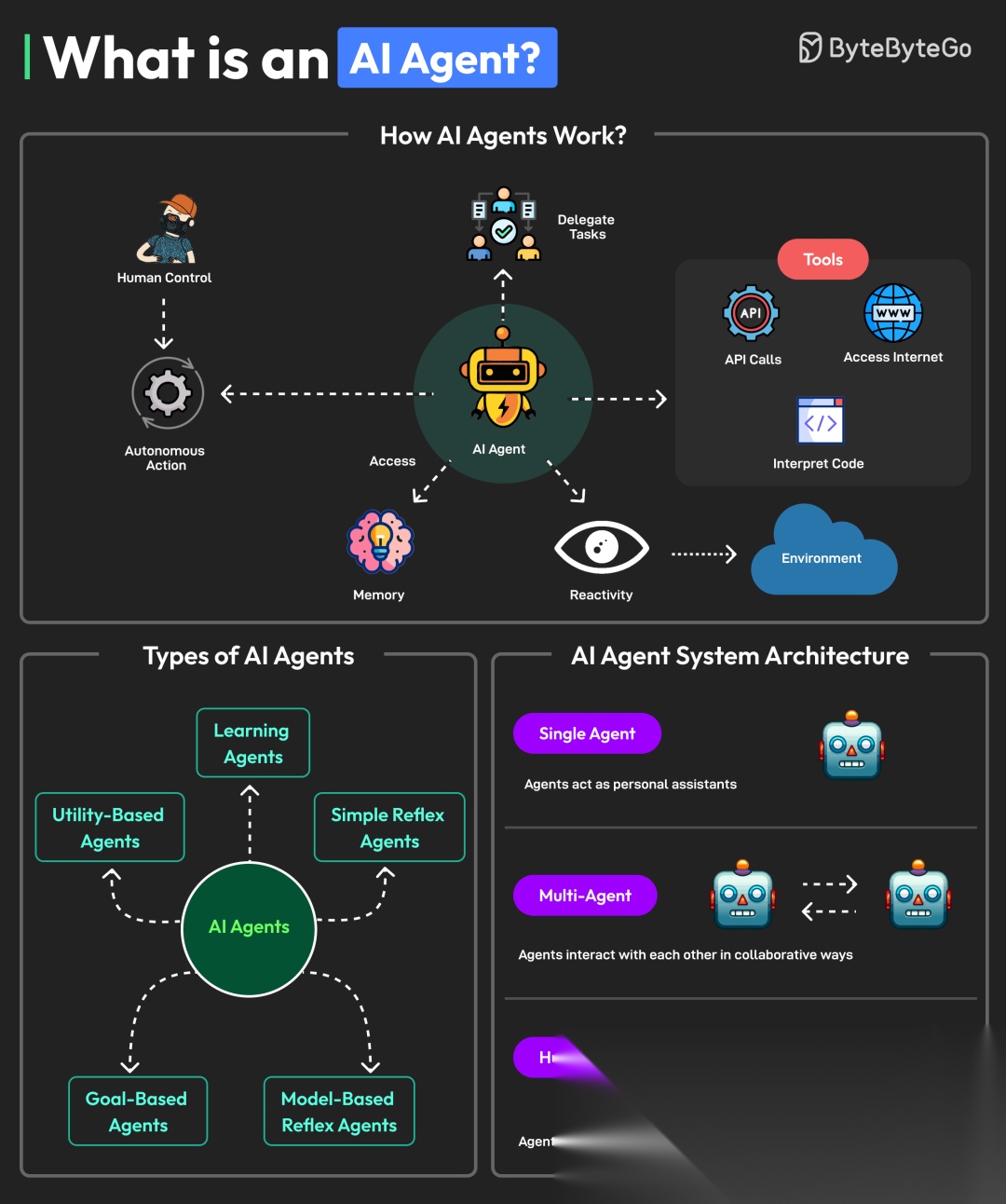
一、先把概念说清:到底什么叫 Agent?
很多人把“带函数调用的聊天机器人”直接叫 Agent,这其实不够严谨。
- Chatbot 不等于 Agent
一个普通问答机器人,即便底层用了大模型,哪怕回答得很聪明,也未必是 Agent。
因为它只是“生成回复”,并没有真正接管任务执行。
比如:“帮我总结这段文本”,这更像单次 LLM 调用。
“帮我查询机票、比较价格、填写乘机人信息并下单”,这才更接近 Agent
区别在于:
前者是“回答问题”;后者是“完成目标”。
OpenAI 在官方实践指南里说得很直接:只集成 LLM,但不让它控制工作流执行的应用,不算 Agent。
真正的 Agent 能以较高自主度替用户执行工作流。
- Workflow 与 Agent 的边界
Anthropic 的划分非常有启发性:
Workflow:LLM 和工具按预定义流程走,代码先写死路径
Agent:LLM 根据上下文和环境反馈,动态决定下一步怎么做、用什么工具、何时结束
这个边界非常重要,因为现实世界里大量“Agent 应用”其实更适合 workflow,而不是完全自治的 agent。
Anthropic 也明确建议:先找最简单可行的方案,只在确实需要时再增加 agentic complexity,因为 agent 往往用更高延迟和更高成本换更强任务表现。
- 一个实用定义
我更喜欢用工程语言给 Agent 下定义:
Agent 是一个由 LLM 驱动的闭环任务执行系统。它围绕目标运行,在状态、工具、环境反馈与安全约束中持续决策,直到完成、失败、被中断或达到停止条件。
这个定义里有五个关键词:
目标:用户想达成什么
决策:下一步做什么
工具:能操作哪些外部系统
反馈:环境返回了什么结果
停止条件:什么时候结束
二、为什么 Agent 会成为新的系统范式?
因为 LLM 的角色变了。
早期大模型更像“语言接口”——你问,它答。
现在的大模型逐渐具备了四种更关键的能力:理解复杂输入、进行推理与规划、可靠使用工具、根据外部反馈修正行为。
Anthropic 在 “Building Effective Agents” 中明确把这四类能力视为 agent 走向生产的关键成熟条件;
OpenAI 也把构建 agent 的核心原语总结为:models、tools、state/memory、orchestration。
传统软件:程序员写死流程,系统执行
Agent 系统:程序员定义边界和能力,模型在边界内动态决策
于是软件工程的范式也变化了:
过去我们主要写业务逻辑,现在我们越来越像在设计一个“受控自治系统”。
三、Agent 的原理:本质上是一个闭环控制系统
Agent 的核心原理,绝不神秘。
它本质上就是一个observe → think → act → observe的循环。
你可以把它理解成一个带语言推理能力的控制器:
接收目标与上下文
观察当前环境状态
判断下一步动作
调用工具或输出结果
获取新反馈
重复,直到完成
OpenAI 在 agent 文档里明确指出:run 的概念本质上是一个 while loop,agent 会持续运行直到满足退出条件,
比如工具调用完成、得到最终结构化输出、出错、或达到最大轮数。
Anthropic 也强调,agent 在执行时必须从环境拿到“ground truth”,例如工具结果或代码执行结果,以评估当前进展。
一个极简抽象:
Goal + Context
↓
LLM Controller
↓
Decide Next Action
↓
Tool Call / Response
↓
Environment Feedback
↓
Update State
↓
Stop? —— No ——> Loop
|
Yes
↓
Final Output
这就是几乎所有 Agent 的骨架。
四、ReAct:Agent 范式真正跑通的关键一步
如果说现代 Agent 有一个“开山之作”,那大概率就是 ReAct。
ReAct 的关键思想非常简单但影响极大:
把 reasoning(推理)与 acting(行动)交错起来。
在 ReAct 之前,很多方法要么强调 chain-of-thought 推理,要么强调 action planning。
而 ReAct 证明,把二者交织在一起,模型能边想边做、边做边修正。
论文原文说得很清楚:它让模型以交错方式生成 reasoning traces 和 task-specific actions,从而形成更强协同。
reasoning 帮助跟踪和更新行动计划,action 则帮助模型与外部知识源或环境交互,拿到更多信息。
这件事为什么重要?
因为真实任务几乎都不是“先完整想完,再一次性执行”。
真正的任务执行更像这样:
先猜一个方向 --> 去查一下–> 发现信息不够 --> 修正判断–> 再执行下一步。
这和人类解决问题的方式也更一致。
ReAct 论文还展示了两个关键价值:减少纯推理路径的幻觉与错误传播和
让中间过程更可解释。
在 HotpotQA 和 FEVER 上,ReAct 通过与简单的 Wikipedia API 交互,缓解了 chain-of-thought 常见的幻觉与误差扩散;
在 ALFWorld 和 WebShop 这类交互决策环境中,也取得了明显提升。
今天绝大多数 Agent loop,本质上都带着 ReAct 的影子。

五、Toolformer:让“用工具”不再只是提示技巧
如果说 ReAct 解释了“Agent 如何边想边做”,那么 Toolformer 解释的是另一个关键问题:
模型能不能自己学会 什么时候该用工具、用什么工具、传什么参数?
Toolformer 给出的答案是可以。
这篇工作提出:语言模型可以通过少量 API 示例,自监督地学习决定何时调用 API、调用哪个 API、传哪些参数,以及如何把返回结果融合回后续 token 预测。()
这背后的意义是巨大的:
工具调用不再只是“外部胶水逻辑”
它可以成为模型推理能力的一部分
Agent 的能力边界,不再只由参数规模决定,还由可接入工具生态决定
你可以把这理解为一句很重要的话:
Agent 时代,模型本体能力 + 工具能力 = 实际系统能力。
一个不会查数据库、不会发邮件、不会执行 SQL、不会读文档、不会调度服务的大模型,再聪明,也很难替你真正完成工作。
六、Agent 的系统架构:不是一个 Prompt,而是一整套运行时
真正的 Agent 从来不是“写个超级 Prompt”就完了。
它更像一套运行时系统。
我把一个生产级 Agent 架构拆成 8 层。
- 交互层:接住用户意图
这一层面向用户,接收:
用户目标
历史对话
附件、图片、音频
权限身份
会话元数据
它的职责不是“回答”,而是把用户任务标准化。
例如把:
“帮我看看下周去上海开会的安排,顺便把酒店订了”
转成一个明确任务对象:
主任务:出差安排
子任务:查行程、查酒店、预订
约束:下周、上海、开会
所需权限:日历、邮件、酒店预订系统
风险等级:中
交互层做不好,后面就会出现“模型理解对了半句,系统却执行错了整件事”的问题。
- Orchestrator:Agent 的大脑外壳
很多人以为 LLM 就是 Agent 的“大脑”。
其实更准确地说:LLM 是决策引擎,而 orchestrator 才是运行时控制器。
它负责:
维护回合循环
决定何时让模型思考
调用哪个工具执行
记录中间状态
处理异常与重试
判断停止条件
触发人工接管
OpenAI 的实践文档把 orchestration 作为 agent 的核心部分,并建议先把单 agent 做强,再考虑多 agent;因为单 agent 加工具,通常已经能覆盖大量任务,而且更易评估和维护。()
所以,工程上最常见的错误之一是:
过早多 Agent 化。
- Model Layer:不止一个模型,而是一组模型策略
生产级 Agent 很少只靠一个模型做所有事。
更常见的是模型分工:
大模型:规划、复杂推理、困难决策
小模型:分类、路由、摘要、格式转换
专用模型:OCR、检索重排、安全检测、代码执行判断
OpenAI 的建议也很实用:先用能力最强的模型建立基线,再尝试替换成更小模型优化成本和延迟。并不是每个子任务都需要最强模型。()
这意味着 Agent 的模型层不是“选型一次”,而是一个router + budget + quality target的组合优化问题。
- Tool Layer:把“会说”变成“会做”
工具层是 Agent 与现实世界连接的地方。
OpenAI 将工具分成三类:
Data tools:获取上下文与信息
Action tools:执行操作
Orchestration tools:把其他 agent 当作工具使用
这其实非常符合工程实践,一个成熟工具层通常包括:
Tool registry:工具注册中心
Schema:参数定义
Executor:执行器
Permission control:权限校验
Retry/timeout:可靠性机制
Result normalizer:结果标准化
工具设计的成败,直接决定 Agent 上限
Anthropic 明确强调:agent 往往就是“LLM 在循环里基于环境反馈使用工具”,所以工具集和工具文档必须设计得清晰、周到。
OpenAI 也强调工具应该有标准化定义、良好文档、可复用和可测试。
这点太重要了。
很多 Agent 失败,不是模型差,而是工具烂:
工具名含糊
参数语义不清
输出格式不稳定
side effect 没说明
错误码不可解释
没有幂等性
无法模拟测试
在工程实践里,写好 tool spec,往往比再调十版 Prompt 更值。
- State / Memory:没有状态,就没有真正连续的 Agent
OpenAI 在官方材料中把state/memory视为构建 agent 的核心原语之一;
Anthropic 也把 memory 列为 augmented LLM 的基础增强能力之一。
但很多团队对 memory 的理解还停留在“把聊天记录拼进去”。
这远远不够。
一个可用的 Agent 至少要区分四类状态:
(1)会话态短期记忆
当前任务的即时上下文,比如:这次任务的目标、已做过哪些步骤、当前轮执行结果、临时变量
(2)任务态过程记忆
这更像“工作台状态”:子任务列表、已完成/未完成节点、工具调用日志、中间产物
(3)长期用户记忆
例如:用户偏好、常用联系人、账户信息、历史决策习惯
(4)外部知识记忆
例如:向量库、文档库、CRM、数据仓库、知识图谱
工程上真正重要的不是“有没有 memory”,而是:
什么该进 prompt,什么该进状态机,什么该进数据库,什么该进检索系统。
把所有东西都塞进上下文,只会让 Agent 又贵又乱又不稳定。
- Observation / Feedback:让 Agent 接触真实世界
Agent 和普通生成系统最大的不同之一,就是它需要不断从环境拿反馈。
这些反馈可能来自:
搜索结果、API 返回、SQL 查询结果、网页状态、文件系统变化、测试用例结果、用户澄清、安全审查器结果
Anthropic 特别强调,Agent 在执行中必须获取 environment ground truth,并以此判断进展。
这意味着 Agent 不是“想得越多越好”,而是:
想一小步,验证一小步,再继续。
这就是为什么真正好用的 Agent 往往不追求“超长思维链一次走到底”,而追求“小步快跑 + 外部校验”。
- Guardrails:没有边界的自治,就是事故源
OpenAI 对这一点讲得非常明确:guardrails 是任何 LLM 部署的关键组成部分,而且应该是分层防御,与认证、授权、访问控制和标准软件安全措施一起使用。
一个成熟 Agent 的 guardrail,至少有五层:
输入防护:越权、注入、越狱、敏感内容
决策防护:不允许超范围目标变更
工具防护:参数校验、权限校验、风险评级
输出防护:敏感信息、品牌风险、合规要求
过程防护:最大步数、预算上限、失败阈值
尤其是高风险动作,一定要引入human-in-the-loop。
OpenAI 也明确建议:对敏感、不可逆或高风险动作,应触发人工干预;而人工接管也是早期上线阶段发现失败模式、建立评测闭环的关键机制。
一句话总结:Agent 可以自动化,但不能无治理。
- Eval / Tracing:看不见,就调不动
很多团队做 Agent 时,把大量精力花在 demo 上,却忽略了最关键的事情:可观测性与评测。
OpenAI 的建议很务实:先建立性能基线、用 eval 评估准确率目标、再做成本与延迟优化、用 tracing 监控 agent loop 和工具调用过程 。
为什么这件事比 Prompt 还重要?
因为 Agent 的错误往往不只出在“最后答案”,而是出在过程某个节点:
任务拆解错了、路由错了、工具选错了、参数传错了、检索召回偏了、安全规则误杀了、重试策略导致死循环。
如果你没有 step trace,就只能看到“结果不对”,却不知道“哪一步先坏掉了”。
所以工程上必须至少记录:
每步 prompt / tool selection
工具输入输出
token、时延、成本
错误类型
终止原因
人工接管点
关键状态转移
七、Agent 的典型工作流模式:不要一上来就全自治
Anthropic 的文章非常值得借鉴,因为它没有鼓吹“越自治越高级”,而是把生产中常见的模式拆成了从简单到复杂的一条光谱。
- Prompt Chaining:串行拆解
适合固定步骤明显的任务。
本质是把一个难任务拆成多个简单 LLM 调用,并在中间加检查点。
典型场景:
提纲 → 审核 → 成文
摘要 → 翻译 → 本地化润色
信息抽取 → 格式校验 → 写入系统
它不是严格意义上的自治 agent,但在很多业务里已经足够好用。
- Routing:先分流,再处理
Routing 把输入分类到不同的下游流程或子 agent。
适合类别明显、不同类别需要不同提示与工具链的场景。
典型场景:
客服分流:退款 / 技术支持 / 售前咨询
医疗分诊:行政问题 / 一般健康咨询 / 高风险建议拦截
金融合规:普通问答 / 投顾限制 / 交易风险提醒
- Parallelization:并行求快或求稳
Anthropic 把并行分成两种:
Sectioning:把独立子任务并行处理
Voting:同一任务多次求解,再投票或聚合
这非常适合:多维评审、安全审核、多草稿生成、多视角分析
本质上,它是在用更多算力换更高置信度。
- Orchestrator-Workers:中央调度 + 动态拆解
这是很多“多 Agent 系统”的真正合理起点。
由中央 orchestrator 根据任务动态拆解,再把子任务交给 worker。Anthropic 认为它特别适合无法预先确定子任务的复杂场景,比如代码修改或多源检索分析。
这类模式比单纯 parallel 更灵活,因为子任务不是预定义的,而是根据输入动态生成的。
- Evaluator-Optimizer:生成—批评—修正
这一模式极其实用。
一个模型负责生成,另一个模型负责评价和反馈,循环改进。
Anthropic 认为当评价标准相对明确、且迭代确实能带来可衡量提升时,这种模式特别有效。
适合:长文写作、搜索研究、复杂 SQL 生成、代码修复、高质量文案产出
- Autonomous Agent:真正的闭环自治
这是最“性感”的模式,也是最容易翻车的模式。
Anthropic 的说法非常到位:适用于无法预估步骤数、不能硬编码固定路径、且你愿意在可信环境中赋予系统一定自治权的任务;但它天然伴随更高成本与错误累积风险,因此必须加强测试和 guardrails。
工程上我非常赞同一个原则:
能用 workflow 解决,就别急着上 full agent。
因为很多业务要的不是“最聪明”,而是“最稳定”。
八、单 Agent 还是多 Agent?我的答案是:先单后多
这是大家最爱问的问题。
我的结论很直接:
默认先做强单 Agent。只有当单 Agent 的提示复杂度、工具复杂度、职责边界已经明显失控时,再拆成多 Agent。
这不是保守,而是工程理性。
OpenAI 的官方建议几乎就是这个意思:
单 agent 通过不断增加工具,往往就能覆盖很多任务,复杂度更可控,评估和维护也更容易。
其总体建议是先把单 agent 的能力最大化,再考虑多 agent,因为更多 agent 会带来额外复杂性和开销。
什么时候应该拆多 Agent?
通常是这几种情况:
- 提示逻辑已经不可维护
一个系统 prompt 里塞满了 if-else、不同角色规则、多个业务分支,改一次就牵一发而动全身。
- 工具过多且高度相似
OpenAI 也提到,问题不只是工具数量,而是工具之间的相似和重叠。少量含糊工具,也可能比十几个清晰工具更难让模型选对。
- 不同任务的评测口径完全不同
例如一个系统同时做客服、财务操作、知识检索、报告写作,这些任务的成功定义不一样,混在一起很难评。
- 权限边界不同
有的 agent 只能读,有的能写,有的能发起敏感动作,这时候拆角色很有必要。
两种常见多 Agent 模式
OpenAI 给出了两种特别典型的多 agent 组织方式:
Manager 模式:中心 agent 像主管一样调用各个专长 agent
Decentralized handoff 模式:多个 agent 彼此转交控制权
前者更适合“一个中枢负责综合”;后者更适合“不同角色轮流接管”。
但请记住:
多 Agent 不是银弹,它只是把复杂性从“一个大 prompt”转移成“多个协同单元”。
九、生产级 Agent 的工程实践:真正难的不是做出来,而是跑得稳
- 从最小闭环开始,而不是从宏大愿景开始
很多团队一上来想做“企业级全能助理”,结果必死。
正确做法是:
先选一个高价值、边界清晰、成功标准明确的任务
把它做成最小闭环
再逐步扩展
Anthropic 总结的两个非常适合 agent 的方向就很典型:
客服类任务:既需要对话,也需要调用外部系统与执行动作
编码类任务:输出可被自动测试验证,反馈明确
这其实揭示了一个普遍规律:
Agent 最适合那些“既有开放性,又有可验证性”的任务。
- 先定义成功,再设计 Agent
这是很多团队最容易跳过的一步。
在动手前,先写清楚:
这个 Agent 的最终任务是什么?
成功的标准是什么?
失败分几类?
不允许做什么?
需要哪些人工接管点?
成本和时延上限是多少?
没有这些定义,你做出来的只会是“看起来很智能”的东西,而不是“能上线负责”的东西。
- 工具先行,而不是 Prompt 先行
很多人是先写 prompt,再补工具。
我建议反过来:
先列出任务需要哪些动作能力
设计好工具接口
规定好输入输出 schema
补齐权限和错误语义
最后再写 agent prompt
因为 Agent 的上限,本质上由“它能可靠完成哪些操作”决定,而不是由“它能说多漂亮”决定。
- 把 Agent 当状态机来做,而不是当聊天机器人来做
这一点特别关键。
工程上要明确维护:
当前任务状态
已执行步骤
中间结果
当前预算
当前风险等级
是否需要人工确认
是否达到停止条件
很多 Agent 的混乱,都是因为状态只放在自然语言上下文里,而没有进入显式状态机。
结果就是模型“记得好像做过”,系统却“不知道做到哪了”。
- 严格设计停止条件
Agent 不怕笨,怕的是不收手。
至少要有这些 stop conditions:
最大步数
最大 token 预算
最大工具调用次数
连续失败阈值
重复动作检测
高风险动作待确认
任务完成置信条件
Anthropic 也明确提到,Agent 常见控制手段之一就是最大迭代数。
很多线上事故,本质上不是“不会做”,而是“停不下来”。
- 让错误变得可恢复
一个成熟 Agent 必须支持三种恢复:
(1)模型恢复
重试
降级
重新规划
(2)工具恢复
超时重试
参数修正
备用工具
(3)人工恢复
请求确认
回退到安全节点
人工接管
OpenAI 也把人工干预视作真实部署中的关键安全阀,尤其适用于失败阈值超限和高风险动作。
- 评测必须覆盖“过程”,不是只测“答案”
Agent 的评测至少分四层:
结果正确性:最终任务是否完成
过程正确性:中间步骤是否合理
工具正确性:调用工具的选择、参数和时机是否正确
系统指标:成本、时延、失败率、人工接管率、重试率
如果只看最终答复,你可能以为系统“偶尔不准”;
但一旦看 trace,你会发现它其实是“经常路由错、偶尔靠运气答对”。
- 安全一定要做成分层体系
一个生产 Agent 的安全,至少应该包括:
Prompt injection 防护
权限边界
工具参数白名单/黑名单
高风险动作审批
数据脱敏
审计日志
输出审查
人工升级通道
OpenAI 对 guardrails 的建议很明确:不是单点规则,而是多层防御机制。
十、Agent 最常见的 10 个坑
- 目标定义模糊
“尽量帮用户处理事情”这种目标没有工程意义。
- 过度自治
给了太多权限,却没给足够约束。
- 工具设计糟糕
模型不知道该选哪个,也不知道怎么传参。
- 没有显式状态
所有过程全靠上下文拼接,必然失控。
- 过早多 Agent 化
架构看起来高级,实际很难调试。
- 没有可观测性
出了问题只能凭感觉改 prompt。
- 没有停止条件
死循环、重复调用、预算爆炸。
- 只测 happy path
一上线就被边缘条件击穿。
- 没有人工接管机制
系统一旦失败,只能硬着头皮胡说八道。
- 追求“通用 Agent”,忽视场景约束
真正创造价值的,往往是“狭义但高闭环”的 Agent。
十一、一个通用 Agent 参考架构
下面给一个相对完整的通用参考架构:
[User / System Goal]
↓
[Task Interpreter]
- 理解目标
- 抽取约束
- 初始化状态
↓
[Planner]
- 任务拆解
- 生成阶段计划
↓
[Execution Controller / Loop]
- 选择下一步
- 调度模型或工具
- 维护状态机
↓
[Tool Layer]
- Search
- Database
- Browser
- Code Executor
- Business APIs
↓
[Observation Processor]
- 解析结果
- 提炼关键信息
- 错误归因
↓
[Memory Layer]
- 短期任务记忆
- 长期用户记忆
- 工作记忆
↓
[Verifier / Guardrails]
- 格式校验
- 规则检查
- 权限控制
- 安全门控
↓
[Output / Action Delivery]
- 文本结果
- 文件交付
- 系统操作
这个架构里,真正最核心的不是某一个模块,而是Execution Controller。
因为它决定:
什么时候思考
什么时候调用工具
什么时候写记忆
什么时候验证
什么时候结束
它就是 Agent 的“操作系统”。
十二、一个实战视角:如何从 0 到 1 做出可上线的 Agent
我会建议按这 7 步走:
第一步:选一个高价值窄任务
比如:
售后退款处理
合同审阅摘要
内部知识检索 + 结论输出
报销材料预审
代码修复与测试回归
第二步:写清任务边界
输入、输出、成功定义、风险点、不允许动作
第三步:先做工具,不急着做“智能”
把读写动作都做成标准工具。
第四步:先做单 Agent 闭环
一个 agent + 一组工具 + 明确 stop conditions。
第五步:加 trace 和 eval
没有它们,后续全靠猜。
第六步:加 guardrails 和人工接管
尤其是涉及钱、隐私、审批、外发动作的任务。
第七步:在真实流量下迭代
不是看 demo 漂不漂亮,而是看:
成功率
接管率
成本
时延
用户满意度
失败模式分布
这个路线其实和 Anthropic、OpenAI 的公开经验很一致:从简单可组合模式起步,先建立强基线,按实际收益再增加复杂度。
十三、对 Agent 的几个判断
最后,我给几个尽量不追热词的判断。
判断一:Agent 不是“更高级的 Prompt”
它是运行时系统、工具系统、状态系统和治理系统的组合。
判断二:Agent 的关键不是“会不会思考”,而是“能不能在反馈中持续纠偏”
这正是 ReAct 这类范式影响深远的原因。
判断三:未来软件的一大方向,是把“写死流程”改成“定义边界内的自治”
但边界、审计、权限、评测会变得比过去更重要。
判断四:单 Agent + 工具,在未来很长时间里都会是主流
多 Agent 会存在,但不会是默认答案。OpenAI 和 Anthropic 的公开建议都偏向先简后繁、先单后多。
判断五:真正能创造业务价值的 Agent,往往不是最通用的,而是最闭环的
越接近明确目标、明确反馈、明确风险边界,越容易落地。
十四、未来 Agent 会演化到什么方向
未来 Agent 很可能会沿这几个方向继续增强:
- 更强的世界模型
不仅会语言推理,还更懂任务结构、环境状态和因果关系。
- 更长时程记忆
支持跨天、跨周、跨项目持续协作。
- 更强的工具自治
能自己发现、学习和组合工具。
- 更强的验证闭环
不再只是“生成结果”,而是“生成—验证—修正”一体化。
- 更深的企业系统融合
直接嵌入 CRM、ERP、工单、研发、办公套件中。
所以,Agent 的未来不是一个孤立 App,而是成为下一代软件系统的智能调度层。
十五、Agent 不是模型外挂,而是“面向目标的软件新范式”
如果要把全文压缩成一句更硬核的话,我会这么说:
Agent 的本质,是把语言模型从“条件文本生成器”升级为“面向目标的闭环任务控制器”。
再展开一点:
LLM提供的是认知近似能力:理解、推理、压缩状态、生成计划
工具系统提供的是外部作用能力:查询、计算、执行、写入
状态系统提供的是任务连续性:记住已知、维护进度、隔离错误
反馈机制提供的是闭环修正:根据环境返回更新行为
护栏与验证提供的是工程可用性:让系统不只聪明,而且可控
所以,Agent 不是“会调工具的大模型”,更不是“几个 AI 角色开会”。
它是一个更深的东西:
一种让自然语言意图能够被持续映射为可验证行动的软件架构。
这才是 Agent 的核心。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 1
1 0
0- 0



 已为社区贡献77条内容
已为社区贡献77条内容

所有评论(0)