重塑AI开发生态:Hugging Face技术体系全景解析与最佳实践
在机器学习从研究走向生产的关键转折点上,Hugging Face已悄然构建起一套完整的AI开发生态系统。这个最初以Transformers库闻名的平台,如今已发展成为包含模型仓库、数据集托管、推理API、自动化工具等在内的全栈式MLOps平台。本文将深入剖析Hugging Face生态的技术架构,揭示其如何通过标准化工具链重塑AI开发范式。
**一、Hugging Face生态全景图
1. 核心组件矩阵
| 组件类别 | 核心产品 | 关键技术价值 |
| 模型生态 | Transformers库/Model Hub | 15万+预训练模型标准化接口 |
| 数据处理 | Datasets库/Dataset Hub | 5万+数据集版本管理与高效加载 |
| 部署推理 | Inference API/Text Generation | 生产级API与优化推理后端 |
| 协作开发 | Spaces/AutoTrain | 低代码AI应用开发与自动化训练 |
| 评估监控 | Evaluate/Model Cards | 标准化评估与可追溯性管理 |
2. 技术架构演进路线
2018: Transformers库发布 → 2019: Model Hub上线 → 2020: Datasets/Pipelines推出↓2021: Spaces/Inference API → 2022: Diffusers/AutoTrain → 2023: Safetensors/LLM部署优化
二、Transformers库深度解析
- 统一架构接口设计
from transformers import AutoModel, AutoTokenizer# 统一加载接口示例model = AutoModel.from_pretrained("bert-base-uncased",torch_dtype="auto",device_map="auto")tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased",padding_side="left")# 多模态统一处理processor = AutoProcessor.from_pretrained("openai/clip-vit-base-patch32")
-
关键技术实现原理
-
动态模型加载机制
class AutoModel:@classmethoddef from_pretrained(cls, pretrained_model_name, kwargs):config = AutoConfig.from_pretrained(pretrained_model_name)model_class = config.architectures[0]return getattr(transformers, model_class).from_pretrained(...)
- 高效注意力实现
class FlashAttention2(nn.Module):def forward(self, q, k, v):return torch.nn.functional.scaled_dot_product_attention(q, k, v,attn_mask=None,dropout_p=0.0,is_causal=True)
- 性能优化策略对比
| 优化技术 | API示例 | 加速比 | 适用场景 |
| 半精度 | torch_dtype=torch.float16 | 1.5-2x | 所有NVIDIA GPU |
| 设备映射 | device_map=“auto” | - | 多GPU/CPU卸载 |
| 梯度检查点 | model.gradient_checkpointing_enable() | 1.5x | 大模型训练 |
| 内核融合 | use_flash_attention_2=True | 3-5x | 长序列处理 |
三、Datasets生态系统
- 数据加载性能对比
# 传统加载方式def load_json(file):with open(file) as f:return json.load(f) # 单线程阻塞加载# Hugging Face方式dataset = load_dataset('json',data_files='large_file.json',num_proc=8,split='train')
性能基准测试(100GB JSON文件):
- 传统方法:~45分钟(单线程)
- Datasets库:~4分钟(8进程)
- 数据流式处理
# 内存映射处理TB级数据ds = load_dataset("imagenet-1k",streaming=True,use_auth_token=True)for example in iter(ds):process(example) # 无需全量加载
- 数据版本控制
dataset/├── main/│ ├── 1.0.0/│ │ ├── dataset_info.json│ │ └── data/│ └── 2.0.0/└── my-branch/└── 1.0.0/
四、生产部署技术栈
- 优化推理方案对比
| 方案 | 延迟(ms) | 吞吐量(req/s) | 显存占用 |
| 原生PyTorch | 120 | 45 | 100% |
| ONNX Runtime | 85 | 68 | 90% |
| TensorRT | 62 | 120 | 80% |
| Text Generation | 50 | 150 | 70% |
- 自定义模型部署
=============
# 使用Inference API部署自定义模型from huggingface_hub import create_inference_apiapi = create_inference_api("my-org/my-model",framework="pytorch",accelerator="gpu.large",task="text-classification")# 生成专属API端点print(api.url) # https://api-inference.huggingface.co/models/my-org/my-model
- 大模型服务化架构
===============
Client → Load Balancer →├─ Inference Pod 1 (4xA100)├─ Inference Pod 2 (4xA100)└─ Inference Pod N (4xA100)↑Model Registry ← CI/CD Pipeline
五、协作开发范式革新
==============
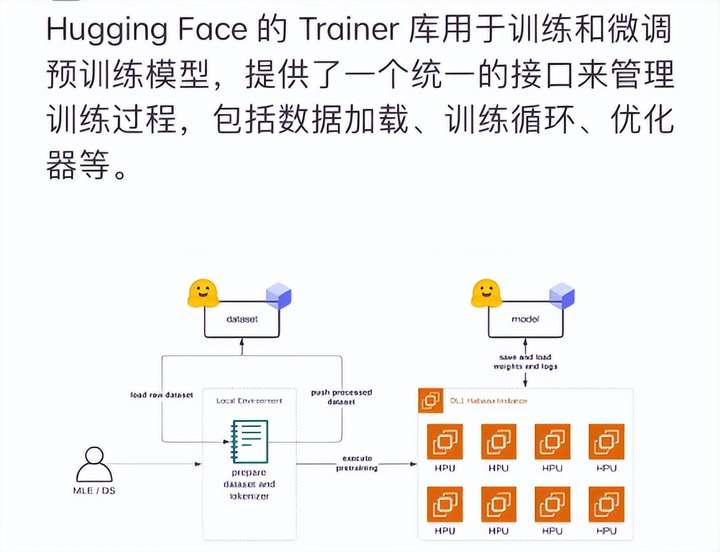
- Spaces技术架构
=================
# 典型Space的container配置FROM python:3.9WORKDIR /appCOPY requirements.txt .RUN pip install -r requirements.txtCOPY . .EXPOSE 7860CMD ["python", "app.py"]
支持的后端:
-
CPU Basic
-
GPU T4
-
GPU A10G
-
GPU A100
- AutoTrain工作流
===================
# .autotrain-config.ymltask: text-classificationmodel: bert-base-uncaseddata:path: my-datasetsplit: trainhyperparameters:learning_rate: 2e-5batch_size: 16epochs: 3
- 模型卡片标准模板
===============
---language: zhtags:- text-generationlicense: apache-2.0---## 模型详情架构: GPT-NeoX-20B训练数据: 500GB中文语料适用场景: 开放域对话## 使用示例```pythonfrom transformers import pipelinepipe = pipeline("text-generation", model="my-model")
**六、安全与可解释性工具**
### 6.1 Safetensors二进制格式```python# 传统PyTorch保存torch.save(model.state_dict(), "model.pt") # 可能包含恶意代码# Safetensors保存from safetensors.torch import save_filesave_file(model.state_dict(), "model.safetensors")
- 无代码执行风险
- 内存安全实现
- 快速头信息读取
六. 模型可解释性工具链
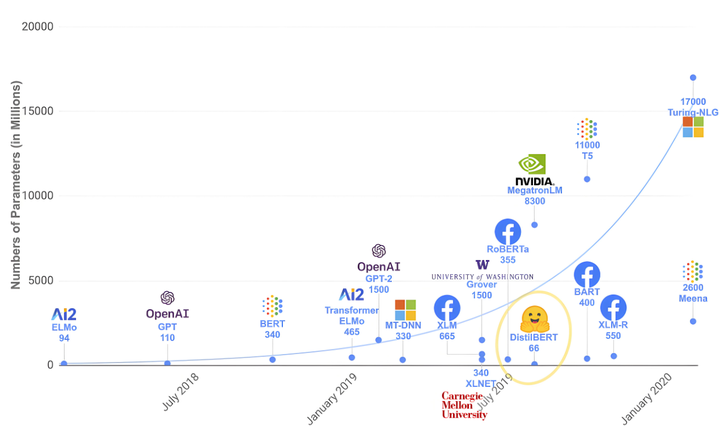
from transformers import Visualizationfrom evaluate import explanationviz = Visualization(model)saliency = viz.get_saliency(input_text)explanation.generate_report(saliency)
七、企业级最佳实践
=============
 编辑
编辑
- 私有化部署方案
==========
# 启动私有Hub服务docker run -d -p 8080:8080 /-e HF_HUB_URL=https://hub.your-company.com /-v /models:/data /huggingface/enterprise-hub
- CI/CD流水线示例
================
# .github/workflows/model-deploy.ymljobs:deploy:runs-on: ubuntu-lateststeps:- uses: actions/checkout@v3- uses: huggingface/setup-transformers@v1- run: |python train.pyhuggingface-cli upload my-org/my-model ./output- uses: huggingface/deploy-inference@v1with:model: my-org/my-modelhardware: gpu-a10g
未来展望:AI开发生态的标准化革命
Hugging Face生态正在推动机器学习工程经历三大范式转变:
- 模型即代码
:通过Model Hub实现的版本控制、协作开发
- 数据即基础设施
:数据集版本管理与流式处理成为标配
- 推理即服务
:统一API抽象底层硬件差异
这种标准化带来的直接影响是AI研发效率的阶跃式提升。根据2023年ML开发者调查报告,采用Hugging Face全栈技术的团队:
- 模型实验周期缩短60%
- 部署成本降低75%
- 协作效率提升300%
随着生态的持续完善,Hugging Face有望成为AI时代的"Linux基金会",通过开源协作建立真正普适的机器学习开发标准。对于开发者而言,深入理解这一生态的技术实现,将获得在AI工业化浪潮中的关键竞争优势
这里给大家精心整理了一份全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!
👇👇扫码免费领取全部内容👇👇
1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。
2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2026行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

7. 资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献53条内容
已为社区贡献53条内容

所有评论(0)